

为了实现对施工现场全视角智能监控,Liu等[4]提出基于线激光旋转扫描的三维重建算法,进一步恢复三维可见表面的几何形状. Yu等[5]提出基于分割激光热应力切割(thermal laser separation,TLS)数据自动重建语义增强三维建筑模型的方法,实现自动化三维重建. 有学者利用相机测量技术,通过获取物体在空间中的三维视觉信息进行物体形状重构. Abdulwahab等[6]提出基于单目视觉的自编码器网络的深度图估计技术,提高了三维信息测量的准确率. Jin等[7]提出单目动态三维目标重建框架,实现基于单目视觉的动态三维重建. 激光扫描技术存在成本投入高、局部重建细节丢失的问题,单目摄影技术存在重建精度不够高的问题. 为了实现高精度的三维重建,Zhang等[8]建立基于双目视觉的形状重建和测量系统,对图像进行畸变矫正和边缘去噪处理. Gai[9]将极坐标约束和蚁群算法相结合,采用蚁群算法优化立体匹配,实现极线约束下的立体匹配搜索函数的最优解. Xiang等[10]提出基于双目立体视觉的聚类番茄识别算法,通过去噪技术提高深度图的精度. 上述研究提高了图像像素点提取匹配的精度和效率,但缺乏近实时性. 为了实现对特征点高精度近实时地动态识别定位,Kang等[11]提出基于YOLOv5的注意力尺度序列融合模型,并结合通道和位置注意力机制(channel and position attention mechanism, CPAM)模块提高模型检测的性能,Duan等[12-13]通过开发大型的施工现场图像数据集,提高了模型泛化性能,减少了目标被错误识别的可能性. 针对目标特征复杂、背景信息复杂、样本标注繁琐等问题,有学者试图通过改进注意力机制、多尺度特征融合、超分辨率等方式提高神经网络模型识别的精度和效率[14-16],但如何对大型现场进行无死角监控仍待进一步研究.
为了实现对施工现场近实时、高精度的全视角管控,本研究提出基于双目视觉和改进YOLOv8的动态三维重建技术. 1)部署双目相机对现场进行三维扫描获取三维模型基底和目标的活动轨迹,2)利用改进的YOLOv8模型对现场动态要素进行近实时识别定位,3)利用获取到的三维深度信息将动态要素行为轨迹三维动态投影至模型基底中.
1. 基于双目视觉的三维重建
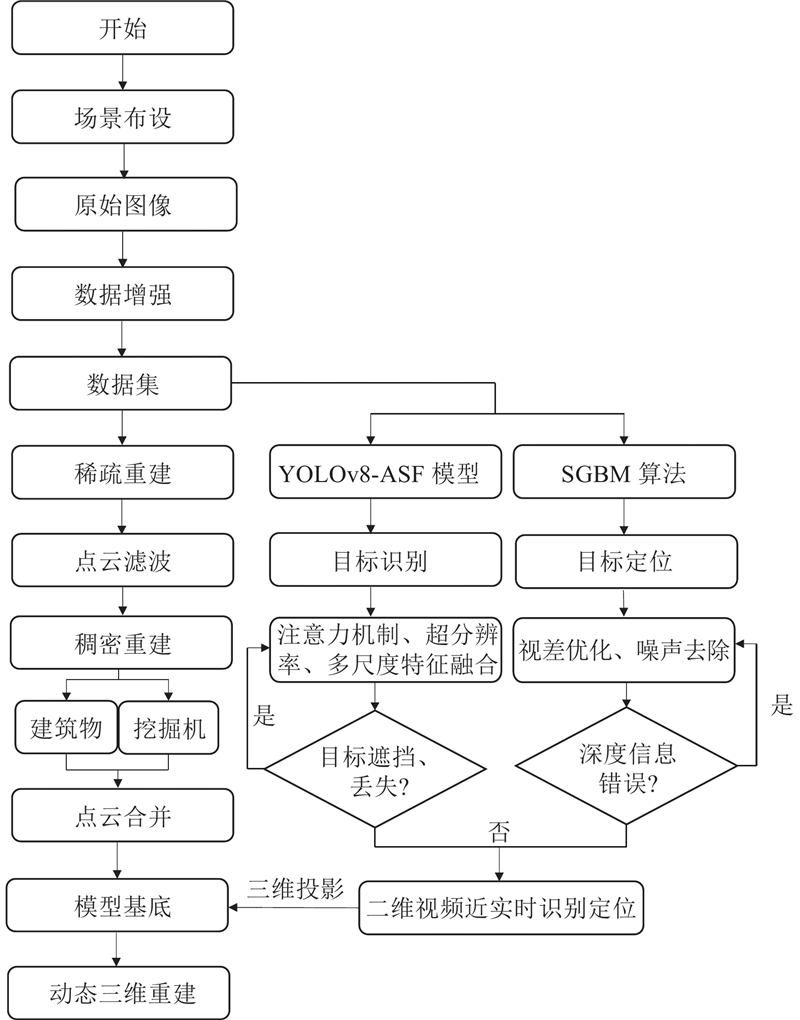
