[1]
陈磊, 刘立波, 王晓丽. 2020年宁夏枸杞虫害图文跨模态检索数据集[J]. 中国科学数据(中英文网络版), 2022, 7(3): 149−156.
[本文引用: 3]
CHEN Lei, LIU Libo, WANG Xiaoli. A dataset of image-text cross-modal retrieval of Lycium barbarum pests in Ningxia in 2020 [J]. China Scientific Data . 2022, 7(3): 149−156.
[本文引用: 3]
[2]
王云露. 基于深度迁移学习的苹果病害识别方法研究[D]. 泰安: 山东农业大学, 2022: 2−14.
[本文引用: 1]
WANG Yunlu. Apple disease identification method based on deep transfer learning [D]. Tai’an: Shandong Agricultural University, 2022: 2−14.
[本文引用: 1]
[3]
胡林龙. 基于图像处理的甘蓝型油菜的虫害程度与识别的研究[D]. 武汉: 武汉轻工大学, 2020: 10−45.
[本文引用: 1]
HU Linlong. Study on pest degree and recognition of brassica napus based on image processing [D]. Wuhan: Wuhan Polytechnic University, 2020: 10−45.
[本文引用: 1]
[4]
EBRAHIMI M A, KHOSHTAGHAZA M H, MINAEI S, et al Vision-based pest detection based on SVM classification method
[J]. Computers and Electronics in Agriculture , 2017 , 137 : 52 - 58
DOI:10.1016/j.compag.2017.03.016
[本文引用: 1]
[5]
WEN C, CHEN H, MA Z, et al Pest-YOLO: a model for large-scale multi-class dense and tiny pest detection and counting
[J]. Frontiers in Plant Science , 2022 , 13 : 973985
DOI:10.3389/fpls.2022.973985
[本文引用: 1]
[6]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020−04−23)[2023−06−22]. https://arxiv.org/pdf/2004.10934.
[本文引用: 1]
[7]
王金星, 马博, 王震, 等 基于改进Mask R-CNN的苹果园害虫识别方法
[J]. 农业机械学报 , 2023 , 54 (6 ): 253 - 263
DOI:10.6041/j.issn.1000-1298.2023.06.026
[本文引用: 1]
WANG Jinxing, MA Bo, WANG Zhen, et al Pest identification method in apple orchard based on improved Mask R-CNN
[J]. Transactions of the Chinese Society of Agricultural Machinery , 2023 , 54 (6 ): 253 - 263
DOI:10.6041/j.issn.1000-1298.2023.06.026
[本文引用: 1]
[8]
HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2961−2969.
[本文引用: 1]
[9]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 3−19.
[本文引用: 1]
[10]
XIE S, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1492−1500.
[本文引用: 1]
[11]
王卫星, 刘泽乾, 高鹏, 等 基于改进YOLO v4的荔枝病虫害检测模型
[J]. 农业机械学报 , 2023 , 54 (5 ): 227 - 235
DOI:10.6041/j.issn.1000-1298.2023.05.023
[本文引用: 1]
WANG Weixing, LIU Zeqian, GAO Peng, et al Detection of litchi diseases and insect pests based on improved YOLO v4 model
[J]. Transactions of the Chinese Society of Agricultural Machinery , 2023 , 54 (5 ): 227 - 235
DOI:10.6041/j.issn.1000-1298.2023.05.023
[本文引用: 1]
[12]
HAN K, WANG Y, TIAN Q, et al. GhostNet: more features from cheap operations [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1580−1589.
[本文引用: 1]
[13]
苏虹. 枸杞病虫害识别方法的研究与设计[D]. 银川: 宁夏大学, 2019: 1−2.
[本文引用: 1]
SU Hong. Research and design of recognition algorithm for wolfberry pests and diseases [D]. Yinchuan: Ningxia University, 2019: 1−2.
[本文引用: 1]
[14]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779−788.
[本文引用: 1]
[15]
JOCHER G. YOLOv5: minor version 6.0 [EB/OL]. (2021−10−12) [2023−06−22]. https://github.com/ultralytics/yolov5/releases/tag/v6.0.
[本文引用: 1]
[16]
LI J, XIA X, LI W, et al. Next-ViT: next generation vision transformer for efficient deployment in realistic industrial scenarios [EB/OL]. (2022−08−16)[2023−06−22]. https://arxiv.org/pdf/2207.05501.
[本文引用: 1]
[17]
CHEN J, KAO S H, HE H, et al. Run, don’t walk: chasing higher FLOPS for faster neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 12021−12031.
[本文引用: 1]
[18]
沈守娟, 郑广浩, 彭译萱, 等 基于YOLOv3算法的教室学生检测与人数统计方法
[J]. 软件导刊 , 2020 , 19 (9 ): 78 - 83
[本文引用: 1]
SHEN Shoujuan, PENG Yixuan, ZHENG Guanghao, et al Crowd detection and statistical methods based on YOLOv3 algorithm in classroom scenes
[J]. Software Guide , 2020 , 19 (9 ): 78 - 83
[本文引用: 1]
[19]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2020−06−03)[2023−06−22]. https://arxiv.org/pdf/2010.11929.
[本文引用: 1]
[20]
YU W, LUO M, ZHOU P, et al. MetaFormer is actually what you need for vision [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 10819−10829.
[本文引用: 1]
[21]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2117−2125.
[本文引用: 1]
[22]
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]// Proceedings of the IEEE International Conference Computer Vision . Venice: IEEE, 2017.
[本文引用: 1]
[23]
LI Y, HU J, WEN Y, et al. Rethinking vision transformers for MobileNet size and speed [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 16889−16900.
[本文引用: 1]
[24]
邵明月, 张建华, 冯全, 等 深度学习在植物叶部病害检测与识别的研究进展
[J]. 智慧农业(中英文) , 2022 , 4 (1 ): 29 - 46
[本文引用: 1]
SHAO Mingyue, ZHANG Jianhua, FENG Quan, et al Research progress of deep learning in detection and recognition of plant leaf diseases
[J]. Smart Agriculture , 2022 , 4 (1 ): 29 - 46
[本文引用: 1]
[25]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018−04−08)[2023−06−22]. https://arxiv.org/pdf/1804.02767.
[本文引用: 2]
[26]
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies set new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Patterns Recognized . Vancouver: IEEE, 2023: 7464−7475.
[本文引用: 2]
[27]
GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021 [EB/OL]. (2021−08−06)[2023−06−22]. https://arxiv.org/pdf/2107.08430
[本文引用: 2]
[28]
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// Proceedings of European Conference on Computer Vision . Glasgow: Springer, 2020: 213−229.
