[18]
程靖云, 王布宏, 罗鹏 基于图表示和MHGAT的代码漏洞静态检测方法
[J]. 系统工程与电子技术 , 2023 , 45 (5 ): 1535 - 1543
[本文引用: 1]
CHENG Jingyun, WANG Buhong, LUO Peng Code vulnerability static detection method based on graph representation and MHGAT
[J]. Journal of Systems Engineering and Electronics , 2023 , 45 (5 ): 1535 - 1543
[本文引用: 1]
[1]
田笑, 常继友, 张弛, 等 开源软件缺陷预测方法综述
[J]. 计算机研究与发展 , 2023 , 60 (7 ): 1467 - 1488
[本文引用: 1]
TIAN Xiao, CHANG Jiyou, ZHANG Chi, et al Survey of open-source software defect prediction method
[J]. Journal of Computer Research and Development , 2023 , 60 (7 ): 1467 - 1488
[本文引用: 1]
[19]
MARCELO A, FRANCISCO C, FRANCISCO B. An user configurable clang static analyzer taint checker [C] //Proceedings of the 35th International Conference of the Chilean Computer Science Society . Valparaíso: IEEE, 2016: 10-14.
[本文引用: 1]
[20]
YAN Y T, PAN Z L, YU L, et al. Research on the influencing factors of LLVM IR optimization effect [C] //Proceedings of the 3rd International Conference on Information Technology, Big Data and Artificial Intelligence . Chongqing: IEEE 2023: 756-763.
[本文引用: 1]
[2]
ZHANG X W, ZHOU Y, TAN S H, et al. Efficient pattern-based static analysis approach via regular-expression rules [C]//Proceedings of the 2023 IEEE International Conference on Software Analysis, Evolution and Reengineering . Taipa: IEEE, 2023: 132-143.
[本文引用: 1]
[3]
CHEN D, ZHANG Y D, WEI W, et al Efficient vulnerability detection based on an optimized rule checking static analysis technique
[J]. Frontiers of Information Technology and Electronic Engineering , 2017 , 18 (3 ): 332 - 345
DOI:10.1631/FITEE.1500379
[本文引用: 2]
[21]
PEELER H, LI S, SLOSS A N, et al. Optimizing LLVM pass sequences with shackleton: a linear genetic programming framework [C] //Proceedings of the 2022 Genetic and Evolutionary Computation Conference Companion . Boston: ACM, 2022: 578-581.
[本文引用: 1]
[22]
MIRSKY Y, MACON G, BROWN M, et al. VulChecker: graph-based vulnerability localization in source code [C] //Proceedings of the 32nd Usenix Security Symposium . Anaheim: ACM, 2023: 6557-6574.
[本文引用: 1]
[4]
苏小红, 郑伟宁, 蒋远, 等 基于学习的源代码漏洞检测研究与进展
[J]. 计算机学报 , 2024 , 47 (2 ): 337 - 374
[本文引用: 1]
SU Xiaohong ZHEN Weining, JIANG Yuan, et al Research and progress on learning-based source code vulnerability detection
[J]. Chinese Journal of Computers , 2024 , 47 (2 ): 337 - 374
[本文引用: 1]
[23]
GILPIN L H, BAU D, YUAN B Z, et al. Explaining explanations: an overview of interpretability of machine learning [C] //Proceedings of the 5th International Conference on Data Science and Advanced Analytics . Turin: IEEE, 2018: 80-89.
[本文引用: 1]
[24]
CHAKRABORTY S, KRISHNA R, DING Y, et al Deep learning based vulnerability detection: are we there yet?
[J]. IEEE Transactions on Software Engineering , 2020 , 9 (48 ): 3280 - 3296
[本文引用: 1]
[5]
LI Z, ZOU D Q, XU S H, et al. VulDeePecker: a deep learning based system for vulnerability detection [C] //Proceedings of the 25th Network and Distributed System Security Symposium . San Diego: IEEE, 2018.
