[1]
SANDY M, ANDERSSON J, BARRÉ-BRISEBOIS C. Directx: evolving microsoft’s graphics platform [C]// Game Developers Conference . San Francisco: IEEE, 2018.
[本文引用: 1]
[3]
HARADA T. Hardware-accelerated ray tracing in AMD Radeon ProRender 2.0 [EB/OL]. [2024-06-20]. https://gpuopen.com/learn/radeon-prorender-2-0/.
[本文引用: 1]
[4]
GUO J, FU X, LIN L, et al. ExtraNet: real-time extrapolated rendering for low-latency temporal supersampling [J]. ACM Transactions on Graphics , 2021, 40(6): 1-16.
[本文引用: 7]
[5]
BAO W, LAI W S, MA C, et al. Depth-aware video frame interpolation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Los Angeles: IEEE, 2019.
[本文引用: 2]
[6]
LEE H, KIM T, CHUNG T Y, et al. AdaCoF: adaptive collaboration of flows for video frame interpolation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020.
[本文引用: 2]
[7]
NIKLAUS S, MAI L, LIU F. Video frame interpolation via adaptive convolution [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Hawaii: IEEE, 2017.
[本文引用: 3]
[8]
OCULUS V. Asynchronous spacewarp [EB/OL]. [2024-06-20]. https://developers.meta.com/horizon/blog/asynchronous-spacewarp/.
[本文引用: 1]
[9]
MEYER S, WANG O, ZIMMER H, et al. Phase-based frame interpolation for video [C]// IEEE Conference on Computer Vision and Pattern Recognition .Washington DC: IEEE, 2015: 1410-1418.
[本文引用: 2]
[10]
MEYER S, DJELOUAH A, MCWILLIAMS B, et al. PhaseNet for video frame interpolation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2018: 498-507.
[本文引用: 1]
[11]
JIANG H, SUN D, JAMPANI V, et al. Super SloMo: high quality estimation of multiple intermediate frames for video interpolation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2018.
[本文引用: 1]
[12]
LONG G, KNEIP L, ALVAREZ J M, et al. Learning image matching by simply watching video [C]//LEIBE B, MATAS J, SEBE N, et al. European Conference on Computer Vision . Cham: Springer, 2016: 434-450.
[本文引用: 1]
[13]
CHOI M, KIM H, HAN B, et al. Channel attention is all you need for video frame interpolation [C]// AAAI Conference on Artificial Intelligence . New York: AAAI, 2020.
[14]
KALLURI T, PATHAK D, CHANDRAKER M, et al. FLAVR: flow-agnostic video representations for fast frame interpolation [C]// IEEE Workshop/Winter Conference on Applications of Computer Vision . [S. l.]: IEEE, 2020.
[15]
LU L, WU R, LIN H, et al. Video frame interpolation with Transformer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 3532-3542.
[16]
REDA F, KONTKANEN J, TABELLION E, et al. FILM: frame interpolation for large motion [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022.
[本文引用: 1]
[17]
DIDYK P, EISEMANN E, RITSCHEL T, et al Perceptually-motivated real-time temporal upsampling of 3D content for high-refresh-rate displays
[J]. Computer Graphics Forum , 2010 , 29 (2 ): 713 - 722
DOI:10.1111/j.1467-8659.2009.01641.x
[本文引用: 2]
[18]
DIDYK P, RITSCHEL T, EISEMANN E, et al. Adaptive image-space stereo view synthesis [C]// Proceedings of Vision, Modeling, and Visualization Workshop 2010 . Siegen: [s. n.], 2010.
[本文引用: 1]
[19]
YANG L, TSE Y C, SANDER P V, et al. Image-based bidirectional scene reprojection [C]// Proceedings of the 2011 SIGGRAPH Asia Conference . Hongkong: ACM, 2011: 1-10.
[本文引用: 2]
[20]
BOWLES H, MITCHELL K, SUMNER R, et al. Iterative image warping [C]// Computer Graphics Forum. Oxford: Blackwell Publishing Ltd, 2012: 237-246.
[本文引用: 1]
[21]
NTAVELIS E, ROMERO A, BIGDELI S, et al. AIM 2020 challenge on image extreme inpainting [EB/OL]. [2024-06-20]. http://arxiv.org/abs/2010.01110.