[本文引用: 2]
[29]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10781−10790.
[本文引用: 2]
[30]
CAI Z, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6154−6162.
[本文引用: 2]
3
... 枸杞虫害早期发现与防治对发展地方经济具有十分重要的意义[1 ] . 枸杞虫害的监测主要依靠人工,通过肉眼观察和人工经验判断害虫种类. 这种方法有很大的局限性,不仅消耗大量人力,而且判断结果易受主观因素的影响. ...
... 在开源的公共病虫害数据中,植物(如苹果、水稻、小麦、玉米、葡萄等)病害数据较多,虫害数据较少,针对某种植物的虫害数据集更少. 本研究自建虫害数据集,步骤如下:1)数据收集:一是引用陈磊等[1 ] 的宁夏枸杞虫害图文跨模态检索数据集中的部分图像,二是网络收集枸杞虫害图像;2)对收集图像进行手动筛选,去掉重复或者周围环境相似的图片,保留具有训练意义的图像;3)所有保留的图像组成数据集. 如图1 所示为所构建数据集中5种虫害的示例图,其中图1 (a)、图1 (b)来自文献[1 ],图1 (c)、图1 (d)来自网络收集. 将数据集中图像进行HSV变换、旋转角度、平移、缩放等数据增强处理,以适应多种复杂环境. 将处理后的图像打乱,随机划分为训练集和验证集;网络收集图像均经过人工审查处理(为了体现模型在复杂环境下的性能,挑选图片以环境复杂图像居多),因此测试集大部分选取处理后的网络收集图像. 数据集中3 600张JPG格式的图像使用MakeSense进行手动标注,生成txt格式和xml格式的标签文件. 如表1 所示,数据集按照70.8%、18.1%、11.1%随机划分为训练集(2 550张)、验证集(650张)、测试集(400张);枸杞虫害种类较多,数据集只选取主要的虫害,包括尺蠖、大青叶蝉、负泥虫、毛跳甲、蚜虫. ...
... (b)来自文献[1 ],图1 (c)、图1 (d)来自网络收集. 将数据集中图像进行HSV变换、旋转角度、平移、缩放等数据增强处理,以适应多种复杂环境. 将处理后的图像打乱,随机划分为训练集和验证集;网络收集图像均经过人工审查处理(为了体现模型在复杂环境下的性能,挑选图片以环境复杂图像居多),因此测试集大部分选取处理后的网络收集图像. 数据集中3 600张JPG格式的图像使用MakeSense进行手动标注,生成txt格式和xml格式的标签文件. 如表1 所示,数据集按照70.8%、18.1%、11.1%随机划分为训练集(2 550张)、验证集(650张)、测试集(400张);枸杞虫害种类较多,数据集只选取主要的虫害,包括尺蠖、大青叶蝉、负泥虫、毛跳甲、蚜虫. ...
3
... 枸杞虫害早期发现与防治对发展地方经济具有十分重要的意义[1 ] . 枸杞虫害的监测主要依靠人工,通过肉眼观察和人工经验判断害虫种类. 这种方法有很大的局限性,不仅消耗大量人力,而且判断结果易受主观因素的影响. ...
... 在开源的公共病虫害数据中,植物(如苹果、水稻、小麦、玉米、葡萄等)病害数据较多,虫害数据较少,针对某种植物的虫害数据集更少. 本研究自建虫害数据集,步骤如下:1)数据收集:一是引用陈磊等[1 ] 的宁夏枸杞虫害图文跨模态检索数据集中的部分图像,二是网络收集枸杞虫害图像;2)对收集图像进行手动筛选,去掉重复或者周围环境相似的图片,保留具有训练意义的图像;3)所有保留的图像组成数据集. 如图1 所示为所构建数据集中5种虫害的示例图,其中图1 (a)、图1 (b)来自文献[1 ],图1 (c)、图1 (d)来自网络收集. 将数据集中图像进行HSV变换、旋转角度、平移、缩放等数据增强处理,以适应多种复杂环境. 将处理后的图像打乱,随机划分为训练集和验证集;网络收集图像均经过人工审查处理(为了体现模型在复杂环境下的性能,挑选图片以环境复杂图像居多),因此测试集大部分选取处理后的网络收集图像. 数据集中3 600张JPG格式的图像使用MakeSense进行手动标注,生成txt格式和xml格式的标签文件. 如表1 所示,数据集按照70.8%、18.1%、11.1%随机划分为训练集(2 550张)、验证集(650张)、测试集(400张);枸杞虫害种类较多,数据集只选取主要的虫害,包括尺蠖、大青叶蝉、负泥虫、毛跳甲、蚜虫. ...