[本文引用: 2]
[6]
LI Z, ZOU D Q, XU S H, et al SySeVR: a framework for using deep learning to detect software vulnerabilities
[J]. IEEE Transactions on Dependable and Secure Computing , 2022 , 19 (4 ): 2244 - 2258
DOI:10.1109/TDSC.2021.3051525
[本文引用: 2]
[7]
LI Z, ZOU D Q, XU S H, et al VulDeeLocator: a deep learning-based fine-grained vulnerability detector
[J]. IEEE Transactions on Dependable and Secure Computing , 2022 , 19 (4 ): 2821 - 2837
DOI:10.1109/TDSC.2021.3076142
[本文引用: 1]
[8]
WU Y M, ZOU D Q, DOU S H, et al. VulCNN: an image inspired scalable vulnerability detection system [C] //Proceedings of the 44th International Conference on Software Engineering , Pittsburgh: ACM, 2022: 2365-2376.
[本文引用: 1]
[9]
ZHOU Y Q, LIU S Q, DU X N, et al Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks
[J]. Neural Information Processing Systems , 2019 , 2019 (32 ): 10197 - 10207
[本文引用: 1]
[10]
WANG H T, YE G X, TANG Z Y, et al Combining graph-based learning with automated data collection for code vulnerability detection
[J]. IEEE Transactions on Information Forensics and Security , 2021 , 2021 (16 ): 1943 - 1958
[本文引用: 2]
[11]
FAN Y H, WAN C H, FU C, et al VDoTR: vulnerability detection based on tensor representation of comprehensive code graphs
[J]. Computers and Security , 2023 , 2023 (130 ): 103247
[本文引用: 2]
[12]
ALOMAR E A, ALOMAR S A, MKAOUER M W. On the use of static analysis to engage students with software quality improvement: an experience with PMD [C] //Proceeding of 2023 IEEE/ACM 45th International Conference on Software Engineering: Software Engineering Education and Training. Melbourne: IEEE, 2023: 179-191.
[本文引用: 1]
[13]
BARTA B, MANZ G, SIKET I, et al. Challenges of sonarqube plug-in maintenance [C] //Proceedings of the 26th International Conference on Software Analysis , Evolution, and Reengineering . Hangzhou: IEEE, 2019: 574-578.
[本文引用: 1]
[14]
PERL H, DECHAND S, SMITH M, et al. VCCFinder: finding potential vulnerabilities in open-source projects to assist code audits [C] //Proceedings of the 22nd ACM Conference on Computer and Communications Security . Denver: ACM, 2015: 426-437.
[本文引用: 1]
[15]
ZOU D Q, XU S H, WANG S J, et al μVulDeePecker: a deep learning-based system for multiclass vulnerability detection
[J]. IEEE Transactions on Dependable and Secure Computing , 2019 , 18 (5 ): 2224 - 2236
[本文引用: 1]
[16]
FENG Q, FENG C D, HONG W J, et al. Graph neural network-based vulnerability predication [C] //Proceedings of the 2020 IEEE International Conference on Software Maintenance and Evolution . Adelaide: IEEE, 2020: 800-801.
[本文引用: 1]
[17]
徐泽鑫, 段立娟, 王文健, 等 基于上下文特征融合的代码漏洞检测方法
[J]. 浙江大学学报: 工学版 , 2022 , 56 (11 ): 2260 - 2270
[本文引用: 1]
XU Zexin, DUAN Lijuan, WANG Wenjian, et al Code vulnerability detection method based on contextual feature fusion
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (11 ): 2260 - 2270
[本文引用: 1]
[25]
张学军, 张奉鹤, 盖继扬, 等 mVulSniffer: 一种多类型源代码漏洞检测方法
[J]. 通信学报 , 2023 , 44 (9 ): 149 - 160
[本文引用: 1]
ZHANG Xuejun, ZHANG Fenghe, GAI Jiyang, et al mVulSniffer: a multi-type source code vulnerability sniffer method
[J]. Journal on Communications , 2023 , 44 (9 ): 149 - 160
[本文引用: 1]
[26]
YANG G A review of machine learning-based zero-day attack detection: challenges and future directions
[J]. The International Journal for the Computer and Telecommunications Industry , 2023 , (198 ): 175 - 185
[本文引用: 1]
[27]
ROMERA P B, TORR P. An embarrassingly simple approach to zero-shot learning [C] //Proceedings of the 2020 Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 100-109.