[本文引用: 1]
[22]
PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: feature learning by inpainting [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1604.07379.
[23]
ZENG Y, FU J, CHAO H, et al. Learning pyramid-context encoder network for high-quality image inpainting [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1904.07475.
[本文引用: 1]
[24]
LIU G, REDA F A, SHIH K J, et al. Image inpainting for irregular holes using partial convolutions [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1804.07723.
[本文引用: 1]
[25]
YU J, LIN Z, YANG J, et al. Free-form image inpainting with gated convolution [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1806.03589.
[本文引用: 2]
[26]
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1511.07122.
[本文引用: 2]
[27]
REN Y, YU X, ZHANG R, et al. StructureFlow: image inpainting via structure-aware appearance flow [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1908.03852.
[本文引用: 1]
[28]
LIU H, WANG Y, WANG M, et al. Delving globally into texture and structure for image inpainting [C]// Proceedings of the 30th ACM International Conference on Multimedia . [S. l. ]: ACM, 2022.
[本文引用: 1]
[29]
PIRNAY J, CHAI K. Inpainting Transformer for anomaly detection [EB/OL]. [2024-06-20]. https://arxiv.org/abs/2104.13897.
[本文引用: 2]
[30]
LUGMAYR A, DANELLJAN M, ROMERO A, et al. RePaint: inpainting using denoising diffusion probabilistic models [EB/OL]. [2024-06-20]. https://arxiv.org/abs/2201.09865.
[本文引用: 1]
[31]
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [[EB/OL]. [2024-06-20]. https://arxiv.org/abs/2006.11239.
[本文引用: 1]
[32]
GUO J, LAI S, TAO C, et al. Highlight-aware two-stream network for single image SVBRDF acquisition [J]. ACM Transactions on Graphics , 2021, 40(4): 1-14.
[本文引用: 2]
[33]
ZENG Z, LIU S, YANG J, et al Temporally reliable motion vectors for real-time ray tracing
[J]. Computer Graphics Forum , 2021 , 40 (2 ): 79 - 90
DOI:10.1111/cgf.142616
[本文引用: 1]
[34]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2018: 7132-7141.
[本文引用: 1]
[35]
PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performance deep learning library [C]//WALLACH H M, LAROCHELLE H, BEYGELZIMER A, et al. Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver: MIT Press, 2019: 8024-8035.
[本文引用: 1]
[36]
KINGMA D P, BA J. Adam: a method for stochastic optimization [C]// BENGIO Y, LECUN Y. 3rd International Conference on Learning Representations. San Diego: MIT Press, 2015.
[本文引用: 1]
[37]
SCHIED C, KAPLANYAN A, WYMAN C, et al. Spatiotemporal variance-guided filtering: real-time reconstruction for path-traced global illumination [C]// Proceedings of High Performance Graphics .[S. l.]: ACM, 2017 .
[本文引用: 1]
[38]
LIU E. DLSS 2.0: image reconstruction for real-time rendering with deep learning [C] // Game Developers Conference . [S. l.]: UBM TechWeb, 2020.
[本文引用: 2]
1
... 近年来,随着虚拟现实系统、AAA游戏、车机系统等产业需求的推动,现代显示器的像素分辨率和刷新率得到了显著的提升. 受限于显卡能力,大部分实时渲染引擎只能以较低的帧率执行渲染,难以满足高分辨率、高刷新率显示器的要求. 此外,随着硬件加速API的出现及包括游戏在内的相关行业对实时光线追踪技术需求的提高,人们期望在呈现高质量渲染内容的前提下,渲染过程的时间开销尽可能低[1 -3 ] . 复杂的渲染算法通常会带来更多的渲染时间开销,简单的渲染管线和渲染方法难以满足实时渲染对时间性能的要求. 随着行业的发展,用户对渲染内容的质量有了更多的期待,人们希望能够得到高帧率的渲染结果,以达到更好的视觉体验. 对于普通的个人电脑应用,大部分用户的最低要求是帧率需要达到30~60帧/s. 由光线追踪带来的渲染时间开销为现有的实时渲染管线带来了新的挑战,如何以更小的时间开销来达到更好的图像质量是当前实时渲染领域的重要问题. ...
