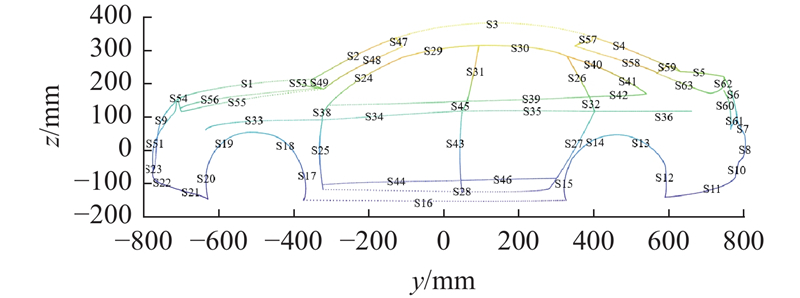
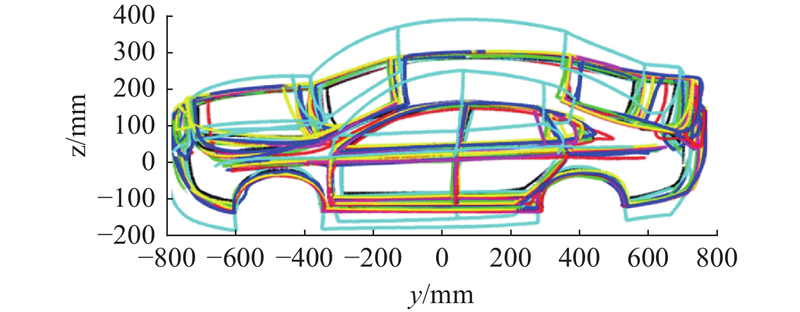
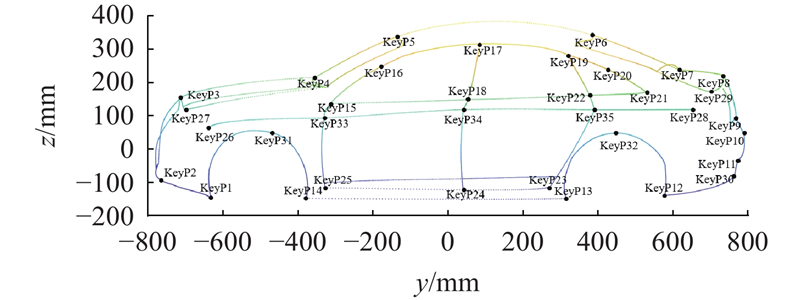
In the face of complex design tasks, traditional hand-drawn sketches and 3D reconstruction methods often require a huge investment of time, labor, and financial resources. In order to overcome these challenges, a geometric topology-based viewpoint recognition and 3D wireframe model reconstruction method for automobiles was proposed. A model library containing a small number of 3D wireframe models of automobiles was established, which was expanded to 3528 models by multi-scale scaling of body height, width, wheelbase and other parameters. The key point labeling of the car body adopted an interactive system developed based on Matlab, which utilized the labeled key points to match with the projection point sets of different viewpoints in the 3D wireframe model library to identify the angles of the car. The reconstruction of the complex 3D wireframe model was accomplished by using the least squares method with constraints based on the topological relationships of the key points in the 3D model. The reconstruction of 3D wireframe model of arbitrary vehicle types could be realized by updating the model in the model library and the positions of key points. The experimental results showed that the reconstruction time was about 33~44 seconds, and the error of key points was controlled within 32 mm. The reconstruction time and reconstruction error of this method were significantly lower those of the traditional reconstruction method in different viewpoints, demonstrating higher reconstruction efficiency and accuracy.
