[1]
范金河. 基于深度学习的超分辨率CT图像重建算法研究[D]. 绵阳: 西南科技大学, 2023: 1–66.
[本文引用: 1]
FAN Jinhe. Research on super-resolution CT image reconstruction algorithm based on deep learning [D]. Mianyang: Southwest University of Science and Technology, 2023: 1–66.
[本文引用: 1]
[2]
赵小强, 王泽, 宋昭漾, 等 基于动态注意力网络的图像超分辨率重建
[J]. 浙江大学学报: 工学版 , 2023 , 57 (8 ): 1487 - 1494
[本文引用: 1]
ZHAO Xiaoqiang, WANG Ze, SONG Zhaoyang, et al Image super-resolution reconstruction based on dynamic attention network
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (8 ): 1487 - 1494
[本文引用: 1]
[3]
郑跃坤, 葛明锋, 常智敏, 等 基于残差网络的结直肠内窥镜图像超分辨率重建方法
[J]. 中国光学(中英文) , 2023 , 16 (5 ): 1022 - 1033
DOI:10.37188/CO.2022-0247
[本文引用: 1]
ZHENG Yuekun, GE Mingfeng, CHANG Zhimin, et al Super-resolution reconstruction for colorectal endoscopic images based on a residual network
[J]. Chinese Optics , 2023 , 16 (5 ): 1022 - 1033
DOI:10.37188/CO.2022-0247
[本文引用: 1]
[4]
李嫣, 任文琦, 张长青, 等 基于真实退化估计与高频引导的内窥镜图像超分辨率重建
[J]. 自动化学报 , 2024 , 50 (2 ): 334 - 347
[本文引用: 1]
LI Yan, REN Wenqi, ZHANG Changqing, et al Super-resolution of endoscopic images based on real degradation estimation and high-frequency guidance
[J]. Acta Automatica Sinica , 2024 , 50 (2 ): 334 - 347
[本文引用: 1]
[5]
宋全博, 李扬科, 范业莹, 等 先验GAN的CBCT牙齿图像超分辨率方法
[J]. 计算机辅助设计与图形学学报 , 2023 , 35 (11 ): 1751 - 1759
[本文引用: 1]
SONG Quanbo, LI Yangke, FAN Yeying, et al CBCT tooth images super-resolution method based on GAN prior
[J]. Journal of Computer-Aided Design and Computer Graphics , 2023 , 35 (11 ): 1751 - 1759
[本文引用: 1]
[6]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Conference on Neural Information Processing Systems . Long Beach: MIT Press, 2017: 6000–6010.
[本文引用: 1]
[7]
LIANG J, CAO J, SUN G, et al. SwinIR: image restoration using swin transformer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops . Montreal: IEEE, 2021: 1833–1844.
[本文引用: 1]
[8]
吕鑫栋, 李娇, 邓真楠, 等 基于改进Transformer的结构化图像超分辨网络
[J]. 浙江大学学报: 工学版 , 2023 , 57 (5 ): 865 - 874
[本文引用: 1]
LV Xindong, LI Jiao, DENG Zhennan, et al Structured image super-resolution network based on improved Transformer
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (5 ): 865 - 874
[本文引用: 1]
[9]
YU P, ZHANG H, KANG H, et al. RPLHR-CT dataset and transformer baseline for volumetric super-resolution from CT scans [C]// Medical Image Computing and Computer Assisted Intervention . [S. l.]: Springer, 2022: 344–353.
[本文引用: 2]
[10]
赵凯光. 基于深度学习的肺部CT图像超分辨率重建[D]. 长春: 长春理工大学, 2022: 1–55.
[本文引用: 2]
ZHAO Kaiguang. Deep learning based on super-resolution reconstruction of lung CT images [D]. Changchun: Changchun University of Science and Technology, 2022: 1–55.
[本文引用: 2]
[11]
刘伟. 基于深度学习的三维头部MRI超分辨率重建[D]. 桂林: 桂林电子科技大学, 2022: 1–54.
[本文引用: 1]
LIU Wei. 3D Head MRI super-resolution reconstruction based on deep learning [D]. Guilin: Guilin University of Electronic Technology, 2023: 1–54.
[本文引用: 1]
[12]
李光远. 基于深度学习的磁共振成像超分辨率重建[D]. 烟台: 烟台大学, 2023: 1–77.
