[1]
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Minneapolis: Association for Computational Linguistics, 2019: 4171–4186.
[本文引用: 6]
[2]
LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. (2019-07-26). https://arxiv.org/pdf/1907.11692.pdf.
[本文引用: 1]
[3]
LEWIS M, LIU Y, GOYAL N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [s.l.]: Association for Computational Linguistics, 2020: 7871–7880.
[本文引用: 2]
[4]
YAN H, DAI J, JI T, et al. A unified generative framework for aspect-based sentiment analysis [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing . [s.l.]: Association for Computational Linguistics, 2021: 2416–2429.
[本文引用: 1]
[5]
ZHAO Q, MA S, REN S. KESA: a knowledge enhanced approach for sentiment analysis [EB/OL]. (2022-02-24). https://arxiv.org/pdf/2202.12093.pdf.
[本文引用: 1]
[6]
BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. (2016-05-19). https://arxiv.org/pdf/1409.0473.pdf.
[本文引用: 1]
[7]
BAPNA A, FIRAT O. Simple, scalable adaptation for neural machine translation [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: Association for Computational Linguistics, 2019: 1538–1548.
[本文引用: 1]
[8]
AKIYAMA K, TAMURA A, NINOMIYA T. Hie-BART: document summarization with hierarchical BART [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistic . [s.l.]: North American Chapter of the Association for Computational Linguistics, 2021: 159–165.
[本文引用: 1]
[9]
SHI T, KENESHLOO Y, RAMAKRISHNAN N, et al. Neural abstractive text summarization with sequence-to-sequence models[EB/OL]. (2020-09-18). https://arxiv.org/pdf/1812.02303.pdf.
[本文引用: 1]
[10]
GUI A, XIAO H. HiFi: high-information attention heads hold for parameter-efficient model adaptation [EB/OL]. (2023-05-08). https://arxiv.org/pdf/2305.04573.pdf.
[本文引用: 1]
[11]
KOLLURU K, AGGARWAL S, RATHORE V, et al. IMoJIE: iterative memory-based joint open information extraction [C]// Proceedings of the 58th Annual meeting of the Association for Computational Linguistics . [s.l.]: Association for Computational Linguistics, 2020: 5871–5886.
[本文引用: 1]
[12]
DODGE J, ILHARCO G, SCHWARTZ R, et al. Fine-tuning pretrained language models: weight initializations, data orders, and early stopping [EB/OL]. (2020-02-15). https://arxiv.org/pdf/2002.06305.pdf.
[本文引用: 1]
[13]
HOWARD J, RUDER S. Universal language model fine-tuning for text classification [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics . Melbourne: Association for Computational Linguistics, 2018: 328–339.
[本文引用: 1]
[15]
DYER E, LEWKOWYCZ A, RAMASESH V. Effect of scale on catastrophic forgetting in neural networks [EB/OL]. (2022-01-29). https://openreview.net/pdf?id=GhVS8_yPeEa.
[本文引用: 1]
DYER E, LEWKOWYCZ A, RAMASESH V. Effect of scale on catastrophic forgetting in neural networks [EB/OL]. (2022-01-29). https://openreview.net/pdf?id=GhVS8_yPeEa.
[本文引用: 1]
[16]
HOULSHY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-efficient transfer learning for NLP [EB/OL]. (2019-06-13). https://arxiv.org/pdf/1902.00751.pdf.
[本文引用: 3]
[17]
HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [EB/OL]. (2021-10-16). https://arxiv.org/pdf/2106.09685.pdf.
[本文引用: 2]
[18]
LI X L, LIANG P. Prefix-tuning: optimizing continuous prompts for generation [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing . [s.l.]: Association for Computational Linguistics, 2021: 4582–4597.
[本文引用: 3]
[19]
CHEN J, ZHANG A, SHI X, et al. Parameter-efficient fine-tuning design spaces [EB/OL]. (2023-06-04). https://arxiv.org/pdf/2301.01821.pdf.
[本文引用: 1]
[20]
HE J, ZHOU C, MA X, et al. Towards a unified view of parameter-efficient transfer learning [EB/OL]. (2022-02-02). https://arxiv.org/pdf/2110.04366.pdf.
[本文引用: 1]
[21]
DE BARCELOS SILVA A, GOMES M M, DA COSTA C A, et al Intelligent personal assistants: a systematic literature review
[J]. Expert Systems with Applications , 2020 , 147 : 113193
DOI:10.1016/j.eswa.2020.113193
[本文引用: 2]
[22]
SUN Z, YU H, SONG X, et al. MobileBERT: a compact task-agnostic BERT for resource-limited devices [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [s.l.]: Association for Computational Linguistics, 2020: 2158–2170.
[本文引用: 3]
[23]
GUO L, CHOE W, LIN F X. STI: turbocharge NLP inference at the edge via elastic pipelining [C]// Proceedings of the 28th ACM International Conference on Architectural Support for Programming languages and Operating Systems . New York: Association for Computing Machinery, 2023: 791–803.
[本文引用: 1]
[24]
VASWANI A. Attention is all you need [J]. Advances in Neural Information Processing Systems. 2017, 30: 5998–6008.
[本文引用: 3]
[25]
RADFORD A, TIM S, ILYA S. Improving language understanding by generative pre-training [EB/OL]. [2024-01-01]. https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035.
[本文引用: 1]
[26]
RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2024-01-01]. https://insightcivic.s3.us-east-1.amazonaws.com/language-models.pdf.
[本文引用: 1]
[27]
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners [C]// LAROCHELLE H, RANZATU M, HADSELL R, et al. Advances in Neural Information Processing Systems: Vol. 33 . [s.l.]: Curran Associates, Inc. , 2020: 1877–1901.
[本文引用: 1]
[28]
RAFFEL C, SHAZEER N, ROBERTS A, et al Exploring the limits of transfer learning with a unified text-to-text transformer
[J]. Journal of Machine Learning Research , 2020 , 21 (140 ): 1 - 67
[本文引用: 1]
[29]
MOOSAVI N S, DELFOSSE Q, KERSTING K, et al. Adaptable Adapters [EB/OL]. (2022-05-03). https://arxiv.org/pdf/2205.01549.pdf.
[本文引用: 1]
[30]
RUCKLE A, GEIGLE G, GLOCKNER M, et al. AdapterDrop: on the efficiency of adapters in transformers [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing . [s.l.]: Association for Computational Linguistics, 2021: 7930–7946.
[本文引用: 2]
[31]
KARIMI MAHABADI R, HENDERSON J, RUDER S. Compacter: efficient low-rank hypercomplex adapter layers [C]// Advances in Neural Information Processing Systems: Vol. 34 . [s.l.]: Curran Associates, Inc. , 2021: 1022–1035.
[本文引用: 1]
[32]
CARTAS A, KOCOUR M, RAMAN A, et al. A reality check on inference at mobile networks edge [C]// Proceedings of the 2nd International Workshop on Edge Systems, Analytics and Networking . New York: Association for Computing Machinery, 2019: 54–59.
[本文引用: 1]
[33]
TAMBE T, HOOPER C, PENTECOST L, et al. EdgeBERT: sentence-level energy optimizations for latency-aware multi-task NLP inference [C]// MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture . New York: Association for Computing Machinery, 2021: 830–844.
[本文引用: 2]
[34]
BA J L, KIROS J R, HINTON G E. Layer normalization [EB/OL]. (2016-07-21). https://arxiv.org/pdf/1607.06450.pdf.
[本文引用: 1]
[35]
BENTIVOGLI L, CLARK P, DAGAN I, et al. The fifth PASCAL recognizing textual entailment challenge [J]. TAC . 2009, 7(8): 1.
[本文引用: 2]
[36]
DAGAN I, GLICKMAN O, MAGNINI B. The PASCAL Recognising textual entailment challenge [M]// QUIÑONERO-CANDELA J, DAGAN I, MAGNINI B, et al. Machine learning challenges. evaluating predictive uncertainty, visual object classification, and recognising tectual entailment . Berlin: Springer Berlin Heidelberg, 2006: 177–190.
[本文引用: 1]
[37]
BAR-HAIM R, DAGAN I, DOLAN B, et al. The second pascal recognising textual entailment challenge [C]// Proceedings of the 2nd PASCAL Challenges Workshop on Recognising Textual Entailment . [s.l.]: MSRA, 2006: 1.
