

在纺织品生产过程中,面料疵点严重影响产品质量,因此疵点检测是生产过程中必不可少的重要环节[1]. 目前,行业内广泛采用人工进行检测,不仅费时费力,也难以满足高标准的生产需求. 因此,面料疵点的检测仍是实际生产中亟待解决的难点和痛点问题.
随着工业4.0的推广,机器视觉检测技术逐渐在织物疵点识别中得到应用. 郑兆伦等[2]提出基于奇异值分解结合形态学处理的缺陷检测算法,针对线形和洞形缺陷取得了良好的检测效果,但奇异值分解作为计算密集型算法,并不适用于实时检测. 周文明等[3]提出基于视觉显著性的算法,通过计算图像块的差异值进行阈值分割得到疵点,但该方法仅依赖局部的视觉显著性差异,在复杂或非均匀的背景下难以准确分离疵点. 闫本超等[4]基于改进的Itti显著性模型对图像进行快速检测,在获取织物亮度及方向特征后,通过归一化获得疵点显著图并分割. 随着深度学习技术的飞速发展,研究者们将这一新技术成功应用于该问题中. Girshick[5]基于Faster R-CNN模型,融合可变形卷积和级联网络来提高机织纱线的检测精度,但这类二阶段目标检测模型在速度方面尚有待提升. 王安静等[6]在YOLOv8s的基础上提出细粒化卷积模块,并引入GFPN特征融合来提高模型对小缺陷的检测能力,但并未考虑模型的轻量化设计. 张艳等[7]提出基于金字塔分割注意力与线性变换的轻量化算法,在降低参数量的同时,提高了模型检测效率. Liu等[8]提出轻量化模型PRC-Light YOLO,通过新的算子优化特征提取,并采用Wise-IoU v3减轻低质量实例的梯度,但其并未针对复杂纹理背景提出合理的解决方案.
现有织物缺陷检测多用YOLO系列模型,其在准确性和实时性上较传统机器视觉方法有一定提升,但其对复杂背景和微小缺陷检测的能力仍待提高. 此外,模型在实际部署过程中受到后处理操作(如非极大值抑制)的限制,算法的实时性能受到影响. 针对上述问题,Carion等[9]提出的DETR(DEtection TRansformer)创新性地将检测任务视为集合预测问题,避免了复杂的后处理操作,有效提高了检测速度. Zhang等[10]针对DETR训练缓慢的问题,提出DINO(DETR with improved denoising anchor boxes)模型,通过引入新的检测头来优化初期的标签分配,以有效加快训练速度. Zhao等[11]提出RT-DETR(Real-Time Detection Transformer)模型,在DINO的基础上,优化了其中的Transformer架构,并通过IoU-aware Query Selection机制进一步提高了检测精度,推动了DETR系列模型的发展.
复杂的布匹纹理和多样的缺陷对保证检测的准确性与实时性提出了更高的要求. 本研究提出基于改进RT-DETR模型的面料疵点检测算法,并以牛仔布面料作为数据集,旨在提升高分辨率和复杂纹理背景下的面料疵点检测性能.
1. RT-DETR目标检测算法
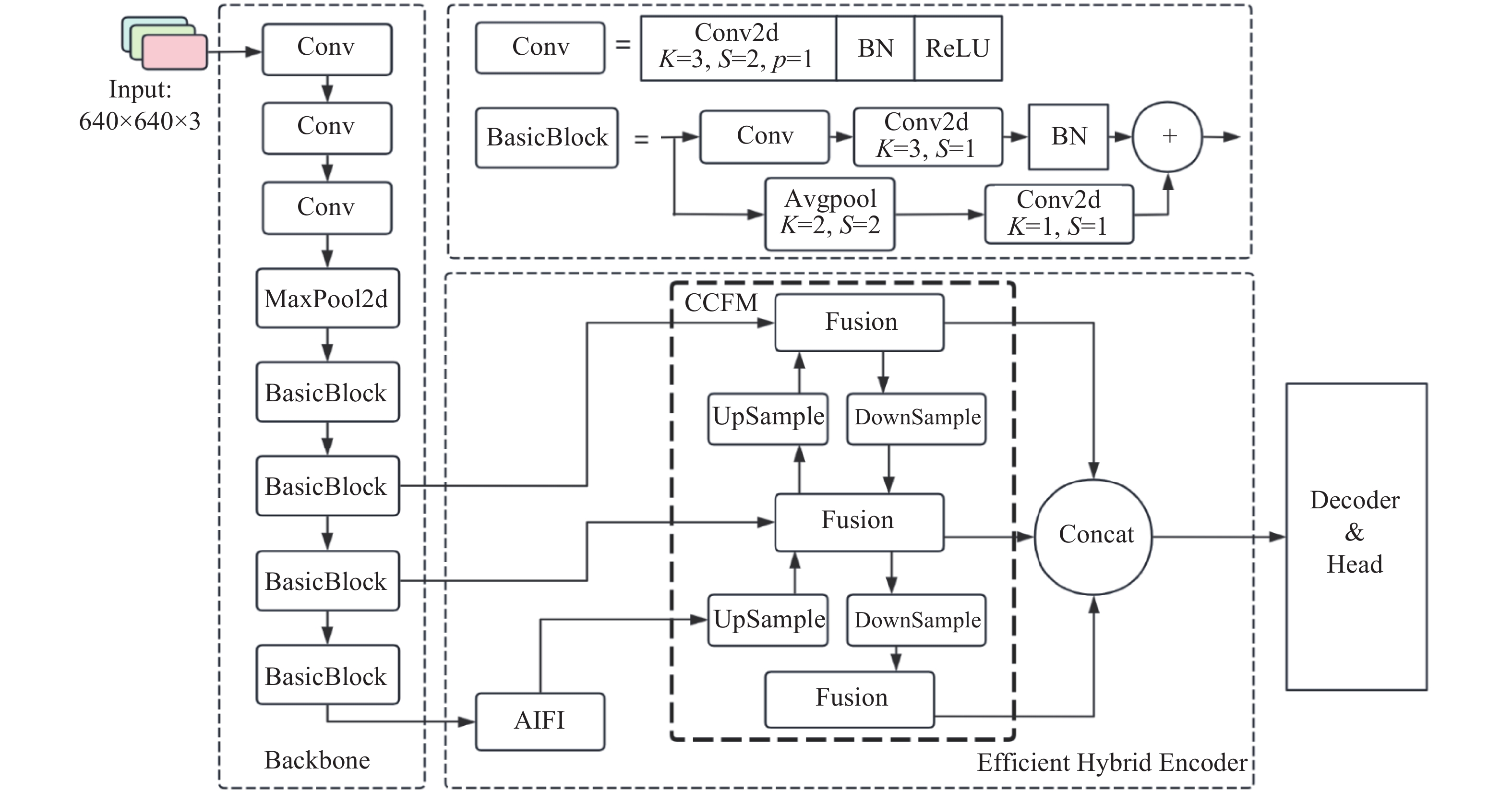
RT-DETR针对DETR训练难、收敛慢的问题,提出了新的解决方案. 首先,RT-DETR采用限定的尺度内特征交互( attention-based intra-scale feature interaction,AIFI)机制,有效避免了特征融合过程中低级特征与高级特征间可能发生的语义冲突和信息冗余;其次,通过高效的混合编码器从低级特征中抽取出富含对象详细语义信息的高级特征,在提升检测精度的同时大幅降低计算开销;进一步地,RT-DETR引入IoU-aware Query Selection机制,确保在进行Top-K特征预测时,所选特征同时具有高分类得分和高IoU得分,从而提升模型的检测精度;最后,RT-DETR结合优秀的DINO检测头,避免训练初期因标签变化而产生的严重误差,大幅提高了训练的速度.基于上述改进,RT-DETR在检测精度与速度上相较原始DETR算法有提升. RT-DETR提供了R18、R50、R101等多种不同尺度的模型变体,考虑检测精度和检测速度的要求,本研究采用R18网络模型作为基准模型展开后续研究,其结构如图1所示. 图中,K表示卷积核大小,S表示卷积核滑动的步长,P表示填充的像素数.