[本文引用: 2]
LI Guangyuan. Deep learning-based magnetic resonance imaging super-resolution reconstruction [D]. Yantai: Yantai University, 2023: 1–77.
[本文引用: 2]
[13]
李众, 王雅婧, 马巧梅 基于空洞卷积的医学图像超分辨率重建算法
[J]. 计算机应用 , 2023 , 43 (9 ): 2940 - 2947
[本文引用: 1]
LI Zhong, WANG Yajing, MA Qiaomei Super-resolution reconstruction algorithm of medical images based on dilated convolution
[J]. Journal of Computer Applications , 2023 , 43 (9 ): 2940 - 2947
[本文引用: 1]
[14]
YANG X, HE X, ZHAO J, et al. COVID-CT-dataset: a CT scan dataset about COVID-19 [EB/OL]. (2020−06−17)[2024−07−18]. https://arxiv.org/pdf/2003.13865.
[本文引用: 1]
[15]
SOARES E, ANGELOV P, BIASO S, et al. SARS-CoV-2 CT-scan dataset: a large dataset of real patients CT scans for SARS-CoV-2 identification [EB/OL]. (2020−05−14)[2024−07−18]. https://www.medrxiv.org/content/10.1101/2020.04.24.20078584v3.full.pdf.
[本文引用: 1]
[16]
WANG C, LV X, SHAO M, et al A novel fuzzy hierarchical fusion attention convolution neural network for medical image super-resolution reconstruction
[J]. Information Sciences , 2023 , 622 : 424 - 436
DOI:10.1016/j.ins.2022.11.140
[本文引用: 1]
[17]
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity
[J]. IEEE Transactions on Image Processing , 2004 , 13 (4 ): 600 - 612
DOI:10.1109/TIP.2003.819861
[本文引用: 1]
[18]
WANG P, CHEN P, YUAN Y, et al. Understanding convolution for semantic segmentation [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision . Lake Tahoe: IEEE, 2018: 1451–1460.
[本文引用: 2]
[19]
SONG Z, ZHAO X, HUI Y, et al Progressive back-projection network for COVID-CT super-resolution
[J]. Computer Methods and Programs in Biomedicine , 2021 , 208 : 106193
DOI:10.1016/j.cmpb.2021.106193
[本文引用: 1]
[20]
ZAMIR S W, ARORA A, KHAN S, et al. Restormer: efficient transformer for high-resolution image restoration [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 5718–5729.
[本文引用: 1]
[21]
FANG J, LIN H, CHEN X, et al. A hybrid network of CNN and transformer for lightweight image super-resolution [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . New Orleans: IEEE, 2022: 1102–1111.
[本文引用: 1]
[22]
CHEN Z, YANG L, LAI J H, et al. CuNeRF: cube-based neural radiance field for zero-shot medical image arbitrary-scale super resolution [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 21128–21138.
[本文引用: 1]
[23]
ZHENG Q, ZHENG L, GUO Y, et al. Self-adaptive reality-guided diffusion for artifact-free super-resolution [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 25806–25816.
[本文引用: 1]
1
... 肺部CT图像的高精度成像设备成本高昂,无法大规模推广[1 ] . 图像超分辨率重建(super-resolution reconstruction,SR)技术被逐渐应用于医疗领域,它是指通过计算机软件增加图像的像素点,从低分辨率(low resolution,LR)图像中重建高分辨率(high resolution,HR)图像的方法[2 ] . ...
1
... 肺部CT图像的高精度成像设备成本高昂,无法大规模推广[1 ] . 图像超分辨率重建(super-resolution reconstruction,SR)技术被逐渐应用于医疗领域,它是指通过计算机软件增加图像的像素点,从低分辨率(low resolution,LR)图像中重建高分辨率(high resolution,HR)图像的方法[2 ] . ...
基于动态注意力网络的图像超分辨率重建
1
2023
... 肺部CT图像的高精度成像设备成本高昂,无法大规模推广[1 ] . 图像超分辨率重建(super-resolution reconstruction,SR)技术被逐渐应用于医疗领域,它是指通过计算机软件增加图像的像素点,从低分辨率(low resolution,LR)图像中重建高分辨率(high resolution,HR)图像的方法[2 ] . ...
基于动态注意力网络的图像超分辨率重建
1
2023
... 肺部CT图像的高精度成像设备成本高昂,无法大规模推广[1 ] . 图像超分辨率重建(super-resolution reconstruction,SR)技术被逐渐应用于医疗领域,它是指通过计算机软件增加图像的像素点,从低分辨率(low resolution,LR)图像中重建高分辨率(high resolution,HR)图像的方法[2 ] . ...