[本文引用: 1]
[38]
GIAMPICCOLO D, MAGNINI B, DAGAN I, et al. The third PASCAL recognizing textual entailment challenge [C]// Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing . Prague: Association for Computational Linguistics, 2007: 1–9.
[本文引用: 2]
[39]
WARSTADT A, SINGH A, BOWMAN S R. Neural network acceptability judgments [EB/OL]. (2019-10-01). https://arxiv.org/pdf/1805.12471.pdf.
[本文引用: 1]
[40]
DOLAN W B, BROCKETT C. Automatically constructing a corpus of sentential paraphrases [C]// Proceedings of the third International Workshop on Paraphrasing . [s.l.]: IWP, 2005.
[本文引用: 1]
[41]
CER D, DIAB M, AGIRRE E, et al. SemEval-2017 task 1: semantic textual similarity multilingual and crosslingual focused evaluation [C]// Proceedings of the 11th International Workshop on Semantic Evaluation . Vancouver: Association for Computational Linguistics, 2017: 1–14.
[本文引用: 1]
[42]
LHONEST Q, VILLANOVA DEL MORAL A, JERNITE Y, et al. Datasets: a community library for natural language processing [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations . [s.l.]: Association for Computational Linguistics, 2021: 175–184.
[本文引用: 1]
[43]
WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations . [s.l.]: Association for Computational Linguistics, 2020: 38–45.
[本文引用: 1]
[44]
PFEIFFER J, RUCKLE A, POTH C, et al. AdapterHub: a framework for adapting transformers [EB/OL]. (2020-10-06). https://arxiv.org/pdf/2007.07779.pdf.
[本文引用: 1]
6
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
... [1 ,12 -13 ]. 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
... 预训练语言模型通常是大型的神经网络模型,被广泛应用于自然语言处理领域. 预训练语言模型通常遵循“预训练-微调”的范式,即模型首先在大规模的无标注语料库上预训练,然后通过在下游任务的标注数据集上微调实现迁移. 随着 Transformer [24 ] 模型结构的提出和发展,目前主流的预训练语言模型通常是基于Transformer 架构的. 这类模型完全通过自注意力机制实现上下文建模,被认为是优质的语言编码器,其产生的上下文语言表示具备丰富的知识,可以被迁移到下游任务. BERT[1 ] 是基于 Transformer 架构的预训练语言模型的一个代表,BERT 利用 Transformer 模型的 Encoder 部分构建了一个双向编码器. 在输入部分,BERT 通过3种嵌入相加作为输入文本的嵌入,并在掩码语言模型(masked language model, MLM)预训练任务和下一句预测(next sentence prediction,NSP)预训练任务下经过大规模无标注语料库的预训练. 在BERT的基础上,RoBERTa[2 ] 仅通过一些训练上的技巧以及使用更多的数据,在相同的模型结构上达到了远超BERT的效果,证明了其模型结构的巨大潜力. 与以BERT和RoBERTa为代表的编码器模型不同,GPT-1[25 ] 以及GPT-2[26 ] 、GPT-3[27 ] 、GPT-4采用了另一种模型结构,即解码器模型. 具体地说,GPT系列模型采用Transformer模型的Decoder部分作为模型基础架构,采用下一词预测(next token prediction,NTP)的自回归式预训练任务进行预训练. 除了只利用Transformer模型的一半(Encoder或Decoder)的模型,也有一些工作同时利用了Encoder和Decoder. 如BART[3 ] 和T5[28 ] 采用Encoder-Decoder架构,同时通过类似MLM的文本去噪任务和类似NTP的回归式任务在大规模的语料库上预训练. 虽然预训练语言模型在众多自然语言处理任务上达到了先进的性能水平,其巨大的参数量对计算资源的要求很高,在资源受限的场景中往往无法有效应用. ...
... 随着自然语言处理技术的不断发展,自然语言处理方法也已经被大量使用在包括手机、IoT设备在内的移动设备中[21 -22 ] . 边缘端自然语言处理主要的云边协同部署方法如图2 所示. 相比于直接部署在云端的方法,部署在边缘侧的方法可以最大化利用分布在用户端的边缘设备算力,大大降低云端的计算和存储需求[32 -33 ] . 目前的边缘端自然语言处理方法主要聚焦于如何使得大型的预训练语言模型能够在边缘设备中运行. 例如MobileBERT[22 ] 提出降维压缩的BERT[1 ] 模型变种,实现了对BERT模型的4倍以上压缩,使之能够运行在移动设备上. EdgeBERT[33 ] 则提出基于熵的早退算法,具体地说,EdgeBERT在每一层使用基于熵的算法计算该层的输出能否满足任务的需要,即是否可以早退,这种机制使得可以BERT模型的前几层就退出计算,可以节省计算资源. 然而,上述方法均须对模型进行一定程度的压缩或剪枝,无法充分利用大型预训练语言模型的强大能力. 同时,常规的压缩或剪枝仅能做到个位数级别的压缩,边缘设备的计算和存储需求没有得到足够的缓解. ...
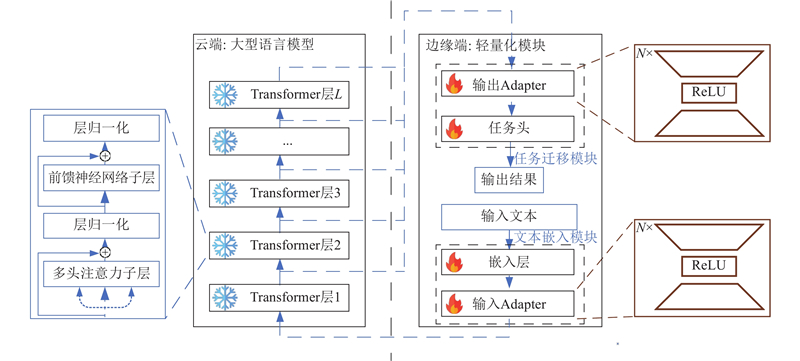
... 采用BERT[1 ] 模型作为骨干网络. 如图4 (左侧)所示,BERT模型是基于 Transformer[24 ] 结构的神经网络模型,Transformer 层是其基本结构. 在BERT模型中,输入文本首先经过嵌入层转换为文本嵌入表示,然后经过若干层结构相同的Transformer层进行双向语义建模. 具体来说,对于输入文本$ {\boldsymbol{X}} $ $ {\boldsymbol{H}}_t^0 $
... 1) BERT[1 ] 模型微调:在下游任务上微调是预训练BERT模型向下游任务迁移的主流做法,但是由于BERT模型运行需要的计算开销过大,通常无法直接在边缘设备中运行. ...
1
... 预训练语言模型通常是大型的神经网络模型,被广泛应用于自然语言处理领域. 预训练语言模型通常遵循“预训练-微调”的范式,即模型首先在大规模的无标注语料库上预训练,然后通过在下游任务的标注数据集上微调实现迁移. 随着 Transformer [24 ] 模型结构的提出和发展,目前主流的预训练语言模型通常是基于Transformer 架构的. 这类模型完全通过自注意力机制实现上下文建模,被认为是优质的语言编码器,其产生的上下文语言表示具备丰富的知识,可以被迁移到下游任务. BERT[1 ] 是基于 Transformer 架构的预训练语言模型的一个代表,BERT 利用 Transformer 模型的 Encoder 部分构建了一个双向编码器. 在输入部分,BERT 通过3种嵌入相加作为输入文本的嵌入,并在掩码语言模型(masked language model, MLM)预训练任务和下一句预测(next sentence prediction,NSP)预训练任务下经过大规模无标注语料库的预训练. 在BERT的基础上,RoBERTa[2 ] 仅通过一些训练上的技巧以及使用更多的数据,在相同的模型结构上达到了远超BERT的效果,证明了其模型结构的巨大潜力. 与以BERT和RoBERTa为代表的编码器模型不同,GPT-1[25 ] 以及GPT-2[26 ] 、GPT-3[27 ] 、GPT-4采用了另一种模型结构,即解码器模型. 具体地说,GPT系列模型采用Transformer模型的Decoder部分作为模型基础架构,采用下一词预测(next token prediction,NTP)的自回归式预训练任务进行预训练. 除了只利用Transformer模型的一半(Encoder或Decoder)的模型,也有一些工作同时利用了Encoder和Decoder. 如BART[3 ] 和T5[28 ] 采用Encoder-Decoder架构,同时通过类似MLM的文本去噪任务和类似NTP的回归式任务在大规模的语料库上预训练. 虽然预训练语言模型在众多自然语言处理任务上达到了先进的性能水平,其巨大的参数量对计算资源的要求很高,在资源受限的场景中往往无法有效应用. ...