图 1
2. 改进RT-DETR缺陷检测算法
2.1. PConv模块
在计算机视觉领域,常用卷积运算提取图像特征,已有研究[12-14] 表明,该操作所产生的冗余通道信息将造成计算量的增加. 轻量级网络架构常用深度卷积或组卷积来提取特征,但其算子将增加内存访问,造成计算效率低下. 为此,引入计算量更少的部分卷积 (partial convolution, PConv)[15]来代替原网络Backbone中标准的2D卷积,PConv结构如图2所示. 假设
图 2
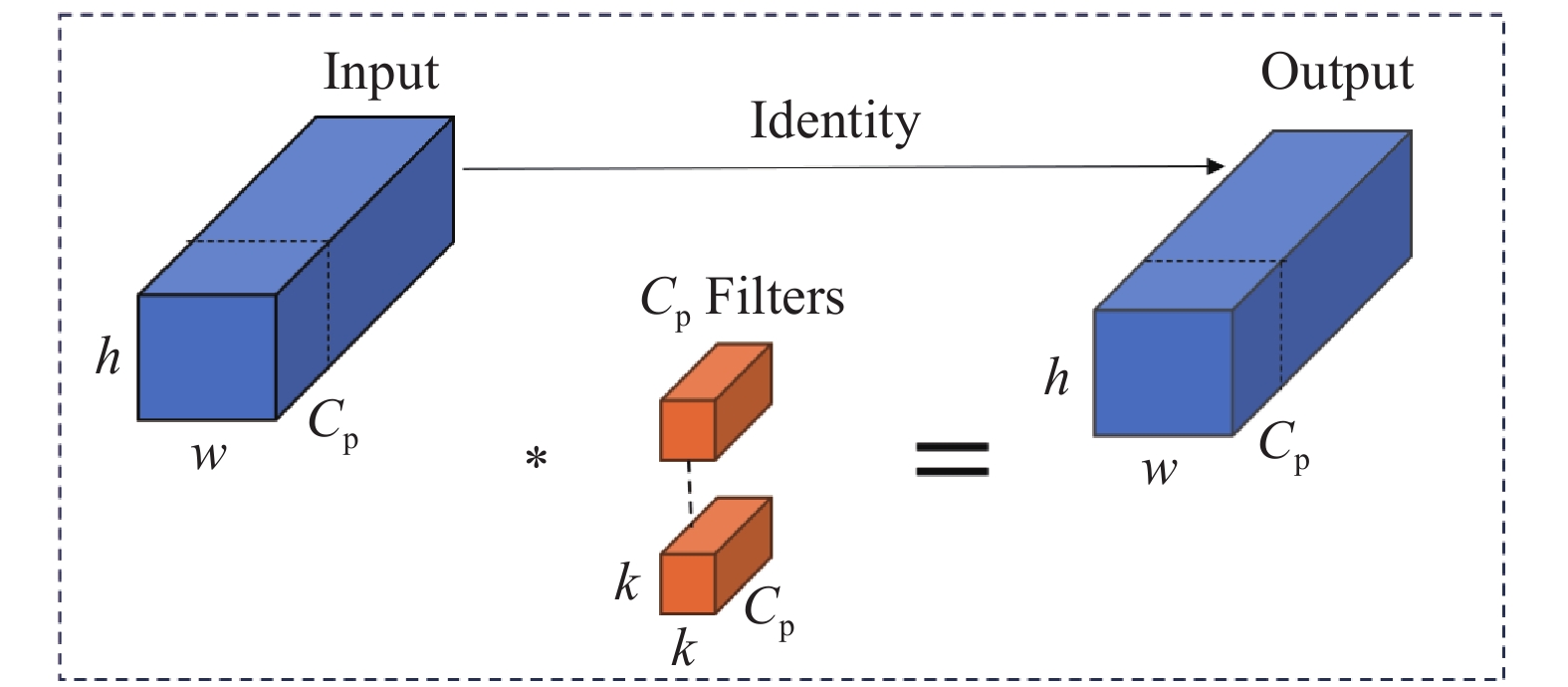
对于PConv,只须选取连续的
2.2. EMA注意力机制
图 3

输入特征图
2.3. 可变形注意力
在RT-DETR模型中,采用自适应内部特征交互机制对S5检测层执行特征交互,这种方式将导致初始化后注意力权重均匀分配,需要长时间的训练才能将注意力集中在特定的Key向量上,造成模型收敛缓慢. 为了克服该缺陷,引入可变形注意力Deformable Attention[17],将注意力集中于参考点及其周围的一组关键采样点上. 给定输入特征图
式中:
Deformable Attention通过动态聚焦关键特征区域,仅须对少量关键向量进行选择性采样即可实现高效的特征建模,减少对整体特征图的计算,显著降低了资源需求,并通过学习每个注意力头中的偏移量,动态调整关注的空间位置,以适应疵点的多样性.