基于残差网络的结直肠内窥镜图像超分辨率重建方法
1
2023
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
基于残差网络的结直肠内窥镜图像超分辨率重建方法
1
2023
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
基于真实退化估计与高频引导的内窥镜图像超分辨率重建
1
2024
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
基于真实退化估计与高频引导的内窥镜图像超分辨率重建
1
2024
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
先验GAN的CBCT牙齿图像超分辨率方法
1
2023
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
先验GAN的CBCT牙齿图像超分辨率方法
1
2023
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
1
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
1
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
基于改进Transformer的结构化图像超分辨网络
1
2023
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
基于改进Transformer的结构化图像超分辨网络
1
2023
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
2
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
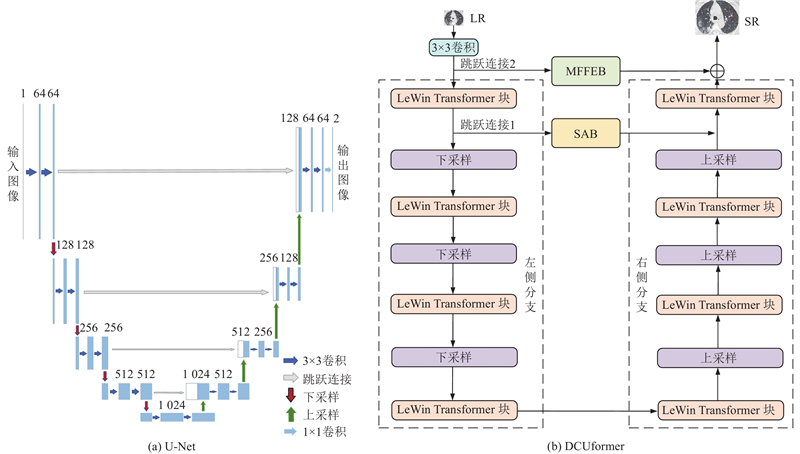
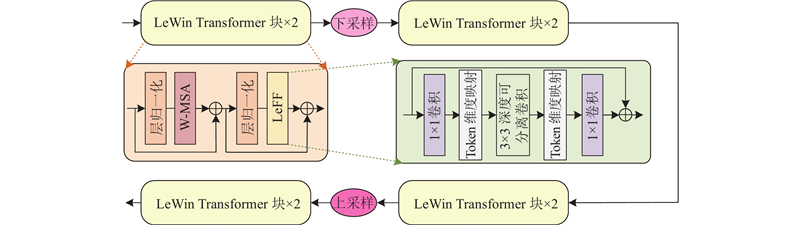
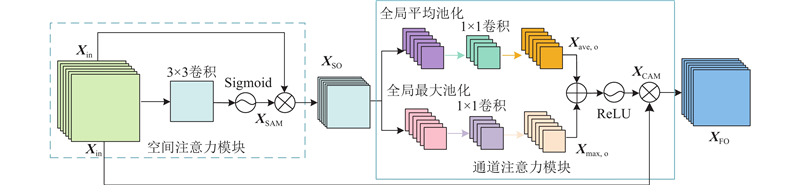
... 现有网络在处理重建灰度级别丰富的肺部CT图像时存在特征提取不充分、重建细节较差的问题. 如TVSRN[9 ] 在特征提取阶段,依赖多层自注意力机制而缺乏卷积计算,导致网络对局部特征的提取不充分. DCA[10 ] 的通道注意力与卷积串联提取特征方式会造成信息丢失,特别是在进行特征融合时,未能有效整合不同层次的信息. MCMRSR[12 ] 使用单一尺寸的卷积无法重建出肺部CT图像的细微病灶变化. 本研究利用Transformer捕获全局信息的优势来保证肺部CT图像重建后整体结构的连续性,考虑到Transformer对于细微结构的特征提取存在局限性,应用U-Net多层特征提取的结构,提出基于局部增强Transformer和U-Net的超分辨率重建网络(super-resolution reconstruction network based on a locally enhanced Transformer and U-Net,DCUformer). 1)在深层特征提取阶段设计基于多感受野的特征提取块,采用不同膨胀率的空洞卷积层获取不同感受野下的全局特征信息. 2)设计基于局部增强模块(LeWin Transformer)的U型结构,在局部增强前馈网络中引入深度卷积,促进图像细节恢复. 3)在解码阶段的跳跃连接中加入分割注意模块,充分利用有用的高频信息获得精确的重建图像. ...
