

科技进步与农业生产模式的转变正推动传统采摘方法向更高效、智能的机器人技术过渡. 这种变革提高了生产效率,并显著改善了果农的劳动条件. 在众多作物中,苹果因其广泛的种植区域和巨大的市场需求,成为机械采摘技术的关键应用对象[7]. 但是,复杂的采摘环境使得准确的苹果检测成为一个技术挑战. 多变的光照条件、苹果大小和形态的差异以及树枝树叶的遮挡,或套袋后的形状改变都给这一过程带来了难以克服的困难. 随着科技的进步,尤其是计算机算力的提升,深度学习在目标检测领域得到了广泛应用. 相较于传统的目标检测方法,深度卷积网络能够自动地从训练集中提取多级特征[8]. 目前基于深度学习目标检测算法的研究主要分为2个方向:1) 以Fast R-CNN、Faster R-CNN等为主的two-stage网络,具有高精度的定位能力但存在训练时间较长且误报相对较高的问题;2) 以SSD、YOLO为主的one-stage网络[9-12]. 虽检测速度快,但存在精度低和小物体检测效果差的问题. 针对two-stage网络,Gao等[13]使用改进的Faster R-CNN模型对密叶果树中的苹果进行检测,平均精度为87.9%,单幅图像平均检测时间为0.241 s. Fu等[14]针对野外猕猴桃开发了基于端到端训练网络 ZFNet 实现的 Faster R-CNN 模型对野外猕猴桃进行检测,对相对分离的猕猴桃检测效果较好,平均精度为92.3%. 针对one-stage网络,张恩宇等[15]利用SSD算法和U分量阈值分割技术有效检测了自然环境中的青苹果,拥有较好的检测效果. 赵辉等[16]针对不同成熟度的苹果果实,提出改进YOLOv3网络模型进行识别. 在测试集上,该模型实现了96.3%的mAP和91.8%的F1值,相比原始网络模型,2项指标都增加了2.0个百分比. Lyu等[17]设计了一个轻量化的YOLOv5-CS目标检测模型,通过在YOLOv5网络中加入注意力模块,成功实现了在自然环境下对绿色柑橘98.23%的高识别准确率.
YOLOv7作为YOLO系列的重要分支,通过模型重参数化和跨网格搜索策略提高了推理速度和训练样本均衡性[18];同时提出高效层聚合网络(efficient layer aggregation network, ELAN),在不破坏原始梯度路径的同时提高网络的学习能力;使用带辅助头训练,通过增加训练成本,在提升精度的同时不影响推理的速度. 尽管YOLOv7在检测的精度与速度上都超越以往YOLO系列,但在对复杂情况下的果园苹果进行检测时,仍存在大量漏检、误检情况,且对于体积较小的苹果始终存在召回率偏低的问题.
针对上述问题,本研究提出基于改进YOLOv7的复杂场景下苹果目标检测算法. 通过整合限制对比度自适应直方图均衡化、多尺度混合自适应注意力机制、全维度动态卷积以及Meta-ACON激活函数等方法提高边缘清晰度、特征提取能力和网络收敛速度,以解决小目标检测问题.
1. 基于改进YOLOv7的果园苹果检测
1.1. 改进YOLOv7网络结构
YOLOv7主要由Input、Backbone、Neck、Head等部分组成. Input模块调整输入图像的尺寸以符合网络的需求. Backbone模块通过BConv、E-ELAN和MPConv层的组合提取图像的多尺度特征,其中BConv层用于基础的特征提取,E-ELAN层增强了特征的多样性,MPConv层通过Maxpool层增加了特征的深度和宽度. Neck模块采用PAFPN结构,改善了特征信息的流动,促进了不同尺度特征的融合. Head模块负责调整特征图的通道数,并进行最终的预测. 然而,在特定复杂果园环境中,仍面临着一些独特的挑战. 这些挑战包括但不限于苹果之间的相似性导致的分类困难、复杂背景下的目标识别问题,以及在不均匀光照条件下对小型或远距离目标的检测不足. 这些问题在原始YOLOv7架构中未得到充分解决,可能会导致检测性能的下降.