RTX on the NVIDIA Turing GPU
0
2020
1
... 近年来,随着虚拟现实系统、AAA游戏、车机系统等产业需求的推动,现代显示器的像素分辨率和刷新率得到了显著的提升. 受限于显卡能力,大部分实时渲染引擎只能以较低的帧率执行渲染,难以满足高分辨率、高刷新率显示器的要求. 此外,随着硬件加速API的出现及包括游戏在内的相关行业对实时光线追踪技术需求的提高,人们期望在呈现高质量渲染内容的前提下,渲染过程的时间开销尽可能低[1 -3 ] . 复杂的渲染算法通常会带来更多的渲染时间开销,简单的渲染管线和渲染方法难以满足实时渲染对时间性能的要求. 随着行业的发展,用户对渲染内容的质量有了更多的期待,人们希望能够得到高帧率的渲染结果,以达到更好的视觉体验. 对于普通的个人电脑应用,大部分用户的最低要求是帧率需要达到30~60帧/s. 由光线追踪带来的渲染时间开销为现有的实时渲染管线带来了新的挑战,如何以更小的时间开销来达到更好的图像质量是当前实时渲染领域的重要问题. ...
7
... 降低渲染成本的一种重要策略是时域超采样,也被称为图像插帧,这是在时间维度上进行超采样的技术: 通过已有的渲染图像直接生成一帧或多帧新的渲染结果来实现图像序列的帧率提升. 目前,图像插帧技术已逐渐成为计算机图形学和计算机视觉的热门研究方向之一[4 -7 ] . ...
... 在图像领域的插帧技术已经有了很多成果,但通常这些方法因巨大的时间开销而无法满足实时渲染对低时延的要求,不能直接迁移到实时渲染中使用. 在工业界,早期使用的较多的插帧方法通常基于传统的ASW[8 ] 技术,但因为功耗过高、时延较长和算法插帧的效果欠佳等问题而难以推广. 近几年,越来越多的技术将深度学习作为渲染内容的插帧,例如以轻量级网络实现帧外插的ExtraNet[4 ] , 在实时渲染的条件下能够得到不错的效果,但从性能角度来看,ExtraNet有很大的提升空间. ...
... 帧外插技术是仅从历史帧信息来预测未来帧的方法,与帧间插值相比,可用信息相对更少. 在计算机视觉领域,由于缺少必要的运动信息,通常不会考虑对视频进行外插值. 在计算机图形学方面,Guo等[4 ] 提出通过深度学习进行帧外插推理的方法,能够达到实时渲染的低时延要求. ...
... 将图像修补模块的输入部分全部拼接到一起,再在网络首端进行输入. 输入的图像包括以下4个部分:与当前帧紧邻的历史帧重投影后的结果、重投影后经过处理得到的0-1遮罩、当前帧的深度信息、当前帧的世界法线信息. 其中0-1遮罩的获取主要是为了标记运动矢量重投影后产生的伪影,利用一些辅助的G-buffers进行生成[4 ] . 该输入可以引入注意力机制,使得网络能够集中处理这些区域. ...
... 相对于之前的帧外插工作[4 ] , 输入删除了Occlusion Motion Vector[33 ] 的重投影结果及2个G-buffer信息: 当前帧的金属性和粗糙度. 针对Occlusion Motion Vector, 本文主要有如下2个考虑. 1)Occlusion Motion Vector在大部分渲染管线中是无法获得的,需要自己定制管线进行输出,且Occlusion Motion Vector的生成及Occlusion Motion Vector的重投影操作需要引入额外的G-buffer信息和额外的时间开销,在整个管线的时延数量级都较小的情况下,引入这部分开销会降低整体的效率. 2)目前的网络本身对于图像填补的能力很强,Occlusion Motion Vector的引入对图像的视觉效果和指标结果的收益影响都较小,因此为了节省时间开销,可以去掉这一部分. G-buffers的削减有如下考虑:G-buffers的引入主要是为了辅助图像填补工作,对于遮挡关系的变化、物体的前后关系能够提供较充分的信息;世界法线坐标信息可以辅助捕获物体的移动.金属度和粗糙度这2个G-buffer能够提供的信息相对有限,引入它们会增加渲染管线的开销,因此该方法考虑去除这2个G-buffer输入. 后续将会通过实验来对比不同G-buffers的引入对本文模型的影响. ...
