Exiting methods of aspect sentiment triplet extraction suffer from the problems of not being able to fully utilize the knowledge of the pre-trained model, being prone to overfitting or underfitting, and having insufficient ability to recognize the fine-grained aspects and sentiments of an utterance. A method for extracting span-level aspect sentiment triples based on a curriculum learning framework was proposed. Data preprocessing was performed based on the curriculum learning framework, and the contextual representation of a sentence was learned using a pre-trained model. By building a span model, all possible spans were extracted in a sentence. Aspect and opinion terms were extracted based on the dual channel, and the correct combinations of aspect-opinion were filtered out for sentiment categorization. Experimental results on the ASTE-Data-V2 dataset show that the F1 value of the proposed method is improved by 2 percentage points over that of SPAN-ASTE. The experimental results of the proposed method outperform the other aspect sentiment triplet extraction methods such as GTS, B-MRC, and JET.
HOU Mingze, RAO Lei, FAN Guangyu, CHEN Niansheng, CHENG Songlin. Span-level aspect sentiment triplet extraction based on curriculum learning. Journal of Zhejiang University(Engineering Science)[J], 2025, 59(1): 79-88 doi:10.3785/j.issn.1008-973X.2025.01.008
方面情感三元组提取(aspect sentiment triplet extraction,ASTE)是细粒度的情感分析任务,其目的是提取句子中的方面词、情感极性和意见词,主要应用于商品评论分析任务[1]. 例如在语句“The sweet treats are good but average service.”中,方面词是“sweet treats”和“service”;意见词是“good”和“average”,它们的情感极性分别是“正面”和“中立”.
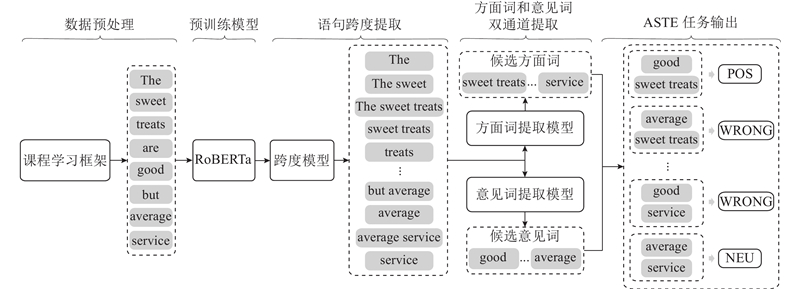
如图2所示,所提基于课程学习框架的跨度级ASTE方法的网络架构由5个部分组成:基于课程学习框架的数据预处理、预训练模型、语句跨度提取、方面词和意见词双通道提取以及ASTE任务输出. 课程学习框架处理输入数据,预训练模型获得词的上下文表示,跨度模型生成所有可能的跨度,方面词提取(aspect term extraction, AE)模型和意见词提取(opinion term extraction,OE)模型提取所有的候选方面词和候选意见词,ASTE提取模型配对正确的方面词和意见词对并分类情感极性,其中POS、NEG和NEU分别对应积极、消极和中立的情感极性,WRONG表示方面词和意见词配对失败,不输出情感极性.
