[1]
吴迪, 朱青松 图像去雾的最新研究进展
[J]. 自动化学报 , 2015 , 41 (2 ): 221 - 239
[本文引用: 1]
WU Di, ZHU Qingsong The latest research progress of image dehazing
[J]. Acta Automatica Sinica , 2015 , 41 (2 ): 221 - 239
[本文引用: 1]
[2]
TAREL J P, HAUTIÈRE N. Fast visibility restoration from a single color or gray level image [C]// IEEE 12th International Conference on Computer Vision . Kyoto: IEEE, 2009: 2201–2208.
[本文引用: 1]
[3]
MENG G, WANG Y, DUAN J, et al. Efficient image dehazing with boundary constraint and contextual regularization [C]// IEEE International Conference on Computer Vision . Sydney: IEEE, 2013: 617–624.
[4]
覃宏超, 李炎炎, 龙伟, 等 基于引导滤波和暗原色先验理论透射率估值的视频去雾算法
[J]. 浙江大学学报: 工学版 , 2018 , 52 (7 ): 1302 - 1309
[本文引用: 1]
QIN Hongchao, LI Yanyan, LONG Wei, et al Real-time video dehazing using guided filtering and transmissivity estimated based on dark channel prior theory
[J]. Journal of Zhejiang University: Engineering Science , 2018 , 52 (7 ): 1302 - 1309
[本文引用: 1]
[5]
NAYAR S K, NARASIMHAN S G. Vision in bad weather [C]// 7th IEEE International Conference on Computer Vision . Kerkyra: IEEE, 1999: 820–827.
[本文引用: 1]
[6]
NARASIMHAN S G, NAYAR S K. Removing weather effects from monochrome images [C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition . Kauai: IEEE, 2001: II.
[本文引用: 1]
[7]
LIHE Z, HE J, YUAN Q, et al PhDnet: a novel physic-aware dehazing network for remote sensing images
[J]. Information Fusion , 2024 , 106 : 102277
DOI:10.1016/j.inffus.2024.102277
[本文引用: 1]
[8]
HE K, SUN J, TANG X. Single image haze removal using dark channel prior [C]// IEEE Conference on Computer Vision and Pattern Recognition . Miami: IEEE, 2009: 1956–1963.
[9]
ZHU Q, MAI J, SHAO L A fast single image haze removal algorithm using color attenuation prior
[J]. IEEE Transactions on Image Processing , 2015 , 24 (11 ): 3522 - 3533
DOI:10.1109/TIP.2015.2446191
[本文引用: 2]
[10]
CAI B, XU X, JIA K, et al DehazeNet: an end-to-end system for single image haze removal
[J]. IEEE Transactions on Image Processing , 2016 , 25 (11 ): 5187 - 5198
[本文引用: 4]
[11]
LI B, PENG X, WANG Z, et al. AOD-net: all-in-one dehazing network [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 4780–4788.
[本文引用: 4]
[12]
HE K, SUN J, TANG X Guided image filtering
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2013 , 35 (6 ): 1397 - 1409
DOI:10.1109/TPAMI.2012.213
[本文引用: 2]
[14]
JU M, DING C, GUO Y J, et al IDGCP: image dehazing based on gamma correction prior
[J]. IEEE Transactions on Image Processing , 2019 , 29 : 3104 - 3118
[本文引用: 1]
[15]
ZHANG J, TAO D FAMED-net: a fast and accurate multi-scale end-to-end dehazing network
[J]. IEEE Transactions on Image Processing , 2020 , 29 : 72 - 84
DOI:10.1109/TIP.2019.2922837
[本文引用: 1]
[16]
REN W, MA L, ZHANG J, et al. Gated fusion network for single image dehazing [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 3253–3261.
[本文引用: 1]
[17]
LIU X, MA Y, SHI Z, et al. GridDehazeNet: attention-based multi-scale network for image dehazing [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 7313–7322.
[本文引用: 1]
[18]
DAS S D, DUTTA S. Fast deep multi-patch hierarchical network for nonhomogeneous image dehazing [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Seattle: IEEE, 2020: 1994–2001.
[本文引用: 1]
[19]
BALLA P K, KUMAR A, PANDEY R A 4-channelled hazy image input generation and deep learning-based single image dehazing
[J]. Journal of Visual Communication and Image Representation , 2024 , 100 : 104099
DOI:10.1016/j.jvcir.2024.104099
[本文引用: 1]
[20]
QIN X, WANG Z, BAI Y, et al FFA-net: feature fusion attention network for single image dehazing
[J]. AAAI Conference on Artificial Intelligence , 2020 , 34 (7 ): 11908 - 11915
DOI:10.1609/aaai.v34i07.6865
[本文引用: 2]
[21]
SHAO Y, LI L, REN W, et al. Domain adaptation for image dehazing [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2805–2814.