如图1所示为动态三维重建技术框架,双目摄像头用于记录挖掘机的轨迹路线,基于分割的视频源进行图像数据增强,图像数据集导入YOLO-注意力量表序列融合(attentional scale sequence fusion,ASF)模型进行训练. YOLOv8-ASF-改进的半全局立体匹配(semi-global block matching,SGBM)(以下简称YAS)算法中的YOLOv8-ASF模型提高目标检测性能,改进的SGBM算法先在二维图像中划分感兴趣区域,缩小捕捉范围,再对像素特征点进行提取与匹配,实现对目标近实时地识别定位,同时获取像素点的三维坐标与深度信息. 将挖掘机投影至场景基底中,通过轨迹复现实现近实时动态三维重建. 将双目视觉、YOLOv8-ASF和SGBM结合,不仅节约了重建成本,也满足了重建精度,节省了人力物力,该方法具有较好的应用前景和工程价值.
图 1
1.1. 场景布置
利用挖掘机模拟施工现场动态要素,建筑物模拟施工现场静态要素,还原施工现场动静态要素的行为活动. 挖掘机长×宽×高为61 cm×17 cm×41 cm;建筑物长×宽×高为37.5 cm×28.1 cm×50.0 cm,尺寸比例均为1∶16,符合大型施工现场设备规范. 试验模拟4种施工现场建筑物排列场景,如图2所示,各个场景的相邻建筑物端点之间的距离均为50 cm,符合建筑距离规范[17]. 配备500万像素的同帧同步双目摄像机,以1 280×480像素的分辨率拍摄图像,采集速率为20帧/s,具有从5 cm到无穷远的焦距范围. 试验旨在将挖掘机的行为轨迹高精度投影至三维模型基底中,实现对场景的近实时、全视角智能监控.
图 2

图 2 施工现场的动静态要素布设模拟场景
Fig.2 Simulation scenario for layout of dynamic and static elements at construction site
1.2. 三维重构
三维重构是将二维图像恢复为三维结构并进行渲染可视化的方式. 利用张正友标定法[18]进行相机标定,消除图像畸变. 该方法基于相机投影模型,根据已知的三维空间点与其对应的二维图像点之间存在的投影矩阵计算相机的内部参数、外部参数和畸变参数. 利用Matlab的标定工具箱和棋盘格标定板对双目相机进行标定,以此获取相机参数,标定原理如图3所示. 使用双目相机对4种模拟场景进行360°环绕式扫描,每张图片的角度不超过30°以确保图像有重叠部分,避免点云丢失. 生成左右图片各700张,通过旋转、缩放、翻转等有监督式数据增强[19]导出左右图片各800张,将导出的左右图片导入Colmap[20]中,依次进行图像提取、特征点匹配、稠密重建以及深度图输出. 将输出的点云数据导入Cloudcompare[21]中进行泊松重建可视化,生成光滑的立体曲面模型基底,如图4所示.