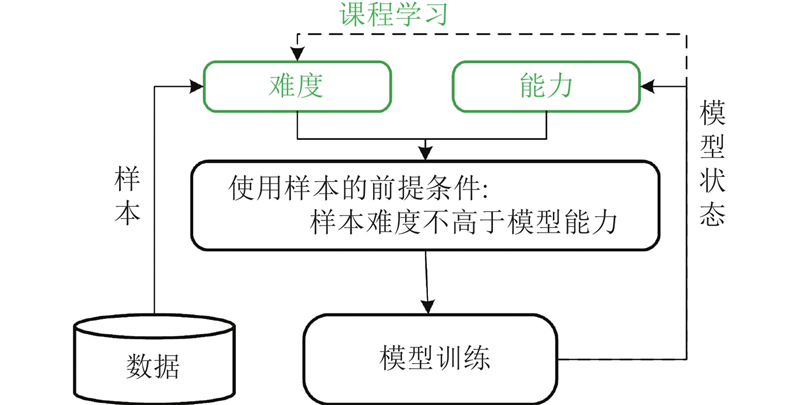
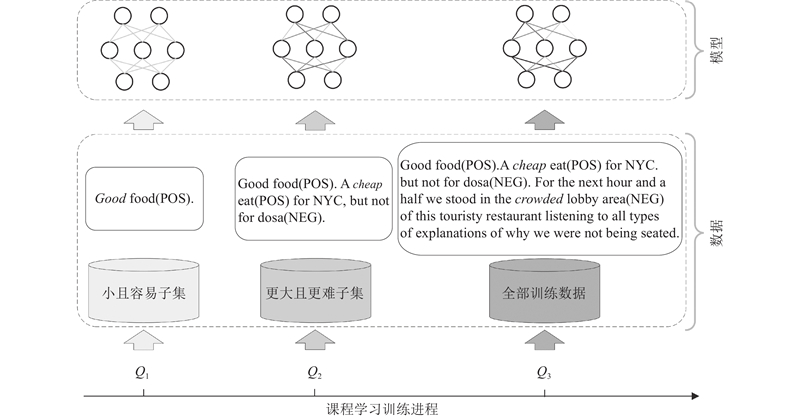
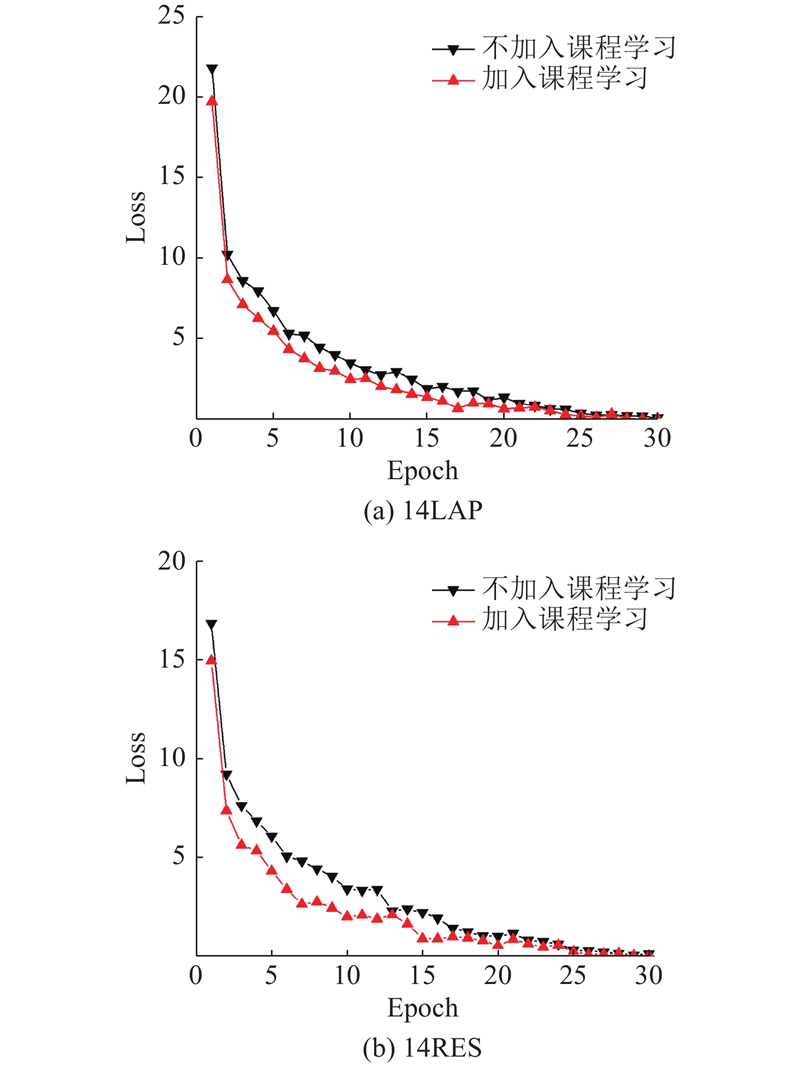
如图3所示为所提课程学习框架在ASTE任务中的训练过程,图中的意见词均用斜体表现,3种情感极性均写在括号内,放在对应的方面词后面. 参考机器翻译的句子划分策略[16-19],将数据集按照句式由短至长排序后分为3份:$ {{Q_1}、{Q_2}、{Q_3}} $. 其中${Q_1}$包含句子长度小于10个字母的样本,如简短语句“Good food(POS) .”;${Q_2}$包含句子长度小于20个字母大于等于10个字母的样本,如较复杂语句 “A cheap eat(POS) for NYC , but not for dosa(NEG) .”;${Q_3}$包含句子长度大于等于20个字母的样本,如复杂语句 “For the next hour and a half we stood in the crowded lobby area(NEG) of this touristy restaurant listening to all types of explanations of why we were not being seated .”. 如算法1所示,定义判断模型是否收敛的函数来表现模型能力,如果模型收敛则本轮学习结束,可以输入更难的样本. 先将${Q_1}$送入模型训练,模型收敛后再送入${Q_2}$, 最后送入${Q_3}$. 通过逐渐增加课程学习框架的任务强度(先训练数据集中小且简单的样本,再加入更难样本,最终放入所有样本),帮助模型逐步学习语句更复杂的特征和规律.
