[1]
MA J, GAO W, WONG K F. Detect rumors in microblog posts using propagation structure via kernel learning [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics . Vancouver: Association for Computational Linguistics, 2017: 708–717.
[本文引用: 1]
[2]
MA J, GAO W, WEI Z, et al. Detect rumors using time series of social context information on microblogging websites [C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management . Melbourne: ACM, 2015: 1751–1754.
[本文引用: 1]
[3]
YANG F, LIU Y, YU X, et al. Automatic detection of rumor on sina weibo [C]// Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics . Beijing: ACM, 2012: 1–7.
[4]
ZHAO Z, RESNICK P, MEI Q. Enquiring minds: early detection of rumors in social media from enquiry posts [C]// Proceedings of the 24th International Conference on World Wide Web . Florence: [s. n.], 2015: 1395–1405.
[本文引用: 1]
[5]
CASTILLO C, MENDOZA M, POBLETE B. Information credibility on Twitter [C]// Proceedings of the 20th International Conference on World Wide Web . Hyderabad: ACM, 2011: 675–684.
[本文引用: 4]
[6]
REIS J C S, CORREIA A, MURAI F, et al Supervised learning for fake news detection
[J]. IEEE Intelligent Systems , 2019 , 34 (2 ): 76 - 81
DOI:10.1109/MIS.2019.2899143
[本文引用: 1]
[7]
YANG R, ZHANG J, GAO X, et al. Simple and effective text matching with richer alignment features [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics . Florence: Association for Computational Linguistics, 2019: 4699–4709.
[本文引用: 1]
[8]
KWON S, CHA M, JUNG K, et al. Prominent features of rumor propagation in online social media [C]// 2013 IEEE 13th International Conference on Data Mining . Dallas: IEEE, 2013: 1103–1108.
[9]
LIU X, NOURBAKHSH A, LI Q, et al. Real-time rumor debunking on Twitter [C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management . Melbourne: ACM, 2015: 1867–1870.
[10]
YU F, LIU Q, WU S, et al. A convolutional approach for misinformation identification [C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence . Melbourne: AAAI Press, 2017: 3901–3907.
[本文引用: 1]
[11]
MA J, GAO W, MITRA P, et al. Detecting rumors from microblogs with recurrent neural networks [C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence . New York: AAAI Press, 2016: 3818–3824.
[本文引用: 4]
[12]
WU K, YANG S, ZHU K Q. False rumors detection on Sina Weibo by propagation structures [C]// 2015 IEEE 31st International Conference on Data Engineering . Seoul: IEEE, 2015: 651–662.
[本文引用: 1]
[13]
VEDOVA M L D, TACCHINI E, MORET S, et al. Automatic online fake news detection combining content and social signals [C]// 2018 22nd Conference of Open Innovations Association (FRUCT) . Jyvaskyla: IEEE, 2018: 272–279.
[本文引用: 1]
[14]
MA J, GAO W, WONG K F. Rumor detection on Twitter with tree-structured recursive neural networks [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics . Melbourne: Association for Computational Linguistics, 2018: 1980–1989.
[本文引用: 2]
[15]
KUMAR S, CARLEY K. Tree LSTMs with convolution units to predict stance and rumor veracity in social media conversations [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics . Florence: Association for Computational Linguistics, 2019: 5047–5058.
[本文引用: 1]
[16]
LAO A, SHI C, YANG Y. Rumor detection with field of linear and non-linear propagation [C]// Proceedings of the Web Conference 2021 . Ljubljana: ACM, 2021: 3178–3187.
[本文引用: 1]
[18]
BIAN T, XIAO X, XU T, et al. Rumor detection on social media with bi-directional graph convolutional networks [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S. l.]: AAAI Press, 2020, 34(1): 549–556.
[本文引用: 3]
[19]
HUANG Q, YU J, WU J, et al. Heterogeneous graph attention networks for early detection of rumors on Twitter [C]// 2020 International Joint Conference on Neural Networks . Glasgow: IEEE, 2020.
[本文引用: 1]
[20]
杨延杰, 王莉, 王宇航 融合源信息和门控图神经网络的谣言检测研究
[J]. 计算机研究与发展 , 2021 , 58 (7 ): 1412 - 1424
YANG Yanjie, WANG Li, WANG Yuhang Rumor detection based on source information and gating graph neural network
[J]. Journal of Computer Research and Development , 2021 , 58 (7 ): 1412 - 1424
[21]
HE Z, LI C, ZHOU F, et al. Rumor detection on social media with event augmentations [C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval . [S.l.]: ACM, 2021: 2020–2024.
[本文引用: 2]
[22]
LIN H, MA J, CHEN L, et al. Detect rumors in microblog posts for low-resource domains via adversarial contrastive learning [C]// Findings of the Association for Computational Linguistics: NAACL 2022 . Seattle: Association for Computational Linguistics, 2022: 2543–2556.
[本文引用: 2]
[23]
WEI L, HU D, ZHOU W, et al. Uncertainty-aware propagation structure reconstruction for fake news detection [C]// Proceedings of the 29th International Conference on Computational Linguistics . Gyeongju: International Committee on Computation Linguistics, 2022: 2759–2768.
[本文引用: 2]
[24]
KHOO L M S, CHIEU H L, QIAN Z, et al. Interpretable rumor detection in microblogs by attending to user interactions [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S. l.]: AAAI Press, 2020: 8783–8790.