... 第3个损失是针对光流重投影模块所引入的损失函数. 在考虑空洞区域已经填补成功的条件下,预测图像与真实图像相差最大的地方是阴影和高光区域,这些区域的运动不会被运动矢量记录,因此历史帧重投影以后的这类区域的像素与真实图像有较大的差距.受Guo等[4 ] 的工作启发,将误差最大的k 个像素的L 1 损失作为第3个损失: ...
... 反照率为网络推理前后用于去除纹理信息的G-buffers.反照率的引入主要是为了提升图像结果的整体质量,可以保证输出结果的整体色调与GT一致[4 ,37 -38 ] . 将运动矢量用作历史帧的重投影,将运动物体蒙版、世界空间坐标、世界法线用于3种空洞遮罩的生成. ...
2
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
... [5 ]利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
2
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
... [6 ]设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
3
... 降低渲染成本的一种重要策略是时域超采样,也被称为图像插帧,这是在时间维度上进行超采样的技术: 通过已有的渲染图像直接生成一帧或多帧新的渲染结果来实现图像序列的帧率提升. 目前,图像插帧技术已逐渐成为计算机图形学和计算机视觉的热门研究方向之一[4 -7 ] . ...
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
... -7 ]. Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
1
... 在图像领域的插帧技术已经有了很多成果,但通常这些方法因巨大的时间开销而无法满足实时渲染对低时延的要求,不能直接迁移到实时渲染中使用. 在工业界,早期使用的较多的插帧方法通常基于传统的ASW[8 ] 技术,但因为功耗过高、时延较长和算法插帧的效果欠佳等问题而难以推广. 近几年,越来越多的技术将深度学习作为渲染内容的插帧,例如以轻量级网络实现帧外插的ExtraNet[4 ] , 在实时渲染的条件下能够得到不错的效果,但从性能角度来看,ExtraNet有很大的提升空间. ...
2
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
... [9 ]设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
1
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
1
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
1
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
1
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
Perceptually-motivated real-time temporal upsampling of 3D content for high-refresh-rate displays
2
2010
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
... [17 -18 ]充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
1
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
2
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
... [19 ]通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
1
... 帧内插值的目标是在2个相邻帧之间合成新的帧. 帧内插值方法通常可以分为以下4类. 1)基于相位的方法[9 -10 ] . Meyer等[9 ] 设计有界位移矫正策略,利用相位信息在一个多尺度金字塔结构中传播,实现了帧内插值. 2)基于光流的方法[5 -7 ,11 ] . Bao等[5 ] 利用光流信息、深度图和可学习的分层特征,设计具有深度感知能力的视频帧内插值方法. 3)基于核的方法[6 -7 ] . Lee等[6 ] 设计称为AdaCoF的图像重投影方法,预测用于目标帧像素推理的卷积核权重和偏移,实现帧预测的功能. 4)直接使用前馈神经网络进行预测的方法[12 -16 ] . 其中,从性能角度出发,基于光流的方法是目前比较主流的思路,尤其是对于那些能够提供准确光流信息( 运动矢量) 的场景,这类方法的性能相对更优秀[17 -19 ] . 在已知运动矢量的条件下,通常会利用图像重投影技术[17 -18 ] 充分复用帧间的重复信息,进行帧间插值. Yang等[19 ] 通过双向投影插值了一对连续的渲染帧; Bowles等[20 ] 提出使用固定点迭代的通用框架,用于后向的图像重投影. ...
1
... 在时域超采样过程中,为了生成新的帧,使用运动矢量进行重投影,会因为遮挡区域变化而无法正确对应的图像区域,产生类似于“空洞”的伪影.目前,针对该问题的解决方案通常是利用神经网络来进行图像修补. 现有的图像修补方法[21 -23 ] 大多数是采用编码器-解码器配置,结合对抗训练和感知损失来加强结果. ...
1
... 在时域超采样过程中,为了生成新的帧,使用运动矢量进行重投影,会因为遮挡区域变化而无法正确对应的图像区域,产生类似于“空洞”的伪影.目前,针对该问题的解决方案通常是利用神经网络来进行图像修补. 现有的图像修补方法[21 -23 ] 大多数是采用编码器-解码器配置,结合对抗训练和感知损失来加强结果. ...
