[1]
KAFFASH S, NGUYEN A T, ZHU J Big data algorithms and applications in intelligent transportation system: a review and bibliometric analysis
[J]. International Journal of Production Economics , 2021 , 231 : 107868
DOI:10.1016/j.ijpe.2020.107868
[本文引用: 1]
[2]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2016 , 39 (6 ): 1137 - 1149
[本文引用: 1]
[3]
LIU W, ANGUELOV D, ERHAN D, et al. Ssd: single shot multibox detector [C]// Computer Vision–ECCV 2016: 14th European Conference . Amsterdam: Springer, 2016: 21-37.
[本文引用: 1]
[4]
LIN T Y, GOYAL P, GIRSHICK R, et al Focal loss for dense object detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 42 (2 ): 2999 - 3007
[本文引用: 1]
[5]
ZHAO Z Q, ZHENG P, XU S T, et al Object detection with deep learning: a review
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2019 , 30 (11 ): 3212 - 3232
DOI:10.1109/TNNLS.2018.2876865
[本文引用: 1]
[6]
邓亚平, 李迎江 YOLO算法及其在自动驾驶场景中目标检测研究综述
[J]. 计算机应用 , 2024 , 44 (6 ): 1949 - 1958
[本文引用: 1]
DENG Yaping, LI Yingjiang Review of YOLO algorithm and its application to object detection in autonomous driving scenes
[J]. Journal of ComputerApplications , 2024 , 44 (6 ): 1949 - 1958
[本文引用: 1]
[7]
ZAIDI S S A, ANSARI M S, ASLAM A, et al A survey of modern deep learning based object detection models
[J]. Digital Signal Processing , 2022 , 126 : 103514
DOI:10.1016/j.dsp.2022.103514
[本文引用: 1]
[8]
王琳毅, 白静, 李文静, 等 YOLO系列目标检测算法研究进展
[J]. 计算机工程与应用 , 2023 , 59 (14 ): 15 - 29
DOI:10.3778/j.issn.1002-8331.2301-0081
[本文引用: 1]
WANG Linyi, BAI Jing, LI Wenjing, et al Research progress of YOLO series target detection algorithms
[J]. Computer Engineering and Applications , 2023 , 59 (14 ): 15 - 29
DOI:10.3778/j.issn.1002-8331.2301-0081
[本文引用: 1]
[9]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[10]
SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 1-9.
[本文引用: 1]
[11]
EVERINGHAM M, VAN GOOL L, WILLIAMS C K, et al The pascal visual object classes (voc) challenge
[J]. International Journal of Computer Vision , 2010 , 88 (2 ): 303 - 338
DOI:10.1007/s11263-009-0275-4
[本文引用: 1]
[12]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 7263-7271.
[本文引用: 1]
[13]
REDMON J, FARHADI A. Yolov3: an incremental improvement [EB/OL]. [2023-01-20]. https://arxiv.org/abs/1804.02767.
[本文引用: 1]
[14]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[15]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2117-2125.
[本文引用: 1]
[16]
RUBY U, YENDAPALLI V Binary cross entropy with deep learning technique for image classification
[J]. Advanced Trends in Computer Science and Engineering , 2020 , 9 (4 ): 5393 - 5397
DOI:10.30534/ijatcse/2020/175942020
[本文引用: 1]
[17]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C]// 13th European Conference of Computer Vision . Zurich: Springer, 2014: 740-755.
[本文引用: 1]
[18]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection [EB/OL]. [2023-01-20]. https://arxiv.org/abs/2004.10934.
[本文引用: 1]
[19]
WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Seattle: IEEE, 2020: 390-391.
[本文引用: 1]
[20]
HE K, ZHANG X, REN S, et al Spatial pyramid pooling in deep convolutional networks for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 37 (9 ): 1904 - 1916
DOI:10.1109/TPAMI.2015.2389824
[本文引用: 1]
[21]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759-8768.
[本文引用: 1]
[22]
ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI Press, 2020: 12993-13000.
[本文引用: 1]
[23]
JOCHER G. YOLOv5 by ultralytics [EB/OL]. (2020-06-09) [2024-04-23]. https://github.com/ultralytics/yolov5.
[本文引用: 1]
[24]
GHIASI G, CUI Y, SRINIVAS A, et al. Simple copy-paste is a strong data augmentation method for instance segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 2918-2928.
[本文引用: 1]
[25]
ZHANG H, CISSE M, DAUPHIN Y N, et al. Mixup: beyond empirical risk minimization [EB/OL]. [2023-01-20]. https://arxiv.org/abs/1710.09412.
[本文引用: 1]
[26]
GE Z, LIU S, WANG F, et al. Yolox: exceeding yolo series in 2021 [EB/OL]. [2023-01-20]. https://arxiv.org/abs/2107.08430.
[本文引用: 1]
[27]
LAW H, DENG J. Cornernet: detecting objects as paired keypoints [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 734-750.
[本文引用: 1]
[28]
DUAN K, BAI S, XIE L, et al. Centernet: keypoint triplets for object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6569-6578.
[本文引用: 1]
[29]
TIAN Z, SHEN C, CHEN H, et al. Fcos: fully convolutional one-stage object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9627-9636.
[本文引用: 1]
[30]
LI C, LI L, JIANG H, et al. YOLOv6: a single-stage object detection framework for industrial applications [EB/OL]. (2022-09-07) [2024-04-23]. https://arxiv.org/abs/2209.02976.
[本文引用: 1]
[31]
DING X, ZHANG X, MA N, et al. Repvgg: making vgg-style convnets great again [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 13733-13742.
[本文引用: 1]
[32]
ZHANG H, WANG Y, DAYOUB F, et al. Varifocalnet: an iou-aware dense object detector [C]/ /Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 8514-8523.
[本文引用: 1]
[33]
GEVORGYAN Z. SIoU loss: more powerful learning for bounding box regression [EB/OL]. (2022-05-25) [2024-04-23]. https://arxiv.org/abs/2205.12740.
[本文引用: 1]
[34]
REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: a metric and a loss for bounding box regression [C]/ /Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seoul: IEEE, 2019: 658-666.
[本文引用: 1]
[35]
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 7464-7475.
[本文引用: 1]
[36]
WANG C Y, LIAO H Y M, YEH I H. Designing network design strategies through gradient path analysis [EB/OL]. (2022-11-09) [2024-04-23]. https://arxiv.org/abs/2211.04800.
[本文引用: 1]
[37]
JOCHER G, CHAURASIA A, QIU J. YOLO by ultralytics [EB/OL]. (2023-01-01) [2024-04-23]. https://github.com/ultralytics/ultralytics.
[本文引用: 1]
[38]
LI X, WANG W, WU L, et al. Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection [EB/OL]. [2023-01-20]. https://proceedings.neurips.cc/paper_files/paper/2020/file/f0bda020d2470f2e74990a07a607ebd9-Paper.pdf.
[本文引用: 1]
[39]
DU L, CHEN X, PEI Z, et al Improved real-time traffic obstacle detection and classification method applied in intelligent and connected vehicles in mixed traffic environment
[J]. Journal of Advanced Transportation , 2022 , 2022 (1 ): 2259113
[本文引用: 2]
[40]
ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein generative adversarial networks [C]// International Conference on Machine Learning . Sydney: PMLR, 2017: 214-223.
[本文引用: 1]
[41]
CAO J, ZHUANG Y, WANG M, et al. Pedestrian detection algorithm based on ViBe and YOLO [C]// Proceedings of the 5th International Conference on Video and Image Processing . New York: ACM, 2021: 92-97.
[本文引用: 2]
[42]
BARNICH O, VAN DROOGENBROECK M ViBe: a universal background subtraction algorithm for video sequences
[J]. IEEE Transactions on Image Processing , 2010 , 20 (6 ): 1709 - 1724
[本文引用: 1]
[43]
CHEN X, JIA Y, TONG X, et al Research on pedestrian detection and deepsort tracking in front of intelligent vehicle based on deep learning
[J]. Sustainability , 2022 , 14 (15 ): 9281
DOI:10.3390/su14159281
[本文引用: 2]
[44]
WOJKE N, BEWLEY A, PAULUS D. Simple online and realtime tracking with a deep association metric [C]// IEEE International Conference on Image Processing . Beijing: IEEE, 2017: 3645-3649.
[本文引用: 1]
[45]
CHAVIS C, NYARKO K, CIRILLO C, et al. A comparative study of pedestrian crossing behavior and safety in Baltimore, MD and Washington, DC using video surveillance [R]. Baltimore: Morgan State University, 2023.
[本文引用: 2]
[46]
LIU X, ZHU Y. Passenger flow modeling and simulation in transit stations [R]. Newark: Rutgers University, 2022.
[本文引用: 2]
[47]
AURENHAMMER F, KLEIN R Voronoi diagrams
[J]. Handbook of Computational Geometry , 2000 , 5 (10 ): 201 - 290
[本文引用: 1]
[48]
YOGESH R, RITHEESH V, REDDY S, et al. Driver drowsiness detection and alert system using YOLO [C]// International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems . Chennai: IEEE, 2022: 1-6.
[本文引用: 2]
[49]
方浩杰, 董红召, 林少轩, 等 多特征融合的驾驶员疲劳状态检测方法
[J]. 浙江大学学报: 工学版 , 2023 , 57 (7 ): 1287 - 1296
[本文引用: 2]
FANG Haojie, DONG Hongzhao, LIN Shaoxuan, et al Driver fatigue state detection method based on multi-feature fusion
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (7 ): 1287 - 1296
[本文引用: 2]
[50]
LIU S, WANG Y, YU Q, et al CEAM-YOLOv7: improved YOLOv7 based on channel expansion and attention mechanism for driver distraction behavior detection
[J]. IEEE Access , 2022 , 10 : 129116 - 129124
DOI:10.1109/ACCESS.2022.3228331
[本文引用: 2]
[51]
LIU Y, SHAO Z, HOFFMANN N. Global attention mechanism: retain information to enhance channel-spatial interactions [EB/OL]. (2021-12-10) [2024-04-23]. https://arxiv.org/abs/2112.05561.
[本文引用: 1]
[52]
ZHAO J, LI C, XU Z, et al. Detection of passenger flow on and off buses based on video images and YOLO algorithm [EB/OL]. [2023-01-20]. https://link.springer.com/article/10.1007/s11042-021-10747-w.
[本文引用: 2]
[53]
LI Y, WANG J, HUANG J, et al Research on deep learning automatic vehicle recognition algorithm based on RES-YOLO model
[J]. Sensors , 2022 , 22 (10 ): 3783
DOI:10.3390/s22103783
[本文引用: 2]
[54]
YU F, CHEN H, WANG X, et al. Bdd100k: a diverse driving dataset for heterogeneous multitask learning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2636-2645.
[本文引用: 1]
[55]
叶佳林, 苏子毅, 马浩炎, 等 改进YOLOv3的非机动车检测与识别方法
[J]. 计算机工程与应用 , 2021 , 57 (1 ): 194 - 199
DOI:10.3778/j.issn.1002-8331.2005-0343
[本文引用: 2]
YE Jialin, SU Ziyi, MA Haoyan, et al Improved YOLOv3 non-motor vehicles detection and recognition method
[J]. Computer Engineering and Applications , 2021 , 57 (1 ): 194 - 199
DOI:10.3778/j.issn.1002-8331.2005-0343
[本文引用: 2]
[56]
RAJ V S, SAI J V M, YOGESH N L, et al. Smart traffic control for emergency vehicles prioritization using video and audio processing [C]// 6th International Conference on Intelligent Computing and Control Systems . Madurai: IEEE, 2022: 1588-1593.
[本文引用: 2]
[57]
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2014-09-04) [2024-04-23]. https://arxiv.org/abs/1409.1556.
[本文引用: 1]
[58]
SIMONY M, MILZY S, AMENDEY K, et al. Complex-yolo: an euler-region-proposal for real-time 3d object detection on point clouds [C]/ /Proceedings of the European Conference on Computer Vision Workshops. Munich: Springer, 2018: 197-209.
[本文引用: 2]
[59]
AZIMJONOV J, ÖZMEN A A real-time vehicle detection and a novel vehicle tracking systems for estimating and monitoring traffic flow on highways
[J]. Advanced Engineering Informatics , 2021 , 50 : 101393
DOI:10.1016/j.aei.2021.101393
[本文引用: 2]
[60]
LIN C J, JHANG J Y Intelligent traffic-monitoring system based on YOLO and convolutional fuzzy neural networks
[J]. IEEE Access , 2022 , 10 : 14120 - 14133
DOI:10.1109/ACCESS.2022.3147866
[本文引用: 2]
[62]
CVIJETIĆ A, DJUKANOVIĆ S, PERUNIČIĆ A. Deep learning-based vehicle speed estimation using the YOLO detector and 1D-CNN [C]// 27th International Conference on Information Technology . Žabljak: IEEE, 2023: 1-4.
[本文引用: 2]
[63]
RAHMAN Z, AMI A M, ULLAH M A. A real-time wrong-way vehicle detection based on YOLO and centroid tracking [C]// 2020 IEEE Region 10 Symposium . Dhaka: IEEE, 2020: 916-920.
[本文引用: 2]
[64]
SABRY K, EMAD M. Road traffic accidents detection based on crash estimation [C]// 17th International Computer Engineering Conference . Cairo: IEEE, 2021: 63-68.
