

为了提高基于手机信令数据的出行链识别精度,本文通过数据同步采集实验获取手机信令数据和对应的真实出行信息,在停留点识别中引入比兴趣点(POI)数据维度更高的兴趣面(area of interest, AOI)和基站位置数据,提出可变参数滑动窗口的停留点识别方法. 构建出行链识别框架,该框架通过贝叶斯优化方法来优化模型,以获得最佳参数. 这一研究有效地提升了出行链的识别精度,为进一步分析交通需求提供了准确的基础数据,支撑城市尺度的出行行为建模和交通规划.
1. 出行链的定义
定义手机信令数据条件下的出行相关概念如下. 如图1所示,轨迹点表示每个手机信令的地理坐标采样点,一个轨迹点对应一条信令数据. 停留点指的是用户在一定空间范围内停留超过一定时间的地点,它是由一个或多个相邻轨迹点聚集形成的,D和T分别为停留点判别的空间和时间阈值. 停留主要包括工作、购物、用餐等“活动”过程.
图 1
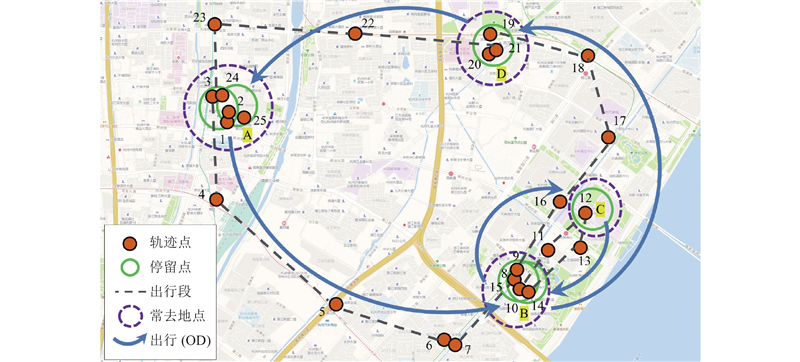
常去地点由停留点聚类形成,表示用户经常去的位置. 参数e为停留点聚类的邻域半径参数.
出行段指的是2个连续停留点之间所有出行轨迹点组成的路径,所有未被划归到停留点的轨迹点均被划归到出行段中. 参数g为出行段内连续轨迹点间允许的最大时间间隔,用于识别短暂的等待和换乘行为,若相邻2个轨迹点的时间间隔超过这个阈值参数,则出行段将会在此处切分. 一般认为每个出行段只对应一种出行方式.
出行(OD)指的是为了某种目的,从一个停留点到另一个停留点的移动,一次“出行”可能由一个或多个不同方式的“出行段”组成. 由于针对的是城市交通,在某些封闭或半封闭区域(如大学校园、工业园区、公园景点等)的内部道路上的移动,不算作一次出行. 对行程时间小于最短持续时间阈值u的出行进行删除处理.
由此,将出行链定义为从居住地出发,经过一系列单一目的的出行和停留,返回居住地的链路集合.
2. 出行链识别方法
算法框架如图2所示. 1)通过数据同步采集实验获取手机信令数据及对应的出行GPS数据,要求出行者对出行轨迹进行标注,获取真实的出行标签. 2)手机信令数据预处理,对重复数据、漂移数据进行清洗. 3)可变参数滑动窗口的停留点识别方法,其中引入了比POI数据维度更高的AOI信息和环境变量,如每个轨迹点的周围基站分布密度、均匀度和采样频率等特征,这些变量决定停留点识别中的时空阈值. 4)判别出行段,基于DBSCAN方法对停留点进行聚类,形成出行OD及出行链. 在模型训练阶段,将基于采集的真实出行数据与识别结果进行对比,利用贝叶斯优化方法对模型参数进行优化,优化目标包含起讫点识别误差、多识别率、准确率等多个性能度量指标.