2
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
... 现有网络在处理重建灰度级别丰富的肺部CT图像时存在特征提取不充分、重建细节较差的问题. 如TVSRN[9 ] 在特征提取阶段,依赖多层自注意力机制而缺乏卷积计算,导致网络对局部特征的提取不充分. DCA[10 ] 的通道注意力与卷积串联提取特征方式会造成信息丢失,特别是在进行特征融合时,未能有效整合不同层次的信息. MCMRSR[12 ] 使用单一尺寸的卷积无法重建出肺部CT图像的细微病灶变化. 本研究利用Transformer捕获全局信息的优势来保证肺部CT图像重建后整体结构的连续性,考虑到Transformer对于细微结构的特征提取存在局限性,应用U-Net多层特征提取的结构,提出基于局部增强Transformer和U-Net的超分辨率重建网络(super-resolution reconstruction network based on a locally enhanced Transformer and U-Net,DCUformer). 1)在深层特征提取阶段设计基于多感受野的特征提取块,采用不同膨胀率的空洞卷积层获取不同感受野下的全局特征信息. 2)设计基于局部增强模块(LeWin Transformer)的U型结构,在局部增强前馈网络中引入深度卷积,促进图像细节恢复. 3)在解码阶段的跳跃连接中加入分割注意模块,充分利用有用的高频信息获得精确的重建图像. ...
2
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
... 现有网络在处理重建灰度级别丰富的肺部CT图像时存在特征提取不充分、重建细节较差的问题. 如TVSRN[9 ] 在特征提取阶段,依赖多层自注意力机制而缺乏卷积计算,导致网络对局部特征的提取不充分. DCA[10 ] 的通道注意力与卷积串联提取特征方式会造成信息丢失,特别是在进行特征融合时,未能有效整合不同层次的信息. MCMRSR[12 ] 使用单一尺寸的卷积无法重建出肺部CT图像的细微病灶变化. 本研究利用Transformer捕获全局信息的优势来保证肺部CT图像重建后整体结构的连续性,考虑到Transformer对于细微结构的特征提取存在局限性,应用U-Net多层特征提取的结构,提出基于局部增强Transformer和U-Net的超分辨率重建网络(super-resolution reconstruction network based on a locally enhanced Transformer and U-Net,DCUformer). 1)在深层特征提取阶段设计基于多感受野的特征提取块,采用不同膨胀率的空洞卷积层获取不同感受野下的全局特征信息. 2)设计基于局部增强模块(LeWin Transformer)的U型结构,在局部增强前馈网络中引入深度卷积,促进图像细节恢复. 3)在解码阶段的跳跃连接中加入分割注意模块,充分利用有用的高频信息获得精确的重建图像. ...
1
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
1
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
2
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
... 现有网络在处理重建灰度级别丰富的肺部CT图像时存在特征提取不充分、重建细节较差的问题. 如TVSRN[9 ] 在特征提取阶段,依赖多层自注意力机制而缺乏卷积计算,导致网络对局部特征的提取不充分. DCA[10 ] 的通道注意力与卷积串联提取特征方式会造成信息丢失,特别是在进行特征融合时,未能有效整合不同层次的信息. MCMRSR[12 ] 使用单一尺寸的卷积无法重建出肺部CT图像的细微病灶变化. 本研究利用Transformer捕获全局信息的优势来保证肺部CT图像重建后整体结构的连续性,考虑到Transformer对于细微结构的特征提取存在局限性,应用U-Net多层特征提取的结构,提出基于局部增强Transformer和U-Net的超分辨率重建网络(super-resolution reconstruction network based on a locally enhanced Transformer and U-Net,DCUformer). 1)在深层特征提取阶段设计基于多感受野的特征提取块,采用不同膨胀率的空洞卷积层获取不同感受野下的全局特征信息. 2)设计基于局部增强模块(LeWin Transformer)的U型结构,在局部增强前馈网络中引入深度卷积,促进图像细节恢复. 3)在解码阶段的跳跃连接中加入分割注意模块,充分利用有用的高频信息获得精确的重建图像. ...