[本文引用: 1]
基于图表示和MHGAT的代码漏洞静态检测方法
1
2023
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
基于图表示和MHGAT的代码漏洞静态检测方法
1
2023
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
开源软件缺陷预测方法综述
1
2023
... 随着市场对软件安全需求的提升,针对软件漏洞的检测成为该领域的研究热点[1 ] . 近年来,国内外学者提出使用静态测试和动态分析的方法对源代码漏洞进行检测与分析. 动态分析在面对大型复杂软件系统的漏洞时,存在检测率较低的问题. 与动态分析相比,静态测试能够在不实际运行程序的情况下发现源代码中的安全漏洞,解决了动态分析无法完全覆盖所有代码的问题,得到了研究者的高度重视. 静态测试主要包括模式匹配[2 ] 、规则检查[3 ] 和基于学习的方法[4 ] . 模式匹配和规则检查严重依赖人工,对未定义的漏洞模式缺乏识别能力. 利用基于学习的方法,能够有效避免因人工定义导致的漏洞模式不全的问题,该方法成为静态测试的主要手段之一. ...
开源软件缺陷预测方法综述
1
2023
... 随着市场对软件安全需求的提升,针对软件漏洞的检测成为该领域的研究热点[1 ] . 近年来,国内外学者提出使用静态测试和动态分析的方法对源代码漏洞进行检测与分析. 动态分析在面对大型复杂软件系统的漏洞时,存在检测率较低的问题. 与动态分析相比,静态测试能够在不实际运行程序的情况下发现源代码中的安全漏洞,解决了动态分析无法完全覆盖所有代码的问题,得到了研究者的高度重视. 静态测试主要包括模式匹配[2 ] 、规则检查[3 ] 和基于学习的方法[4 ] . 模式匹配和规则检查严重依赖人工,对未定义的漏洞模式缺乏识别能力. 利用基于学习的方法,能够有效避免因人工定义导致的漏洞模式不全的问题,该方法成为静态测试的主要手段之一. ...
1
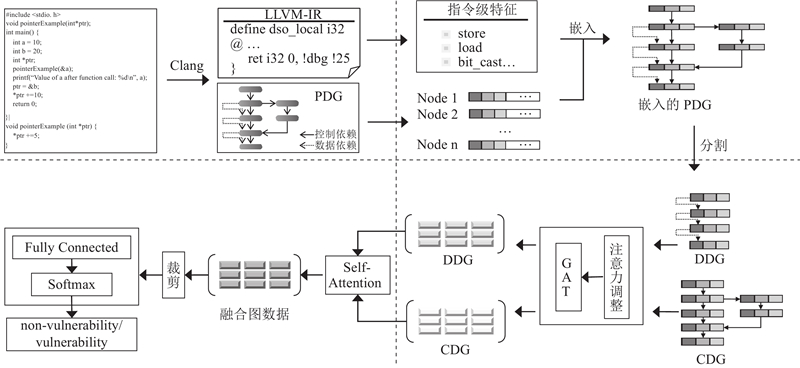
... 如图1 (a)所示,本文通过底层虚拟机(low-level virtual machine, LLVM)编译器前端Clang[19 ] ,生成中间代码LLVM-IR[20 ] 和AST,利用Pass[21 ] 提取依赖信息以生成PDG. ...
1
... 如图1 (a)所示,本文通过底层虚拟机(low-level virtual machine, LLVM)编译器前端Clang[19 ] ,生成中间代码LLVM-IR[20 ] 和AST,利用Pass[21 ] 提取依赖信息以生成PDG. ...
1
... 随着市场对软件安全需求的提升,针对软件漏洞的检测成为该领域的研究热点[1 ] . 近年来,国内外学者提出使用静态测试和动态分析的方法对源代码漏洞进行检测与分析. 动态分析在面对大型复杂软件系统的漏洞时,存在检测率较低的问题. 与动态分析相比,静态测试能够在不实际运行程序的情况下发现源代码中的安全漏洞,解决了动态分析无法完全覆盖所有代码的问题,得到了研究者的高度重视. 静态测试主要包括模式匹配[2 ] 、规则检查[3 ] 和基于学习的方法[4 ] . 模式匹配和规则检查严重依赖人工,对未定义的漏洞模式缺乏识别能力. 利用基于学习的方法,能够有效避免因人工定义导致的漏洞模式不全的问题,该方法成为静态测试的主要手段之一. ...