[本文引用: 2]
[25]
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [EB/OL]. (2017–02–22)[2023–07–19]. https://arxiv.org/pdf/1609.02907.
[本文引用: 1]
[26]
NIKOLENTZOS G, TIXIER A, VAZIRGIANNIS M. Message passing attention networks for document understanding [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S. l.]: AAAI Press, 2020: 8544–8551.
[本文引用: 1]
[27]
WEI L, HU D, ZHOU W, et al. Towards propagation uncertainty: edge-enhanced bayesian graph convolutional networks for rumor detection [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing . [S.l.]: Association for Computational Linguistics, 2021: 3845–3854.
[本文引用: 2]
[28]
LI S, ZHAO Z, HU R, et al. Analogical reasoning on Chinese morphological and semantic relations [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics . Melbourne: Association for Computational Linguistics, 2018: 138–143.
[本文引用: 1]
[29]
HUANG Q, ZHOU C, WU J, et al. Deep structure learning for rumor detection on Twitter [C]// 2019 International Joint Conference on Neural Networks . Budapest: IEEE, 2019: 1–8.
[本文引用: 1]
[30]
KINGMA D P, BA J. Adam: a method for stochastic optimization [EB/OL]. (2017–01–30)[2023–03–29]. https://arxiv.org/pdf/1412.6980.
[本文引用: 1]
[31]
SONG C, YANG C, CHEN H, et al CED: credible early detection of social media rumors
[J]. IEEE Transactions on Knowledge and Data Engineering , 2021 , 33 (8 ): 3035 - 3047
DOI:10.1109/TKDE.2019.2961675
[本文引用: 1]
1
... 早期学者训练支持向量机(support vector machine, SVM)、决策树(decision tree, DT)[1 –5 ] 、随机森林(random forest, RF)[6 ] 等传统机器学习方法进行谣言识别[5 ,7 –11 ] . Castillo等[5 ] 使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
1
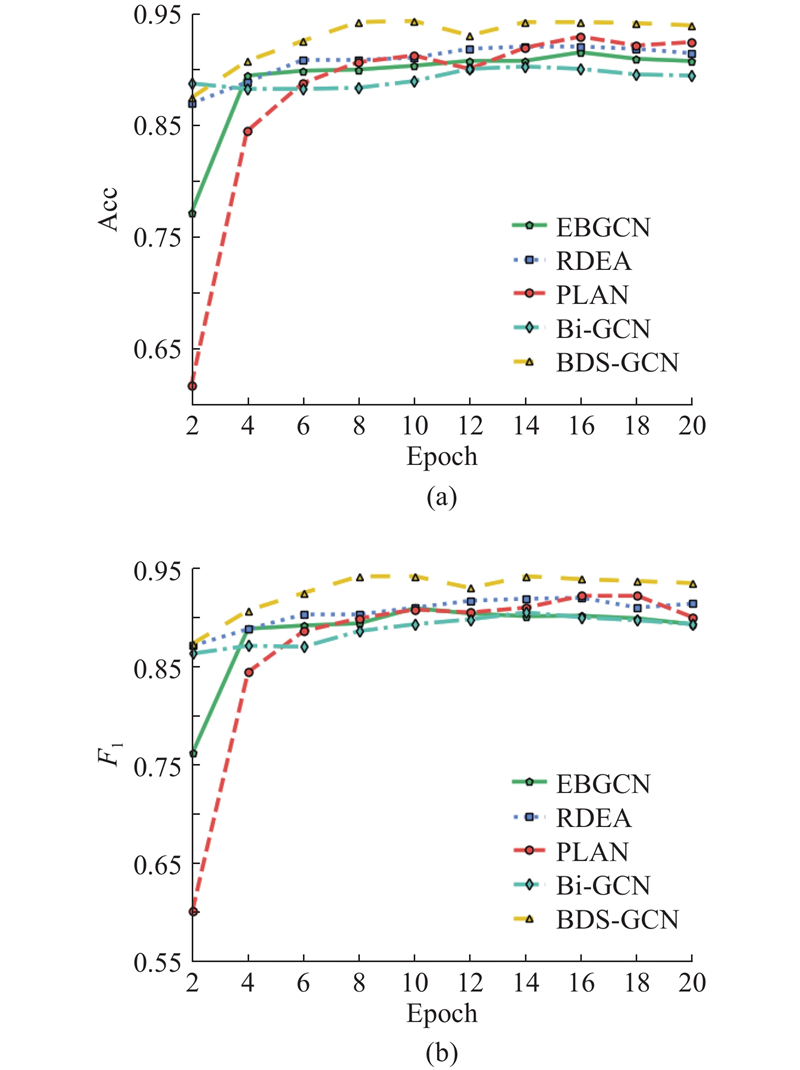
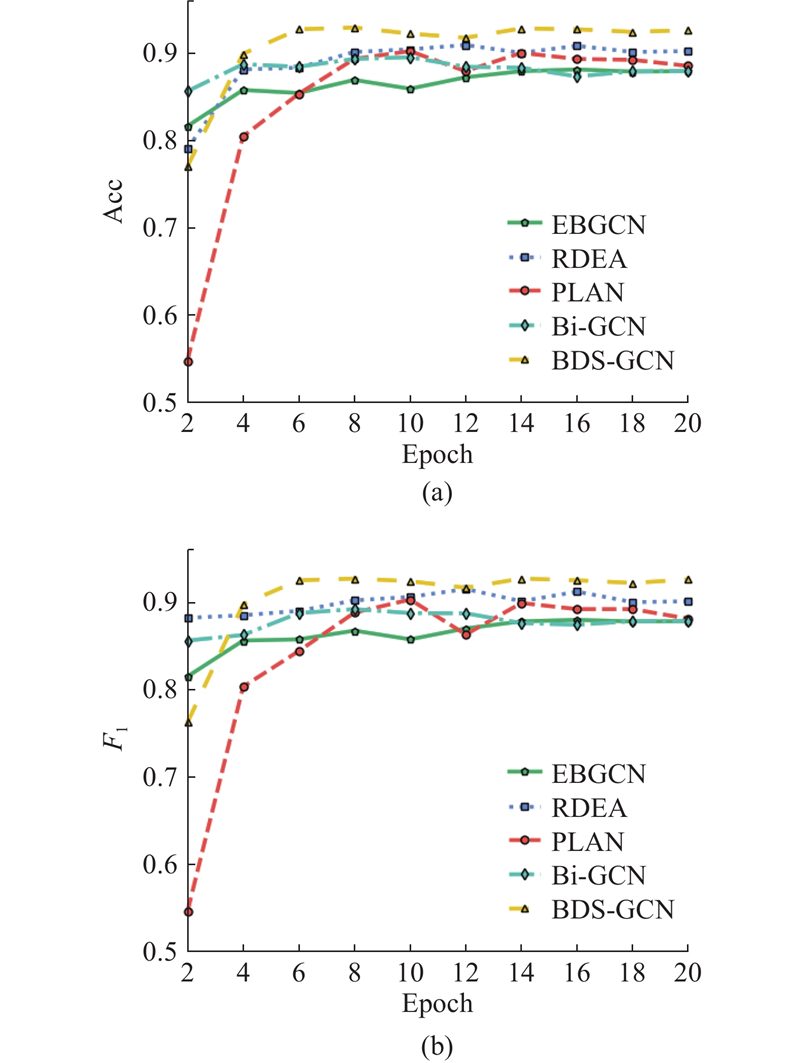
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
1
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
4