2.4. S2检测层
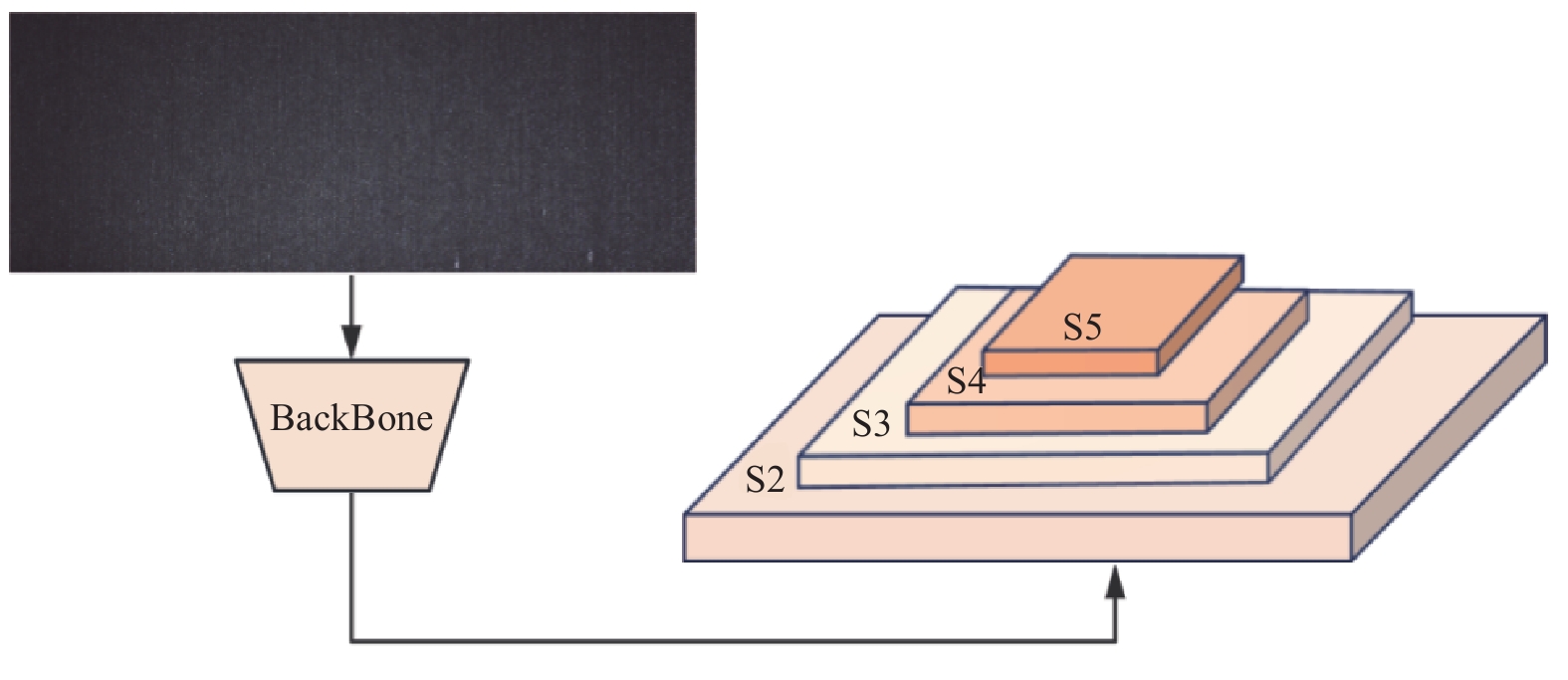
在工业检测系统中,采集到的图像具有高分辨率、显著宽高比的特性,而其中的疵点缺陷可能仅占极少像素,并与背景纹理具有高度相似性,容易误导模型做出错误判断. 因此,本研究在原有网络结构的基础上,添加S2小目标检测层,旨在避免小目标缺陷被忽略或误判,增强模型对于小尺度目标物体的检测能力,S2检测层示意图如图4所示.
图 4
2.5. 优化损失函数
在RT-DETR模型中,使用GIoU来计算边界框的回归损失,但IoU度量指标对于微小尺度物体敏感性较高. 如图5所示,每个网格代表一个像素,框A表示实际边界框,框B、C表示预测框,分别具有1像素和4像素的对角线偏差. 从图5(a)、(b)中可以看出,对于微小尺度的物体,极小的像素偏差对于IoU结果有极大影响,这限制了基于IoU的损失函数在精确定位微小物体方面的效率. 为此,提出新的联合损失函数
图 5
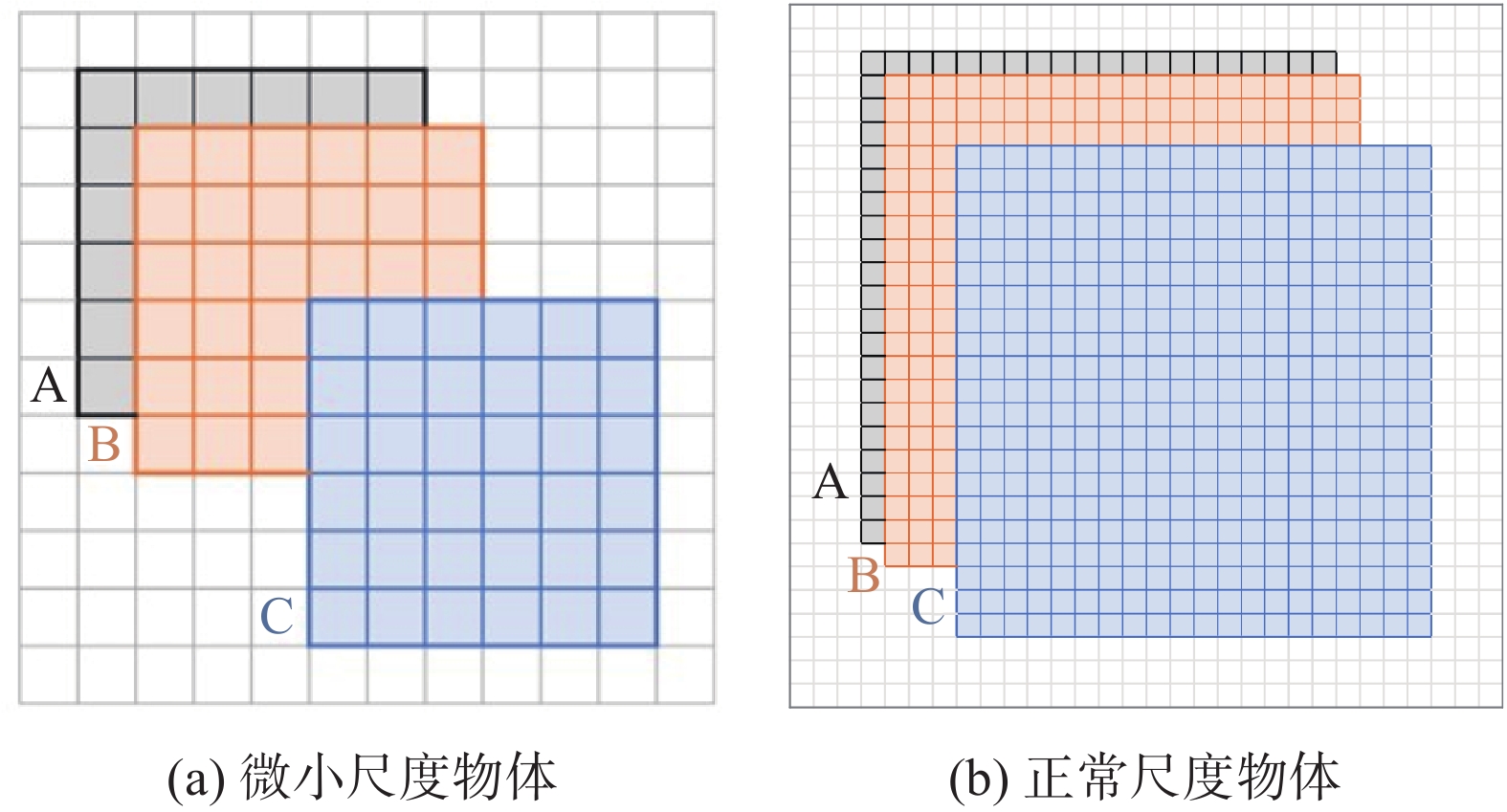
图 5 IoU对微小和正常尺度物体的敏感度分析
Fig.5 IoU sensitivity analysis for tiny- and normal-scale objects
式中:
考虑到实际预测过程中,边界框内疵点像素只占小部分,大多为无关的背景像素,且分别集中在边界框的中心和边界上. 为了更好地描述不同像素的权重,可将边界框建模为二维高斯分布. 预测框为
式中:
式中:
NWD损失函数将预测框和边界框之间的相似度转换为2个高斯分布之间的分布距离,能有效缓解不同尺度目标的敏感性问题.