[本文引用: 1]
[22]
SONG Y, HE Z, QIAN H, et al Vision transformers for single image dehazing
[J]. IEEE Transactions on Image Processing , 2023 , 32 : 1927 - 1941
DOI:10.1109/TIP.2023.3256763
[本文引用: 2]
[23]
YU Y, ZHANG Y, CHENG Z, et al MCA: multidimensional collaborative attention in deep convolutional neural networks for image recognition
[J]. Engineering Applications of Artificial Intelligence , 2023 , 126 : 107079
DOI:10.1016/j.engappai.2023.107079
[本文引用: 1]
[24]
ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2472–2481.
[本文引用: 1]
[25]
YAN Q, GONG D, SHI Q, et al. Attention-guided network for ghost-free high dynamic range imaging [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1751–1760.
[本文引用: 1]
[26]
杨爱萍, 刘瑾, 邢金娜, 等 基于内容特征和风格特征融合的单幅图像去雾网络
[J]. 自动化学报 , 2023 , 49 (4 ): 769 - 777
[本文引用: 1]
YANG Aiping, LIU Jin, XING Jinna, et al Content feature and style feature fusion network for single image dehazing
[J]. Acta Automatica Sinica , 2023 , 49 (4 ): 769 - 777
[本文引用: 1]
[27]
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity
[J]. IEEE Transactions on Image Processing , 2004 , 13 (4 ): 600 - 612
DOI:10.1109/TIP.2003.819861
[本文引用: 1]
[28]
HE T, ZHANG Z, ZHANG H, et al. Bag of tricks for image classification with convolutional neural networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 558–567.
[本文引用: 1]
[29]
KINGMA D P, BA J, HAMMAD M M. Adam: a method for stochastic optimization [EB/OL]. (2014−12−22)[2024−02−03]. https://arxiv.org/abs/1412.6980v9.
[本文引用: 1]
[30]
LI B, REN W, FU D, et al Benchmarking single image dehazing and beyond
[J]. IEEE Transactions on Image Processing , 2018 , 1 : 492 - 505
[本文引用: 2]
[31]
MANNOS J, SAKRISON D The effects of a visual fidelity criterion of the encoding of images
[J]. IEEE Transactions on Information Theory , 1974 , 20 (4 ): 525 - 536
DOI:10.1109/TIT.1974.1055250
[本文引用: 1]
[32]
ZHANG Y, DING L, SHARMA G. HazeRD: an outdoor scene dataset and benchmark for single image dehazing [C]// IEEE International Conference on Image Processing . Beijing: IEEE, 2017: 3205–3209.
[本文引用: 1]
[33]
CHEN D, HE M, FAN Q, et al. Gated context aggregation network for image dehazing and deraining [C]// IEEE Winter Conference on Applications of Computer Vision . Waikoloa Village: IEEE, 2019: 1375–1383.
[本文引用: 1]
[34]
ZHENG Z, REN W, CAO X, et al. Ultra-high-definition image dehazing via multi-guided bilateral learning [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 16180–16189.
[本文引用: 1]
[35]
BAI H, PAN J, XIANG X, et al Self-guided image dehazing using progressive feature fusion
[J]. IEEE Transactions on Image Processing , 2022 , 31 : 1217 - 1229
DOI:10.1109/TIP.2022.3140609
[本文引用: 1]
[36]
CHEN Z, HE Z, LU Z M DEA-net: single image dehazing based on detail-enhanced convolution and content-guided attention
[J]. IEEE Transactions on Image Processing , 2024 , 33 : 1002 - 1015
DOI:10.1109/TIP.2024.3354108
[本文引用: 1]
图像去雾的最新研究进展
1
2015
... 雾是一种常见的天气现象,它会导致相机所拍摄的图像模糊、对比度下降,边缘信息丢失,从而影响后续的高级视觉任务(如目标检测和分割、自动驾驶、地图测绘等[1 ] ). 因此,单幅图像去雾是重要的研究课题. ...
图像去雾的最新研究进展
1
2015
... 雾是一种常见的天气现象,它会导致相机所拍摄的图像模糊、对比度下降,边缘信息丢失,从而影响后续的高级视觉任务(如目标检测和分割、自动驾驶、地图测绘等[1 ] ). 因此,单幅图像去雾是重要的研究课题. ...