图 3
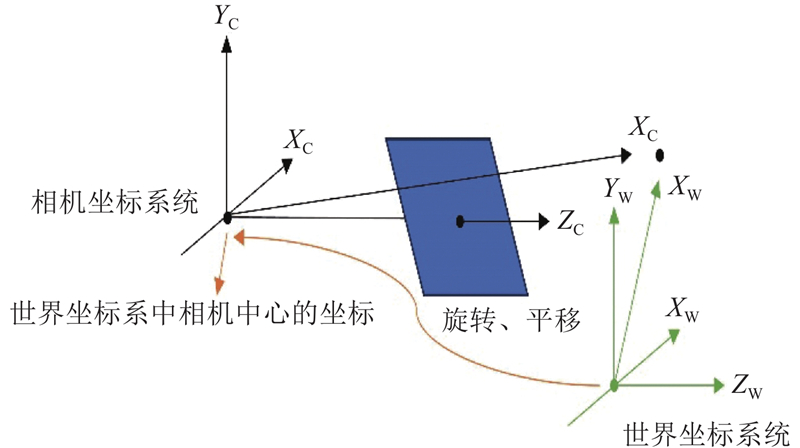
图 4

图 4 施工现场动静态要素布设模拟场景下的重建图
Fig.4 Reconstruction results under simulation scenario for dynamic and static element layout at construction site
1.3. 重建精度分析
为了验证基于双目视觉下的三维重建精度,分别获取建筑物和挖掘机的点云尺寸. 点云没有单位,因此通过计算实际单元尺寸与相对应的点云尺寸的比例误差来确定重建精度,误差计算式为
式中:
表 1 动静态要素真实尺寸与点云尺寸的比例误差
Tab.1
| 元素 | L/cm | W/cm | H/cm | Rr | l | w | h | Rc | PE/% |
| 建筑物 | 37.5 | 28.1 | 50.0 | 1∶0.75∶1.33 | 37.87 | 28.24 | 49.76 | 1∶0.75∶1.31 | 1.5 |
| 挖掘机 | 61 | 17 | 41 | 1∶0.28∶0.67 | 62.79 | 17.54 | 40.95 | 1∶0.28∶0.65 | 3.0 |
2. 基于YOLOv8-注意力量表序列融合的近实时目标检测
2.1. YOLOv8-ASF模型构建
为了实现对各类要素的近实时识别检测,提高特征点提取的效率和精度,引入YOLOv8深度学习模型[22],它不仅能高效满足实时应用,数据增强还可提高模型泛化性,在各种复杂场景下的鲁棒性高. 为了解决识别过程中精度低、目标物遮挡和丢失等痛点,本研究基于YOLOv8引入ASF模块,模型原理如图5所示,其中
图 5
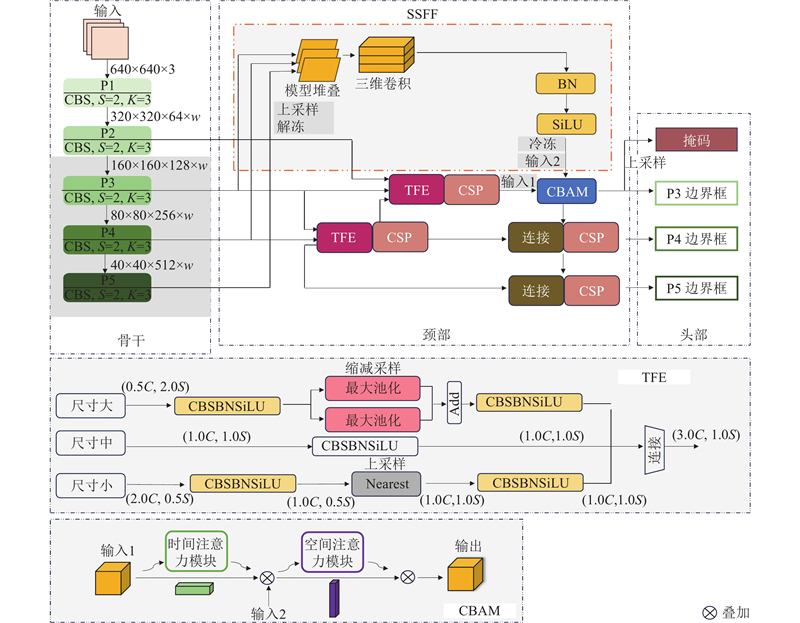
图 5 YOLOv8-注意力量表序列融合模型框架
Fig.5 Framework of YOLOv8-attentional scale sequence fusion model
2.2. 数据预处理
固定双目相机的位置进行场景拍摄,拍摄时长均为35 s,帧率为20 帧/s,分帧得到图片各700张,利用数据增强技术将图片增加至800张,图像以7∶2∶1划分为训练集(560张),验证集(160张)和验证集(80张),标签种类分为挖掘机和建筑物2个类别. 设置迭代轮次为300,样本大小为16[11],交并比为0.8,上述参数均为本模型训练过程中的最优解.