如图5所示为所提方法在不同预训练模型下的推理结果. 其中虚线矩形内为方面词,实线矩形内为意见词. 可以看出,基于跨度的方法能够提高多词的提取效果,却出现提取错误跨度的问题. 在BERT的预测中,“saag and paneer and korma”被识别为同一目标,这可能是句子的上下文中共享相似的情感信息,导致模型将这些单词合并为一个目标. RoBERTa模型只针对掩码任务训练,更专注与句子中词与词的关系,可以提升提取的准确性,因此选择RoBERTa模型作为所提方法的最终模型.
PENG H, XU L, BING L, et al. Knowing what, how and why: a near complete solution for aspect-based sentiment analysis [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2020, 34(5): 8600–8607.
XU L, LI H, LU W, et al. Position-aware tagging for aspect sentiment triplet extraction [EB/OL]. (2021–03–09) [2024–01–29]. https://arxiv.org/abs/2010.02609.
YAN H, DAI J, QIU X, et al. A unified generative framework for aspect-based sentiment analysis [EB/OL]. (2021–06–08) [2024–01–29]. https://arxiv.org/abs/2106.04300.
ZHANG W, LI X, DENG Y, et al. Towards generative aspect-based sentiment analysis [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) . [S.l.]: Association for Computational Linguistics, 2021: 504–510.
CHEN S, WANG Y, LIU J, et al. Bidirectional machine reading comprehension for aspect sentiment triplet extraction [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2021, 35(14): 12666–12674.
MAO Y, SHEN Y, YU C, et al. A joint training dual-MRC framework for aspect based sentiment analysis [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2021, 35(15): 13543–13551.
CHEN Z, QIAN T. Bridge-based active domain adaptation for aspect term extraction [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) . [S.l.]: Association for Computational Linguistics, 2021: 317–327.
SUN K, ZHANG R, MENSAH S, et al. Aspect-level sentiment analysis via convolution over dependency tree [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: Association for Computational Linguistics, 2019: 5679–5688.
ZHANG C, LI Q, SONG D. Aspect-based sentiment classification with aspect-specific graph convolutional networks [EB/OL]. (2019–10–13) [2024–01–29]. https://arxiv.org/abs/1909.03477.
PONTIKI M, GALANIS D, PAVLOPOULOS J, et al. SemEval-2014 task 4: aspect based sentiment analysis [C]// Proceeding of the 8th International Workshop on Semantic Evaluation . Dublin: Association for Computational Linguistics, 2014: 27–35.
PONTIKI M, GALANIS D, PAPAGEORGIOU H, et al. SemEval-2015 task 12: aspect based sentiment analysis [C]// Proceedings of the 9th International Workshop on Semantic Evaluation . Denver: Association for Computational Linguistics, 2015: 486–495.
PONTIKI M, GALANIS D, PAPAGEORGIOU H, et al. SemEval-2016 task 5: aspect based sentiment analysis [C]// Proceedings of the 10th International workshop on Semantic Evaluation . San Diego: Association for Computational Linguistics, 2016: 19–30.
BENGIO Y, LOURADOUR J, COLLOBERT R, et al. Curriculum learning [C]// Proceedings of the 26th Annual International Conference on Machine Learning . [S.l.]: Association for Computing Machinery, 2009: 41–48.
PLATANIOS E A, STRETCU O, NEUBIG G, et al. Competence-based curriculum learning for neural machine translation [EB/OL]. (2019–03–06) [2024–01–29]. https://arxiv.org/abs/1903.09848.