2
... 针对肺部CT图像的超分辨率重建网络研究取得突破性进展,该网络主要基于卷积神经网络(CNN)、生成对抗网络(generative adversarial network,GAN)和基于Transformer网络. 基于CNN的网络[3 -4 ] 恢复高频信息的能力强,但在多尺度特征分析方面存在局限性. 基于GAN的网络[5 ] 在主观视觉感知方面优势明显,但图像细节的恢复性能不完善. 谷歌机器翻译团队提出Transformer[6 ] ,在自然语言处理领域取得优异表现. 这种结构不依赖CNN和循环神经网络,通过全局自注意力机制捕获数据中的长距离依赖关系. 之后,Transformer被应用于超分辨率重建任务,SwinIR[7 ] 结合CNN和Transformer的优点,衍生出一系列以SwinIR为基础的、性能优越的超分辨率重建网络[8 ] . Yu等[9 ] 提出基于注意力机制的Transformer体积超分辨率网络(Transformer volume super-resolution network,TVSRN),结合注意力机制并利用体积数据的空间位置关系,在医学图像的超分辨率上获得了令人满意的成果. 赵凯光[10 ] 将通道注意力与卷积结合,进一步融合肺部CT图像的全局与局部特征信息. 刘伟[11 ] 采用Transformer和CNN混合框架进行磁共振图像(magnetic resonance imaging,MRI)重建,增强了纹理细节的呈现效果. 李光远[12 ] 设计基于Transformer的多尺度特征重建网络,解决了多尺度和长距离依赖的问题,提高了MRI的图像质量. ...
... 现有网络在处理重建灰度级别丰富的肺部CT图像时存在特征提取不充分、重建细节较差的问题. 如TVSRN[9 ] 在特征提取阶段,依赖多层自注意力机制而缺乏卷积计算,导致网络对局部特征的提取不充分. DCA[10 ] 的通道注意力与卷积串联提取特征方式会造成信息丢失,特别是在进行特征融合时,未能有效整合不同层次的信息. MCMRSR[12 ] 使用单一尺寸的卷积无法重建出肺部CT图像的细微病灶变化. 本研究利用Transformer捕获全局信息的优势来保证肺部CT图像重建后整体结构的连续性,考虑到Transformer对于细微结构的特征提取存在局限性,应用U-Net多层特征提取的结构,提出基于局部增强Transformer和U-Net的超分辨率重建网络(super-resolution reconstruction network based on a locally enhanced Transformer and U-Net,DCUformer). 1)在深层特征提取阶段设计基于多感受野的特征提取块,采用不同膨胀率的空洞卷积层获取不同感受野下的全局特征信息. 2)设计基于局部增强模块(LeWin Transformer)的U型结构,在局部增强前馈网络中引入深度卷积,促进图像细节恢复. 3)在解码阶段的跳跃连接中加入分割注意模块,充分利用有用的高频信息获得精确的重建图像. ...
基于空洞卷积的医学图像超分辨率重建算法
1
2023
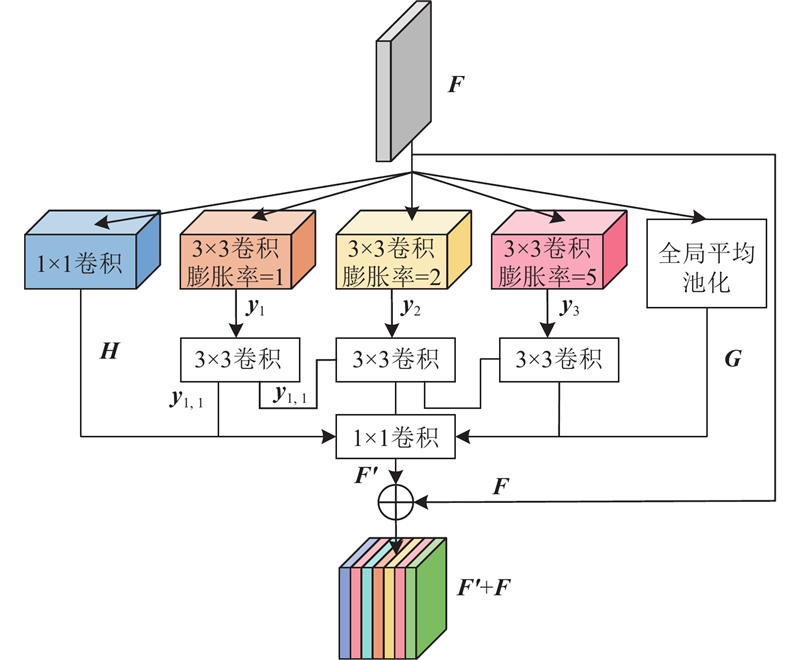
... 采用单一卷积层提取特征信息的网络无法充分利用局部图像的相邻像素信息,较深的网络层主要提取深层特征,浅层特征信息往往被忽略,导致在重建复杂纹理时效果较差[13 ] . 如图2 所示,MFFEB通过3×3的卷积层提取原始特征,利用不同膨胀率的空洞卷积层进行深层特征提取,通过融合不同尺度下提取的特征信息,捕捉到更丰富的细节特征,使重建图像的质量得到显著提升. MFFEB采用1×1卷积层来减小特征的通道维度: ...