1
... 近年来,又有一些研究工作提出新的思路. 普通的神经网络对图像中的空洞区域不敏感,因此部分工作考虑引入注意力机制来加强网络的修补功能.部分卷积[24 ] 和门控卷积[25 ] 可以用来估计加权掩码,引导主干网络的卷积操作,加强网络对空洞区域的关注.针对帧与帧前后移动幅度过大的问题,需要增加网络的感受野来捕获图像中的长距离对应关系.Yu等[26 -29 ] 提出扩张卷积[26 ] 、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
2
... 近年来,又有一些研究工作提出新的思路. 普通的神经网络对图像中的空洞区域不敏感,因此部分工作考虑引入注意力机制来加强网络的修补功能.部分卷积[24 ] 和门控卷积[25 ] 可以用来估计加权掩码,引导主干网络的卷积操作,加强网络对空洞区域的关注.针对帧与帧前后移动幅度过大的问题,需要增加网络的感受野来捕获图像中的长距离对应关系.Yu等[26 -29 ] 提出扩张卷积[26 ] 、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
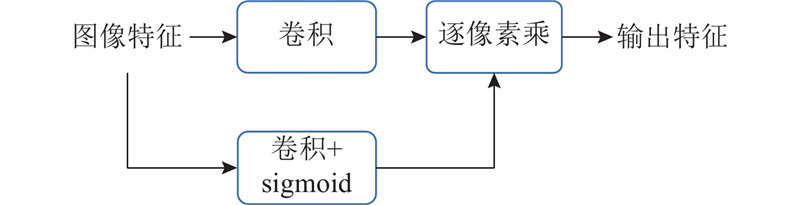
... 针对图像修补的任务,提出的网络模型主要有以下2个设计. 第1个设计是前2个门卷积操作( LWG Conv) ,基本思路来自类似的图像修补工作[25 , 32 ] . 将图像的特征分别经过2组卷积,其中一组卷积正常输出特征,另一组卷积输出类似于空洞遮罩的特征,并经过sigmoid激活函数,将输出变换到0~1.0. 空洞遮罩的卷积操作可以直接输出1通道的特征结果,由此可以大幅降低门卷积的时间开销,但在结果质量上没有明显的影响. 设计的门卷积流程如图3 所示. ...
2
... 近年来,又有一些研究工作提出新的思路. 普通的神经网络对图像中的空洞区域不敏感,因此部分工作考虑引入注意力机制来加强网络的修补功能.部分卷积[24 ] 和门控卷积[25 ] 可以用来估计加权掩码,引导主干网络的卷积操作,加强网络对空洞区域的关注.针对帧与帧前后移动幅度过大的问题,需要增加网络的感受野来捕获图像中的长距离对应关系.Yu等[26 -29 ] 提出扩张卷积[26 ] 、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
... [26 ]、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
1
... 近年来,又有一些研究工作提出新的思路. 普通的神经网络对图像中的空洞区域不敏感,因此部分工作考虑引入注意力机制来加强网络的修补功能.部分卷积[24 ] 和门控卷积[25 ] 可以用来估计加权掩码,引导主干网络的卷积操作,加强网络对空洞区域的关注.针对帧与帧前后移动幅度过大的问题,需要增加网络的感受野来捕获图像中的长距离对应关系.Yu等[26 -29 ] 提出扩张卷积[26 ] 、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
1
... 近年来,又有一些研究工作提出新的思路. 普通的神经网络对图像中的空洞区域不敏感,因此部分工作考虑引入注意力机制来加强网络的修补功能.部分卷积[24 ] 和门控卷积[25 ] 可以用来估计加权掩码,引导主干网络的卷积操作,加强网络对空洞区域的关注.针对帧与帧前后移动幅度过大的问题,需要增加网络的感受野来捕获图像中的长距离对应关系.Yu等[26 -29 ] 提出扩张卷积[26 ] 、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
2
... 近年来,又有一些研究工作提出新的思路. 普通的神经网络对图像中的空洞区域不敏感,因此部分工作考虑引入注意力机制来加强网络的修补功能.部分卷积[24 ] 和门控卷积[25 ] 可以用来估计加权掩码,引导主干网络的卷积操作,加强网络对空洞区域的关注.针对帧与帧前后移动幅度过大的问题,需要增加网络的感受野来捕获图像中的长距离对应关系.Yu等[26 -29 ] 提出扩张卷积[26 ] 、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