2
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
... 预训练语言模型通常是大型的神经网络模型,被广泛应用于自然语言处理领域. 预训练语言模型通常遵循“预训练-微调”的范式,即模型首先在大规模的无标注语料库上预训练,然后通过在下游任务的标注数据集上微调实现迁移. 随着 Transformer [24 ] 模型结构的提出和发展,目前主流的预训练语言模型通常是基于Transformer 架构的. 这类模型完全通过自注意力机制实现上下文建模,被认为是优质的语言编码器,其产生的上下文语言表示具备丰富的知识,可以被迁移到下游任务. BERT[1 ] 是基于 Transformer 架构的预训练语言模型的一个代表,BERT 利用 Transformer 模型的 Encoder 部分构建了一个双向编码器. 在输入部分,BERT 通过3种嵌入相加作为输入文本的嵌入,并在掩码语言模型(masked language model, MLM)预训练任务和下一句预测(next sentence prediction,NSP)预训练任务下经过大规模无标注语料库的预训练. 在BERT的基础上,RoBERTa[2 ] 仅通过一些训练上的技巧以及使用更多的数据,在相同的模型结构上达到了远超BERT的效果,证明了其模型结构的巨大潜力. 与以BERT和RoBERTa为代表的编码器模型不同,GPT-1[25 ] 以及GPT-2[26 ] 、GPT-3[27 ] 、GPT-4采用了另一种模型结构,即解码器模型. 具体地说,GPT系列模型采用Transformer模型的Decoder部分作为模型基础架构,采用下一词预测(next token prediction,NTP)的自回归式预训练任务进行预训练. 除了只利用Transformer模型的一半(Encoder或Decoder)的模型,也有一些工作同时利用了Encoder和Decoder. 如BART[3 ] 和T5[28 ] 采用Encoder-Decoder架构,同时通过类似MLM的文本去噪任务和类似NTP的回归式任务在大规模的语料库上预训练. 虽然预训练语言模型在众多自然语言处理任务上达到了先进的性能水平,其巨大的参数量对计算资源的要求很高,在资源受限的场景中往往无法有效应用. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
Catastrophic forgetting in connectionist networks
1
1999
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
3
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
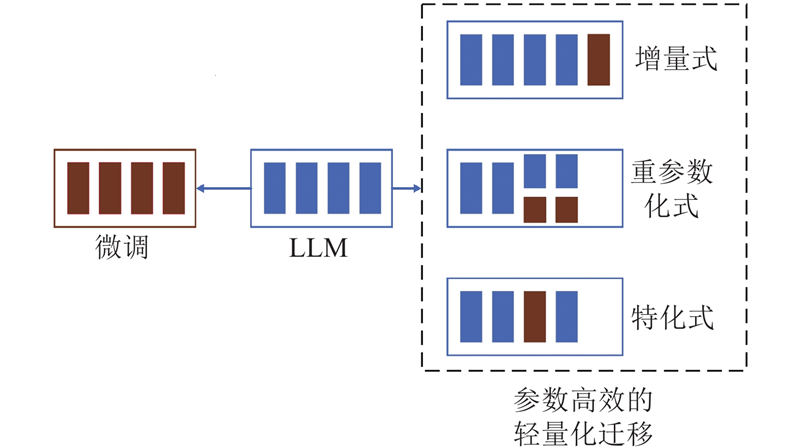
... 参数高效的轻量化迁移学习如图1 所示,这种方法的核心思想在于保持大型预训练语言模型中的绝大部分参数不变,在迁移过程中仅微调极少量的参数. 如 Adapter 方法[16 ,29 -30 ] 通过在预训练模型的每一个 Transformer [24 ] 层(或部分层)中插入轻量化 Adapter 模块,并在微调时冻结预训练语言模型的参数,仅微调轻量化 Adapter 模块的参数实现向下游任务的迁移. 一些工作尝试在 Adapter 方法的基础上进一步提高参数效率. 例如 Compactor [31 ] 提出使用hypercomplex multiplication 将参数矩阵分解,并在多个层中共享参数以实现更高的参数效率. AdapterDrop[30 ] 则是通过去除最初几层中的 Adapter 模块实现训练参数量的减少. Prefix-tuning[18 ] 是另一种参数高效的轻量化微调方法,与 Adapter 方法向 Transformer 层中插入轻量化模块不同,Prefix-tuning方法通过在模型的输入中向每一层激活向量中插入一些可训练的前缀向量来实现迁移学习. LoRA[17 ] 方法则基于预训练语言模型迁移微调的低秩性假设,提出对 Transformer 模型自注意力部分的参数进行重参数化,通过矩阵低秩分解的方法实现高效的迁移. 虽然上述轻量化迁移方法已经达到了较高的参数效率,但是它们均须和预训练语言模型紧密耦合,无法实现分离式的部署. 本研究所提出的方法也具备参数高效的特点,然而与上述参数高效的轻量化学习方法不同,本研究专注于可分布式部署的轻量化迁移学习研究. ...
... 2) 参数高效的轻量化迁移方法:以Adapter[16 ] 、LoRA[17 ] 、Prefix-tuining[18 ] 等模型为代表的轻量化迁移方法为大型预训练语言模型全量微调的迁移方法提供了高效且强力的替代,但这类方法向预训练语言模型的每一层中插入新的模块,其对预训练语言模型每一层的计算结果都会带来改变,因此这种方法是一种与预训练语言模型紧密耦合的架构,无法与预训练语言模型分离部署. ...
2
... 参数高效的轻量化迁移学习如图1 所示,这种方法的核心思想在于保持大型预训练语言模型中的绝大部分参数不变,在迁移过程中仅微调极少量的参数. 如 Adapter 方法[16 ,29 -30 ] 通过在预训练模型的每一个 Transformer [24 ] 层(或部分层)中插入轻量化 Adapter 模块,并在微调时冻结预训练语言模型的参数,仅微调轻量化 Adapter 模块的参数实现向下游任务的迁移. 一些工作尝试在 Adapter 方法的基础上进一步提高参数效率. 例如 Compactor [31 ] 提出使用hypercomplex multiplication 将参数矩阵分解,并在多个层中共享参数以实现更高的参数效率. AdapterDrop[30 ] 则是通过去除最初几层中的 Adapter 模块实现训练参数量的减少. Prefix-tuning[18 ] 是另一种参数高效的轻量化微调方法,与 Adapter 方法向 Transformer 层中插入轻量化模块不同,Prefix-tuning方法通过在模型的输入中向每一层激活向量中插入一些可训练的前缀向量来实现迁移学习. LoRA[17 ] 方法则基于预训练语言模型迁移微调的低秩性假设,提出对 Transformer 模型自注意力部分的参数进行重参数化,通过矩阵低秩分解的方法实现高效的迁移. 虽然上述轻量化迁移方法已经达到了较高的参数效率,但是它们均须和预训练语言模型紧密耦合,无法实现分离式的部署. 本研究所提出的方法也具备参数高效的特点,然而与上述参数高效的轻量化学习方法不同,本研究专注于可分布式部署的轻量化迁移学习研究. ...
... 2) 参数高效的轻量化迁移方法:以Adapter[16 ] 、LoRA[17 ] 、Prefix-tuining[18 ] 等模型为代表的轻量化迁移方法为大型预训练语言模型全量微调的迁移方法提供了高效且强力的替代,但这类方法向预训练语言模型的每一层中插入新的模块,其对预训练语言模型每一层的计算结果都会带来改变,因此这种方法是一种与预训练语言模型紧密耦合的架构,无法与预训练语言模型分离部署. ...
