

数据驱动的进化算法(data-driven evolutionary algorithm, DDEA)[1]是对使用历史数据建立代理模型,并以其辅助进化算法(evolutionary algorithm, EA)中的真实目标函数对个体进行适应度评估的算法的统称,有时也被称为代理辅助的进化算法(surrogate assisted evolutionary algorithm, SAEA)[2]. 通常,传统的EA需要多次迭代, 且每次迭代时都要对种群中的所有个体进行适应度评估.在真实环境中, 频繁评估的高昂代价可能难以承受[3], 这制约了EA在实际问题中的应用. 近年来, 为了节省计算资源, 学者们提出了一些DDEA, 它们在部分评价昂贵的优化问题上取得了不错的效果, 如创伤系统设计[4]、熔镁炉性能优化[5]、飞行器翼型优化[6]等.
在DDEA中, 常用的代理模型包括径向基函数网络(radial basis function network, RBFN)[7]、克里金模型(kriging)[8]、岭回归(ridge regression, RR)[9]、多项式回归(polynomial regression, PR)[10]等. DDEA的性能在很大程度上受到离线数据集规模的影响[1,6]. 一般而言,用于训练的数据越多, 代理模型越准确,从而能够更好地指导EA搜索最优解[11]. 由于DDEA常被用来解决昂贵优化问题,在这些问题中数据的获取可能是昂贵的[12],因此DDEA能够利用的数据通常很少. 例如用于预测蛋白质结构的AlphaFold2, 其参数优化需要128个TPUv3核运行数周的时间, 这使得研究者很难通过实验得到充足的数据[13].
DDEA有在线[14]和离线[6]2种形式. 离线的DDEA完全不进行真实评估,算法可依赖的只有数量有限的离线数据,因此更容易受到小数据的影响. 小数据难以建立准确的代理模型,这是离线的DDEA面临的主要挑战. 现有算法已为解决这一问题做出了许多尝试,主要包括引入集成学习[15]、半监督学习[16]、多核学习[17]、协同进化[18]等方法.Wang等[19]提出的DDEA-SE通过Bagging训练大量代理模型,在迭代时自适应地选择部分模型进行集成. Huang等[7, 11]分别提出TT-DDEA和SRK-DDEA. 前者使用三体训练[20]将无标签数据转化为伪标签数据,以优化每次迭代中训练的3个代理模型;后者使用离线数据训练4个不同核函数的RBFN, 利用随机排序[21]平衡模型之间的误差.Gong等[22]提出的CC-DDEA同时构建局部与全局代理模型,通过协同进化实现从局部并行到全局的搜索. 除了常见的回归模型外,一些其他类型的网络被应用到DDEA中. Huang等[23]提出的CL-DDEA使用孪生对比学习网络与拓扑排序辅助选择操作,减弱算法对离线数据质量的依赖.相关文献的实验结果表明,上述算法在数据量充足的情况下能够取得良好的效果. 当数据量大幅降低时,这些算法的性能会显著变差.
针对离线的DDEA在数据量极低的情况下表现差的问题,本文结合RBFN隐含层节点数寻优与多核学习生成伪标签数据的策略,提出基于多核数据合成的离线数据驱动的进化算法(offline data-driven evolutionary algorithm based on multi-kernel data synthesis, DDEA-MKDS). 实验表明, 利用所提算法,能够有效增强离线的DDEA对小数据的适应能力,大幅减少算法的运行时间.
1. 径向基函数网络的相关知识
1.1. 径向基函数网络的结构
RBFN训练速度快,逼近能力强,是离线的DDEA中常用的代理模型之一. 从结构上看, RBFN属于3层前向式的神经网络, 包括输入层、隐含层、输出层, 如图1所示.
图 1
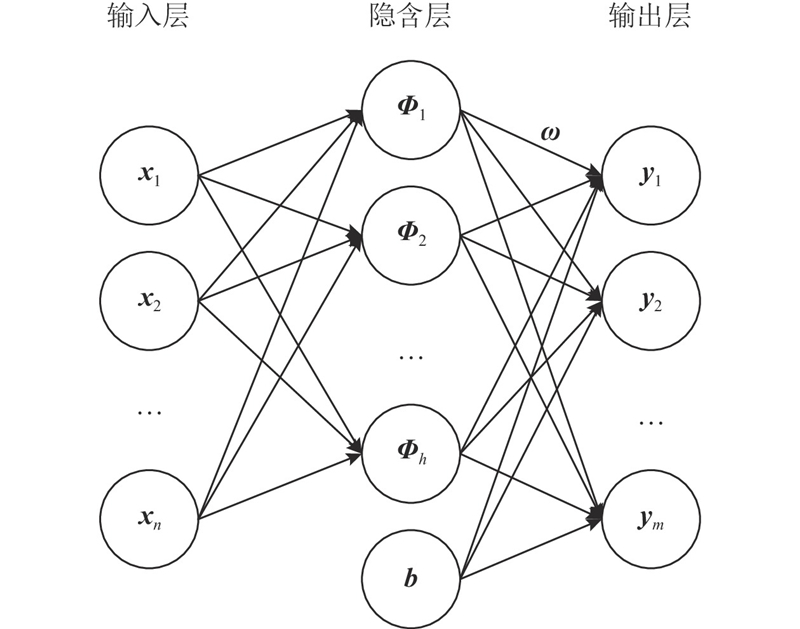
根据网络的结构, RBFN的输出可以描述为
式中:yj为第j个输出层节点的输出,h为隐含层节点数,Φi为第i个隐含层节点的核函数输出,ωij为第i个隐含层节点到第j个输出层节点之间的权值,b为网络中设置的偏置单元.
1.2. 径向基函数网络的核函数
与其他3层神经网络相比, RBFN的主要区别是使用了径向基函数(radial basis function, RBF)作为核函数. RBF是一类实值函数, 其取值只依赖于数据点到某个特定点的距离, 该特定点一般被称为中心点. RBF的通式如下:
式中:dist为数据点到中心点之间的欧氏距离,dist = ||x−c||.