所提出的苹果检测算法网络框架图如图1所示,主要步骤如下:采集不同场景下果园苹果作为图像数据,调整其分辨率为640×640;利用限制对比度自适应直方图均衡化图像增强算法优化图像质量;利用图像算法对数据集进行增广,以提高模型的泛化性和健全性;在训练过程使用特定的损失函数和优化器训练预处理后的图像及标签,以优化特定任务中模型的性能,得到模型权重文件;利用训练好的模型权重在测试集上验证测试,评估模型的性能,并记录训练过程中的平均准确率、平均召回率之类的关键指标,全面评估模型表现. 该流程旨在精确高效地检测复杂场景下的果园苹果,以保证采摘机器人在定位苹果位置过程中的稳定性.
图 1

1.2. 多尺度混合自适应注意力
在复杂果园环境下,YOLOv7模型面临着苹果形状和特征多样性、目标显著性低以及苹果间及其与树叶间遮挡等挑战. 这些因素导致原模型在苹果的准确检测和特征定位上存在困难. 针对上述挑战,提出多尺度混合自适应注意力机制模块(multi-scale hybrid adaptive attention mechanism, MHAAM),并将其分别添加到Backbone网络中的首尾ELAN模块的后面,用于自适应调整关注点使之更有效地处理苹果与周围环境之间的遮挡问题,增强模型对苹果形状和大小的感知能力. 网络结构如图2所示,该网络充分利用了多尺度自适应注意力结构的建模能力,且对信息查询模块进行降维,在保证计算量的前提下,实现了一种非常有效的长短距离建模,能有效提升模型对复杂环境中苹果特征的识别和定位能力.
图 2

图 2 多尺度混合自适应注意力模块结构
Fig.2 Multi-scale hybrid adaptive attention module structure
多尺度混合自适应注意力结构融合了通道注意力机制[19]和空间注意力[20]. 特征图中不同通道信息重要性各异,使用通道注意力机制对通道信息加权学习,可以有效抑制无用信息传播,为此本研究提出多层次通道自适应注意力机制(multi-level channel adaptive attention, MCAA). 首先,通过不同尺度的膨胀卷积获取多样化感受野特征,且对通道信息进行三等分的降维,旨在降低通道特征维度数量,将信息编码到更紧凑的表示中;同时使用1×1卷积使一个通道维度的特征完全坍塌作为信息查询模块使用. 然后通过重塑将每个膨胀卷积后的特征图和与之对应的查询模块保持相同的维度以便做后续的矩阵乘法. 为了计算每个像素位置的权重,对查询模块使用Softmax函数增强注意力的范围. 将这些权重与先前获得的降维特征图进行各自矩阵乘法并与最后的相乘结果做拼接操作,使查询模块得到的信息与不同尺度的上下文中的每个特征位置进行有选择性的权重分配. 对于最终通道特征图
式中:
传统的卷积层通常只能捕获局部的空间信息,而空间注意力机制允许模型在整个特征图中选择性地关注某些区域,从而捕获长距离的依赖关系. 为此本研究提出多尺度空间自适应注意力机制(multi-scale spatial adaptive attention, MSAA). 空间注意力分支与通道注意力分支类似,同样使用不同大小的膨胀卷积核提取多尺度感受野,并通过1×1卷积核构建查询模块,不同的是,这次特征提取的过程对输入特征做4等分的划分,且对查询模块进行全局平均池化操作,得到沿空间方向的全局空间查询特征图
式中:
1.3. 全维度动态卷积
针对传统YOLOv7模型在复杂的果园环境中,苹果间以及苹果与树叶之间遮挡导致关键特征信息的丢失的问题,引入ODConv模块替换网络Backbone中的ELAN模块中的普通卷积,旨在通过精细化的注意力机制优化特征选择过程,进而细化苹果的局部细粒度特征.
图 3

ODConv对输入特征图
式中:
1.4. 小目标检测改进
果园环境多变,如土壤、天气和灌溉水质等因素,会影响苹果生长,导致果实形态小且颜色不均,特别在逆光或有光影的条件下,幼果与枝叶难以区分. 此外,从远处观察时幼果占比较小,容易出现互相遮挡的现象.
