$ {\boldsymbol{F}}_{\mathrm{m},k}\in {\mathbf{R}}^{K\times H\times W} $ $ {\boldsymbol{F}}_{\mathrm{h}} $ $ {\boldsymbol{F}}_{\mathrm{l},k} $ $ {\boldsymbol{F}}_{\mathrm{m},k} $ $ {\boldsymbol{F}}_{\mathrm{l},k} $ $ {\boldsymbol{F}}_{\mathrm{h}} $ [28 ] ,$ {\boldsymbol{F}}_{\mathrm{h}} $ $ {\boldsymbol{F}}_{\mathrm{l},k} $ $ {\boldsymbol{F}}_{\mathrm{l},k} $ $ {\boldsymbol{F}}_{\mathrm{h}} $ $ {\boldsymbol{F}}_{\mathrm{m},k} $ $ {\boldsymbol{F}}_{\mathrm{h}} $ $ {\boldsymbol{F}}_{\mathrm{m},k} $ $ {\boldsymbol{F}}_{\mathrm{m},k} $ $ {\boldsymbol{F}}_{\mathrm{m}}\in {\mathbf{R}}^{K\times K\times H\times W} $
式中: $ {\boldsymbol{V}}_{\mathrm{u},k}{\in \mathbf{R}}^{1\times N} $ k 个关键点的专享特征综合,$ {\boldsymbol{V}}_{\mathrm{l},k,b}{\in \mathbf{R}}^{1\times N} $ b 个人体中第k 个关键点的特征,B 为批次大小,$ \mathrm{S}\mathrm{u}\mathrm{m}(\cdot ) $ $ {\boldsymbol{V}}_{\mathrm{l},k,b} $ . 所有关键点均执行上述操作,获得所有关键点的专享特征$ {\boldsymbol{V}}_{\mathrm{u}}{\in \mathbf{R}}^{K\times N} $ . 将$ {\boldsymbol{V}}_{\mathrm{s}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $
[1]
孙雪菲, 张瑞峰, 关欣, 等 强化先验骨架结构的轻量型高效人体姿态估计
[J]. 浙江大学学报: 工学版 , 2024 , 58 (1 ): 50 - 60
[本文引用: 1]
SUN Xuefei, ZHANG Ruifeng, GUAN Xin, et al Lightweight and efficient human pose estimation with enhanced priori skeleton structure
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (1 ): 50 - 60
[本文引用: 1]
[2]
YU X W, CHEN G S. HRPoseFormer: high-resolution Transformer for human pose estimation via multi-scale token aggregation [C]// IEEE 16th International Conference on Solid-State and Integrated Circuit Technology . Nanjing: IEEE, 2022: 1–3.
[本文引用: 1]
[3]
ZHOU L, CHEN Y, WANG J Progressive direction-aware pose grammar for human pose estimation
[J]. IEEE Transactions on Biometrics, Behavior, and Identity Science , 2023 , 5 (4 ): 593 - 605
DOI:10.1109/TBIOM.2023.3315509
[本文引用: 3]
[4]
ZHANG Z, LIU M, SHEN J, et al Lightweight whole body human pose estimation with two-stage refinement training strategy
[J]. IEEE Transactions on Human-Machine Systems , 2024 , 54 (1 ): 121 - 130
DOI:10.1109/THMS.2024.3349652
[本文引用: 4]
[5]
LIN J, ZHENG Z, ZHONG Z, et al. Joint representation learning and keypoint detection for cross-view geo-localization [J]. IEEE Transactions on Image Processing , 2022, 31: 3780–3792.
[本文引用: 1]
[6]
MENG Q, QIN C, BAI W, et al MulViMotion: shape-aware 3D myocardial motion tracking from multi-view cardiac MRI
[J]. IEEE Transactions on Medical Imaging , 2022 , 41 (8 ): 1961 - 1974
DOI:10.1109/TMI.2022.3154599
[本文引用: 2]
[7]
CHAKRAVARTHI B, PATIL A K, RYU J Y, et al Scenario-based sensed human motion editing and validation through the motion-sphere
[J]. IEEE Access , 2022 , 10 : 28295 - 28307
DOI:10.1109/ACCESS.2022.3157939
[本文引用: 1]
[8]
MARQUES B, SILVA S, ALVES J, et al A conceptual model and taxonomy for collaborative augmented reality
[J]. IEEE Transactions on Visualization and Computer Graphics , 2022 , 28 (12 ): 5113 - 5133
DOI:10.1109/TVCG.2021.3101545
[本文引用: 1]
[9]
LI N, CHEN X, FENG Y, et al Human–computer interaction cognitive behavior modeling of command and control systems
[J]. IEEE Internet of Things Journal , 2022 , 9 (14 ): 12723 - 12736
DOI:10.1109/JIOT.2021.3138247
[本文引用: 1]
[10]
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5693–5703.
[本文引用: 3]
[11]
WANG J, SUN K, CHENG T, et al Deep high-resolution representation learning for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 43 (10 ): 3349 - 3364
DOI:10.1109/TPAMI.2020.2983686
[本文引用: 5]
[12]
KE L, CHANG M C, QI H, et al DetPoseNet: improving multi-person pose estimation via coarse-pose filtering
[J]. IEEE Transactions on Image Processing , 2022 , 31 : 2782 - 2795
DOI:10.1109/TIP.2022.3161081
[本文引用: 2]
[13]
CAO Z, HIDALGO G, SIMON T, et al OpenPose: realtime multi-person 2D pose estimation using part affinity fields
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 43 (1 ): 172 - 186
DOI:10.1109/TPAMI.2019.2929257
[本文引用: 2]
[14]
LI Q, ZHANG Z, ZHANG F, et al HRNeXt: high-resolution context network for crowd pose estimation
[J]. IEEE Transactions on Multimedia , 2023 , 25 (46 ): 1521 - 1528
[本文引用: 3]
[15]
KIM G, KIM H, KONG K, et al Human body aware feature extractor using attachable feature corrector for human pose estimation
[J]. IEEE Transactions on Multimedia , 2023 , 25 : 5789 - 5799
DOI:10.1109/TMM.2022.3199098
[本文引用: 3]
[16]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision . [S. l.]: Springer, 2014: 740–755.
[本文引用: 3]
[17]
BANZI J, BULUGU I, YE Z Learning a deep predictive coding network for a semi-supervised 3D-hand pose estimation
[J]. IEEE/CAA Journal of Automatica Sinica , 2020 , 7 (5 ): 1371 - 1379
DOI:10.1109/JAS.2020.1003090
[本文引用: 1]
[18]
KIM S, KANG S, CHOI H, et al Keypoint aware robust representation for transformer-based re-identification of occluded person
[J]. IEEE Signal Processing Letters , 2023 , 30 : 65 - 69
DOI:10.1109/LSP.2023.3240596
[本文引用: 3]
[19]
WANG Y J, LUO Y M, BAI G H, et al UformPose: a U-shaped hierarchical multi-scale keypoint-aware framework for human pose estimation
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2023 , 33 (4 ): 1697 - 1709
DOI:10.1109/TCSVT.2022.3213206
[本文引用: 1]
[20]
PENG S, ZHOU X, LIU Y, et al PVNet: pixel-wise voting network for 6DoF object pose estimation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (1 ): 3212 - 3223
[本文引用: 5]
[21]
ARTACHO B, SAVAKIS A UniPose+: a unified framework for 2D and 3D human pose estimation in images and videos
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (12 ): 9641 - 9653
DOI:10.1109/TPAMI.2021.3124736
[本文引用: 3]
[22]
GAI D, FENG R Y, MIN W, et al Spatiotemporal learning transformer for video-based human pose estimation
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2023 , 33 (9 ): 4564 - 4576
DOI:10.1109/TCSVT.2023.3269666
[本文引用: 2]
[23]
YIN Y, LIU M, ZHU Q, et al Multibranch attention graph convolutional networks for 3-D human pose estimation
[J]. IEEE Transactions on Instrumentation and Measurement , 2023 , 72 : 2520412.
[本文引用: 1]
[24]
FAN J, ZHENG P, LI S, et al An integrated hand-object dense pose estimation approach with explicit occlusion awareness for human-robot collaborative disassembly
[J]. IEEE Transactions on Automation Science and Engineering , 2024 , 21 (1 ): 147 - 156
DOI:10.1109/TASE.2022.3215584
[本文引用: 2]
[25]
PASA L, NAVARIN N, SPERDUTI A Multiresolution reservoir graph neural network
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2022 , 33 (6 ): 2642 - 2653
DOI:10.1109/TNNLS.2021.3090503
[本文引用: 1]
[26]
MORSHED M G, SULTANA T, LEE Y K LeL-GNN: learnable edge sampling and line based graph neural network for link prediction
[J]. IEEE Access , 2023 , 11 : 56083 - 56097
DOI:10.1109/ACCESS.2023.3283029
[本文引用: 1]
[27]
ISUFI E, GAMA F, RIBEIRO A EdgeNets: edge varying graph neural networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (11 ): 7457 - 7473
DOI:10.1109/TPAMI.2021.3111054
[本文引用: 1]
[28]
XU L, JIN S, LIU W, et al ZoomNAS: searching for whole-body human pose estimation in the wild
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2023 , 45 (8 ): 5296 - 5313
[本文引用: 7]
[29]
LEE K, KIM W, LEE S From human pose similarity metric to 3D human pose estimator: temporal propagating LSTM networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2023 , 45 (2 ): 1781 - 1797
DOI:10.1109/TPAMI.2022.3164344
[本文引用: 1]
[30]
LI J, WANG C, ZHU H, et al. CrowdPose: efficient crowded scenes pose estimation and a new benchmark [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 10855–10864.