2.3. 模型精度比较
图 6
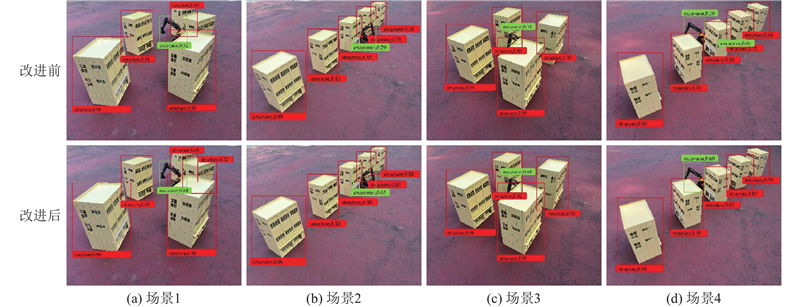
图 6 注意力量表序列融合改进YOLOv8前后的模型目标识别结果可视化
Fig.6 Visualization of model target recognition results before and after attenetional scale sequence fusion to improve YOLOv8
图 7
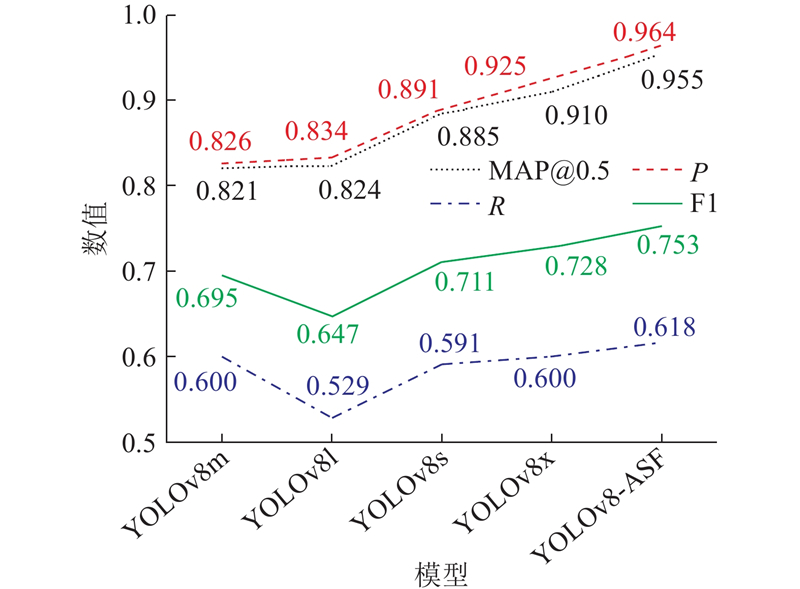
图 7 不同YOLOv8模型的目标检测性能比较
Fig.7 Comparison of object detection performance of different YOLOv8 models
式中:TP为正确的预测正样本,FP为错误的预测正样本,FN为错误的预测负样本.