... 早期学者训练支持向量机(support vector machine, SVM)、决策树(decision tree, DT)[1 –5 ] 、随机森林(random forest, RF)[6 ] 等传统机器学习方法进行谣言识别[5 ,7 –11 ] . Castillo等[5 ] 使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
... [5 ,7 –11 ]. Castillo等[5 ] 使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
... [5 ]使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
Supervised learning for fake news detection
1
2019
... 早期学者训练支持向量机(support vector machine, SVM)、决策树(decision tree, DT)[1 –5 ] 、随机森林(random forest, RF)[6 ] 等传统机器学习方法进行谣言识别[5 ,7 –11 ] . Castillo等[5 ] 使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
1
... 早期学者训练支持向量机(support vector machine, SVM)、决策树(decision tree, DT)[1 –5 ] 、随机森林(random forest, RF)[6 ] 等传统机器学习方法进行谣言识别[5 ,7 –11 ] . Castillo等[5 ] 使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
1
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
4
... 早期学者训练支持向量机(support vector machine, SVM)、决策树(decision tree, DT)[1 –5 ] 、随机森林(random forest, RF)[6 ] 等传统机器学习方法进行谣言识别[5 ,7 –11 ] . Castillo等[5 ] 使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
... 软件环境为Python3.7+Pytorch1.9.0+cuda10.0,CPU为Intel Xeon Gold5218,内存为64G,显卡为NVIDIA GeForce RTX 2080Ti. 为了验证所提方法的有效性,在2个真实公开的数据集Weibo2016[11 ] 和CED[31 ] 上进行实验. 这2个数据集均来源于新浪微博管理中心平台发布的不实信息统计,数据集的参数如表1 所示. ...
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
1
... 早期学者训练支持向量机(support vector machine, SVM)、决策树(decision tree, DT)[1 –5 ] 、随机森林(random forest, RF)[6 ] 等传统机器学习方法进行谣言识别[5 ,7 –11 ] . Castillo等[5 ] 使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
1
... 早期学者训练支持向量机(support vector machine, SVM)、决策树(decision tree, DT)[1 –5 ] 、随机森林(random forest, RF)[6 ] 等传统机器学习方法进行谣言识别[5 ,7 –11 ] . Castillo等[5 ] 使用情感词典提取文本中的情感词,构建了包括平均情感分数在内的15个指标;Wu等[12 ] 利用特征工程提取基于文本、用户和传播的有效特征应用于多个机器学习方法,取得了较好效果. Vedova等[13 ] 考虑与谣言信息进行交互的用户,充分利用文本和用户环境特征进行谣言检测. 以上方法的性能过多依赖人为构建的特征工程,该过程费时费力并对专业知识要求较高,难以获得谣言事件的特征表示,因此模型精度还有很大的提升空间. ...