Keywords:car modeling
;
geometric topology
;
key point
;
vehicle angle recognition
;
3D wireframe reconstruction
WU Qi, WANG Bo, WANG Huawei, HU Li, LI Baojun. Vehicle view recognition and 3D wireframe model reconstruction based on geometric topology. Journal of Zhejiang University(Engineering Science)[J], 2025, 59(9): 1864-1871 doi:10.3785/j.issn.1008-973X.2025.09.010
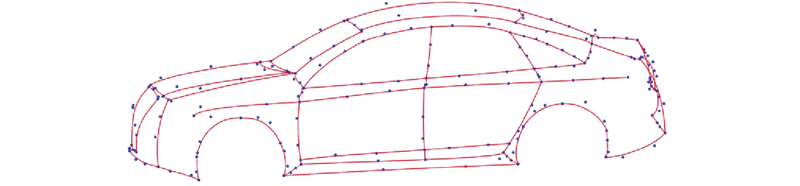
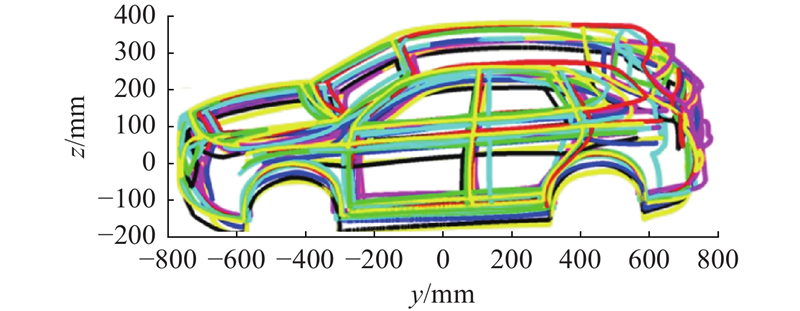
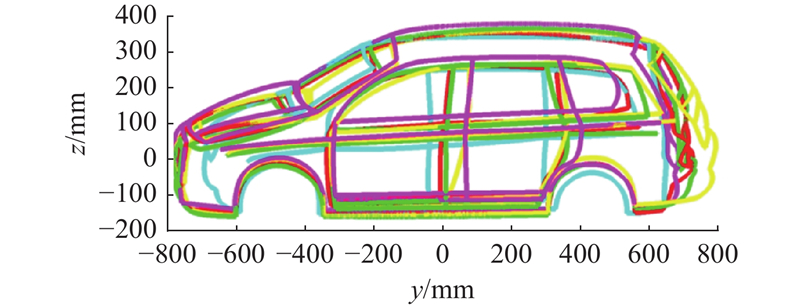
Fig.10
Plotting results of reconstructed wireframe model in image
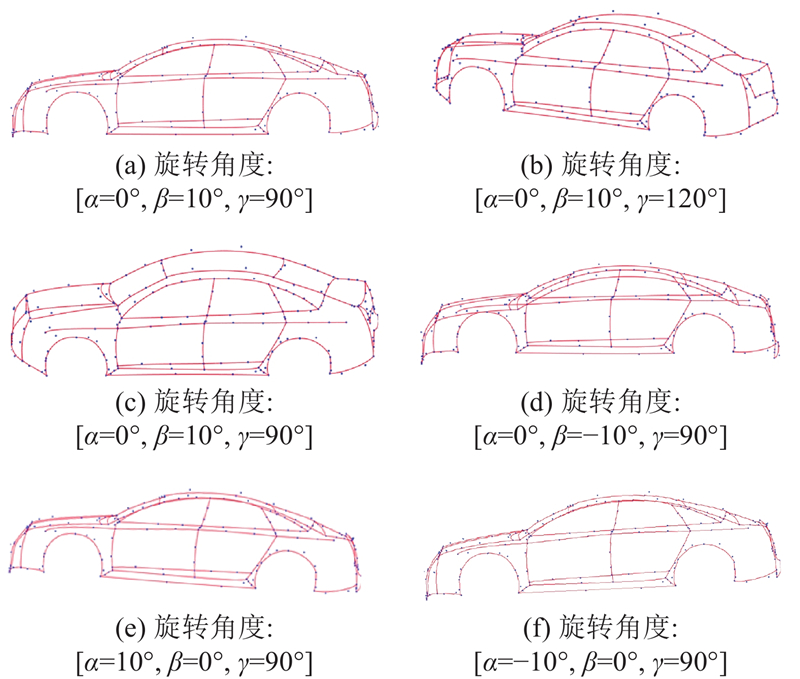
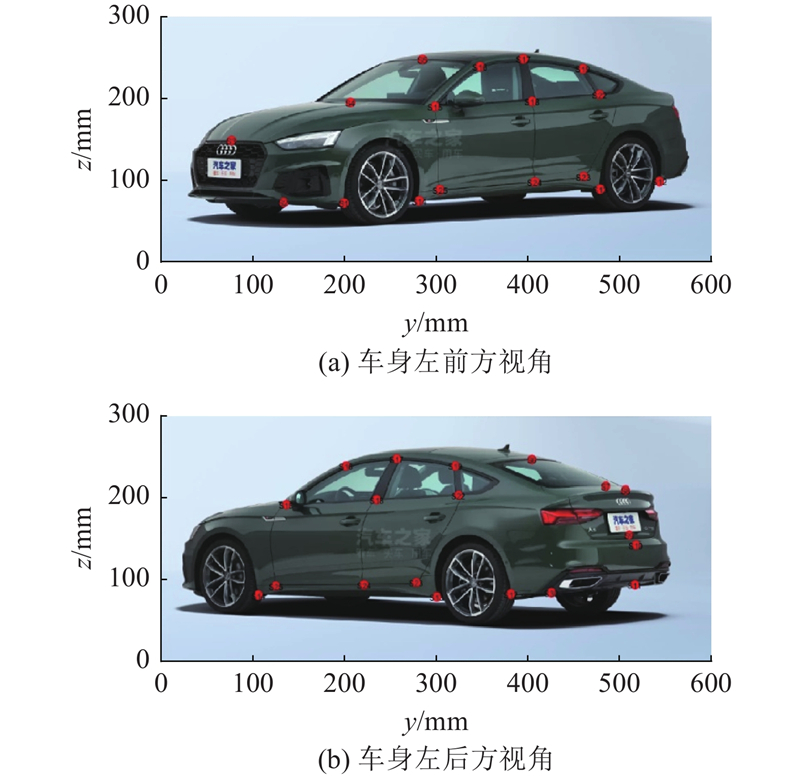
手工重建汽车三维线框模型的时间会根据多种因素而变化,包括建模者的经验、汽车模型的复杂度、所需精细度以及每天投入的工作时间. 一个专业的汽车建模工程师绘制三维线框模型需要约3~4 h. 相比之下,本研究算法凭借自动化和高效的数据处理能力,能在短时间内完成汽车三维线框模型的重建. 其中,关键点标注阶段用时30~40 s,重建三维线框阶段用时3~4 s,全过程用时33~44 s.