基于空洞卷积的医学图像超分辨率重建算法
1
2023
... 采用单一卷积层提取特征信息的网络无法充分利用局部图像的相邻像素信息,较深的网络层主要提取深层特征,浅层特征信息往往被忽略,导致在重建复杂纹理时效果较差[13 ] . 如图2 所示,MFFEB通过3×3的卷积层提取原始特征,利用不同膨胀率的空洞卷积层进行深层特征提取,通过融合不同尺度下提取的特征信息,捕捉到更丰富的细节特征,使重建图像的质量得到显著提升. MFFEB采用1×1卷积层来减小特征的通道维度: ...
1
... 实验采用2个公共数据集:COVID-CT[14 ] 和SARS-CoV-2[15 ] . COVID-CT数据集中的图像主要来自武汉各大医院,其中感染新冠病毒者的CT图像有349幅,未感染新冠病毒者的CT图像有397幅. SARS-CoV-2数据集中的图像主要来自巴西圣保罗公立医院,包含1 252幅感染新冠病毒者的CT图像和1 230幅未感染新冠病毒者的CT图像. 在2个数据集中随机取出20%的图像作为测试集,其他作为训练集. 训练时采用随机水平翻转和随机垂直翻转进行数据增强,对公共数据集进行2倍扩充,将扩充后的图像输入网络进行训练. 采用基于结构重叠的下采样方法获得HR图像对应的LR图像,使二者匹配. 实验环境:显存为11 GB的Nvidia GTX 1080Ti GPU,CPU为8核Intel i9 9900K,主频为3.6 GHz,使用Python语言和Pytorch框架. ...
1
... 实验采用2个公共数据集:COVID-CT[14 ] 和SARS-CoV-2[15 ] . COVID-CT数据集中的图像主要来自武汉各大医院,其中感染新冠病毒者的CT图像有349幅,未感染新冠病毒者的CT图像有397幅. SARS-CoV-2数据集中的图像主要来自巴西圣保罗公立医院,包含1 252幅感染新冠病毒者的CT图像和1 230幅未感染新冠病毒者的CT图像. 在2个数据集中随机取出20%的图像作为测试集,其他作为训练集. 训练时采用随机水平翻转和随机垂直翻转进行数据增强,对公共数据集进行2倍扩充,将扩充后的图像输入网络进行训练. 采用基于结构重叠的下采样方法获得HR图像对应的LR图像,使二者匹配. 实验环境:显存为11 GB的Nvidia GTX 1080Ti GPU,CPU为8核Intel i9 9900K,主频为3.6 GHz,使用Python语言和Pytorch框架. ...
A novel fuzzy hierarchical fusion attention convolution neural network for medical image super-resolution reconstruction
1
2023
... 通过主观评价和客观评价标准衡量重建图像的质量,其中主观评价是指视觉效果,客观评价采用峰值信噪比(peak signal to noise ratio,PSNR)[16 ] 和结构相似性(structural similarity index measure,SSIM)[17 ] 指标评定,PSNR和SSIM的数值越大,说明重建图像质量越好. ...
Image quality assessment: from error visibility to structural similarity
1
2004
... 通过主观评价和客观评价标准衡量重建图像的质量,其中主观评价是指视觉效果,客观评价采用峰值信噪比(peak signal to noise ratio,PSNR)[16 ] 和结构相似性(structural similarity index measure,SSIM)[17 ] 指标评定,PSNR和SSIM的数值越大,说明重建图像质量越好. ...