[本文引用: 2]
强化先验骨架结构的轻量型高效人体姿态估计
1
2024
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
强化先验骨架结构的轻量型高效人体姿态估计
1
2024
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
1
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
Progressive direction-aware pose grammar for human pose estimation
3
2023
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
... Detection performance comparison of different algorithms
Tab.4 算法 GFLOPs Par/106 v /(帧·s−1 )文献[11 ] 14.6 28.5 10.0 文献[20 ] 28.5 19.8 11.2 文献[14 ] 27.7 65.5 14.1 文献[22 ] 37.1 33.8 12.4 文献[3 ] 14.5 51.4 12.9 本研究 29.4 64.5 11.1
3.5. 可视化展示 如图4 所示为所提网络在遮挡环境下的关键点热力图检测效果图. 可以看出,HRNet对被遮挡的脚部关键点检测误差较大;所提网络的热力值较集中且趋于真实位置,具有更高的检测精度. 如图5 所示,在多人且存在遮挡的情况下,所提网络较好地估计了站在后排且存在严重遮挡的人体姿态,对被物体遮挡、自身遮挡的姿态均有较好的效果. 如图6 所示,在多人且存在复杂遮挡环境下,所提网络对后排人的严重遮挡腿部的估计更精确,该网络在遮挡环境下的优越性能得以验证. ...
Lightweight whole body human pose estimation with two-stage refinement training strategy
4
2024
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
... Performance comparison of different algorithms in CrowdPose dataset
Tab.3 % 算法 AP AP5 AP75 APe APm APh 文献[4 ] 75.9 93.3 81.4 84.0 76.7 68.2 文献[13 ] 71.1 90.8 78.3 80.0 71.7 61.6 文献[20 ] 74.9 92.1 80.7 83.3 75.2 66.8 文献[28 ] 73.0 92.8 80.9 85.1 72.2 64.7 本研究 77.8 94.6 83.2 85.9 78.6 69.5
3.4. 消融实验 OB的浅层训练策略通过HLFMA强化遮挡区域,将输出特征图作为浅层训练数据来替换遮挡训练集,从NB迁移深层权重作为先验知识,进而弥补训练数据不足的问题. 为了验证HLFMA的有效性,在自建遮挡数据集上进行平均准确率和训练数据使用量对比分析. 当训练集中样本数量为2 000张时,文献[20 ]方法的平均准确率为47.5%,所提方法的精度为79.7%;使用500张时,所提方法的精度为45.8%. 可以看出,所提方法仅使用对比方法1/4的训练数据即可实现与之相当的精度,当使用相同数量时,精度高出32.2个百分点. 该结果验证了所提训练方法的有效性. ...
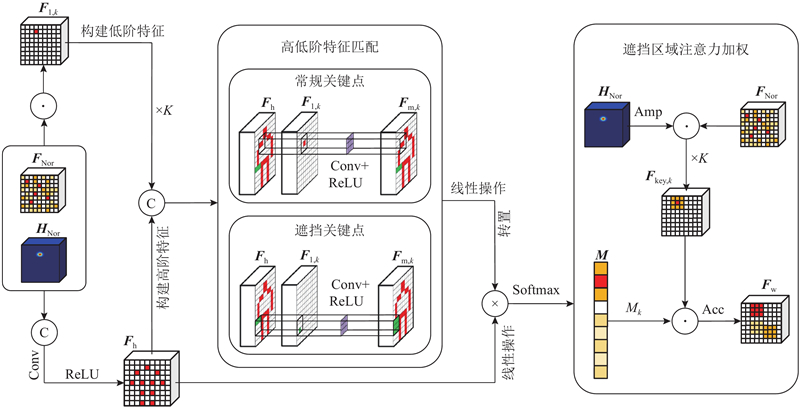
... 为了提升网络对遮挡区域的关注能力,本研究提出HLFMA,通过匹配高低阶特征识别遮挡关键点并对该点区域进行特征增强. 该模块可以融合到任何能够生成热力图与特征图的算法中,以提高其遮挡处理能力. 为了验证HLFMA的有效性,将它集成到文献[4 ]、[11 ]、[15 ]的算法中,集成方法是将HLFMA的输出$ {\boldsymbol{F}}_{\mathrm{w}} $
1
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
MulViMotion: shape-aware 3D myocardial motion tracking from multi-view cardiac MRI
2
2022
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
Scenario-based sensed human motion editing and validation through the motion-sphere
1
2022
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
A conceptual model and taxonomy for collaborative augmented reality
1
2022
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
Human–computer interaction cognitive behavior modeling of command and control systems
1
2022
... 人体姿态估计是基于图像或视频中人体关键点之间的空间结构关系来推断姿势和分析运动状态的技术[1 -3 ] . 准确检测人体关键点的位置对于人体姿态估计至关重要[4 -5 ] ,而且关键点检测逐渐成为姿态估计的主流方法. 人体姿态估计在运动捕捉[6 ] 、运动分析[7 ] 、增强现实[8 ] 和人机交互[9 ] 等领域都有广泛的应用. ...
3
... 根据图片中出现的人体数目,姿态估计分为单人和多人2个类别. 前者仅包含单个人体且背景较理想,后者面向更复杂的环境和不确定数目的人体;前者仅须检测单个人体所有部位关键点并形成人体姿态,后者的检测方法分为自上而下的方法[10 -12 ] 和自下而上的方法[13 -15 ] ;前者先定位每个人的边界框,再在每个框内执行单人关键点检测,后者检测所有关键点,将属于同一个人的关键点聚合. 总之,单人姿态估计的检测效率高,检测准确性取决于边界框的准确性;多人姿态估计提取的细节特征全面,但搜索范围较大,检测效率有待提升. 现有关键点检测方法在理想环境下表现良好,在遮挡环境下的检测效果欠佳. 主要原因是1)遮挡训练数据不足:如在COCO2017数据集中,包含遮挡案例的图片占总体的25%[16 ] ,仅有极少关键点被遮挡,网络权重会逐渐向常规无遮挡关键点方向收敛. 2)遮挡关键点的特征表达能力不强:关键点被障碍物遮挡,无法描述关键点真实属性. 可见,网络权重应向遮挡方向收敛,遮挡部位特征的表达能力须改善. ...
... 如表1 所示,在COCO2017数据集上将所提网络与其他算法进行比较,评估所提网络的性能. 由表可知,所提网络在所有算法中的平均准确率最高,为78.5%,召回率AR较高,为80.6%. 结果表明,所提网络可以在正常和遮挡场景下有效地检测人体关键点. COCO-Wholebody数据集具有全面注释,在该数据集上进行全身、手、脸和头的关键点检测实验,结果如表2 所示. 由表可知,除了在文献[10 ]和文献[21 ]中的脚部检测结果,所提网络在所有比较的其他检测结果中的平均准确率最高. 在灵活和遮挡的手部检测中,所提网络的AP比文献[28 ]算法的AP提高了3个百分点. 该结果验证了所提网络在遮挡环境下的有效性. 所提网络在脚部检测中没有达到最佳性能的原因:脚部通常位于特征图的底部,提取遮挡区域的方法在HLFMA中会扩大热点区域,当提取脚部区域时,提取范围可能超过特征图范围,导致特征提取精度降低和提取空白特征. 为了验证所提网络在遮挡场景中的性能,在CrowdPose数据集上比较不同算法. 如表3 所示,所提网络在所有比较算法中性能指标最好. 总结所提方法精度提升的原因. 1)HLFMA识别出存在遮挡的关键点,对其周围区域注意力加权,使网络能够强化特征提取. 2)OCNN的网络架构是对常规点及遮挡点独立检测,在强化遮挡部位的同时不影响常规关键点的检测精度. 3)在OGCN中,对节点特征进行障碍物特征弱化,关键点共享特征及专享特征的强化,使节点特征具有更全面的关键点属性描述能力及更高的准确性. 4)改进邻接矩阵使邻接矩阵能够跟据节点之间关系精确地描述关联性. ...
... Performance comparison of different algorithms in COCO-Wholebody dataset
Tab.2 % 算法 全身 脚 脸 手 躯干 AP AR AP AR AP AR AP AR AP AR 文献[10 ] 57.3 63.5 76.3 80.1 73.2 81.2 53.7 64.7 66.6 74.7 文献[18 ] 65.3 76.9 62.2 68.9 89.1 93.0 59.9 70.4 72.1 79.4 文献[21 ] 58.9 68.9 66.0 79.4 74.5 82.2 54.5 65.4 73.3 79.1 文献[28 ] 65.4 74.4 61.7 71.8 88.9 93.0 62.5 74.0 74.0 80.7 文献[30 ] 57.8 65.0 69.0 76.5 75.9 82.0 45.9 53.8 69.3 74.0 本研究 67.1 77.9 74.3 76.8 89.7 93.3 65.5 76.6 76.8 81.5
表 3 不同算法在CrowdPose数据集上的性能对比 ...