CIoU损失部分的计算公式如下:
式中:IoU表示2个区域的交集面积与并集面积之比,
式中:
LCIoU补充了对于边界框的重叠度、形状和尺寸差异的考虑,能更全面地评判边界框回归的质量.
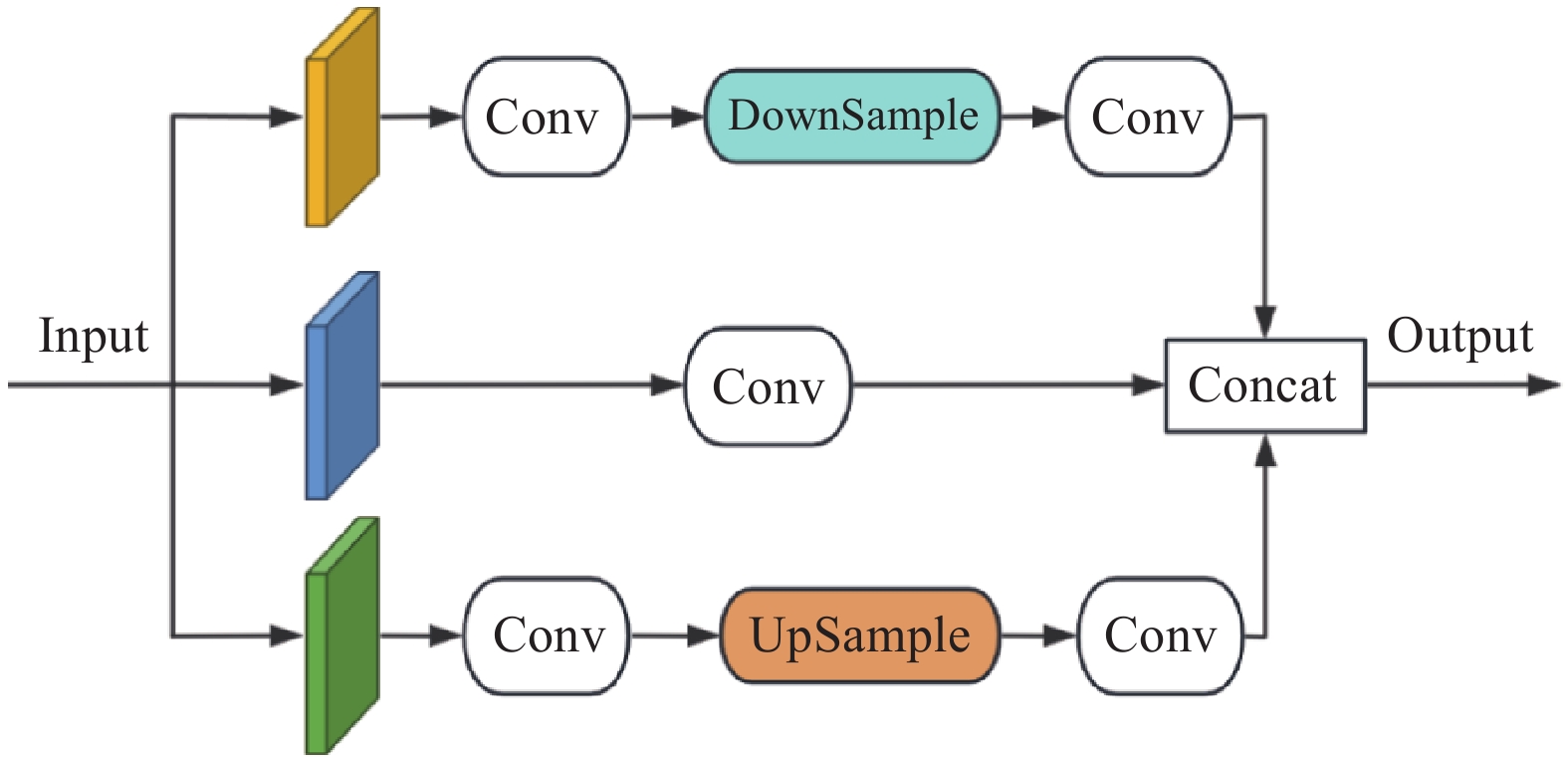
2.6. 多尺度特征融合及编码
如图6所示,在RT-DETR架构中,采用跨尺度特征融合(cross-scale feature fusion module, CCFM)模块实现不同特征层之间的有效信息整合. 不过,其融合策略主要针对尺寸相似的特征层,忽略了不同尺度特征间的互补性;多个融合模块之间缺乏有效的交互机制,仅依赖简单拼接,限制了模型在整合不同特征图相关性方面的能力. 为了更有效地整合深层特征图中的高维信息与浅层特征图的细节信息,同时避免引入更多的计算量,提出多尺度特征融合(multi-scale feature fusion, MSFF)模块和多特征编码(multi-feature encoding, MFE)模块,分别如图7、8所示.