... (b)来自文献[1 ],图1 (c)、图1 (d)来自网络收集. 将数据集中图像进行HSV变换、旋转角度、平移、缩放等数据增强处理,以适应多种复杂环境. 将处理后的图像打乱,随机划分为训练集和验证集;网络收集图像均经过人工审查处理(为了体现模型在复杂环境下的性能,挑选图片以环境复杂图像居多),因此测试集大部分选取处理后的网络收集图像. 数据集中3 600张JPG格式的图像使用MakeSense进行手动标注,生成txt格式和xml格式的标签文件. 如表1 所示,数据集按照70.8%、18.1%、11.1%随机划分为训练集(2 550张)、验证集(650张)、测试集(400张);枸杞虫害种类较多,数据集只选取主要的虫害,包括尺蠖、大青叶蝉、负泥虫、毛跳甲、蚜虫. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
Vision-based pest detection based on SVM classification method
1
2017
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
Pest-YOLO: a model for large-scale multi-class dense and tiny pest detection and counting
1
2022
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
基于改进Mask R-CNN的苹果园害虫识别方法
1
2023
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
基于改进Mask R-CNN的苹果园害虫识别方法
1
2023
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
基于改进YOLO v4的荔枝病虫害检测模型
1
2023
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
基于改进YOLO v4的荔枝病虫害检测模型
1
2023
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 随着科学技术发展,基于计算机视觉的虫害检测逐步发展为主流,可分为传统方法和深度学习方法2个类别. 传统方法以传统机器学习为主,通过图像预处理(灰度化、直方图均衡化、色彩空间转化、中值滤波等)、图像分割和特征提取技术(局部二值化、灰度共生矩阵、颜色共生矩阵、间灰度相关矩阵等)人为进行特征选择和设计,再通过特定的机器学习算法〔如支持向量机(support vector machine,SVM)、随机森林、线性回归分析、主成分分析等〕训练模型对特定特征向量的分类能力,达到识别病虫害图像的目的[2 ] . 胡林龙[3 ] 研究甘蓝型油菜叶片图像的虫害程度与识别的检测方法,从图像处理和图像特征提取的角度,将SVM结合如颜色、纹理的特征构建分类模型,该方法的平均识别准确率达到91%. Ebrahimi等[4 ] 以温室草莓害虫的蓟马为研究对象,采用新的图像处理技术来检测草莓植株上可能存在的寄生虫,使用带有差分核函数的SVM对寄生虫进行分类并检测蓟马,分类结果的平均误差小于2.25%. 传统方法虽然在病虫害识别中能够实现较高的检测精度和识别准确率,但须手动提取特征和选择分类器,检测方法的性能和效率在大多数情况下弱于深度学习方法,并且存在通用性和可扩展性的问题. 相比于传统方法,深度学习方法不仅具有更快的检测速度和更高的准确率,而且处理复杂背景检测时的性能也更好. Wen等[5 ] 提出用于多类别密集和微小害虫的害虫检测器Pest-YOLO,通过在损失函数中引入焦点损失来提高硬样本的注意力,采用汇合策略最大程度地消除由微小密集害虫个体之间的遮挡、黏附和未标记造成的检测误差和遗漏. 实验结果比原YOLOv4[6 ] 在平均精度均值和召回率上分别提高了5.32%和28.12%. 王金星等[7 ] 提出基于改进Mask R-CNN[8 ] 的苹果园害虫识别方法,引入拥有CBAM[9 ] 注意力机制的ResNeXt[10 ] 模型以及Boundary损失函数,该方法具有模型体积小,检测速度快的优点. 王卫星等[11 ] 在荔枝病虫害检测中以YOLOv4为基础,使用轻量化网络GhostNet[12 ] 作为骨干网络,引入更低成本的卷积Ghost 模块并使用新特征融合方法和CBAM改进YOLOv4-G. ...
1
... 针对枸杞虫害检测的研究较少,主要为枸杞虫害的识别分类. 苏虹[13 ] 在MobileNet V2中嵌入挤压与激励(squeeze-and-excitation, SE)模块,实现特征通道的自适应校准,改进模型将枸杞病虫害图像分类识别精度提升了约2.46%. 不同于精准的目标检测,在面对图片中有多种虫害的情况时,枸杞虫害识别分类难以给出准确结果,实用性较差. 此外,枸杞虫害检测存在数据集和样本缺少、虫害目标区域定位难、目标特征缺失等问题. 在YOLO[14 ] 系列中相较于YOLOv4更新版本的YOLOv5[15 ] 是高效且准确的目标检测算法. 针对上述目标区域定位、特征缺失和小目标检测等问题,本研究提出NCF-YOLO(next contextual function YOLO)枸杞虫害检测模型. 本研究1)以YOLOv5m为基本模型并进行模型改进,使用下一代视觉转换器(next generation vision transformer,Next-ViT) [16 ] 作为骨干网络,通过增强模型对目标虫害区域的定位来提高模型的特征提取能力;2)将上下文增强模块(context augmentation module,CAM)添加到模型的颈部,以解决模型对密集小目标检测较差的问题,提高模型对枸杞虫害中小目标(蚜虫)的检测能力;3)基于轻量化模型FasterNet[17 ] 提出C3_Faster模块,替换模型颈部原有的C3模块,在减少模型占用量的同时提升检测精度. ...
1
... 针对枸杞虫害检测的研究较少,主要为枸杞虫害的识别分类. 苏虹[13 ] 在MobileNet V2中嵌入挤压与激励(squeeze-and-excitation, SE)模块,实现特征通道的自适应校准,改进模型将枸杞病虫害图像分类识别精度提升了约2.46%. 不同于精准的目标检测,在面对图片中有多种虫害的情况时,枸杞虫害识别分类难以给出准确结果,实用性较差. 此外,枸杞虫害检测存在数据集和样本缺少、虫害目标区域定位难、目标特征缺失等问题. 在YOLO[14 ] 系列中相较于YOLOv4更新版本的YOLOv5[15 ] 是高效且准确的目标检测算法. 针对上述目标区域定位、特征缺失和小目标检测等问题,本研究提出NCF-YOLO(next contextual function YOLO)枸杞虫害检测模型. 本研究1)以YOLOv5m为基本模型并进行模型改进,使用下一代视觉转换器(next generation vision transformer,Next-ViT) [16 ] 作为骨干网络,通过增强模型对目标虫害区域的定位来提高模型的特征提取能力;2)将上下文增强模块(context augmentation module,CAM)添加到模型的颈部,以解决模型对密集小目标检测较差的问题,提高模型对枸杞虫害中小目标(蚜虫)的检测能力;3)基于轻量化模型FasterNet[17 ] 提出C3_Faster模块,替换模型颈部原有的C3模块,在减少模型占用量的同时提升检测精度. ...
1
... 针对枸杞虫害检测的研究较少,主要为枸杞虫害的识别分类. 苏虹[13 ] 在MobileNet V2中嵌入挤压与激励(squeeze-and-excitation, SE)模块,实现特征通道的自适应校准,改进模型将枸杞病虫害图像分类识别精度提升了约2.46%. 不同于精准的目标检测,在面对图片中有多种虫害的情况时,枸杞虫害识别分类难以给出准确结果,实用性较差. 此外,枸杞虫害检测存在数据集和样本缺少、虫害目标区域定位难、目标特征缺失等问题. 在YOLO[14 ] 系列中相较于YOLOv4更新版本的YOLOv5[15 ] 是高效且准确的目标检测算法. 针对上述目标区域定位、特征缺失和小目标检测等问题,本研究提出NCF-YOLO(next contextual function YOLO)枸杞虫害检测模型. 本研究1)以YOLOv5m为基本模型并进行模型改进,使用下一代视觉转换器(next generation vision transformer,Next-ViT) [16 ] 作为骨干网络,通过增强模型对目标虫害区域的定位来提高模型的特征提取能力;2)将上下文增强模块(context augmentation module,CAM)添加到模型的颈部,以解决模型对密集小目标检测较差的问题,提高模型对枸杞虫害中小目标(蚜虫)的检测能力;3)基于轻量化模型FasterNet[17 ] 提出C3_Faster模块,替换模型颈部原有的C3模块,在减少模型占用量的同时提升检测精度. ...