[本文引用: 2]
[65]
BOLME D S, BEVERIDGE J R, DRAPER B A, et al. Visual object tracking using adaptive correlation filters [C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition . San Francisco: IEEE, 2010: 2544-2550.
[本文引用: 1]
[66]
ARCEDA V M, FABIÁN K F, GUTÍERREZ J C. Real time violence detection in video [C]// The Institution of Engineering and Technology Conference Proceedings. Talca: IEEE, 2016.
[本文引用: 1]
[67]
GEIGER A, LENZ P, STILLER C, et al Vision meets robotics: the kitti dataset
[J]. The International Journal of Robotics Research , 2013 , 32 (11 ): 1231 - 1237
DOI:10.1177/0278364913491297
[本文引用: 1]
[68]
DONG Z, WU Y, PEI M, et al Vehicle type classification using a semisupervised convolutional neural network
[J]. IEEE Transactions on Intelligent Transportation Systems , 2015 , 16 (4 ): 2247 - 2256
DOI:10.1109/TITS.2015.2402438
[本文引用: 1]
[69]
GUERRERO-GÓMEZ-OLMEDO R, LÓPEZ-SASTRE R J, MALDONADO-BASCÓN S, et al. Vehicle tracking by simultaneous detection and viewpoint estimation [C]// Natural and Artificial Computation in Engineering and Medical Applications: 5th International Work-Conference on the Interplay Between Natural and Artificial Computation . Mallorca: Springer, 2013: 306-316.
[本文引用: 1]
[70]
DJUKANOVIĆ S, BULATOVIĆ N, ČAVOR I. A dataset for audio-video based vehicle speed estimation [C]// 30th Telecommunications Forum . Belgrade: IEEE, 2022: 1-4.
[本文引用: 1]
[71]
SONG W, SUANDI S A Tsr-yolo: a Chinese traffic sign recognition algorithm for intelligent vehicles in complex scenes
[J]. Sensors , 2023 , 23 (2 ): 749
DOI:10.3390/s23020749
[本文引用: 2]
[72]
ZHANG J, ZOU X, KUANG L D, et al. CCTSDB 2021: a more comprehensive traffic sign detection benchmark [EB/OL]. [2023-01-20]. https://centaur.reading.ac.uk/106129/1/12-23.pdf.
[本文引用: 1]
[74]
BEHRENDT K, NOVAK L, BOTROS R. A deep learning approach to traffic lights: detection, tracking, and classification [C]// IEEE International Conference on Robotics and Automation . Singapore: IEEE, 2017: 1370-1377.
[本文引用: 1]
[75]
MII Y, MIYAZAKI R, YOSHIMOTO Y, et al A road marking detection system using partial template matching and region estimation by deep neural network
[J]. Journal of Japan Society for Fuzzy Theory and Intelligent Informatics , 2021 , 33 (1 ): 566 - 571
DOI:10.3156/jsoft.33.1_566
[本文引用: 2]
[76]
CHEN Z, WANG X, ZHANG W, et al Autonomous parking space detection for electric vehicles based on improved YOLOV5-OBB algorithm
[J]. World Electric Vehicle Journal , 2023 , 14 (10 ): 276
DOI:10.3390/wevj14100276
[本文引用: 2]
[77]
HENDRYCKS D, GIMPEL K. Gaussian error linear units (gelus) [EB/OL]. (2016-06-27) [2024-04-23]. https://arxiv.org/abs/1606.08415.
[本文引用: 1]
[78]
HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 13713-13722.
[本文引用: 1]
[79]
董红召, 方浩杰, 张楠 旋转框定位的多尺度再生物品目标检测算法
[J]. 浙江大学学报: 工学版 , 2022 , 56 : 16 - 25
[本文引用: 1]
DONG Hongzhao, FANG Haojie, ZHANG Nan Multi-scale object detection algorithm for recycled objects based on rotating block positioning
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 : 16 - 25
[本文引用: 1]
[80]
YANG X, YAN J. Arbitrary-oriented object detection with circular smooth label [C]// 16th European Conference of Computer Vision . Glasgow: Springer, 2020: 677-694.
[本文引用: 1]
[81]
SRIVASTAVA I. Retraining of object detectors to become suitable for trash detection in the context of autonomous driving [D]. Dresden: Technische Universität Dresden, 2022.
[本文引用: 2]
[82]
WAN F, SUN C, HE H, et al YOLO-LRDD: a lightweight method for road damage detection based on improved YOLOv5s
[J]. EURASIP Journal on Advances in Signal Processing , 2022 , 2022 (1 ): 98
DOI:10.1186/s13634-022-00931-x
[本文引用: 2]
[83]
MA N, ZHANG X, ZHENG H T, et al. Shufflenet v2: practical guidelines for efficient cnn architecture design [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 116-131.
[本文引用: 1]
[84]
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11534-11542.
[本文引用: 1]
[85]
PROENÇA P F, SIMOES P. Taco: trash annotations in context for litter detection [EB/OL]. (2020-03-16) [2024-04-23]. https://arxiv.org/abs/2003.06975.
[本文引用: 1]
[86]
ARYA D, MAEDA H, GHOSH S K, et al RDD2020: an annotated image dataset for automatic road damage detection using deep learning
[J]. Data In Brief , 2021 , 36 : 107133
DOI:10.1016/j.dib.2021.107133
[本文引用: 1]
Big data algorithms and applications in intelligent transportation system: a review and bibliometric analysis
1
2021
... 目标检测是机器视觉的核心技术之一,旨在准确识别和定位图像或视频中的目标物体. 在交通领域,目标检测算法在识别车辆、行人和道路标志等各类交通目标方面发挥着不可或缺的重要作用,为交通监控、事故预防和自动驾驶系统等提供了关键的技术支持[1 ] . 精准识别和实时定位交通目标有助于提升交通系统的安全性、效率和智能化水平. 目标检测技术的不断发展和优化对推动交通领域的创新和进步具有重要意义. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2016
... 随着目标检测技术的持续发展,选择适用的算法对于实现高效、精准的交通场景分析至关重要. YOLO系列算法以其出色的性能表现在交通目标检测中展现出巨大的潜力. 相较于传统的Two-Stage目标检测算法(如Faster R-CNN[2 ] ),YOLO算法将检测任务视作单一的回归问题,通过单次前向传播即可完成检测和定位;传统的Two-Stage方法需要多个网络模块来生成候选框,进行分类和回归操作. 这种单阶段检测机制使得YOLO算法能够更加快速且准确地识别图像中的交通目标. 与其他One-Stage目标检测算法(如SSD[3 ] 、RetinaNet[4 ] )相比,YOLO算法仅通过卷积神经网络对整个图像进行一次性预测[5 ] ,而其他算法需要多次滑动窗口扫描来完成目标检测. 这使得YOLO算法在保持检测速度的同时,具备较高的检测精度和定位准确性,尤其在小目标检测和密集目标场景下表现出色. 结合交通目标检测的需求,选择YOLO算法进行目标检测,不仅能够满足实时性和高效性的要求,还能够保证对交通目标的准确识别和定位. ...
1
... 随着目标检测技术的持续发展,选择适用的算法对于实现高效、精准的交通场景分析至关重要. YOLO系列算法以其出色的性能表现在交通目标检测中展现出巨大的潜力. 相较于传统的Two-Stage目标检测算法(如Faster R-CNN[2 ] ),YOLO算法将检测任务视作单一的回归问题,通过单次前向传播即可完成检测和定位;传统的Two-Stage方法需要多个网络模块来生成候选框,进行分类和回归操作. 这种单阶段检测机制使得YOLO算法能够更加快速且准确地识别图像中的交通目标. 与其他One-Stage目标检测算法(如SSD[3 ] 、RetinaNet[4 ] )相比,YOLO算法仅通过卷积神经网络对整个图像进行一次性预测[5 ] ,而其他算法需要多次滑动窗口扫描来完成目标检测. 这使得YOLO算法在保持检测速度的同时,具备较高的检测精度和定位准确性,尤其在小目标检测和密集目标场景下表现出色. 结合交通目标检测的需求,选择YOLO算法进行目标检测,不仅能够满足实时性和高效性的要求,还能够保证对交通目标的准确识别和定位. ...
Focal loss for dense object detection
1
2017
... 随着目标检测技术的持续发展,选择适用的算法对于实现高效、精准的交通场景分析至关重要. YOLO系列算法以其出色的性能表现在交通目标检测中展现出巨大的潜力. 相较于传统的Two-Stage目标检测算法(如Faster R-CNN[2 ] ),YOLO算法将检测任务视作单一的回归问题,通过单次前向传播即可完成检测和定位;传统的Two-Stage方法需要多个网络模块来生成候选框,进行分类和回归操作. 这种单阶段检测机制使得YOLO算法能够更加快速且准确地识别图像中的交通目标. 与其他One-Stage目标检测算法(如SSD[3 ] 、RetinaNet[4 ] )相比,YOLO算法仅通过卷积神经网络对整个图像进行一次性预测[5 ] ,而其他算法需要多次滑动窗口扫描来完成目标检测. 这使得YOLO算法在保持检测速度的同时,具备较高的检测精度和定位准确性,尤其在小目标检测和密集目标场景下表现出色. 结合交通目标检测的需求,选择YOLO算法进行目标检测,不仅能够满足实时性和高效性的要求,还能够保证对交通目标的准确识别和定位. ...
Object detection with deep learning: a review
1
2019
... 随着目标检测技术的持续发展,选择适用的算法对于实现高效、精准的交通场景分析至关重要. YOLO系列算法以其出色的性能表现在交通目标检测中展现出巨大的潜力. 相较于传统的Two-Stage目标检测算法(如Faster R-CNN[2 ] ),YOLO算法将检测任务视作单一的回归问题,通过单次前向传播即可完成检测和定位;传统的Two-Stage方法需要多个网络模块来生成候选框,进行分类和回归操作. 这种单阶段检测机制使得YOLO算法能够更加快速且准确地识别图像中的交通目标. 与其他One-Stage目标检测算法(如SSD[3 ] 、RetinaNet[4 ] )相比,YOLO算法仅通过卷积神经网络对整个图像进行一次性预测[5 ] ,而其他算法需要多次滑动窗口扫描来完成目标检测. 这使得YOLO算法在保持检测速度的同时,具备较高的检测精度和定位准确性,尤其在小目标检测和密集目标场景下表现出色. 结合交通目标检测的需求,选择YOLO算法进行目标检测,不仅能够满足实时性和高效性的要求,还能够保证对交通目标的准确识别和定位. ...
YOLO算法及其在自动驾驶场景中目标检测研究综述
1
2024
... 目前,已有一些综述研究探讨了YOLO算法在车辆、行人、交通标识等交通目标检测方面的应用现状[6 ] . 仅从单一目标的视角可能限制了对各种类型交通目标的全面理解. 针对该问题,从交通系统的三大核心要素“人-车-路”出发,综合评述了YOLO算法在交通目标检测中的应用和研究进展. 通过将交通对象分为“人-车-路”3类,以这种综合性的分类视角对交通目标检测进行综述,能够更全面地理解和评估算法在实际交通场景中的表现和应用,有助于从真实交通场景的需求出发去更好地理解算法在实际应用中面临的挑战和发展的潜力. ...
YOLO算法及其在自动驾驶场景中目标检测研究综述
1
2024
... 目前,已有一些综述研究探讨了YOLO算法在车辆、行人、交通标识等交通目标检测方面的应用现状[6 ] . 仅从单一目标的视角可能限制了对各种类型交通目标的全面理解. 针对该问题,从交通系统的三大核心要素“人-车-路”出发,综合评述了YOLO算法在交通目标检测中的应用和研究进展. 通过将交通对象分为“人-车-路”3类,以这种综合性的分类视角对交通目标检测进行综述,能够更全面地理解和评估算法在实际交通场景中的表现和应用,有助于从真实交通场景的需求出发去更好地理解算法在实际应用中面临的挑战和发展的潜力. ...
A survey of modern deep learning based object detection models
1
2022
... 在目标检测领域,评价算法性能通常依赖于标准化的评价指标,以便研究者和开发者理解算法效果并进行客观比较. 为了方便定义这些指标,将检测目标分为正样本和负样本,预测结果分为真阳性(true positive, TP)、假阳性(false positive, FP)、真阴性(true negative, TN)和假阴性(false negative, FN). 以下是YOLO算法中常用的关键评价指标[7 ] . ...
YOLO系列目标检测算法研究进展
1
2023
... 如图1 所示,自YOLO算法首次提出以来,该算法经历了多个版本的迭代和改进. 每个版本在性能和效率方面都有所提升,这是复杂交通场景目标检测的迫切需求. 研究者们已对YOLO系列算法的演变进行了细致的梳理[8 ] ,如图2 、3 所示为对YOLOv1至v8各版本的主要发展历程和结构变化的进一步总结和更新. ...
YOLO系列目标检测算法研究进展
1
2023
... 如图1 所示,自YOLO算法首次提出以来,该算法经历了多个版本的迭代和改进. 每个版本在性能和效率方面都有所提升,这是复杂交通场景目标检测的迫切需求. 研究者们已对YOLO系列算法的演变进行了细致的梳理[8 ] ,如图2 、3 所示为对YOLOv1至v8各版本的主要发展历程和结构变化的进一步总结和更新. ...