在RBFN中,可使用的核函数有很多, 其中较常见的是gaussian函数、逆多二次函数和逆sigmoid函数, 它们的形式如下所示:
式中:σ为RBF的拓展常数,有时被称为宽度, σ越大表示每个隐含层节点可控制的范围越大.
2. DDEA-MKDS算法的设计
2.1. 算法总流程
DDEA-MKDS的算法流程如图2所示.
图 2
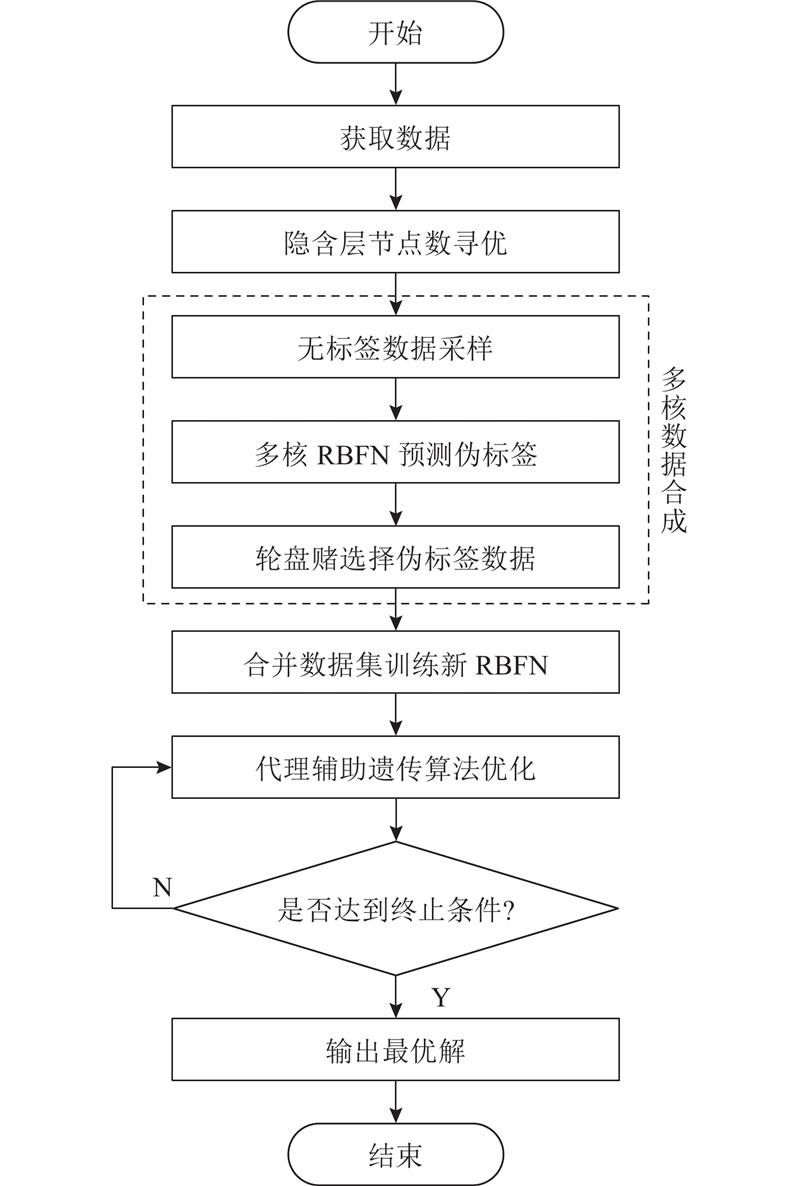
DDEA-MKDS分为以下3个阶段.
1)算法结合经验公式与遍历搜索,找出针对离线数据集的最佳隐含层节点数,在后续训练RBFN时,参数按照该阶段的寻优结果进行设置.
2)算法采样决策空间中的大量无标签数据, 使用基于离线数据集训练的3个不同核函数的RBFN模型预测它们的伪标签. 通过轮盘赌法按不确定度规则选择其中的部分数据,将选择的伪标签数据加入原数据集,形成合成数据集.
3)算法使用合成数据集,训练单个RBFN作为代理模型来代替遗传算法中的目标函数,开展个体评估.
与大多数离线的DDEA相同, 该算法选择遗传算法作为优化器. 由于离线的DDEA中代理模型的作用仅是代替进化优化过程中的真实评估,算法可以根据实际问题的特性选择不同的EA, 代理模型的构建方法是可以移植的.
DDEA-MKDS的伪代码如下所示.
算法1 DDEA-MKDS的总体框架 输入:离线数据集D、初始化种群pop、最大迭代次数G
输出:最优解sbest
1) 进行隐含层节点数寻优,得到基于D的最佳隐含层节点数hB.
2) 使用D训练多核模型MRBFN1、MRBFN2、MRBFN3,隐含层节点数为hB.
3) 由多核数据合成,得到合成数据集DS.
4) 由DS训练新模型MRBFN4, 隐含层节点数为hB.
5) 使用遗传算法对pop进行迭代寻优,以MRBFN4对个体的预测值代替个体适应度. 迭代次数为G.
6) 记最后一代种群中的最优个体为sbest.
7) return sbest
2.2. 隐含层节点数寻优
DDEA-MKDS是针对数据量极小的情况设计的. 为了避免代理模型因小数据陷入过拟合, 加快训练速度, 通过隐含层节点数寻优的策略来简化RBFN的结构.
具体而言, 该策略结合了经验公式与遍历搜索的思想. 当隐含层节点只有1个时, RBFN会失效,因此算法设置寻优区间为[2,hT], 上限hT由下面的经验公式[27]计算得出:
式中:hT为隐含层节点数的计算结果,n为输入层节点数,m为输出层节点数.