Deep high-resolution representation learning for visual recognition
5
2021
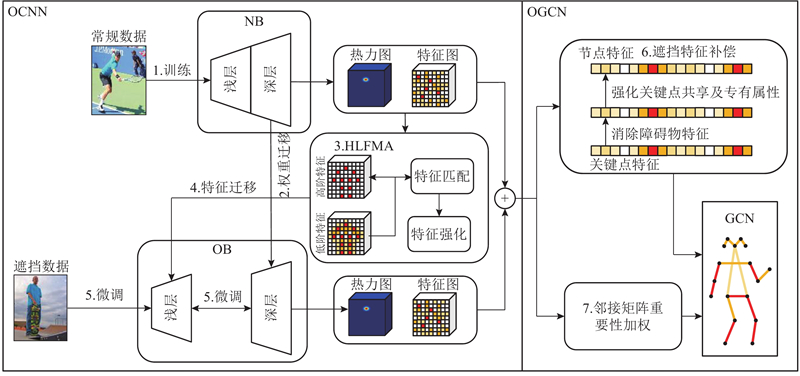
... 为了提升遮挡部位的检测精度,本研究提出基于知识共享的遮挡人体姿态估计网络,分为遮挡区域强化卷积网络(occluded parts enhanced convolutional network, OCNN)和遮挡特征补偿图卷积网络(occluded features compensation graph convolutional network, OGCN) 2个部分,通过融合OCNN与OGCN实现对遮挡部位的增强检测. OCNN具有2个子网络,为常规关键点检测骨干(normal bone, NB)和遮挡增强骨干(occlusion bone, OB),子网络的结构均为HRNet[11 ] . NB有充足训练数据,但遮挡部位的检测性能差;OB能够提升遮挡处理性能,但缺少遮挡训练数据. 本研究将NB深层权重迁移至OB,作为OB提取人体拓扑结构的先验知识;提出高低阶特征匹配注意力(high-low order feature matching attention, HLFMA)来强化遮挡区域的表达能力,将强化后的特征图作为OB浅层的训练数据,利用少量数据微调网络权重使浅层收敛. OGCN能够提升关键点特征的表达能力. 为了进一步改善遮挡部位特征的表达能力,本研究提出遮挡特征补偿方法,消除障碍物特征并融合关键点的共有属性及专有属性;提出邻接矩阵重要性加权方法,加权后的邻接矩阵能够根据节点之间的关联性对边的连接关系进行准确定义. ...
... 在COCO2017关键点检测数据集[16 ] 、COCO-Wholebody数据集[28 ] 和CrowdPose数据集[30 ] 上验证所提网络在不同场景下的性能. COCO2017数据集为每个人标注17个关键点,包括头部的5个关键点、躯干和四肢的12个关键点,有140000 个标注人,5000 张验证图像和20000 张测试图像,其中75%为正常场景,25%为遮挡场景,为算法性能提供了全面的评估. COCO-Wholebody数据集共标注133个关键点,包括68个面部关键点、42个手部关键点和23个身体关键点,包括118000 个训练数据和5000 个测试数据. CrowdPose数据集包含80000 个标注人物,共14个关键点,该数据集的遮挡场景较多,平均边界框交并比IoU =0.27,给人体关键点检测方法带来了额外的挑战. 为了使OB收敛,注释包含3 000个遮挡案例的遮挡数据集,每个案例中至少有3个关键点被遮挡,其中2 000张图片为训练集,1 000张为验证集. 注释格式与COCO2017数据集一致. 使用对象关键点相似性作为评估指标[11 ] . AP为平均准确率,进一步细分为AP5、AP75、APM和APL. 对于每个类别,将检测结果按照置信度从高到低排序,AP5表示取前5%的检测结果进行计算;AP75取前75%;APM取中间50%;APL取最低的5%. AR为召回率. APe、APm、APh代表不同的遮挡情况;其中APe表示样本遮挡比例为0%~10%,APm为10%~80%,APh为80%~100%. ...
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
... 为了提升网络对遮挡区域的关注能力,本研究提出HLFMA,通过匹配高低阶特征识别遮挡关键点并对该点区域进行特征增强. 该模块可以融合到任何能够生成热力图与特征图的算法中,以提高其遮挡处理能力. 为了验证HLFMA的有效性,将它集成到文献[4 ]、[11 ]、[15 ]的算法中,集成方法是将HLFMA的输出$ {\boldsymbol{F}}_{\mathrm{w}} $
... Detection performance comparison of different algorithms
Tab.4 算法 GFLOPs Par/106 v /(帧·s−1 )文献[11 ] 14.6 28.5 10.0 文献[20 ] 28.5 19.8 11.2 文献[14 ] 27.7 65.5 14.1 文献[22 ] 37.1 33.8 12.4 文献[3 ] 14.5 51.4 12.9 本研究 29.4 64.5 11.1
3.5. 可视化展示 如图4 所示为所提网络在遮挡环境下的关键点热力图检测效果图. 可以看出,HRNet对被遮挡的脚部关键点检测误差较大;所提网络的热力值较集中且趋于真实位置,具有更高的检测精度. 如图5 所示,在多人且存在遮挡的情况下,所提网络较好地估计了站在后排且存在严重遮挡的人体姿态,对被物体遮挡、自身遮挡的姿态均有较好的效果. 如图6 所示,在多人且存在复杂遮挡环境下,所提网络对后排人的严重遮挡腿部的估计更精确,该网络在遮挡环境下的优越性能得以验证. ...
DetPoseNet: improving multi-person pose estimation via coarse-pose filtering
2
2022
... 根据图片中出现的人体数目,姿态估计分为单人和多人2个类别. 前者仅包含单个人体且背景较理想,后者面向更复杂的环境和不确定数目的人体;前者仅须检测单个人体所有部位关键点并形成人体姿态,后者的检测方法分为自上而下的方法[10 -12 ] 和自下而上的方法[13 -15 ] ;前者先定位每个人的边界框,再在每个框内执行单人关键点检测,后者检测所有关键点,将属于同一个人的关键点聚合. 总之,单人姿态估计的检测效率高,检测准确性取决于边界框的准确性;多人姿态估计提取的细节特征全面,但搜索范围较大,检测效率有待提升. 现有关键点检测方法在理想环境下表现良好,在遮挡环境下的检测效果欠佳. 主要原因是1)遮挡训练数据不足:如在COCO2017数据集中,包含遮挡案例的图片占总体的25%[16 ] ,仅有极少关键点被遮挡,网络权重会逐渐向常规无遮挡关键点方向收敛. 2)遮挡关键点的特征表达能力不强:关键点被障碍物遮挡,无法描述关键点真实属性. 可见,网络权重应向遮挡方向收敛,遮挡部位特征的表达能力须改善. ...
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
OpenPose: realtime multi-person 2D pose estimation using part affinity fields
2
2021
... 根据图片中出现的人体数目,姿态估计分为单人和多人2个类别. 前者仅包含单个人体且背景较理想,后者面向更复杂的环境和不确定数目的人体;前者仅须检测单个人体所有部位关键点并形成人体姿态,后者的检测方法分为自上而下的方法[10 -12 ] 和自下而上的方法[13 -15 ] ;前者先定位每个人的边界框,再在每个框内执行单人关键点检测,后者检测所有关键点,将属于同一个人的关键点聚合. 总之,单人姿态估计的检测效率高,检测准确性取决于边界框的准确性;多人姿态估计提取的细节特征全面,但搜索范围较大,检测效率有待提升. 现有关键点检测方法在理想环境下表现良好,在遮挡环境下的检测效果欠佳. 主要原因是1)遮挡训练数据不足:如在COCO2017数据集中,包含遮挡案例的图片占总体的25%[16 ] ,仅有极少关键点被遮挡,网络权重会逐渐向常规无遮挡关键点方向收敛. 2)遮挡关键点的特征表达能力不强:关键点被障碍物遮挡,无法描述关键点真实属性. 可见,网络权重应向遮挡方向收敛,遮挡部位特征的表达能力须改善. ...
... Performance comparison of different algorithms in CrowdPose dataset
Tab.3 % 算法 AP AP5 AP75 APe APm APh 文献[4 ] 75.9 93.3 81.4 84.0 76.7 68.2 文献[13 ] 71.1 90.8 78.3 80.0 71.7 61.6 文献[20 ] 74.9 92.1 80.7 83.3 75.2 66.8 文献[28 ] 73.0 92.8 80.9 85.1 72.2 64.7 本研究 77.8 94.6 83.2 85.9 78.6 69.5
3.4. 消融实验 OB的浅层训练策略通过HLFMA强化遮挡区域,将输出特征图作为浅层训练数据来替换遮挡训练集,从NB迁移深层权重作为先验知识,进而弥补训练数据不足的问题. 为了验证HLFMA的有效性,在自建遮挡数据集上进行平均准确率和训练数据使用量对比分析. 当训练集中样本数量为2 000张时,文献[20 ]方法的平均准确率为47.5%,所提方法的精度为79.7%;使用500张时,所提方法的精度为45.8%. 可以看出,所提方法仅使用对比方法1/4的训练数据即可实现与之相当的精度,当使用相同数量时,精度高出32.2个百分点. 该结果验证了所提训练方法的有效性. ...