1
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
基于引导滤波和暗原色先验理论透射率估值的视频去雾算法
1
2018
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
基于引导滤波和暗原色先验理论透射率估值的视频去雾算法
1
2018
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
1
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
1
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
PhDnet: a novel physic-aware dehazing network for remote sensing images
1
2024
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
A fast single image haze removal algorithm using color attenuation prior
2
2015
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
... He等[12 ] 通过对大量无雾图像的观察,提出暗通道先验理论(dark channel prior, DCP)估计透射率,再通过大气散射模型恢复清晰图像. 为了减少暗通道算法的处理时间,张登银等[13 ] 用“边缘替代法”替换“软抠图”,在解决天空区域暗通道先验失效的同时,大幅降低单幅图像的去雾时间. Zhu等[9 ] 对大量有雾图像的远近景进行分析,建立颜色衰减先验模型(color attenuation prior, CAP)来估计透射率,提出依场景深度变化估计雾浓度的去雾方法,改善近景颜色失真的情况. Ju等[14 ] 提出伽马校正先验(gamma correction prior,GCP)来估计有雾图像的均匀虚拟变换和深度信息,再通过大气散射理论恢复清晰图像. 上述基于先验的去雾方法能在特定场景下取得良好的去雾效果,但当先验条件不合适时,其结果往往较差. ...
DehazeNet: an end-to-end system for single image haze removal
4
2016
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
... [10 ]结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...
4
... 在深度学习兴起之前,大部分有雾图像恢复算法[2 -4 ] 基于物理模型−大气散射模型[5 -6 ] . 多数去雾算法[7 -9 ] 以先验知识为基础,结合大气散射模型取得了良好的性能,但在复杂环境中,透射率和大气光值估计不准确会导致去雾结果不理想. 随着深度学习兴起,研究者们用神经网络学习透射率和大气光值[10 -11 ] ,再结合大气散射模型恢复清晰图像. 这类方法须利用有雾图像和对应的透射率图像作为样本对训练网络,但是实际有雾图像的透射率和透射率标签图像存在偏差,影响去雾算法的效果. 为了将图像去雾从物理模型中分离出来,研究者们设计去雾网络模型,直接学习有雾图像与清晰图像之间的映射关系,实现端到端去雾. 但是,现有去雾算法忽略了模糊图像的内容细节和边缘信息是不同特征,影响有雾图像恢复的最终效果. ...
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
... [11 ]改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...
Guided image filtering
2
2013
... He等[12 ] 通过对大量无雾图像的观察,提出暗通道先验理论(dark channel prior, DCP)估计透射率,再通过大气散射模型恢复清晰图像. 为了减少暗通道算法的处理时间,张登银等[13 ] 用“边缘替代法”替换“软抠图”,在解决天空区域暗通道先验失效的同时,大幅降低单幅图像的去雾时间. Zhu等[9 ] 对大量有雾图像的远近景进行分析,建立颜色衰减先验模型(color attenuation prior, CAP)来估计透射率,提出依场景深度变化估计雾浓度的去雾方法,改善近景颜色失真的情况. Ju等[14 ] 提出伽马校正先验(gamma correction prior,GCP)来估计有雾图像的均匀虚拟变换和深度信息,再通过大气散射理论恢复清晰图像. 上述基于先验的去雾方法能在特定场景下取得良好的去雾效果,但当先验条件不合适时,其结果往往较差. ...
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...
一种基于暗通道先验的快速图像去雾算法
1
2015
... He等[12 ] 通过对大量无雾图像的观察,提出暗通道先验理论(dark channel prior, DCP)估计透射率,再通过大气散射模型恢复清晰图像. 为了减少暗通道算法的处理时间,张登银等[13 ] 用“边缘替代法”替换“软抠图”,在解决天空区域暗通道先验失效的同时,大幅降低单幅图像的去雾时间. Zhu等[9 ] 对大量有雾图像的远近景进行分析,建立颜色衰减先验模型(color attenuation prior, CAP)来估计透射率,提出依场景深度变化估计雾浓度的去雾方法,改善近景颜色失真的情况. Ju等[14 ] 提出伽马校正先验(gamma correction prior,GCP)来估计有雾图像的均匀虚拟变换和深度信息,再通过大气散射理论恢复清晰图像. 上述基于先验的去雾方法能在特定场景下取得良好的去雾效果,但当先验条件不合适时,其结果往往较差. ...