... -29 ]等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
1
... 近年来,又有一些研究工作提出新的思路. 普通的神经网络对图像中的空洞区域不敏感,因此部分工作考虑引入注意力机制来加强网络的修补功能.部分卷积[24 ] 和门控卷积[25 ] 可以用来估计加权掩码,引导主干网络的卷积操作,加强网络对空洞区域的关注.针对帧与帧前后移动幅度过大的问题,需要增加网络的感受野来捕获图像中的长距离对应关系.Yu等[26 -29 ] 提出扩张卷积[26 ] 、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
1
... 近年来,又有一些研究工作提出新的思路. 普通的神经网络对图像中的空洞区域不敏感,因此部分工作考虑引入注意力机制来加强网络的修补功能.部分卷积[24 ] 和门控卷积[25 ] 可以用来估计加权掩码,引导主干网络的卷积操作,加强网络对空洞区域的关注.针对帧与帧前后移动幅度过大的问题,需要增加网络的感受野来捕获图像中的长距离对应关系.Yu等[26 -29 ] 提出扩张卷积[26 ] 、外观流[27 ] 和基于Transformer的设计[28 -29 ] 等. 与编码器-解码器结构相反,Lugmayr等[30 ] 提出用于图像修补任务的DDPM[31 ] 方法,以更多的推理时间为代价来获得各种各样的输出. 在本文中,2项工作都涉及利用运动向量运行重投影的操作,因此都会在遮挡区域产生空洞,需要利用基于深度学习的图像修补技术进行处理. ...
2
... 1)在两大模块输入前、后加入上采样和下采样操作,这一操作的目的主要是减少整个网络的时间开销,由于2个重要模块本身的网络规模很小,仅仅是替换某几个小模块或者是减少通道数量,对整体的性能提升影响不大. 更有效的方法是在整个网络推理过程中减少流动的数据数量,因此将更小的图像( 低分辨率图像) 输入网络会为网络性能带来数倍的提升,这在一些类似的工作中[32 ] 有相似的操作. 经过后续的实验验证可知,以低分辨率的状态进行网络推理对图像质量的影响不大,这证明了该方法的可行性. ...
... 针对图像修补的任务,提出的网络模型主要有以下2个设计. 第1个设计是前2个门卷积操作( LWG Conv) ,基本思路来自类似的图像修补工作[25 , 32 ] . 将图像的特征分别经过2组卷积,其中一组卷积正常输出特征,另一组卷积输出类似于空洞遮罩的特征,并经过sigmoid激活函数,将输出变换到0~1.0. 空洞遮罩的卷积操作可以直接输出1通道的特征结果,由此可以大幅降低门卷积的时间开销,但在结果质量上没有明显的影响. 设计的门卷积流程如图3 所示. ...
Temporally reliable motion vectors for real-time ray tracing
1
2021
... 相对于之前的帧外插工作[4 ] , 输入删除了Occlusion Motion Vector[33 ] 的重投影结果及2个G-buffer信息: 当前帧的金属性和粗糙度. 针对Occlusion Motion Vector, 本文主要有如下2个考虑. 1)Occlusion Motion Vector在大部分渲染管线中是无法获得的,需要自己定制管线进行输出,且Occlusion Motion Vector的生成及Occlusion Motion Vector的重投影操作需要引入额外的G-buffer信息和额外的时间开销,在整个管线的时延数量级都较小的情况下,引入这部分开销会降低整体的效率. 2)目前的网络本身对于图像填补的能力很强,Occlusion Motion Vector的引入对图像的视觉效果和指标结果的收益影响都较小,因此为了节省时间开销,可以去掉这一部分. G-buffers的削减有如下考虑:G-buffers的引入主要是为了辅助图像填补工作,对于遮挡关系的变化、物体的前后关系能够提供较充分的信息;世界法线坐标信息可以辅助捕获物体的移动.金属度和粗糙度这2个G-buffer能够提供的信息相对有限,引入它们会增加渲染管线的开销,因此该方法考虑去除这2个G-buffer输入. 后续将会通过实验来对比不同G-buffers的引入对本文模型的影响. ...