1
... 如图2 (a)所示,Redmon等[9 ] 提出YOLOv1网络,它的检测原理如下. 在输入阶段,将输入图像划分成$ S \times S $ [10 ] 作为Backbone来提取图像特征,通过2个全连接层来生成预测特征图,特征图中每个网格单元包含多个预测边界框(bounding boxes). 在预测阶段,通过对特征图中每个网格的特征向量应用NMS来剔除低置信度的预测框,保留置信度与类别概率乘积最高的预测框作为最终的预测结果. YOLOv1的简单架构和创新的全图像一次性回归方法使它兼具高识别准确率和实时性能,在PASCAL VOC数据集[11 ] 中的mAP和检测速度分别为63.4%和45 帧/s. ...
1
... 如图2 (a)所示,Redmon等[9 ] 提出YOLOv1网络,它的检测原理如下. 在输入阶段,将输入图像划分成$ S \times S $ [10 ] 作为Backbone来提取图像特征,通过2个全连接层来生成预测特征图,特征图中每个网格单元包含多个预测边界框(bounding boxes). 在预测阶段,通过对特征图中每个网格的特征向量应用NMS来剔除低置信度的预测框,保留置信度与类别概率乘积最高的预测框作为最终的预测结果. YOLOv1的简单架构和创新的全图像一次性回归方法使它兼具高识别准确率和实时性能,在PASCAL VOC数据集[11 ] 中的mAP和检测速度分别为63.4%和45 帧/s. ...
The pascal visual object classes (voc) challenge
1
2010
... 如图2 (a)所示,Redmon等[9 ] 提出YOLOv1网络,它的检测原理如下. 在输入阶段,将输入图像划分成$ S \times S $ [10 ] 作为Backbone来提取图像特征,通过2个全连接层来生成预测特征图,特征图中每个网格单元包含多个预测边界框(bounding boxes). 在预测阶段,通过对特征图中每个网格的特征向量应用NMS来剔除低置信度的预测框,保留置信度与类别概率乘积最高的预测框作为最终的预测结果. YOLOv1的简单架构和创新的全图像一次性回归方法使它兼具高识别准确率和实时性能,在PASCAL VOC数据集[11 ] 中的mAP和检测速度分别为63.4%和45 帧/s. ...
1
... 由于YOLOv1每个网格单元最多只能检测2个同类对象,在检测多个临近小目标时导致失准. Redmon等[12 ] 提出YOLOv2网络. 如图2 (b)所示,它在YOLOv1的基础上作出了如下改进. 在输入阶段,采用多尺度训练方法,以增强模型对不同尺度对象的识别能力,在每个网格单元中划分了多个预定义的锚框(anchor box). 在特征提取阶段,YOLOv2将backbone替换为更轻量化的Darknet-19,去除全连接层以适应不同尺寸的图像输入,引入批归一化层(batch normalization)和LeakyReLu激活函数组成CBL模块. 在预测阶段,结合锚框与特征图直接预测边界框的位置坐标,显著提高了检测准确性和效率. 这些改进使得YOLOv2在PASCAL VOC数据集上达到了78.6%的AP. ...
1
... 尽管YOLOv2引入了多尺度训练,但它仍然只针对单一尺度的特征图进行预测,限制了其对不同尺寸和比例的物体的处理能力. Redmon等[13 ] 提出YOLO v3网络,如图2 (c)所示,主要改进如下. 在特征提取阶段,backbone采用包含ResNet (residual network)[14 ] 残差连接结构的Darknet-53,以提升特征提取能力. 此外,YOLO v3借鉴特征金字塔网络(feature pyramid network, FPN)[15 ] 形成Neck层,用于融合和细化backbone提取的不同尺度的空间和语义特征. 在预测阶段,采用二元交叉熵 (binary cross entropy, BCE)[16 ] 来训练logistic多标签分类器,从3个不同的尺度预测边界框. YOLOv3将验证数据集从PASCAL VOC数据集更换为MS COCO数据集[17 ] ,这些改进使得它在MS COCO数据集上实现了36.2%的AP和20 帧/s的检测速度. ...
1
... 尽管YOLOv2引入了多尺度训练,但它仍然只针对单一尺度的特征图进行预测,限制了其对不同尺寸和比例的物体的处理能力. Redmon等[13 ] 提出YOLO v3网络,如图2 (c)所示,主要改进如下. 在特征提取阶段,backbone采用包含ResNet (residual network)[14 ] 残差连接结构的Darknet-53,以提升特征提取能力. 此外,YOLO v3借鉴特征金字塔网络(feature pyramid network, FPN)[15 ] 形成Neck层,用于融合和细化backbone提取的不同尺度的空间和语义特征. 在预测阶段,采用二元交叉熵 (binary cross entropy, BCE)[16 ] 来训练logistic多标签分类器,从3个不同的尺度预测边界框. YOLOv3将验证数据集从PASCAL VOC数据集更换为MS COCO数据集[17 ] ,这些改进使得它在MS COCO数据集上实现了36.2%的AP和20 帧/s的检测速度. ...
1
... 尽管YOLOv2引入了多尺度训练,但它仍然只针对单一尺度的特征图进行预测,限制了其对不同尺寸和比例的物体的处理能力. Redmon等[13 ] 提出YOLO v3网络,如图2 (c)所示,主要改进如下. 在特征提取阶段,backbone采用包含ResNet (residual network)[14 ] 残差连接结构的Darknet-53,以提升特征提取能力. 此外,YOLO v3借鉴特征金字塔网络(feature pyramid network, FPN)[15 ] 形成Neck层,用于融合和细化backbone提取的不同尺度的空间和语义特征. 在预测阶段,采用二元交叉熵 (binary cross entropy, BCE)[16 ] 来训练logistic多标签分类器,从3个不同的尺度预测边界框. YOLOv3将验证数据集从PASCAL VOC数据集更换为MS COCO数据集[17 ] ,这些改进使得它在MS COCO数据集上实现了36.2%的AP和20 帧/s的检测速度. ...
Binary cross entropy with deep learning technique for image classification
1
2020
... 尽管YOLOv2引入了多尺度训练,但它仍然只针对单一尺度的特征图进行预测,限制了其对不同尺寸和比例的物体的处理能力. Redmon等[13 ] 提出YOLO v3网络,如图2 (c)所示,主要改进如下. 在特征提取阶段,backbone采用包含ResNet (residual network)[14 ] 残差连接结构的Darknet-53,以提升特征提取能力. 此外,YOLO v3借鉴特征金字塔网络(feature pyramid network, FPN)[15 ] 形成Neck层,用于融合和细化backbone提取的不同尺度的空间和语义特征. 在预测阶段,采用二元交叉熵 (binary cross entropy, BCE)[16 ] 来训练logistic多标签分类器,从3个不同的尺度预测边界框. YOLOv3将验证数据集从PASCAL VOC数据集更换为MS COCO数据集[17 ] ,这些改进使得它在MS COCO数据集上实现了36.2%的AP和20 帧/s的检测速度. ...
1
... 尽管YOLOv2引入了多尺度训练,但它仍然只针对单一尺度的特征图进行预测,限制了其对不同尺寸和比例的物体的处理能力. Redmon等[13 ] 提出YOLO v3网络,如图2 (c)所示,主要改进如下. 在特征提取阶段,backbone采用包含ResNet (residual network)[14 ] 残差连接结构的Darknet-53,以提升特征提取能力. 此外,YOLO v3借鉴特征金字塔网络(feature pyramid network, FPN)[15 ] 形成Neck层,用于融合和细化backbone提取的不同尺度的空间和语义特征. 在预测阶段,采用二元交叉熵 (binary cross entropy, BCE)[16 ] 来训练logistic多标签分类器,从3个不同的尺度预测边界框. YOLOv3将验证数据集从PASCAL VOC数据集更换为MS COCO数据集[17 ] ,这些改进使得它在MS COCO数据集上实现了36.2%的AP和20 帧/s的检测速度. ...
1
... Bochkovskiy等[18 ] 提出YOLOv4网络,如图3 (a)所示,它的改进方法如下. 在输入阶段,采用Mosaic数据增强技术来增强对不同上下文中对象的检测能力,引入自我对抗训练(self-adversarial training, SAT),提高模型对扰动的鲁棒性. 在特征提取阶段,采用CSPD Darknet53作为Backbone,通过跨阶段局部网络(cross stage partial,CSP)[19 ] 分割并融合特征图. 在neck层引入空间金字塔池化块(spatial pyramid pooling,SPP)[20 ] 和路径聚合网络(path aggregation network,PAN)[21 ] ,提高模型对多尺度目标的感知能力. 在预测阶段,引入CIoU(complete-IoU)损失[22 ] 来更准确地关注被测对象的位置、大小和形状的一致性. 这些改进使得YOLOv4在MS COCO数据集上达到43.5%的AP和超过50 帧/s的检测速度. ...
1
... Bochkovskiy等[18 ] 提出YOLOv4网络,如图3 (a)所示,它的改进方法如下. 在输入阶段,采用Mosaic数据增强技术来增强对不同上下文中对象的检测能力,引入自我对抗训练(self-adversarial training, SAT),提高模型对扰动的鲁棒性. 在特征提取阶段,采用CSPD Darknet53作为Backbone,通过跨阶段局部网络(cross stage partial,CSP)[19 ] 分割并融合特征图. 在neck层引入空间金字塔池化块(spatial pyramid pooling,SPP)[20 ] 和路径聚合网络(path aggregation network,PAN)[21 ] ,提高模型对多尺度目标的感知能力. 在预测阶段,引入CIoU(complete-IoU)损失[22 ] 来更准确地关注被测对象的位置、大小和形状的一致性. 这些改进使得YOLOv4在MS COCO数据集上达到43.5%的AP和超过50 帧/s的检测速度. ...
Spatial pyramid pooling in deep convolutional networks for visual recognition
1
2015
... Bochkovskiy等[18 ] 提出YOLOv4网络,如图3 (a)所示,它的改进方法如下. 在输入阶段,采用Mosaic数据增强技术来增强对不同上下文中对象的检测能力,引入自我对抗训练(self-adversarial training, SAT),提高模型对扰动的鲁棒性. 在特征提取阶段,采用CSPD Darknet53作为Backbone,通过跨阶段局部网络(cross stage partial,CSP)[19 ] 分割并融合特征图. 在neck层引入空间金字塔池化块(spatial pyramid pooling,SPP)[20 ] 和路径聚合网络(path aggregation network,PAN)[21 ] ,提高模型对多尺度目标的感知能力. 在预测阶段,引入CIoU(complete-IoU)损失[22 ] 来更准确地关注被测对象的位置、大小和形状的一致性. 这些改进使得YOLOv4在MS COCO数据集上达到43.5%的AP和超过50 帧/s的检测速度. ...
1
... Bochkovskiy等[18 ] 提出YOLOv4网络,如图3 (a)所示,它的改进方法如下. 在输入阶段,采用Mosaic数据增强技术来增强对不同上下文中对象的检测能力,引入自我对抗训练(self-adversarial training, SAT),提高模型对扰动的鲁棒性. 在特征提取阶段,采用CSPD Darknet53作为Backbone,通过跨阶段局部网络(cross stage partial,CSP)[19 ] 分割并融合特征图. 在neck层引入空间金字塔池化块(spatial pyramid pooling,SPP)[20 ] 和路径聚合网络(path aggregation network,PAN)[21 ] ,提高模型对多尺度目标的感知能力. 在预测阶段,引入CIoU(complete-IoU)损失[22 ] 来更准确地关注被测对象的位置、大小和形状的一致性. 这些改进使得YOLOv4在MS COCO数据集上达到43.5%的AP和超过50 帧/s的检测速度. ...
1
... Bochkovskiy等[18 ] 提出YOLOv4网络,如图3 (a)所示,它的改进方法如下. 在输入阶段,采用Mosaic数据增强技术来增强对不同上下文中对象的检测能力,引入自我对抗训练(self-adversarial training, SAT),提高模型对扰动的鲁棒性. 在特征提取阶段,采用CSPD Darknet53作为Backbone,通过跨阶段局部网络(cross stage partial,CSP)[19 ] 分割并融合特征图. 在neck层引入空间金字塔池化块(spatial pyramid pooling,SPP)[20 ] 和路径聚合网络(path aggregation network,PAN)[21 ] ,提高模型对多尺度目标的感知能力. 在预测阶段,引入CIoU(complete-IoU)损失[22 ] 来更准确地关注被测对象的位置、大小和形状的一致性. 这些改进使得YOLOv4在MS COCO数据集上达到43.5%的AP和超过50 帧/s的检测速度. ...
1
... Jocher[23 ] 发布了YOLOv5网络. 如图3 (b)所示,它的改进方法如下. 在输入阶段,同时使用Mosaic、copy paste[24 ] 、MixUp[25 ] 等多种数据增强技术,加强对小目标和类别分布不均衡数据的检测效果. 引入自适应锚框算法(autoanchor)和图像自适应缩放技术,确保模型能够准确识别各种尺度和比例的对象. 在特征提取阶段,结合Focus模块和CSPDarknet53网络作为Backbone,以优化模型计算效率. 在Neck层引入CSP模块,加强网络特征融合的能力. YOLOv5在MS COCO数据集上实现了55.8%的AP. ...