图 6
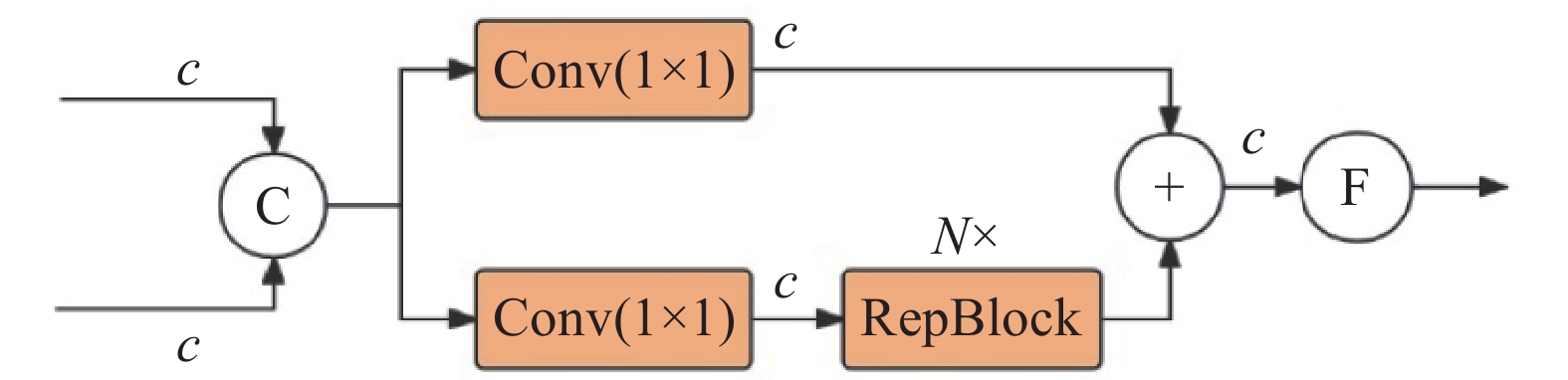
图 7
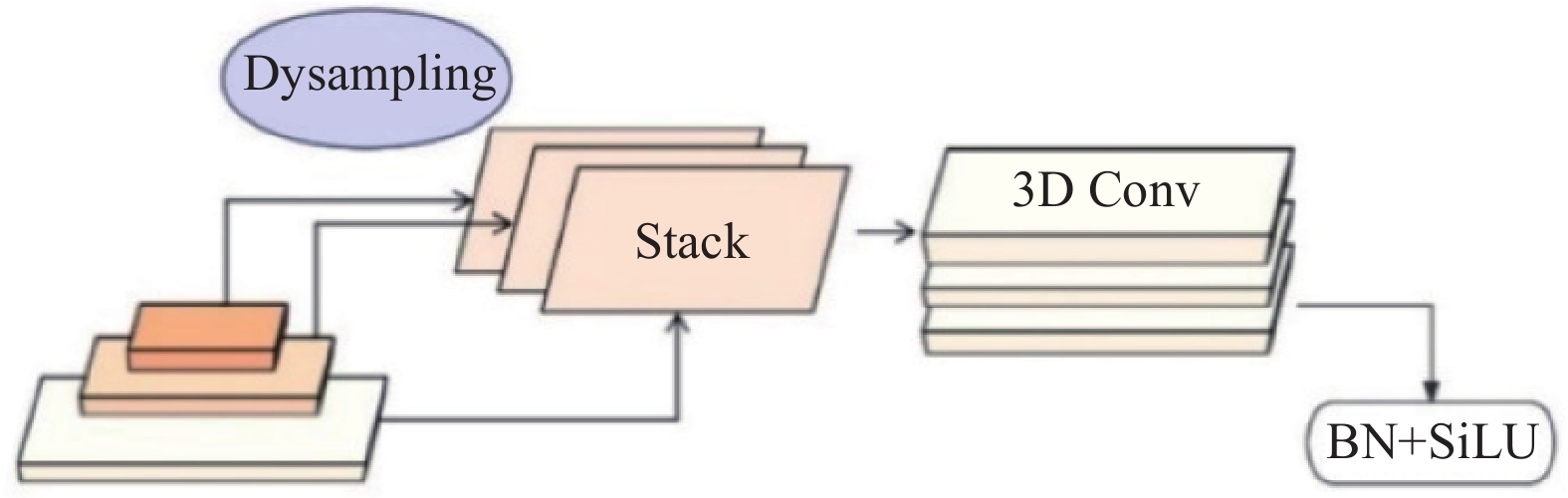
图 8
在MSFF模块中,首先通过DySample[19]技术,代替传统的最近邻插值方法,将输入的特征图统一上采样至最大特征图的维度,进而利用3D卷积提取特征,以减少模型参数,同时聚合不同层的特征以获取更丰富和更细致的特征表示,增强模型提取多尺度特征的能力. 进一步,通过多特征编码(MFE)模块对CCFM模块的融合效果进行增强. 考虑到疵点的大小、形状多样性及其位置的不固定性,单一尺度的特征表示可能导致部分关键信息的丢失,影响检测性能,MFE模块通过融合不同尺度的特征图来丰富语义特征的表示. 具体地,对于较大尺寸的特征图,采用HWD[20]算子来保留更多的信息;对于小尺寸特征图,采用Dysample上采样操作来维持局部特征丰富性,以防止小目标特征信息的遗失. 通过采样操作将不同尺度的特征层进行统一调整,保证通道数的一致,随后,将这3个特征图沿通道维度进行拼接,以实现深度特征的高效融合:
式中:
2.7. 整体结构
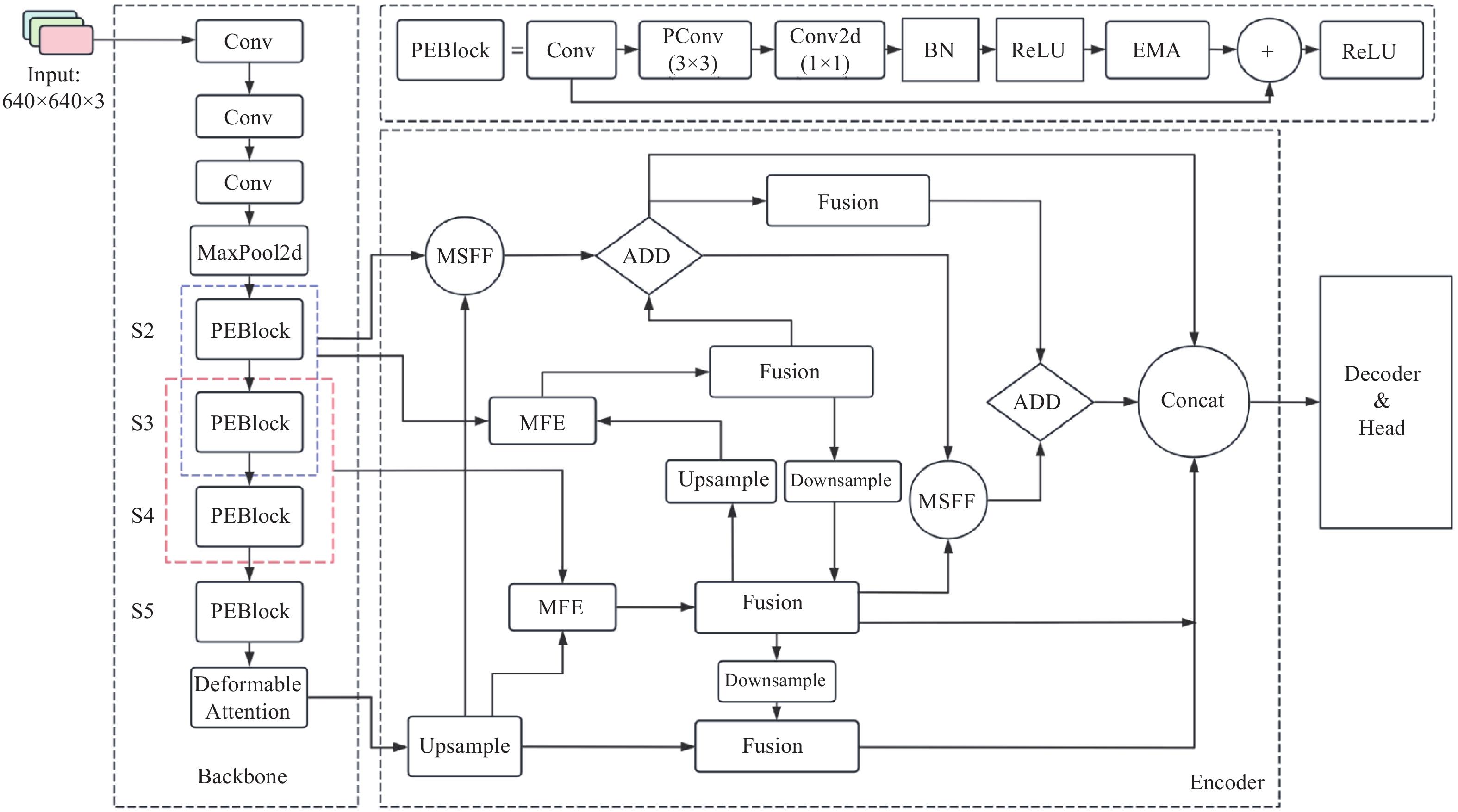
针对复杂工业场景下疵点检测存在的多尺度特征融合不足、小目标敏感度低之类的共性问题,以RT-DETR为基准模型,对骨干网络及特征融合部分进行针对性的改进,并优化损失函数,整体结构如图9所示.骨干网络作为提取图像特征的主要网络,其提取特征能力的强弱对模型的整体检测效果影响较大,本研究在RT-DETR原有骨干网络基础上以部分卷积(PConv)替换原有的标准2D卷积,并结合EMA注意力机制形成PEBlock,来进一步加强特征提取能力,并将原模型的AIFI机制替换为Deformable Attention来适应形状多样的疵点. 在特征融合部分,在添加S2检测层的基础上结合所提出的新的特征融合方式MSFF和MFE来加强不同尺寸特征图之间的交互性,旨在获得更丰富的特征表示,并引入不同的采样算子来最大化保留特征信息. 最后,将原模型中的损失函数替换为由NWD损失函数结合CIoU损失的联合损失函数,加快模型收敛.