算法重复训练拥有不同隐含层节点数的RBFN,在验证数据上比较这些模型的误差, 找出该参数的最佳设置.在小数据的条件下,每个数据对模型训练的影响都较大. 为了减少数据分割带来的干扰, 算法每次训练前都从离线数据集中随机抽取仅1个数据作为验证数据. 模型误差按照下式计算:
式中:ei为隐含层节点数为i时的预测误差; preal为所抽取的验证数据的真实值; ppre为模型对所抽取的验证数据的预测值; 特别地, 若preal = 0, 则重新抽取验证数据. 算法最终会输出ei最小时的i作为隐含层节点数寻优的结果.
本部分的伪代码如下所示.
算法2 DDEA-MKDS中的隐含层节点数寻优 输入:离线数据集D、输入层节点数n、输出层节点数m
输出:最佳隐含层节点数hB
1) 由式(6)计算得到寻优区间上限hT.
2) for i = 2 : hT
从D中取出数据ptest(px,preal), 若preal = 0,则重新抽取. 将剩余数据集记为DR.
使用DR训练模型MiRBFN,MiRBFN为隐含层节点数为i的模型.
记MiRBFN对px的预测值为ppre.
由式(7)计算ei.
end for
3) 记ei最小时的i为is, 令hB = is.
4) return hB
2.3. 多核数据的合成
小数据条件下代理模型难以获得理想的精度. 提出基于多核RBFN的伪标签数据合成策略, 以达到补充数据量的目的.算法中无标签数据的采样量以相对于离线数据量的倍数dm表示.
由于单个RBFN无法提供预测值的不确定度,为了在选择数据时有可靠的参考,DDEA-MKDS训练了3个RBFN模型来预测无标签数据的伪标签,将不确定度定义为预测值的标准差,如下所示:
式中:σa为数据a预测值的标准差;par为模型r对数据a的预测值;ya为3个模型预测值的均值,作为数据a的伪标签.
要使式(8)有效,3个模型的预测值在尽量准确的同时具有一定的差异,因此算法在训练这3个RBFN时使用了不同的核函数,分别为gaussian函数、逆多二次函数和逆sigmoid函数.
不确定度越低,即3个RBFN对该数据的预测值越接近,可以认为该伪标签是更可信的,所以应选择更多不确定度低的数据. 不确定度高的数据对模型训练有积极作用,这是由于RBFN的预测能力与距离相关,一般离真实数据越远,模型的预测能力越低,所以不确定度低的数据会紧密分布在真实数据的周围. 若只选择这部分数据, 则模型的泛化能力会下降. 本算法使用轮盘赌选择法, 根据下式对所有数据的不确定度进行归一化处理, 将归一化后的值作为数据被选中的概率:
式中:qa为归一化值; σa为数据a的不确定度; σmin与σmax分别为所有数据的不确定度的最小值与最大值; ε设为10−5. 每一个数据都有机会被选中, 不确定度越低,被选中的概率越大.
本部分的伪代码如算法3所示. 其中rand为随机生成的0~1.0的浮点数.
算法3 DDEA-MKDS中的多核数据合成 输入:离线数据集D、无标签数据采样量dm
输出:合成数据集DS
1) DS = D.
2) 采样得到无标签数据集DU{(xa,·), a=1, 2
3) 使用D训练模型MRBFN1、MRBFN2、MRBFN3,模型分别使用式(3)~(5)所示的核函数.
4) 由模型预测得到伪标签数据集DF{(xa,ya), a=1,2
5) 利用式(8)、(9)得到带选择概率的数据集DF’{(xa, ya, qa), a=1, 2
6) for a = 1 : n
if qa > rand
将数据(xa,ya)加入DS.
end if
end for
7) return DS
3. 实验结果与分析
3.1. 对比实验的设计
在DDEA-MKDS中,代理模型RBFN利用K-均值算法获取中心点,权重由伪逆法计算,拓展常数为中心点间平均距离的2倍,除多核数据合成阶段外,使用的核函数为gaussian函数,dm设置为60.
所有算法都使用遗传算法进行优化,种群大小为100,迭代次数为100,交叉与变异的概率各为1与1/d,其中d为问题的维度.
与其他同类研究中使用的方法相似, 实验中最优个体的适应度是通过真实函数计算得到的, 但真实函数仅用于算法的性能评估, 不会对优化过程产生任何影响.
3.2. 对比实验结果
如表1所示为DDEA-MKDS与各对比算法在数据量为15时的优化结果, 形式为均值±标准差, 每个测试实例中的最优结果加粗显示. 可以看出, 综合表现最好的是DDEA-MKDS, 平均排名是最高的. 此外, 所有实验结果均经过Wilcoxon匹配对符号秩检验, 其中+/≈/−分别表示DDEA-MKDS显著优于/无显著差异于/显著差于对比算法. 在几乎所有的实例上, DDEA-MKDS都显著优于TT-DDEA、CL-DDEA和DDEA-SE. DDEA-MKDS中使用的隐含层节点数寻优能够有效地避免代理模型产生过拟合, 通过多核数据合成的策略弥补了数据量不足的问题,算法在面对小数据时的表现较优秀. DDEA-SE通过数据抽样构建大量代理模型,当数据量本身很少时,每一个模型的精度都较差,这会导致算法的性能显著降低. TT-DDEA具有同样的问题, 由于算法需要将数据集分割为3等份, 这会使单个模型可依赖的数据量进一步减少, 在这种情况下不准确的模型无法提供可信的伪标签数据. CL-DDEA中设计的孪生式对比网络需要依赖成对数据训练, 当数据量匮乏时, 对比网络无法达到理想的精度, 这会使其在拓扑排序的过程中产生严重的误差,算法很难进行正常的选择操作,其在所有问题上的表现都很差. 从结果上来看, 除DDEA-MKDS外, 对比算法中表现较好的是SRK-DDEA和CC-DDEA, 二者的平均排名相当. SRK-DDEA中使用基于多核学习训练的径向基函数网络作为代理模型,虽然当离线数据很少时模型精度不足,但随机排序的策略能够较好地平衡模型之间的误差. CC-DDEA中的全局模型是由多个局部模型集成形成的, 这在一定程度上减小了数据量匮乏带来的影响, 能够加强算法在高维度问题上的表现, 算法在所有100维的问题上都是表现最好的. 除了Levy与Griewank外, CC-DDEA在其他多数10维、30维与50维的问题上都显著差于DDEA-MKDS, 这意味着协同进化不适用于一些较低维度的问题的求解.