1
... Jocher[23 ] 发布了YOLOv5网络. 如图3 (b)所示,它的改进方法如下. 在输入阶段,同时使用Mosaic、copy paste[24 ] 、MixUp[25 ] 等多种数据增强技术,加强对小目标和类别分布不均衡数据的检测效果. 引入自适应锚框算法(autoanchor)和图像自适应缩放技术,确保模型能够准确识别各种尺度和比例的对象. 在特征提取阶段,结合Focus模块和CSPDarknet53网络作为Backbone,以优化模型计算效率. 在Neck层引入CSP模块,加强网络特征融合的能力. YOLOv5在MS COCO数据集上实现了55.8%的AP. ...
1
... Jocher[23 ] 发布了YOLOv5网络. 如图3 (b)所示,它的改进方法如下. 在输入阶段,同时使用Mosaic、copy paste[24 ] 、MixUp[25 ] 等多种数据增强技术,加强对小目标和类别分布不均衡数据的检测效果. 引入自适应锚框算法(autoanchor)和图像自适应缩放技术,确保模型能够准确识别各种尺度和比例的对象. 在特征提取阶段,结合Focus模块和CSPDarknet53网络作为Backbone,以优化模型计算效率. 在Neck层引入CSP模块,加强网络特征融合的能力. YOLOv5在MS COCO数据集上实现了55.8%的AP. ...
1
... Ge等[26 ] 提出YOLOX网络,如图3 (c)所示,它的改进方法如下. 在输入阶段,采用与CornerNet[27 ] 、CenterNet[28 ] 和FCOS[29 ] 等检测器相似的无锚框结构来简化模型的训练与预测过程. 在特征提取阶段,Neck层被简化为由FPN模块和PAN模块组合而成的结构. 在预测阶段,使用Decoupled head解耦头结构,使分类、定位和置信度预测由不同的卷积层来处理,以提升整体的检测性能. YOLOX在MS COCO数据集上实现了50.1%的AP和68.9 帧/s的检测速度. ...
1
... Ge等[26 ] 提出YOLOX网络,如图3 (c)所示,它的改进方法如下. 在输入阶段,采用与CornerNet[27 ] 、CenterNet[28 ] 和FCOS[29 ] 等检测器相似的无锚框结构来简化模型的训练与预测过程. 在特征提取阶段,Neck层被简化为由FPN模块和PAN模块组合而成的结构. 在预测阶段,使用Decoupled head解耦头结构,使分类、定位和置信度预测由不同的卷积层来处理,以提升整体的检测性能. YOLOX在MS COCO数据集上实现了50.1%的AP和68.9 帧/s的检测速度. ...
1
... Ge等[26 ] 提出YOLOX网络,如图3 (c)所示,它的改进方法如下. 在输入阶段,采用与CornerNet[27 ] 、CenterNet[28 ] 和FCOS[29 ] 等检测器相似的无锚框结构来简化模型的训练与预测过程. 在特征提取阶段,Neck层被简化为由FPN模块和PAN模块组合而成的结构. 在预测阶段,使用Decoupled head解耦头结构,使分类、定位和置信度预测由不同的卷积层来处理,以提升整体的检测性能. YOLOX在MS COCO数据集上实现了50.1%的AP和68.9 帧/s的检测速度. ...
1
... Ge等[26 ] 提出YOLOX网络,如图3 (c)所示,它的改进方法如下. 在输入阶段,采用与CornerNet[27 ] 、CenterNet[28 ] 和FCOS[29 ] 等检测器相似的无锚框结构来简化模型的训练与预测过程. 在特征提取阶段,Neck层被简化为由FPN模块和PAN模块组合而成的结构. 在预测阶段,使用Decoupled head解耦头结构,使分类、定位和置信度预测由不同的卷积层来处理,以提升整体的检测性能. YOLOX在MS COCO数据集上实现了50.1%的AP和68.9 帧/s的检测速度. ...
1
... Li等[30 ] 提出YOLOv6网络,如图3 (d)所示,它的改进方法如下. 在特征提取阶段,基于可重参化的RepVGG[31 ] 设计EfficientRep和Rep-PAN分别作为Backbone和Neck层,旨在高效利用GPU的计算资源. 在预测阶段,设计Efficient Decoupled head解耦头,以进一步降低计算成本. 引入VariFocal[32 ] 分类损失和SIoU[33 ] /GIoU[34 ] 回归损失,以提高检测的精度和效率. YOLOv6在MS COCO数据集上实现了57.2%的AP和29 帧/s的检测速度. ...
1
... Li等[30 ] 提出YOLOv6网络,如图3 (d)所示,它的改进方法如下. 在特征提取阶段,基于可重参化的RepVGG[31 ] 设计EfficientRep和Rep-PAN分别作为Backbone和Neck层,旨在高效利用GPU的计算资源. 在预测阶段,设计Efficient Decoupled head解耦头,以进一步降低计算成本. 引入VariFocal[32 ] 分类损失和SIoU[33 ] /GIoU[34 ] 回归损失,以提高检测的精度和效率. YOLOv6在MS COCO数据集上实现了57.2%的AP和29 帧/s的检测速度. ...
1
... Li等[30 ] 提出YOLOv6网络,如图3 (d)所示,它的改进方法如下. 在特征提取阶段,基于可重参化的RepVGG[31 ] 设计EfficientRep和Rep-PAN分别作为Backbone和Neck层,旨在高效利用GPU的计算资源. 在预测阶段,设计Efficient Decoupled head解耦头,以进一步降低计算成本. 引入VariFocal[32 ] 分类损失和SIoU[33 ] /GIoU[34 ] 回归损失,以提高检测的精度和效率. YOLOv6在MS COCO数据集上实现了57.2%的AP和29 帧/s的检测速度. ...
1
... Li等[30 ] 提出YOLOv6网络,如图3 (d)所示,它的改进方法如下. 在特征提取阶段,基于可重参化的RepVGG[31 ] 设计EfficientRep和Rep-PAN分别作为Backbone和Neck层,旨在高效利用GPU的计算资源. 在预测阶段,设计Efficient Decoupled head解耦头,以进一步降低计算成本. 引入VariFocal[32 ] 分类损失和SIoU[33 ] /GIoU[34 ] 回归损失,以提高检测的精度和效率. YOLOv6在MS COCO数据集上实现了57.2%的AP和29 帧/s的检测速度. ...
1
... Li等[30 ] 提出YOLOv6网络,如图3 (d)所示,它的改进方法如下. 在特征提取阶段,基于可重参化的RepVGG[31 ] 设计EfficientRep和Rep-PAN分别作为Backbone和Neck层,旨在高效利用GPU的计算资源. 在预测阶段,设计Efficient Decoupled head解耦头,以进一步降低计算成本. 引入VariFocal[32 ] 分类损失和SIoU[33 ] /GIoU[34 ] 回归损失,以提高检测的精度和效率. YOLOv6在MS COCO数据集上实现了57.2%的AP和29 帧/s的检测速度. ...
1
... Wang等[35 ] 提出YOLOv7网络,如图3 (e)所示,它的网络结构如下. 在特征提取阶段,基于ELAN[36 ] 提出扩展高效层聚合网络(extended efficient layer aggregation network,E-ELAN),通过结合不同群体特征来增强学习能力. Backbone改为由CBS模块、E-ELAN模块和MP模块构成. 在预测阶段,将neck层整合融入head 层中,网络结构由SPPCSPC模块、E-ELAN模块、RepConv模块和CBM模块构成. YOLOv7模型的参数量大幅减少,在MS COCO数据集上实现了55.2%的AP和50 帧/s的检测速度. ...
1
... Wang等[35 ] 提出YOLOv7网络,如图3 (e)所示,它的网络结构如下. 在特征提取阶段,基于ELAN[36 ] 提出扩展高效层聚合网络(extended efficient layer aggregation network,E-ELAN),通过结合不同群体特征来增强学习能力. Backbone改为由CBS模块、E-ELAN模块和MP模块构成. 在预测阶段,将neck层整合融入head 层中,网络结构由SPPCSPC模块、E-ELAN模块、RepConv模块和CBM模块构成. YOLOv7模型的参数量大幅减少,在MS COCO数据集上实现了55.2%的AP和50 帧/s的检测速度. ...
1
... Jocher等[37 ] 提出YOLOv8网络,如图3 (f)所示,它的改进方法如下. 在输入阶段,采用与YOLOX相同的无锚框结构. 在特征提取阶段,在YOLOv5的基础上将CSPDarknet53和FPN-PAN中的C3模块替换为C2f模块,通过结合高级特征与上下文信息来提高检测精度. 在预测阶段,沿用解耦头结构,使用TAL标签分配策略、DFL[38 ] 和CIoU损失函数,提升对小目标的检测能力. YOLOv8在MS COCO数据集上实现了53.9%的AP和280 帧/s的检测速度(在相同的硬件和输入条件下,YOLOv5的平均精度为50.7%). ...
1
... Jocher等[37 ] 提出YOLOv8网络,如图3 (f)所示,它的改进方法如下. 在输入阶段,采用与YOLOX相同的无锚框结构. 在特征提取阶段,在YOLOv5的基础上将CSPDarknet53和FPN-PAN中的C3模块替换为C2f模块,通过结合高级特征与上下文信息来提高检测精度. 在预测阶段,沿用解耦头结构,使用TAL标签分配策略、DFL[38 ] 和CIoU损失函数,提升对小目标的检测能力. YOLOv8在MS COCO数据集上实现了53.9%的AP和280 帧/s的检测速度(在相同的硬件和输入条件下,YOLOv5的平均精度为50.7%). ...
Improved real-time traffic obstacle detection and classification method applied in intelligent and connected vehicles in mixed traffic environment
2
2022
... 行人检测研究的主要创新和改进方向是提高模型的准确性和实时性. Du等[39 ] 结合Wasserstein距离损失[40 ] 和损失函数,提高模型对交通环境中对行人检测错误分类的关注度. 改进后的YOLOv3模型实现了高达98.57%的mAP,而改进后的YOLOv4-tiny模型的检测速度达到了22.592 8 帧/s,满足了实时检测的需求. Cao等[41 ] 使用ViBe算法[42 ] 初步检测所有移动目标,将获取的前景图像输入到YOLOv4网络进行精确的二次行人检测. 通过将SPP-Net结构集成到CSPDarkNet53网络的最后一个卷积层中,显著提升了YOLO模型对图像中属于小目标的行人目标的检测能力. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
1
... 行人检测研究的主要创新和改进方向是提高模型的准确性和实时性. Du等[39 ] 结合Wasserstein距离损失[40 ] 和损失函数,提高模型对交通环境中对行人检测错误分类的关注度. 改进后的YOLOv3模型实现了高达98.57%的mAP,而改进后的YOLOv4-tiny模型的检测速度达到了22.592 8 帧/s,满足了实时检测的需求. Cao等[41 ] 使用ViBe算法[42 ] 初步检测所有移动目标,将获取的前景图像输入到YOLOv4网络进行精确的二次行人检测. 通过将SPP-Net结构集成到CSPDarkNet53网络的最后一个卷积层中,显著提升了YOLO模型对图像中属于小目标的行人目标的检测能力. ...
2
... 行人检测研究的主要创新和改进方向是提高模型的准确性和实时性. Du等[39 ] 结合Wasserstein距离损失[40 ] 和损失函数,提高模型对交通环境中对行人检测错误分类的关注度. 改进后的YOLOv3模型实现了高达98.57%的mAP,而改进后的YOLOv4-tiny模型的检测速度达到了22.592 8 帧/s,满足了实时检测的需求. Cao等[41 ] 使用ViBe算法[42 ] 初步检测所有移动目标,将获取的前景图像输入到YOLOv4网络进行精确的二次行人检测. 通过将SPP-Net结构集成到CSPDarkNet53网络的最后一个卷积层中,显著提升了YOLO模型对图像中属于小目标的行人目标的检测能力. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
ViBe: a universal background subtraction algorithm for video sequences
1
2010
... 行人检测研究的主要创新和改进方向是提高模型的准确性和实时性. Du等[39 ] 结合Wasserstein距离损失[40 ] 和损失函数,提高模型对交通环境中对行人检测错误分类的关注度. 改进后的YOLOv3模型实现了高达98.57%的mAP,而改进后的YOLOv4-tiny模型的检测速度达到了22.592 8 帧/s,满足了实时检测的需求. Cao等[41 ] 使用ViBe算法[42 ] 初步检测所有移动目标,将获取的前景图像输入到YOLOv4网络进行精确的二次行人检测. 通过将SPP-Net结构集成到CSPDarkNet53网络的最后一个卷积层中,显著提升了YOLO模型对图像中属于小目标的行人目标的检测能力. ...