一种基于暗通道先验的快速图像去雾算法
1
2015
... He等[12 ] 通过对大量无雾图像的观察,提出暗通道先验理论(dark channel prior, DCP)估计透射率,再通过大气散射模型恢复清晰图像. 为了减少暗通道算法的处理时间,张登银等[13 ] 用“边缘替代法”替换“软抠图”,在解决天空区域暗通道先验失效的同时,大幅降低单幅图像的去雾时间. Zhu等[9 ] 对大量有雾图像的远近景进行分析,建立颜色衰减先验模型(color attenuation prior, CAP)来估计透射率,提出依场景深度变化估计雾浓度的去雾方法,改善近景颜色失真的情况. Ju等[14 ] 提出伽马校正先验(gamma correction prior,GCP)来估计有雾图像的均匀虚拟变换和深度信息,再通过大气散射理论恢复清晰图像. 上述基于先验的去雾方法能在特定场景下取得良好的去雾效果,但当先验条件不合适时,其结果往往较差. ...
IDGCP: image dehazing based on gamma correction prior
1
2019
... He等[12 ] 通过对大量无雾图像的观察,提出暗通道先验理论(dark channel prior, DCP)估计透射率,再通过大气散射模型恢复清晰图像. 为了减少暗通道算法的处理时间,张登银等[13 ] 用“边缘替代法”替换“软抠图”,在解决天空区域暗通道先验失效的同时,大幅降低单幅图像的去雾时间. Zhu等[9 ] 对大量有雾图像的远近景进行分析,建立颜色衰减先验模型(color attenuation prior, CAP)来估计透射率,提出依场景深度变化估计雾浓度的去雾方法,改善近景颜色失真的情况. Ju等[14 ] 提出伽马校正先验(gamma correction prior,GCP)来估计有雾图像的均匀虚拟变换和深度信息,再通过大气散射理论恢复清晰图像. 上述基于先验的去雾方法能在特定场景下取得良好的去雾效果,但当先验条件不合适时,其结果往往较差. ...
FAMED-net: a fast and accurate multi-scale end-to-end dehazing network
1
2020
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
1
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
1
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
1
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
A 4-channelled hazy image input generation and deep learning-based single image dehazing
1
2024
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
FFA-net: feature fusion attention network for single image dehazing
2
2020
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