图 9
3. 实验结果分析
3.1. 数据集及预处理
3.1.1. 数据集及缺陷种类
所用数据集来自阿里云-天池大数据众智平台的布匹疵点检测数据集,布匹面料为牛仔布,共选取图片
图 10

牛仔面料通常采用粗棉纱制作,该材料在纤维的粗细和扭曲度上具有非均匀性,这种特性显著增加了面料的纹理复杂度. 在其染色工艺中,内外层纱线易形成明显的色差,进一步增强了纹理的多样性. 此外,牛仔布常采用三对一斜纹织法,该织法交织染色与未染色纱线,使得未染色纱线在染色纱线构成的背景上形成明显的视觉点状效果. 这种织造技术不仅为牛仔面料的视觉效果增添了层次,也复杂化了纹理的感知,进一步提高了检测的难度.
如图10所示为牛仔布匹缺陷检测样本的示意图. 通过缺陷样本可以观察到,疵点像素占整体像素比重极小,且疵点与背景纹理相似. 因此,选用牛仔面料作为本研究的数据集,来验证本研究所提出模型在复杂纹理背景下的有效性.
3.1.2. 图像预处理
为了消除光照不均和拍摄设备引入的噪声和干扰,对图像进行相应的预处理操作:采用高斯滤波器平滑图像,减少图像的随机噪声,保持纹理边缘的清晰度. 同时,采取直方图均衡化处理,调整图像的对比度,使整个图像的亮度分布更加均匀,从而增强了图像中的局部细节.
3.2. 实验环境的搭建
表 1 深度学习的实验环境配置
Tab.1
| 配置环境 | 配置名称(版本) |
| 操作系统 | Windows10 |
| CPU | Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz |
| GPU | RTX |
| 编译器 | Python 3.8(ubuntu20.04) |
| 深度学习框架 | PyTorch 1.11.0 |
| 加速模块 | CUDA Toolkit-11.3.1 |
表 2 深度学习的实验超参数
Tab.2
| 参数 | 含义 | 数值 |
| Images size | 图像尺度 | 640 |
| batch size | 批数量 | 4 |
| E | 迭代次数 | 200 |
| lr | 学习率 | |
| Momentum | 动量 | 0.9 |
| Weight_decay | 权重衰减率 |
3.3. 实验结果和分析
3.3.1. 损失函数参数设置对比实验
NWD损失函数在检测微小瑕疵方面表现出显著的尺度不变性,并且能有效测量非重叠或相互包含的边界框之间的相似度,涵盖了部分CIoU的特性. CIoU损失函数主要旨在补偿对边界框尺寸和形状的精确度调整. 基于此,以NWD损失为主要导向,确定联合损失函数中的权重
表 3 损失函数参数设置对比实验
Tab.3
| 权重取值 | mAP@0.5/% | mAP@0.50−0.95/% |
| 55.3 | 25.3 | |
| 55.6 | 25.8 | |
| 56.0 | 25.9 | |
| 56.3 | 26.1 | |
| 55.9 | 25.7 |
3.3.2. 单一改进有效性对比实验
为了评估所提出模型改进措施的有效性,设计一系列单项改进效果对比实验,通过将各项改进分别整合至基准模型中,逐一分析每项改进对模型性能的具体影响.
将基准模型简记为“R18”;将PConv替换主干网络中的2D卷积记为改进模型1;添加EMA注意力机制记为改进模型2;引入Deformable Attention记为改进模型3;添加小目标检测层并结合MSFF与MFE模块记为改进模型4;结合所有改进的新模型为本研究模型. 实验结果以每秒运算帧数
表 4 单一改进有效性对比实验结果
Tab.4
| 算法 | S/MB | ||||||
| RT-DETR-R18 | 0.667 | 0.557 | 54.7 | 25.1 | 57.1 | 1.988 | 38.6 |
| R18+PConv(改进模型1) | 0.686 | 0.587 | 58.3 | 27.0 | 51.2 | 1.679 | 32.8 |
| R18+EMA(改进模型2) | 0.703 | 0.583 | 57.9 | 28.1 | 45.2 | 1.998 | 38.9 |
| R18+Deformable Attention(改进模型3) | 0.697 | 0.608 | 58.7 | 27.9 | 49.3 | 1.988 | 38.6 |
| R18+S2+MSFF-MFE(改进模型4) | 0.710 | 0.588 | 58.6 | 28.8 | 49.2 | 1.500 | 29.1 |
| R18+3个改进点(本研究模型) | 0.710 | 0.603 | 60.0 | 28.6 | 37.4 | 1.190 | 23.5 |
改进1采用PConv替换原模型中的2D卷积,相对于原模型,参数量降低了15.5%,有效减少了冗余的计算,同时mAP@0.5、mAP@0.50−0.95分别提升3.6、1.9个百分点,证明了其对于准确率的提升. 改进2通过在主干网络中添加EMA注意力机制,使得模型能够更关注于重要特征部分,增强了对于缺陷特征的捕捉,使得mAP@0.5提升了3.2个百分点,mAP@0.50−0.95提升了3.0个百分点. 改进3通过替换原模型中的AIFI为Deformable Attention,在未引起网络结构变化的前提下,优化了模型对不同形状疵点的适应性. 结果显示,mAP@0.5提升4.0个百分点,mAP@0.50−0.95提升2.8个百分点,证明了该策略在增强模型对疵点形状多样性识别能力方面的有效性. 改进4通过添加针对小目标的检测层及采用多尺度特征融合(MSFF)和多特征编码(MFE),实现对模型检测性能的提升. 对特征维度的压缩设计也显著降低了参数量. 精确率提升4.3个百分点,mAP@0.5、mAP@0.50−0.95分别提升3.9、3.7个百分点. 本研究模型将上述模块集成至基准模型中,形成了本研究所提模型,结合上述模块的优点后,检测速度和精确率都有明显的提升. 尽管网络复杂度和深度的增加导致推理速度有所下降,但检测性能的显著提升证明了其在实时疵点检测中的应用潜力.