Research on pedestrian detection and deepsort tracking in front of intelligent vehicle based on deep learning
2
2022
... 随着行人检测技术的发展,应用方向已扩展到行人跟踪、行为模式识别、人群密度估计和客流计算等更复杂的领域. 针对行人运动的不确定性和多变性,Chen等[43 ] 使用YOLOv3算法在视频帧中识别和定位行人,获取边界框信息. 使用DeepSort算法[44 ] 预测行人的运动状态,利用马氏距离和外观特征计算跟踪目标的相似度. 该方法结合YOLO算法的检测能力与DeepSort算法的跟踪能力,有效地实现了对行人的准确检测和连续跟踪. 针对城市交通环境中行人乱穿马路这一常见问题,Chavis等[45 ] 分析巴尔的摩和华盛顿的5个街道上的行人行为. 采用YOLOv8算法获取每个行人在连续视频帧中的位置,通过分析行人的位置、方向和速度变化等运动特征,识别直接过街、停顿、变更方向等不同的行人交通行为模式. 对于公交站点这类关键交通场所,人群密度估计和客流计算对于保证运营效率和安全性至关重要. Liu等[46 ] 结合YOLOv3和DeepSort进行人员检测与跟踪,通过分析行人的行走方向并计算通过出入口的人数,获取流量数据. 此外,使用Voronoi图[47 ] 来计算每个人的占用区域,实现了基于个体的人群密度计算. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
1
... 随着行人检测技术的发展,应用方向已扩展到行人跟踪、行为模式识别、人群密度估计和客流计算等更复杂的领域. 针对行人运动的不确定性和多变性,Chen等[43 ] 使用YOLOv3算法在视频帧中识别和定位行人,获取边界框信息. 使用DeepSort算法[44 ] 预测行人的运动状态,利用马氏距离和外观特征计算跟踪目标的相似度. 该方法结合YOLO算法的检测能力与DeepSort算法的跟踪能力,有效地实现了对行人的准确检测和连续跟踪. 针对城市交通环境中行人乱穿马路这一常见问题,Chavis等[45 ] 分析巴尔的摩和华盛顿的5个街道上的行人行为. 采用YOLOv8算法获取每个行人在连续视频帧中的位置,通过分析行人的位置、方向和速度变化等运动特征,识别直接过街、停顿、变更方向等不同的行人交通行为模式. 对于公交站点这类关键交通场所,人群密度估计和客流计算对于保证运营效率和安全性至关重要. Liu等[46 ] 结合YOLOv3和DeepSort进行人员检测与跟踪,通过分析行人的行走方向并计算通过出入口的人数,获取流量数据. 此外,使用Voronoi图[47 ] 来计算每个人的占用区域,实现了基于个体的人群密度计算. ...
2
... 随着行人检测技术的发展,应用方向已扩展到行人跟踪、行为模式识别、人群密度估计和客流计算等更复杂的领域. 针对行人运动的不确定性和多变性,Chen等[43 ] 使用YOLOv3算法在视频帧中识别和定位行人,获取边界框信息. 使用DeepSort算法[44 ] 预测行人的运动状态,利用马氏距离和外观特征计算跟踪目标的相似度. 该方法结合YOLO算法的检测能力与DeepSort算法的跟踪能力,有效地实现了对行人的准确检测和连续跟踪. 针对城市交通环境中行人乱穿马路这一常见问题,Chavis等[45 ] 分析巴尔的摩和华盛顿的5个街道上的行人行为. 采用YOLOv8算法获取每个行人在连续视频帧中的位置,通过分析行人的位置、方向和速度变化等运动特征,识别直接过街、停顿、变更方向等不同的行人交通行为模式. 对于公交站点这类关键交通场所,人群密度估计和客流计算对于保证运营效率和安全性至关重要. Liu等[46 ] 结合YOLOv3和DeepSort进行人员检测与跟踪,通过分析行人的行走方向并计算通过出入口的人数,获取流量数据. 此外,使用Voronoi图[47 ] 来计算每个人的占用区域,实现了基于个体的人群密度计算. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
2
... 随着行人检测技术的发展,应用方向已扩展到行人跟踪、行为模式识别、人群密度估计和客流计算等更复杂的领域. 针对行人运动的不确定性和多变性,Chen等[43 ] 使用YOLOv3算法在视频帧中识别和定位行人,获取边界框信息. 使用DeepSort算法[44 ] 预测行人的运动状态,利用马氏距离和外观特征计算跟踪目标的相似度. 该方法结合YOLO算法的检测能力与DeepSort算法的跟踪能力,有效地实现了对行人的准确检测和连续跟踪. 针对城市交通环境中行人乱穿马路这一常见问题,Chavis等[45 ] 分析巴尔的摩和华盛顿的5个街道上的行人行为. 采用YOLOv8算法获取每个行人在连续视频帧中的位置,通过分析行人的位置、方向和速度变化等运动特征,识别直接过街、停顿、变更方向等不同的行人交通行为模式. 对于公交站点这类关键交通场所,人群密度估计和客流计算对于保证运营效率和安全性至关重要. Liu等[46 ] 结合YOLOv3和DeepSort进行人员检测与跟踪,通过分析行人的行走方向并计算通过出入口的人数,获取流量数据. 此外,使用Voronoi图[47 ] 来计算每个人的占用区域,实现了基于个体的人群密度计算. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
Voronoi diagrams
1
2000
... 随着行人检测技术的发展,应用方向已扩展到行人跟踪、行为模式识别、人群密度估计和客流计算等更复杂的领域. 针对行人运动的不确定性和多变性,Chen等[43 ] 使用YOLOv3算法在视频帧中识别和定位行人,获取边界框信息. 使用DeepSort算法[44 ] 预测行人的运动状态,利用马氏距离和外观特征计算跟踪目标的相似度. 该方法结合YOLO算法的检测能力与DeepSort算法的跟踪能力,有效地实现了对行人的准确检测和连续跟踪. 针对城市交通环境中行人乱穿马路这一常见问题,Chavis等[45 ] 分析巴尔的摩和华盛顿的5个街道上的行人行为. 采用YOLOv8算法获取每个行人在连续视频帧中的位置,通过分析行人的位置、方向和速度变化等运动特征,识别直接过街、停顿、变更方向等不同的行人交通行为模式. 对于公交站点这类关键交通场所,人群密度估计和客流计算对于保证运营效率和安全性至关重要. Liu等[46 ] 结合YOLOv3和DeepSort进行人员检测与跟踪,通过分析行人的行走方向并计算通过出入口的人数,获取流量数据. 此外,使用Voronoi图[47 ] 来计算每个人的占用区域,实现了基于个体的人群密度计算. ...
2
... YOLO算法还广泛应用于识别车内驾驶员和乘客的行为与状态. Yogesh等[48 ] 使用Dlib人脸识别库来获取驾驶员的面部特征,运用YOLOv3算法检测驾驶员的面部和眼睛. 通过计算眼睛闭合比例、嘴巴张开比例和头部倾斜角度,判断驾驶员是否疲劳驾驶. 方浩杰等[49 ] 增加YOLOv5模型的特征采样次数,引入BiFPN网络结构以保留多尺度特征信息,提高了对眼睛、嘴巴的检测精度. 提出疲劳参数补偿机制,以准确识别视频中的眨眼、打哈欠帧数. 融合多种疲劳参数,准确识别了佩戴口罩情况下的驾驶员疲劳状态. Liu等[50 ] 在YOLOv7的backbone和head部分加入全局注意机制(GAM)模块[51 ] ,通过通道扩展(CE)数据增强策略对全局维度的交互特征进行增强,有效地检测了喝水、使用手机、违规抓握方向盘等多种分心驾驶行为. Zhao等[52 ] 结合YOLOv3和Cam-shift算法进行公交车上下客流检测的研究,使用YOLOv3模型从视频图像中识别乘客头部,利用Cam-shift算法持续跟踪这些头部目标的运动轨迹,根据运动轨迹的变化判断乘客的上下车行为. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
多特征融合的驾驶员疲劳状态检测方法
2
2023
... YOLO算法还广泛应用于识别车内驾驶员和乘客的行为与状态. Yogesh等[48 ] 使用Dlib人脸识别库来获取驾驶员的面部特征,运用YOLOv3算法检测驾驶员的面部和眼睛. 通过计算眼睛闭合比例、嘴巴张开比例和头部倾斜角度,判断驾驶员是否疲劳驾驶. 方浩杰等[49 ] 增加YOLOv5模型的特征采样次数,引入BiFPN网络结构以保留多尺度特征信息,提高了对眼睛、嘴巴的检测精度. 提出疲劳参数补偿机制,以准确识别视频中的眨眼、打哈欠帧数. 融合多种疲劳参数,准确识别了佩戴口罩情况下的驾驶员疲劳状态. Liu等[50 ] 在YOLOv7的backbone和head部分加入全局注意机制(GAM)模块[51 ] ,通过通道扩展(CE)数据增强策略对全局维度的交互特征进行增强,有效地检测了喝水、使用手机、违规抓握方向盘等多种分心驾驶行为. Zhao等[52 ] 结合YOLOv3和Cam-shift算法进行公交车上下客流检测的研究,使用YOLOv3模型从视频图像中识别乘客头部,利用Cam-shift算法持续跟踪这些头部目标的运动轨迹,根据运动轨迹的变化判断乘客的上下车行为. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
多特征融合的驾驶员疲劳状态检测方法
2
2023
... YOLO算法还广泛应用于识别车内驾驶员和乘客的行为与状态. Yogesh等[48 ] 使用Dlib人脸识别库来获取驾驶员的面部特征,运用YOLOv3算法检测驾驶员的面部和眼睛. 通过计算眼睛闭合比例、嘴巴张开比例和头部倾斜角度,判断驾驶员是否疲劳驾驶. 方浩杰等[49 ] 增加YOLOv5模型的特征采样次数,引入BiFPN网络结构以保留多尺度特征信息,提高了对眼睛、嘴巴的检测精度. 提出疲劳参数补偿机制,以准确识别视频中的眨眼、打哈欠帧数. 融合多种疲劳参数,准确识别了佩戴口罩情况下的驾驶员疲劳状态. Liu等[50 ] 在YOLOv7的backbone和head部分加入全局注意机制(GAM)模块[51 ] ,通过通道扩展(CE)数据增强策略对全局维度的交互特征进行增强,有效地检测了喝水、使用手机、违规抓握方向盘等多种分心驾驶行为. Zhao等[52 ] 结合YOLOv3和Cam-shift算法进行公交车上下客流检测的研究,使用YOLOv3模型从视频图像中识别乘客头部,利用Cam-shift算法持续跟踪这些头部目标的运动轨迹,根据运动轨迹的变化判断乘客的上下车行为. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
CEAM-YOLOv7: improved YOLOv7 based on channel expansion and attention mechanism for driver distraction behavior detection
2
2022
... YOLO算法还广泛应用于识别车内驾驶员和乘客的行为与状态. Yogesh等[48 ] 使用Dlib人脸识别库来获取驾驶员的面部特征,运用YOLOv3算法检测驾驶员的面部和眼睛. 通过计算眼睛闭合比例、嘴巴张开比例和头部倾斜角度,判断驾驶员是否疲劳驾驶. 方浩杰等[49 ] 增加YOLOv5模型的特征采样次数,引入BiFPN网络结构以保留多尺度特征信息,提高了对眼睛、嘴巴的检测精度. 提出疲劳参数补偿机制,以准确识别视频中的眨眼、打哈欠帧数. 融合多种疲劳参数,准确识别了佩戴口罩情况下的驾驶员疲劳状态. Liu等[50 ] 在YOLOv7的backbone和head部分加入全局注意机制(GAM)模块[51 ] ,通过通道扩展(CE)数据增强策略对全局维度的交互特征进行增强,有效地检测了喝水、使用手机、违规抓握方向盘等多种分心驾驶行为. Zhao等[52 ] 结合YOLOv3和Cam-shift算法进行公交车上下客流检测的研究,使用YOLOv3模型从视频图像中识别乘客头部,利用Cam-shift算法持续跟踪这些头部目标的运动轨迹,根据运动轨迹的变化判断乘客的上下车行为. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
1
... YOLO算法还广泛应用于识别车内驾驶员和乘客的行为与状态. Yogesh等[48 ] 使用Dlib人脸识别库来获取驾驶员的面部特征,运用YOLOv3算法检测驾驶员的面部和眼睛. 通过计算眼睛闭合比例、嘴巴张开比例和头部倾斜角度,判断驾驶员是否疲劳驾驶. 方浩杰等[49 ] 增加YOLOv5模型的特征采样次数,引入BiFPN网络结构以保留多尺度特征信息,提高了对眼睛、嘴巴的检测精度. 提出疲劳参数补偿机制,以准确识别视频中的眨眼、打哈欠帧数. 融合多种疲劳参数,准确识别了佩戴口罩情况下的驾驶员疲劳状态. Liu等[50 ] 在YOLOv7的backbone和head部分加入全局注意机制(GAM)模块[51 ] ,通过通道扩展(CE)数据增强策略对全局维度的交互特征进行增强,有效地检测了喝水、使用手机、违规抓握方向盘等多种分心驾驶行为. Zhao等[52 ] 结合YOLOv3和Cam-shift算法进行公交车上下客流检测的研究,使用YOLOv3模型从视频图像中识别乘客头部,利用Cam-shift算法持续跟踪这些头部目标的运动轨迹,根据运动轨迹的变化判断乘客的上下车行为. ...
