[2]
刘侠 基于OpencCV中Mean Shift的图像卡通化处理
[J]. 信息与电脑: 理论版 , 2020 , 32 (20 ): 54 - 57
[本文引用: 1]
LIU Xia Image cartoon processing based on Mean Shift in OpencCV
[J]. Information and Computer: Theory Edition , 2020 , 32 (20 ): 54 - 57
[本文引用: 1]
[3]
CANNY J A computational approach to edge detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 1986 , PAMI-8 (6 ): 679 - 698
DOI:10.1109/TPAMI.1986.4767851
[本文引用: 4]
[4]
WU Z, ZHU Z, DU J, et al. CCPL: contrastive coherence preserving loss for versatile style transfer [C]// 17th European Conference on Computer Vision . Cham: Springer, 2022: 189-206.
[本文引用: 2]
[5]
ZHANG Y, TANG F, DONG W, et al. Domain enhanced arbitrary image style transfer via contrastive learning [C]// ACM SIGGRAPH 2022 Conference Proceedings . Vancouver: ACM, 2022: 1-8.
[本文引用: 2]
[6]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2223-2232.
[本文引用: 3]
[7]
CHEN Y, LAI Y K, LIU Y J. Cartoongan: generative adversarial networks for photo cartoonization [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 9465-9474.
[本文引用: 3]
[8]
PĘŚKO M, SVYSTUN A, ANDRUSZKIEWICZ P, et al Comixify: transform video into comics
[J]. Fundamenta Informaticae , 2019 , 168 (2-4 ): 311 - 333
DOI:10.3233/FI-2019-1834
[本文引用: 1]
[9]
WANG X, YU J. Learning to cartoonize using white-box cartoon representations [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 8090-8099.
[本文引用: 2]
[10]
LI R, WU C H, LIU S, et al SDP-GAN: saliency detail preservation generative adversarial networks for high perceptual quality style transfer
[J]. IEEE Transactions on Image Processing , 2020 , 30 : 374 - 385
[本文引用: 2]
[11]
CHEN J, LIU G, CHEN X. Animegan: a novel lightweight GAN for photo animation [C]// International Symposium on Intelligence Computation and Applications . Singapore: Springer, 2020: 242-256.
[本文引用: 3]
[12]
GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2414-2423.
[本文引用: 1]
[13]
SHU Y, YI R, XIA M, et al GAN-based multi-style photo cartoonization
[J]. IEEE Transactions on Visualization and Computer Graphics , 2021 , 28 (10 ): 3376 - 3390
[本文引用: 2]
[14]
DONG Y, TAN W, TAO D, et al cartoonLossGAN: learning surface and coloring of images for cartoonization
[J]. IEEE Transactions on Image Processing , 2021 , 31 : 485 - 498
[本文引用: 1]
[15]
GAO X, ZHANG Y, TIAN Y. Learning to incorporate texture saliency adaptive attention to image cartoonization [EB/OL]. (2022-08-02)[2023-06-01]. https://arxiv.org/abs/2208.01587.
[本文引用: 1]
[16]
KANG H, LEE S, CHUI C K Flow-based image abstraction
[J]. IEEE Transactions on Visualization and Computer Graphics , 2008 , 15 (1 ): 62 - 76
[本文引用: 2]
[17]
WINNEMOELLER H, KYPRIANIDIS J E, OLSEN S C XDoG: an extended difference-of-Gaussians compendium including advanced image stylization
[J]. Computers and Graphics , 2012 , 36 (6 ): 740 - 753
DOI:10.1016/j.cag.2012.03.004
[本文引用: 2]
[19]
SÝKORA D, BURIÁNEK J, ŽÁRA J. Sketching cartoons by example [C]// Proceedings of Eurographics Workshop on Sketch Based Interfaces and Modeling . Schoten: Eurographics Association, 2005: 27-33.
[本文引用: 1]
[20]
ZHANG S H, CHEN T, ZHANG Y F, et al Vectorizing cartoon animations
[J]. IEEE Transactions on Visualization and Computer Graphics , 2009 , 15 (4 ): 618 - 629
DOI:10.1109/TVCG.2009.9
[本文引用: 1]
[21]
LIU X, MAO X, YANG X, et al Stereoscopizing cel animations
[J]. ACM Transactions on Graphics , 2013 , 32 (6 ): 1 - 10
[本文引用: 1]
[22]
LI C, LIU X, WONG T T Deep extraction of manga structural lines
[J]. ACM Transactions on Graphics , 2017 , 36 (4 ): 1 - 12
[本文引用: 1]
[23]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Elsevier, 2018: 3-19.