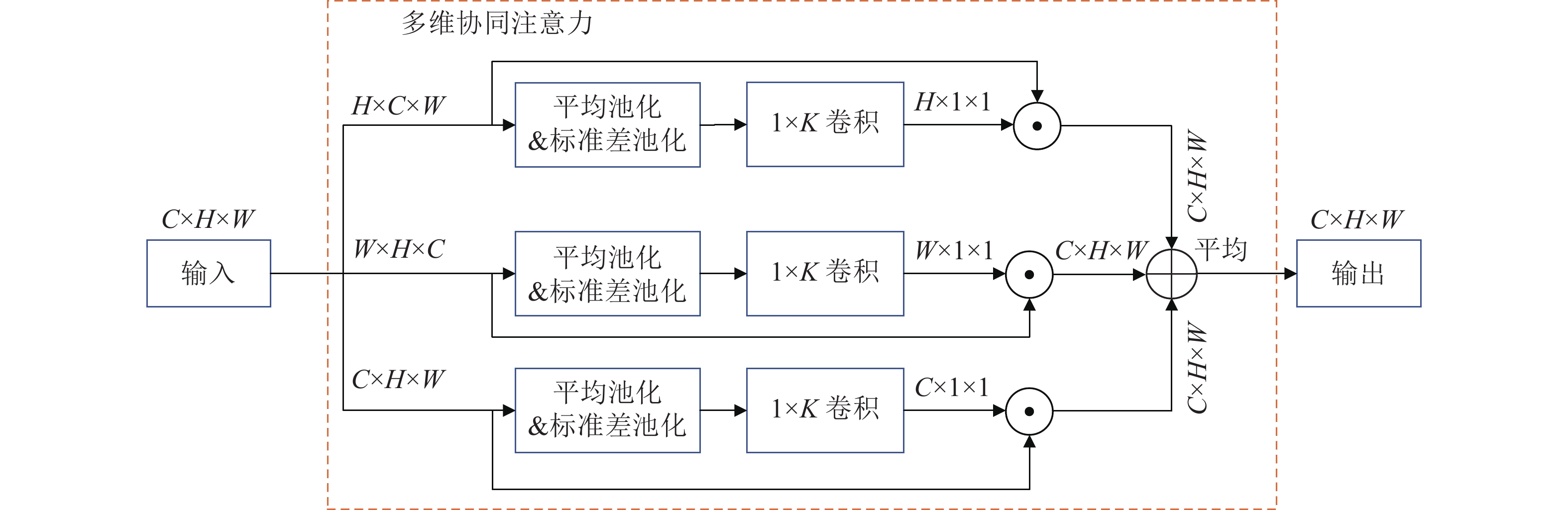
... 与文献[20 ]中的通道注意力和像素注意力不同,多维协同注意力(MCA)能够在空间和通道维度上同时建模,实现特征信息交互,使网络模型对有雾图像中的重要特征进行权重标定. 如图3 所示,多维协同注意力由并行的3个分支组成,其中最上面2个分支负责空间维度上的特征相互依赖关系,最后1个分支用于捕获通道间的重要程度. 具体过程如下:将上一层的输出特征图$ {\boldsymbol{F}} \in {{\bf{R}}^{{{C}} \times {{H}} \times {{W}}}} $ $ {{C}} $ $ {{H}} $ $ {{W}} $ $ {\boldsymbol{F}} $ $ {{W}} \times {{H}} \times {{C}} $ $ {{H}} \times {{C}} \times {{W}} $ $ {{C}} \times H \times W $ $ {{H}} \times 1 \times 1 $ $ {{W}} \times 1 \times 1 $ $ {{C}} \times 1 \times 1 $
1
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
Vision transformers for single image dehazing
2
2023
... 基于深度学习的单幅图像去雾算法主要分为2类:结合模型的方法和非结合模型的方法. 早期的方法[10 -11 ,15 ] 主要通过神经网络估计透射率和大气光值,再结合大气散射模型实现图像去雾. Cai等[10 ] 结合现有的先验理论提出DehazeNet来估计有雾图像的透射率. Li等[11 ] 改写大气散射模型,构建级联的轻型去雾网络估计联合参数,最后借助大气散射模型输出清晰图像. 上述早期基于深度学习的方法依旧须依靠大气散射模型,存在一定的局限性,并且容易造成误差累积导致去雾不彻底. 非结合模型的方法[16 -19 ] 通过神经网络学习有雾图像与清晰图像的映射关系,实现图像去雾. Liu等[17 ] 提出由预处理模块、主干模块和后处理模块组成的网格去雾网络GridDehazeNet. Das等[18 ] 针对非均匀有雾图像,提出快速深度分层网络,该网络能够快速恢复浓度分布不均匀的有雾图像. Qin等[20 ] 提出特征融合注意力图像去雾网络FFA-Net(feature fusion attention network),该网络通过注意力机制在通道维度和像素维度实现不同特征层的权重标定以实现图像去雾. Shao等[21 ] 通过1个图像迁移模块和2个图像去雾模块的组合提出域适应模型,实现有雾图像与清晰图像的映射. Song等[22 ] 将视觉Transformer机制用于图像去雾任务,以多头自注意力机制为基础,对雾特征的全局依赖关系建模,最终实现复杂有雾场景的复原. 上述端到端的方法能在一定程度上去除雾气,但是会对图像中的边缘细节一同去除,不能够保持原有的纹理细节. 针对以上问题,提出基于多维协同注意力的双支特征联合去雾网络,从内容特征提取和边缘细节恢复2个角度出发,实现恢复纹理细节更完整的清晰图像. ...
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...