TAY Y, WANG S, TUAN L A, et al. Simple and effective curriculum pointer-generator networks for reading comprehension over long narratives [EB/OL]. (2019–05–26) [2024–01–29]. https://arxiv.org/abs/1905.10847.
LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. (2019–07–26) [2024–01–29]. https://arxiv.org/abs/1907.11692.
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2019–05–24) [2024–01–29]. https://arxiv.org/abs/1810.04805.
RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [J]. The Journal of Machine Learning Research , 2020, 21: 1–67.
LEWIS M,LIU Y,GOYAL N,et al. BART: denoising swquence-to-sequence pre-training for natural language generation, translation, and comprehension [EB/OL]. (2019–10–29)[2024–01–29]. https://arxiv.org/abs/1910.13461.
CHEN Y, KEMING C, SUN X, et al. A span-level bidirectional network for aspect sentiment triplet extraction [C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing . Abu Dhabi: Association for Computational Linguistics, 2022: 4300–4309.
JANOCHA K, CZARNECKI W M. On loss functions for deep neural networks in classification [EB/OL]. (2017–02–18) [2024–01–29]. https://arxiv.org/abs/1702.05659.
... 方面情感三元组提取(aspect sentiment triplet extraction,ASTE)是细粒度的情感分析任务,其目的是提取句子中的方面词、情感极性和意见词,主要应用于商品评论分析任务[1]. 例如在语句“The sweet treats are good but average service.”中,方面词是“sweet treats”和“service”;意见词是“good”和“average”,它们的情感极性分别是“正面”和“中立”. ...
... Comparison of aspect sentiment triplet extraction task results from different models Tab.6
%
模型
类型
14LAP
14RES
15RES
16RES
P
R
F1
P
R
F1
P
R
F1
P
R
F1
GAS[15]
T5
—
—
60.78
—
—
72.16
—
—
62.10
—
—
70.10
BARTABSA[14]
BART
61.41
56.19
58.69
65.52
64.99
65.25
59.14
59.38
59.26
66.60
68.68
67.62
JET[15]
BERT
55.39
47.33
51.04
70.56
55.94
62.40
64.45
51.96
57.53
70.42
58.37
63.83
B-MRC[18]
BERT
65.12
54.41
59.27
71.32
70.09
70.69
63.71
58.63
61.05
67.74
68.56
68.13
Dual-MRC[19]
BERT
57.39
53.88
55.58
71.55
69.14
70.32
63.78
51.87
57.21
68.60
66.24
67.40
GTS[29]
BERT
57.52
51.92
54.58
70.92
69.49
70.20
59.29
58.07
58.67
68.58
66.60
67.58
Span-ASTE[18]
BERT
63.44
55.84
59.38
72.89
70.89
71.85
62.18
64.45
63.27
69.45
71.17
70.26
本研究
BERT
62.83
56.43
59.56
72.68
71.26
71.96
62.97
63.61
63.29
69.75
71.04
70.39
本研究(CL)
BERT
64.32
57.34
60.63
73.10
71.34
72.21
63.57
64.53
64.05
69.98
71.53
70.75
本研究
RoBERTa
65.87
56.17
60.64
74.49
72.31
73.38
63.12
64.37
63.74
70.81
72.36
71.58
本研究(CL)
RoBERTa
67.49
58.63
62.75
75.36
72.52
73.91
64.17
64.76
64.46
71.88
72.74
72.31
3.7. 错误分析
如图5所示为所提方法在不同预训练模型下的推理结果. 其中虚线矩形内为方面词,实线矩形内为意见词. 可以看出,基于跨度的方法能够提高多词的提取效果,却出现提取错误跨度的问题. 在BERT的预测中,“saag and paneer and korma”被识别为同一目标,这可能是句子的上下文中共享相似的情感信息,导致模型将这些单词合并为一个目标. RoBERTa模型只针对掩码任务训练,更专注与句子中词与词的关系,可以提升提取的准确性,因此选择RoBERTa模型作为所提方法的最终模型. ...