原YOLOv7模型骨干网络包含5次下采样过程,得到P1至P5共5层特征表达. YOLOv7为了在Neck部分实现多尺度特征的聚合路径融合,从Backbone中提取P3、P4、P5与Neck部分进行特征拼接融合,最后在Head部分上进行目标坐标的预测. 对于坐标预测回归部分,默认采用K-Means算法聚类数据集生成的锚框做先验,并与Head部分的预测坐标计算损失进而对锚框做调整.
1.5. Meta-ACON激活函数
在YOLOv7网络中,一般使用SiLU激活函数对CBS模块进行激活,传统的SiLU激活函数具有无上界有下界、平滑、非单调的特征,对于输入较大或较小的情况下,导数易趋近于零从而导致梯度消失的问题.
为了解决这一问题,提出在YOLOv7网络中引入Meta-ACON激活函数. 与传统的激活函数ReLU、Sigmoid、Tanh相比,Meta-ACON[23]在输入为正数或负数时均能够保持合适的梯度以避免常见的梯度小时或梯度爆炸的问题,且能根据输入数据的分布自适应地调节其参数,使得在不同的数据分布下都够取得良好的效果. 具体表达式如下:
式中:
针对上述问题,将YOLOv7网络中CBS模块的SiLU激活函数替换为Meta-ACON激活函数,具体网络结构如图4所示. 图中,k为算子大小,P为padding卷积填充取值. 替换后对于复杂遮挡场景下的苹果能较准确地识别和召回.
图 4

1.6. 基于限制对比度自适应直方图均衡化的图像增强
果园环境复杂,枝叶繁茂、光照不均、苹果与枝叶颜色相近、机器人相机像素低等内外因素易造成图像模糊偏暗和苹果轮廓边缘信息缺失情况,严重影响检测网络的预测精度,因此,采用限制对比度自适应直方图均衡化算法优化检测网络输入图像质量,以提高算法的识别精度.
限制对比度自适应直方图均衡化(contrast limited adaptive histogram equalization, CLAHE)方法[24]是基于自适应直方图均衡化的改进. 通过独立计算图像每个小区块的直方图并重新分配亮度,能有效提升局部对比度并揭示更多细节. 不同于传统直方图均衡化可能导致的对比度过度放大和噪声问题,CLAHE能够在保证图像对比度得以提高的同时,还确保物体轮廓更为清晰,从而为数据集标注及后续的物体识别工作打下坚实基础. 限制对比度自适应直方图均衡化算法的流程大致如下.
1) 将待增强的图像进行若干子块划分,并保证子块之间大小相等且互不相叠,
2) 计算图像中每个子块的直方图
3) 根据剪切阈值剪辑每个子块的直方图,规则如下:
式中:
4) 重复步骤1)~3),直到每个子块分配完毕.
5) 直方图均衡化并用双线性插值根据各子块中心像素点的灰度值重构图像的灰度值.
图像增强前、后对比如图5所示. 经过限制对比度自适应直方图均衡化图像增强算法,图像的亮度与对比度得到了提升. 在极端黑暗与光照不均环境下,苹果、树叶、树枝等轮廓信息相对增强前更为明显.
图 5

2. 模型训练及结果分析
2.1. 实验环境配置
实验在配置了GeForce RTX
对基于YOLOv7的网络模型进行优化,再将其与机器人摄像头相结合,形成果园苹果检测系统的核心部分. 该检测系统的用户界面如图6所示.
图 6

2.2. 数据集构建
训练神经网络模型离不开高质量的数据集. 本实验使用的果园苹果数据集经过人工采集,其中图像的像素均超过
表 1 数据集拍摄信息
Tab.1
| 影响因素 | 图像类别 | Ns |
| 幼果 | 顺光 | 317 |
| 逆光 | 233 | |
| 成熟期 | 顺光 | 675 |
| 逆光 | 775 | |
| 树枝遮挡 | 顺光 | 472 |
| 逆光 | 491 | |
| 远距离 | — | 872 |
| 光照不均 | — | 517 |
| 光照低 | — | 372 |
图 7

图 8

2.3. 模型训练参数设置
采用Adam[25]优化器优化训练损失,设置动量因子为0.937,以增强优化过程的稳定性和效率. 通过实验确定模型的训练特性,前200轮采用0.001的初始学习率以迅速逼近初步合理解,随后100轮将学习率调整为
2.4. 实验结果及分析
为了验证本研究算法的效果,选用Faster R-CNN、SSD、YOLOv5、YOLOv7、改进YOLOv7模型进行对比分析.