Efficient vulnerability detection based on an optimized rule checking static analysis technique
2
2017
... 随着市场对软件安全需求的提升,针对软件漏洞的检测成为该领域的研究热点[1 ] . 近年来,国内外学者提出使用静态测试和动态分析的方法对源代码漏洞进行检测与分析. 动态分析在面对大型复杂软件系统的漏洞时,存在检测率较低的问题. 与动态分析相比,静态测试能够在不实际运行程序的情况下发现源代码中的安全漏洞,解决了动态分析无法完全覆盖所有代码的问题,得到了研究者的高度重视. 静态测试主要包括模式匹配[2 ] 、规则检查[3 ] 和基于学习的方法[4 ] . 模式匹配和规则检查严重依赖人工,对未定义的漏洞模式缺乏识别能力. 利用基于学习的方法,能够有效避免因人工定义导致的漏洞模式不全的问题,该方法成为静态测试的主要手段之一. ...
... Comparison of “operation instructions” and source code
Tab.1 类型 LLVM-IR 数量 源代码(举例) 算数指令 add,sub… 12 +, −, *, /, % 位指令 shl,lshr… 6 <<, >>, &, |, ^ 转换指令 trunc,zext… 9 char b = 97 内存指令 load,store… 3 free *ptr 比较指令 icmp,fcmp… 2 >, <, == 分支指令 call,ret,br… 3 goto label 异常处理 landingpad… 2 std::exception 向量指令 llvm.vector… 3 vec[3 ] = 5 原子指令 atomicrmw… 3 fetch_add() 聚合指令 insertvalue… 4 struct S {float x } 其他指令 select,phi… 3 condition ? a : b
“操作指令”具有确定数量的特征项,通过指令名称可以精确地描述程序的运行逻辑,例如load、store和alloca清晰地描述了内存的读取、存储和分配. 这8种指令级特征是通过统计所有项目中的LLVM-IR指令并对其分类后得到,它们与程序运行逻辑密切相关,能够覆盖的漏洞范围超过了4种漏洞语法规则[6 ] . ...
1
... 如图1 (a)所示,本文通过底层虚拟机(low-level virtual machine, LLVM)编译器前端Clang[19 ] ,生成中间代码LLVM-IR[20 ] 和AST,利用Pass[21 ] 提取依赖信息以生成PDG. ...
1
... 为了解决底层信息提取不足的问题,从Mirsky等[22 ] 提供的C/C++项目中,提取8种指令级特征:节点编号、内置函数、静态赋值、操作指令、条件分支、变量、变量类型、原函数. 以8种指令级特征之一的“操作指令”为例,与源代码信息进行对比,如表1 所示. ...
基于学习的源代码漏洞检测研究与进展
1
2024
... 随着市场对软件安全需求的提升,针对软件漏洞的检测成为该领域的研究热点[1 ] . 近年来,国内外学者提出使用静态测试和动态分析的方法对源代码漏洞进行检测与分析. 动态分析在面对大型复杂软件系统的漏洞时,存在检测率较低的问题. 与动态分析相比,静态测试能够在不实际运行程序的情况下发现源代码中的安全漏洞,解决了动态分析无法完全覆盖所有代码的问题,得到了研究者的高度重视. 静态测试主要包括模式匹配[2 ] 、规则检查[3 ] 和基于学习的方法[4 ] . 模式匹配和规则检查严重依赖人工,对未定义的漏洞模式缺乏识别能力. 利用基于学习的方法,能够有效避免因人工定义导致的漏洞模式不全的问题,该方法成为静态测试的主要手段之一. ...
基于学习的源代码漏洞检测研究与进展
1
2024
... 随着市场对软件安全需求的提升,针对软件漏洞的检测成为该领域的研究热点[1 ] . 近年来,国内外学者提出使用静态测试和动态分析的方法对源代码漏洞进行检测与分析. 动态分析在面对大型复杂软件系统的漏洞时,存在检测率较低的问题. 与动态分析相比,静态测试能够在不实际运行程序的情况下发现源代码中的安全漏洞,解决了动态分析无法完全覆盖所有代码的问题,得到了研究者的高度重视. 静态测试主要包括模式匹配[2 ] 、规则检查[3 ] 和基于学习的方法[4 ] . 模式匹配和规则检查严重依赖人工,对未定义的漏洞模式缺乏识别能力. 利用基于学习的方法,能够有效避免因人工定义导致的漏洞模式不全的问题,该方法成为静态测试的主要手段之一. ...