HRNeXt: high-resolution context network for crowd pose estimation
3
2023
... 式中: $ {\boldsymbol{F}}_{\mathrm{G}\mathrm{C}\mathrm{N}}{\in \mathbf{R}}^{K\times H\times \mathrm{W}} $ 图1 中GCN所示,颜色越深的边代表权重越高,连接的节点之间关联程度越大. GCN能够从物理角度描述的人体结构约束,融合不同程度的每个关键点特征到自身. 将$ {\boldsymbol{F}}_{\mathrm{C}\mathrm{N}\mathrm{N}} $ $ {\boldsymbol{F}}_{\mathrm{G}\mathrm{C}\mathrm{N}} $ [14 ] . 假设由$ {\boldsymbol{V}}_{\mathrm{l}} $ $ \boldsymbol{w} $ $ {\boldsymbol{w}}^{\mathrm{*}} $ $ \boldsymbol{V} $ $ \overline{\boldsymbol{w}} $ $ {\overline{\boldsymbol{w}}}^{\mathrm{*}} $ . 根据式(2),分别在收敛权重$ {\boldsymbol{w}}^{\mathrm{*}} $ $ {\overline{\boldsymbol{w}}}^{\mathrm{*}} $ $ {\boldsymbol{V}}_{\mathrm{l}} $ $ \boldsymbol{L}(w) $ $ \boldsymbol{V} $ $ \boldsymbol{L}(\overline{w}) $ $ \boldsymbol{V} $ $ {\boldsymbol{A}}_{\mathrm{w}} $ $ \boldsymbol{V} $ $ \boldsymbol{A} $ $ {\boldsymbol{V}}_{\mathrm{l}\mathrm{o}\mathrm{w}} $ $ {\overline{\boldsymbol{w}}}^{\mathrm{*}} $ $ {\boldsymbol{w}}^{\mathrm{*}} $ $ L({\overline{\boldsymbol{w}}}^{\mathrm{*}}) < L({\boldsymbol{w}}^{\mathrm{*}}) $ . OCNN提供了充足的节点特征且算力足够,$ \boldsymbol{w} $ $ \overline{\boldsymbol{w}} $ $ \boldsymbol{w}\approx {\boldsymbol{w}}^{\mathrm{*}} $ $ \overline{\boldsymbol{w}}\approx {\overline{\boldsymbol{w}}}^{\mathrm{*}} $ . 因此有$ L(\overline{\boldsymbol{w}}) < L(\boldsymbol{w}) $ . 综上所述,$ \boldsymbol{V} $ $ {\boldsymbol{A}}_{\mathrm{w}} $
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
... Detection performance comparison of different algorithms
Tab.4 算法 GFLOPs Par/106 v /(帧·s−1 )文献[11 ] 14.6 28.5 10.0 文献[20 ] 28.5 19.8 11.2 文献[14 ] 27.7 65.5 14.1 文献[22 ] 37.1 33.8 12.4 文献[3 ] 14.5 51.4 12.9 本研究 29.4 64.5 11.1
3.5. 可视化展示 如图4 所示为所提网络在遮挡环境下的关键点热力图检测效果图. 可以看出,HRNet对被遮挡的脚部关键点检测误差较大;所提网络的热力值较集中且趋于真实位置,具有更高的检测精度. 如图5 所示,在多人且存在遮挡的情况下,所提网络较好地估计了站在后排且存在严重遮挡的人体姿态,对被物体遮挡、自身遮挡的姿态均有较好的效果. 如图6 所示,在多人且存在复杂遮挡环境下,所提网络对后排人的严重遮挡腿部的估计更精确,该网络在遮挡环境下的优越性能得以验证. ...
Human body aware feature extractor using attachable feature corrector for human pose estimation
3
2023
... 根据图片中出现的人体数目,姿态估计分为单人和多人2个类别. 前者仅包含单个人体且背景较理想,后者面向更复杂的环境和不确定数目的人体;前者仅须检测单个人体所有部位关键点并形成人体姿态,后者的检测方法分为自上而下的方法[10 -12 ] 和自下而上的方法[13 -15 ] ;前者先定位每个人的边界框,再在每个框内执行单人关键点检测,后者检测所有关键点,将属于同一个人的关键点聚合. 总之,单人姿态估计的检测效率高,检测准确性取决于边界框的准确性;多人姿态估计提取的细节特征全面,但搜索范围较大,检测效率有待提升. 现有关键点检测方法在理想环境下表现良好,在遮挡环境下的检测效果欠佳. 主要原因是1)遮挡训练数据不足:如在COCO2017数据集中,包含遮挡案例的图片占总体的25%[16 ] ,仅有极少关键点被遮挡,网络权重会逐渐向常规无遮挡关键点方向收敛. 2)遮挡关键点的特征表达能力不强:关键点被障碍物遮挡,无法描述关键点真实属性. 可见,网络权重应向遮挡方向收敛,遮挡部位特征的表达能力须改善. ...
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
... 为了提升网络对遮挡区域的关注能力,本研究提出HLFMA,通过匹配高低阶特征识别遮挡关键点并对该点区域进行特征增强. 该模块可以融合到任何能够生成热力图与特征图的算法中,以提高其遮挡处理能力. 为了验证HLFMA的有效性,将它集成到文献[4 ]、[11 ]、[15 ]的算法中,集成方法是将HLFMA的输出$ {\boldsymbol{F}}_{\mathrm{w}} $
3
... 根据图片中出现的人体数目,姿态估计分为单人和多人2个类别. 前者仅包含单个人体且背景较理想,后者面向更复杂的环境和不确定数目的人体;前者仅须检测单个人体所有部位关键点并形成人体姿态,后者的检测方法分为自上而下的方法[10 -12 ] 和自下而上的方法[13 -15 ] ;前者先定位每个人的边界框,再在每个框内执行单人关键点检测,后者检测所有关键点,将属于同一个人的关键点聚合. 总之,单人姿态估计的检测效率高,检测准确性取决于边界框的准确性;多人姿态估计提取的细节特征全面,但搜索范围较大,检测效率有待提升. 现有关键点检测方法在理想环境下表现良好,在遮挡环境下的检测效果欠佳. 主要原因是1)遮挡训练数据不足:如在COCO2017数据集中,包含遮挡案例的图片占总体的25%[16 ] ,仅有极少关键点被遮挡,网络权重会逐渐向常规无遮挡关键点方向收敛. 2)遮挡关键点的特征表达能力不强:关键点被障碍物遮挡,无法描述关键点真实属性. 可见,网络权重应向遮挡方向收敛,遮挡部位特征的表达能力须改善. ...
... 在COCO2017关键点检测数据集[16 ] 、COCO-Wholebody数据集[28 ] 和CrowdPose数据集[30 ] 上验证所提网络在不同场景下的性能. COCO2017数据集为每个人标注17个关键点,包括头部的5个关键点、躯干和四肢的12个关键点,有140000 个标注人,5000 张验证图像和20000 张测试图像,其中75%为正常场景,25%为遮挡场景,为算法性能提供了全面的评估. COCO-Wholebody数据集共标注133个关键点,包括68个面部关键点、42个手部关键点和23个身体关键点,包括118000 个训练数据和5000 个测试数据. CrowdPose数据集包含80000 个标注人物,共14个关键点,该数据集的遮挡场景较多,平均边界框交并比IoU =0.27,给人体关键点检测方法带来了额外的挑战. 为了使OB收敛,注释包含3 000个遮挡案例的遮挡数据集,每个案例中至少有3个关键点被遮挡,其中2 000张图片为训练集,1 000张为验证集. 注释格式与COCO2017数据集一致. 使用对象关键点相似性作为评估指标[11 ] . AP为平均准确率,进一步细分为AP5、AP75、APM和APL. 对于每个类别,将检测结果按照置信度从高到低排序,AP5表示取前5%的检测结果进行计算;AP75取前75%;APM取中间50%;APL取最低的5%. AR为召回率. APe、APm、APh代表不同的遮挡情况;其中APe表示样本遮挡比例为0%~10%,APm为10%~80%,APh为80%~100%. ...
... 在OGCN中,本研究对节点特征进行补偿,对邻接矩阵进行重要性加权. 为了验证这2种方法的有效性,设计如下消融实验. 在关键点特征补偿方法中,消除障碍物特征,融入所有关键点的共有属性和每个关键点的专有属性对特征进行质量补偿. 为了验证消除障碍物、融合共有属性、融合专有属性3种特征补偿方法的有效性,提出3种对比方法: 1)无障碍物特征消除,即该方法中的节点特征$ {\boldsymbol{V}}_{\mathrm{l}} $ $\boldsymbol{M} $ $ {\boldsymbol{F}}_{\mathrm{l}} $ $ \mathrm{s}\mathrm{u}\mathrm{m}(\cdot ) $ $ \mathrm{L}\mathrm{i}\mathrm{n}(\cdot ) $ $ {\boldsymbol{V}}_{\mathrm{s}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $ . 对比方法1)的精度比所提网络的精度下降了1.7个百分点,原因是障碍物特征没有被消除,进而后续特征的提取精度有所下降,影响了检测精度. 对比方法2)的精度比所提网络的精度下降了2.0个百分点,表明融合所有关键点共有属性特征的方法有效,验证了对$ {\boldsymbol{V}}_{\mathrm{s}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $ $ \boldsymbol{A} $ $ {\boldsymbol{A}}_{\mathrm{w}} $ . 该对比方法的精度下降了1.8个百分点. 验证了邻接矩阵改进模块的有效性. 使用每秒十亿浮点运算GFLOPs作为神经网络模型的计算复杂度指标[24 ] ,使用参数量大小Par衡量模型大小,使用帧率v 作为检测阶段的耗时指标[16 ] ,对比结果如表4 所示. 本研究提出仅在训练过程中涉及权重和特征迁移与融合的训练策略,没有显著增加复杂度. 由于HLFMA,特征补偿模块中存在用于特征相似性匹配的矩阵计算,虽然引入了复杂度,但在实际应用范围内,且准确性高于其他算法. 参数量和检测速度位于最佳和最差之间,处于实际应用范围内. ...