1
... 针对枸杞虫害检测的研究较少,主要为枸杞虫害的识别分类. 苏虹[13 ] 在MobileNet V2中嵌入挤压与激励(squeeze-and-excitation, SE)模块,实现特征通道的自适应校准,改进模型将枸杞病虫害图像分类识别精度提升了约2.46%. 不同于精准的目标检测,在面对图片中有多种虫害的情况时,枸杞虫害识别分类难以给出准确结果,实用性较差. 此外,枸杞虫害检测存在数据集和样本缺少、虫害目标区域定位难、目标特征缺失等问题. 在YOLO[14 ] 系列中相较于YOLOv4更新版本的YOLOv5[15 ] 是高效且准确的目标检测算法. 针对上述目标区域定位、特征缺失和小目标检测等问题,本研究提出NCF-YOLO(next contextual function YOLO)枸杞虫害检测模型. 本研究1)以YOLOv5m为基本模型并进行模型改进,使用下一代视觉转换器(next generation vision transformer,Next-ViT) [16 ] 作为骨干网络,通过增强模型对目标虫害区域的定位来提高模型的特征提取能力;2)将上下文增强模块(context augmentation module,CAM)添加到模型的颈部,以解决模型对密集小目标检测较差的问题,提高模型对枸杞虫害中小目标(蚜虫)的检测能力;3)基于轻量化模型FasterNet[17 ] 提出C3_Faster模块,替换模型颈部原有的C3模块,在减少模型占用量的同时提升检测精度. ...
1
... 针对枸杞虫害检测的研究较少,主要为枸杞虫害的识别分类. 苏虹[13 ] 在MobileNet V2中嵌入挤压与激励(squeeze-and-excitation, SE)模块,实现特征通道的自适应校准,改进模型将枸杞病虫害图像分类识别精度提升了约2.46%. 不同于精准的目标检测,在面对图片中有多种虫害的情况时,枸杞虫害识别分类难以给出准确结果,实用性较差. 此外,枸杞虫害检测存在数据集和样本缺少、虫害目标区域定位难、目标特征缺失等问题. 在YOLO[14 ] 系列中相较于YOLOv4更新版本的YOLOv5[15 ] 是高效且准确的目标检测算法. 针对上述目标区域定位、特征缺失和小目标检测等问题,本研究提出NCF-YOLO(next contextual function YOLO)枸杞虫害检测模型. 本研究1)以YOLOv5m为基本模型并进行模型改进,使用下一代视觉转换器(next generation vision transformer,Next-ViT) [16 ] 作为骨干网络,通过增强模型对目标虫害区域的定位来提高模型的特征提取能力;2)将上下文增强模块(context augmentation module,CAM)添加到模型的颈部,以解决模型对密集小目标检测较差的问题,提高模型对枸杞虫害中小目标(蚜虫)的检测能力;3)基于轻量化模型FasterNet[17 ] 提出C3_Faster模块,替换模型颈部原有的C3模块,在减少模型占用量的同时提升检测精度. ...
1
... 针对枸杞虫害检测的研究较少,主要为枸杞虫害的识别分类. 苏虹[13 ] 在MobileNet V2中嵌入挤压与激励(squeeze-and-excitation, SE)模块,实现特征通道的自适应校准,改进模型将枸杞病虫害图像分类识别精度提升了约2.46%. 不同于精准的目标检测,在面对图片中有多种虫害的情况时,枸杞虫害识别分类难以给出准确结果,实用性较差. 此外,枸杞虫害检测存在数据集和样本缺少、虫害目标区域定位难、目标特征缺失等问题. 在YOLO[14 ] 系列中相较于YOLOv4更新版本的YOLOv5[15 ] 是高效且准确的目标检测算法. 针对上述目标区域定位、特征缺失和小目标检测等问题,本研究提出NCF-YOLO(next contextual function YOLO)枸杞虫害检测模型. 本研究1)以YOLOv5m为基本模型并进行模型改进,使用下一代视觉转换器(next generation vision transformer,Next-ViT) [16 ] 作为骨干网络,通过增强模型对目标虫害区域的定位来提高模型的特征提取能力;2)将上下文增强模块(context augmentation module,CAM)添加到模型的颈部,以解决模型对密集小目标检测较差的问题,提高模型对枸杞虫害中小目标(蚜虫)的检测能力;3)基于轻量化模型FasterNet[17 ] 提出C3_Faster模块,替换模型颈部原有的C3模块,在减少模型占用量的同时提升检测精度. ...
基于YOLOv3算法的教室学生检测与人数统计方法
1
2020
... YOLOv5是单阶段目标识别算法,算法的核心思想是将物体检测任务转化为分类与回归问题[18 ] ,通过单次前向传递即可同时完成目标检测和定位. YOLO系列算法以高速和准确度而闻名,YOLOv5建立在前几个版本的基础上,由于采用了新的技术和改进,检测性能得到提升(如改进的CSPNet骨干网络、多尺度检测、数据增强). YOLOv5网络主要由3个部分组成:骨干网络(backbone network)、颈部(neck)和检测. 骨干网络对经预处理的图像进行特征提取;颈部将低级特征与高级特征融合,以捕捉不同尺度的目标信息;检测层对输入的特征信息进行检测并生成边界框和预测类别. 本研究检测5类虫害,在综合考虑模型识别的准确率、效率及模型体积后,将YOLOv5m作为基础网络,网络结构如图2 所示. ...
基于YOLOv3算法的教室学生检测与人数统计方法
1
2020
... YOLOv5是单阶段目标识别算法,算法的核心思想是将物体检测任务转化为分类与回归问题[18 ] ,通过单次前向传递即可同时完成目标检测和定位. YOLO系列算法以高速和准确度而闻名,YOLOv5建立在前几个版本的基础上,由于采用了新的技术和改进,检测性能得到提升(如改进的CSPNet骨干网络、多尺度检测、数据增强). YOLOv5网络主要由3个部分组成:骨干网络(backbone network)、颈部(neck)和检测. 骨干网络对经预处理的图像进行特征提取;颈部将低级特征与高级特征融合,以捕捉不同尺度的目标信息;检测层对输入的特征信息进行检测并生成边界框和预测类别. 本研究检测5类虫害,在综合考虑模型识别的准确率、效率及模型体积后,将YOLOv5m作为基础网络,网络结构如图2 所示. ...