2
... YOLO算法还广泛应用于识别车内驾驶员和乘客的行为与状态. Yogesh等[48 ] 使用Dlib人脸识别库来获取驾驶员的面部特征,运用YOLOv3算法检测驾驶员的面部和眼睛. 通过计算眼睛闭合比例、嘴巴张开比例和头部倾斜角度,判断驾驶员是否疲劳驾驶. 方浩杰等[49 ] 增加YOLOv5模型的特征采样次数,引入BiFPN网络结构以保留多尺度特征信息,提高了对眼睛、嘴巴的检测精度. 提出疲劳参数补偿机制,以准确识别视频中的眨眼、打哈欠帧数. 融合多种疲劳参数,准确识别了佩戴口罩情况下的驾驶员疲劳状态. Liu等[50 ] 在YOLOv7的backbone和head部分加入全局注意机制(GAM)模块[51 ] ,通过通道扩展(CE)数据增强策略对全局维度的交互特征进行增强,有效地检测了喝水、使用手机、违规抓握方向盘等多种分心驾驶行为. Zhao等[52 ] 结合YOLOv3和Cam-shift算法进行公交车上下客流检测的研究,使用YOLOv3模型从视频图像中识别乘客头部,利用Cam-shift算法持续跟踪这些头部目标的运动轨迹,根据运动轨迹的变化判断乘客的上下车行为. ...
... Application of YOLO algorithm with 'Human' as detection object in traffic target
Tab.1 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[39 ] 车载行人检测 自建数据集 YOLOv3 结合Wasserstein — 98.57 3.858 6 文献[41 ] 监控行人检测 自建数据集 YOLOv4 引入SPP-Net结构 — 84.47 — 文献[43 ] 行人跟踪 PD-2022 YOLOv3 结合DeepSort算法 72.02 — 33 文献[45 ] 行人行为模式识别 自建数据集 YOLOv8 结合运动特征分析 — — — 文献[46 ] 人群密度估计和客流计算 自建数据集 YOLOv3 结合DeepSort算法、 97.87 — — 文献[48 ] 驾驶员疲劳检测 自建数据集 YOLOv3 — 94.66(眨眼)、 — — 文献[49 ] 驾驶员疲劳检测 自建数据集、NTHU-DDD YOLOv5 增加特征采样次数, — 99.40 100 文献[50 ] 驾驶员分心检测 IR dataset of HNUST and HNU YOLOv7 结合全局注意机制(GAM), — 73.60 156 文献[52 ] 乘客客流检测 自建数据集 YOLOv3 结合Cam-shift算法 89.71 — —
2.2. 以“车”为对象的目标检测 YOLO算法以“车”为对象的交通目标检测涉及从车辆静态特征到动态行为的全方位分析以及进一步深入的交通事件检测,展现了当前研究的多样性和深度,为智能车辆的自动驾驶技术和安全系统的发展提供了关键的技术支持. ...
Research on deep learning automatic vehicle recognition algorithm based on RES-YOLO model
2
2022
... Li等[53 ] 将YOLOv5算法的Backbone替换为ResNet50,引入自适应比例系数来重构损失函数. 这一改进在BDDK100数据集[54 ] 上实现了86%的mAP,有效降低了多车辆目标下的高丢失率和对外部环境的敏感性. 叶佳林等[55 ] 提出基于YOLOv3的非机动车检测算法,通过改进特征融合结构降低非机动车的漏检率,采用GIOU损失来提高定位精度,解决了在高车流密度和易遮挡条件下非机动车的漏检和定位不准确的问题. Raj等[56 ] 结合YOLOv5和VGGNet算法[57 ] ,从视频和音频2个维度检测救护车、消防车和警车等应急车辆的位置和状态. 通过调整交通信号灯,使得应急车辆能够迅速且安全地穿过交通拥堵区,显著提高了应急响应的安全性和效率. Simony等[58 ] 将YOLOv2的2D目标检测能力扩展到3D空间,提出适用于点云数据目标检测的Complex-YOLO网络. 通过将3D激光雷达扫描得到的点云数据转换为RGB鸟瞰视图,使用Euler-Region-Proposal Network(E-RPN)进行3D物体检测,实现了对各种车辆类型的识别. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
1
... Li等[53 ] 将YOLOv5算法的Backbone替换为ResNet50,引入自适应比例系数来重构损失函数. 这一改进在BDDK100数据集[54 ] 上实现了86%的mAP,有效降低了多车辆目标下的高丢失率和对外部环境的敏感性. 叶佳林等[55 ] 提出基于YOLOv3的非机动车检测算法,通过改进特征融合结构降低非机动车的漏检率,采用GIOU损失来提高定位精度,解决了在高车流密度和易遮挡条件下非机动车的漏检和定位不准确的问题. Raj等[56 ] 结合YOLOv5和VGGNet算法[57 ] ,从视频和音频2个维度检测救护车、消防车和警车等应急车辆的位置和状态. 通过调整交通信号灯,使得应急车辆能够迅速且安全地穿过交通拥堵区,显著提高了应急响应的安全性和效率. Simony等[58 ] 将YOLOv2的2D目标检测能力扩展到3D空间,提出适用于点云数据目标检测的Complex-YOLO网络. 通过将3D激光雷达扫描得到的点云数据转换为RGB鸟瞰视图,使用Euler-Region-Proposal Network(E-RPN)进行3D物体检测,实现了对各种车辆类型的识别. ...
改进YOLOv3的非机动车检测与识别方法
2
2021
... Li等[53 ] 将YOLOv5算法的Backbone替换为ResNet50,引入自适应比例系数来重构损失函数. 这一改进在BDDK100数据集[54 ] 上实现了86%的mAP,有效降低了多车辆目标下的高丢失率和对外部环境的敏感性. 叶佳林等[55 ] 提出基于YOLOv3的非机动车检测算法,通过改进特征融合结构降低非机动车的漏检率,采用GIOU损失来提高定位精度,解决了在高车流密度和易遮挡条件下非机动车的漏检和定位不准确的问题. Raj等[56 ] 结合YOLOv5和VGGNet算法[57 ] ,从视频和音频2个维度检测救护车、消防车和警车等应急车辆的位置和状态. 通过调整交通信号灯,使得应急车辆能够迅速且安全地穿过交通拥堵区,显著提高了应急响应的安全性和效率. Simony等[58 ] 将YOLOv2的2D目标检测能力扩展到3D空间,提出适用于点云数据目标检测的Complex-YOLO网络. 通过将3D激光雷达扫描得到的点云数据转换为RGB鸟瞰视图,使用Euler-Region-Proposal Network(E-RPN)进行3D物体检测,实现了对各种车辆类型的识别. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
改进YOLOv3的非机动车检测与识别方法
2
2021
... Li等[53 ] 将YOLOv5算法的Backbone替换为ResNet50,引入自适应比例系数来重构损失函数. 这一改进在BDDK100数据集[54 ] 上实现了86%的mAP,有效降低了多车辆目标下的高丢失率和对外部环境的敏感性. 叶佳林等[55 ] 提出基于YOLOv3的非机动车检测算法,通过改进特征融合结构降低非机动车的漏检率,采用GIOU损失来提高定位精度,解决了在高车流密度和易遮挡条件下非机动车的漏检和定位不准确的问题. Raj等[56 ] 结合YOLOv5和VGGNet算法[57 ] ,从视频和音频2个维度检测救护车、消防车和警车等应急车辆的位置和状态. 通过调整交通信号灯,使得应急车辆能够迅速且安全地穿过交通拥堵区,显著提高了应急响应的安全性和效率. Simony等[58 ] 将YOLOv2的2D目标检测能力扩展到3D空间,提出适用于点云数据目标检测的Complex-YOLO网络. 通过将3D激光雷达扫描得到的点云数据转换为RGB鸟瞰视图,使用Euler-Region-Proposal Network(E-RPN)进行3D物体检测,实现了对各种车辆类型的识别. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
2
... Li等[53 ] 将YOLOv5算法的Backbone替换为ResNet50,引入自适应比例系数来重构损失函数. 这一改进在BDDK100数据集[54 ] 上实现了86%的mAP,有效降低了多车辆目标下的高丢失率和对外部环境的敏感性. 叶佳林等[55 ] 提出基于YOLOv3的非机动车检测算法,通过改进特征融合结构降低非机动车的漏检率,采用GIOU损失来提高定位精度,解决了在高车流密度和易遮挡条件下非机动车的漏检和定位不准确的问题. Raj等[56 ] 结合YOLOv5和VGGNet算法[57 ] ,从视频和音频2个维度检测救护车、消防车和警车等应急车辆的位置和状态. 通过调整交通信号灯,使得应急车辆能够迅速且安全地穿过交通拥堵区,显著提高了应急响应的安全性和效率. Simony等[58 ] 将YOLOv2的2D目标检测能力扩展到3D空间,提出适用于点云数据目标检测的Complex-YOLO网络. 通过将3D激光雷达扫描得到的点云数据转换为RGB鸟瞰视图,使用Euler-Region-Proposal Network(E-RPN)进行3D物体检测,实现了对各种车辆类型的识别. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
1
... Li等[53 ] 将YOLOv5算法的Backbone替换为ResNet50,引入自适应比例系数来重构损失函数. 这一改进在BDDK100数据集[54 ] 上实现了86%的mAP,有效降低了多车辆目标下的高丢失率和对外部环境的敏感性. 叶佳林等[55 ] 提出基于YOLOv3的非机动车检测算法,通过改进特征融合结构降低非机动车的漏检率,采用GIOU损失来提高定位精度,解决了在高车流密度和易遮挡条件下非机动车的漏检和定位不准确的问题. Raj等[56 ] 结合YOLOv5和VGGNet算法[57 ] ,从视频和音频2个维度检测救护车、消防车和警车等应急车辆的位置和状态. 通过调整交通信号灯,使得应急车辆能够迅速且安全地穿过交通拥堵区,显著提高了应急响应的安全性和效率. Simony等[58 ] 将YOLOv2的2D目标检测能力扩展到3D空间,提出适用于点云数据目标检测的Complex-YOLO网络. 通过将3D激光雷达扫描得到的点云数据转换为RGB鸟瞰视图,使用Euler-Region-Proposal Network(E-RPN)进行3D物体检测,实现了对各种车辆类型的识别. ...
2
... Li等[53 ] 将YOLOv5算法的Backbone替换为ResNet50,引入自适应比例系数来重构损失函数. 这一改进在BDDK100数据集[54 ] 上实现了86%的mAP,有效降低了多车辆目标下的高丢失率和对外部环境的敏感性. 叶佳林等[55 ] 提出基于YOLOv3的非机动车检测算法,通过改进特征融合结构降低非机动车的漏检率,采用GIOU损失来提高定位精度,解决了在高车流密度和易遮挡条件下非机动车的漏检和定位不准确的问题. Raj等[56 ] 结合YOLOv5和VGGNet算法[57 ] ,从视频和音频2个维度检测救护车、消防车和警车等应急车辆的位置和状态. 通过调整交通信号灯,使得应急车辆能够迅速且安全地穿过交通拥堵区,显著提高了应急响应的安全性和效率. Simony等[58 ] 将YOLOv2的2D目标检测能力扩展到3D空间,提出适用于点云数据目标检测的Complex-YOLO网络. 通过将3D激光雷达扫描得到的点云数据转换为RGB鸟瞰视图,使用Euler-Region-Proposal Network(E-RPN)进行3D物体检测,实现了对各种车辆类型的识别. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
A real-time vehicle detection and a novel vehicle tracking systems for estimating and monitoring traffic flow on highways
2
2021
... YOLO算法在车辆动态检测方面得到了广泛的研究和发展. Azimjonov等[59 ] 使用YOLOv3算法检测车辆类型和位置,计算连续2帧中车辆边界框的欧式距离,通过比对不同边界框之间的相似性,实现了视频序列中的车辆位置跟踪和移动分析. 车辆计数和交通密度分析是车辆跟踪的进一步深入研究. Lin等[60 ] 结合mYOLOv4-tiny算法和CFNN卷积模糊神经网络[61 ] ,准确地分类和定位不同类型的车辆,通过统计不同时间段内检测到的车辆数量来分析交通密度. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
Intelligent traffic-monitoring system based on YOLO and convolutional fuzzy neural networks
2
2022
... YOLO算法在车辆动态检测方面得到了广泛的研究和发展. Azimjonov等[59 ] 使用YOLOv3算法检测车辆类型和位置,计算连续2帧中车辆边界框的欧式距离,通过比对不同边界框之间的相似性,实现了视频序列中的车辆位置跟踪和移动分析. 车辆计数和交通密度分析是车辆跟踪的进一步深入研究. Lin等[60 ] 结合mYOLOv4-tiny算法和CFNN卷积模糊神经网络[61 ] ,准确地分类和定位不同类型的车辆,通过统计不同时间段内检测到的车辆数量来分析交通密度. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
CFNN: correlated fuzzy neural network
1
2015
... YOLO算法在车辆动态检测方面得到了广泛的研究和发展. Azimjonov等[59 ] 使用YOLOv3算法检测车辆类型和位置,计算连续2帧中车辆边界框的欧式距离,通过比对不同边界框之间的相似性,实现了视频序列中的车辆位置跟踪和移动分析. 车辆计数和交通密度分析是车辆跟踪的进一步深入研究. Lin等[60 ] 结合mYOLOv4-tiny算法和CFNN卷积模糊神经网络[61 ] ,准确地分类和定位不同类型的车辆,通过统计不同时间段内检测到的车辆数量来分析交通密度. ...