Learning a deep predictive coding network for a semi-supervised 3D-hand pose estimation
1
2020
... 研究者采用不同方法处理遮挡问题. 1)深度先验方法:Banzi 等 [17 ] 整合网络不同层提取的特征提取能力以捕捉关键点之间的关系;Kim 等[18 ] 引入自适应采样策略和深度一致性约束,有效地解决了遮挡问题. 2)身体先验方法:Wang 等 [19 ] 提出关节关系提取器,以伪热图表示的关键点作为输入,使网络能够推断被遮挡关键点的位置;Peng 等 [20 ] 提出人体骨骼拓扑结构,用于在模型中提取非相邻关键点之间的相关关系. 3)时间先验方法:Artacho 等 [21 ] 提出基于LSTM的框架,结合跨尺度的上下文信息和高斯热图解码来提高骨干特征提取器的性能;Gai 等 [22 ] 提取并集成不同人的特征,在时间维度获得时空特征后,在目标帧上建立全局线索,提高了目标帧特征的全面性. 上述方法将常规关键点与遮挡关键点的检测视为统一问题并用单个网络解决,由于遮挡特征与关键点特征的离散性,极少的遮挡数据无法使网络收敛于遮挡方向,导致遮挡处理能力较差. 此外,这些方法没有对被遮挡的关键点特征进行补偿,导致高层次特征不完整,影响了整体特征精度. 遮挡问题的处理方法须具备以下特点:准确识别被遮挡的关键点,消除障碍物特征,使用与关键点真实特性相匹配的多维特征来增强关键点特征的表达能力,构建完整的高阶特征. ...
Keypoint aware robust representation for transformer-based re-identification of occluded person
3
2023
... 研究者采用不同方法处理遮挡问题. 1)深度先验方法:Banzi 等 [17 ] 整合网络不同层提取的特征提取能力以捕捉关键点之间的关系;Kim 等[18 ] 引入自适应采样策略和深度一致性约束,有效地解决了遮挡问题. 2)身体先验方法:Wang 等 [19 ] 提出关节关系提取器,以伪热图表示的关键点作为输入,使网络能够推断被遮挡关键点的位置;Peng 等 [20 ] 提出人体骨骼拓扑结构,用于在模型中提取非相邻关键点之间的相关关系. 3)时间先验方法:Artacho 等 [21 ] 提出基于LSTM的框架,结合跨尺度的上下文信息和高斯热图解码来提高骨干特征提取器的性能;Gai 等 [22 ] 提取并集成不同人的特征,在时间维度获得时空特征后,在目标帧上建立全局线索,提高了目标帧特征的全面性. 上述方法将常规关键点与遮挡关键点的检测视为统一问题并用单个网络解决,由于遮挡特征与关键点特征的离散性,极少的遮挡数据无法使网络收敛于遮挡方向,导致遮挡处理能力较差. 此外,这些方法没有对被遮挡的关键点特征进行补偿,导致高层次特征不完整,影响了整体特征精度. 遮挡问题的处理方法须具备以下特点:准确识别被遮挡的关键点,消除障碍物特征,使用与关键点真实特性相匹配的多维特征来增强关键点特征的表达能力,构建完整的高阶特征. ...
... 其中$ {\boldsymbol{V}}_{\mathrm{l}}{\in \mathbf{R}}^{K\times N} $ $ {\boldsymbol{V}}_{\mathrm{l}} $ [18 ] . 将$ \boldsymbol{M} $ $ {\boldsymbol{V}}_{\mathrm{l}} $
... Performance comparison of different algorithms in COCO-Wholebody dataset
Tab.2 % 算法 全身 脚 脸 手 躯干 AP AR AP AR AP AR AP AR AP AR 文献[10 ] 57.3 63.5 76.3 80.1 73.2 81.2 53.7 64.7 66.6 74.7 文献[18 ] 65.3 76.9 62.2 68.9 89.1 93.0 59.9 70.4 72.1 79.4 文献[21 ] 58.9 68.9 66.0 79.4 74.5 82.2 54.5 65.4 73.3 79.1 文献[28 ] 65.4 74.4 61.7 71.8 88.9 93.0 62.5 74.0 74.0 80.7 文献[30 ] 57.8 65.0 69.0 76.5 75.9 82.0 45.9 53.8 69.3 74.0 本研究 67.1 77.9 74.3 76.8 89.7 93.3 65.5 76.6 76.8 81.5
表 3 不同算法在CrowdPose数据集上的性能对比 ...
UformPose: a U-shaped hierarchical multi-scale keypoint-aware framework for human pose estimation
1
2023
... 研究者采用不同方法处理遮挡问题. 1)深度先验方法:Banzi 等 [17 ] 整合网络不同层提取的特征提取能力以捕捉关键点之间的关系;Kim 等[18 ] 引入自适应采样策略和深度一致性约束,有效地解决了遮挡问题. 2)身体先验方法:Wang 等 [19 ] 提出关节关系提取器,以伪热图表示的关键点作为输入,使网络能够推断被遮挡关键点的位置;Peng 等 [20 ] 提出人体骨骼拓扑结构,用于在模型中提取非相邻关键点之间的相关关系. 3)时间先验方法:Artacho 等 [21 ] 提出基于LSTM的框架,结合跨尺度的上下文信息和高斯热图解码来提高骨干特征提取器的性能;Gai 等 [22 ] 提取并集成不同人的特征,在时间维度获得时空特征后,在目标帧上建立全局线索,提高了目标帧特征的全面性. 上述方法将常规关键点与遮挡关键点的检测视为统一问题并用单个网络解决,由于遮挡特征与关键点特征的离散性,极少的遮挡数据无法使网络收敛于遮挡方向,导致遮挡处理能力较差. 此外,这些方法没有对被遮挡的关键点特征进行补偿,导致高层次特征不完整,影响了整体特征精度. 遮挡问题的处理方法须具备以下特点:准确识别被遮挡的关键点,消除障碍物特征,使用与关键点真实特性相匹配的多维特征来增强关键点特征的表达能力,构建完整的高阶特征. ...
PVNet: pixel-wise voting network for 6DoF object pose estimation
5
2022
... 研究者采用不同方法处理遮挡问题. 1)深度先验方法:Banzi 等 [17 ] 整合网络不同层提取的特征提取能力以捕捉关键点之间的关系;Kim 等[18 ] 引入自适应采样策略和深度一致性约束,有效地解决了遮挡问题. 2)身体先验方法:Wang 等 [19 ] 提出关节关系提取器,以伪热图表示的关键点作为输入,使网络能够推断被遮挡关键点的位置;Peng 等 [20 ] 提出人体骨骼拓扑结构,用于在模型中提取非相邻关键点之间的相关关系. 3)时间先验方法:Artacho 等 [21 ] 提出基于LSTM的框架,结合跨尺度的上下文信息和高斯热图解码来提高骨干特征提取器的性能;Gai 等 [22 ] 提取并集成不同人的特征,在时间维度获得时空特征后,在目标帧上建立全局线索,提高了目标帧特征的全面性. 上述方法将常规关键点与遮挡关键点的检测视为统一问题并用单个网络解决,由于遮挡特征与关键点特征的离散性,极少的遮挡数据无法使网络收敛于遮挡方向,导致遮挡处理能力较差. 此外,这些方法没有对被遮挡的关键点特征进行补偿,导致高层次特征不完整,影响了整体特征精度. 遮挡问题的处理方法须具备以下特点:准确识别被遮挡的关键点,消除障碍物特征,使用与关键点真实特性相匹配的多维特征来增强关键点特征的表达能力,构建完整的高阶特征. ...
... Performance comparison of different algorithms in COCO 2017 dataset
Tab.1 % 算法 AP AP5 AP75 APM APL AR 文献[2 ] 75.0 90.2 82.7 72.0 79.3 77.6 文献[3 ] 74.8 92.5 81.6 72.0 79.3 77.6 文献[4 ] 77.6 93.7 83.2 73.8 81.9 80.8 文献[6 ] 72.1 91.4 80.0 68.8 77.2 78.5 文献[11 ] 74.4 90.5 81.9 70.8 81.0 79.8 文献[12 ] 77.3 92.1 83.8 73.6 83.3 80.1 文献[14 ] 76.1 90.6 83.4 72.8 82.7 81.3 文献[20 ] 75.6 90.1 83.0 72.7 83.2 78.5 文献[15 ] 75.2 90.5 82.3 71.5 81.9 80.3 本研究 78.5 94.0 84.2 74.7 82.6 80.6
表 2 不同算法在COCO-Wholebody数据集上的性能对比 ...
... Performance comparison of different algorithms in CrowdPose dataset
Tab.3 % 算法 AP AP5 AP75 APe APm APh 文献[4 ] 75.9 93.3 81.4 84.0 76.7 68.2 文献[13 ] 71.1 90.8 78.3 80.0 71.7 61.6 文献[20 ] 74.9 92.1 80.7 83.3 75.2 66.8 文献[28 ] 73.0 92.8 80.9 85.1 72.2 64.7 本研究 77.8 94.6 83.2 85.9 78.6 69.5
3.4. 消融实验 OB的浅层训练策略通过HLFMA强化遮挡区域,将输出特征图作为浅层训练数据来替换遮挡训练集,从NB迁移深层权重作为先验知识,进而弥补训练数据不足的问题. 为了验证HLFMA的有效性,在自建遮挡数据集上进行平均准确率和训练数据使用量对比分析. 当训练集中样本数量为2 000张时,文献[20 ]方法的平均准确率为47.5%,所提方法的精度为79.7%;使用500张时,所提方法的精度为45.8%. 可以看出,所提方法仅使用对比方法1/4的训练数据即可实现与之相当的精度,当使用相同数量时,精度高出32.2个百分点. 该结果验证了所提训练方法的有效性. ...