图 2
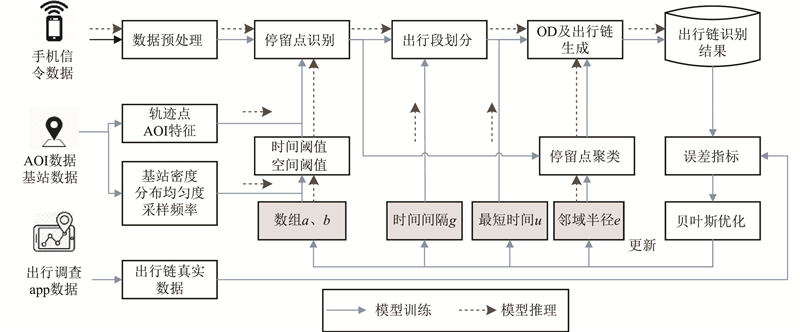
图 2 出行链识别算法框架的示意图
Fig.2 Schematic diagram of trip chain identification algorithm framework
2.1. 数据预处理
2.2. 基于可变参数滑动窗口的停留点识别
停留点是指从轨迹数据中识别出行者在较小空间区域内停留了较长时间的轨迹点集合. 可变参数滑动窗口的停留点识别方法的基本思想如下:由每个轨迹点的环境变量(包括周围基站分布和采样频率)计算获得对应的时空阈值,使得时空阈值能够动态调整,以此可变的时空阈值参数来设置滑动窗口. 通过滑动窗口选取在时间和空间上都临近的轨迹点进行聚集,利用各轨迹点所在的AOI辅助判断,实现个体停留点的识别.
停留点识别算法的具体流程如下. 1)对轨迹点根据记录时间进行排序,计算每个轨迹点的环境变量. 2)根据环境变量,计算每点对应的空间阈值D和时间阈值T(可变参数). 3)逐个检查连续2个轨迹点之间的时间间隔,如果大于最大停留时间阈值
图 3

2.2.1. 环境变量影响下的阈值
时间阈值和空间阈值是判断出行者是否停留的2个关键参数. 考虑这些阈值的设定依据和背后影响机理,而非简单地依赖于固定值或研究者的经验. 一般而言,出行者在停留或者静止时不会因基站切换产生手机信令或者产生的信令位置相同或临近,当出行者移动时,由于手机连接的基站发生切换,产生相应的手机信令记录. 切换动作的发生与2个因素密切相关:一是基站的分布,二是手机用户的移动速度. 每个基站本身的覆盖范围影响时空阈值. 在基站密度较高,分布较均匀的情况下,单个基站的服务半径和空间阈值较小;当用户的移动速度较大时,信令采样频率会增加,此时用户更有可能处于出行状态,设置较小的时间阈值. 相反条件时同理.
提出定性假设,即识别停留点时的T、D与轨迹点及所在环境的一些特征有关,具体如下.
1)基站密度为与每个轨迹点距离小于400 m的基站数量
2)基站方向分布均匀度为与每个轨迹点距离小于400 m的基站相对分布方向的方差
基于Zar等[27-28]提出的关于角度及方向数据方差的计算方法,将与每个轨迹点距离小于400 m的所有基站按其相对于轨迹点的方位,分布到以轨迹点为圆心的单位圆上,如图4(a)所示. 每个基站相对轨迹点的方向可以视作单位向量
图 4

图 4 基站分布均匀度计算的示意图
Fig.4 Schematic diagram for calculating uniformity of base station distribution
平均向量
使用
3)采样频率为每个轨迹点前15 min和后15 min的采样数量(
为了使时空阈值能够随环境变量的变化而动态调整,给出线性关系的假设:
式中:特征数组[
2.2.2. AOI特性
AOI(area of interest)即兴趣面,比POI(point of interest)多一项区域边界信息,主要用于在地图中表达区域状的地理实体,如一个居民小区、一所学校或一个景区等. 通过百度地图API方式共获取到杭州市AOI数据一万多条,分布示意图如图5所示.
图 5

图 5 杭州市主城区部分AOI的分布示意图
Fig.5 Distribution of partial AOI in main urban area of Hangzhou City
轨迹点的AOI信息主要用于帮助判断是否形成新的停留点,根据1节的出行链定义可知,若只在同一个AOI区域内移动,则不被视为一次新的出行,处在停留过程中. 根据2.2节的内容和图3可知,
2.3. 停留点聚类
停留点是一个或多个连续地被识别为停留状态的轨迹点的质心. 对于用户多次停留的同一地点,由于每次停留时连接基站不同,不同的停留点坐标间略有偏差,具体如图1所示. 为了解决该问题,使用DBSCAN方法对识别的停留点进行空间聚类,形成“常去地点”,即将空间上临近的停留点按不同用户聚类形成“簇”. 在该算法中,设置邻域半径参数e,并将聚类的最小停留点数量设置为1,这样多次停留的有偏移的停留点会聚合为一个,单次停留点会保留.
2.4. 出行段划分
在停留点识别后,所有未被识别为停留状态的轨迹点均被划归为出行状态,由2个连续停留点之间所有出行轨迹点组成的路径将被划分为出行段. 为了切分出连续的出行轨迹,需要识别短暂的等待和换乘行为. 若某2个连续出行轨迹点的时间间隔大于g,则原先的出行段将在此处中断,形成2个新的出行段.