3
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
... 参数高效的轻量化迁移学习如图1 所示,这种方法的核心思想在于保持大型预训练语言模型中的绝大部分参数不变,在迁移过程中仅微调极少量的参数. 如 Adapter 方法[16 ,29 -30 ] 通过在预训练模型的每一个 Transformer [24 ] 层(或部分层)中插入轻量化 Adapter 模块,并在微调时冻结预训练语言模型的参数,仅微调轻量化 Adapter 模块的参数实现向下游任务的迁移. 一些工作尝试在 Adapter 方法的基础上进一步提高参数效率. 例如 Compactor [31 ] 提出使用hypercomplex multiplication 将参数矩阵分解,并在多个层中共享参数以实现更高的参数效率. AdapterDrop[30 ] 则是通过去除最初几层中的 Adapter 模块实现训练参数量的减少. Prefix-tuning[18 ] 是另一种参数高效的轻量化微调方法,与 Adapter 方法向 Transformer 层中插入轻量化模块不同,Prefix-tuning方法通过在模型的输入中向每一层激活向量中插入一些可训练的前缀向量来实现迁移学习. LoRA[17 ] 方法则基于预训练语言模型迁移微调的低秩性假设,提出对 Transformer 模型自注意力部分的参数进行重参数化,通过矩阵低秩分解的方法实现高效的迁移. 虽然上述轻量化迁移方法已经达到了较高的参数效率,但是它们均须和预训练语言模型紧密耦合,无法实现分离式的部署. 本研究所提出的方法也具备参数高效的特点,然而与上述参数高效的轻量化学习方法不同,本研究专注于可分布式部署的轻量化迁移学习研究. ...
... 2) 参数高效的轻量化迁移方法:以Adapter[16 ] 、LoRA[17 ] 、Prefix-tuining[18 ] 等模型为代表的轻量化迁移方法为大型预训练语言模型全量微调的迁移方法提供了高效且强力的替代,但这类方法向预训练语言模型的每一层中插入新的模块,其对预训练语言模型每一层的计算结果都会带来改变,因此这种方法是一种与预训练语言模型紧密耦合的架构,无法与预训练语言模型分离部署. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
1
... 随着大型预训练语言模型(large pre-trained language model, LLM)[1 -3 ] 的快速发展,许多自然语言处理(natural language processing, NLP)的下游任务的性能得到了显著提升,如情感分析[4 -5 ] 、机器翻译[6 -7 ] 、文本摘要[8 -9 ] 和信息抽取[10 -11 ] 等. 在典型的设置下,将大型预训练语言模型应用在具体的下游任务的流行做法是直接在下游任务的有标注数据集上微调大型预训练语言模型[1 ,12 -13 ] . 然而,大型预训练语言模型通常由百亿乃至千亿以上的参数组成,其对于计算资源(算力、内存、存储)的要求越来越高,使得大型预训练语言模型无法在包括移动设备在内的边缘设备上运行. 此外,由于深度学习中普遍存在的灾难性遗忘(catastrophic forgetting)问题[14 -15 ] 的存在,在多任务或者多领域场景下,须为每个不同的任务或领域创建一个独立的预训练语言模型的副本,并分别进行训练. 这样的模型需要极大的计算和存储开销,使得大型预训练语言模型无法有效地使用在多任务或多领域场景. 最近,参数高效的轻量化迁移学习(parameter efficient transfer learning, PETL)方法吸引了众多研究人员的注意. 参数高效的轻量化迁移学习[16 -18 ] 方法是基于大型预训练语言模型设计一个新的模型,并将新模型的参数分为2个部分:占绝大部分的被冻结的预训练语言模型参数和占少部分的轻量化可学习模块[19 -20 ] . 在向下游任务迁移时,参数高效的轻量化学习方法只在下游任务数据集上微调轻量化可学习模块的参数,保持占绝大部分的预训练语言模型参数不变. 最终不同任务上获得的模型仅在少部分轻量化模块参数上存在差异,因此可以在多个任务或领域下共享大型预训练语言模型的参数,从而实现较高的计算和存储效率. ...
Intelligent personal assistants: a systematic literature review
2
2020
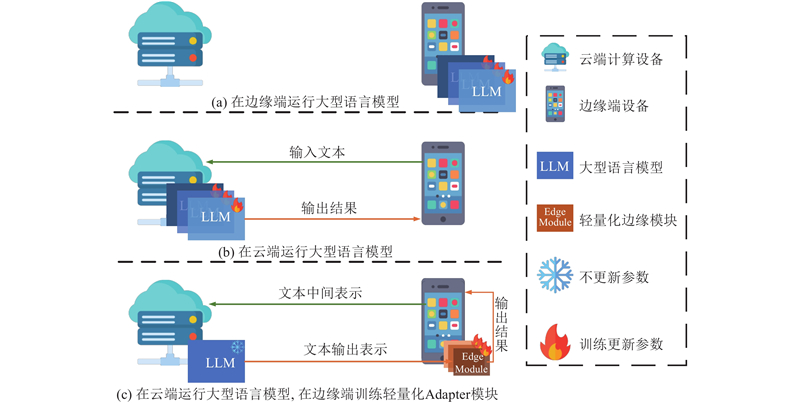
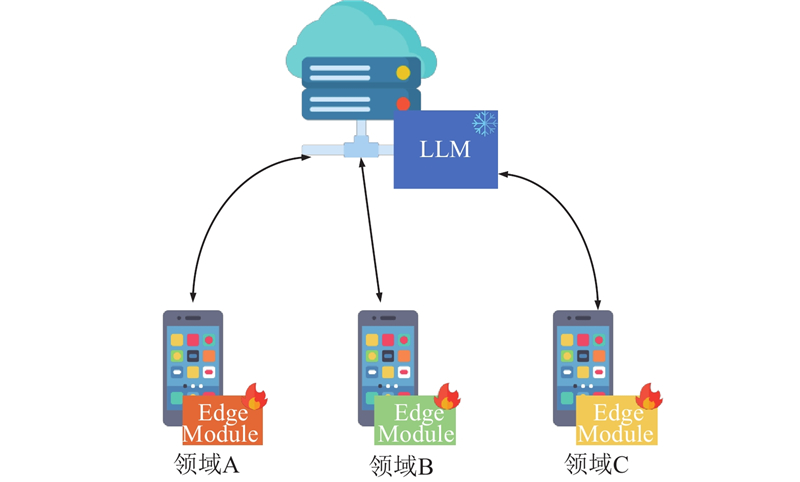
... 在边缘设备场景中,自然语言处理技术的快速推广带动了许多深入不同用户习惯和场景的应用的发展,如智能语音助手[21 ] . 在这类场景下一种简单的做法是直接将模型运行在计算资源丰富的云端,但是这种做法难以权衡计算和存储开销与模型性能表现. 如果为每个场景微调不同的模型,那么云端须为每个场景分别保存和运行不同的大型预训练语言模型;如果所有场景共享同一个模型,那么模型性能难以较好地泛化到所有场景,因此用户体验难以保证. 另一种做法是尝试在边缘设备上运行模型[22 -23 ] ,这样的做法可以减轻云端的压力,充分利用分布在用户端的计算资源;但是大型预训练语言模型巨大的参数量所带来的高额计算开销是边缘设备难以提供的,轻量化的小模型又难以达到令人满意的性能. 参数高效的轻量化学习方法为大型预训练语言模型微调提供了一个高效的替代方案. 不过,目前典型的轻量化迁移学习方法仍然难以做到在边缘设备中运行. 这是因为轻量化迁移方法所引入或特化的轻量化可学习模块都会改变预训练语言模型的中间计算状态,这使得大型预训练语言模型与轻量化模块之间必须频繁交互,导致它们只能运行于同一个计算设备上,无法实现分布式部署. ...
... 随着自然语言处理技术的不断发展,自然语言处理方法也已经被大量使用在包括手机、IoT设备在内的移动设备中[21 -22 ] . 边缘端自然语言处理主要的云边协同部署方法如图2 所示. 相比于直接部署在云端的方法,部署在边缘侧的方法可以最大化利用分布在用户端的边缘设备算力,大大降低云端的计算和存储需求[32 -33 ] . 目前的边缘端自然语言处理方法主要聚焦于如何使得大型的预训练语言模型能够在边缘设备中运行. 例如MobileBERT[22 ] 提出降维压缩的BERT[1 ] 模型变种,实现了对BERT模型的4倍以上压缩,使之能够运行在移动设备上. EdgeBERT[33 ] 则提出基于熵的早退算法,具体地说,EdgeBERT在每一层使用基于熵的算法计算该层的输出能否满足任务的需要,即是否可以早退,这种机制使得可以BERT模型的前几层就退出计算,可以节省计算资源. 然而,上述方法均须对模型进行一定程度的压缩或剪枝,无法充分利用大型预训练语言模型的强大能力. 同时,常规的压缩或剪枝仅能做到个位数级别的压缩,边缘设备的计算和存储需求没有得到足够的缓解. ...