... OB的浅层训练策略通过HLFMA强化遮挡区域,将输出特征图作为浅层训练数据来替换遮挡训练集,从NB迁移深层权重作为先验知识,进而弥补训练数据不足的问题. 为了验证HLFMA的有效性,在自建遮挡数据集上进行平均准确率和训练数据使用量对比分析. 当训练集中样本数量为2 000张时,文献[20 ]方法的平均准确率为47.5%,所提方法的精度为79.7%;使用500张时,所提方法的精度为45.8%. 可以看出,所提方法仅使用对比方法1/4的训练数据即可实现与之相当的精度,当使用相同数量时,精度高出32.2个百分点. 该结果验证了所提训练方法的有效性. ...
... Detection performance comparison of different algorithms
Tab.4 算法 GFLOPs Par/106 v /(帧·s−1 )文献[11 ] 14.6 28.5 10.0 文献[20 ] 28.5 19.8 11.2 文献[14 ] 27.7 65.5 14.1 文献[22 ] 37.1 33.8 12.4 文献[3 ] 14.5 51.4 12.9 本研究 29.4 64.5 11.1
3.5. 可视化展示 如图4 所示为所提网络在遮挡环境下的关键点热力图检测效果图. 可以看出,HRNet对被遮挡的脚部关键点检测误差较大;所提网络的热力值较集中且趋于真实位置,具有更高的检测精度. 如图5 所示,在多人且存在遮挡的情况下,所提网络较好地估计了站在后排且存在严重遮挡的人体姿态,对被物体遮挡、自身遮挡的姿态均有较好的效果. 如图6 所示,在多人且存在复杂遮挡环境下,所提网络对后排人的严重遮挡腿部的估计更精确,该网络在遮挡环境下的优越性能得以验证. ...
UniPose+: a unified framework for 2D and 3D human pose estimation in images and videos
3
2022
... 研究者采用不同方法处理遮挡问题. 1)深度先验方法:Banzi 等 [17 ] 整合网络不同层提取的特征提取能力以捕捉关键点之间的关系;Kim 等[18 ] 引入自适应采样策略和深度一致性约束,有效地解决了遮挡问题. 2)身体先验方法:Wang 等 [19 ] 提出关节关系提取器,以伪热图表示的关键点作为输入,使网络能够推断被遮挡关键点的位置;Peng 等 [20 ] 提出人体骨骼拓扑结构,用于在模型中提取非相邻关键点之间的相关关系. 3)时间先验方法:Artacho 等 [21 ] 提出基于LSTM的框架,结合跨尺度的上下文信息和高斯热图解码来提高骨干特征提取器的性能;Gai 等 [22 ] 提取并集成不同人的特征,在时间维度获得时空特征后,在目标帧上建立全局线索,提高了目标帧特征的全面性. 上述方法将常规关键点与遮挡关键点的检测视为统一问题并用单个网络解决,由于遮挡特征与关键点特征的离散性,极少的遮挡数据无法使网络收敛于遮挡方向,导致遮挡处理能力较差. 此外,这些方法没有对被遮挡的关键点特征进行补偿,导致高层次特征不完整,影响了整体特征精度. 遮挡问题的处理方法须具备以下特点:准确识别被遮挡的关键点,消除障碍物特征,使用与关键点真实特性相匹配的多维特征来增强关键点特征的表达能力,构建完整的高阶特征. ...
... 如表1 所示,在COCO2017数据集上将所提网络与其他算法进行比较,评估所提网络的性能. 由表可知,所提网络在所有算法中的平均准确率最高,为78.5%,召回率AR较高,为80.6%. 结果表明,所提网络可以在正常和遮挡场景下有效地检测人体关键点. COCO-Wholebody数据集具有全面注释,在该数据集上进行全身、手、脸和头的关键点检测实验,结果如表2 所示. 由表可知,除了在文献[10 ]和文献[21 ]中的脚部检测结果,所提网络在所有比较的其他检测结果中的平均准确率最高. 在灵活和遮挡的手部检测中,所提网络的AP比文献[28 ]算法的AP提高了3个百分点. 该结果验证了所提网络在遮挡环境下的有效性. 所提网络在脚部检测中没有达到最佳性能的原因:脚部通常位于特征图的底部,提取遮挡区域的方法在HLFMA中会扩大热点区域,当提取脚部区域时,提取范围可能超过特征图范围,导致特征提取精度降低和提取空白特征. 为了验证所提网络在遮挡场景中的性能,在CrowdPose数据集上比较不同算法. 如表3 所示,所提网络在所有比较算法中性能指标最好. 总结所提方法精度提升的原因. 1)HLFMA识别出存在遮挡的关键点,对其周围区域注意力加权,使网络能够强化特征提取. 2)OCNN的网络架构是对常规点及遮挡点独立检测,在强化遮挡部位的同时不影响常规关键点的检测精度. 3)在OGCN中,对节点特征进行障碍物特征弱化,关键点共享特征及专享特征的强化,使节点特征具有更全面的关键点属性描述能力及更高的准确性. 4)改进邻接矩阵使邻接矩阵能够跟据节点之间关系精确地描述关联性. ...
... Performance comparison of different algorithms in COCO-Wholebody dataset
Tab.2 % 算法 全身 脚 脸 手 躯干 AP AR AP AR AP AR AP AR AP AR 文献[10 ] 57.3 63.5 76.3 80.1 73.2 81.2 53.7 64.7 66.6 74.7 文献[18 ] 65.3 76.9 62.2 68.9 89.1 93.0 59.9 70.4 72.1 79.4 文献[21 ] 58.9 68.9 66.0 79.4 74.5 82.2 54.5 65.4 73.3 79.1 文献[28 ] 65.4 74.4 61.7 71.8 88.9 93.0 62.5 74.0 74.0 80.7 文献[30 ] 57.8 65.0 69.0 76.5 75.9 82.0 45.9 53.8 69.3 74.0 本研究 67.1 77.9 74.3 76.8 89.7 93.3 65.5 76.6 76.8 81.5
表 3 不同算法在CrowdPose数据集上的性能对比 ...
Spatiotemporal learning transformer for video-based human pose estimation
2
2023
... 研究者采用不同方法处理遮挡问题. 1)深度先验方法:Banzi 等 [17 ] 整合网络不同层提取的特征提取能力以捕捉关键点之间的关系;Kim 等[18 ] 引入自适应采样策略和深度一致性约束,有效地解决了遮挡问题. 2)身体先验方法:Wang 等 [19 ] 提出关节关系提取器,以伪热图表示的关键点作为输入,使网络能够推断被遮挡关键点的位置;Peng 等 [20 ] 提出人体骨骼拓扑结构,用于在模型中提取非相邻关键点之间的相关关系. 3)时间先验方法:Artacho 等 [21 ] 提出基于LSTM的框架,结合跨尺度的上下文信息和高斯热图解码来提高骨干特征提取器的性能;Gai 等 [22 ] 提取并集成不同人的特征,在时间维度获得时空特征后,在目标帧上建立全局线索,提高了目标帧特征的全面性. 上述方法将常规关键点与遮挡关键点的检测视为统一问题并用单个网络解决,由于遮挡特征与关键点特征的离散性,极少的遮挡数据无法使网络收敛于遮挡方向,导致遮挡处理能力较差. 此外,这些方法没有对被遮挡的关键点特征进行补偿,导致高层次特征不完整,影响了整体特征精度. 遮挡问题的处理方法须具备以下特点:准确识别被遮挡的关键点,消除障碍物特征,使用与关键点真实特性相匹配的多维特征来增强关键点特征的表达能力,构建完整的高阶特征. ...
... Detection performance comparison of different algorithms
Tab.4 算法 GFLOPs Par/106 v /(帧·s−1 )文献[11 ] 14.6 28.5 10.0 文献[20 ] 28.5 19.8 11.2 文献[14 ] 27.7 65.5 14.1 文献[22 ] 37.1 33.8 12.4 文献[3 ] 14.5 51.4 12.9 本研究 29.4 64.5 11.1
3.5. 可视化展示 如图4 所示为所提网络在遮挡环境下的关键点热力图检测效果图. 可以看出,HRNet对被遮挡的脚部关键点检测误差较大;所提网络的热力值较集中且趋于真实位置,具有更高的检测精度. 如图5 所示,在多人且存在遮挡的情况下,所提网络较好地估计了站在后排且存在严重遮挡的人体姿态,对被物体遮挡、自身遮挡的姿态均有较好的效果. 如图6 所示,在多人且存在复杂遮挡环境下,所提网络对后排人的严重遮挡腿部的估计更精确,该网络在遮挡环境下的优越性能得以验证. ...
