Person re-identification method based on multi-part guided foreground enhancement
LIU Junjing,, ZHENG Wanlu, GUO Ziqiang, WANG Shaorong,
1. School of Information Science and Technology, Beijing Forest University, Beijing 100083, China
2. Engineering Research Center for Forestry-oriented Intelligent Information Processing of National Forestry and Grassland Administration, Beijing 100083, China
3. Beijing Virtual Simulation and Visualization Engineering Center, Beijing 100871, China
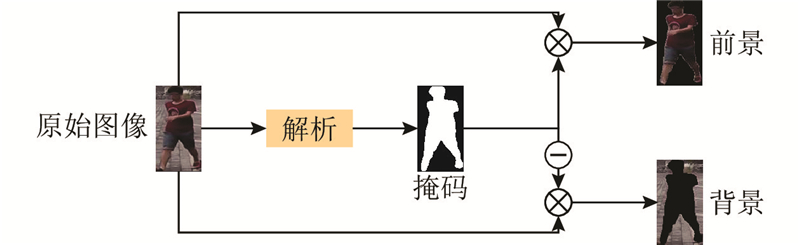
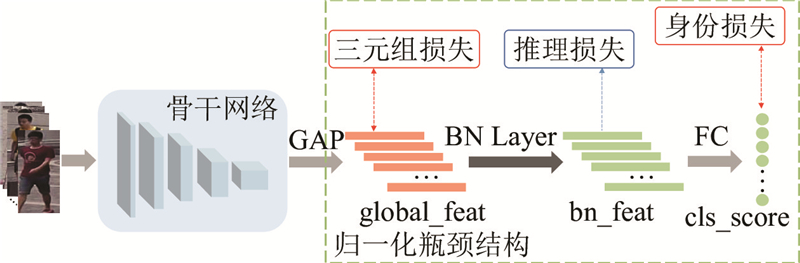
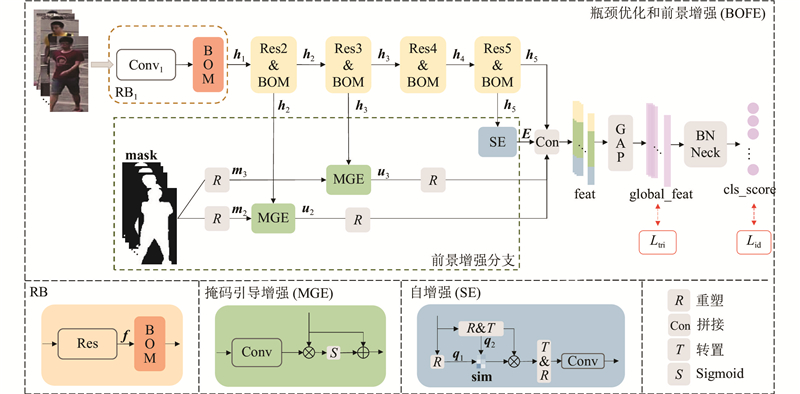
A multi-part guided foreground enhancement method for person re-identification was proposed in order to solve the problem that the performance of person re-identification model was overly depend on background environmental factors. The model’s attention to the person’s foreground was enhanced by employing mask-guided enhancement and self-enhancement strategies, while retaining some background information. This effectively reduced the model’s dependence on background information and improved its generalization ability. A bottleneck optimization module was integrated into the backbone network, utilizing dilated convolutions to enlarge the model’s receptive field while maintaining the original parameter scale, thereby improving the overall performance of the model. The experimental results demonstrated that the proposed model achieved Rank-1 accuracies of 95% and 88.3% on the Market1501 and DukeMTMC_reID datasets, respectively. The effectiveness of the multi-part guided foreground enhancement method was verified, which strengthened the foreground while incorporating appropriate background information, and significantly enhanced the performance of the baseline model.