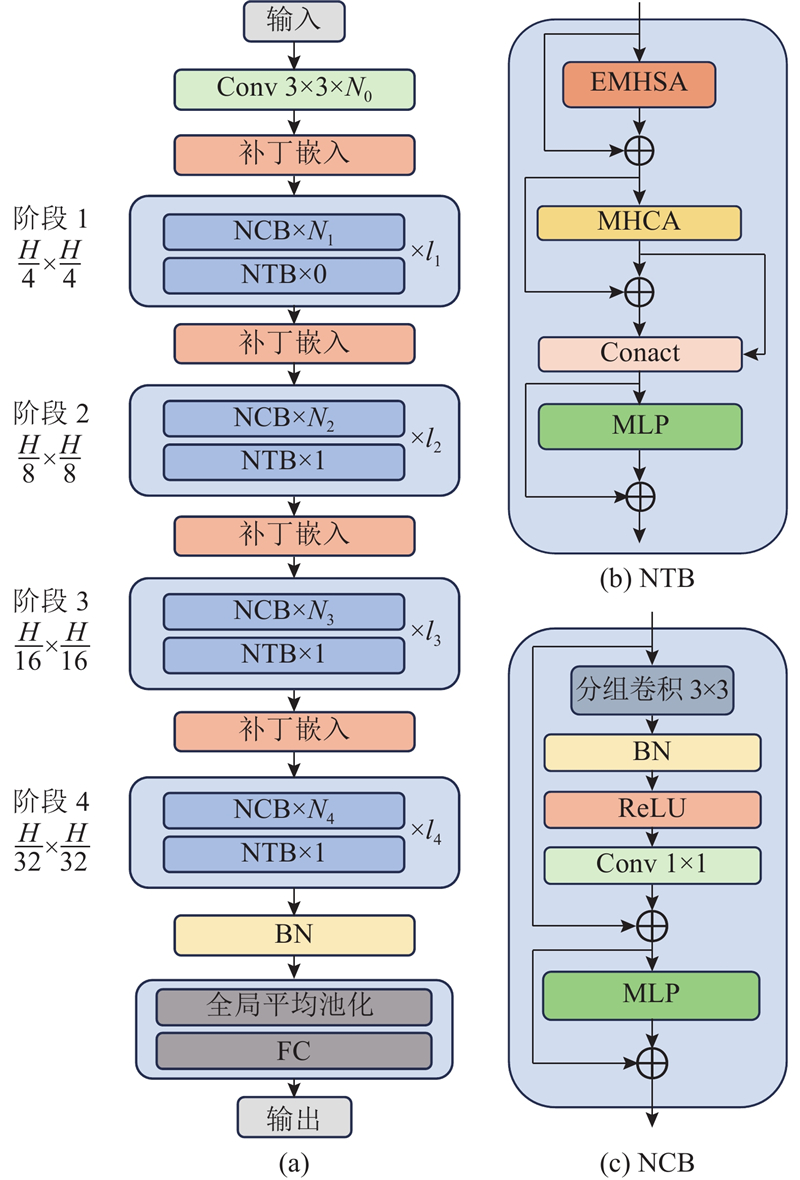
1
... 视觉转换器(vision transformer,ViT)[19 ] 的注意力机制和模型设计复杂,在现实的工业部署场景中执行效率不如卷积神经网络(convolutional neural networks, CNN). Next-ViT能够在现实工业场景中有效部署,它的性能可以媲美CNN 和 ViT. Next-ViT的特征定位和提取能力强,能够较好地克服枸杞虫害检测中的复杂环境影响和难以定位的问题,为此将Next-ViT作为YOLOv5m的骨干网络;采用迁移学习训练方式,使模型更快收敛并更好地适应数据,达到在准确率和召回率较为平衡的基础上提高检测精度的目的. 如图3 所示,Next-ViT为分层金字塔结构,每个阶段均使用补丁嵌入层和一系列卷积或转换块;空间分辨率将逐步降低32倍,通道尺寸将在不同阶段扩展;局部和全局信息的融合在下一转换块(next transformer block,NTB)中进行,以进一步增强建模能力;为了克服现有方法的固有缺陷,引入下一代混合策略,该策略堆叠下一卷积块(next convolution block,NCB)和NTB,以构建先进的CNN转换器混合架构. NCB将输入信息与经过组卷积、批归一化(batch normalization,BN)、ReLU激活函数、卷积处理的信息加和后输出,接着在优化的多层感知机(multilayer perceptron, MLP)中进行同样的操作后,将信息输出. NCB在保持瓶颈(bottleneck)块部署优势的同时获得转换块的突出性能, NCB遵循MetaFormer[20 ] 的一般架构: ...
1
... 视觉转换器(vision transformer,ViT)[19 ] 的注意力机制和模型设计复杂,在现实的工业部署场景中执行效率不如卷积神经网络(convolutional neural networks, CNN). Next-ViT能够在现实工业场景中有效部署,它的性能可以媲美CNN 和 ViT. Next-ViT的特征定位和提取能力强,能够较好地克服枸杞虫害检测中的复杂环境影响和难以定位的问题,为此将Next-ViT作为YOLOv5m的骨干网络;采用迁移学习训练方式,使模型更快收敛并更好地适应数据,达到在准确率和召回率较为平衡的基础上提高检测精度的目的. 如图3 所示,Next-ViT为分层金字塔结构,每个阶段均使用补丁嵌入层和一系列卷积或转换块;空间分辨率将逐步降低32倍,通道尺寸将在不同阶段扩展;局部和全局信息的融合在下一转换块(next transformer block,NTB)中进行,以进一步增强建模能力;为了克服现有方法的固有缺陷,引入下一代混合策略,该策略堆叠下一卷积块(next convolution block,NCB)和NTB,以构建先进的CNN转换器混合架构. NCB将输入信息与经过组卷积、批归一化(batch normalization,BN)、ReLU激活函数、卷积处理的信息加和后输出,接着在优化的多层感知机(multilayer perceptron, MLP)中进行同样的操作后,将信息输出. NCB在保持瓶颈(bottleneck)块部署优势的同时获得转换块的突出性能, NCB遵循MetaFormer[20 ] 的一般架构: ...
1
... 上下文增强模块是用于自然语言处理任务的技术,旨在改善模型对文本上下文的理解和推理能力. 上下文增强模块主要通过引入附加信息来增强模型对上下文的理解,使用不同的扩张卷积速率来获得不同感受野的上下文信息并丰富特征金字塔网络[21 ] 的上下文信息. 如图4 所示,为了获取不同感受野的特征,将CAM中的特征以1∶3∶5输入扩展卷积进行处理,之后通过融合这些特征来获取更丰富的语境信息. 采用不同的扩张卷积率进行卷积扩张,以获取不同感受野的背景信息. CAM能够有效地提高模型对周围环境的感知和理解. ...