3
... 在边缘设备场景中,自然语言处理技术的快速推广带动了许多深入不同用户习惯和场景的应用的发展,如智能语音助手[21 ] . 在这类场景下一种简单的做法是直接将模型运行在计算资源丰富的云端,但是这种做法难以权衡计算和存储开销与模型性能表现. 如果为每个场景微调不同的模型,那么云端须为每个场景分别保存和运行不同的大型预训练语言模型;如果所有场景共享同一个模型,那么模型性能难以较好地泛化到所有场景,因此用户体验难以保证. 另一种做法是尝试在边缘设备上运行模型[22 -23 ] ,这样的做法可以减轻云端的压力,充分利用分布在用户端的计算资源;但是大型预训练语言模型巨大的参数量所带来的高额计算开销是边缘设备难以提供的,轻量化的小模型又难以达到令人满意的性能. 参数高效的轻量化学习方法为大型预训练语言模型微调提供了一个高效的替代方案. 不过,目前典型的轻量化迁移学习方法仍然难以做到在边缘设备中运行. 这是因为轻量化迁移方法所引入或特化的轻量化可学习模块都会改变预训练语言模型的中间计算状态,这使得大型预训练语言模型与轻量化模块之间必须频繁交互,导致它们只能运行于同一个计算设备上,无法实现分布式部署. ...
... 随着自然语言处理技术的不断发展,自然语言处理方法也已经被大量使用在包括手机、IoT设备在内的移动设备中[21 -22 ] . 边缘端自然语言处理主要的云边协同部署方法如图2 所示. 相比于直接部署在云端的方法,部署在边缘侧的方法可以最大化利用分布在用户端的边缘设备算力,大大降低云端的计算和存储需求[32 -33 ] . 目前的边缘端自然语言处理方法主要聚焦于如何使得大型的预训练语言模型能够在边缘设备中运行. 例如MobileBERT[22 ] 提出降维压缩的BERT[1 ] 模型变种,实现了对BERT模型的4倍以上压缩,使之能够运行在移动设备上. EdgeBERT[33 ] 则提出基于熵的早退算法,具体地说,EdgeBERT在每一层使用基于熵的算法计算该层的输出能否满足任务的需要,即是否可以早退,这种机制使得可以BERT模型的前几层就退出计算,可以节省计算资源. 然而,上述方法均须对模型进行一定程度的压缩或剪枝,无法充分利用大型预训练语言模型的强大能力. 同时,常规的压缩或剪枝仅能做到个位数级别的压缩,边缘设备的计算和存储需求没有得到足够的缓解. ...
... [22 ]提出降维压缩的BERT[1 ] 模型变种,实现了对BERT模型的4倍以上压缩,使之能够运行在移动设备上. EdgeBERT[33 ] 则提出基于熵的早退算法,具体地说,EdgeBERT在每一层使用基于熵的算法计算该层的输出能否满足任务的需要,即是否可以早退,这种机制使得可以BERT模型的前几层就退出计算,可以节省计算资源. 然而,上述方法均须对模型进行一定程度的压缩或剪枝,无法充分利用大型预训练语言模型的强大能力. 同时,常规的压缩或剪枝仅能做到个位数级别的压缩,边缘设备的计算和存储需求没有得到足够的缓解. ...
1
... 在边缘设备场景中,自然语言处理技术的快速推广带动了许多深入不同用户习惯和场景的应用的发展,如智能语音助手[21 ] . 在这类场景下一种简单的做法是直接将模型运行在计算资源丰富的云端,但是这种做法难以权衡计算和存储开销与模型性能表现. 如果为每个场景微调不同的模型,那么云端须为每个场景分别保存和运行不同的大型预训练语言模型;如果所有场景共享同一个模型,那么模型性能难以较好地泛化到所有场景,因此用户体验难以保证. 另一种做法是尝试在边缘设备上运行模型[22 -23 ] ,这样的做法可以减轻云端的压力,充分利用分布在用户端的计算资源;但是大型预训练语言模型巨大的参数量所带来的高额计算开销是边缘设备难以提供的,轻量化的小模型又难以达到令人满意的性能. 参数高效的轻量化学习方法为大型预训练语言模型微调提供了一个高效的替代方案. 不过,目前典型的轻量化迁移学习方法仍然难以做到在边缘设备中运行. 这是因为轻量化迁移方法所引入或特化的轻量化可学习模块都会改变预训练语言模型的中间计算状态,这使得大型预训练语言模型与轻量化模块之间必须频繁交互,导致它们只能运行于同一个计算设备上,无法实现分布式部署. ...
3
... 预训练语言模型通常是大型的神经网络模型,被广泛应用于自然语言处理领域. 预训练语言模型通常遵循“预训练-微调”的范式,即模型首先在大规模的无标注语料库上预训练,然后通过在下游任务的标注数据集上微调实现迁移. 随着 Transformer [24 ] 模型结构的提出和发展,目前主流的预训练语言模型通常是基于Transformer 架构的. 这类模型完全通过自注意力机制实现上下文建模,被认为是优质的语言编码器,其产生的上下文语言表示具备丰富的知识,可以被迁移到下游任务. BERT[1 ] 是基于 Transformer 架构的预训练语言模型的一个代表,BERT 利用 Transformer 模型的 Encoder 部分构建了一个双向编码器. 在输入部分,BERT 通过3种嵌入相加作为输入文本的嵌入,并在掩码语言模型(masked language model, MLM)预训练任务和下一句预测(next sentence prediction,NSP)预训练任务下经过大规模无标注语料库的预训练. 在BERT的基础上,RoBERTa[2 ] 仅通过一些训练上的技巧以及使用更多的数据,在相同的模型结构上达到了远超BERT的效果,证明了其模型结构的巨大潜力. 与以BERT和RoBERTa为代表的编码器模型不同,GPT-1[25 ] 以及GPT-2[26 ] 、GPT-3[27 ] 、GPT-4采用了另一种模型结构,即解码器模型. 具体地说,GPT系列模型采用Transformer模型的Decoder部分作为模型基础架构,采用下一词预测(next token prediction,NTP)的自回归式预训练任务进行预训练. 除了只利用Transformer模型的一半(Encoder或Decoder)的模型,也有一些工作同时利用了Encoder和Decoder. 如BART[3 ] 和T5[28 ] 采用Encoder-Decoder架构,同时通过类似MLM的文本去噪任务和类似NTP的回归式任务在大规模的语料库上预训练. 虽然预训练语言模型在众多自然语言处理任务上达到了先进的性能水平,其巨大的参数量对计算资源的要求很高,在资源受限的场景中往往无法有效应用. ...
... 参数高效的轻量化迁移学习如图1 所示,这种方法的核心思想在于保持大型预训练语言模型中的绝大部分参数不变,在迁移过程中仅微调极少量的参数. 如 Adapter 方法[16 ,29 -30 ] 通过在预训练模型的每一个 Transformer [24 ] 层(或部分层)中插入轻量化 Adapter 模块,并在微调时冻结预训练语言模型的参数,仅微调轻量化 Adapter 模块的参数实现向下游任务的迁移. 一些工作尝试在 Adapter 方法的基础上进一步提高参数效率. 例如 Compactor [31 ] 提出使用hypercomplex multiplication 将参数矩阵分解,并在多个层中共享参数以实现更高的参数效率. AdapterDrop[30 ] 则是通过去除最初几层中的 Adapter 模块实现训练参数量的减少. Prefix-tuning[18 ] 是另一种参数高效的轻量化微调方法,与 Adapter 方法向 Transformer 层中插入轻量化模块不同,Prefix-tuning方法通过在模型的输入中向每一层激活向量中插入一些可训练的前缀向量来实现迁移学习. LoRA[17 ] 方法则基于预训练语言模型迁移微调的低秩性假设,提出对 Transformer 模型自注意力部分的参数进行重参数化,通过矩阵低秩分解的方法实现高效的迁移. 虽然上述轻量化迁移方法已经达到了较高的参数效率,但是它们均须和预训练语言模型紧密耦合,无法实现分离式的部署. 本研究所提出的方法也具备参数高效的特点,然而与上述参数高效的轻量化学习方法不同,本研究专注于可分布式部署的轻量化迁移学习研究. ...