表 1 DDEA-MKDS与各对比算法在6个测试问题上的优化结果
Tab.1
| 问题 | d | DDEA-MKDS | TT-DDEA | SRK-DDEA | CC-DDEA | CL-DDEA | DDEA-SE |
| Ellipsoid | 10 | 0.79±0.73 | 4.52±6.36(+) | 1.91±2.52(≈) | 1.91±1.12(+) | 114.41±97.15(+) | 2.81±1.38(+) |
| 30 | 5.58±2.99 | 18.68±14.99(+) | 11.40±11.59(+) | 9.05±5.60(+) | 451.17±394.59(+) | 48.57±21.00(+) | |
| 50 | 27.88±9.13 | 110.19±84.30(+) | 23.99±14.62(−) | 32.19±12.61(+) | 195.13±57.46(+) | ||
| 100 | 252.72±52.58 | 269.84±54.97(≈) | 49.60±22.66(−) | ||||
| Rosenbrock | 10 | 16.22±7.00 | 20.84±10.33(≈) | 23.90±12.02(+) | 31.33±15.88(+) | 941.78±796.76(+) | 31.81±14.69(+) |
| 30 | 39.82±9.80 | 57.50±25.14(+) | 65.48±29.53(+) | 61.12±16.51(+) | 80.95±28.13(+) | ||
| 50 | 69.24±18.95 | 125.76±37.03(+) | 85.74±20.65(≈) | 104.91±51.58(+) | 217.48±61.36(+) | ||
| 100 | 209.61±36.64 | 373.37±68.49(+) | 189.10±24.13(≈) | 178.94±42.90(≈) | 714.23±121.78(+) | ||
| Ackley | 10 | 5.78±1.73 | 9.71±4.75(+) | 6.42±1.90(≈) | 7.57±2.24(+) | 10.27±4.71(≈) | 6.35±1.63(≈) |
| 30 | 4.25±0.69 | 6.91±1.98(+) | 6.10±2.17(+) | 8.19±4.71(+) | 16.19±2.45(+) | 8.96±1.35(+) | |
| 50 | 4.73±0.47 | 7.63±0.81(+) | 5.94±1.65(≈) | 5.73±1.98(≈) | 11.51±3.09(+) | 10.25±0.86(+) | |
| 100 | 7.20±0.57 | 11.02±2.01(+) | 7.28±0.60(≈) | 4.95±0.85(−) | 13.01±4.70(+) | 11.59±0.52(+) | |
| Levy | 10 | 1.60±0.36 | 3.19±3.00(≈) | 2.30±1.22(≈) | 2.48±2.42(≈) | 18.56±9.85(+) | 2.95±2.53(≈) |
| 30 | 3.57±0.76 | 10.18±10.03(+) | 4.39±1.33(≈) | 4.02±0.87(≈) | 51.71±39.59(+) | 8.62±3.44(+) | |
| 50 | 5.94±0.77 | 16.57±11.72(+) | 6.01±1.06(≈) | 10.30±4.54(+) | 109.68±64.49(+) | 20.91±6.25(+) | |
| 100 | 13.70±3.59 | 106.97±66.70(+) | 13.88±3.64(≈) | 11.03±1.97(≈) | 154.60±79.65(+) | 73.42±17.79(+) | |
| Griewank | 10 | 1.21±0.28 | 3.51±3.64(+) | 1.12±0.11(≈) | 1.19±0.21(≈) | 26.32±25.28(+) | 2.26±0.54(+) |
| 30 | 3.32±1.00 | 5.72±3.12(+) | 1.47±0.14(−) | 1.70±0.33(−) | 96.19±122.65(+) | 12.34±4.19(+) | |
| 50 | 6.24±1.81 | 9.23±6.83(≈) | 3.04±0.51(−) | 2.21±0.40(−) | 136.93±114.01(+) | 22.87±6.96(+) | |