1
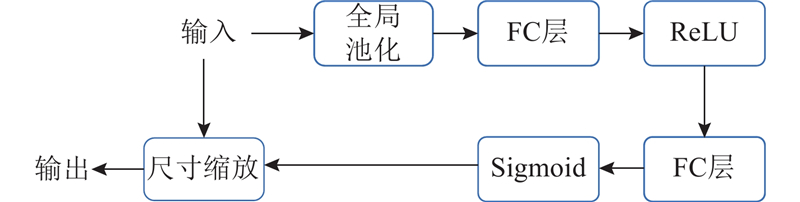
... 在整个网络流程中,只引入2个门卷积操作,后续的填补工作由挤压与激发( squeeze-and-excitation, SE)模块[34 ] 来完成. SE模块如图4 所示,基本思路是生成遮罩. 输入的特征经过1×1大小的自适应池化处理( global pooling) , 将每个通道整张图的特征压缩为一个值. 经过全连接层( FC layer) 进行特征提取,经过Sigmoid激活函数变换到0~1.0后,再还原到原始的图像. 由此产生的遮罩特征与输入特征相乘得到输出. 对于2个全连接层的输入输出,SE模块有一个R 值的超参数设置. 当经过第1个全连接层时,将通道数降为原本的1/R ( 整除),再在第2个全连接层进行还原,该方法所设置的R 为16. R 的设置可以减少全连接层计算的开销,优化SE模块的效率.采用门卷积和SE这2个Inpainting模块的原因如下. 1) SE模块相对于改进后的门卷积模块开销更小,可以进一步降低网络推理的时延. 2)SE模块可以自适应地调节通道级别的特征响应,更好地填补空洞区域,相对于门卷积,能够更好地提供注意力机制去填补空洞的区域. 3)SE模块经过池化后提取的遮罩特征是来自全图的全局特征,而门卷积操作中单个卷积提取的感受野有限,是局部特征,这2个特征在图像填补的过程中都是有用的信息. 该方法通过2个门卷积进行初步的图像填补,再经过3个SE模块对填洞效果进行进一步的加强. ...
1
... 针对以上的方法,使用Pytorch[35 ] 框架进行具体的实现,优化器采用mini-batch SGD的Adam优化器[36 ] . 虽然实际训练使用的输入图像分辨率较大,但网络模型本身较小,因此训练的批大小设置为8. Adam优化器的参数${\beta _1}$ ${\beta _2}$ ${10^{ - 3}}$
1
... 针对以上的方法,使用Pytorch[35 ] 框架进行具体的实现,优化器采用mini-batch SGD的Adam优化器[36 ] . 虽然实际训练使用的输入图像分辨率较大,但网络模型本身较小,因此训练的批大小设置为8. Adam优化器的参数${\beta _1}$ ${\beta _2}$ ${10^{ - 3}}$
1
... 反照率为网络推理前后用于去除纹理信息的G-buffers.反照率的引入主要是为了提升图像结果的整体质量,可以保证输出结果的整体色调与GT一致[4 ,37 -38 ] . 将运动矢量用作历史帧的重投影,将运动物体蒙版、世界空间坐标、世界法线用于3种空洞遮罩的生成. ...
2
... 反照率为网络推理前后用于去除纹理信息的G-buffers.反照率的引入主要是为了提升图像结果的整体质量,可以保证输出结果的整体色调与GT一致[4 ,37 -38 ] . 将运动矢量用作历史帧的重投影,将运动物体蒙版、世界空间坐标、世界法线用于3种空洞遮罩的生成. ...
... 如表2 所示为指标结果. 针对帧外插算法,采用2个基本指标用于定量分析: 峰值信噪比(peak signal-to-noise ratio,PSNR) 和结构相似性(structural similarity index measure,SSIM) [38 ] . 除此以外,还引入新的评估指标: 平均单次推理峰值信噪比PT. 该指标的计算是将PSNR除以网络执行一次完整推理的时间,能够将时间开销和输出图像质量统一起来考虑. 对于本文方法和ExtraNet的基本指标( PSNR、SSIM), MD场景下降相对较少,主要原因是码头相对森林的细节更少. 虽然本文方法相对ExtraNet的指标整体上有所下降,但本文方法在时间性能上的提升很突出. 第3个指标在加入了时间的影响以后,本文的2种方法在指标结果上均优于ExtraNet, 在某些需要追求极致帧率的应用场景下,本文方法相对于ExtraNet有明显的优势. ...










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}