Multibranch attention graph convolutional networks for 3-D human pose estimation
1
2023
... 图神经网络具有特征传递及提取能力,在遮挡环境中能够提取其他关键点特征并对被遮挡关键点进行补偿. Yin 等 [23 ] 提出多分支注意力图卷积运算,使用几种变换矩阵提取对被遮挡关键点有贡献的特征信息. Fan 等 [24 ] 提出的利用全局关系推理图卷积网络能够有效捕捉不同身体关节之间的全局关系,有助于构建高阶特征,使遮挡关键点检测精度提升. Pasa 等 [25 ] 提出多分辨率储层图神经网络,旨在生成显式的无监督图表示,进一步处理节点特征之间的关系. Morshed 等 [26 ] 提出可学习的边缘采样和折线图,在训练前通过学习参数选择特定数量的边缘采样机制减少了过度平滑,缓解了信息丢失的问题. Isufi 等 [27 ] 提出的边缘变化图神经网络,通过学习与边缘和邻居相关的权重来捕获局部细节并共享参数. 图神经网络应用于人体姿态估计存在节点特征提取方法单一的问题,这不仅会导致特征描述不全面,还会导致大量冗余特征参与特征构建. 由此可见,在图神经网络中,全面构建节点特征并精确描述邻接矩阵是必要的. ...
An integrated hand-object dense pose estimation approach with explicit occlusion awareness for human-robot collaborative disassembly
2
2024
... 图神经网络具有特征传递及提取能力,在遮挡环境中能够提取其他关键点特征并对被遮挡关键点进行补偿. Yin 等 [23 ] 提出多分支注意力图卷积运算,使用几种变换矩阵提取对被遮挡关键点有贡献的特征信息. Fan 等 [24 ] 提出的利用全局关系推理图卷积网络能够有效捕捉不同身体关节之间的全局关系,有助于构建高阶特征,使遮挡关键点检测精度提升. Pasa 等 [25 ] 提出多分辨率储层图神经网络,旨在生成显式的无监督图表示,进一步处理节点特征之间的关系. Morshed 等 [26 ] 提出可学习的边缘采样和折线图,在训练前通过学习参数选择特定数量的边缘采样机制减少了过度平滑,缓解了信息丢失的问题. Isufi 等 [27 ] 提出的边缘变化图神经网络,通过学习与边缘和邻居相关的权重来捕获局部细节并共享参数. 图神经网络应用于人体姿态估计存在节点特征提取方法单一的问题,这不仅会导致特征描述不全面,还会导致大量冗余特征参与特征构建. 由此可见,在图神经网络中,全面构建节点特征并精确描述邻接矩阵是必要的. ...
... 在OGCN中,本研究对节点特征进行补偿,对邻接矩阵进行重要性加权. 为了验证这2种方法的有效性,设计如下消融实验. 在关键点特征补偿方法中,消除障碍物特征,融入所有关键点的共有属性和每个关键点的专有属性对特征进行质量补偿. 为了验证消除障碍物、融合共有属性、融合专有属性3种特征补偿方法的有效性,提出3种对比方法: 1)无障碍物特征消除,即该方法中的节点特征$ {\boldsymbol{V}}_{\mathrm{l}} $ $\boldsymbol{M} $ $ {\boldsymbol{F}}_{\mathrm{l}} $ $ \mathrm{s}\mathrm{u}\mathrm{m}(\cdot ) $ $ \mathrm{L}\mathrm{i}\mathrm{n}(\cdot ) $ $ {\boldsymbol{V}}_{\mathrm{s}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $ . 对比方法1)的精度比所提网络的精度下降了1.7个百分点,原因是障碍物特征没有被消除,进而后续特征的提取精度有所下降,影响了检测精度. 对比方法2)的精度比所提网络的精度下降了2.0个百分点,表明融合所有关键点共有属性特征的方法有效,验证了对$ {\boldsymbol{V}}_{\mathrm{s}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $ $ {\boldsymbol{V}}_{\mathrm{u}} $ $ \boldsymbol{A} $ $ {\boldsymbol{A}}_{\mathrm{w}} $ . 该对比方法的精度下降了1.8个百分点. 验证了邻接矩阵改进模块的有效性. 使用每秒十亿浮点运算GFLOPs作为神经网络模型的计算复杂度指标[24 ] ,使用参数量大小Par衡量模型大小,使用帧率v 作为检测阶段的耗时指标[16 ] ,对比结果如表4 所示. 本研究提出仅在训练过程中涉及权重和特征迁移与融合的训练策略,没有显著增加复杂度. 由于HLFMA,特征补偿模块中存在用于特征相似性匹配的矩阵计算,虽然引入了复杂度,但在实际应用范围内,且准确性高于其他算法. 参数量和检测速度位于最佳和最差之间,处于实际应用范围内. ...
Multiresolution reservoir graph neural network
1
2022
... 图神经网络具有特征传递及提取能力,在遮挡环境中能够提取其他关键点特征并对被遮挡关键点进行补偿. Yin 等 [23 ] 提出多分支注意力图卷积运算,使用几种变换矩阵提取对被遮挡关键点有贡献的特征信息. Fan 等 [24 ] 提出的利用全局关系推理图卷积网络能够有效捕捉不同身体关节之间的全局关系,有助于构建高阶特征,使遮挡关键点检测精度提升. Pasa 等 [25 ] 提出多分辨率储层图神经网络,旨在生成显式的无监督图表示,进一步处理节点特征之间的关系. Morshed 等 [26 ] 提出可学习的边缘采样和折线图,在训练前通过学习参数选择特定数量的边缘采样机制减少了过度平滑,缓解了信息丢失的问题. Isufi 等 [27 ] 提出的边缘变化图神经网络,通过学习与边缘和邻居相关的权重来捕获局部细节并共享参数. 图神经网络应用于人体姿态估计存在节点特征提取方法单一的问题,这不仅会导致特征描述不全面,还会导致大量冗余特征参与特征构建. 由此可见,在图神经网络中,全面构建节点特征并精确描述邻接矩阵是必要的. ...
LeL-GNN: learnable edge sampling and line based graph neural network for link prediction
1
2023
... 图神经网络具有特征传递及提取能力,在遮挡环境中能够提取其他关键点特征并对被遮挡关键点进行补偿. Yin 等 [23 ] 提出多分支注意力图卷积运算,使用几种变换矩阵提取对被遮挡关键点有贡献的特征信息. Fan 等 [24 ] 提出的利用全局关系推理图卷积网络能够有效捕捉不同身体关节之间的全局关系,有助于构建高阶特征,使遮挡关键点检测精度提升. Pasa 等 [25 ] 提出多分辨率储层图神经网络,旨在生成显式的无监督图表示,进一步处理节点特征之间的关系. Morshed 等 [26 ] 提出可学习的边缘采样和折线图,在训练前通过学习参数选择特定数量的边缘采样机制减少了过度平滑,缓解了信息丢失的问题. Isufi 等 [27 ] 提出的边缘变化图神经网络,通过学习与边缘和邻居相关的权重来捕获局部细节并共享参数. 图神经网络应用于人体姿态估计存在节点特征提取方法单一的问题,这不仅会导致特征描述不全面,还会导致大量冗余特征参与特征构建. 由此可见,在图神经网络中,全面构建节点特征并精确描述邻接矩阵是必要的. ...
EdgeNets: edge varying graph neural networks
1
2022
... 图神经网络具有特征传递及提取能力,在遮挡环境中能够提取其他关键点特征并对被遮挡关键点进行补偿. Yin 等 [23 ] 提出多分支注意力图卷积运算,使用几种变换矩阵提取对被遮挡关键点有贡献的特征信息. Fan 等 [24 ] 提出的利用全局关系推理图卷积网络能够有效捕捉不同身体关节之间的全局关系,有助于构建高阶特征,使遮挡关键点检测精度提升. Pasa 等 [25 ] 提出多分辨率储层图神经网络,旨在生成显式的无监督图表示,进一步处理节点特征之间的关系. Morshed 等 [26 ] 提出可学习的边缘采样和折线图,在训练前通过学习参数选择特定数量的边缘采样机制减少了过度平滑,缓解了信息丢失的问题. Isufi 等 [27 ] 提出的边缘变化图神经网络,通过学习与边缘和邻居相关的权重来捕获局部细节并共享参数. 图神经网络应用于人体姿态估计存在节点特征提取方法单一的问题,这不仅会导致特征描述不全面,还会导致大量冗余特征参与特征构建. 由此可见,在图神经网络中,全面构建节点特征并精确描述邻接矩阵是必要的. ...
ZoomNAS: searching for whole-body human pose estimation in the wild
7
2023
... OCNN的设计过程如图1 所示. NB收敛且浅层和深层对不同特征的关注点不同. 浅层关注细节特征,深层由于卷积层堆叠而关注全局高阶特征[28 ] ,为此将子网络分为浅层和深层. 人体拓扑结构特征是常规和被遮挡的关键点,具有很高的相似性[28 ] , NB对被遮挡关键点的检测能力主要来自深层拓扑结构,因此将NB深层的权重迁移到OB的相应部分,作为初始化的先验知识,使OB具备提取高阶拓扑结构的能力. 损失函数用来衡量神经网络的收敛状态和检测精度,表达式为 ...
... [28 ], NB对被遮挡关键点的检测能力主要来自深层拓扑结构,因此将NB深层的权重迁移到OB的相应部分,作为初始化的先验知识,使OB具备提取高阶拓扑结构的能力. 损失函数用来衡量神经网络的收敛状态和检测精度,表达式为 ...