3. 基于新算法的空间信息感知
3.1. 半全局立体匹配算法
图 8
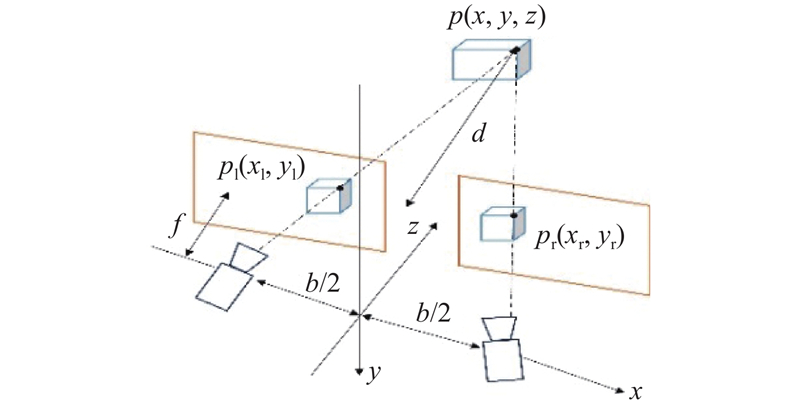
式中:
3.2. 算法改进
基于感兴趣区域(ROI)算法[24]对4种模拟场景进行特征点的自动提取和匹配,场景布局以及建筑物的遮挡程度不同,因此不同模拟场景下提取到的特征点的个数和位置均不同. 在本研究中建筑物与挖掘机均为刚体,在移动过程中形状和大小保持不变,根据刚体不变性原理,它们的形态和位置通过测量指定特征点之间的相对距离确定. 为了获取任一像素点的三维坐标和深度信息,基于SGBM算法引入“鼠标事件(onclick)”模块[25],即在鼠标完成点击的过程中瞬间触发定位函数对自动提取和匹配到的特征点进行捕捉. 利用改进之后的SGBM算法同时获取特征点的三维坐标和深度信息,为了实现对挖掘机行驶轨迹的识别与定位,将数据集种类仅突出为挖掘机,再基于YAS算法,获取挖掘机每一帧的实况位置,如图9所示的三维坐标均为预测框的中心位置,其余特征点的深度信息均由文本导出. 获取挖掘机和建筑物特征点之间的像素距离,计算式为
图 9

图 9 模拟场景下改进模型对挖掘机的识别定位
Fig.9 Detection and localization of excavator by improved model in simulation scenarios
式中:
3.3. 算法精度比较
为了验证YAS算法的精度,对于每个模拟场景,基于已自动匹配到的特征点,分别选取挖掘机上的1个特征点和建筑物上的15个特征点,利用获取到的深度信息计算特征点之间的像素距离,计算特征点像素距离与真实距离的相对距离误差:
式中:
图 10
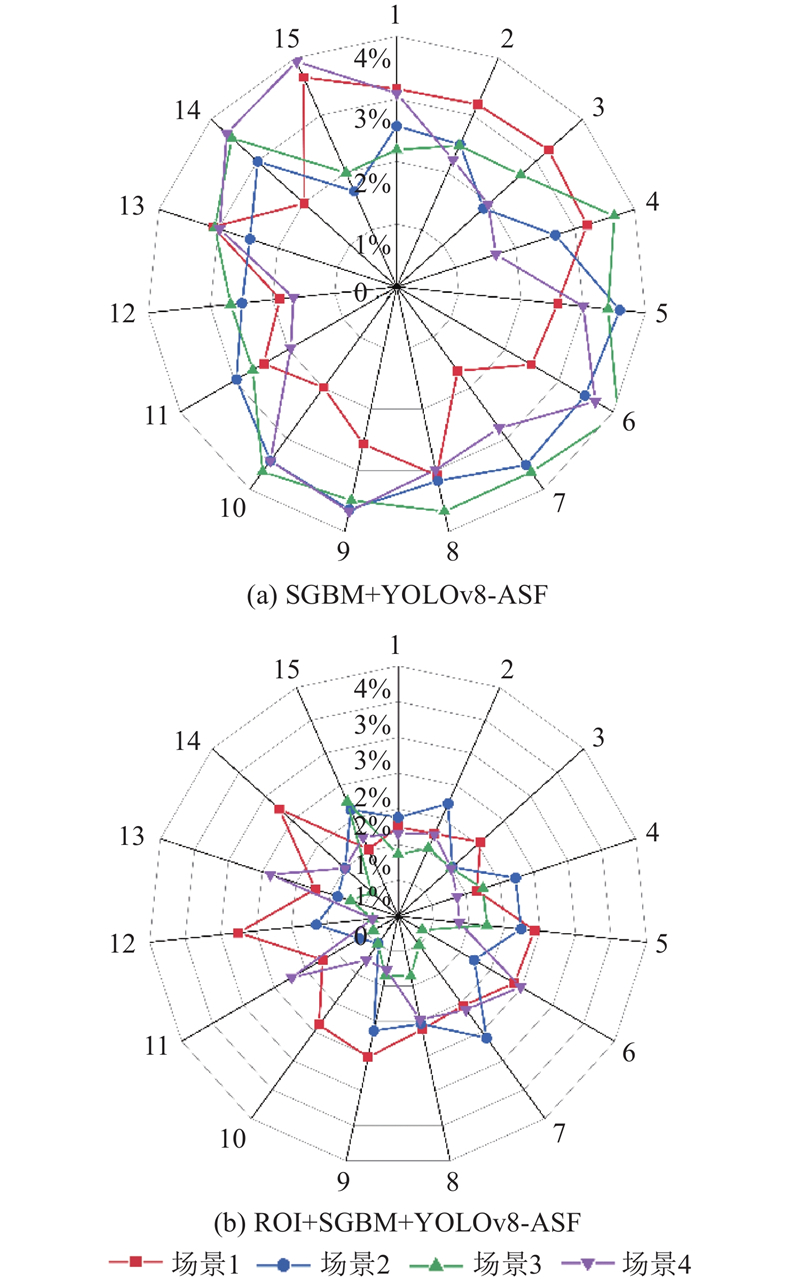
图 10 不同算法在4种模拟场景下的特征点匹配精度
Fig.10 Feature point matching accuracy of different algorithms in four simulation scenarios
4. 动态三维重建