... 采用BERT[1 ] 模型作为骨干网络. 如图4 (左侧)所示,BERT模型是基于 Transformer[24 ] 结构的神经网络模型,Transformer 层是其基本结构. 在BERT模型中,输入文本首先经过嵌入层转换为文本嵌入表示,然后经过若干层结构相同的Transformer层进行双向语义建模. 具体来说,对于输入文本$ {\boldsymbol{X}} $ $ {\boldsymbol{H}}_t^0 $
1
... 预训练语言模型通常是大型的神经网络模型,被广泛应用于自然语言处理领域. 预训练语言模型通常遵循“预训练-微调”的范式,即模型首先在大规模的无标注语料库上预训练,然后通过在下游任务的标注数据集上微调实现迁移. 随着 Transformer [24 ] 模型结构的提出和发展,目前主流的预训练语言模型通常是基于Transformer 架构的. 这类模型完全通过自注意力机制实现上下文建模,被认为是优质的语言编码器,其产生的上下文语言表示具备丰富的知识,可以被迁移到下游任务. BERT[1 ] 是基于 Transformer 架构的预训练语言模型的一个代表,BERT 利用 Transformer 模型的 Encoder 部分构建了一个双向编码器. 在输入部分,BERT 通过3种嵌入相加作为输入文本的嵌入,并在掩码语言模型(masked language model, MLM)预训练任务和下一句预测(next sentence prediction,NSP)预训练任务下经过大规模无标注语料库的预训练. 在BERT的基础上,RoBERTa[2 ] 仅通过一些训练上的技巧以及使用更多的数据,在相同的模型结构上达到了远超BERT的效果,证明了其模型结构的巨大潜力. 与以BERT和RoBERTa为代表的编码器模型不同,GPT-1[25 ] 以及GPT-2[26 ] 、GPT-3[27 ] 、GPT-4采用了另一种模型结构,即解码器模型. 具体地说,GPT系列模型采用Transformer模型的Decoder部分作为模型基础架构,采用下一词预测(next token prediction,NTP)的自回归式预训练任务进行预训练. 除了只利用Transformer模型的一半(Encoder或Decoder)的模型,也有一些工作同时利用了Encoder和Decoder. 如BART[3 ] 和T5[28 ] 采用Encoder-Decoder架构,同时通过类似MLM的文本去噪任务和类似NTP的回归式任务在大规模的语料库上预训练. 虽然预训练语言模型在众多自然语言处理任务上达到了先进的性能水平,其巨大的参数量对计算资源的要求很高,在资源受限的场景中往往无法有效应用. ...
1
... 预训练语言模型通常是大型的神经网络模型,被广泛应用于自然语言处理领域. 预训练语言模型通常遵循“预训练-微调”的范式,即模型首先在大规模的无标注语料库上预训练,然后通过在下游任务的标注数据集上微调实现迁移. 随着 Transformer [24 ] 模型结构的提出和发展,目前主流的预训练语言模型通常是基于Transformer 架构的. 这类模型完全通过自注意力机制实现上下文建模,被认为是优质的语言编码器,其产生的上下文语言表示具备丰富的知识,可以被迁移到下游任务. BERT[1 ] 是基于 Transformer 架构的预训练语言模型的一个代表,BERT 利用 Transformer 模型的 Encoder 部分构建了一个双向编码器. 在输入部分,BERT 通过3种嵌入相加作为输入文本的嵌入,并在掩码语言模型(masked language model, MLM)预训练任务和下一句预测(next sentence prediction,NSP)预训练任务下经过大规模无标注语料库的预训练. 在BERT的基础上,RoBERTa[2 ] 仅通过一些训练上的技巧以及使用更多的数据,在相同的模型结构上达到了远超BERT的效果,证明了其模型结构的巨大潜力. 与以BERT和RoBERTa为代表的编码器模型不同,GPT-1[25 ] 以及GPT-2[26 ] 、GPT-3[27 ] 、GPT-4采用了另一种模型结构,即解码器模型. 具体地说,GPT系列模型采用Transformer模型的Decoder部分作为模型基础架构,采用下一词预测(next token prediction,NTP)的自回归式预训练任务进行预训练. 除了只利用Transformer模型的一半(Encoder或Decoder)的模型,也有一些工作同时利用了Encoder和Decoder. 如BART[3 ] 和T5[28 ] 采用Encoder-Decoder架构,同时通过类似MLM的文本去噪任务和类似NTP的回归式任务在大规模的语料库上预训练. 虽然预训练语言模型在众多自然语言处理任务上达到了先进的性能水平,其巨大的参数量对计算资源的要求很高,在资源受限的场景中往往无法有效应用. ...
1
... 预训练语言模型通常是大型的神经网络模型,被广泛应用于自然语言处理领域. 预训练语言模型通常遵循“预训练-微调”的范式,即模型首先在大规模的无标注语料库上预训练,然后通过在下游任务的标注数据集上微调实现迁移. 随着 Transformer [24 ] 模型结构的提出和发展,目前主流的预训练语言模型通常是基于Transformer 架构的. 这类模型完全通过自注意力机制实现上下文建模,被认为是优质的语言编码器,其产生的上下文语言表示具备丰富的知识,可以被迁移到下游任务. BERT[1 ] 是基于 Transformer 架构的预训练语言模型的一个代表,BERT 利用 Transformer 模型的 Encoder 部分构建了一个双向编码器. 在输入部分,BERT 通过3种嵌入相加作为输入文本的嵌入,并在掩码语言模型(masked language model, MLM)预训练任务和下一句预测(next sentence prediction,NSP)预训练任务下经过大规模无标注语料库的预训练. 在BERT的基础上,RoBERTa[2 ] 仅通过一些训练上的技巧以及使用更多的数据,在相同的模型结构上达到了远超BERT的效果,证明了其模型结构的巨大潜力. 与以BERT和RoBERTa为代表的编码器模型不同,GPT-1[25 ] 以及GPT-2[26 ] 、GPT-3[27 ] 、GPT-4采用了另一种模型结构,即解码器模型. 具体地说,GPT系列模型采用Transformer模型的Decoder部分作为模型基础架构,采用下一词预测(next token prediction,NTP)的自回归式预训练任务进行预训练. 除了只利用Transformer模型的一半(Encoder或Decoder)的模型,也有一些工作同时利用了Encoder和Decoder. 如BART[3 ] 和T5[28 ] 采用Encoder-Decoder架构,同时通过类似MLM的文本去噪任务和类似NTP的回归式任务在大规模的语料库上预训练. 虽然预训练语言模型在众多自然语言处理任务上达到了先进的性能水平,其巨大的参数量对计算资源的要求很高,在资源受限的场景中往往无法有效应用. ...
Exploring the limits of transfer learning with a unified text-to-text transformer
1
2020
... 预训练语言模型通常是大型的神经网络模型,被广泛应用于自然语言处理领域. 预训练语言模型通常遵循“预训练-微调”的范式,即模型首先在大规模的无标注语料库上预训练,然后通过在下游任务的标注数据集上微调实现迁移. 随着 Transformer [24 ] 模型结构的提出和发展,目前主流的预训练语言模型通常是基于Transformer 架构的. 这类模型完全通过自注意力机制实现上下文建模,被认为是优质的语言编码器,其产生的上下文语言表示具备丰富的知识,可以被迁移到下游任务. BERT[1 ] 是基于 Transformer 架构的预训练语言模型的一个代表,BERT 利用 Transformer 模型的 Encoder 部分构建了一个双向编码器. 在输入部分,BERT 通过3种嵌入相加作为输入文本的嵌入,并在掩码语言模型(masked language model, MLM)预训练任务和下一句预测(next sentence prediction,NSP)预训练任务下经过大规模无标注语料库的预训练. 在BERT的基础上,RoBERTa[2 ] 仅通过一些训练上的技巧以及使用更多的数据,在相同的模型结构上达到了远超BERT的效果,证明了其模型结构的巨大潜力. 与以BERT和RoBERTa为代表的编码器模型不同,GPT-1[25 ] 以及GPT-2[26 ] 、GPT-3[27 ] 、GPT-4采用了另一种模型结构,即解码器模型. 具体地说,GPT系列模型采用Transformer模型的Decoder部分作为模型基础架构,采用下一词预测(next token prediction,NTP)的自回归式预训练任务进行预训练. 除了只利用Transformer模型的一半(Encoder或Decoder)的模型,也有一些工作同时利用了Encoder和Decoder. 如BART[3 ] 和T5[28 ] 采用Encoder-Decoder架构,同时通过类似MLM的文本去噪任务和类似NTP的回归式任务在大规模的语料库上预训练. 虽然预训练语言模型在众多自然语言处理任务上达到了先进的性能水平,其巨大的参数量对计算资源的要求很高,在资源受限的场景中往往无法有效应用. ...