[本文引用: 1]
[24]
RUSSAKOVSKY O, DENG J, SU H, et al Imagenet large scale visual recognition challenge
[J]. International Journal of Computer Vision , 2015 , 115 (3 ): 211 - 252
DOI:10.1007/s11263-015-0816-y
[本文引用: 1]
[25]
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2014-09-04)[2023-06-01]. https://arxiv.org/abs/1409.1556.
[本文引用: 1]
[26]
MAO X, LI Q, XIE H, et al. Least squares generative adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2794-2802.
[本文引用: 1]
[27]
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 30.
[本文引用: 1]
[28]
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2818-2826.
[本文引用: 1]
[29]
CHATTOPADHAY A, SARKAR A, HOWLADER P, et al. Grad-CAM++: generalized gradient-based visual explanations for deep convolutional networks [C]// IEEE Winter Conference on Applications of Computer Vision . Nevada: IEEE, 2018: 839-847.
[本文引用: 1]
基于Mean Shift和FDoG的图像卡通化渲染
1
2016
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
基于Mean Shift和FDoG的图像卡通化渲染
1
2016
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
基于OpencCV中Mean Shift的图像卡通化处理
1
2020
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
基于OpencCV中Mean Shift的图像卡通化处理
1
2020
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
A computational approach to edge detection
4
1986
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
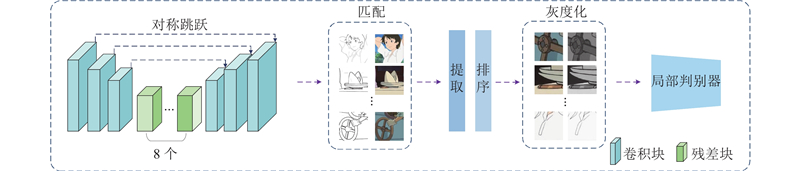
... 目前,关于风格化的边缘处理常采用边缘检测方法,提出了许多边缘检测器[3 ,16 -17 ] ,例如Canny[3 ] 边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
... [3 ]边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
... [3 ]边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
2
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
2
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
3
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
... 训练数据包含真实世界的图像和卡通图像,测试数据只包括真实世界的图像. 所有的训练图像都被调整为256×256大小. 源域包含5568张训练图像和792张定量测试图像,它是从文献[6 ]的训练和定量测试集中选取的. 针对目标域训练数据,使用Makoto Shinkai、Mamoru Hosoda和Hayao 3个不同风格的卡通数据集. 由于不同的创作者有独特的创作风格,为了得到同种风格的一系列图片,从风格相同的电影中截取关键帧,得到4725、4099和4370个卡通图像,分别用于训练Makoto Shinkai、Mamoru Hosoda和Hayao风格模型. ...
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
3
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
... 由于GAN网络使用未配对的数据进行端到端训练,具有随机初始化和高度非线性的特点,出现优化陷入次优局部最小值的问题. Chen等[7 ] 提出生成器的预训练有助于加速GAN收敛,因此预训练10个轮次后,通过100个轮次训练模型,交替最小化损失,以优化生成器部分和判别器部分,学习率为$ 2 \times {10^{ - 4}} $ . 在该阶段,设置各损失的权重为$ w_{\text{adv}} $ $ w_{\text{con}} $ $ w_{\text{col}} $ $ \beta_1 $ $ \beta_2 $ $ n $
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
Comixify: transform video into comics
1
2019
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
2
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
SDP-GAN: saliency detail preservation generative adversarial networks for high perceptual quality style transfer
2
2020
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
3
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
... 为了使图像的颜色重建效果更好,采用文献[11 ]的颜色重建损失$ L_{\text{col}}\left(G,D\right) $ $ L_1 $ Y 通道,Huber损失被用于U 和V 通道,如下所示: ...