| 100 | 21.39±4.12 | 61.68±30.82(+) | 18.56±3.96(≈) | 3.61±0.74(−) | 148.10±168.05(+) | 90.66±20.69(+) | |
| Rastrigin | 10 | 42.23±26.46 | 58.47±28.90(≈) | 64.47±35.35(+) | 89.87±37.44(+) | 138.64±34.53(+) | 76.92±26.52(≈) |
| 30 | 95.41±61.47 | 242.85±162.46(+) | 152.73±104.34(≈) | 195.63±60.41(+) | 322.84±68.42(+) | 219.82±36.95(+) | |
| 50 | 184.75±61.41 | 397.02±89.28(+) | 245.34±101.93(+) | 280.60±89.96(+) | 570.56±47.71(+) | 431.38±57.44(+) | |
| 100 | 692.34±122.68 | 697.66±128.78(≈) | 319.72±271.23(−) | 953.94±51.30(+) | |||
| +/≈/− | NA | 20/4/0 | 6/15/3 | 12/6/6 | 23/1/0 | 21/3/0 | |
| Friedman Rank | 1.63 | 4.04 | 2.40 | 2.40 | 6.00 | 4.54 | |
图 3
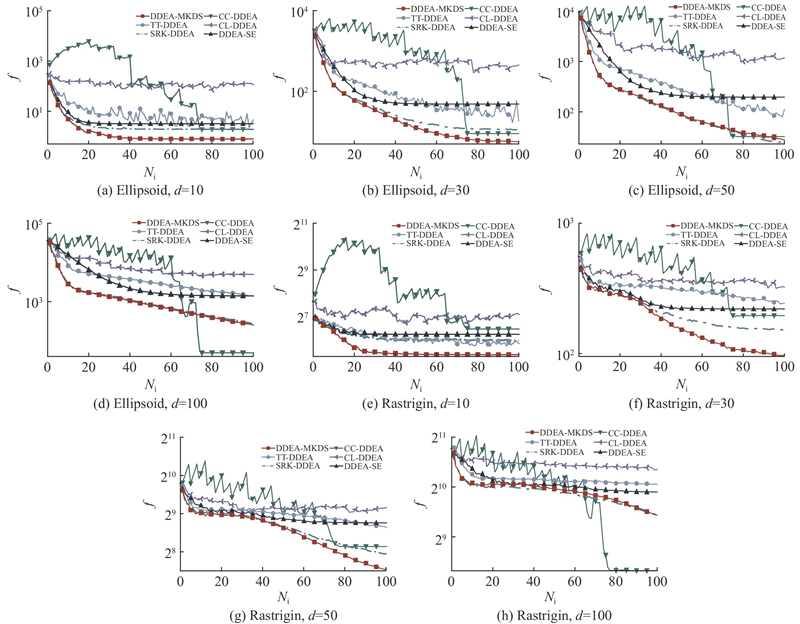
图 3 DDEA-MKDS与各对比算法在Ellipsoid与Rastrigin问题上的收敛曲线
Fig.3 Convergence curves of DDEA-MKDS and other comparison algorithms on Ellipsoid and Rastrigin
离线DDEA常被用来求解昂贵优化问题, 需要尽量减少时间成本, 因此算法的效率是很重要的. 如图4所示为各算法在所有问题上的平均运行时间,测试使用的计算机CPU为Intel(R) Core i5-10400,算法运行环境为Python 3.9.13. 可以看出,由于离线数据数量较少,且是固定规模,不随维度而变化,各算法的运行时间因维度升高而增加的幅度均不明显. DDEA-MKDS在各维度的问题上均显著快于其他所有对比算法, 差距是数量级级别的. 这主要得益于算法中的隐含层节点数寻优策略,通过减少模型隐含层节点数来简化RBFN的结构,能够显著加快训练速度. DDEA-MKDS最终用于指导进化过程的代理模型数量只有一个,不像其他算法需要训练多个模型,这进一步提升了算法的效率.速度最慢的是CL-DDEA,该算法训练对比网络时需要成对数据,实际上其训练数据量会增加到原始数据集的平方,因此对比网络的训练比传统的回归模型消耗更多的时间. 综合优化结果和运行时间来看, DDEA-MKDS是表现最好的算法.
图 4
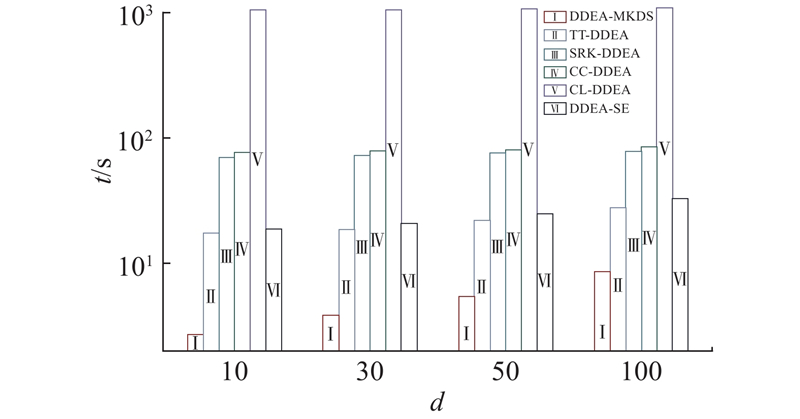
图 4 DDEA-MKDS与各对比算法在所有问题上的平均运行时间
Fig.4 Average running time of DDEA-MKDS and other comparison algorithms on all problems
3.3. 策略有效性的分析
为了验证DDEA-MKDS中使用的策略的有效性, 设计4种变体算法,与原算法进行实验对比. 变体算法的描述如下, 除有说明外,算法的其余策略和参数与DDEA-MKDS保持一致.
DDEA-MKDS(h/n):不进行隐含层节点数寻优,节点数等于离线数据量.
DDEA-RBFN(h):不添加合成数据.
DDEA-MKDS(g):不使用轮盘赌法,选择合成数据时只选择不确定度最低的一半数据.
DDEA-RBFN:无任何特殊策略,仅用离线数据训练RBFN作为代理模型,节点数等于离线数据量.
如表2所示为DDEA-MKDS与各变体算法在Ellipsoid与Rastrigin 2个问题上的优化结果.实验中,所有算法均独立运行20次, 离线数据量为15个,问题维度为10、30、50、100. 实验结果为均值±标准差的形式,且经过Wilcoxon匹配对符号秩检验,+/≈/−分别表示DDEA-MKDS在该实例上显著优于/无显著差异于/显著差于变体算法.