2
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
1
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
1
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
The spread of true and false news online
2
2018
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
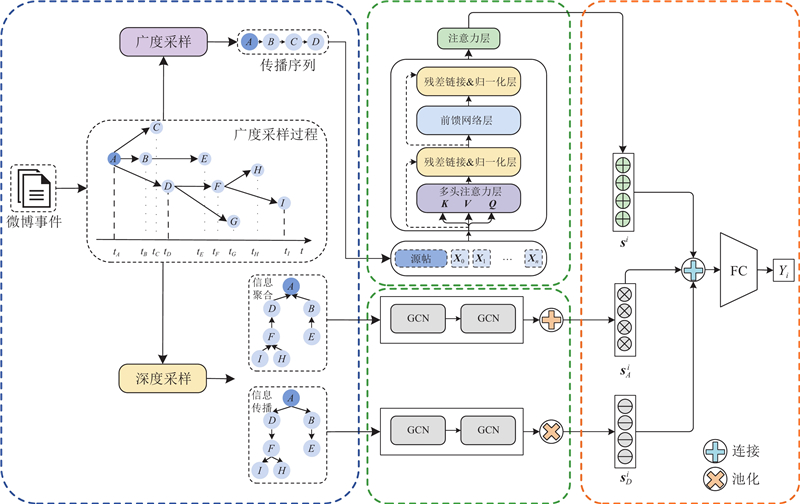
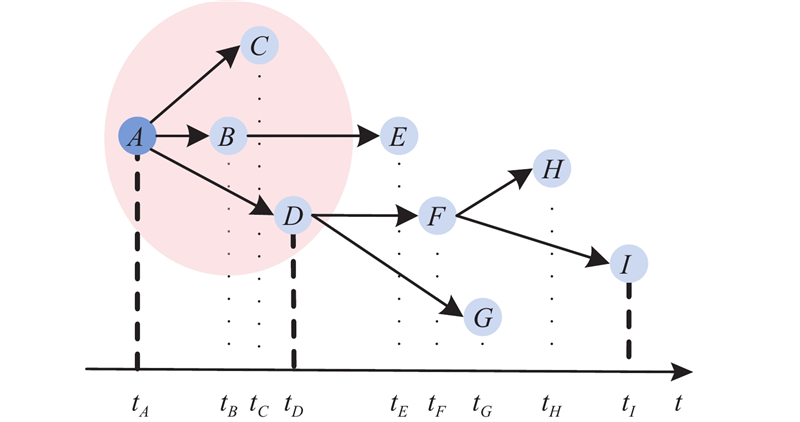
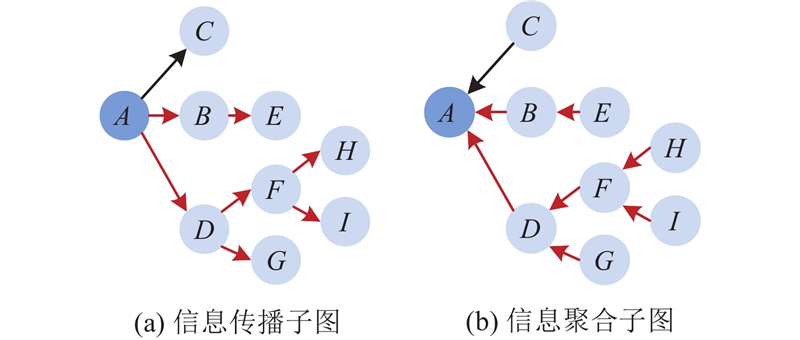
... 针对图4 ,若给定D =50,此时依据所提深度采样策略得到的路径集合为$ {L}_{i,D}=\{\left\{A\to D\to F\to H\right\}, \left\{A\to D\to F\to I\right\}\} $ $ {G}_{D}^{i} $ . 事件传播图相连节点间除了包含由评论回复操作构成的显式传播关系外,还包含由信息聚合操作构成的隐式传播关系[17 ] . 在事件传播图$ {G}_{i} $ $ {G}_{D}^{i} $ $ {G}_{D}^{i} $ $ {G}_{A}^{i}= < {V}_{i,A},{E}_{i,A} > $ $ {V}_{i,A}={V}_{i,{D}},{E}_{ij}^{A}=\left\{{e}_{k+1,k}^{i}\right\} $ $ {L}_{i,A}=\{\{H\to F\to D \to A\}, \{I\to F\to D\to A\}\} $ . 如图5 所示,信息传播子图和信息聚合子图区别在于它们获得特征信息的方向不同. 具体而言,信息传播子图中每个节点的表示由自身节点及其被转发(评论)节点对应的语义内容决定;在信息聚合子图中,每个节点的表示除了与自身语义内容相关外,还与转发(评论)该节点的节点语义内容相关. 综合利用信息传播关系和信息聚合关系能够有效融合当前节点的上下层节点对该节点的影响,提高该节点表示的准确性. ...