图 6

2.5. 出行OD及出行链校准
2个停留点之间的所有出行段可以合并为1次出行(OD),它可能包含一个或多个出行段. 出行的起止时间分别为该出行的第1个出行段的起点时间和最后1个出行段的终点时间,出行的O点和D点坐标分别为两端停留点的坐标. 少部分出行两端或其中一端没有停留点的,O点和D点坐标分别为第1个出行段起点和最后1个出行段终点的坐标.
在部分往返的真实出行中,因在目的地停留时间较短而未识别出停留点,较典型的为“去车站接送人”场景,导致识别的出行的起、终点位置相同. 根据出行定义,此类出行应该被划分为2次出行而不是1次. 针对这种情况,对O、D点位置相同的出行进行拆分. 具体如下:筛选出O点和D点在同一常去地点且中间有至少2个出行段的出行,找到每个出行中D点离O点最远的出行段. 由此将1次出行拆分为2次出行:第1次为原O点到离O点最远的出行段的终点,第2次为离原O点最远的出行段的下一个出行段的起点到原D点.
对于持续时间较短的出行,设置出行时间阈值u,删掉持续时间小于阈值的出行OD. 将原本属于该出行的轨迹点划归到前一个停留点中,该过程相当于间接处理掉了一些噪声数据.
图 7

图 7 信令数据经过模型处理后获得的出行链信息示意图
Fig.7 Trip chain information obtained after model processing of signaling data
表 1 某用户某天的出行链信息
Tab.1
| 时间 | 状态 | 坐标 |
| 00:00:00—08:33:00 | 停留 | |
| 08:33:00—09:12:19 | 出行 | |
| 09:12:19—22:14:36 | 停留 | |
| 22:14:36—22:52:51 | 出行 | |
| 22:52:51—23:59:58 | 停留 |
2.6. 模型参数的贝叶斯优化
在获得真实出行轨迹和标注信息的前提下,可以进行模型参数的优化. 确定8个性能度量指标作为优化目标,总体上可以分为以下2个方面. 1)识别率指标,用于评估真实出行是否被识别或识别错误. 2)误差指标,用于评估识别结果与真实出行在时间空间上的一致性.
识别率各项指标的计算公式如下.
1) 查准率
2)查全率
3)正确率
4)多识别率
式中:
使用模型识别结果与真实标注在时间上产生交集且一一对应的出行对,即
在优化参数上,模型中共有13个参数需要确定. 具体来说,有10个系数参数([
当构建损失函数时,考虑各项指标的归一化,即将各项指标的变化范围控制在同一尺度下. 将多目标优化的目标函数即损失函数Y定义为
式中:
损失函数对各参数的导数是未知的,因此无法使用梯度下降的方法求最优解. 贝叶斯优化(Bayesian optimization)适用于解决计算成本昂贵的黑盒优化问题,利用贝叶斯定理来指导搜索以找到目标函数的最小值或最大值,在每次迭代的时候,利用之前观测到的历史信息(先验知识)进行下一次优化. 采用贝叶斯优化中的TPE(tree-structured Parzen estimator)方法[29-30]求解损失函数的最小值,得到最优参数. TPE是非参数化的概率密度估计方法,用于在高维空间中进行贝叶斯优化,优势在于能够自适应地选择新的候选参数组合,更新核密度估计器来引导搜索,可以快速收敛到具有良好性能的参数组合,提高贝叶斯优化的效率.
由于贝叶斯优化的结果有一定的随机性,每次优化的结果可能都略有不同,不一定能达到全局最优,需要进行多轮优化,选择其中较好的结果. 将此优化得到的最优参数输入,可得最终的出行链识别模型.
3. 数据采集与参数优化结果
3.1. 手机信令数据及时空特性
使用的“手机信令数据”指的是用户设备在与基站进行通信时所产生的日志数据,存储于运营商通信系统数据库,如表2所示,每行记录包含用户编号(user_id)、与基站通信时的时刻(time)、与手机通信的基站的经纬度坐标(longitude、latitude)等基本数据字段. 同一用户id的不同记录集合即该用户的轨迹点集,通过从数据集中提取以个体为单位的轨迹点序列,形成了轨迹信息.