表 2 DDEA-MKDS与各变体算法在Ellipsoid与Rastrigin问题上的优化结果
Tab.2
| 问题 | d | DDEA-MKDS | DDEA-MKDS(h/n) | DDEA-RBFN(h) | DDEA-MKDS(g) | DDEA-RBFN |
| Ellipsoid | 10 | 0.79±0.73 | 60.57±35.39(+) | 2.83±2.18(+) | 3.10±1.97(+) | 50.96±54.94(+) |
| 30 | 5.58±2.99 | 422.51±574.92(+) | 10.23±5.03(≈) | 36.28±14.82(+) | ||
| 50 | 27.88±9.13 | 44.91±29.69(≈) | 63.95±26.79(+) | |||
| 100 | 252.72±52.58 | 377.01±240.00(≈) | 370.92±133.13(+) | |||
| Rastrigin | 10 | 42.23±26.46 | 138.32±30.58(+) | 70.23±29.99(+) | 67.95±24.70(≈) | 142.56±51.07(+) |
| 30 | 95.41±61.47 | 331.56±32.75(+) | 233.53±93.44(+) | 178.98±85.91(≈) | 665.82±133.87(+) | |
| 50 | 184.75±61.41 | 540.96±69.72(+) | 393.08±159.99(+) | 300.36±68.50(+) | ||
| 100 | 692.34±122.68 | 759.84±59.12(+) | ||||
| +/≈/− | NA | 8/0/0 | 5/3/0 | 6/2/0 | 8/0/0 | |
从表2可以看出,DDEA-MKDS在全部8个实例上都大幅优于所有的变体算法.由于DDEA-MKDS(h/n)没有使用隐含层节点数寻优的策略,代理模型容易因小数据陷入过拟合, 性能较差,这证明了隐含层节点数寻优是有效的. DDEA-RBFN(h)与DDEA-RBFN因为数据量匮乏的问题,无法训练更准确的代理模型,尤其是后者, 当不进行任何处理时, 仅依靠单个RBFN完全无法应对小数据的情况,表现最差, 说明DDEA-MKDS中设计的数据合成策略能够显著增强算法的表现. 与原算法相比, DDEA-MKDS(g)仅选择了不确定度较低的数据加入离线数据集,这会导致代理模型的泛化能力变差, 因此表现不佳, 证明原算法中进行轮盘赌选择使所有伪标签数据均有机会被选择的策略是有效的.
如图5所示为DDEA-MKDS与变体算法在所有问题上的平均运行时间. 其中DDEA-MKDS、DDEA-RBFN(h)与DDEA-MKDS(g)使用隐含层节点数寻优的策略,代理模型的结构被简化,节省的训练时间多于进行隐含层节点数寻优的时间,因此这3种算法的运行时间短于其他算法. 与不进行数据合成及不使用轮盘赌选择法的DDEA-RBFN(h)和DDEA-MKDS(g)相比,DDEA-MKDS的运行时间没有明显差异,说明这2种策略不会消耗太多时间,策略的设计是合理的.
图 5
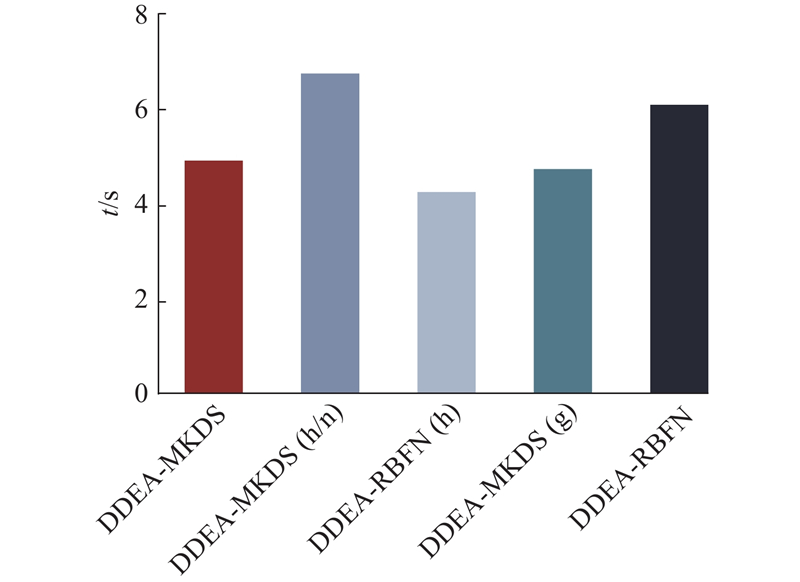
图 5 DDEA-MKDS与各变体算法在所有问题上的平均运行时间
Fig.5 Average running time of DDEA-MKDS and other various algorithm on all problems
3.4. 核函数对算法的影响
DDEA-MKDS中用于数据合成的RBFN使用了3个不同的核函数, 对于具体该如何进行核函数的选择,目前尚无系统的研究. 设计相关实验,分析核函数的选择对算法性能的影响.
由于在DDEA-MKDS中, 算法根据不同模型预测值的标准差选择合成数据, 一般认为若数据少于2个,其标准差无统计学意义,因此核函数的数量应至少为3. 采用最常见的4种径向基核函数的不同组合,具体设置如下.
DDEA-MKDS: gaussian函数、逆多二次函数和逆sigmoid函数.
DDEA-MKDS(k3b): gaussian函数、逆多二次函数和多二次函数.
DDEA-MKDS(k3c): gaussian函数、多二次函数和逆sigmoid函数.
DDEA-MKDS(k3d): 多二次函数、逆多二次函数和逆sigmoid函数.
DDEA-MKDS(k4): gaussian函数、多二次函数、逆多二次函数和逆sigmoid函数.
多二次函数的形式如下:
如表3所示为使用不同核函数时DDEA-MKDS在Ellipsoid与Rastrigin 2个问题上的优化结果, 实验中离线数据量为15个, 在所有情况下算法均独立运行20次,问题维度为10、50、100, 结果以均值±标准差的形式呈现. 从结果来看,表现最好的是原算法中的组合,但优势不明显,总体上不同的核函数组合之间的差距不显著,p为0.050.