3
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
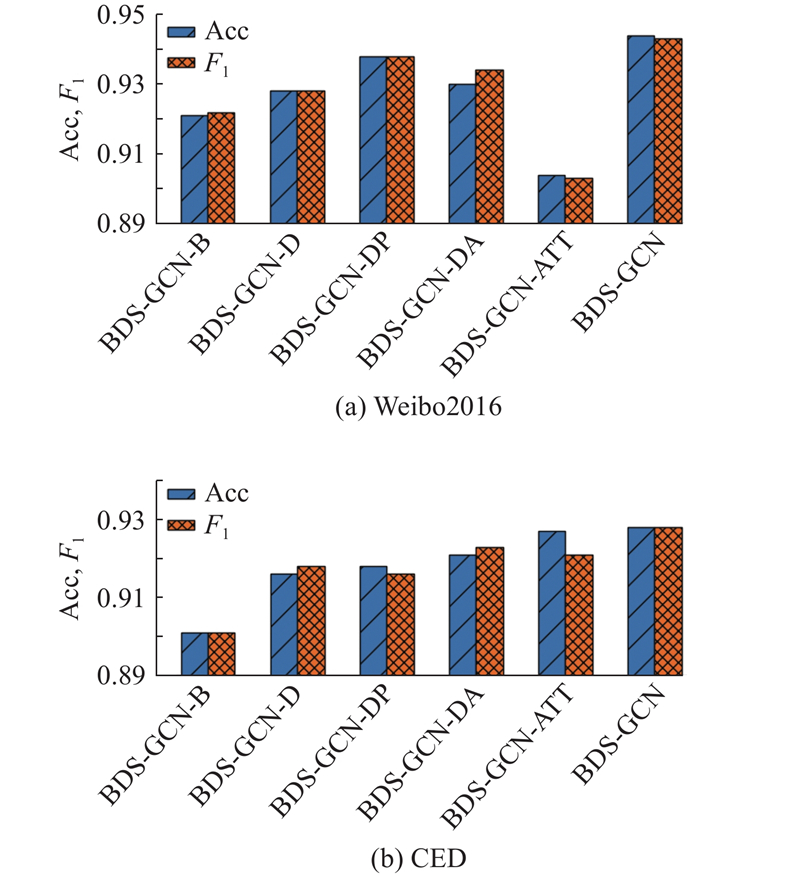
... 为了降低数据量并减少过拟合风险,Bi-GCN[18 ] 、RDEA[21 ] 、EBGCN[27 ] 等方法均采用随机删除边及节点信息的采样方式,此类采样方法存在丢失关键数据、时效性较差等问题. 在某个谣言事件的传播过程中,早期评论数据以及直接与源交互的评论数据中通常包含实现谣言早期识别的关键信息,本研究引入广度采样的概念,通过提取事件浅层节点获取事件对应的早期评论信息,利用Transformer模块充分考虑不同节点的信息交互. ...
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
1
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
融合源信息和门控图神经网络的谣言检测研究
0
2021
融合源信息和门控图神经网络的谣言检测研究
0
2021
2
... 为了降低数据量并减少过拟合风险,Bi-GCN[18 ] 、RDEA[21 ] 、EBGCN[27 ] 等方法均采用随机删除边及节点信息的采样方式,此类采样方法存在丢失关键数据、时效性较差等问题. 在某个谣言事件的传播过程中,早期评论数据以及直接与源交互的评论数据中通常包含实现谣言早期识别的关键信息,本研究引入广度采样的概念,通过提取事件浅层节点获取事件对应的早期评论信息,利用Transformer模块充分考虑不同节点的信息交互. ...
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
2
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