表 2 手机信令数据的样例记录
Tab.2
| 用户编号 | 时间戳 | 经度 | 纬度 |
| 000142****fb | 11/9 12:55:11 | ||
| 000142****fb | 11/9 12:55:36 | ||
| 000142****fb | 11/9 12:56:58 | ||
| 000142****fb | 11/9 12:59:22 | ||
| 000142****fb | 11/9 13:07:13 |
使用的手机信令数据采集时间为2022年10月31日至11月27日,共获取到31位用户的共7.3 万条手机信令位置数据,平均每人每天产生85 条信令数据. 如图8所示为某用户某次出行的手机信令轨迹和同时收集到的GPS轨迹.
图 8

图 8 某次出行的手机信令和GPS数据对比
Fig.8 Comparison of mobile signaling and GPS data for certain trip
对所有手机信令数据的采样间隔时间
对比分析手机信令数据与出行者的实际出行状态及GPS数据,可以得到手机信令数据相对于GPS数据的特点如下.
1)位置不确定性. 手机信令数据通常使用通信基站位置作为用户位置坐标,由于基站的空间分布差异较大,定位误差
图 9
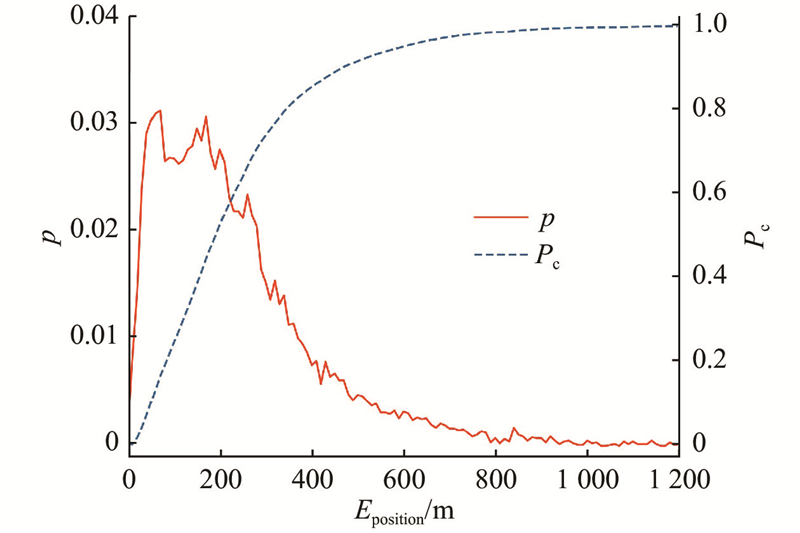
图 9 手机信令数据的定位误差分布
Fig.9 Distribution of position error in mobile signaling data
2)采样间隔的不均匀性. 手机信令数据是由移动通信网络在为手机用户提供通信服务时产生的,包括打电话、上网及移动过程中的基站切换等. 用户在出行中产生连续的基站切换,此时采样间隔较短,速度越快采样频率越高. 在静止驻留时,可能在较长时间内不产生基站切换,采样频率较低. 手机信令数据的采样频率f与实际移动速度v的关系如图10所示.
图 10
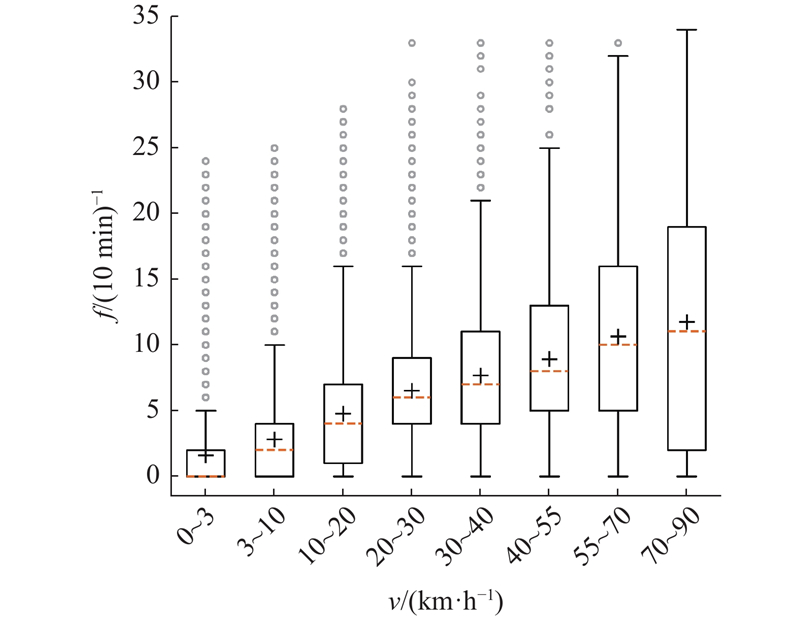
图 10 手机信令采样频率与实际移动速度的关系
Fig.10 Relationship between sampling frequency of mobile phone signaling and actual movement speed
3.2. 出行标注与GPS轨迹采集
为了更加精准地对提出的方法进行参数优化和结果验证,开发了一款名为Check·Track的APP,用于出行调查的GPS轨迹收集和出行标注,以此配合从运营商处获取的对应手机信令数据. APP的页面如图11所示,用户点击“开始出行”即可开始记录GPS轨迹,轨迹数据的采样频率为5 s/次. 在当天的GPS数据记录完成后,用户需要手动在APP中划分出行,标注每次出行的起止时刻、起终点类型、出行目的和出行方式等信息.