1
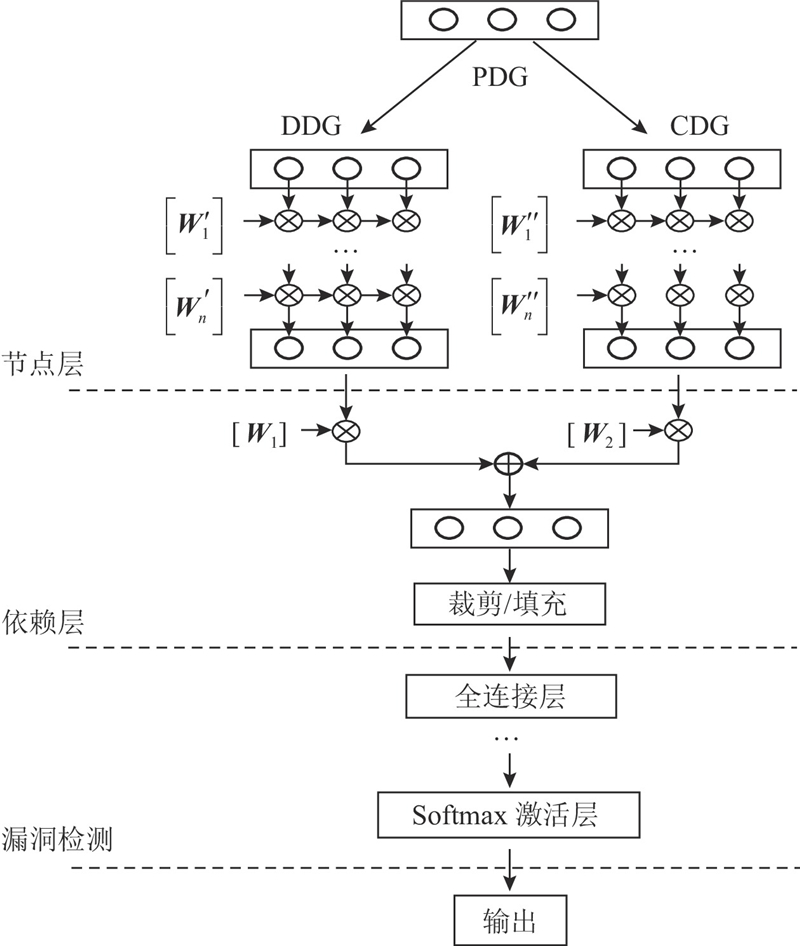
... 式中:$ \tau $ $j$ ${{{N}}_{\text{G}}}$ $ \tau = 2 $ ${e_{ij}}$ $j$ ${e_{ij}}$ [23 ] ,利用干预学习中的权重调整操作,对重要节点的注意力系数进行倍数扩大来提高重要节点的聚合权重. 式(6)的归一化计算保证了系数调整的合理性: ...
Deep learning based vulnerability detection: are we there yet?
1
2020
... 实验采用2个合成数据集和2个真实数据集. 合成数据集包括自建数据集和SySeVR数据集,真实数据集包括Devign和REVEAL[24 ] . ...
2
... Li等[5 ] 利用双向长短时记忆网络检测漏洞,但其严重依赖上下文,捕获长距离依赖关系的能力有限. 为了提取更丰富的语法和语义信息,SySeVR扩充了4种漏洞语法规则[6 ] . 上述方法只在源代码层面提取漏洞特征,缺乏对底层逻辑的有效提取. Li等[7 ] 从中间代码表示(IR)中提取特征,构建样本切片和代码语句之间的关联,实现了细粒度检测. 将IR视为纯文本会影响模型对程序底层逻辑的学习,且过短的切片不利于漏洞信息的远距离传播. Wu等[8 -9 ] 分别采用卷积神经网络和图神经网络(graph neural network, GNN)提取特征,取得了更高的准确率,但传统GNN对异质图的泛化能力不足. Wang等[10 -11 ] 采用改进的GNN,通过拼接方式融合异构依赖关系. 拼接会使得依赖层异质性缺失,降低漏洞模式的自适应能力. ...