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
1
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
GAN-based multi-style photo cartoonization
2
2021
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
cartoonLossGAN: learning surface and coloring of images for cartoonization
1
2021
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
1
... 风格迁移是将一张图片渲染为特定风格或特征的新图像的过程. 图像卡通化是风格迁移的一个方面,旨在从真实世界的照片中生成具有清晰边缘、平滑着色和相对简单纹理的卡通图像. 梅洪等[1 ] 提出基于Mean Shift和FDoG的图像卡通化渲染技术. 利用Mean Shift对图像进行分割,对分割出的区域进行进一步处理,通过FDoG来提取连贯的图像边界,结合获得的2个结果并进行亮度量化. 最终结果的色彩不够明亮鲜艳,且分割出的区域不符合人类视觉特性. 刘侠[2 ] 采用Mean Shift进行彩色图像分割,再使用Canny[3 ] 算法提取原图边界轮廓,将分割图像与边界图像进行合并,得到新的图像,最后调整对比度形成色彩鲜明的卡通风格图像. 最终的卡通化效果不明显. Wu等[4 ] 提出适用于局部补丁的对比一致性保持损失和简单协方差变换,有效地将内容特征的二阶统计量和风格特征对齐,更好地融合内容和风格特征. Zhang等[5 ] 提出的框架由3个关键部分组成,即用于风格编码的多层投影仪、用于有效学习风格分布的领域增强模块以及用于图像风格转移的生成网络,实现任意图像风格化. 以上这2种方法不适合卡通图像的生成. 随着GAN的提出,研究者们提出很多基于GAN架构的图像转换方法. Zhu等[6 ] 提出的CycleGAN是第一个不需要配对数据集就可以进行风格转换的GAN网络,它使用循环一致性损失来保证生成器的输出和原图内容之间的相似性,但输出图不具有明显的卡通效果. Chen等[7 ] 提出第一个为图像卡通化设计的网络CartoonGAN,其中设计了新颖的边缘对抗性损失来引导生成器生成清晰的边缘,但卡通化效果不明显,生成的边缘和轮廓仍有不足. Pęśko等[8 ] 在CartoonGAN上进行改进,解决了CartoonGAN中边线不够清晰和颜色不自然的问题,但生成的图像中会存在过度风格化的区域,令原始照片内容有损. Wang等[9 ] 提出3种白盒卡通化的特征表示法:外观特征、结构特征及纹理特征,通过调整三者的权重,可以平衡最终生成的效果. Li等[10 ] 引入显著性网络,它与生成器同时进行训练,该方法保留了重要显著区域的细节,提高了整体图像的感知质量,但在风格化过程中会丢失部分颜色和内容. Chen等[11 ] 将风格纹理Gram[12 ] 损失转移到GAN框架,提出3种提高视觉效果的损失,分别是灰度风格损失、颜色重建损失和灰度对抗性损失,以此来学习卡通纹理特征,但在纹理转移的过程中丢失了部分内容,生成的图像会存在局部模糊和伪影. Shu等[13 ] 提出MS-CartoonGAN,它由一个公用编码器、多个解码器和多个判别器组成,其中多个判别器与多个解码器一一对应,用于判断输入图像是真实的还是生成的卡通图像;增加辅助分类器,帮助网络更好地学习到不同风格之间的区别,实现了不同风格的图像卡通化,但生成的图像部分区域偏暗,颜色丢失. Dong等[14 ] 通过重用判别器的编码器部分建立紧凑的生成式对抗网络,提出新的卡通损失函数和初始化策略,提高了生成图像的质量. Gao等[15 ] 采用单独的局部区域对抗学习分支,实现更好的边缘效果. 虽然边缘检测和滤波操作对边缘处理具有实质性的作用,但生成的图像含有大量的冗余线条,使得视觉效果杂乱. ...
Flow-based image abstraction
2
2008
... 目前,关于风格化的边缘处理常采用边缘检测方法,提出了许多边缘检测器[3 ,16 -17 ] ,例如Canny[3 ] 边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
... [16 ]. Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
XDoG: an extended difference-of-Gaussians compendium including advanced image stylization
2
2012