MCA: multidimensional collaborative attention in deep convolutional neural networks for image recognition
1
2023
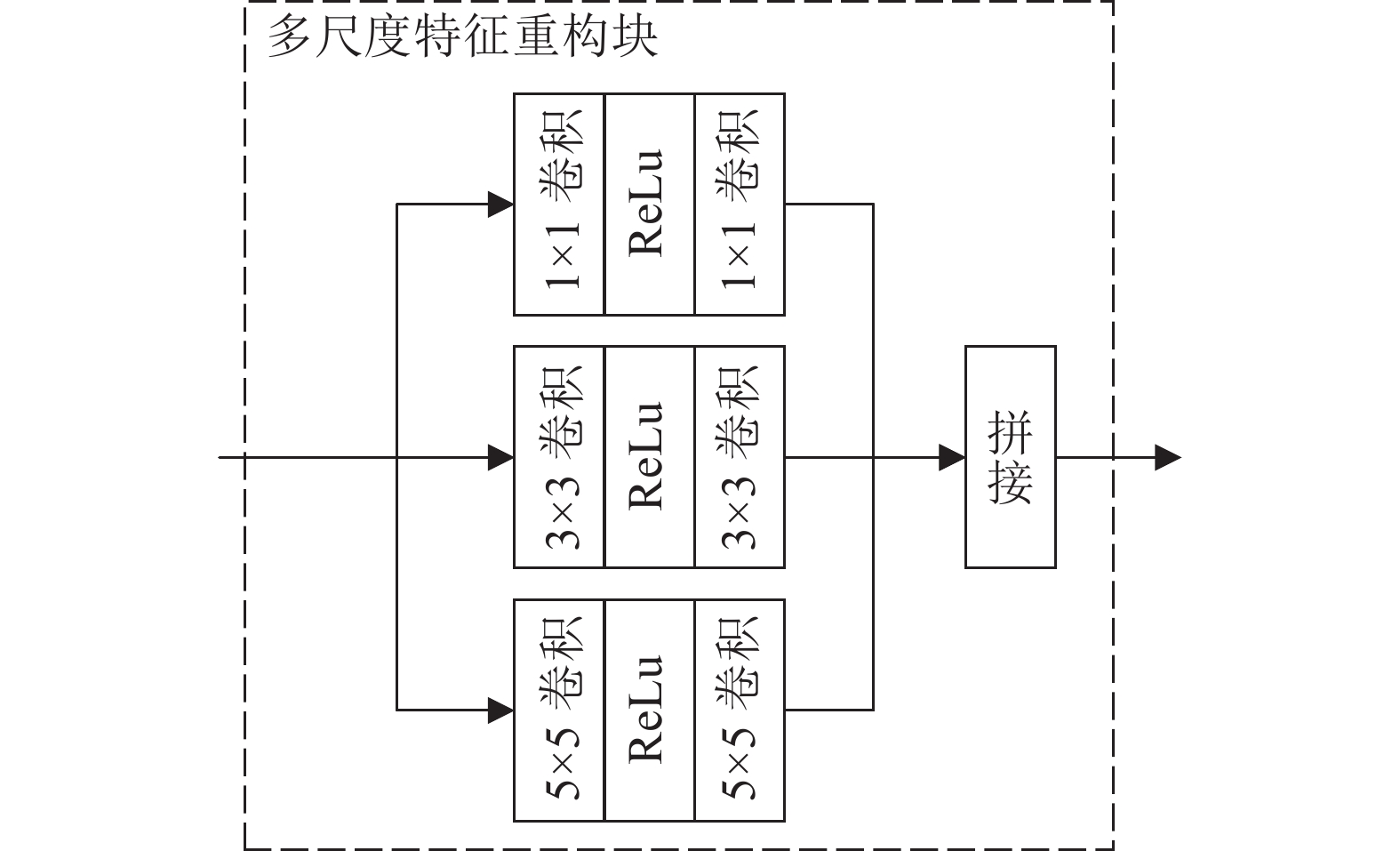
... 场景中的雾弱化了图像中颜色和场景语义深层的内容信息,为了深层次提取有雾图像的内容信息,设计以空洞卷积残差密集块(DRDB)和多维协同注意力(multidimensional collaborative attention,MCA)[23 ] 的串联组合为核心的内容信息提取模块. 首先用1×1卷积对有雾图像进行通道变换,然后通过3个连续的DRDB-MCA块,得到含有初级内容信息的特征图. ...
1
... 密集残差块[24 ] 通过密集连接的卷积层,充分利用所有层的层次特征,以提取有雾图像中丰富的局部特征. 图像去雾任务须从图像整个场景中获得足够的位置和方向信息,需要更大的感受野来提取有雾图像的特征,但是通过较大的卷积核来扩大感受野会降低模型的运行效率. 本研究用空洞卷积[25 ] 替代普通卷积,在卷积核中的相邻元素间插入不同数量的“0”来实现不同的感受野,如图2 所示. 每个空洞卷积密集残差块的结构相同,均包含4个卷积层,在每个卷积层后使用ReLu激活函数. 其中,前3个卷积层是3×3的空洞卷积,膨胀率分别设置为1、2、3,第4个卷积层的卷积核大小为1×1. 每个卷积层都将来自前一层的所有特征作为输入,以整体的方式自适应地学习图像的全局层次特征. 同时,这种残差结构有益于网络的收敛. ...