... Comparison of aspect sentiment triplet extraction task results from different models Tab.6
%
模型
类型
14LAP
14RES
15RES
16RES
P
R
F1
P
R
F1
P
R
F1
P
R
F1
GAS[15]
T5
—
—
60.78
—
—
72.16
—
—
62.10
—
—
70.10
BARTABSA[14]
BART
61.41
56.19
58.69
65.52
64.99
65.25
59.14
59.38
59.26
66.60
68.68
67.62
JET[15]
BERT
55.39
47.33
51.04
70.56
55.94
62.40
64.45
51.96
57.53
70.42
58.37
63.83
B-MRC[18]
BERT
65.12
54.41
59.27
71.32
70.09
70.69
63.71
58.63
61.05
67.74
68.56
68.13
Dual-MRC[19]
BERT
57.39
53.88
55.58
71.55
69.14
70.32
63.78
51.87
57.21
68.60
66.24
67.40
GTS[29]
BERT
57.52
51.92
54.58
70.92
69.49
70.20
59.29
58.07
58.67
68.58
66.60
67.58
Span-ASTE[18]
BERT
63.44
55.84
59.38
72.89
70.89
71.85
62.18
64.45
63.27
69.45
71.17
70.26
本研究
BERT
62.83
56.43
59.56
72.68
71.26
71.96
62.97
63.61
63.29
69.75
71.04
70.39
本研究(CL)
BERT
64.32
57.34
60.63
73.10
71.34
72.21
63.57
64.53
64.05
69.98
71.53
70.75
本研究
RoBERTa
65.87
56.17
60.64
74.49
72.31
73.38
63.12
64.37
63.74
70.81
72.36
71.58
本研究(CL)
RoBERTa
67.49
58.63
62.75
75.36
72.52
73.91
64.17
64.76
64.46
71.88
72.74
72.31
3.7. 错误分析
如图5所示为所提方法在不同预训练模型下的推理结果. 其中虚线矩形内为方面词,实线矩形内为意见词. 可以看出,基于跨度的方法能够提高多词的提取效果,却出现提取错误跨度的问题. 在BERT的预测中,“saag and paneer and korma”被识别为同一目标,这可能是句子的上下文中共享相似的情感信息,导致模型将这些单词合并为一个目标. RoBERTa模型只针对掩码任务训练,更专注与句子中词与词的关系,可以提升提取的准确性,因此选择RoBERTa模型作为所提方法的最终模型. ...
... [15]
BERT
55.39
47.33
51.04
70.56
55.94
62.40
64.45
51.96
57.53
70.42
58.37
63.83
B-MRC[18]
BERT
65.12
54.41
59.27
71.32
70.09
70.69
63.71
58.63
61.05
67.74
68.56
68.13
Dual-MRC[19]
BERT
57.39
53.88
55.58
71.55
69.14
70.32
63.78
51.87
57.21
68.60
66.24
67.40
GTS[29]
BERT
57.52
51.92
54.58
70.92
69.49
70.20
59.29
58.07
58.67
68.58
66.60
67.58
Span-ASTE[18]
BERT
63.44
55.84
59.38
72.89
70.89
71.85
62.18
64.45
63.27
69.45
71.17
70.26
本研究
BERT
62.83
56.43
59.56
72.68
71.26
71.96
62.97
63.61
63.29
69.75
71.04
70.39
本研究(CL)
BERT
64.32
57.34
60.63
73.10
71.34
72.21
63.57
64.53
64.05
69.98
71.53
70.75
本研究
RoBERTa
65.87
56.17
60.64
74.49
72.31
73.38
63.12
64.37
63.74
70.81
72.36
71.58
本研究(CL)
RoBERTa
67.49
58.63
62.75
75.36
72.52
73.91
64.17
64.76
64.46
71.88
72.74
72.31
3.7. 错误分析
如图5所示为所提方法在不同预训练模型下的推理结果. 其中虚线矩形内为方面词,实线矩形内为意见词. 可以看出,基于跨度的方法能够提高多词的提取效果,却出现提取错误跨度的问题. 在BERT的预测中,“saag and paneer and korma”被识别为同一目标,这可能是句子的上下文中共享相似的情感信息,导致模型将这些单词合并为一个目标. RoBERTa模型只针对掩码任务训练,更专注与句子中词与词的关系,可以提升提取的准确性,因此选择RoBERTa模型作为所提方法的最终模型. ...