表 3 使用不同核函数时DDEA-MKDS在Ellipsoid与Rastrigin问题上的优化结果
Tab.3
| 问题 | d | DDEA-MKDS | DDEA-MKDS(k3b) | DDEA-MKDS(k3c) | DDEA-MKDS(k3d) | DDEA-MKDS(k4) |
| Ellipsoid | 10 | 0.79±0.73 | 0.87±0.74 | 0.62±0.40 | 1.35±1.54 | 1.02±1.08 |
| 50 | 27.88±9.13 | 35.22±29.27 | 21.75±8.84 | 30.53±13.86 | 28.66±10.13 | |
| 100 | 252.72±52.58 | 265.44±34.73 | 314.06±123.93 | 270.38±60.79 | 307.81±86.81 | |
| Rastrigin | 10 | 42.23±26.46 | 42.78±32.77 | 37.91±26.06 | 45.81±36.64 | 42.30±26.75 |
| 50 | 184.75±61.41 | 180.45±88.49 | 190.50±110.37 | 225.95±108.19 | 221.98±107.42 | |
| 100 | 692.34±122.68 | 695.47±127.53 | 725.05±134.91 | 706.52±134.54 | 704.88±81.15 | |
| Friedman Rank | 1.67 | 2.83 | 2.67 | 4.33 | 3.50 | |
如表4所示为使用3个与4个核函数时算法在Ellipsoid与Rastrigin问题上的平均运行时间,在所有测试实例上使用3个核函数时的运行时间均较短.使用4个核函数意味着要多训练一个RBFN,且算法须花费更多的时间来计算标准差和选择数据.综合而言,原算法中的3个核函数组合是最优设置.
表 4 使用不同数量核函数时DDEA-MKDS的平均运行时间
Tab.4
| 问题 | d | DDEA-MKDS(k3) | DDEA-MKDS(k4) |
| Ellipsoid | 10 | 2.67±0.20 | 2.81±0.22 |
| 50 | 5.34±0.49 | 5.43±0.46 | |
| 100 | 8.31±0.68 | 8.63±0.69 | |
| Rastrigin | 10 | 2.62±0.21 | 2.71±0.21 |
| 50 | 5.23±0.42 | 5.43±0.48 | |
| 100 | 8.26±0.70 | 8.30±0.86 |
3.5. 参数敏感性实验
表 5 dm取不同值时DDEA-MKDS在Ellipsoid与Rastrigin问题上的优化结果
Tab.5
| 问题 | d | dm=5 | dm=20 | dm=40 | dm=60 | dm=80 | dm=100 | dm=120 |
| Ellipsoid | 10 | 2.90±1.92 | 1.56±1.44 | 0.92±0.96 | 0.79±0.73 | 1.24±1.60 | 0.93±1.02 | 1.24±1.34 |
| Ellipsoid | 50 | 78.96±26.00 | 38.55±20.31 | 33.67±15.68 | 27.88±9.13 | 30.44±13.83 | 30.71±19.06 | 25.34±16.28 |
| Ellipsoid | 100 | 533.97±134.03 | 360.59±84.39 | 265.83±53.41 | 252.72±52.58 | 277.75±63.42 | 262.33±46.02 | 264.12±81.76 |
| Rastrigin | 10 | 80.36±24.35 | 46.61±31.06 | 40.37±29.60 | 42.23±46.46 | 49.75±35.83 | 40.66±28.60 | 30.73±21.73 |
| Rastrigin | 50 | 381.77±75.94 | 279.04±115.55 | 202.29±63.64 | 184.75±61.41 | 188.77±68.81 | 186.22±120.27 | 218.12±101.16 |
| Rastrigin | 100 | 857.95±112.39 | 811.04±131.71 | 777.63±161.02 | 692.34±122.68 | 670.59±108.23 | 684.92±108.10 | 675.76±126.05 |
| Friedman Rank | 7.00 | 5.83 | 3.67 | 2.17 | 3.75 | 2.83 | 2.75 | |
| p | 0.000 | 0.003 | 0.229 | NA | 0.204 | 0.593 | 0.640 | |
图 6
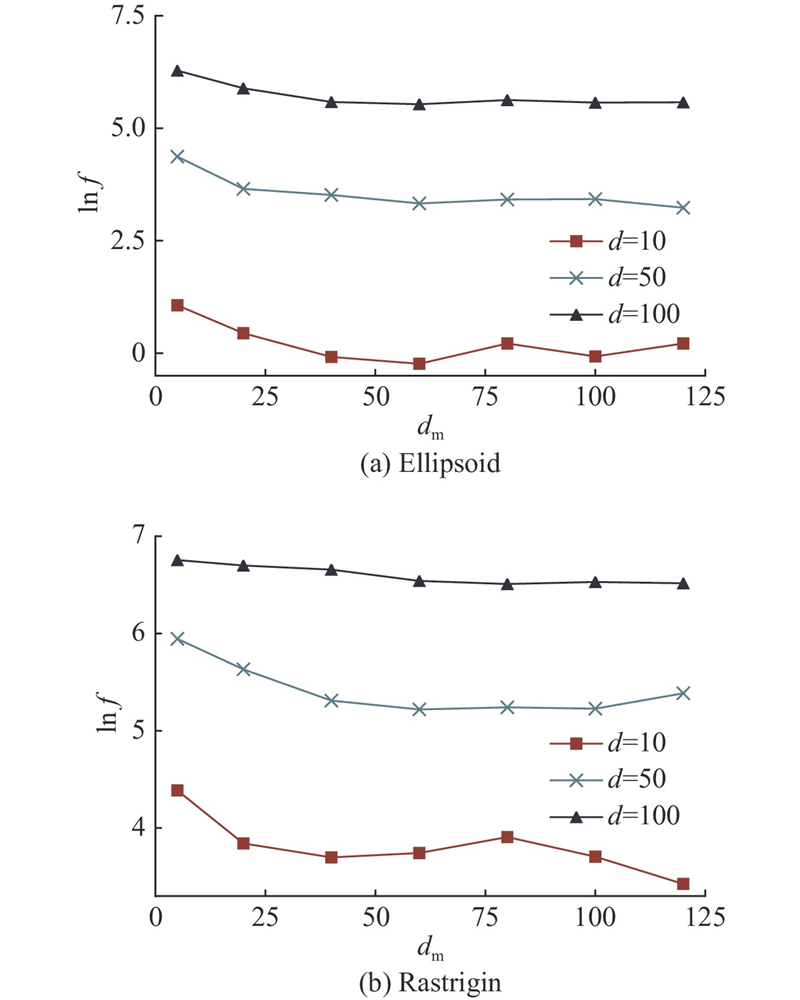
图 6 dm取不同值时DDEA-MKDS的优化结果的变化趋势
Fig.6 Variation trend of optimization result of DDEA-MKDS when dm takes different values
从结果来看,当dm = 60时,DDEA-MKDS的表现最好. dm越大, 采样得到的无标签数据量越多,最终加入原数据集的伪标签数据也越多. 当dm较小时,DDEA-MKDS的性能随着dm的增大而提升,原因是在一定范围内合成数据量的增多会使代理模型的准确率更高. 在dm超过60后,算法的表现变差,性能的变化不再有趋势性.这是因为伪标签数据的标签是由模型预测得到的,与真实值之间存在一定的差异,过多地加入伪标签数据会对进化过程及代理模型的训练产生误导, 因此dm的取值要在合理范围内进行选择.