3.3.3. 损失函数对比实验
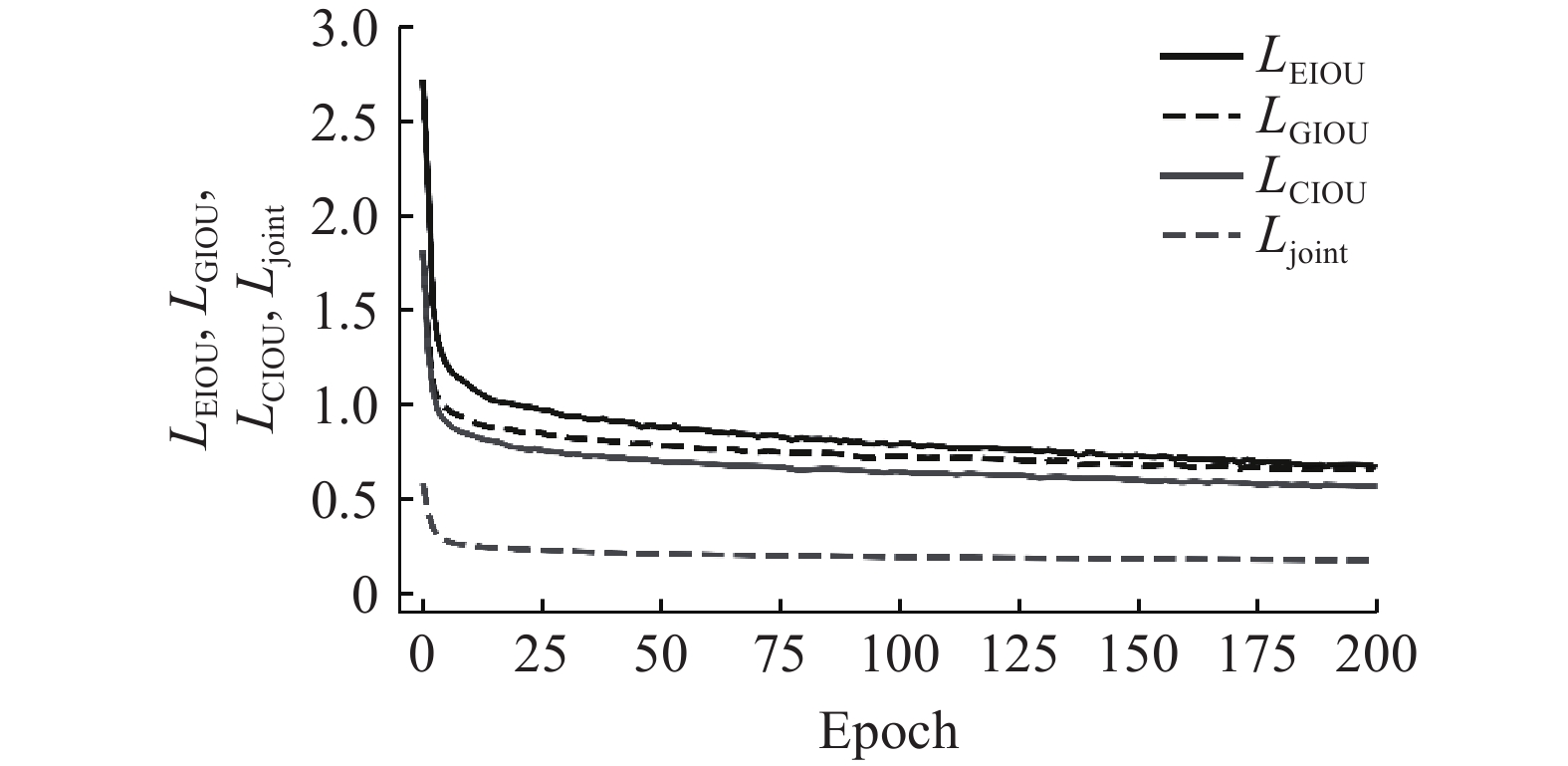
为了验证本研究提出的联合损失函数的有效性,在本研究模型的基础上,通过替换不同的损失函数来分别对比预测的准确度与收敛情况. 用于对比的损失函数如下:GIOU (generalized IoU)在 IoU 基础上引入最小闭合区域(包围两框的最小矩形);CIOU (complete IoU)在考虑中心点距离的基础上,额外加入长宽比一致性惩罚;EIOU (efficient IoU)将 CIOU 的长宽比惩罚拆解为独立的宽度和高度的差异惩罚,直接约束宽高绝对值而非比例. 实验结果分别如表5和图11所示. 其中,epoch表示模型的迭代次数. 从表5结果可以看出,将原始的GIoU损失函数替换为联合损失函数
表 5 损失函数对比实验
Tab.5
| 损失函数 | ||||
| LGIoU | 0.687 | 0.575 | 57.0 | 26.1 |
| LCIoU | 0.706 | 0.587 | 59.3 | 28.1 |
| LEIoU | 0.701 | 0.585 | 58.7 | 27.9 |
| 0.716 | 0.593 | 60.3 | 28.9 |
图 11
3.3.4. 消融实验
为了全面评估所提改进策略对模型性能的综合影响,在RT-DETR模型的基础上执行一系列消融实验,模型评估指标包括mAP@0.5、mAP@0.50−0.95、模型参数量Np及FPS,旨在从精度、模型复杂度和检测速度3个维度分析. 消融实验结果通过表6展现,其中“×”表示相应的模块未被集成于模型中,“√”表示相应的模块已被纳入模型,实验结果揭示了各改进模块对模型检测性能的提升. 实验结果表明,PConv和EMA注意力机制使得模型的特征提取能力得到增强;集成S2小目标检测层及使用MSFF、MFE替代原有特征融合结构,使得模型在降低参数量的基础上,性能得到提升. 综合所有改进模块后的新模型,与原模型相比,mAP@0.5提升了5.6个百分点,mAP@0.50−0.95提升了3.8个百分点,同时参数量减少40.1%,FPS指标仍满足实时要求. 实验数据表明,改进后的模型在预测准确率指标上实现了显著性提升,参数量的大幅度降低证明了轻量化部署的可行性.