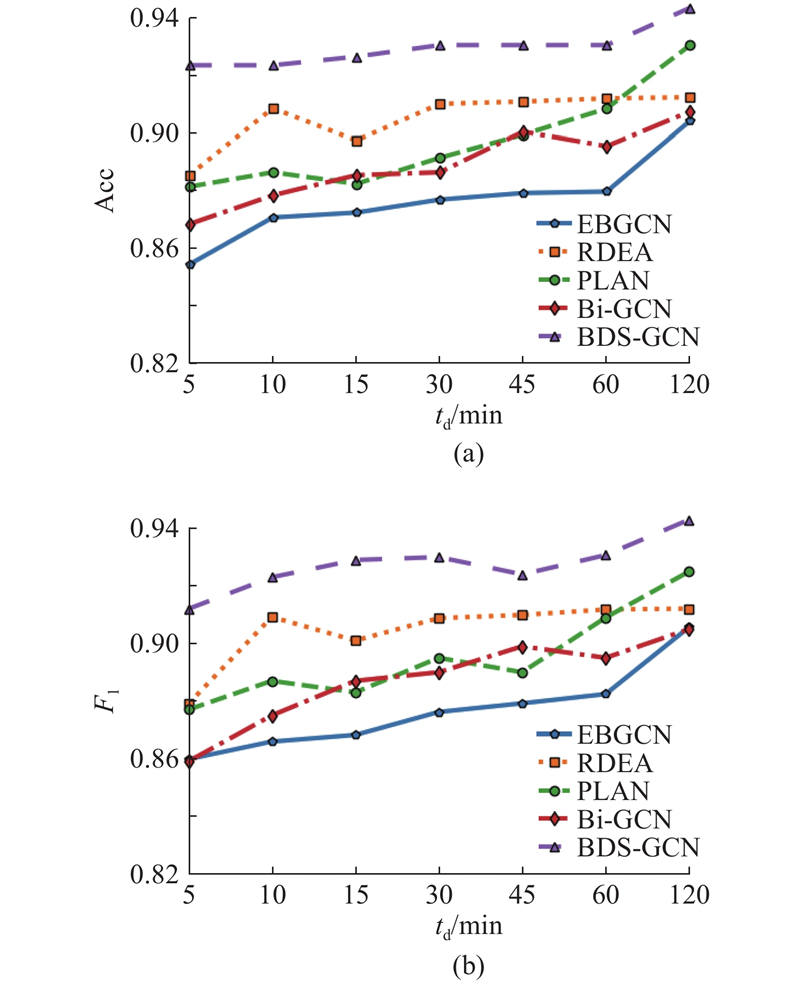
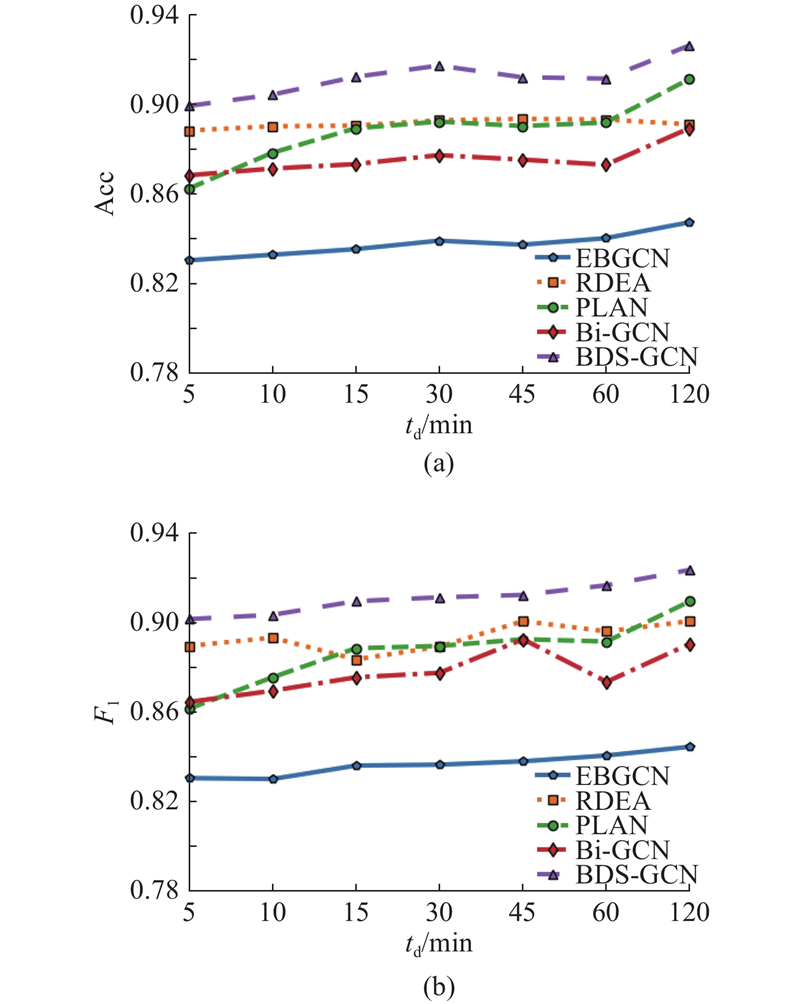
... 为了验证所提方法在英文数据集上的表现,增加英文谣言数据集Twitter-COVID19[22 ] ,所提方法和不同基线方法在3个数据集上的实验结果如表5 所示. 表中,每个评价指标的最优值用粗体表示,次优指标用下划线表示. 由表可知,在基于传统机器学习的谣言检测方法中,SVM-TS比DTC和DTR优势明显,主要原因是SVM-TS加入时间特征,能够有效捕获传播序列特征对于谣言识别的影响. 相较于基于传统机器学习的方法,基于深度学习的方法在检测性能上整体表现更好,原因是基于深度学习的方法能够利用复杂的网络结构学习到区分谣言事件和非谣言事件的深层特征信息. 在基于深度学习的谣言识别方法中,PLAN和RvNN的检测效果明显优于GRU,原因是GRU仅依赖事件的时间和文本特征,忽略了帖子间的回复-转发关系的影响,导致模型无法捕捉到关键的传播路径和关联信息;PLAN在基于传播序列的方法中表现最好,主要原因是该方法能够建模长距离帖子间的交互信息,从而获得事件完整表达. 进一步发现,基于事件传播结构的方法对应结果普遍优于基于传播序列的方法. 与Bi-GCN相比,RDEA通过引入对比学习思想,提升了谣言检测性能,方法准确率在Weibo2016数据集上与Bi-GCN相近但在CED数据集上比Bi-GCN高出0.016. 在Twitter-COVID19中,所提方法的准确率为0.682,略低于ACLR-BiGCN,高于绝大多数基线模型. 主要原因在于Twitter-COVID19数据集的数据规模较小,导致所提方法难以从中充分学习到事件的传播结构信息, ACLR-BiGCN利用丰富的源数据(Weibo2016)训练模型,通过监督对比学习获得源数据和目标数据(Twitter-COVID19)之间的通用知识,能够在数据资源较少的情况下实现谣言检测. ...