3.2. 误差分析
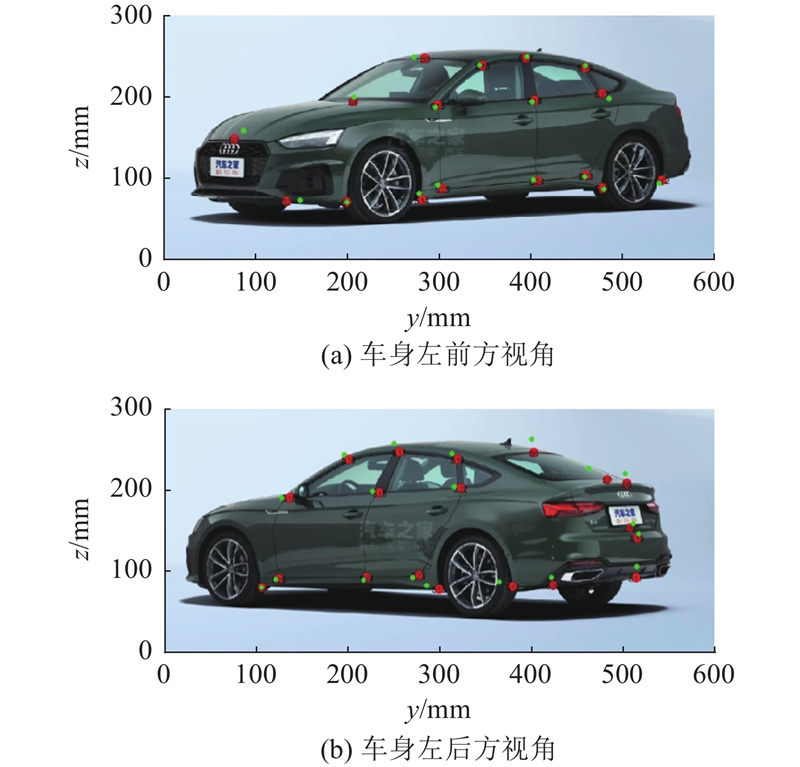
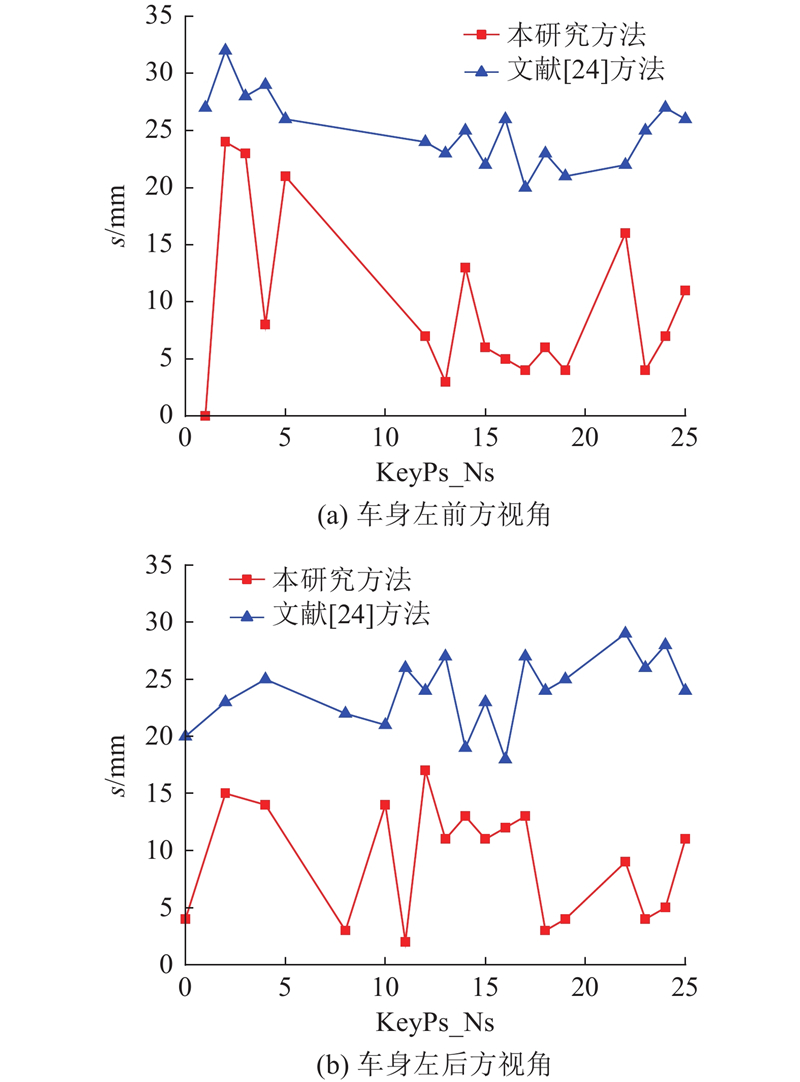
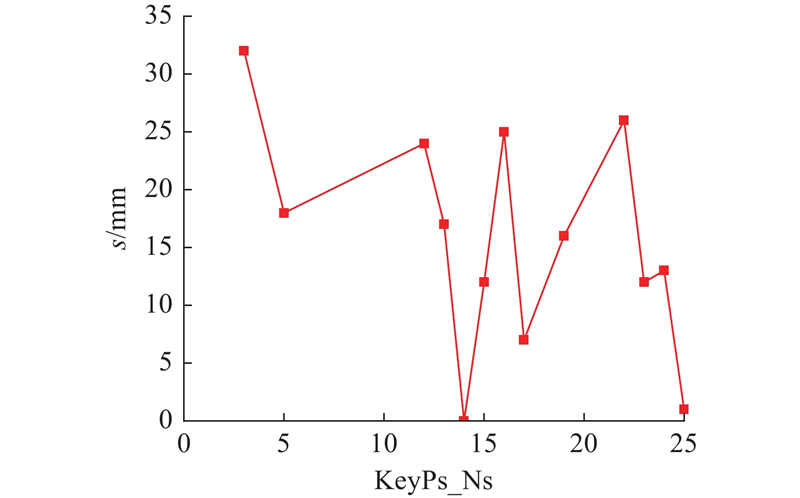
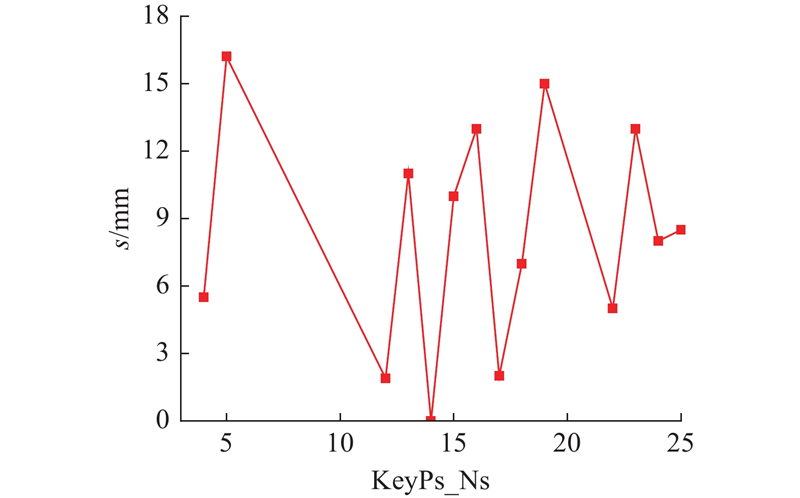
本研究方法与文献[24]中方法的重建误差对比分析结果如图11所示. 从误差分析结果可以看出,基于本研究的方法,图7(a)的关键点误差s小于25 mm,图7(b)的关键点误差s小于17 mm. 与文献[24]相比,本研究重建方法显著提高了重建精度.
LIU F, LIU X. 2D GANs meet unsupervised single-view 3D reconstruction [C]// European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 497–514.
WALLACE B, HARIHARAN B. Few-shot generalization for single-image 3D reconstruction via priors [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 3817−3826.
KATO H, HARADA T. Learning view priors for single-view 3D reconstruction [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 9770−9779.