为了实现对模拟场景中挖掘机的全视角近实时智能监控,在三维场景中还原挖掘机的行驶轨迹,对每个模拟场景进行拍摄分帧,在4段模拟场景视频中各选取1帧,确保挖掘机在不同的模拟场景下处于不同的遮挡位置,利用获取的特征点深度信息进行三维投影,如图11所示. 为了验证场景基于视频图像投影至三维平台的精度,在不同模拟场景下选取的帧与每帧中的特征点均与3.2节相同,再获取三维场景中相同特征点的点云距离,由于点云没有单位,利用挖掘机上的特征点分别到建筑物特征点的距离比例进行精度分析,
图 11

图 11 模拟场景下挖掘机行为轨迹的动态重建
Fig.11 Dynamic reconstruction of excavator behavior trajectory in simulation scenario
式中:
图 12
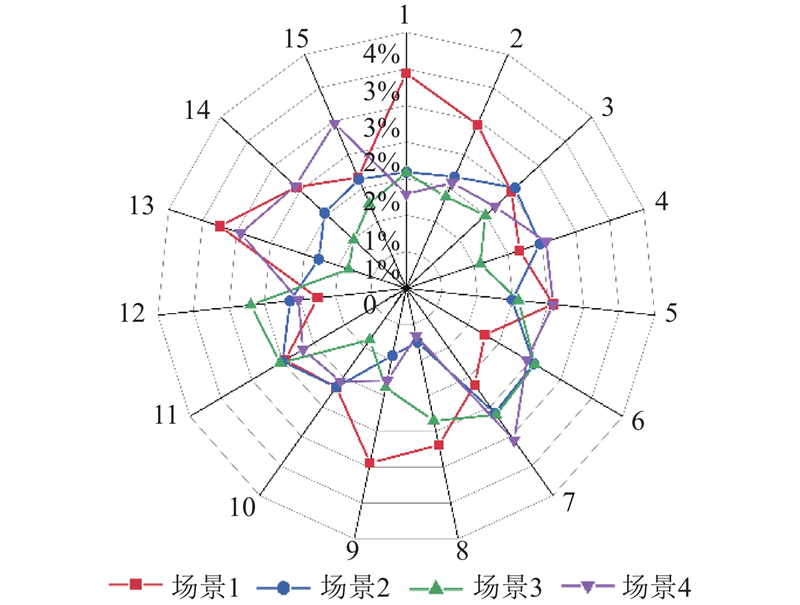
图 12 模拟场景下挖掘机行为轨迹的动态重建精度
Fig.12 Accuracy of dynamic reconstruction of excavator behavior trajectory in simulation scenario
5. 结 语
1)利用双目相机对现场进行三维重构,相比如激光扫描仪、无人机的重构设备,在保证精度的同时降低了投入成本. 2)利用YOLOv8-ASF模型对数据集进行训练,相比YOLOv8经典模型,解决了在不同遮挡情况下目标遮挡丢失的问题,提高了目标识别置信度,增加了模型泛化性. 3)将改进后的SGBM算法与YOLOv8n-ASF模型融合,解决了特征点提取延迟、丢失和错误等痛点,实现了基于图像视频的高精度近实时识别定位. 4)将二维图像视频信息投影至三维数字化场景中,解决了视线盲区、环境干扰和资源耗费等问题,在三维模型中实现了对施工现场的智能化管控,对于未来建筑类项目具有较大的工程价值. 本研究利用模拟场景来证明系统的实用性,未来若运用至实际大型施工现场,须扩大数据集(如不同种类的机械设备、要素行为轨迹和施工规模等)以适应多样工种、环境和工况的安全需求;系统须优化以运用于真实施工场景. 未来研究方向:1)大型施工现场的技术实施;2)引入其他动态元素(如工程人员和不同类型的机械设备)增强技术的多功能性;3)将所提技术与安全预警系统相集成,实现对建筑工地的全面、近实时的安全监控.