图 11
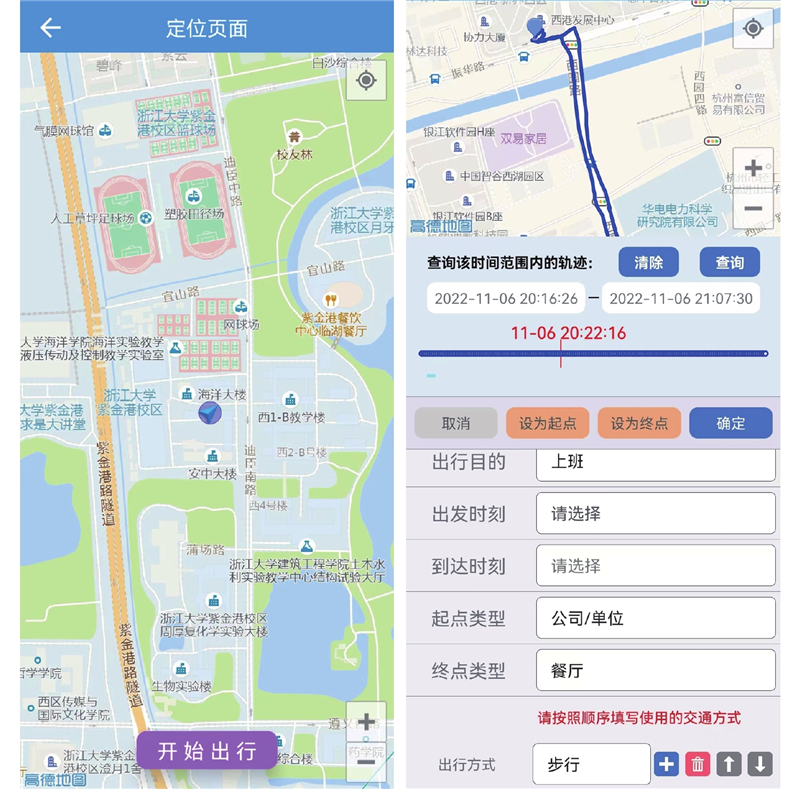
图 11 出行轨迹APP的定位与标注页面
Fig.11 Location and annotation page of travel trajectory app
2022年11月,组织37名志愿者使用该APP进行2~4周不等的连续出行调查和轨迹记录,累计472 (人×天)的出行数据. 从运营商处获取这些志愿者对应的手机信令数据. 将调查得到的出行OD标注数据,与GPS、信令数据进行核对,筛选出29名用户的737 次准确出行OD作为真实标签,累计276 (人×天)的出行数据. 这些数据对应31 994 条手机信令数据. 真实的出行标注数据如表3所示.