... 如图3所示为所提课程学习框架在ASTE任务中的训练过程,图中的意见词均用斜体表现,3种情感极性均写在括号内,放在对应的方面词后面. 参考机器翻译的句子划分策略[16-19],将数据集按照句式由短至长排序后分为3份:$ {{Q_1}、{Q_2}、{Q_3}} $. 其中${Q_1}$包含句子长度小于10个字母的样本,如简短语句“Good food(POS) .”;${Q_2}$包含句子长度小于20个字母大于等于10个字母的样本,如较复杂语句 “A cheap eat(POS) for NYC , but not for dosa(NEG) .”;${Q_3}$包含句子长度大于等于20个字母的样本,如复杂语句 “For the next hour and a half we stood in the crowded lobby area(NEG) of this touristy restaurant listening to all types of explanations of why we were not being seated .”. 如算法1所示,定义判断模型是否收敛的函数来表现模型能力,如果模型收敛则本轮学习结束,可以输入更难的样本. 先将${Q_1}$送入模型训练,模型收敛后再送入${Q_2}$, 最后送入${Q_3}$. 通过逐渐增加课程学习框架的任务强度(先训练数据集中小且简单的样本,再加入更难样本,最终放入所有样本),帮助模型逐步学习语句更复杂的特征和规律. ...
... Comparison of aspect sentiment triplet extraction task results from different models Tab.6
%
模型
类型
14LAP
14RES
15RES
16RES
P
R
F1
P
R
F1
P
R
F1
P
R
F1
GAS[15]
T5
—
—
60.78
—
—
72.16
—
—
62.10
—
—
70.10
BARTABSA[14]
BART
61.41
56.19
58.69
65.52
64.99
65.25
59.14
59.38
59.26
66.60
68.68
67.62
JET[15]
BERT
55.39
47.33
51.04
70.56
55.94
62.40
64.45
51.96
57.53
70.42
58.37
63.83
B-MRC[18]
BERT
65.12
54.41
59.27
71.32
70.09
70.69
63.71
58.63
61.05
67.74
68.56
68.13
Dual-MRC[19]
BERT
57.39
53.88
55.58
71.55
69.14
70.32
63.78
51.87
57.21
68.60
66.24
67.40
GTS[29]
BERT
57.52
51.92
54.58
70.92
69.49
70.20
59.29
58.07
58.67
68.58
66.60
67.58
Span-ASTE[18]
BERT
63.44
55.84
59.38
72.89
70.89
71.85
62.18
64.45
63.27
69.45
71.17
70.26
本研究
BERT
62.83
56.43
59.56
72.68
71.26
71.96
62.97
63.61
63.29
69.75
71.04
70.39
本研究(CL)
BERT
64.32
57.34
60.63
73.10
71.34
72.21
63.57
64.53
64.05
69.98
71.53
70.75
本研究
RoBERTa
65.87
56.17
60.64
74.49
72.31
73.38
63.12
64.37
63.74
70.81
72.36
71.58
本研究(CL)
RoBERTa
67.49
58.63
62.75
75.36
72.52
73.91
64.17
64.76
64.46
71.88
72.74
72.31
3.7. 错误分析
如图5所示为所提方法在不同预训练模型下的推理结果. 其中虚线矩形内为方面词,实线矩形内为意见词. 可以看出,基于跨度的方法能够提高多词的提取效果,却出现提取错误跨度的问题. 在BERT的预测中,“saag and paneer and korma”被识别为同一目标,这可能是句子的上下文中共享相似的情感信息,导致模型将这些单词合并为一个目标. RoBERTa模型只针对掩码任务训练,更专注与句子中词与词的关系,可以提升提取的准确性,因此选择RoBERTa模型作为所提方法的最终模型. ...
... [18]
BERT
63.44
55.84
59.38
72.89
70.89
71.85
62.18
64.45
63.27
69.45
71.17
70.26
本研究
BERT
62.83
56.43
59.56
72.68
71.26
71.96
62.97
63.61
63.29
69.75
71.04
70.39
本研究(CL)
BERT
64.32
57.34
60.63
73.10
71.34
72.21
63.57
64.53
64.05
69.98
71.53
70.75
本研究
RoBERTa
65.87
56.17
60.64
74.49
72.31
73.38
63.12
64.37
63.74
70.81
72.36
71.58
本研究(CL)
RoBERTa
67.49
58.63
62.75
75.36
72.52
73.91
64.17
64.76
64.46
71.88
72.74
72.31
3.7. 错误分析
如图5所示为所提方法在不同预训练模型下的推理结果. 其中虚线矩形内为方面词,实线矩形内为意见词. 可以看出,基于跨度的方法能够提高多词的提取效果,却出现提取错误跨度的问题. 在BERT的预测中,“saag and paneer and korma”被识别为同一目标,这可能是句子的上下文中共享相似的情感信息,导致模型将这些单词合并为一个目标. RoBERTa模型只针对掩码任务训练,更专注与句子中词与词的关系,可以提升提取的准确性,因此选择RoBERTa模型作为所提方法的最终模型. ...