参考文献
Sustainability performance in on-site construction processes: a systematic literature review
[J].DOI:10.3390/su16031047 [本文引用: 1]
Relationships between lean and sustainable construction: positive impacts of lean practices over sustainability during construction phase
[J].DOI:10.1016/j.jclepro.2019.05.216 [本文引用: 1]
Semantically enhanced 3D building model reconstruction from terrestrial laser-scanning data
[J].DOI:10.1061/(ASCE)SU.1943-5428.0000232 [本文引用: 1]
Monocular depth map estimation based on a multi-scale deep architecture and curvilinear saliency feature boosting
[J].DOI:10.1007/s00521-022-07663-x [本文引用: 1]
A shape reconstruction and measurement method for spherical hedges using binocular vision
[J].DOI:10.3389/fpls.2022.849821 [本文引用: 1]
Optimization of stereo matching in 3D reconstruction based on binocular vision
[J].
Recognition of clustered tomatoes based on binocular stereo vision
[J].DOI:10.1016/j.compag.2014.05.006 [本文引用: 1]
ASF-YOLO: a novel YOLO model with attentional scale sequence fusion for cell instance segmentation
[J].DOI:10.1016/j.imavis.2024.105057 [本文引用: 2]
SODA: a large-scale open site object detection dataset for deep learning in construction
[J].DOI:10.1016/j.autcon.2022.104499 [本文引用: 1]
Dataset and benchmark for detecting moving objects in construction sites
[J].DOI:10.1016/j.autcon.2020.103482 [本文引用: 1]
A generative statistical approach to automatic 3D building roof reconstruction from laser scanning data
[J].DOI:10.1016/j.isprsjprs.2013.02.004 [本文引用: 1]
A survey of SAR image target detection based on convolutional neural networks
[J].
Literature review on ship localization, classification, and detection methods based on optical sensors and neural networks
[J].DOI:10.3390/s22186879 [本文引用: 1]
建筑防火技术在民用建筑设计中的应用研究
[J].
Research on the application of building fire protection technology in civil building design
[J].
基于棋盘标定板的优化相机参数标定方法
[J].DOI:10.3969/j.issn.1673-629X.2023.12.014 [本文引用: 1]
Optimized camera parameter calibration method based on checkerboard
[J].DOI:10.3969/j.issn.1673-629X.2023.12.014 [本文引用: 1]
基于图像的数据增强方法发展现状综述
[J].
A survey on the development of image data augmentation
[J].
Application of drone for landslide mapping, dimension estimation and its 3D reconstruction
[J].DOI:10.1007/s12524-017-0727-1 [本文引用: 1]
YOLO-drone: an optimized YOLOv8 network for tiny UAV object detection
[J].
基于双目立体视觉的乘员运动姿态测量方法研究
[J].DOI:10.3969/j.issn.2095-509X.2024.01.026 [本文引用: 1]
Research on test method of occupant motion attitude measurement based on binocular stereo vision
[J].DOI:10.3969/j.issn.2095-509X.2024.01.026 [本文引用: 1]
A review of deep learning-based three-dimensional medical image registration methods
[J].DOI:10.21037/qims-21-175 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}