1
... 深度学习网络模型的可解释性通常较差,本研究采用Grad-CAM[22 ] 生成热力图,以实现可视化的检测效果对比. 如图9 所示,相较于原始YOLOv5m模型,本研究所提模型可以准确地找到虫害的关键特征区域,例如尺蠖的中间皮肤纹理或者蚜虫和大青叶蝉的腹部. 所提模型除了在大青叶蝉的检测上会些许关注与害虫颜色相近的叶片纹理外,在其他4种虫害的识别上重点关注区域均为害虫本身. 由此可知,YOLOv5m的重点区域杂乱和对密集小目标(蚜虫)存在漏检的情况,所提模型在关注重点特征区域和小目标检测两方面的表现均优于YOLOv5m. ...
1
... 验证所提模型各模块的检测性能,结果如表2 所示. 表中,YOLOv5-P表示由PoolFormer替换骨干网络,载入权重为PoolFormer_s24;YOLOv5-E表示将YOLOv5的骨干网络替换为EfficientFormerV2[23 ] ,载入权重为EfficientFormerV2_s0;YOLOv5-N表示将Next-ViT作为骨干网络,采用迁移学习方式的NextViT-base预训练权重;YOLOv5-NC表示基于YOLOv5-N并在颈部增加CAM,使检测层获取更多的语义信息. 由表可知,相较于YOLOv5-PoolFormer和YOLOv5-E,Next-ViT在性能上表现更优,mAP50分别高1.5和3.2个百分点. 与YOLOv5m相比, YOLOv5-N不仅在2种虫害的检测平均精度上均有提升,在召回率和mAP50上都有较好的表现,mAP50提升了0.9个百分点. 在替换骨干网络的基础上添加CAM后,模型的mAP50有小幅的涨点,特别在针对小目标蚜虫上有较高的提升,相比于YOLOv5-N在蚜虫检测上提升了最高3.1个百分点. 所提模型的mAP50达到94.7%,比YOLOv5m的提高了1.9个百分点,在枸杞主要虫害的蚜虫上的检测平均精度提高了9.4个百分点,说明所提模型在枸杞虫害的检测方面具有更强的针对性与鲁棒性. ...
深度学习在植物叶部病害检测与识别的研究进展
1
2022
... 为了更直观地比较模型改进前后的检测效果,选取测试集中的蚜虫与负泥虫检测图像进行原始YOLOv5m和所提模型的虫害检测效果对比,结果如图10 所示. 可以看出,YOLOv5存在蚜虫漏检情况,该情况在使用所提模型后明显改善. 原因是YOLOv5对小目标的检测效果相对较差,所提模型引入CAM,提高了模型对环境的感知与理解,同时获取的不同感受野特征也丰富了特征金字塔网络的上下文信息. 挑选出的对负泥虫错检、漏检样例,如图11 所示. 可以看出,改进前后的模型在负泥虫检测上均存在漏检(无文字框均为漏检的害虫)、误检的情况,原因是复杂的自然环境和其他外部因素会严重影响模型的检测性能. 由图11 (a)、图11 (b)可以看出,2种模型都未检测出负泥虫且都误检出尺蠖. 周围环境复杂是造成这种情形的主要原因. 受光线的影响,有些害虫在植物表面不明显,或者害虫的形态与植物相似;光线和拍摄角度也会影响图像质量,导致虫害区域难以定位和识别[24 ] . 此外,模型内部因素也会影响检测性能. 由图11 (c)可知,YOLOv5m没有检测出负泥虫,所提模型检测出害虫却误检为毛田甲. 分析原因:1)这2类害虫的图像较为相似,模型检测出目标区域无法正确分配标签;2)构建数据集的数据有限,模型训练程度有待提高. ...
深度学习在植物叶部病害检测与识别的研究进展
1
2022
... 为了更直观地比较模型改进前后的检测效果,选取测试集中的蚜虫与负泥虫检测图像进行原始YOLOv5m和所提模型的虫害检测效果对比,结果如图10 所示. 可以看出,YOLOv5存在蚜虫漏检情况,该情况在使用所提模型后明显改善. 原因是YOLOv5对小目标的检测效果相对较差,所提模型引入CAM,提高了模型对环境的感知与理解,同时获取的不同感受野特征也丰富了特征金字塔网络的上下文信息. 挑选出的对负泥虫错检、漏检样例,如图11 所示. 可以看出,改进前后的模型在负泥虫检测上均存在漏检(无文字框均为漏检的害虫)、误检的情况,原因是复杂的自然环境和其他外部因素会严重影响模型的检测性能. 由图11 (a)、图11 (b)可以看出,2种模型都未检测出负泥虫且都误检出尺蠖. 周围环境复杂是造成这种情形的主要原因. 受光线的影响,有些害虫在植物表面不明显,或者害虫的形态与植物相似;光线和拍摄角度也会影响图像质量,导致虫害区域难以定位和识别[24 ] . 此外,模型内部因素也会影响检测性能. 由图11 (c)可知,YOLOv5m没有检测出负泥虫,所提模型检测出害虫却误检为毛田甲. 分析原因:1)这2类害虫的图像较为相似,模型检测出目标区域无法正确分配标签;2)构建数据集的数据有限,模型训练程度有待提高. ...
2
... 在相同条件下对比不同模型的检测性能,结果如表3 所示. 由表可知,所提模型取得了最高的平均精度均值,比YOLOv3[25 ] 、YOLOv7[26 ] 分别高4.4和1.6个百分点,比YOLOX[27 ] 高1.6个百分点;相较于DETR[28 ] 、EfficientDet-D1[29 ] 、Cascade R-CNN[30 ] ,所提模型的平均精度均值分别高了2.8、3.5和1.0个百分点. 由于在自然环境获取的枸杞虫害图像背景复杂,表现较好的Cascade R-CNN难以提取有效特征,检测的平均精度均值相比所提模型低, 并且模型大小占用量过大,不适于实际场景的应用. 虽然所提模型的检测表现优于对比模型,但模型占用量较YOLOv5m和EfficientDet-D1大,因此在所提模型的轻量化方面仍须进一步研究. ...