... 目前,关于风格化的边缘处理常采用边缘检测方法,提出了许多边缘检测器[3 ,16 -17 ] ,例如Canny[3 ] 边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
... [17 ]提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
Segmentation of black and white cartoons
1
2005
... 目前,关于风格化的边缘处理常采用边缘检测方法,提出了许多边缘检测器[3 ,16 -17 ] ,例如Canny[3 ] 边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
1
... 目前,关于风格化的边缘处理常采用边缘检测方法,提出了许多边缘检测器[3 ,16 -17 ] ,例如Canny[3 ] 边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
Vectorizing cartoon animations
1
2009
... 目前,关于风格化的边缘处理常采用边缘检测方法,提出了许多边缘检测器[3 ,16 -17 ] ,例如Canny[3 ] 边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
Stereoscopizing cel animations
1
2013
... 目前,关于风格化的边缘处理常采用边缘检测方法,提出了许多边缘检测器[3 ,16 -17 ] ,例如Canny[3 ] 边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
Deep extraction of manga structural lines
1
2017
... 目前,关于风格化的边缘处理常采用边缘检测方法,提出了许多边缘检测器[3 ,16 -17 ] ,例如Canny[3 ] 边缘检测器和基于流的高斯差分[16 ] . Winnemoeller等[17 ] 提出的XDoG通过差分滤波可以得到更深刻的边缘线条,但很容易与高对比度的屏幕图案混淆. Sykora等[18 -19 ] 假定卡通图像中的装饰线都是颜色较深的实线,采用高斯拉普拉斯算子(LoG)提取闭合轮廓的方法定位线条,实现卡通图像矢量化. 它对卡通线条的假设前提过于严格,使得该方法无法区分边缘与装饰线,在应用于现代卡通图像时,将直接导致2个问题:对卡通图像线条的漏取和误取. Zhang等[20 ] 提出将Canny[3 ] 边缘检测器和Steger的链接算法合并,检测卡通动画中的装饰线. Liu等[21 ] 提出通过利用自适应直方图均衡和中值滤波来提取边缘. Li等[22 ] 提出新的数据驱动方法来识别卡通图像中的结构线,输出清晰、流畅的结构线. 卡通图像通常使用结构线来突出基本几何形状和关键特征,将物体的主要部分和关键特征串联在一起,使卡通图像更具易读性和可理解性,为后续的色彩和纹理表现提供指导和参考. 本文采用结构线提取的方法来优化边缘,实现图像卡通化. ...
1
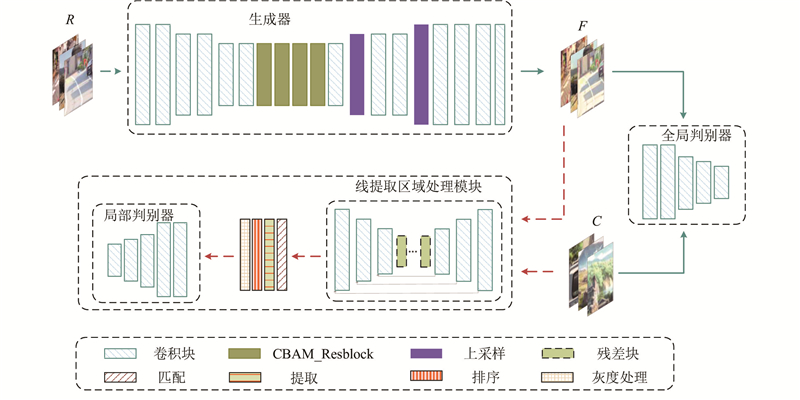
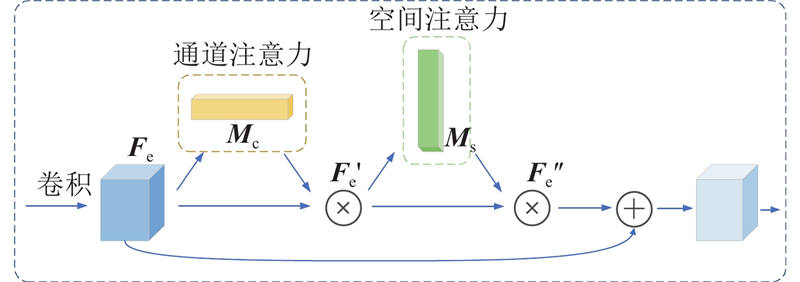
... 由于风格化的结果没有显式地捕捉区域之间的差异,没有突出图像中的重要特征信息,受文献[23 ]的启发,注意力机制CBAM是轻量的通用模块,可以将该模块融入各种卷积神经网络中进行端到端的训练. 其中通道注意力用来聚焦图像中有意义的特征,通过对输入特征的空间维度进行压缩,有效地计算通道注意力. 空间注意力用来聚焦最具信息量的部分,该空间注意图编码了模型所需要关注或抑制的特定位置信息,这是对通道注意力的补充. ...
Imagenet large scale visual recognition challenge
1
2015
... 在该架构中,为了保证输入图像和卡通化结果之间的内容一致性,采用Russakovsky等[24 ] 预先训练的VGG19[25 ] 作为感知网络,提取图像的高级语义特征. 内容损失为输入图像和生成图像的$ L_1 $
1
... 在该架构中,为了保证输入图像和卡通化结果之间的内容一致性,采用Russakovsky等[24 ] 预先训练的VGG19[25 ] 作为感知网络,提取图像的高级语义特征. 内容损失为输入图像和生成图像的$ L_1 $
1
... 全局判别器$ D_{\text{global}} $ $ L_{\text{global}}\left(G,D_{\text{global}}\right) $ [26 ] 的最小二乘损失,提高生成图像的质量和训练过程中的稳定性. 全局对抗性损失如下: ...