2
... 在车辆跟踪和计数研究的基础上,以车为对象的交通目标检测拓展到了车辆速度估计、异常行为识别和交通事故检测等更复杂的领域. Cvijetić等[62 ] 使用YOLOv5算法检测视频中的车辆类别和位置,通过1D-CNN模型逐帧计算车辆靠近摄像机时边界框的面积来获取边界框变化区域(CBBA),根据CBBA曲线的变化来估计车辆速度. Rahman等[63 ] 使用YOLOv3算法从视频帧中检测车辆位置,在指定区域内应用质心跟踪算法进行车辆跟踪. 通过逐帧比较车辆质心位置的变化来检测车辆行驶方向,识别逆行行为. Sabry等[64 ] 将YOLOv3算法输出的车辆位置信息传递给MOSSE(minimum output sum of squared error)跟踪算法[65 ] 进行车辆位置跟踪. 通过比较2辆车的实际和预测中心之间的最大距离来进行碰撞检测,利用暴力流(violent flow, ViF)描述符[66 ] 分析可能的碰撞区域,判断是否发生了交通事故. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
2
... 在车辆跟踪和计数研究的基础上,以车为对象的交通目标检测拓展到了车辆速度估计、异常行为识别和交通事故检测等更复杂的领域. Cvijetić等[62 ] 使用YOLOv5算法检测视频中的车辆类别和位置,通过1D-CNN模型逐帧计算车辆靠近摄像机时边界框的面积来获取边界框变化区域(CBBA),根据CBBA曲线的变化来估计车辆速度. Rahman等[63 ] 使用YOLOv3算法从视频帧中检测车辆位置,在指定区域内应用质心跟踪算法进行车辆跟踪. 通过逐帧比较车辆质心位置的变化来检测车辆行驶方向,识别逆行行为. Sabry等[64 ] 将YOLOv3算法输出的车辆位置信息传递给MOSSE(minimum output sum of squared error)跟踪算法[65 ] 进行车辆位置跟踪. 通过比较2辆车的实际和预测中心之间的最大距离来进行碰撞检测,利用暴力流(violent flow, ViF)描述符[66 ] 分析可能的碰撞区域,判断是否发生了交通事故. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
2
... 在车辆跟踪和计数研究的基础上,以车为对象的交通目标检测拓展到了车辆速度估计、异常行为识别和交通事故检测等更复杂的领域. Cvijetić等[62 ] 使用YOLOv5算法检测视频中的车辆类别和位置,通过1D-CNN模型逐帧计算车辆靠近摄像机时边界框的面积来获取边界框变化区域(CBBA),根据CBBA曲线的变化来估计车辆速度. Rahman等[63 ] 使用YOLOv3算法从视频帧中检测车辆位置,在指定区域内应用质心跟踪算法进行车辆跟踪. 通过逐帧比较车辆质心位置的变化来检测车辆行驶方向,识别逆行行为. Sabry等[64 ] 将YOLOv3算法输出的车辆位置信息传递给MOSSE(minimum output sum of squared error)跟踪算法[65 ] 进行车辆位置跟踪. 通过比较2辆车的实际和预测中心之间的最大距离来进行碰撞检测,利用暴力流(violent flow, ViF)描述符[66 ] 分析可能的碰撞区域,判断是否发生了交通事故. ...
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
1
... 在车辆跟踪和计数研究的基础上,以车为对象的交通目标检测拓展到了车辆速度估计、异常行为识别和交通事故检测等更复杂的领域. Cvijetić等[62 ] 使用YOLOv5算法检测视频中的车辆类别和位置,通过1D-CNN模型逐帧计算车辆靠近摄像机时边界框的面积来获取边界框变化区域(CBBA),根据CBBA曲线的变化来估计车辆速度. Rahman等[63 ] 使用YOLOv3算法从视频帧中检测车辆位置,在指定区域内应用质心跟踪算法进行车辆跟踪. 通过逐帧比较车辆质心位置的变化来检测车辆行驶方向,识别逆行行为. Sabry等[64 ] 将YOLOv3算法输出的车辆位置信息传递给MOSSE(minimum output sum of squared error)跟踪算法[65 ] 进行车辆位置跟踪. 通过比较2辆车的实际和预测中心之间的最大距离来进行碰撞检测,利用暴力流(violent flow, ViF)描述符[66 ] 分析可能的碰撞区域,判断是否发生了交通事故. ...
1
... 在车辆跟踪和计数研究的基础上,以车为对象的交通目标检测拓展到了车辆速度估计、异常行为识别和交通事故检测等更复杂的领域. Cvijetić等[62 ] 使用YOLOv5算法检测视频中的车辆类别和位置,通过1D-CNN模型逐帧计算车辆靠近摄像机时边界框的面积来获取边界框变化区域(CBBA),根据CBBA曲线的变化来估计车辆速度. Rahman等[63 ] 使用YOLOv3算法从视频帧中检测车辆位置,在指定区域内应用质心跟踪算法进行车辆跟踪. 通过逐帧比较车辆质心位置的变化来检测车辆行驶方向,识别逆行行为. Sabry等[64 ] 将YOLOv3算法输出的车辆位置信息传递给MOSSE(minimum output sum of squared error)跟踪算法[65 ] 进行车辆位置跟踪. 通过比较2辆车的实际和预测中心之间的最大距离来进行碰撞检测,利用暴力流(violent flow, ViF)描述符[66 ] 分析可能的碰撞区域,判断是否发生了交通事故. ...
Vision meets robotics: the kitti dataset
1
2013
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
Vehicle type classification using a semisupervised convolutional neural network
1
2015
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
1
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
1
... Application of YOLO algorithm with 'Vehicle' as detection object in traffic target
Tab.2 文献 研究方向 数据集 YOLO原型 改进方式 P /%mAP/% v /(帧·s−1 )文献[53 ] 机动车检测 BDDK100 YOLOv5 将主干网络替换为ResNet50, 86 — — 文献[55 ] 非机动车检测 自建数据集 YOLOv3 改进特征融合结构,采用GIOU损失 — 70.8 — 文献[56 ] 应急车辆检测 自建数据集 YOLOv5 结合VGGNet算法 — 95.7 — 文献[58 ] 3D车辆检测 KITTI[67 ] YOLOv2 改为3D目标检测,引入E-RPN — 54.77 50.4 文献[59 ] 车辆跟踪 自建数据集 YOLOv3 结合边界框距离计算与相似性对比 95.45 — — 文献[60 ] 交通密度分析 BIT-Vehicle Dataset[68 ] 、[69 ] YOLOv4 结合CFNN卷积模糊神经网络 90.45 99 30 文献[62 ] 车辆速度估计 VS13[70 ] YOLOv5 结合1D-CNN算法 — — — 文献[63 ] 车辆异常行为检测 自建数据集 YOLOv3 结合质心跟踪算法 100 — — 文献[64 ] 交通事故检测 自建数据集 YOLOv3 结合MOSSE跟踪算法、ViF描述符 93 — —
2.3. 以“路”为对象的目标检测 YOLO算法以“路”为对象的目标检测的首要任务是检测路面上的交通标志、信号灯和道路划线,这些是智能车辆判断道路使用模式的重要依据之一. 其次是检测驾驶过程中需要及时规避的路面障碍和损坏,以保障车辆的安全行驶. ...
Tsr-yolo: a Chinese traffic sign recognition algorithm for intelligent vehicles in complex scenes
2
2023
... Song等[71 ] 提出TSR-YOLO算法,引入改进的轻量级BECA注意力机制和增强的密集SPP模块,使用k-means++聚类算法获取更适合交通标志检测的锚框. 该算法在CCTSDB2021数据集[72 ] 上达到92.77%的mAP和81 帧/s的处理速度,证明利用该算法能够在复杂场景中准确检测交通标志,满足智能车辆对交通标志检测任务的实时性要求. 针对交通灯尺寸小和环境复杂导致的特征提取难题,钱伍等[73 ] 设计ACBlock(asymmetric convolution block)、SoftPool和DSConv(depthwise separable convolution)模块以提高Backbone的特征提取能力,改进特征融合网络来增强对小目标的检测能力. 在BDD100K和Bosch数据集[74 ] 上,分别实现了74.3%、84.4%的AP以及111、126 帧/s的检测速度,提升了交通灯检测的准确性和实时性. ...
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...
1
... Song等[71 ] 提出TSR-YOLO算法,引入改进的轻量级BECA注意力机制和增强的密集SPP模块,使用k-means++聚类算法获取更适合交通标志检测的锚框. 该算法在CCTSDB2021数据集[72 ] 上达到92.77%的mAP和81 帧/s的处理速度,证明利用该算法能够在复杂场景中准确检测交通标志,满足智能车辆对交通标志检测任务的实时性要求. 针对交通灯尺寸小和环境复杂导致的特征提取难题,钱伍等[73 ] 设计ACBlock(asymmetric convolution block)、SoftPool和DSConv(depthwise separable convolution)模块以提高Backbone的特征提取能力,改进特征融合网络来增强对小目标的检测能力. 在BDD100K和Bosch数据集[74 ] 上,分别实现了74.3%、84.4%的AP以及111、126 帧/s的检测速度,提升了交通灯检测的准确性和实时性. ...
改进YOLOv5的交通灯实时检测鲁棒算法
2
2022
... Song等[71 ] 提出TSR-YOLO算法,引入改进的轻量级BECA注意力机制和增强的密集SPP模块,使用k-means++聚类算法获取更适合交通标志检测的锚框. 该算法在CCTSDB2021数据集[72 ] 上达到92.77%的mAP和81 帧/s的处理速度,证明利用该算法能够在复杂场景中准确检测交通标志,满足智能车辆对交通标志检测任务的实时性要求. 针对交通灯尺寸小和环境复杂导致的特征提取难题,钱伍等[73 ] 设计ACBlock(asymmetric convolution block)、SoftPool和DSConv(depthwise separable convolution)模块以提高Backbone的特征提取能力,改进特征融合网络来增强对小目标的检测能力. 在BDD100K和Bosch数据集[74 ] 上,分别实现了74.3%、84.4%的AP以及111、126 帧/s的检测速度,提升了交通灯检测的准确性和实时性. ...
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...
改进YOLOv5的交通灯实时检测鲁棒算法
2
2022
... Song等[71 ] 提出TSR-YOLO算法,引入改进的轻量级BECA注意力机制和增强的密集SPP模块,使用k-means++聚类算法获取更适合交通标志检测的锚框. 该算法在CCTSDB2021数据集[72 ] 上达到92.77%的mAP和81 帧/s的处理速度,证明利用该算法能够在复杂场景中准确检测交通标志,满足智能车辆对交通标志检测任务的实时性要求. 针对交通灯尺寸小和环境复杂导致的特征提取难题,钱伍等[73 ] 设计ACBlock(asymmetric convolution block)、SoftPool和DSConv(depthwise separable convolution)模块以提高Backbone的特征提取能力,改进特征融合网络来增强对小目标的检测能力. 在BDD100K和Bosch数据集[74 ] 上,分别实现了74.3%、84.4%的AP以及111、126 帧/s的检测速度,提升了交通灯检测的准确性和实时性. ...
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...
1
... Song等[71 ] 提出TSR-YOLO算法,引入改进的轻量级BECA注意力机制和增强的密集SPP模块,使用k-means++聚类算法获取更适合交通标志检测的锚框. 该算法在CCTSDB2021数据集[72 ] 上达到92.77%的mAP和81 帧/s的处理速度,证明利用该算法能够在复杂场景中准确检测交通标志,满足智能车辆对交通标志检测任务的实时性要求. 针对交通灯尺寸小和环境复杂导致的特征提取难题,钱伍等[73 ] 设计ACBlock(asymmetric convolution block)、SoftPool和DSConv(depthwise separable convolution)模块以提高Backbone的特征提取能力,改进特征融合网络来增强对小目标的检测能力. 在BDD100K和Bosch数据集[74 ] 上,分别实现了74.3%、84.4%的AP以及111、126 帧/s的检测速度,提升了交通灯检测的准确性和实时性. ...
A road marking detection system using partial template matching and region estimation by deep neural network
2
2021
... Mii等[75 ] 使用YOLOv2算法识别出含有道路划线的区域,应用模板匹配技术来精确识别道路划线. 比较图像与预设模板之间的相似度以识别道路使用模式,克服了传统基于亮度的模板匹配方法在阳光照射或道路标记模糊情况下检测失效的局限性. Chen等[76 ] 在YOLOv5的基础上替换空间金字塔快速池化(spatial pyramid pooling-fast, SPPF)模块、引入GELU(Gaussian error linear unit)[77 ] 激活函数和CA(coordinate attention)机制[78 ] ,在减少模型参数量的同时,提升了特征感知和表达能力. 使用旋转框获取目标的角度信息已在目标检测领域得到了广泛的应用[79 ] ,通过使用圆形平滑标签(circular smooth label)[80 ] 进行角度分类,将角度回归问题转化为分类问题,准确识别停车位的位置和朝向. ...
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...
Autonomous parking space detection for electric vehicles based on improved YOLOV5-OBB algorithm
2
2023
... Mii等[75 ] 使用YOLOv2算法识别出含有道路划线的区域,应用模板匹配技术来精确识别道路划线. 比较图像与预设模板之间的相似度以识别道路使用模式,克服了传统基于亮度的模板匹配方法在阳光照射或道路标记模糊情况下检测失效的局限性. Chen等[76 ] 在YOLOv5的基础上替换空间金字塔快速池化(spatial pyramid pooling-fast, SPPF)模块、引入GELU(Gaussian error linear unit)[77 ] 激活函数和CA(coordinate attention)机制[78 ] ,在减少模型参数量的同时,提升了特征感知和表达能力. 使用旋转框获取目标的角度信息已在目标检测领域得到了广泛的应用[79 ] ,通过使用圆形平滑标签(circular smooth label)[80 ] 进行角度分类,将角度回归问题转化为分类问题,准确识别停车位的位置和朝向. ...