2
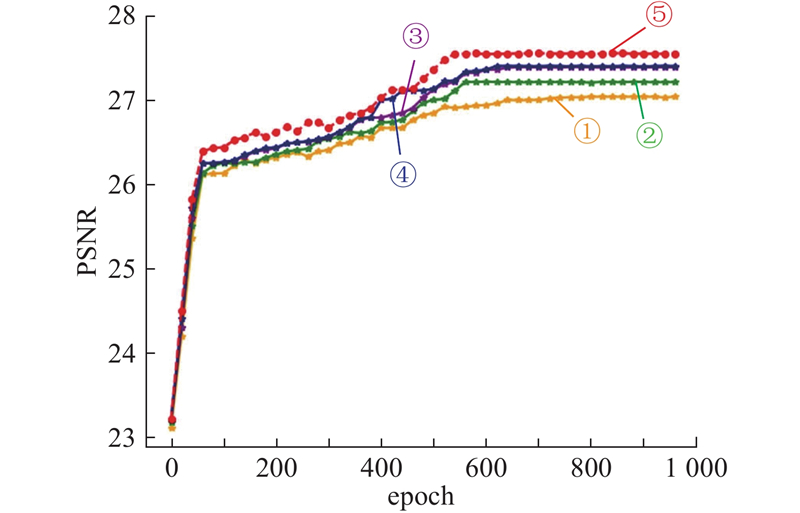
... DCUformer在特征提取策略中添加了空洞卷积,不同膨胀率的卷积获得的感受野大小不同,提取多尺度特征的效果也不同,为了使多个空洞卷积能够覆盖所有的底层特征,设计6种膨胀率,量化结果如表1 所示. 表中,加粗数据为最优结果,下划线数据为次优结果. 连续使用多个膨胀系数相同的空洞卷积,会导致栅格效应,破坏信息的连续性,并且膨胀率的公约数应不大于1[18 ] . 为了便于选择合适的膨胀率,文献[18 ]中定义了2个非零元素的最大间距, ...
... . 为了便于选择合适的膨胀率,文献[18 ]中定义了2个非零元素的最大间距, ...
Progressive back-projection network for COVID-CT super-resolution
1
2021
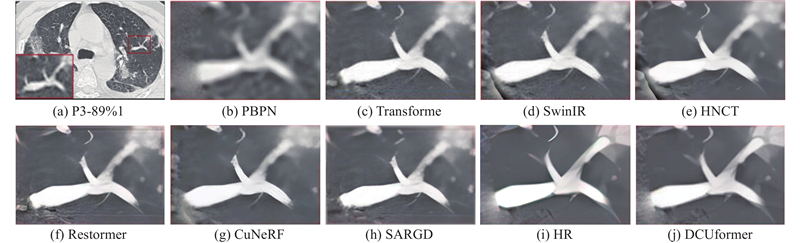
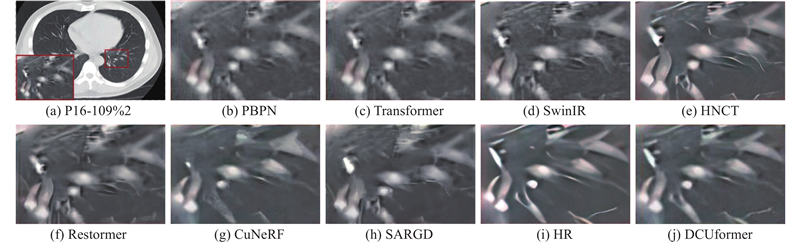
... 在2个数据集中分别对比PBPN[19 ] 、Transformer、SwinIR、Restormer[20 ] 、HNCT[21 ] 、CuNeRF[22 ] 、SARGD[23 ] 和DCUformer的客观评价指标和主观视觉效果. 通过对输入的低分辨率肺部CT图像进行2倍、3倍、4倍的尺寸放大和重建(×2LR、×3LR和×4LR分别表示低分辨率图像的尺寸放大倍数),获得客观指标如表5 、表6 、表7 所示. 由表可知,在3种放大倍数下,所提网络均优于主流网络(HNCT、CuNeRF、SARGD). 分析原因:本研究设计多尺度空洞卷积来聚焦全局和局部信息,同时设计非重叠窗口的自注意力机制和深度卷积,进一步增强了特征之间的关联性,使不同层级间的灰度信息得到有效融合. 以放大4倍为例,与Transformer网络相比,DCUformer在SARS-CoV-2数据集中,SSIM和PSNR分别提高了0.029和0.186 dB,在COVID-CT数据集中,SSIM和PSNR分别提高了0.029和0.511 dB. ...