4. 结 语
针对离线的DDEA在数据量极少时表现差的问题, 本文提出基于多核数据合成的离线小数据驱动的进化算法DDEA-MKDS. 该算法使用结合经验公式与遍历法的隐含层节点数寻优策略,简化算法中使用的RBFN的结构, 以避免模型因小数据产生过拟合,大幅加快训练速度. 该算法提出基于多核学习的数据合成策略和使用轮盘赌的数据选择方法, 弥补离线数据量的不足. 将DDEA-MKDS与5种代表性的离线DDEA在6个基准测试问题上进行对比,结果表明,本文算法在小数据条件下的优化能力和效率显著优于对比算法.实验部分通过DDEA-MKDS与变体算法的对比,证明了原算法中所提策略的有效性,讨论了核函数的选择对算法性能的影响,对算法中的特有参数进行敏感性分析.未来将针对算法在高维小数据问题中的表现进行改善,提出更有效的数据合成策略, 并将算法用于实际的昂贵优化问题的求解.
参考文献
Data-driven evolutionary optimization: an overview and case studies
[J].DOI:10.1109/TEVC.2018.2869001 [本文引用: 2]
Model-based evolutionary algorithms: a short survey
[J].DOI:10.1007/s40747-018-0080-1 [本文引用: 1]
A repository of real-world datasets for data-driven evolutionary multiobjective optimization
[J].DOI:10.1007/s40747-019-00126-2 [本文引用: 1]
Data-driven surrogate-assisted multiobjective evolutionary optimization of a trauma system
[J].DOI:10.1109/TEVC.2016.2555315 [本文引用: 1]
A multiobjective evolutionary algorithm using gaussian process-based inverse modeling
[J].DOI:10.1109/TEVC.2015.2395073 [本文引用: 1]
基于剪枝堆栈泛化的离线数据驱动进化优化
[J].
Offline data driven evolutionary optimization based on pruning stacked generalization
[J].
Offline data-driven evolutionary optimization based on tri-training
[J].DOI:10.1016/j.swevo.2020.100800 [本文引用: 3]
A data-driven surrogate-assisted evolutionary algorithm applied to a many-objective blast furnace optimization problem
[J].DOI:10.1080/10426914.2016.1269923 [本文引用: 1]
Evolutionary computation for expensive optimization: a survey
[J].DOI:10.1007/s11633-022-1317-4 [本文引用: 1]
A surrogate-assisted reference vector guided evolutionary algorithm for computationally expensive many-objective optimization
[J].
Improved generalization in semi-supervised learning: a survey of theoretical results
[J].DOI:10.1109/TPAMI.2022.3198175 [本文引用: 1]
Multiple kernel learning algorithms
[J].
A survey on cooperative co-evolutionary algorithms
[J].DOI:10.1109/TEVC.2018.2868770 [本文引用: 1]
Offline data-driven evolutionary optimization using selective surrogate ensembles
[J].
Tri-training: exploiting unlabeled data using three classifiers
[J].DOI:10.1109/TKDE.2005.186 [本文引用: 1]
Materialized view selection for query performance enhancement using stochastic ranking based cuckoo search algorithm
[J].DOI:10.1142/S0218539320500084 [本文引用: 1]
Contrastive learning: an alternative surrogate for offline data-driven evolutionary computation
[J].DOI:10.1109/TEVC.2022.3170638 [本文引用: 2]
Training with scaled logits to alleviate class-level over-fitting in few-shot learning
[J].DOI:10.1016/j.neucom.2022.12.011 [本文引用: 1]
The impact of functional form complexity on model overfitting for nonlinear mixed-effects models
[J].DOI:10.1080/00273171.2022.2119360 [本文引用: 1]
A step forward in studying the compact genetic algorithm
[J].DOI:10.1162/evco.2006.14.3.277 [本文引用: 1]
BP神经网络隐含层节点数确定方法研究
[J].DOI:10.3969/j.issn.1673-629X.2018.04.007 [本文引用: 2]
Research on method of determining hidden layer nodes in BP neural network
[J].DOI:10.3969/j.issn.1673-629X.2018.04.007 [本文引用: 2]
Study of the magnetic properties of haematite based on spectroscopy and the IPSO-ELM neural network
[J].
A novel kernel-based extreme learning machine with incremental hidden layer nodes
[J].DOI:10.1016/j.ifacol.2020.12.695 [本文引用: 1]
Distribution adaptation and classification framework based on multiple kernel learning for motor imagery BCI illiteracy
[J].DOI:10.3390/s22176572 [本文引用: 1]
Kernel matrix-based heuristic multiple kernel learning
[J].DOI:10.3390/math10122026 [本文引用: 1]
Experimental testing of advanced scatter search designs for global optimization of multimodal functions
[J].DOI:10.1007/s10898-004-1936-z [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}