图 9
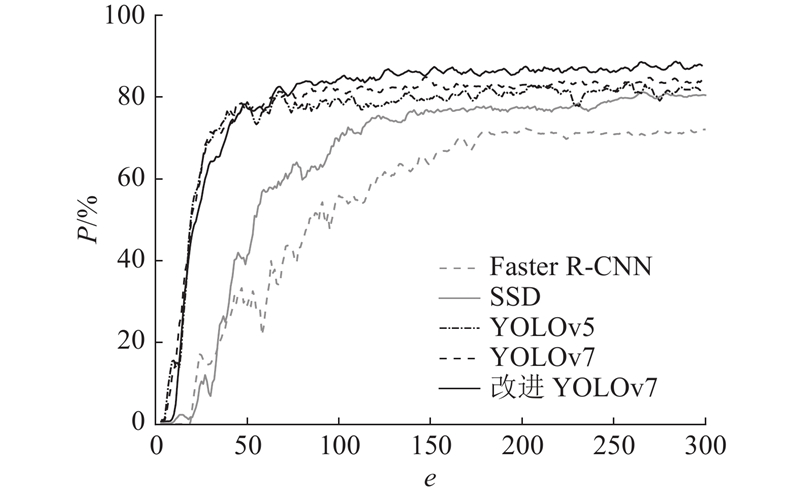
图 10

在平均召回率方面,Faster R-CNN和SSD训练较于其他模型波动明显,YOLOv5和YOLOv7在正样本检测过程中的平均召回率约为84.0%. 在Backbone部分引入了多尺度混合残差注意力结构并采用四检测头的方式显著提升了改进后模型的小目标检测性能. 因此,与其他YOLO模型相比,改进后的模型在正样本检测中的平均召回率有所提升,最终达到87.0%. 综合分析,改进后的YOLOv7算法在苹果目标检测任务中的性能有显著提升.
如表2所示为不同模型结果的指标对比. 表中,WS为权重文件大小,t为识别时间. 可以看出,改进的YOLOv7模型在苹果检测任务上的表现超过了Faster R-CNN、SSD、YOLOv5和原始YOLOv7. 此外,改进的YOLOv7在权重文件大小和识别时间上也表现出一定的优势. 结果充分说明改进后的YOLOv7模型在苹果检测任务上的优越性能.
表 2 不同模型的指标对比
Tab.2
| 模型 | P/% | R/% | WS/MB | t/s |
| Faster R-CNN (voc_resnet.pth) | 70.2 | 73.3 | 108.0 | 0.154 |
| SSD(voc_vgg.pth) | 78.1 | 80.5 | 90.6 | 0.079 |
| YOLOv5(yolov5l.pt) | 81.2 | 83.4 | 89.3 | 0.045 |
| YOLOv7(yolov7.pt) | 83.2 | 85.7 | 73.8 | 0.040 |
| 改进YOLOv7 | 85.7 | 87.0 | 80.6 | 0.047 |
2.5. 消融实验结果
为了更好地验证改进算法相对原有算法的优化,设计了4种网络进行消融实验,均使用相同的果园苹果数据集、批次、训练周期. 如表3所示为消融实验结果. 表中,第1行为原始YOLOv7模型结果,√ 表示在YOLOv7模型基础上加入对应模块. 可以看出,YOLOv7模型单独加入MHAAM模块后检测准确率提升了1.4个百分点,效果最为明显. 结合所有改进策略的YOLOv7模型达到了85.7%的准确率、87.0%的召回率,并且检测时间为0.047 s,相当于每秒处理21帧. 模型的检测速率大于机器人摄像头的拍摄速率20帧/s,满足苹果采摘机器人的检测需求.