1
... 在2个数据集中分别对比PBPN[19 ] 、Transformer、SwinIR、Restormer[20 ] 、HNCT[21 ] 、CuNeRF[22 ] 、SARGD[23 ] 和DCUformer的客观评价指标和主观视觉效果. 通过对输入的低分辨率肺部CT图像进行2倍、3倍、4倍的尺寸放大和重建(×2LR、×3LR和×4LR分别表示低分辨率图像的尺寸放大倍数),获得客观指标如表5 、表6 、表7 所示. 由表可知,在3种放大倍数下,所提网络均优于主流网络(HNCT、CuNeRF、SARGD). 分析原因:本研究设计多尺度空洞卷积来聚焦全局和局部信息,同时设计非重叠窗口的自注意力机制和深度卷积,进一步增强了特征之间的关联性,使不同层级间的灰度信息得到有效融合. 以放大4倍为例,与Transformer网络相比,DCUformer在SARS-CoV-2数据集中,SSIM和PSNR分别提高了0.029和0.186 dB,在COVID-CT数据集中,SSIM和PSNR分别提高了0.029和0.511 dB. ...
1
... 在2个数据集中分别对比PBPN[19 ] 、Transformer、SwinIR、Restormer[20 ] 、HNCT[21 ] 、CuNeRF[22 ] 、SARGD[23 ] 和DCUformer的客观评价指标和主观视觉效果. 通过对输入的低分辨率肺部CT图像进行2倍、3倍、4倍的尺寸放大和重建(×2LR、×3LR和×4LR分别表示低分辨率图像的尺寸放大倍数),获得客观指标如表5 、表6 、表7 所示. 由表可知,在3种放大倍数下,所提网络均优于主流网络(HNCT、CuNeRF、SARGD). 分析原因:本研究设计多尺度空洞卷积来聚焦全局和局部信息,同时设计非重叠窗口的自注意力机制和深度卷积,进一步增强了特征之间的关联性,使不同层级间的灰度信息得到有效融合. 以放大4倍为例,与Transformer网络相比,DCUformer在SARS-CoV-2数据集中,SSIM和PSNR分别提高了0.029和0.186 dB,在COVID-CT数据集中,SSIM和PSNR分别提高了0.029和0.511 dB. ...
1
... 在2个数据集中分别对比PBPN[19 ] 、Transformer、SwinIR、Restormer[20 ] 、HNCT[21 ] 、CuNeRF[22 ] 、SARGD[23 ] 和DCUformer的客观评价指标和主观视觉效果. 通过对输入的低分辨率肺部CT图像进行2倍、3倍、4倍的尺寸放大和重建(×2LR、×3LR和×4LR分别表示低分辨率图像的尺寸放大倍数),获得客观指标如表5 、表6 、表7 所示. 由表可知,在3种放大倍数下,所提网络均优于主流网络(HNCT、CuNeRF、SARGD). 分析原因:本研究设计多尺度空洞卷积来聚焦全局和局部信息,同时设计非重叠窗口的自注意力机制和深度卷积,进一步增强了特征之间的关联性,使不同层级间的灰度信息得到有效融合. 以放大4倍为例,与Transformer网络相比,DCUformer在SARS-CoV-2数据集中,SSIM和PSNR分别提高了0.029和0.186 dB,在COVID-CT数据集中,SSIM和PSNR分别提高了0.029和0.511 dB. ...
1
... 在2个数据集中分别对比PBPN[19 ] 、Transformer、SwinIR、Restormer[20 ] 、HNCT[21 ] 、CuNeRF[22 ] 、SARGD[23 ] 和DCUformer的客观评价指标和主观视觉效果. 通过对输入的低分辨率肺部CT图像进行2倍、3倍、4倍的尺寸放大和重建(×2LR、×3LR和×4LR分别表示低分辨率图像的尺寸放大倍数),获得客观指标如表5 、表6 、表7 所示. 由表可知,在3种放大倍数下,所提网络均优于主流网络(HNCT、CuNeRF、SARGD). 分析原因:本研究设计多尺度空洞卷积来聚焦全局和局部信息,同时设计非重叠窗口的自注意力机制和深度卷积,进一步增强了特征之间的关联性,使不同层级间的灰度信息得到有效融合. 以放大4倍为例,与Transformer网络相比,DCUformer在SARS-CoV-2数据集中,SSIM和PSNR分别提高了0.029和0.186 dB,在COVID-CT数据集中,SSIM和PSNR分别提高了0.029和0.511 dB. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}