表 3 某用户的出行OD标注数据示例
Tab.3
| 用户id | 开始时间 | 结束时间 | 起点经度 | 起点纬度 | 终点经度 | 终点纬度 |
| 1985******* | 2022-11-23 8:30:12 | 2022-11-23 9:09:53 | ||||
| 1985******* | 2022-11-23 21:43:00 | 2022-11-23 21:48:00 | ||||
| 1985******* | 2022-11-23 23:44:37 | 2022-11-24 0:04:43 | ||||
| 1985******* | 2022-11-24 8:30:08 | 2022-11-24 9:09:28 | ||||
| 1985******* | 2022-11-24 22:03:34 | 2022-11-24 22:59:32 |
3.3. 损失函数与参数优化结果
将收集的出行OD标注作为真实标签,采用贝叶斯优化方法对模型进行参数优化. 在该过程中,采用网格搜索(grid search)方法对贝叶斯优化的超参数进行选取,得到最优参数组合为初始观测值60个,计算集合函数考虑样本数80个. 经过多次优化实验,损失函数停止减小时的迭代次数为600~
表 4 优化获得的损失函数及各项参数值
Tab.4
| 优化结果 | 系数 | 系数参数值 | 阈值参数值 | Y | |||||||
| i = 0 | i = 1 | i = 2 | i = 3 | i = 4 | g | e | u | ||||
| 取值范围 | ai | (400, 650) | (−0.7, 0.7) | (−39, 39) | (−4.2, 4.2) | (−4.2, 4.2) | (8, 15) | (150, 300) | (100, 240) | — | |
| bi | (25, 35) | (−0.04, 0.04) | (−2.3, 2.3) | (−0.25, 0.25) | (−0.25, 0.25) | ||||||
| 优化结果1 | ai | 617 | −0.42 | −13 | −3.1 | 3.3 | 14.0 | 252 | 196 | −0.006 | |
| bi | 32.5 | −0.017 | 1.4 | −0.19 | −0.16 | ||||||
| 优化结果2 | ai | 622 | −0.37 | −36 | −1.5 | 2.5 | 12.8 | 155 | 137 | −0.006 | |
| bi | 33.0 | −0.002 | −1.0 | −0.22 | −0.18 | ||||||
| 优化结果3 | ai | 632 | −0.45 | −38 | −0.7 | −2.1 | 12.7 | 257 | 187 | −0.006 | |
| bi | 32.7 | −0.032 | −1.1 | −0.16 | −0.21 | ||||||
| 优化结果4 | ai | 628 | −0.36 | −34 | −1.5 | 0.2 | 12.7 | 270 | 181 | −0.005 | |
| bi | 33.2 | −0.004 | −0.9 | −0.21 | −0.07 | ||||||
| 优化结果5 | ai | 620 | −0.63 | −24 | −2.0 | 2.4 | 12.6 | 202 | 199 | −0.007 | |
| bi | 32.1 | −0.031 | −0.2 | −0.15 | −0.24 | ||||||
在各参数的取值范围内进行随机取值,运行本文模型500 次,统计各项性能指标组合的变化,以75%分位数与25%分位数的差作为变化幅度. 分别赋予3个指标组合25%、25%、50%的权重,计算得到对应的归一化系数,如表5所示. 将多目标优化的目标函数即损失函数Y定义为
表 5 各项性能度量指标组合的变化、权重及系数
Tab.5
| 统计项 | M − A | ||
| 25%分位数 | 564.6 | 13.533 | − |
| 75%分位数 | 603.0 | 14.326 | − |
| 75%分位数−25%分位数 | 38.4 | 0.793 | |
| 计算权重 | 25% | 25% | 50% |
| 归一化系数 | 1/ | 1/32 | 1 |
经过5轮优化,每次得到的Y和各项参数如表4所示. 对比各个优化结果的系数参数和损失函数,可以确定停留点识别时的D和T分别与部分环境变量具有相关性. 具体来讲,D与轨迹点周围的基站密度和基站方向分布均匀度负相关,T与采样频率负相关. 经过比较,优化结果5得到的损失函数最小,因此选择优化结果5的参数值作为最优参数,将最优参数输入到模型中,可得最终模型.
4. 模型验证与结果分析
由于出行链是由识别的出行OD连接而成的,出行OD的识别指标能够反映出行链的识别效果,以识别的出行OD为基本比较单元构建指标,可以间接地反映出停留点、出行段及出行链的整体识别质量. 评价指标为2.6节所述的8个性能度量指标,对比方法分别是Marra’s Heuristic算法[16]、Trackintel方法[11]及本文框架下的固定时空阈值法. Marra’s Heuristic算法是启发式停留点识别算法,在本研究中增加了形成出行的步骤. 由于本研究的算法存在优化模型参数的过程,类似于机器学习中的“训练”,为了综合比较,将性能对比分为最优性能和泛化性能两部分,如表6所示. 最优性能指使用100%的数据优化模型参数,直接比较优化后的性能. 泛化性能指用60%的数据优化模型参数,使用剩余40%的数据运行并比较性能.