WU J, ZHANG C, ZHANG X, et al. Learning shape priors for single-view 3D completion and reconstruction [C]// European Conference on Computer Vision. Cham: Springer International Publishing, 2018: 673–691.
XU Q, WANG W, CEYLAN D, et al. DISN: Deep implicit surface network for high-quality single-view 3d reconstru- ction[J]. Advances in neural information processing syste- ms , 2019, 32.
REDDY N D, VO M, NARASIMHAN S G. CarFusion: combining point tracking and part detection for dynamic 3D reconstruction of vehicles [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1906–1915.
TATARCHENKO M, RICHTER S R, RANFTL R, et al. What do single-view 3D reconstruction networks learn? [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 3400-3409.
GAO C, SUN C, SHAN L, et al. Rotate3D: representing relations as rotations in three-dimensional space for knowledge graph embedding [C]// Proceedings of the 29th ACM International Conference on Information and Knowledge Management. [s. l. ]: ACM, 2020: 385−394.
HUANG Y, ZHENG W, ZHANG Y, et al. Tri-perspective view for vision-based 3D semantic occupancy prediction [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2023: 9223–9232.
ZHAO R, WANG H, ZHANG C, et al. PointNeuron: 3D neuron reconstruction via geometry and topology learning of point clouds [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2023: 5776–5786.
DI NUCCI D, SIMONI A, TOMEI M, et al. KRONC: keypoint-based robust camera optimization for 3D car reconstruction [C]// European Conference on Computer Vision. Cham: Springer, 2025: 140−157.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}