... Comparison of detection performance for different models
Tab.3 模型 mAP50/% M /MBYOLOv5m 92.8 42.20 YOLOv3[25 ] 90.3 123.50 YOLOv7[26 ] 93.1 74.80 YOLOX[27 ] 93.1 130.16 DETR[28 ] 91.9 186.20 EfficientDet-D1[29 ] 91.2 26.80 Cascade R-CNN[30 ] 93.7 527.20 NCF-YOLO 94.7 57.40
3. 结 语 为了解决复杂自然环境中的枸杞虫害检测问题,本研究提出新的枸杞虫害检测模型. 在枸杞害虫检测的平均精度均值方面,所提模型高于主流模型,特别是在检测枸杞的主要害虫蚜虫上,所提模型的检测平均精度远高于原始YOLOv5m;在模型的占用量方面,所提模型低于大多数主流模型. 在构建的枸杞虫害数据集中测试模型,结果显示所提模型的检测精度比大多数主流模型的高,模型大小在可接受范围. 结果表明,所提模型具有较高的实际应用价值,可为后续复杂自然场景下的枸杞虫害检测研究提供参考. 所提模型在复杂极端的环境背景和害虫特征相似情况下的检测性能有待改进. 后续研究计划:一方面增强数据集的多样性,引入注意力机制和更复杂的特征融合策略,让模型更好地适应复杂环境,关注重要特征并增强对不同尺度目标的检测能力;另一方面不断进行模型轻量化尝试,使模型满足实际应用需求. ...
2
... 在相同条件下对比不同模型的检测性能,结果如表3 所示. 由表可知,所提模型取得了最高的平均精度均值,比YOLOv3[25 ] 、YOLOv7[26 ] 分别高4.4和1.6个百分点,比YOLOX[27 ] 高1.6个百分点;相较于DETR[28 ] 、EfficientDet-D1[29 ] 、Cascade R-CNN[30 ] ,所提模型的平均精度均值分别高了2.8、3.5和1.0个百分点. 由于在自然环境获取的枸杞虫害图像背景复杂,表现较好的Cascade R-CNN难以提取有效特征,检测的平均精度均值相比所提模型低, 并且模型大小占用量过大,不适于实际场景的应用. 虽然所提模型的检测表现优于对比模型,但模型占用量较YOLOv5m和EfficientDet-D1大,因此在所提模型的轻量化方面仍须进一步研究. ...
... Comparison of detection performance for different models
Tab.3 模型 mAP50/% M /MBYOLOv5m 92.8 42.20 YOLOv3[25 ] 90.3 123.50 YOLOv7[26 ] 93.1 74.80 YOLOX[27 ] 93.1 130.16 DETR[28 ] 91.9 186.20 EfficientDet-D1[29 ] 91.2 26.80 Cascade R-CNN[30 ] 93.7 527.20 NCF-YOLO 94.7 57.40
3. 结 语 为了解决复杂自然环境中的枸杞虫害检测问题,本研究提出新的枸杞虫害检测模型. 在枸杞害虫检测的平均精度均值方面,所提模型高于主流模型,特别是在检测枸杞的主要害虫蚜虫上,所提模型的检测平均精度远高于原始YOLOv5m;在模型的占用量方面,所提模型低于大多数主流模型. 在构建的枸杞虫害数据集中测试模型,结果显示所提模型的检测精度比大多数主流模型的高,模型大小在可接受范围. 结果表明,所提模型具有较高的实际应用价值,可为后续复杂自然场景下的枸杞虫害检测研究提供参考. 所提模型在复杂极端的环境背景和害虫特征相似情况下的检测性能有待改进. 后续研究计划:一方面增强数据集的多样性,引入注意力机制和更复杂的特征融合策略,让模型更好地适应复杂环境,关注重要特征并增强对不同尺度目标的检测能力;另一方面不断进行模型轻量化尝试,使模型满足实际应用需求. ...
2
... 在相同条件下对比不同模型的检测性能,结果如表3 所示. 由表可知,所提模型取得了最高的平均精度均值,比YOLOv3[25 ] 、YOLOv7[26 ] 分别高4.4和1.6个百分点,比YOLOX[27 ] 高1.6个百分点;相较于DETR[28 ] 、EfficientDet-D1[29 ] 、Cascade R-CNN[30 ] ,所提模型的平均精度均值分别高了2.8、3.5和1.0个百分点. 由于在自然环境获取的枸杞虫害图像背景复杂,表现较好的Cascade R-CNN难以提取有效特征,检测的平均精度均值相比所提模型低, 并且模型大小占用量过大,不适于实际场景的应用. 虽然所提模型的检测表现优于对比模型,但模型占用量较YOLOv5m和EfficientDet-D1大,因此在所提模型的轻量化方面仍须进一步研究. ...
... Comparison of detection performance for different models
Tab.3 模型 mAP50/% M /MBYOLOv5m 92.8 42.20 YOLOv3[25 ] 90.3 123.50 YOLOv7[26 ] 93.1 74.80 YOLOX[27 ] 93.1 130.16 DETR[28 ] 91.9 186.20 EfficientDet-D1[29 ] 91.2 26.80 Cascade R-CNN[30 ] 93.7 527.20 NCF-YOLO 94.7 57.40
3. 结 语 为了解决复杂自然环境中的枸杞虫害检测问题,本研究提出新的枸杞虫害检测模型. 在枸杞害虫检测的平均精度均值方面,所提模型高于主流模型,特别是在检测枸杞的主要害虫蚜虫上,所提模型的检测平均精度远高于原始YOLOv5m;在模型的占用量方面,所提模型低于大多数主流模型. 在构建的枸杞虫害数据集中测试模型,结果显示所提模型的检测精度比大多数主流模型的高,模型大小在可接受范围. 结果表明,所提模型具有较高的实际应用价值,可为后续复杂自然场景下的枸杞虫害检测研究提供参考. 所提模型在复杂极端的环境背景和害虫特征相似情况下的检测性能有待改进. 后续研究计划:一方面增强数据集的多样性,引入注意力机制和更复杂的特征融合策略,让模型更好地适应复杂环境,关注重要特征并增强对不同尺度目标的检测能力;另一方面不断进行模型轻量化尝试,使模型满足实际应用需求. ...
2
... 在相同条件下对比不同模型的检测性能,结果如表3 所示. 由表可知,所提模型取得了最高的平均精度均值,比YOLOv3[25 ] 、YOLOv7[26 ] 分别高4.4和1.6个百分点,比YOLOX[27 ] 高1.6个百分点;相较于DETR[28 ] 、EfficientDet-D1[29 ] 、Cascade R-CNN[30 ] ,所提模型的平均精度均值分别高了2.8、3.5和1.0个百分点. 由于在自然环境获取的枸杞虫害图像背景复杂,表现较好的Cascade R-CNN难以提取有效特征,检测的平均精度均值相比所提模型低, 并且模型大小占用量过大,不适于实际场景的应用. 虽然所提模型的检测表现优于对比模型,但模型占用量较YOLOv5m和EfficientDet-D1大,因此在所提模型的轻量化方面仍须进一步研究. ...