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
SySeVR: a framework for using deep learning to detect software vulnerabilities
2
2022
... Li等[5 ] 利用双向长短时记忆网络检测漏洞,但其严重依赖上下文,捕获长距离依赖关系的能力有限. 为了提取更丰富的语法和语义信息,SySeVR扩充了4种漏洞语法规则[6 ] . 上述方法只在源代码层面提取漏洞特征,缺乏对底层逻辑的有效提取. Li等[7 ] 从中间代码表示(IR)中提取特征,构建样本切片和代码语句之间的关联,实现了细粒度检测. 将IR视为纯文本会影响模型对程序底层逻辑的学习,且过短的切片不利于漏洞信息的远距离传播. Wu等[8 -9 ] 分别采用卷积神经网络和图神经网络(graph neural network, GNN)提取特征,取得了更高的准确率,但传统GNN对异质图的泛化能力不足. Wang等[10 -11 ] 采用改进的GNN,通过拼接方式融合异构依赖关系. 拼接会使得依赖层异质性缺失,降低漏洞模式的自适应能力. ...
... “操作指令”具有确定数量的特征项,通过指令名称可以精确地描述程序的运行逻辑,例如load、store和alloca清晰地描述了内存的读取、存储和分配. 这8种指令级特征是通过统计所有项目中的LLVM-IR指令并对其分类后得到,它们与程序运行逻辑密切相关,能够覆盖的漏洞范围超过了4种漏洞语法规则[6 ] . ...
VulDeeLocator: a deep learning-based fine-grained vulnerability detector
1
2022
... Li等[5 ] 利用双向长短时记忆网络检测漏洞,但其严重依赖上下文,捕获长距离依赖关系的能力有限. 为了提取更丰富的语法和语义信息,SySeVR扩充了4种漏洞语法规则[6 ] . 上述方法只在源代码层面提取漏洞特征,缺乏对底层逻辑的有效提取. Li等[7 ] 从中间代码表示(IR)中提取特征,构建样本切片和代码语句之间的关联,实现了细粒度检测. 将IR视为纯文本会影响模型对程序底层逻辑的学习,且过短的切片不利于漏洞信息的远距离传播. Wu等[8 -9 ] 分别采用卷积神经网络和图神经网络(graph neural network, GNN)提取特征,取得了更高的准确率,但传统GNN对异质图的泛化能力不足. Wang等[10 -11 ] 采用改进的GNN,通过拼接方式融合异构依赖关系. 拼接会使得依赖层异质性缺失,降低漏洞模式的自适应能力. ...
1
... Li等[5 ] 利用双向长短时记忆网络检测漏洞,但其严重依赖上下文,捕获长距离依赖关系的能力有限. 为了提取更丰富的语法和语义信息,SySeVR扩充了4种漏洞语法规则[6 ] . 上述方法只在源代码层面提取漏洞特征,缺乏对底层逻辑的有效提取. Li等[7 ] 从中间代码表示(IR)中提取特征,构建样本切片和代码语句之间的关联,实现了细粒度检测. 将IR视为纯文本会影响模型对程序底层逻辑的学习,且过短的切片不利于漏洞信息的远距离传播. Wu等[8 -9 ] 分别采用卷积神经网络和图神经网络(graph neural network, GNN)提取特征,取得了更高的准确率,但传统GNN对异质图的泛化能力不足. Wang等[10 -11 ] 采用改进的GNN,通过拼接方式融合异构依赖关系. 拼接会使得依赖层异质性缺失,降低漏洞模式的自适应能力. ...
Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks
1
2019
... Li等[5 ] 利用双向长短时记忆网络检测漏洞,但其严重依赖上下文,捕获长距离依赖关系的能力有限. 为了提取更丰富的语法和语义信息,SySeVR扩充了4种漏洞语法规则[6 ] . 上述方法只在源代码层面提取漏洞特征,缺乏对底层逻辑的有效提取. Li等[7 ] 从中间代码表示(IR)中提取特征,构建样本切片和代码语句之间的关联,实现了细粒度检测. 将IR视为纯文本会影响模型对程序底层逻辑的学习,且过短的切片不利于漏洞信息的远距离传播. Wu等[8 -9 ] 分别采用卷积神经网络和图神经网络(graph neural network, GNN)提取特征,取得了更高的准确率,但传统GNN对异质图的泛化能力不足. Wang等[10 -11 ] 采用改进的GNN,通过拼接方式融合异构依赖关系. 拼接会使得依赖层异质性缺失,降低漏洞模式的自适应能力. ...