1
... 参数高效的轻量化迁移学习如图1 所示,这种方法的核心思想在于保持大型预训练语言模型中的绝大部分参数不变,在迁移过程中仅微调极少量的参数. 如 Adapter 方法[16 ,29 -30 ] 通过在预训练模型的每一个 Transformer [24 ] 层(或部分层)中插入轻量化 Adapter 模块,并在微调时冻结预训练语言模型的参数,仅微调轻量化 Adapter 模块的参数实现向下游任务的迁移. 一些工作尝试在 Adapter 方法的基础上进一步提高参数效率. 例如 Compactor [31 ] 提出使用hypercomplex multiplication 将参数矩阵分解,并在多个层中共享参数以实现更高的参数效率. AdapterDrop[30 ] 则是通过去除最初几层中的 Adapter 模块实现训练参数量的减少. Prefix-tuning[18 ] 是另一种参数高效的轻量化微调方法,与 Adapter 方法向 Transformer 层中插入轻量化模块不同,Prefix-tuning方法通过在模型的输入中向每一层激活向量中插入一些可训练的前缀向量来实现迁移学习. LoRA[17 ] 方法则基于预训练语言模型迁移微调的低秩性假设,提出对 Transformer 模型自注意力部分的参数进行重参数化,通过矩阵低秩分解的方法实现高效的迁移. 虽然上述轻量化迁移方法已经达到了较高的参数效率,但是它们均须和预训练语言模型紧密耦合,无法实现分离式的部署. 本研究所提出的方法也具备参数高效的特点,然而与上述参数高效的轻量化学习方法不同,本研究专注于可分布式部署的轻量化迁移学习研究. ...
2
... 参数高效的轻量化迁移学习如图1 所示,这种方法的核心思想在于保持大型预训练语言模型中的绝大部分参数不变,在迁移过程中仅微调极少量的参数. 如 Adapter 方法[16 ,29 -30 ] 通过在预训练模型的每一个 Transformer [24 ] 层(或部分层)中插入轻量化 Adapter 模块,并在微调时冻结预训练语言模型的参数,仅微调轻量化 Adapter 模块的参数实现向下游任务的迁移. 一些工作尝试在 Adapter 方法的基础上进一步提高参数效率. 例如 Compactor [31 ] 提出使用hypercomplex multiplication 将参数矩阵分解,并在多个层中共享参数以实现更高的参数效率. AdapterDrop[30 ] 则是通过去除最初几层中的 Adapter 模块实现训练参数量的减少. Prefix-tuning[18 ] 是另一种参数高效的轻量化微调方法,与 Adapter 方法向 Transformer 层中插入轻量化模块不同,Prefix-tuning方法通过在模型的输入中向每一层激活向量中插入一些可训练的前缀向量来实现迁移学习. LoRA[17 ] 方法则基于预训练语言模型迁移微调的低秩性假设,提出对 Transformer 模型自注意力部分的参数进行重参数化,通过矩阵低秩分解的方法实现高效的迁移. 虽然上述轻量化迁移方法已经达到了较高的参数效率,但是它们均须和预训练语言模型紧密耦合,无法实现分离式的部署. 本研究所提出的方法也具备参数高效的特点,然而与上述参数高效的轻量化学习方法不同,本研究专注于可分布式部署的轻量化迁移学习研究. ...
... [30 ]则是通过去除最初几层中的 Adapter 模块实现训练参数量的减少. Prefix-tuning[18 ] 是另一种参数高效的轻量化微调方法,与 Adapter 方法向 Transformer 层中插入轻量化模块不同,Prefix-tuning方法通过在模型的输入中向每一层激活向量中插入一些可训练的前缀向量来实现迁移学习. LoRA[17 ] 方法则基于预训练语言模型迁移微调的低秩性假设,提出对 Transformer 模型自注意力部分的参数进行重参数化,通过矩阵低秩分解的方法实现高效的迁移. 虽然上述轻量化迁移方法已经达到了较高的参数效率,但是它们均须和预训练语言模型紧密耦合,无法实现分离式的部署. 本研究所提出的方法也具备参数高效的特点,然而与上述参数高效的轻量化学习方法不同,本研究专注于可分布式部署的轻量化迁移学习研究. ...
1
... 参数高效的轻量化迁移学习如图1 所示,这种方法的核心思想在于保持大型预训练语言模型中的绝大部分参数不变,在迁移过程中仅微调极少量的参数. 如 Adapter 方法[16 ,29 -30 ] 通过在预训练模型的每一个 Transformer [24 ] 层(或部分层)中插入轻量化 Adapter 模块,并在微调时冻结预训练语言模型的参数,仅微调轻量化 Adapter 模块的参数实现向下游任务的迁移. 一些工作尝试在 Adapter 方法的基础上进一步提高参数效率. 例如 Compactor [31 ] 提出使用hypercomplex multiplication 将参数矩阵分解,并在多个层中共享参数以实现更高的参数效率. AdapterDrop[30 ] 则是通过去除最初几层中的 Adapter 模块实现训练参数量的减少. Prefix-tuning[18 ] 是另一种参数高效的轻量化微调方法,与 Adapter 方法向 Transformer 层中插入轻量化模块不同,Prefix-tuning方法通过在模型的输入中向每一层激活向量中插入一些可训练的前缀向量来实现迁移学习. LoRA[17 ] 方法则基于预训练语言模型迁移微调的低秩性假设,提出对 Transformer 模型自注意力部分的参数进行重参数化,通过矩阵低秩分解的方法实现高效的迁移. 虽然上述轻量化迁移方法已经达到了较高的参数效率,但是它们均须和预训练语言模型紧密耦合,无法实现分离式的部署. 本研究所提出的方法也具备参数高效的特点,然而与上述参数高效的轻量化学习方法不同,本研究专注于可分布式部署的轻量化迁移学习研究. ...
1
... 随着自然语言处理技术的不断发展,自然语言处理方法也已经被大量使用在包括手机、IoT设备在内的移动设备中[21 -22 ] . 边缘端自然语言处理主要的云边协同部署方法如图2 所示. 相比于直接部署在云端的方法,部署在边缘侧的方法可以最大化利用分布在用户端的边缘设备算力,大大降低云端的计算和存储需求[32 -33 ] . 目前的边缘端自然语言处理方法主要聚焦于如何使得大型的预训练语言模型能够在边缘设备中运行. 例如MobileBERT[22 ] 提出降维压缩的BERT[1 ] 模型变种,实现了对BERT模型的4倍以上压缩,使之能够运行在移动设备上. EdgeBERT[33 ] 则提出基于熵的早退算法,具体地说,EdgeBERT在每一层使用基于熵的算法计算该层的输出能否满足任务的需要,即是否可以早退,这种机制使得可以BERT模型的前几层就退出计算,可以节省计算资源. 然而,上述方法均须对模型进行一定程度的压缩或剪枝,无法充分利用大型预训练语言模型的强大能力. 同时,常规的压缩或剪枝仅能做到个位数级别的压缩,边缘设备的计算和存储需求没有得到足够的缓解. ...
2
... 随着自然语言处理技术的不断发展,自然语言处理方法也已经被大量使用在包括手机、IoT设备在内的移动设备中[21 -22 ] . 边缘端自然语言处理主要的云边协同部署方法如图2 所示. 相比于直接部署在云端的方法,部署在边缘侧的方法可以最大化利用分布在用户端的边缘设备算力,大大降低云端的计算和存储需求[32 -33 ] . 目前的边缘端自然语言处理方法主要聚焦于如何使得大型的预训练语言模型能够在边缘设备中运行. 例如MobileBERT[22 ] 提出降维压缩的BERT[1 ] 模型变种,实现了对BERT模型的4倍以上压缩,使之能够运行在移动设备上. EdgeBERT[33 ] 则提出基于熵的早退算法,具体地说,EdgeBERT在每一层使用基于熵的算法计算该层的输出能否满足任务的需要,即是否可以早退,这种机制使得可以BERT模型的前几层就退出计算,可以节省计算资源. 然而,上述方法均须对模型进行一定程度的压缩或剪枝,无法充分利用大型预训练语言模型的强大能力. 同时,常规的压缩或剪枝仅能做到个位数级别的压缩,边缘设备的计算和存储需求没有得到足够的缓解. ...
... [33 ]则提出基于熵的早退算法,具体地说,EdgeBERT在每一层使用基于熵的算法计算该层的输出能否满足任务的需要,即是否可以早退,这种机制使得可以BERT模型的前几层就退出计算,可以节省计算资源. 然而,上述方法均须对模型进行一定程度的压缩或剪枝,无法充分利用大型预训练语言模型的强大能力. 同时,常规的压缩或剪枝仅能做到个位数级别的压缩,边缘设备的计算和存储需求没有得到足够的缓解. ...