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...
1
... Mii等[75 ] 使用YOLOv2算法识别出含有道路划线的区域,应用模板匹配技术来精确识别道路划线. 比较图像与预设模板之间的相似度以识别道路使用模式,克服了传统基于亮度的模板匹配方法在阳光照射或道路标记模糊情况下检测失效的局限性. Chen等[76 ] 在YOLOv5的基础上替换空间金字塔快速池化(spatial pyramid pooling-fast, SPPF)模块、引入GELU(Gaussian error linear unit)[77 ] 激活函数和CA(coordinate attention)机制[78 ] ,在减少模型参数量的同时,提升了特征感知和表达能力. 使用旋转框获取目标的角度信息已在目标检测领域得到了广泛的应用[79 ] ,通过使用圆形平滑标签(circular smooth label)[80 ] 进行角度分类,将角度回归问题转化为分类问题,准确识别停车位的位置和朝向. ...
1
... Mii等[75 ] 使用YOLOv2算法识别出含有道路划线的区域,应用模板匹配技术来精确识别道路划线. 比较图像与预设模板之间的相似度以识别道路使用模式,克服了传统基于亮度的模板匹配方法在阳光照射或道路标记模糊情况下检测失效的局限性. Chen等[76 ] 在YOLOv5的基础上替换空间金字塔快速池化(spatial pyramid pooling-fast, SPPF)模块、引入GELU(Gaussian error linear unit)[77 ] 激活函数和CA(coordinate attention)机制[78 ] ,在减少模型参数量的同时,提升了特征感知和表达能力. 使用旋转框获取目标的角度信息已在目标检测领域得到了广泛的应用[79 ] ,通过使用圆形平滑标签(circular smooth label)[80 ] 进行角度分类,将角度回归问题转化为分类问题,准确识别停车位的位置和朝向. ...
旋转框定位的多尺度再生物品目标检测算法
1
2022
... Mii等[75 ] 使用YOLOv2算法识别出含有道路划线的区域,应用模板匹配技术来精确识别道路划线. 比较图像与预设模板之间的相似度以识别道路使用模式,克服了传统基于亮度的模板匹配方法在阳光照射或道路标记模糊情况下检测失效的局限性. Chen等[76 ] 在YOLOv5的基础上替换空间金字塔快速池化(spatial pyramid pooling-fast, SPPF)模块、引入GELU(Gaussian error linear unit)[77 ] 激活函数和CA(coordinate attention)机制[78 ] ,在减少模型参数量的同时,提升了特征感知和表达能力. 使用旋转框获取目标的角度信息已在目标检测领域得到了广泛的应用[79 ] ,通过使用圆形平滑标签(circular smooth label)[80 ] 进行角度分类,将角度回归问题转化为分类问题,准确识别停车位的位置和朝向. ...
旋转框定位的多尺度再生物品目标检测算法
1
2022
... Mii等[75 ] 使用YOLOv2算法识别出含有道路划线的区域,应用模板匹配技术来精确识别道路划线. 比较图像与预设模板之间的相似度以识别道路使用模式,克服了传统基于亮度的模板匹配方法在阳光照射或道路标记模糊情况下检测失效的局限性. Chen等[76 ] 在YOLOv5的基础上替换空间金字塔快速池化(spatial pyramid pooling-fast, SPPF)模块、引入GELU(Gaussian error linear unit)[77 ] 激活函数和CA(coordinate attention)机制[78 ] ,在减少模型参数量的同时,提升了特征感知和表达能力. 使用旋转框获取目标的角度信息已在目标检测领域得到了广泛的应用[79 ] ,通过使用圆形平滑标签(circular smooth label)[80 ] 进行角度分类,将角度回归问题转化为分类问题,准确识别停车位的位置和朝向. ...
1
... Mii等[75 ] 使用YOLOv2算法识别出含有道路划线的区域,应用模板匹配技术来精确识别道路划线. 比较图像与预设模板之间的相似度以识别道路使用模式,克服了传统基于亮度的模板匹配方法在阳光照射或道路标记模糊情况下检测失效的局限性. Chen等[76 ] 在YOLOv5的基础上替换空间金字塔快速池化(spatial pyramid pooling-fast, SPPF)模块、引入GELU(Gaussian error linear unit)[77 ] 激活函数和CA(coordinate attention)机制[78 ] ,在减少模型参数量的同时,提升了特征感知和表达能力. 使用旋转框获取目标的角度信息已在目标检测领域得到了广泛的应用[79 ] ,通过使用圆形平滑标签(circular smooth label)[80 ] 进行角度分类,将角度回归问题转化为分类问题,准确识别停车位的位置和朝向. ...
2
... Srivastava[81 ] 使用包含各种垃圾和野生动物图像的数据集,对YOLOv5模型进行特定训练. 通过对这些物体进行“可驾驶”或“不可驾驶”的二元分类,评估各种路面障碍对安全驾驶的潜在影响. Wan等[82 ] 将YOLOv5s模型的Backbone替换为由轻量级网络ShuffleNetV2[83 ] 和ECA注意力机制[84 ] 组成的Shuffle-ECANet,提高模型的检测速度和精度. 通过实时检测路面的各种裂缝和坑洞缺陷,辅助智能车辆规划驾驶路线,以避开这些受损道路存在的交通风险. ...
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...
YOLO-LRDD: a lightweight method for road damage detection based on improved YOLOv5s
2
2022
... Srivastava[81 ] 使用包含各种垃圾和野生动物图像的数据集,对YOLOv5模型进行特定训练. 通过对这些物体进行“可驾驶”或“不可驾驶”的二元分类,评估各种路面障碍对安全驾驶的潜在影响. Wan等[82 ] 将YOLOv5s模型的Backbone替换为由轻量级网络ShuffleNetV2[83 ] 和ECA注意力机制[84 ] 组成的Shuffle-ECANet,提高模型的检测速度和精度. 通过实时检测路面的各种裂缝和坑洞缺陷,辅助智能车辆规划驾驶路线,以避开这些受损道路存在的交通风险. ...
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...
1
... Srivastava[81 ] 使用包含各种垃圾和野生动物图像的数据集,对YOLOv5模型进行特定训练. 通过对这些物体进行“可驾驶”或“不可驾驶”的二元分类,评估各种路面障碍对安全驾驶的潜在影响. Wan等[82 ] 将YOLOv5s模型的Backbone替换为由轻量级网络ShuffleNetV2[83 ] 和ECA注意力机制[84 ] 组成的Shuffle-ECANet,提高模型的检测速度和精度. 通过实时检测路面的各种裂缝和坑洞缺陷,辅助智能车辆规划驾驶路线,以避开这些受损道路存在的交通风险. ...
1
... Srivastava[81 ] 使用包含各种垃圾和野生动物图像的数据集,对YOLOv5模型进行特定训练. 通过对这些物体进行“可驾驶”或“不可驾驶”的二元分类,评估各种路面障碍对安全驾驶的潜在影响. Wan等[82 ] 将YOLOv5s模型的Backbone替换为由轻量级网络ShuffleNetV2[83 ] 和ECA注意力机制[84 ] 组成的Shuffle-ECANet,提高模型的检测速度和精度. 通过实时检测路面的各种裂缝和坑洞缺陷,辅助智能车辆规划驾驶路线,以避开这些受损道路存在的交通风险. ...
1
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...
RDD2020: an annotated image dataset for automatic road damage detection using deep learning
1
2021
... Application of YOLO algorithm with 'Road' as detection object in traffic target
% Tab.3 文献 研究方向 数据集 YOLO原型 改进方式 P AP mAP 文献[71 ] 交通标志检测 CCTSDB2021 YOLOv4 引入BECA注意力机制、密集SPP模块、k-means++聚类算法 96.62 — 92.77 文献[73 ] 交通灯检测 BDD100K、 YOLOv5 引入ACBlock、SoftPool、DSConv模块 — 74.3 — 文献[75 ] 道路划线检测 自建数据集 YOLOv2 结合模板匹配技术 100 — — 文献[76 ] 停车位检测 自建数据集 YOLOv5 引入SPPF模块、GELU激活函数、CA机制、圆形平滑标签 — — 70.72 文献[81 ] 路面障碍检测 TACO[85 ] YOLOv5 — — — 24.77 文献[82 ] 道路损坏检测 RDD2020[86 ] (自主拓展) YOLOv5 将主干网络替换为Shuffle-ECANet 59.2 — 57.6
3. 结 语 针对YOLO算法在交通场景目标检测任务中的技术挑战和局限性,未来的研究方向如下. ...



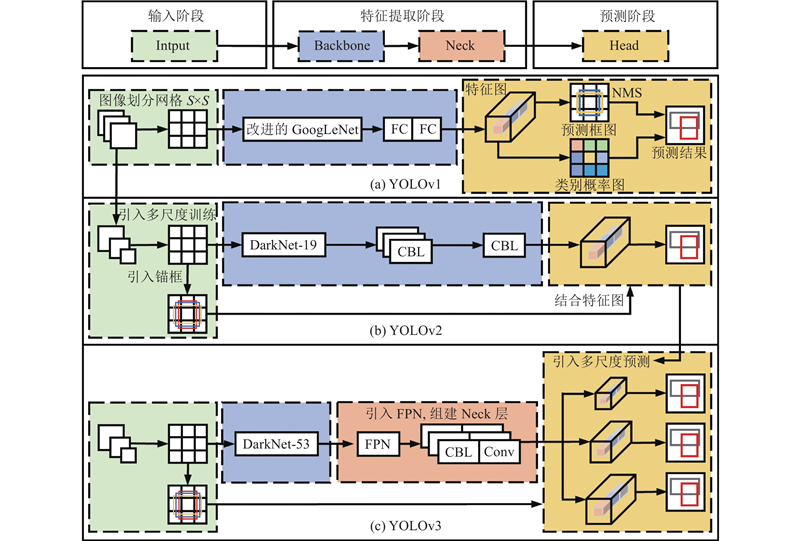
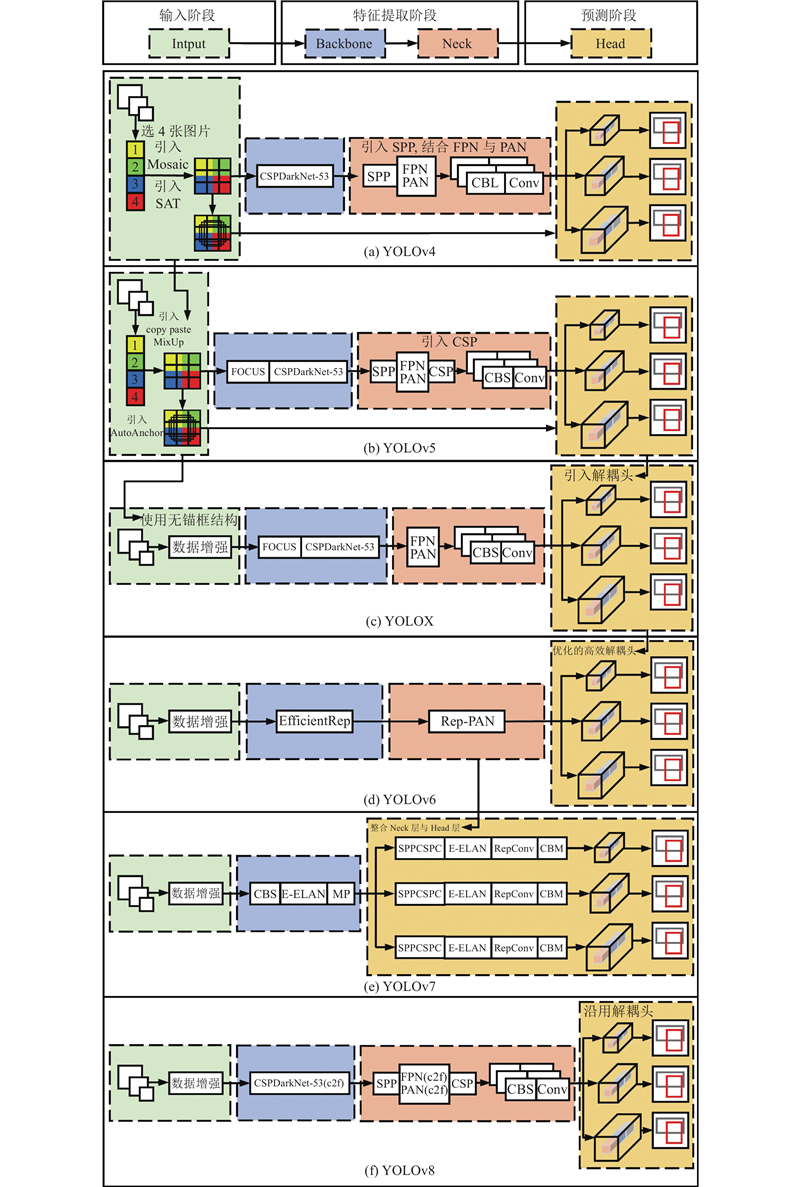

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}