... Comparison of detection performance for different models
Tab.3 模型 mAP50/% M /MBYOLOv5m 92.8 42.20 YOLOv3[25 ] 90.3 123.50 YOLOv7[26 ] 93.1 74.80 YOLOX[27 ] 93.1 130.16 DETR[28 ] 91.9 186.20 EfficientDet-D1[29 ] 91.2 26.80 Cascade R-CNN[30 ] 93.7 527.20 NCF-YOLO 94.7 57.40
3. 结 语 为了解决复杂自然环境中的枸杞虫害检测问题,本研究提出新的枸杞虫害检测模型. 在枸杞害虫检测的平均精度均值方面,所提模型高于主流模型,特别是在检测枸杞的主要害虫蚜虫上,所提模型的检测平均精度远高于原始YOLOv5m;在模型的占用量方面,所提模型低于大多数主流模型. 在构建的枸杞虫害数据集中测试模型,结果显示所提模型的检测精度比大多数主流模型的高,模型大小在可接受范围. 结果表明,所提模型具有较高的实际应用价值,可为后续复杂自然场景下的枸杞虫害检测研究提供参考. 所提模型在复杂极端的环境背景和害虫特征相似情况下的检测性能有待改进. 后续研究计划:一方面增强数据集的多样性,引入注意力机制和更复杂的特征融合策略,让模型更好地适应复杂环境,关注重要特征并增强对不同尺度目标的检测能力;另一方面不断进行模型轻量化尝试,使模型满足实际应用需求. ...
2
... 在相同条件下对比不同模型的检测性能,结果如表3 所示. 由表可知,所提模型取得了最高的平均精度均值,比YOLOv3[25 ] 、YOLOv7[26 ] 分别高4.4和1.6个百分点,比YOLOX[27 ] 高1.6个百分点;相较于DETR[28 ] 、EfficientDet-D1[29 ] 、Cascade R-CNN[30 ] ,所提模型的平均精度均值分别高了2.8、3.5和1.0个百分点. 由于在自然环境获取的枸杞虫害图像背景复杂,表现较好的Cascade R-CNN难以提取有效特征,检测的平均精度均值相比所提模型低, 并且模型大小占用量过大,不适于实际场景的应用. 虽然所提模型的检测表现优于对比模型,但模型占用量较YOLOv5m和EfficientDet-D1大,因此在所提模型的轻量化方面仍须进一步研究. ...
... Comparison of detection performance for different models
Tab.3 模型 mAP50/% M /MBYOLOv5m 92.8 42.20 YOLOv3[25 ] 90.3 123.50 YOLOv7[26 ] 93.1 74.80 YOLOX[27 ] 93.1 130.16 DETR[28 ] 91.9 186.20 EfficientDet-D1[29 ] 91.2 26.80 Cascade R-CNN[30 ] 93.7 527.20 NCF-YOLO 94.7 57.40
3. 结 语 为了解决复杂自然环境中的枸杞虫害检测问题,本研究提出新的枸杞虫害检测模型. 在枸杞害虫检测的平均精度均值方面,所提模型高于主流模型,特别是在检测枸杞的主要害虫蚜虫上,所提模型的检测平均精度远高于原始YOLOv5m;在模型的占用量方面,所提模型低于大多数主流模型. 在构建的枸杞虫害数据集中测试模型,结果显示所提模型的检测精度比大多数主流模型的高,模型大小在可接受范围. 结果表明,所提模型具有较高的实际应用价值,可为后续复杂自然场景下的枸杞虫害检测研究提供参考. 所提模型在复杂极端的环境背景和害虫特征相似情况下的检测性能有待改进. 后续研究计划:一方面增强数据集的多样性,引入注意力机制和更复杂的特征融合策略,让模型更好地适应复杂环境,关注重要特征并增强对不同尺度目标的检测能力;另一方面不断进行模型轻量化尝试,使模型满足实际应用需求. ...
2
... 在相同条件下对比不同模型的检测性能,结果如表3 所示. 由表可知,所提模型取得了最高的平均精度均值,比YOLOv3[25 ] 、YOLOv7[26 ] 分别高4.4和1.6个百分点,比YOLOX[27 ] 高1.6个百分点;相较于DETR[28 ] 、EfficientDet-D1[29 ] 、Cascade R-CNN[30 ] ,所提模型的平均精度均值分别高了2.8、3.5和1.0个百分点. 由于在自然环境获取的枸杞虫害图像背景复杂,表现较好的Cascade R-CNN难以提取有效特征,检测的平均精度均值相比所提模型低, 并且模型大小占用量过大,不适于实际场景的应用. 虽然所提模型的检测表现优于对比模型,但模型占用量较YOLOv5m和EfficientDet-D1大,因此在所提模型的轻量化方面仍须进一步研究. ...
... Comparison of detection performance for different models
Tab.3 模型 mAP50/% M /MBYOLOv5m 92.8 42.20 YOLOv3[25 ] 90.3 123.50 YOLOv7[26 ] 93.1 74.80 YOLOX[27 ] 93.1 130.16 DETR[28 ] 91.9 186.20 EfficientDet-D1[29 ] 91.2 26.80 Cascade R-CNN[30 ] 93.7 527.20 NCF-YOLO 94.7 57.40
3. 结 语 为了解决复杂自然环境中的枸杞虫害检测问题,本研究提出新的枸杞虫害检测模型. 在枸杞害虫检测的平均精度均值方面,所提模型高于主流模型,特别是在检测枸杞的主要害虫蚜虫上,所提模型的检测平均精度远高于原始YOLOv5m;在模型的占用量方面,所提模型低于大多数主流模型. 在构建的枸杞虫害数据集中测试模型,结果显示所提模型的检测精度比大多数主流模型的高,模型大小在可接受范围. 结果表明,所提模型具有较高的实际应用价值,可为后续复杂自然场景下的枸杞虫害检测研究提供参考. 所提模型在复杂极端的环境背景和害虫特征相似情况下的检测性能有待改进. 后续研究计划:一方面增强数据集的多样性,引入注意力机制和更复杂的特征融合策略,让模型更好地适应复杂环境,关注重要特征并增强对不同尺度目标的检测能力;另一方面不断进行模型轻量化尝试,使模型满足实际应用需求. ...













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}