LIU Junjing, ZHENG Wanlu, GUO Ziqiang, WANG Shaorong. Person re-identification method based on multi-part guided foreground enhancement. Journal of Zhejiang University(Engineering Science)[J], 2025, 59(5): 929-937 doi:10.3785/j.issn.1008-973X.2025.05.006
ZHENG L, ZHANG H, SUN S, et al. Person re-identification in the wild [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1367-1376.
ZHAO L, LI X, ZHUANG Y, et al. Deeply-learned part-aligned representations for person re-identification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Venice: IEEE, 2017: 3219-3228.
SU C, ZHANG S, XING J, et al. Deep attributes driven multi-camera person re-identification [C]// Proceedings of the European Conference on Computer Vision . Amsterdam: Springer, 2016: 475-491.
MATSUKAWA T, SUZUKI E. Person re-identification using CNN features learned from combination of attributes [C]// 23rd International Conference on Pattern Recognition . Cancun: IEEE, 2016: 2428-2433.
HUANG H, LI D, ZHANG Z, et al. Adversarially occluded samples for person re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 5098-5107.
VARIOR R R, SHUAI B, LU J, et al. A siamese long short-term memory architecture for human Re-identification [C]// Proceedings of the European Conference on Computer Vision . Amsterdam: Springer, 2016: 135-153.
SONG C, HUANG Y, OUYANG W, et al. Mask-guided contrastive attention model for person re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1179-1188.
YE M, LIANG C, WANG Z, et al. Ranking optimization for person re-identification via similarity and dissimilarity [C]// Proceedings of the ACM International Conference on Multimedia. Brisbane: ACM, 2015: 1239-1242.
TIAN M, YI S, LI H, et al. Eliminating background-bias for robust person re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 5794-5803.
FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3146-3154.
PARK J, WOO S, LEE J Y, et al. BAM: bottleneck attention module [C]// Proceedings of the British Machine Vision Conference . London: BMVA Press, 2018: 147-160.
ZHENG L, SHEN L, TIAN L, et al. Scalable person re-identification: a benchmark [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Santiago: IEEE, 2015: 1116-1124.
ZHENG Z, ZHENG L, YANG Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Venice: IEEE, 2017: 3754-3762.
WANG X, DORETTO G, SEBASTIAN T, et al. Shape and appearance context modeling [C]// IEEE 11th International Conference on Computer Vision . Rio de Janeiro: IEEE, 2007: 1-8.
HERMANS A, BEYER L, LEIBE B. In defense of the triplet loss for person re-identification [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Long Beach: IEEE, 2019: 1526-1535.
LI W, ZHAO R, XIAO T, et al. Deepreid: deep filter pairing neural network for person re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 152-159.
LI W, ZHU X, GONG S. Person re-identification by deep joint learning of multi-loss classification [C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne: IJCAI Press, 2017: 2194-2200.
LI W, ZHU X, GONG S. Person re-identification by deep joint learning of multi-loss classification [C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence . Melbourne: IJCAI Press, 2017: 2194-2200.
ZHANG X, LUO H, FAN X, et al. AlignedReID: surpassing human-level performance in person re-identification [EB/OL]. (2018-01-31)[2024-07-06]. https://arxiv.org/pdf/1711.08184.
LI W, ZHU X, GONG S. Harmonious attention network for person re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2285-2294.
SUN Y, ZHENG L, YANG Y, et al. Beyond part models: person retrieval with refined part pooling (and a strong convolutional baseline [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 480-496.
WANG C, ZHANG Q, HUANG C, et al. Mancs: a multi-task attentional network with curriculum sampling for person re-identification [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 365-381.
ZHOU K, YANG Y, CAVALLARO A, et al. Omni-scale feature learning for person re-identification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 3702-3712.
QUAN R, DONG X, WU Y, et al. Auto-reid: searching for a part-aware convnet for person re-identification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 3750-3759.
WANG G, YANG S, LIU H, et al. High-order information matters: learning relation and topology for occluded person re-identification [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 6449-6458.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}