Combining graph-based learning with automated data collection for code vulnerability detection
2
2021
... Li等[5 ] 利用双向长短时记忆网络检测漏洞,但其严重依赖上下文,捕获长距离依赖关系的能力有限. 为了提取更丰富的语法和语义信息,SySeVR扩充了4种漏洞语法规则[6 ] . 上述方法只在源代码层面提取漏洞特征,缺乏对底层逻辑的有效提取. Li等[7 ] 从中间代码表示(IR)中提取特征,构建样本切片和代码语句之间的关联,实现了细粒度检测. 将IR视为纯文本会影响模型对程序底层逻辑的学习,且过短的切片不利于漏洞信息的远距离传播. Wu等[8 -9 ] 分别采用卷积神经网络和图神经网络(graph neural network, GNN)提取特征,取得了更高的准确率,但传统GNN对异质图的泛化能力不足. Wang等[10 -11 ] 采用改进的GNN,通过拼接方式融合异构依赖关系. 拼接会使得依赖层异质性缺失,降低漏洞模式的自适应能力. ...
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
VDoTR: vulnerability detection based on tensor representation of comprehensive code graphs
2
2023
... Li等[5 ] 利用双向长短时记忆网络检测漏洞,但其严重依赖上下文,捕获长距离依赖关系的能力有限. 为了提取更丰富的语法和语义信息,SySeVR扩充了4种漏洞语法规则[6 ] . 上述方法只在源代码层面提取漏洞特征,缺乏对底层逻辑的有效提取. Li等[7 ] 从中间代码表示(IR)中提取特征,构建样本切片和代码语句之间的关联,实现了细粒度检测. 将IR视为纯文本会影响模型对程序底层逻辑的学习,且过短的切片不利于漏洞信息的远距离传播. Wu等[8 -9 ] 分别采用卷积神经网络和图神经网络(graph neural network, GNN)提取特征,取得了更高的准确率,但传统GNN对异质图的泛化能力不足. Wang等[10 -11 ] 采用改进的GNN,通过拼接方式融合异构依赖关系. 拼接会使得依赖层异质性缺失,降低漏洞模式的自适应能力. ...
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
1
... 基于规则的检测方法通过预定义的漏洞规则,对源代码文件进行遍历和匹配,找到潜在的漏洞威胁,但此类方法对漏洞规则具有很强的依赖性. 检测工具PMD[12 ] 涵盖了编码规范、设计原则和安全漏洞等规则,以应对复杂的代码场景. 工具SonarQube[13 ] 在可靠性、适用性方面进行了提升,不仅提供了多维度的代码质量评估,而且支持多种编程语言的检测任务. 基于学习的检测方法分为基于机器学习和基于深度学习的检测方法. Perl等[14 ] 将GitHub提交记录映射到已知漏洞,使用支持向量机来标记可能存在漏洞的样本,但该方法在实际检测中存在较高的假阳性率. 相比之下,基于深度学习的方法更有利于深层次特征的提取. ...
1
... 基于规则的检测方法通过预定义的漏洞规则,对源代码文件进行遍历和匹配,找到潜在的漏洞威胁,但此类方法对漏洞规则具有很强的依赖性. 检测工具PMD[12 ] 涵盖了编码规范、设计原则和安全漏洞等规则,以应对复杂的代码场景. 工具SonarQube[13 ] 在可靠性、适用性方面进行了提升,不仅提供了多维度的代码质量评估,而且支持多种编程语言的检测任务. 基于学习的检测方法分为基于机器学习和基于深度学习的检测方法. Perl等[14 ] 将GitHub提交记录映射到已知漏洞,使用支持向量机来标记可能存在漏洞的样本,但该方法在实际检测中存在较高的假阳性率. 相比之下,基于深度学习的方法更有利于深层次特征的提取. ...