2
... 如图3所示为所提课程学习框架在ASTE任务中的训练过程,图中的意见词均用斜体表现,3种情感极性均写在括号内,放在对应的方面词后面. 参考机器翻译的句子划分策略[16-19],将数据集按照句式由短至长排序后分为3份:$ {{Q_1}、{Q_2}、{Q_3}} $. 其中${Q_1}$包含句子长度小于10个字母的样本,如简短语句“Good food(POS) .”;${Q_2}$包含句子长度小于20个字母大于等于10个字母的样本,如较复杂语句 “A cheap eat(POS) for NYC , but not for dosa(NEG) .”;${Q_3}$包含句子长度大于等于20个字母的样本,如复杂语句 “For the next hour and a half we stood in the crowded lobby area(NEG) of this touristy restaurant listening to all types of explanations of why we were not being seated .”. 如算法1所示,定义判断模型是否收敛的函数来表现模型能力,如果模型收敛则本轮学习结束,可以输入更难的样本. 先将${Q_1}$送入模型训练,模型收敛后再送入${Q_2}$, 最后送入${Q_3}$. 通过逐渐增加课程学习框架的任务强度(先训练数据集中小且简单的样本,再加入更难样本,最终放入所有样本),帮助模型逐步学习语句更复杂的特征和规律. ...
... Comparison of aspect sentiment triplet extraction task results from different models Tab.6
%
模型
类型
14LAP
14RES
15RES
16RES
P
R
F1
P
R
F1
P
R
F1
P
R
F1
GAS[15]
T5
—
—
60.78
—
—
72.16
—
—
62.10
—
—
70.10
BARTABSA[14]
BART
61.41
56.19
58.69
65.52
64.99
65.25
59.14
59.38
59.26
66.60
68.68
67.62
JET[15]
BERT
55.39
47.33
51.04
70.56
55.94
62.40
64.45
51.96
57.53
70.42
58.37
63.83
B-MRC[18]
BERT
65.12
54.41
59.27
71.32
70.09
70.69
63.71
58.63
61.05
67.74
68.56
68.13
Dual-MRC[19]
BERT
57.39
53.88
55.58
71.55
69.14
70.32
63.78
51.87
57.21
68.60
66.24
67.40
GTS[29]
BERT
57.52
51.92
54.58
70.92
69.49
70.20
59.29
58.07
58.67
68.58
66.60
67.58
Span-ASTE[18]
BERT
63.44
55.84
59.38
72.89
70.89
71.85
62.18
64.45
63.27
69.45
71.17
70.26
本研究
BERT
62.83
56.43
59.56
72.68
71.26
71.96
62.97
63.61
63.29
69.75
71.04
70.39
本研究(CL)
BERT
64.32
57.34
60.63
73.10
71.34
72.21
63.57
64.53
64.05
69.98
71.53
70.75
本研究
RoBERTa
65.87
56.17
60.64
74.49
72.31
73.38
63.12
64.37
63.74
70.81
72.36
71.58
本研究(CL)
RoBERTa
67.49
58.63
62.75
75.36
72.52
73.91
64.17
64.76
64.46
71.88
72.74
72.31
3.7. 错误分析
如图5所示为所提方法在不同预训练模型下的推理结果. 其中虚线矩形内为方面词,实线矩形内为意见词. 可以看出,基于跨度的方法能够提高多词的提取效果,却出现提取错误跨度的问题. 在BERT的预测中,“saag and paneer and korma”被识别为同一目标,这可能是句子的上下文中共享相似的情感信息,导致模型将这些单词合并为一个目标. RoBERTa模型只针对掩码任务训练,更专注与句子中词与词的关系,可以提升提取的准确性,因此选择RoBERTa模型作为所提方法的最终模型. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}