表 3 改进模型消融实验结果
Tab.3
| CLAHE | MHAAM | ODConv | 四检测头 | 激活函数 | P/% | R/% | t/s |
| — | — | — | — | — | 83.2 | 85.7 | 0.040 |
| √ | — | — | — | — | 84.0 | 85.9 | 0.041 |
| — | √ | — | — | — | 84.6 | 86.2 | 0.044 |
| — | — | √ | — | — | 84.4 | 86.1 | 0.042 |
| — | — | — | √ | — | 84.3 | 86.0 | 0.042 |
| — | — | — | — | √ | 84.1 | 85.8 | 0.040 |
| √ | √ | √ | √ | √ | 85.7 | 87.0 | 0.047 |
为了验证本算法的优点,将改进的YOLOv7部署至检测平台后,对果园苹果验证集数据进行识别,挑选具有代表性的5组检测结果进行对比验证,如图11所示. 其中,在纵向第1组图像分析中,Faster R-CNN和SSD展现了对单一苹果的重复检测问题,Faster R-CNN、SSD和YOLOv5模型出现大量的树叶被误检成苹果的问题,预测框置信度相对较低. YOLOv7模型对于上述问题有所改善但依然存在漏检. 加入MHAAM注意力机制的改进YOLOv7模型,能在复杂的背景中对检测目标特征产生更敏锐的反应,对于树枝遮挡以及幼果与背景颜色相近造成干扰的问题的检测效果显著,基本没有出现漏检、误检的情况. 从纵向第2组图像识别结果可以看出,Faster R-CNN、SSD和YOLOv5模型在识别树枝遮挡的单一苹果时存在多次检测的问题,且因地上的落叶与苹果颜色相近而对其产生误检,而原始的YOLOv7和改进后的YOLOv7模型均无误检的情况发生,值得注意的是,改进后的YOLOv7模型通过引入ODConv、Meta-ACON手段技术,相比于原始的YOLOv7模型,目标框的回归精度和苹果预测的置信度都有显著提高,平均置信度相较于YOLOv5和YOLOv7模型分别有14.5、12.2个百分点的明显提升. 在第3组图像识别结果中,尽管在极端光照低的场景下所有模型都能识别出较为明显的中型苹果,但对于体积较小且与背光相似的小苹果均发生漏检现象,SSD模型还将背景误检成苹果,改进后的YOLOv7模型通过引入4检测头的方法使模型对于小目标特征的捕捉更为敏感,且限制对比度自适应直方图均衡化方法使得模型对于光照不均、对比度较差的场景能够进行更好的图像补偿,实现对苹果的精准定位. 对于最后2组光照不均与远距离逆光的场景,其他模型对于远处的苹果小目标均存在严重的漏检问题,而改进后的YOLOv7不但能精准识别远端的苹果,还能一一定位落地被遮掩的苹果,在小目标检测任务中准确率与召回率明显优于其他模型. 上述对比实验证明了改进模型的优越性与可行性,其基本满足复杂场景下苹果检测的需求.
图 11

2.6. 注意力机制性能分析
为了全面评估MHAAM在YOLOv7模型中的性能,将MHAAM与其他几种流行的注意力机制进行消融实验分析. 实验的目的是分析这些不同注意力机制在苹果幼果目标检测任务中的性能差异. 对比模型为在Backbone的首尾ELAN之后加入相应注意力机制的YOLOv7+SE、YOLOv7+CA、YOLOv7+CBAM,单独在Backbone首部和尾部集成MHAAM的YOLOv7+MHAAM1和YOLOv7+MHAAM2,以及首尾均加入MHAAM的YOLOv7+MHAAM. 如表4所示展示了7种配置的性能指标.