表 6 出行链识别算法的性能比较
Tab.6
| 性能 | 算法 | 误差指标 | 识别率指标 | |||||||
| P | R | A | M | |||||||
| 最优性能 | Marra’s Heuristic | 517 | 597 | 8.6 | 8.2 | 0.595 | 0.628 | 0.822 | 0.237 | |
| Trackintel | 275 | 282 | 7.2 | 7.1 | 0.681 | 0.769 | 0.829 | 0.304 | ||
| 本文框架固定阈值法 | 267 | 317 | 7.1 | 6.9 | 0.774 | 0.803 | 0.872 | 0.168 | ||
| 本文方法 | 267 | 259 | 7.0 | 6.0 | 0.830 | 0.826 | 0.875 | 0.125 | ||
| 泛化性能 | Marra’s Heuristic | 492 | 548 | 9.3 | 7.3 | 0.598 | 0.636 | 0.815 | 0.255 | |
| Trackintel | 244 | 234 | 6.8 | 7.3 | 0.619 | 0.752 | 0.818 | 0.397 | ||
| 本文框架固定阈值法 | 261 | 292 | 6.8 | 6.9 | 0.781 | 0.792 | 0.841 | 0.164 | ||
| 本文方法 | 251 | 248 | 6.8 | 5.9 | 0.818 | 0.804 | 0.856 | 0.136 | ||
从表6可以看出,本文算法在除了泛化性能中的起点和终点平均距离误差(
为了验证模型的稳定性,采用五折交叉验证方法估计模型的泛化能力. 将276 (人×天)的出行OD和对应的信令数据随机划分为5个相同大小的子集. 依次选择其中1份作为测试集,其余4份用于训练,重复5次,每次实验中都计算各项评价指标,分别计算训练和测试的平均结果. 如表7所示,当使用不同的样本进行优化时,部分参数几乎不发生变化,如
表 7 出行链识别算法稳定性实验(五折交叉验证)
Tab.7
| 数据集 | 部分参数 | 误差指标 | 识别率指标 | |||||||||||||
| a0 | a1 | b0 | b3 | g | e | P | R | A | M | |||||||
| 训练1 | 619 | −0.45 | 30.8 | −0.24 | 13.3 | 262 | 272 | 259 | 6.9 | 5.7 | 0.819 | 0.814 | 0.872 | 0.125 | ||
| 测试1 | 259 | 329 | 7.8 | 7.1 | 0.808 | 0.803 | 0.868 | 0.125 | ||||||||
| 训练2 | 611 | −0.38 | 31.9 | −0.14 | 14.3 | 215 | 265 | 251 | 7.0 | 6.4 | 0.830 | 0.826 | 0.866 | 0.131 | ||
| 测试2 | 287 | 315 | 8.1 | 5.8 | 0.826 | 0.809 | 0.894 | 0.099 | ||||||||
| 训练3 | 622 | −0.6 | 32.9 | −0.14 | 12.9 | 198 | 266 | 257 | 7.4 | 6.1 | 0.837 | 0.830 | 0.879 | 0.118 | ||
| 测试3 | 258 | 245 | 6.4 | 6.1 | 0.760 | 0.816 | 0.882 | 0.191 | ||||||||
| 训练4 | 632 | −0.43 | 33.2 | −0.08 | 14.2 | 158 | 273 | 255 | 7.0 | 6.5 | 0.809 | 0.828 | 0.886 | 0.142 | ||
| 测试4 | 270 | 238 | 7.1 | 5.5 | 0.827 | 0.777 | 0.825 | 0.120 | ||||||||
| 训练5 | 623 | −0.5 | 31.9 | −0.16 | 12.6 | 225 | 266 | 255 | 6.9 | 6.2 | 0.815 | 0.813 | 0.877 | 0.126 | ||
| 测试5 | 261 | 254 | 7.5 | 7.2 | 0.815 | 0.838 | 0.866 | 0.152 | ||||||||
| 平均训练 | — | — | — | — | — | — | 268.4 | 255.4 | 7.04 | 6.18 | 0.822 | 0.822 | 0.876 | 0.128 | ||
| 平均测试 | 267 | 276.2 | 7.38 | 6.34 | 0.807 | 0.809 | 0.867 | 0.137 | ||||||||
5. 结 论
(1)针对手机信令数据时空特性的分析表明,手机信令数据的定位存在时空不确定性,即位置不确定性和采样间隔不均匀性,且采样频率与实际移动速度相关. 采样间隔时间和间隔距离的中位数分别为81 s和326 m. 将手机信令数据的经纬度坐标与真实GPS坐标对比可知,手机信令数据的平均定位误差为240 m.