2
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
2
... 深度学习在自然语言处理领域中有较好的应用效果. Ma等[11 ] 提出基于循环神经网络(recurrent neural network, RNN)的谣言检测方法,该方法在Twitter和微博数据集上的应用效果较好,在谣言早期检测方面的表现良好. Yu等[10 ] 根据时间将评论划分为不同类型,使用Doc2vec技术对相关文本编码,使用卷积神经网络(convolutional neural networks, CNN)获得事件特征表达. 递归循环神经网络(recursive neural network, RvNN)[14 ] 、基于树的长短期记忆网络(long short-term memory, LSTM)[15 ] 和基于线性和非线性传播领域的谣言检测(rumor detection with field of linear and non-linear propagation,RDLNP)方法[16 ] 均证实,谣言与非谣言在社交媒体上的传播方式不同. 谣言在传播结构上具有更远、更深、更广的特征[17 ] ,当某个帖子否认谣言时,往往会引发其他用户的支持或肯定回复,以证实这一否认;相反,否认非谣言往往会在其子节点引发质疑或否认. 为了更深入研究传播结构在谣言检测过程中的作用,Bian等[18 ] 基于图卷积网络(graph convolutional network, GCN)提出Bi-GCN方法并应用于谣言检测领域,该方法将谣言传播结构表示为有向图,从自顶向下(top-down)和自底向上(bottom-up)2个方向提取谣言事件的深度传播信息和广度散播信息;Huang等[19 -23 ] 均在Bi-GCN的基础上分别通过引入异质图、门控机制、数据增强和对比学习、跨语言对抗对比学习框架和基于高斯分布的不确定性结构重建方法实现谣言检测并均取得较好的谣言检测效果. 上述方法均利用随机删除用户节点、节点连边的方式进行子图采样,极易造成数据信息损失. 传统基于传播结构的方法没有充分考虑不同分支下节点之间的信息交互,无法捕获长距离评论信息之间的关系. Khoo等[24 ] 提出将谣言事件传播树结构抽象为时间序列,利用自注意力网络模拟任意一对用户之间的信息交互,实现了长距离用户评论间的消息传递. 该类方法忽略了谣言事件传播过程中的全局结构关系,因此无法有效获得事件的深层次特征表达. ...
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
1
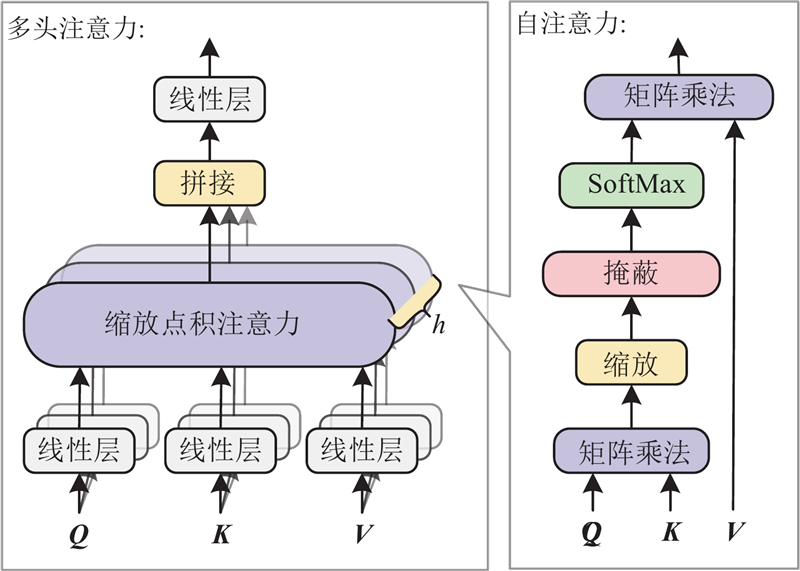
... 图神经网络(graph neural network, GNN)是针对网状结构数据提出的新型神经网络模型,GCN是GNN的一种[25 ] ,该算法将待处理数据表征为网状结构,利用“消息传递”机制定义聚合函数对网络中的每个节点进行卷积操作,通过汇聚相邻区域内的特征信息来更新中心节点的信息[26 ] ,进而获取节点最终特征表示. 给定图结构$ G= < V,E > $ $ V $ $ E $ $ \boldsymbol{A}\in {\mathbf{R}}^{n\times n} $ $ n $ $ i $ $ j $ $ {e}_{ij}\in E $ $ \boldsymbol{A} $ $ i $ $ j $
1
... 图神经网络(graph neural network, GNN)是针对网状结构数据提出的新型神经网络模型,GCN是GNN的一种[25 ] ,该算法将待处理数据表征为网状结构,利用“消息传递”机制定义聚合函数对网络中的每个节点进行卷积操作,通过汇聚相邻区域内的特征信息来更新中心节点的信息[26 ] ,进而获取节点最终特征表示. 给定图结构$ G= < V,E > $ $ V $ $ E $ $ \boldsymbol{A}\in {\mathbf{R}}^{n\times n} $ $ n $ $ i $ $ j $ $ {e}_{ij}\in E $ $ \boldsymbol{A} $ $ i $ $ j $
2
... 为了降低数据量并减少过拟合风险,Bi-GCN[18 ] 、RDEA[21 ] 、EBGCN[27 ] 等方法均采用随机删除边及节点信息的采样方式,此类采样方法存在丢失关键数据、时效性较差等问题. 在某个谣言事件的传播过程中,早期评论数据以及直接与源交互的评论数据中通常包含实现谣言早期识别的关键信息,本研究引入广度采样的概念,通过提取事件浅层节点获取事件对应的早期评论信息,利用Transformer模块充分考虑不同节点的信息交互. ...