... $ {\boldsymbol{F}}_{\mathrm{m},k}\in {\mathbf{R}}^{K\times H\times W} $ $ {\boldsymbol{F}}_{\mathrm{h}} $ $ {\boldsymbol{F}}_{\mathrm{l},k} $ $ {\boldsymbol{F}}_{\mathrm{m},k} $ $ {\boldsymbol{F}}_{\mathrm{l},k} $ $ {\boldsymbol{F}}_{\mathrm{h}} $ [28 ] ,$ {\boldsymbol{F}}_{\mathrm{h}} $ $ {\boldsymbol{F}}_{\mathrm{l},k} $ $ {\boldsymbol{F}}_{\mathrm{l},k} $ $ {\boldsymbol{F}}_{\mathrm{h}} $ $ {\boldsymbol{F}}_{\mathrm{m},k} $ $ {\boldsymbol{F}}_{\mathrm{h}} $ $ {\boldsymbol{F}}_{\mathrm{m},k} $ $ {\boldsymbol{F}}_{\mathrm{m},k} $ $ {\boldsymbol{F}}_{\mathrm{m}}\in {\mathbf{R}}^{K\times K\times H\times W} $
... 在COCO2017关键点检测数据集[16 ] 、COCO-Wholebody数据集[28 ] 和CrowdPose数据集[30 ] 上验证所提网络在不同场景下的性能. COCO2017数据集为每个人标注17个关键点,包括头部的5个关键点、躯干和四肢的12个关键点,有140000 个标注人,5000 张验证图像和20000 张测试图像,其中75%为正常场景,25%为遮挡场景,为算法性能提供了全面的评估. COCO-Wholebody数据集共标注133个关键点,包括68个面部关键点、42个手部关键点和23个身体关键点,包括118000 个训练数据和5000 个测试数据. CrowdPose数据集包含80000 个标注人物,共14个关键点,该数据集的遮挡场景较多,平均边界框交并比IoU =0.27,给人体关键点检测方法带来了额外的挑战. 为了使OB收敛,注释包含3 000个遮挡案例的遮挡数据集,每个案例中至少有3个关键点被遮挡,其中2 000张图片为训练集,1 000张为验证集. 注释格式与COCO2017数据集一致. 使用对象关键点相似性作为评估指标[11 ] . AP为平均准确率,进一步细分为AP5、AP75、APM和APL. 对于每个类别,将检测结果按照置信度从高到低排序,AP5表示取前5%的检测结果进行计算;AP75取前75%;APM取中间50%;APL取最低的5%. AR为召回率. APe、APm、APh代表不同的遮挡情况;其中APe表示样本遮挡比例为0%~10%,APm为10%~80%,APh为80%~100%. ...
... 如表1 所示,在COCO2017数据集上将所提网络与其他算法进行比较,评估所提网络的性能. 由表可知,所提网络在所有算法中的平均准确率最高,为78.5%,召回率AR较高,为80.6%. 结果表明,所提网络可以在正常和遮挡场景下有效地检测人体关键点. COCO-Wholebody数据集具有全面注释,在该数据集上进行全身、手、脸和头的关键点检测实验,结果如表2 所示. 由表可知,除了在文献[10 ]和文献[21 ]中的脚部检测结果,所提网络在所有比较的其他检测结果中的平均准确率最高. 在灵活和遮挡的手部检测中,所提网络的AP比文献[28 ]算法的AP提高了3个百分点. 该结果验证了所提网络在遮挡环境下的有效性. 所提网络在脚部检测中没有达到最佳性能的原因:脚部通常位于特征图的底部,提取遮挡区域的方法在HLFMA中会扩大热点区域,当提取脚部区域时,提取范围可能超过特征图范围,导致特征提取精度降低和提取空白特征. 为了验证所提网络在遮挡场景中的性能,在CrowdPose数据集上比较不同算法. 如表3 所示,所提网络在所有比较算法中性能指标最好. 总结所提方法精度提升的原因. 1)HLFMA识别出存在遮挡的关键点,对其周围区域注意力加权,使网络能够强化特征提取. 2)OCNN的网络架构是对常规点及遮挡点独立检测,在强化遮挡部位的同时不影响常规关键点的检测精度. 3)在OGCN中,对节点特征进行障碍物特征弱化,关键点共享特征及专享特征的强化,使节点特征具有更全面的关键点属性描述能力及更高的准确性. 4)改进邻接矩阵使邻接矩阵能够跟据节点之间关系精确地描述关联性. ...
... Performance comparison of different algorithms in COCO-Wholebody dataset
Tab.2 % 算法 全身 脚 脸 手 躯干 AP AR AP AR AP AR AP AR AP AR 文献[10 ] 57.3 63.5 76.3 80.1 73.2 81.2 53.7 64.7 66.6 74.7 文献[18 ] 65.3 76.9 62.2 68.9 89.1 93.0 59.9 70.4 72.1 79.4 文献[21 ] 58.9 68.9 66.0 79.4 74.5 82.2 54.5 65.4 73.3 79.1 文献[28 ] 65.4 74.4 61.7 71.8 88.9 93.0 62.5 74.0 74.0 80.7 文献[30 ] 57.8 65.0 69.0 76.5 75.9 82.0 45.9 53.8 69.3 74.0 本研究 67.1 77.9 74.3 76.8 89.7 93.3 65.5 76.6 76.8 81.5
表 3 不同算法在CrowdPose数据集上的性能对比 ...
... Performance comparison of different algorithms in CrowdPose dataset
Tab.3 % 算法 AP AP5 AP75 APe APm APh 文献[4 ] 75.9 93.3 81.4 84.0 76.7 68.2 文献[13 ] 71.1 90.8 78.3 80.0 71.7 61.6 文献[20 ] 74.9 92.1 80.7 83.3 75.2 66.8 文献[28 ] 73.0 92.8 80.9 85.1 72.2 64.7 本研究 77.8 94.6 83.2 85.9 78.6 69.5
3.4. 消融实验 OB的浅层训练策略通过HLFMA强化遮挡区域,将输出特征图作为浅层训练数据来替换遮挡训练集,从NB迁移深层权重作为先验知识,进而弥补训练数据不足的问题. 为了验证HLFMA的有效性,在自建遮挡数据集上进行平均准确率和训练数据使用量对比分析. 当训练集中样本数量为2 000张时,文献[20 ]方法的平均准确率为47.5%,所提方法的精度为79.7%;使用500张时,所提方法的精度为45.8%. 可以看出,所提方法仅使用对比方法1/4的训练数据即可实现与之相当的精度,当使用相同数量时,精度高出32.2个百分点. 该结果验证了所提训练方法的有效性. ...
From human pose similarity metric to 3D human pose estimator: temporal propagating LSTM networks
1
2023
... 式中:$ \boldsymbol{M}\in {\mathbf{R}}^{1\times K} $ $ {\boldsymbol{V}}_{\mathrm{m}} $ $ {\boldsymbol{V}}_{\mathrm{h}} $ $ \boldsymbol{M} $ [29 ] . 扩展$ {\boldsymbol{H}}_{\mathrm{N}\mathrm{o}\mathrm{r},k} $ $ {\boldsymbol{F}}_{\mathrm{N}\mathrm{o}\mathrm{r}} $
2
... 在COCO2017关键点检测数据集[16 ] 、COCO-Wholebody数据集[28 ] 和CrowdPose数据集[30 ] 上验证所提网络在不同场景下的性能. COCO2017数据集为每个人标注17个关键点,包括头部的5个关键点、躯干和四肢的12个关键点,有140000 个标注人,5000 张验证图像和20000 张测试图像,其中75%为正常场景,25%为遮挡场景,为算法性能提供了全面的评估. COCO-Wholebody数据集共标注133个关键点,包括68个面部关键点、42个手部关键点和23个身体关键点,包括118000 个训练数据和5000 个测试数据. CrowdPose数据集包含80000 个标注人物,共14个关键点,该数据集的遮挡场景较多,平均边界框交并比IoU =0.27,给人体关键点检测方法带来了额外的挑战. 为了使OB收敛,注释包含3 000个遮挡案例的遮挡数据集,每个案例中至少有3个关键点被遮挡,其中2 000张图片为训练集,1 000张为验证集. 注释格式与COCO2017数据集一致. 使用对象关键点相似性作为评估指标[11 ] . AP为平均准确率,进一步细分为AP5、AP75、APM和APL. 对于每个类别,将检测结果按照置信度从高到低排序,AP5表示取前5%的检测结果进行计算;AP75取前75%;APM取中间50%;APL取最低的5%. AR为召回率. APe、APm、APh代表不同的遮挡情况;其中APe表示样本遮挡比例为0%~10%,APm为10%~80%,APh为80%~100%. ...
... Performance comparison of different algorithms in COCO-Wholebody dataset
Tab.2 % 算法 全身 脚 脸 手 躯干 AP AR AP AR AP AR AP AR AP AR 文献[10 ] 57.3 63.5 76.3 80.1 73.2 81.2 53.7 64.7 66.6 74.7 文献[18 ] 65.3 76.9 62.2 68.9 89.1 93.0 59.9 70.4 72.1 79.4 文献[21 ] 58.9 68.9 66.0 79.4 74.5 82.2 54.5 65.4 73.3 79.1 文献[28 ] 65.4 74.4 61.7 71.8 88.9 93.0 62.5 74.0 74.0 80.7 文献[30 ] 57.8 65.0 69.0 76.5 75.9 82.0 45.9 53.8 69.3 74.0 本研究 67.1 77.9 74.3 76.8 89.7 93.3 65.5 76.6 76.8 81.5
表 3 不同算法在CrowdPose数据集上的性能对比 ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}