(2)本研究的贡献主要在于提出的基于手机信令数据的出行链识别框架,在传统时空阈值识别停留点方法的基础上,考虑轨迹点所在AOI和周围基站密度、均匀度等环境变量对时空阈值参数的影响,提出可变参数滑动窗口的出行停留点识别方法. 采用贝叶斯多目标优化得到出行链模型的最佳参数,实现时空阈值的动态调整,提升模型的识别精度和泛化性能. 基于开发的出行轨迹记录APP采集的数据与从运营商处获取的手机信令数据对比实验结果表明,本文方法在泛化性能和最优性能两方面均能够有效地降低模型的误差,提升识别率. 识别率比其他最新的算法有3%~26%的改进,尤其多识别率显著降低. 五折交叉验证结果证明了算法的良好泛化性能.
(3)提出的环境变量对停留点时空阈值的影响基于简单的线性关系假设,函数关系的形式需要进一步的探究. 此外,可以直接使用本文中的参数标定结果,也可以遵循该方法进行更大规模的出行轨迹和标签收集实验,便于应用到城市规模的手机信令数据分析上,刻画城市尺度的交通出行需求. 在未来的研究中,可以基于识别的出行链进一步判断居住和工作地点,计算城市规模的通勤OD矩阵和路径,分析城市出行的瓶颈,研究降低通勤时耗的策略. 另外,可以基于历史轨迹推演人口整体的迁移态势,如预测交通拥堵及群体性聚集事件,便于实施智能管控.
参考文献
Practical approach to model trip chaining
[J].
居民出行链、出行方式与出发时间联合选择的交叉巢式Logit模型
[J].
Cross-nested logit model for the joint choice of residential location, travel mode, and departure time
[J].
Accurate map matching method for mobile phone signaling data under spatio-temporal uncertainty
[J].
A novel trip coverage index for transit accessibility assessment using mobile phone data
[J].
Estimating commuting matrix and error mitigation: a complementary use of aggregate travel survey, location-based big data and discrete choice models
[J].DOI:10.1016/j.tbs.2021.04.012 [本文引用: 1]
Mobile phone data in urban commuting: a network community detection-based framework to unveil the spatial structure of commuting demand
[J].
Inferring fine-grained transport modes from mobile phone cellular signaling data
[J].
基于手机信令数据的旅游客流特征分析
[J].
Analysis of tourist flow characteristics based on mobile phone signaling data
[J].
Trip-chain-based travel-mode-shares-driven framework using cellular signaling data and web-based mapping service data
[J].DOI:10.1177/0361198119834006 [本文引用: 1]
TRANSIT: fine-grained human mobility trajectory inference at scale with mobile network signaling data
[J].DOI:10.1016/j.trc.2021.103257 [本文引用: 1]
Trackintel: an open-source Python library for human mobility analysis
[J].
Activity location recognition from mobile phone data using improved HAC and Bi-LSTM
[J].DOI:10.1049/itr2.12211 [本文引用: 2]
基于手机信令数据的出行端点识别效果评估
[J].
Evaluation of activity location recognition using cellular signaling data
[J].
A spatial econometric model for travel flow analysis and real-world applications with massive mobile phone data
[J].DOI:10.1016/j.trc.2017.12.002 [本文引用: 2]
基于滑动窗口的手机定位数据个体停留区域识别算法
[J].DOI:10.12082/dqxxkx.2018.180087 [本文引用: 1]
Detecting individual stay areas from mobile phone location data based on moving windows
[J].DOI:10.12082/dqxxkx.2018.180087 [本文引用: 1]
Developing a passive GPS tracking system to study long-term travel behavior
[J].DOI:10.1016/j.trc.2019.05.006 [本文引用: 2]
Improved F-DBSCAN for trip end identification using mobile phone data in combination with base station density
[J].
Modeling real-time human mobility based on mobile phone and transportation data fusion
[J].DOI:10.1016/j.trc.2018.09.016 [本文引用: 1]
A data-driven approach for origin–destination matrix construction from cellular network signalling data: a case study of Lyon region (France)
[J].DOI:10.1007/s11116-020-10108-w [本文引用: 1]
地理空间数据结合手机信令等多源数据刻画城市居民出行特征
[J].
Geospatial data combined with multi-source data such as mobile phone signaling data to depict the travel characteristics of city residents
[J].
Analysis of human mobility patterns from GPS trajectories and contextual information
[J].DOI:10.1080/13658816.2015.1100731 [本文引用: 1]
Detecting outliers in cell phone data: correcting trajectories to improve traffic modeling
[J].
An adaptive staying point recognition algorithm based on spatiotemporal characteristics using cellular signaling data
[J].DOI:10.1109/TITS.2021.3094636 [本文引用: 2]
Inferring dynamic origin-destination flows by transport mode using mobile phone data
[J].DOI:10.1016/j.trc.2019.02.013 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}