1
... 将本研究与先前的几种风格化工作进行比较,包括CycleGAN[6 ] 、CartoonGAN[7 ] 、SDP-GAN[10 ] 、White-box[9 ] 、AnimeGANv2[11 ] 、MS-CartoonGAN[13 ] 、CCPL[4 ] 及CAST[5 ] . 在定性实验中,给出9种不同方法的生成图像及比较分析. 在定量实验中,使用Fréchet Inception distance(FID)[27 ] 计算源图像分布和目标图像分布之间的距离来评估性能. 在消融实验中,分别对损失函数和各组件进行实验对比及分析,验证本文方法的有效性. ...
1
... 定量指标FID为真实样本和生成样本在特征空间上的距离. 利用Inception-v3[28 ] 网络来提取特征,使用高斯模型对特征空间进行建模,求解2个特征之间的距离. 利用这个距离来衡量真实图像和生成图像的相似程度,FID越小,则相似程度越高,即生成的图像更接近真实图像. ...
1
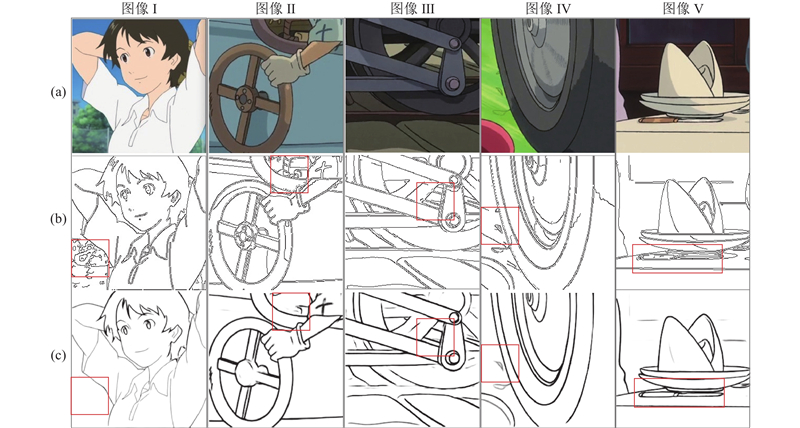
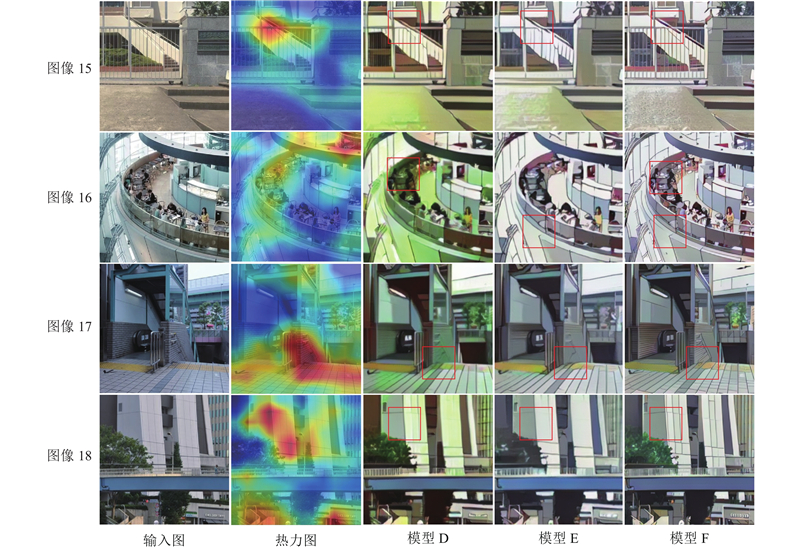
... 图9 中的模型D、模型E及模型F分别对应没有注意力模块、Canny线条提取及整个模型的结果. 为了证明注意力模块的有效性,开展消融实验. 从Chattopadhay[29 ] 得到的注意力图可知,模型D的图像16中的人群、图像17的阶梯处及图像18的建筑都存在一定程度的细节丢失,颜色与输入图颜色相差较大,没有明显的风格化效果. 模型E和模型F比较了Canny和结构线提取对图像卡通化的作用. 结构线可以看作是卡通图像中的“骨架”,能够帮助实现更好的图像卡通化. 模型E中的线条表达较差,模型F的线条及整体风格化效果更好. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}