表 4 注意力机制在YOLOv7中的应用消融实验结果
Tab.4
| 模型 | P/% | R/% | WS/MB | t/s |
| YOLOv7 | 83.2 | 85.7 | 73.8 | 0.040 |
| YOLOv7+SE | 83.3 | 85.7 | 75.1 | 0.043 |
| YOLOv7+CA | 83.1 | 85.6 | 74.9 | 0.042 |
| YOLOv7+CBAM | 83.5 | 85.8 | 75.2 | 0.043 |
| YOLOv7+MHAAM1 | 83.9 | 86.0 | 75.0 | 0.042 |
| YOLOv7+MHAAM2 | 83.6 | 85.8 | 74.7 | 0.041 |
| YOLOv7+MHAAM | 84.6 | 86.2 | 76.3 | 0.044 |
相较于其他模型,引入MHAAM的YOLOv7模型显示出了更优异的性能表现. YOLOv7+MHAAM1和YOLOv7+MHAAM2分别代表在Backbone的首部和尾部的ELAN单独加入MHAAM,而YOLOv7+MHAAM则表示在整个Backbone中全加入MHAAM. 结果显示,完全集成MHAAM的YOLOv7模型在平均准确度和召回率上均有显著提高,达到了84.6%和86.2%,虽然导致一定的参数量增加和检测时间延长,但这种增加是为了获得更优的检测性能而做出的合理权衡. 这一结果表明,MHAAM能有效提高YOLOv7在复杂果园环境下关键特征的提取,实现有效的长短距离建模,尤其是在提高准确性和召回率方面有较大优势.
2.7. 引入ODConv分析
为了评估ODConv动态卷积模块在YOLOv7网络中的有效性,在YOLOv7网络的不同层中引入ODConv模块进行消融实验,结果如表5所示. 表中,ODConv_neck表示仅将ODConv应用在Neck中;ODConv_backbone1、2、3、4则表示分别在Backbone中的第4、第17、第25、第37层中引入ODConv模块;ODConv_backbone表示仅将ODConv应用在Backbone中;ODConv_all表示ODConv同时应用在Backbone与Neck中. 可以看出,同时在Backbone与Neck中引入ODConv虽然能够保证一定的平均准确度与召回率的提升,但同时会带来参数量与检测时间的增加,对苹果检测这种实时性高的任务来说,不是最优的选择. 仅在Backbone中引入ODConv,能在维持检测精度的同时,有效平衡性能与实时性,更符合实际应用需求.
表 5 ODConv在YOLOv7中的应用消融实验结果
Tab.5
| 模型 | P/% | R/% | WS/MB | t/s |
| YOLOv7 | 83.2 | 85.7 | 73.8 | 0.040 |
| ODConv_neck | 83.6 | 85.9 | 74.7 | 0.042 |
| ODConv_backbone1 | 83.4 | 85.9 | 74.4 | 0.041 |
| ODConv_backbone2 | 83.3 | 85.8 | 74.2 | 0.041 |
| ODConv_backbone3 | 83.3 | 85.7 | 74.1 | 0.040 |
| ODConv_backbone4 | 83.2 | 85.7 | 74.1 | 0.040 |
| ODConv_backbone | 84.4 | 86.1 | 74.9 | 0.042 |
| ODConv_all | 84.3 | 86.2 | 75.6 | 0.047 |
2.8. 检测热力图分析
目标检测的视觉解释性对于理解模型决策过程至关重要. 热力图提供了一种直观的方式来揭示模型在图像中重点关注的区域,从而表明了这些区域对于检测结果的贡献.
Grad-CAM[26]是一种依赖于梯度的深度网络可视化策略. 它通过捕捉最后一个卷积层的梯度信息来估算各个通道的影响权重. 然后,将这些权重与特征图结合,形成热力图并叠加到原图上,这样热力图中的每个像素可以反映其在模型分类决策中的相对重要性. 在本次研究中采用 Grad-CAM 技术对YOLOv7与改进YOLOv7模型进行检测热力图分析. 结果如图12所示. 在热力图表示中,如图 12(a) 、 (d) 所示,列中区域的由浅到深色表示对检测物的肯定值从低到高. 当这些区域远离真实苹果区域,或者虽位于真实苹果区域但热力值相对较低时,容易发生漏检问题. 倘若热力图对于图像中其他干扰物存在较高的热力值表示,则容易如图12(b)、(c)、(e)列所示存在误检的问题. 对比YOLOv7与改进YOLOv7模型的热力图表示可知,对于复杂场景,改进YOLOv7模型在处理弱语义目标时能够捕获更为丰富的特征,表现出更好的鲁棒性和适应性.