1
... 基于规则的检测方法通过预定义的漏洞规则,对源代码文件进行遍历和匹配,找到潜在的漏洞威胁,但此类方法对漏洞规则具有很强的依赖性. 检测工具PMD[12 ] 涵盖了编码规范、设计原则和安全漏洞等规则,以应对复杂的代码场景. 工具SonarQube[13 ] 在可靠性、适用性方面进行了提升,不仅提供了多维度的代码质量评估,而且支持多种编程语言的检测任务. 基于学习的检测方法分为基于机器学习和基于深度学习的检测方法. Perl等[14 ] 将GitHub提交记录映射到已知漏洞,使用支持向量机来标记可能存在漏洞的样本,但该方法在实际检测中存在较高的假阳性率. 相比之下,基于深度学习的方法更有利于深层次特征的提取. ...
μVulDeePecker: a deep learning-based system for multiclass vulnerability detection
1
2019
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
1
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
基于上下文特征融合的代码漏洞检测方法
1
2022
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
基于上下文特征融合的代码漏洞检测方法
1
2022
... 基于深度学习的检测方法通常采用Token或图形的方式对源代码进行表征. μ VulDeePecker[15 ] 在VulDeePecker[5 ] 的基础上引入代码小工具来细化漏洞特征提取,获得了多类型漏洞检测能力. 相比于Token,图表征对代码结构的表达更加清晰和显式化. Feng等[16 ] 验证了多种GNN模型,获得了优于Token表征的检测结果,但GNN难以充分提取图表征中的异构信息. 徐泽鑫等[17 ] 通过解耦、融合的方式获得了高质量特征,并利用距离损失放大漏洞样本的差异性降低了误报率. 程靖云等[18 ] 以不相交图的形式拼接子图,采用多头图注意力网络(multi-head graph attention network, MHGAT)跨图层传递信息,有效提取了图数据异构特征. 以上方法虽然考虑了图数据异构性,但存在特征分布稀疏问题. Wang等[10 ] 利用门控图神经网络(gated graph neural network, GGNN),在表示特定依赖的子图之间提取异构特征,Fan等[11 ] 采用圆形GGNN融合张量中的异构信息. 虽然这2种方法对图数据异构特征的考虑更深入,但缺乏对异构元素的独立提取和重要性评估,导致隐秘的漏洞节点和边在聚合过程中被忽视. 本文针对异构特征提取不充分的问题,提出基于异构图的源代码漏洞检测方法. ...
mVulSniffer: 一种多类型源代码漏洞检测方法
1
2023
... 从表3 可以看出,VulHetG在2类漏洞上的Acc达到94%和96%,高于双通道模型mVulSniffer[25 ] . 这可能是因为在中间代码中,变量在每次参与运算时都会附带完整的变量信息,且会用地址指针代替变量作为传参,在多数情况下,模型只需要跨越很短的距离就可以提取依赖关系. ...
mVulSniffer: 一种多类型源代码漏洞检测方法
1
2023
... 从表3 可以看出,VulHetG在2类漏洞上的Acc达到94%和96%,高于双通道模型mVulSniffer[25 ] . 这可能是因为在中间代码中,变量在每次参与运算时都会附带完整的变量信息,且会用地址指针代替变量作为传参,在多数情况下,模型只需要跨越很短的距离就可以提取依赖关系. ...
A review of machine learning-based zero-day attack detection: challenges and future directions
1
2023
... 除现有实验之外,本文在低层次漏洞上进行验证并取得了较好的检测效果,表明VulHetG具备提取细微特征进而发掘0day漏洞的潜力. VulHetG与传统的检测模型一样,都缺少0day漏洞标签、通用的数据集和通用的比较方案[26 -27 ] ,使得模型对0day漏洞的检测效果尚无定论. 另外,VulHetG用于提取特征的数据模态较单一,缺乏对文档、日志、源代码等多模态数据特征的学习,对真实场景的漏洞泛化能力有待提升. ...
1
... 除现有实验之外,本文在低层次漏洞上进行验证并取得了较好的检测效果,表明VulHetG具备提取细微特征进而发掘0day漏洞的潜力. VulHetG与传统的检测模型一样,都缺少0day漏洞标签、通用的数据集和通用的比较方案[26 -27 ] ,使得模型对0day漏洞的检测效果尚无定论. 另外,VulHetG用于提取特征的数据模态较单一,缺乏对文档、日志、源代码等多模态数据特征的学习,对真实场景的漏洞泛化能力有待提升. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}