... 式中:TP为实际与预测结果均为谣言的事件数量;FP为实际为非谣言预测结果为谣言的事件数量;TN为实际与预测结果均为非谣言的事件数量,FN为实际为谣言预测结果为非谣言的事件数量. 选取谣言检测领域典型的9种方法与所提方法进行对比. 不同方法对应的实验参数设置如表2 所示. 1)DTR由Zhao等[4 ] 提出,通过基于决策树算法的搜索排序结果识别谣言. 2)DTC由Castillo等[5 ] 提出,利用丰富的手工设计特征和数据统计信息建模谣言事件. 3)SVM-TS由Ma等[2 ] 提出,基于线性支持向量机方法将社会情景内容建模为固定时间区间的时间序列. 4)GRU由Ma等[11 ] 提出,利用GRU循环神经网络将用户评论按顺序建模为时间序列,以学习谣言序列特征表示,完成谣言检测任务. 5)RvNN由Ma等[14 ] 提出,实现基于树传播结构的递归神经网络,验证了传播结构在谣言检测中的重要性. 6)PLAN由Khoo等[24 ] 提出,将分层注意力方法应用于谣言检测,通过自注意力机制建模谣言事件中的信息交互. 7)Bi-GCN由Bian等[18 ] 提出,在准确率上优于SVM-TS、RvNN方法. 8)RDEA由He等[21 ] 提出,引入3种事件增强策略来缓解数据标注困难的问题. 9)EBGCN由Wei等[27 ] 提出,在Bi-GCN的基础上采用贝叶斯思想建模节点间连边权重. 10)ACLR-BiGCN由Lin等[22 ] 提出,在Bi-GCN的基础构建对抗对比学习框架,使用对抗攻击增强低资源数据的多样性. 11)UPSR由Wei等[23 ] 提出,通过多个高斯分布改进原始确定性节点表示,构建了新的基于双图的传播结构重建模型. ...
1
... 在采样得到传播序列后,使用jieba库对提取节点的文本进行分词,使用预训练的词向量[28 ] 作为分词后每个词语的特征向量表示. 一个帖子由一系列分词后的词语组成,表示为$ {P}_{ij}=\{{H}_{ij,0},{H}_{ij,1},\cdots , {H}_{ij,\mid {P}_{ij}|-1}\} $ $ {P}_{ij} $ $ i $ $ j $ $ \mid {P}_{ij}\mid $ $ {P}_{ij} $ $ {H}_{ij,k} $ $ {P}_{ij} $ $ k(0\leqslant k\leqslant \mid {P}_{ij}\mid -1) $ $ {H}_{ij,k} $ $ {h}_{ij,k}\in {\mathbf{R}}^{{d}_{{\mathrm{w}}}} $ $ {d}_{{\mathrm{w}}} $ $ {\boldsymbol{x}}_{j}^{i} $ $ i $ $ j $
1
... 当$ k=1 $ $ {\left({\boldsymbol{H}}_{D}^{i}\right)}_{0} $ $ {\left({\boldsymbol{H}}_{A}^{i}\right)}_{0}=\boldsymbol{X} $ $ {\left({\boldsymbol{H}}_{D}^{i}\right)}_{k}\in {\mathbf{R}}^{n\times {v}_{k}} $ $ {\left({\boldsymbol{H}}_{A}^{i}\right)}_{k}\in {\mathbf{R}}^{n\times {v}_{k}} $ $ \boldsymbol{X} $ $ {G}_{D}^{i} $ $ {G}_{A}^{i} $ k 个GCN层输出向量;$ {\widehat{\boldsymbol{A}}}_{D}^{i}\in {\mathbf{R}}^{n\times n} $ $ {\widehat{\boldsymbol{A}}}_{A}^{i}\in {\mathbf{R}}^{n\times n} $ $ {\boldsymbol{A}}^{\mathrm{{'}}} $ $ {{\boldsymbol{A}}^{\mathrm{{'}}\mathrm{T}}} $ $ n $ $ {v}_{k} $ k 个GCN层对应的向量维度;$ {\left({\boldsymbol{W}}_{D}^{i}\right)}_{k-1}\in {\mathbf{R}}^{{v}_{k-1}\times {v}_{k}} $ $ {\left({\boldsymbol{W}}_{A}^{i}\right)}_{k-1}\in {\mathbf{R}}^{{v}_{k-1}\times {v}_{k}} $ k 个GCN层对应的可训练权重矩阵. 在社交媒体中大规模扩散事件的源帖子通常含有丰富的语义信息和传递信息[29 ] ,为此在式(19)、式(20)的基础上,利用图中根节点(源贴节点)对当前节点进行语义增强,即将每个节点在第k 个GCN层对应的状态向量与第$ k-1 $
1
... 式中:$ \mathrm{F}\mathrm{C}(\cdot) $ ${\widehat{\boldsymbol{y}}}_{i}\in {\mathbf{R}}^{K} $ K ,$ \boldsymbol{W} $ $ \boldsymbol{b} $ [30 ] 优化更新模型参数. 将交叉熵函数作为所提方法的分类损失,计算预测结果与真实标签之间的差距: ...
CED: credible early detection of social media rumors
1
2021
... 软件环境为Python3.7+Pytorch1.9.0+cuda10.0,CPU为Intel Xeon Gold5218,内存为64G,显卡为NVIDIA GeForce RTX 2080Ti. 为了验证所提方法的有效性,在2个真实公开的数据集Weibo2016[11 ] 和CED[31 ] 上进行实验. 这2个数据集均来源于新浪微博管理中心平台发布的不实信息统计,数据集的参数如表1 所示. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}