1
... 密集残差块[24 ] 通过密集连接的卷积层,充分利用所有层的层次特征,以提取有雾图像中丰富的局部特征. 图像去雾任务须从图像整个场景中获得足够的位置和方向信息,需要更大的感受野来提取有雾图像的特征,但是通过较大的卷积核来扩大感受野会降低模型的运行效率. 本研究用空洞卷积[25 ] 替代普通卷积,在卷积核中的相邻元素间插入不同数量的“0”来实现不同的感受野,如图2 所示. 每个空洞卷积密集残差块的结构相同,均包含4个卷积层,在每个卷积层后使用ReLu激活函数. 其中,前3个卷积层是3×3的空洞卷积,膨胀率分别设置为1、2、3,第4个卷积层的卷积核大小为1×1. 每个卷积层都将来自前一层的所有特征作为输入,以整体的方式自适应地学习图像的全局层次特征. 同时,这种残差结构有益于网络的收敛. ...
基于内容特征和风格特征融合的单幅图像去雾网络
1
2023
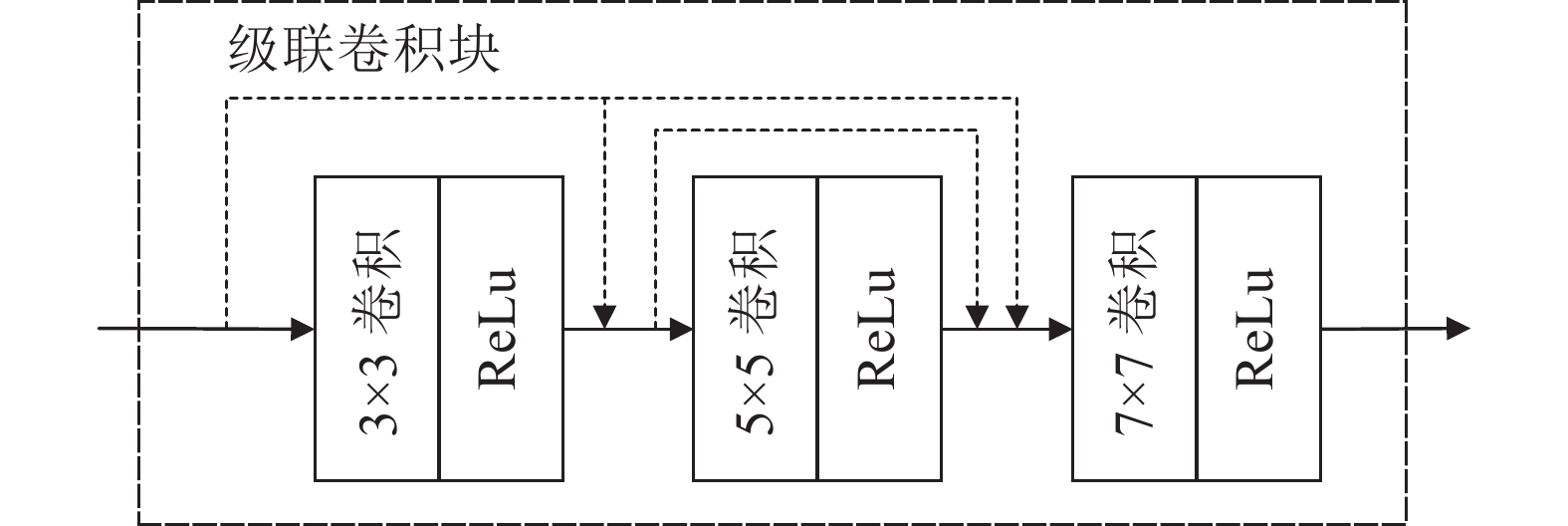
... 边缘细节信息属于图像的局部特征[26 ] ,主要是图像中结构的轮廓细节,所含语义较低,较容易恢复. 因此,设计轻便、多尺度特征提取模块−级联卷积块(cascaded convolutional block,CCB)用于恢复图像的边缘细节,如图4 所示. 级联卷积块是由3个尺寸分别为3、5、7的卷积层构成,在每层卷积之后连接一个ReLU激活函数,下一层的输入特征图由前置所有网络的特征输出融合而生成,既能在最大尺度上保留每一层提取的边缘特征,又能通过级联连接捕获上下文融合边缘信息. ...
基于内容特征和风格特征融合的单幅图像去雾网络
1
2023
... 边缘细节信息属于图像的局部特征[26 ] ,主要是图像中结构的轮廓细节,所含语义较低,较容易恢复. 因此,设计轻便、多尺度特征提取模块−级联卷积块(cascaded convolutional block,CCB)用于恢复图像的边缘细节,如图4 所示. 级联卷积块是由3个尺寸分别为3、5、7的卷积层构成,在每层卷积之后连接一个ReLU激活函数,下一层的输入特征图由前置所有网络的特征输出融合而生成,既能在最大尺度上保留每一层提取的边缘特征,又能通过级联连接捕获上下文融合边缘信息. ...