表 6 改进模块消融实验结果
Tab.6
| 检测模型 | PEBlock-EMA | MSFF-MFE | Deformable Attention | |||||
| Model1 | 54.7 | 25.1 | 1.988 | 57.1 | ||||
| Model3 | √ | 59.2 | 28.4 | 1.690 | 39.5 | |||
| Model4 | √ | √ | 58.7 | 28.8 | 1.190 | 35.2 | ||
| Model5 | √ | √ | √ | 60.0 | 28.6 | 1.190 | 37.4 | |
| Model6 (本研究模型) | √ | √ | √ | √ | 60.3 | 28.9 | 1.190 | 37.1 |
3.3.5. 模型特征可视
为了更加直观地观察到Deformable Attention对于疵点识别能力的提升,采用Grad-CAM[21](gradient-weighted class activation mapping)方法对模型所提取的目标域特征进行可视化. Grad-CAM利用训练权重反向传播,将得到的梯度矩阵进行空间维度全局平均池化,并对特征层的各通道进行加权激活,最终得到热力图,图中某一区域的亮度变化直观表征了图像区域对模型预测结果的影响权重差异. 替换Deformable Attention前、后的热力图如图12所示.与如图12(b)所示未替换Deformable Attention的热力图结果相比,图12(c)的疵点处颜色更亮,完整地关注到了疵点处,可见替换Deformable Attention后,模型对于疵点的感知加强,能更准确地关注到疵点特征.
图 12

3.3.6. 模型对比实验
为了综合评估本研究方法在精确识别纺织品表面疵点方面的性能表现,将其与YOLOv5和YOLOv8目标检测算法进行对比实验,同时将DETR的检测头成功地移植到YOLO模型上,来验证DETR将目标检测任务视为二分问题的优势,实验结果如表7所示. 可以看出,将YOLO系列的检测头替换为DETR的检测头后,检测准确率均有提升,同时RT-DETR模型的精度仍高于YOLO系列检测模型的,证明了DETR检测头的先进性.
表 7 本研究模型与已有模型的对比实验
Tab.7
| 算法模型 | ||||
| YOLOv5m | 50.5 | 21.1 | 62.3 | 2.504 |
| YOLOv8m | 50.1 | 21.4 | 64.5 | 2.584 |
| YOLOv5m-DETR | 52.7 | 23.8 | 55.2 | 2.490 |
| YOLOv8m-DETR | 53.2 | .23.9 | 61.2 | 2.608 |
| RT-DETR | 54.7 | 25.1 | 57.1 | 1.988 |
| 本研究方法 | 60.3 | 28.9 | 37.4 | 1.190 |
3.3.7. 模型改进效果的对比图
如图13所示为RT-DETR-R18模型改进前、后的疵点检测对比图. 可以看出,改进后的RT-DETR模型在检测精确度上有提升,同时也避免了一定的漏检与误检.
图 13

图 13 RT-DETR 改进前后的疵点检测结果对比图
Fig.13 Comparison of defect detection results before and after RT-DETR improvement
3.3.8. TILDA数据集缺陷检测实验
为了验证改进后的RT-DETR算法在不同数据集上的对比结果,将改进前、后的RT-DETR算法在公开的TILDA织物缺陷数据集上进行对比实验,选取破洞、污渍这2类缺陷,通过对比改进前、后的算法对缺陷的检测能力,验证了改进后的算法在不同数据集下对小缺陷目标的检测能力有一定的提升.
如表8所示,与原始的RT-DETR模型相比,改进模型在破洞、污渍这2种缺陷上的mAP@0.5分别提高4.8和3.0个百分点,证明改进算法在不同数据集下对小目标缺陷检测的性能有一定提升.
表 8 TILDA数据集缺陷检测实验结果
Tab.8
| 模型 | mAP@0.5/% | |
| 破洞 | 污渍 | |
| RT-DETR-R18 | 92.9 | 93.2 |
| 本研究方法 | 97.7 | 96.2 |
3.3.9. 硅钢带的微观表面缺陷检测实验
图 14

图 14 硅钢带的微观表面缺陷示意图
Fig.14 Schematic diagram of microscopic surface defects of silicon steel strip
表 9 硅钢带的微观表面缺陷检测实验
Tab.9
| 模型 | mAP@0.5/% | mAP@0.50−0.95/% |
| RT-DETR-R18 | 90.2 | 39.8 |
| 本研究方法 | 92.3 | 41.5 |
4. 结 论
(1) 利用部分卷积(PConv)减少冗余的计算,引入EMA注意力机制来提升重要特征的权重,提高小目标检测的精度.
(2) 在添加S2特征层的基础上,提出MFE和MSFF模块,增强同级尺度特征和非同级尺度特征的多级融合.
(3) 使用Deformable Attention替换传统的多头注意力机制,使模型可以更好地适应面料疵点的形变,泛化力得到提升.
(4) 优化边界框损失函数,采用NWD结合CIoU的联合损失函数来代替原模型中的GIoU损失函数,在加速模型收敛的同时,提高了检测的精度.
(5) 采用改进算法,在牛仔布缺陷数据集上进行实验. 与原始RT-DETR-R18相比,改进算法在mAP@0.5和mAP@0.50−0.95上分别提升了5.6和3.8个百分点,模型的总参数量下降了40.1%. 为了证明改进后的算法对复杂背景图案的小目标缺陷的检测能力提升的普适性,在TILDA数据集和硅钢带的微观表面数据集上进行实验,结果证明改进算法对面料缺陷检测性能有较大的提升.
(6) 在加深网络结构后,检测的帧率有所下降,后续可考虑采用剪枝操作去除不必要的通道,降低网络负担,提高检测速度,同时继续面向其他种类缺陷开展复杂纹理下的缺陷识别研究.
参考文献
基于改进的加权中值滤波与K-means聚类的织物缺陷检测
[J].
Fabric defect detection method based on improved fast weighted Median filtering and K-means
[J].
基于奇异值分解的双算法织物缺陷检测
[J].
Dual-algorithm for fabric defect detection based on singular value decomposition
[J].
应用上下文视觉显著性的色织物疵点检测
[J].
Yarn-dyed fabric defect detection based on context visual saliency
[J].
基于改进Itti显著模型的织物疵点实时检测
[J].
Real-time detection of fabric defects based on use of improved Itti salient model
[J].
基于改进YOLOv8s的鼓形滚子表面缺陷检测算法
[J].
Drum roller surface defect detection algorithm based on improved YOLOv8s
[J].
基于分割注意力与线性变换的轻量化目标检测
[J].
Lightweight object detection based on split attention and linear transformation
[J].
PRC-light YOLO: an efficient lightweight model for fabric defect detection
[J].DOI:10.3390/app14020938 [本文引用: 1]
Haar wavelet downsampling: a simple but effective downsampling module for semantic segmentation
[J].DOI:10.1016/j.patcog.2023.109819 [本文引用: 1]
Grad-CAM: visual explanations from deep networks via gradient-based localization
[J].DOI:10.1007/s11263-019-01228-7 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}