图 12

3. 结 论
(1)采用限制对比度自适应直方图均衡化方法增强果园中苹果图像的对比度,以提高图像的清晰度,并减轻阴影和遮挡的影响;设计MHAAM注意力机制,以提高模型对显著性较弱目标的识别能力;引入全维度动态卷积替换ELAN模块中的普通卷积细化苹果的局部细粒度特征;使用4检测头的方式解决小型苹果检测难的问题;采用Meta-ACON激活函数对网络进行激活,增加网络语义特征信息提取能力,进一步提高苹果检测精度. 通过消融实验验证了改进措施对提升模型性能的具体贡献. 利用Grad-CAM技术生成了目标检测的热力图,使得研究者可以更直观地了解模型关注的区域,从而更深入地理解模型的工作原理.
(2)通过自建的果园数据集进行实验验证,结果表明,改进后的YOLOv7模型在苹果检测上精度和召回率,分别达到了85.7%和87.0%,相比原始的YOLOv7模型分别提高了2.5和 1.3个百分点.
综上所述,改进YOLOv7模型在复杂环境下对苹果的检测上展现了卓越的性能,为苹果生长监测和机械摘果研究提供了重要的技术支持,但在极端光照条件和处理重叠果实的能力方面还有待提高. 未来的研究将优化模型的光照适应性,引入先进图像预处理技术提高鲁棒性. 同时,开发新算法改善对重叠果实的分辨率并提高运行效率,以满足实时应用需求. 这些改进将使模型更适应复杂果园环境,能增强其实际应用性能.
参考文献
2020年度中国苹果产业发展报告: 精简版
[J].
2020 China apple industry development report: simplified version
[J].
2021年全国各省(区, 市)主要水果产量分布及变化
[J].
Distribution and change of major fruit production in provinces (autonomous regions and municipalities) of China in 2021
[J].
我国苹果生产的现状, 问题与发展对策
[J].
Current status, problems and development strategies of apple production in my country
[J].
我国果园机械化生产现状与发展策略
[J].
Current situation and development strategy of mechanized production of orchards in China
[J].
苹果化学疏花疏果技术研究进展
[J].
Research progress on chemical flower and fruit thinning technology of apples
[J].
振动式高酸苹果采摘机的设计与试验
[J].
Design and test of vibrating high-acid apple picking machine
[J].
Experimental and simulation analysis of optimum picking patterns for robotic apple harvesting
[J].DOI:10.1016/j.scienta.2019.108937 [本文引用: 1]
Scale-aware fast R-CNN for pedestrian detection
[J].
Faster R-CNN: towards real-time object detection with region proposal networks
[J].
Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN
[J].DOI:10.1016/j.compag.2020.105634 [本文引用: 1]
Kiwifruit detection in field images using Faster R-CNN with ZFNet
[J].DOI:10.1016/j.ifacol.2018.08.059 [本文引用: 1]
基于SSD算法的自然条件下青苹果识别
[J].DOI:10.3969/j.issn.2095-2783.2020.03.004 [本文引用: 1]
Green apple recognition under natural conditions based on SSD algorithm
[J].DOI:10.3969/j.issn.2095-2783.2020.03.004 [本文引用: 1]
基于改进YOLOv3的果园复杂环境下苹果果实识别
[J].
Apple fruit recognition in complex environment of orchard based on improved YOLOv3
[J].
Green citrus detection and counting in orchards based on YOLOv5-CS and AI edge system
[J].DOI:10.3390/s22020576 [本文引用: 1]
Deep learning based efficient ship detection from drone-captured images for maritime surveillance
[J].DOI:10.1016/j.oceaneng.2023.115440 [本文引用: 1]
复杂环境下煤矿井下胶带运输异物在线检测算法优化与分析
[J].
Optimization and analysis of online detection algorithm for foreign objects in underground coal mine tape transportation under complex environment
[J].
Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}