Image quality assessment: from error visibility to structural similarity
1
2004
... 结构相似性(structural similarity,SSIM)[27 ] 是衡量2幅图像相似程度的指标,SSIM越大,表明2幅图像的相似度越高,其表达式如下: ...
1
... 使用Pytorch框架实现网络模型,实验硬件环境为Intel(R) Core(TM) i7-10750H CPU 2.60 GHz,显卡型号NVIDIA GeForce GTX 1650 ,内存为4 GB,操作系统为Windows11. 初始学习率为10−4 ,并采用余弦退火策略[28 ] 调整学习率. 使用Adam优化器[29 ] ($ {\beta _1} $ $ {\beta _2} $
1
... 使用Pytorch框架实现网络模型,实验硬件环境为Intel(R) Core(TM) i7-10750H CPU 2.60 GHz,显卡型号NVIDIA GeForce GTX 1650 ,内存为4 GB,操作系统为Windows11. 初始学习率为10−4 ,并采用余弦退火策略[28 ] 调整学习率. 使用Adam优化器[29 ] ($ {\beta _1} $ $ {\beta _2} $
Benchmarking single image dehazing and beyond
2
2018
... 本研究所提网络将有雾图像和对应的边缘图像作为网络的输入,用清晰图像和清晰图像的边缘图作为标签进行反向传播. 从公共数据集RESIDE的室外训练集(outdoor training set,OTS)和室内训练集(indoor training set,ITS)[30 ] 中选取30000 幅合成图像,按9∶1的比例进行划分,分别作为网络模型训练阶段和测试阶段的数据集. 首先对数据集进行预处理,用Sobel算子得到有雾图像数据集对应的边缘图像,然后将有雾图像和对应边缘图像作为网络训练的输入. ...
... 对不同模型在RESIDE SOTS-outdoor测试集[30 ] 的峰值信噪比(peak signal-to-noise ratio,PSNR)[31 ] 、结构相似度SSIM和参数量M 进行比较. 其中,SSIM是衡量2幅图像相似度的指标,其值越大表明去雾结果越接近真实的清晰图像;PSNR是衡量图像失真或噪声水平的指标,其值越高说明去雾结果效果越好;参数量越大,表明模型越复杂. 如表1 所示,当DRDB的数量为3、5和7时,PSNR和SSIM指标接近,但是参数量却成倍增加. 在加入边缘细节恢复分支和多维协同注意力机制后,客观指标和去雾效果均明显提升. 当边缘细节恢复分支输入仅为有雾图像时,客观指标明显降低,主观效果上色彩偏暗纹理较模糊,如图6 和表1 所示. ...
The effects of a visual fidelity criterion of the encoding of images
1
1974
... 对不同模型在RESIDE SOTS-outdoor测试集[30 ] 的峰值信噪比(peak signal-to-noise ratio,PSNR)[31 ] 、结构相似度SSIM和参数量M 进行比较. 其中,SSIM是衡量2幅图像相似度的指标,其值越大表明去雾结果越接近真实的清晰图像;PSNR是衡量图像失真或噪声水平的指标,其值越高说明去雾结果效果越好;参数量越大,表明模型越复杂. 如表1 所示,当DRDB的数量为3、5和7时,PSNR和SSIM指标接近,但是参数量却成倍增加. 在加入边缘细节恢复分支和多维协同注意力机制后,客观指标和去雾效果均明显提升. 当边缘细节恢复分支输入仅为有雾图像时,客观指标明显降低,主观效果上色彩偏暗纹理较模糊,如图6 和表1 所示. ...
1
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...
1
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...
1
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...
Self-guided image dehazing using progressive feature fusion
1
2022
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...
DEA-net: single image dehazing based on detail-enhanced convolution and content-guided attention
1
2024
... 为了验证所提算法的有效性,在测试集SOTS-outdoor、SOTS-indoor和HazeRD[32 ] 上与经典的去雾算法进行去雾效果比较. 经典算法包括DCP[12 ] 、DehazeNet[10 ] 、AOD-Net[11 ] 、GCA-Net[33 ] 、UHD[34 ] 、SGID[35 ] 、DehazeFormer[22 ] 和DEA-Net[36 ] . ...












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}