1
... 式中:${\boldsymbol{H}}_t^{1{\text{out}}}$ $ {\boldsymbol{H}}_t^{1{\text{in}}} $ $ {\boldsymbol{Q}}、 $ $ {\boldsymbol{K}}、{\boldsymbol{V}} $ ${{\boldsymbol{W}}^{\boldsymbol{Q}}}$ ${{\boldsymbol{W}}^{\boldsymbol{K}}}$ ${{\boldsymbol{W}}^{\boldsymbol{V}}}$ $ {\boldsymbol{Q}}、{\boldsymbol{K}}、{\boldsymbol{V}} $ ${\text{MHA}}\;({\text{ }})$ ${\text{LN ( )}}$ ${\text{FFN}}\;({\text{ }})$ [34 ] 和前馈神经网络子层. 经过L 层Transformer层之后,最终的模型输出如下: ...
2
... 在4个公开任务数据集上验证所提方法的有效性,任务数据集分别为RTE[35 -38 ] 、CoLA[39 ] 、MRPC[40 ] 、STSB[41 ] . 这4个数据集的详细介绍如下. ...
... 1)RTE (the recognizing textual entailment):RTE数据集来自一系列的年度文本蕴含挑战赛,该数据集的收集者结合了RTE-1[36 ] 、RTE-2[37 ] 、RTE-3[38 ] 和RTE-5[35 ] 的数据. 其中的数据样本根据新闻和维基百科文本构建而成. ...
1
... 1)RTE (the recognizing textual entailment):RTE数据集来自一系列的年度文本蕴含挑战赛,该数据集的收集者结合了RTE-1[36 ] 、RTE-2[37 ] 、RTE-3[38 ] 和RTE-5[35 ] 的数据. 其中的数据样本根据新闻和维基百科文本构建而成. ...
1
... 1)RTE (the recognizing textual entailment):RTE数据集来自一系列的年度文本蕴含挑战赛,该数据集的收集者结合了RTE-1[36 ] 、RTE-2[37 ] 、RTE-3[38 ] 和RTE-5[35 ] 的数据. 其中的数据样本根据新闻和维基百科文本构建而成. ...
2
... 在4个公开任务数据集上验证所提方法的有效性,任务数据集分别为RTE[35 -38 ] 、CoLA[39 ] 、MRPC[40 ] 、STSB[41 ] . 这4个数据集的详细介绍如下. ...
... 1)RTE (the recognizing textual entailment):RTE数据集来自一系列的年度文本蕴含挑战赛,该数据集的收集者结合了RTE-1[36 ] 、RTE-2[37 ] 、RTE-3[38 ] 和RTE-5[35 ] 的数据. 其中的数据样本根据新闻和维基百科文本构建而成. ...
1
... 在4个公开任务数据集上验证所提方法的有效性,任务数据集分别为RTE[35 -38 ] 、CoLA[39 ] 、MRPC[40 ] 、STSB[41 ] . 这4个数据集的详细介绍如下. ...
1
... 在4个公开任务数据集上验证所提方法的有效性,任务数据集分别为RTE[35 -38 ] 、CoLA[39 ] 、MRPC[40 ] 、STSB[41 ] . 这4个数据集的详细介绍如下. ...
1
... 在4个公开任务数据集上验证所提方法的有效性,任务数据集分别为RTE[35 -38 ] 、CoLA[39 ] 、MRPC[40 ] 、STSB[41 ] . 这4个数据集的详细介绍如下. ...
1
... 在实验中使用由Huggingface[42 ] 托管的上述公开数据集的数据副本,由于其中没有提供测试集,从每个任务的训练集中分出10%的样本作为开发集,并将原来的开发集作为测试集使用. 经过数据分割后的数据集详细统计信息如表1 所示. 表中,${T_{\text{r}}}$ $D$ $ {T_{\text{e}}} $
1
... 基于Huggingface维护的Transformer代码库[43 ] 中BERT模型实现作为基准模型中BERT模型微调的代码实现,并使用bert-base模型权重初始化模型. 同时,基于该实现构建本研究所提模型. 对于参数高效的轻量化迁移基准模型,采用AdapterHub[44 ] 中的代码实现. 对于每个基线模型与每个任务,使用不同的随机数种子进行3组实验,并汇报3组实验结果的平均值和标准偏差. 所有实验在Nvidia Geforce 1080TI GPU上完成,使用的Pytorch版本为1.12.0,CUDA版本为12.1. 在超参数方面,使用对应论文中所使用的超参数训练基准模型. 对于所提方法,训练过程中使用的超参数如下:学习率为5×10−4 ,最大样本长度为128,批次大小为32,丢弃率为0.5,周期为10,Adapter层数为1. ...
1
... 基于Huggingface维护的Transformer代码库[43 ] 中BERT模型实现作为基准模型中BERT模型微调的代码实现,并使用bert-base模型权重初始化模型. 同时,基于该实现构建本研究所提模型. 对于参数高效的轻量化迁移基准模型,采用AdapterHub[44 ] 中的代码实现. 对于每个基线模型与每个任务,使用不同的随机数种子进行3组实验,并汇报3组实验结果的平均值和标准偏差. 所有实验在Nvidia Geforce 1080TI GPU上完成,使用的Pytorch版本为1.12.0,CUDA版本为12.1. 在超参数方面,使用对应论文中所使用的超参数训练基准模型. 对于所提方法,训练过程中使用的超参数如下:学习率为5×10−4 ,最大样本长度为128,批次大小为32,丢弃率为0.5,周期为10,Adapter层数为1. ...


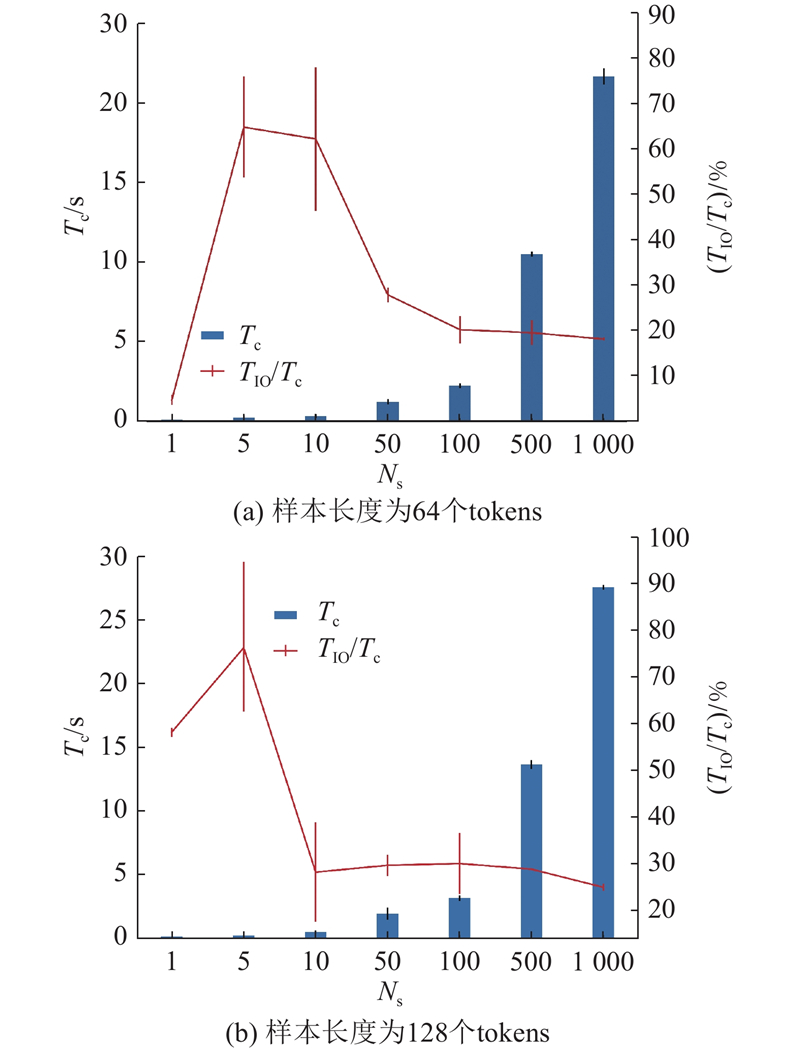

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}