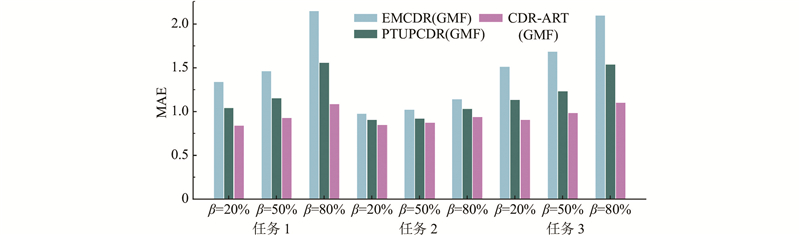
A cross-domain recommendation model that utilizes source domain data augmentation and multi-interest refinement transfer was proposed in order to address the issues of difficulty in modeling interest preferences in cross-domain recommendation tasks caused by the lack of user interaction data in the source domain, as well as the problem of ignored associations between multiple interests. A source-domain data augmentation strategy was introduced, generating a denoised auxiliary sequence for each user in the source domain. Then the sparsity of user interaction data in the source domain was alleviated, and enriched user interest preferences were obtained. The interest extraction and multi-interest refinement transfer were implemented by utilizing the dual sequence multi-interest extraction module and the multi-interest refinement transfer module. Three publicly cross-domain recommendation evaluation tasks were conducted. The proposed model achieved the best performance compared with the best baseline, reducing the average MAE by 22.86% and the average RMSE by 19.65%, which verified the effectiveness of the method.
Keywords:cold-start problem
;
cross-domain recommendation
;
data augmentation
;
multi-interest extraction
;
multi-interest refinement transfer
YIN Yabo, ZHU Xiaofei, LIU Yidan. Cross-domain recommendation model based on source domain data augmentation and multi-interest refinement transfer. Journal of Zhejiang University(Engineering Science)[J], 2024, 58(8): 1717-1727 doi:10.3785/j.issn.1008-973X.2024.08.018
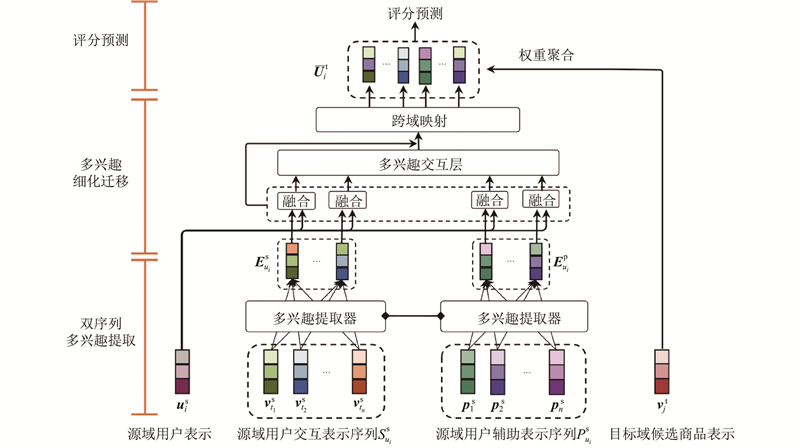
针对之前工作中存在的问题,本文提出源域数据增强与多兴趣细化迁移的跨域推荐模型(cross-domain recommendation model based on source domain data augmentation and multi-interest refinement transfer,CDR-ART)来解决上述问题. 针对源域中用户交互数据稀疏的问题,本文提出应用于跨域推荐场景的源域数据增强策略,通过为用户生成额外的辅助序列,显式地挖掘用户的潜在兴趣. 对于用户存在的多个相互关联的兴趣,本文使用双序列多兴趣提取模块和多兴趣细化迁移模块,实现提取多个兴趣与进行用户表示的多兴趣细化迁移. 最终在3个公开跨域推荐评测任务中,CDR-ART的性能优于现存的基线模型,证明了本文提出方法的有效性。
1. 相关工作
1.1. 跨域推荐
近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移.
从表4可以看出,当$ M $从2增加到10时,使3个任务的MAE指标最优的$ M $分别为10、6和2. 3个任务的RMSE指标最优的$ M $分别设置为4、4和8. 总体来说,当$ M $较小时往往不能对用户的多个兴趣进行充分地建模,但$ M $被设置得过大时可能会引入更多的噪音参数,对模型的性能造成损害. 超参数$ M $的设置应随着任务不同而进行动态地调整.
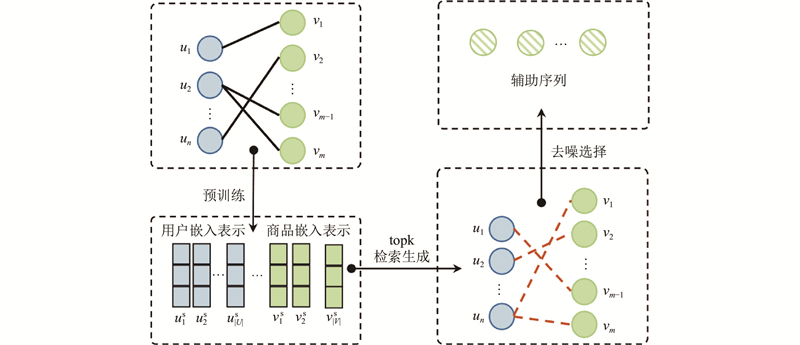
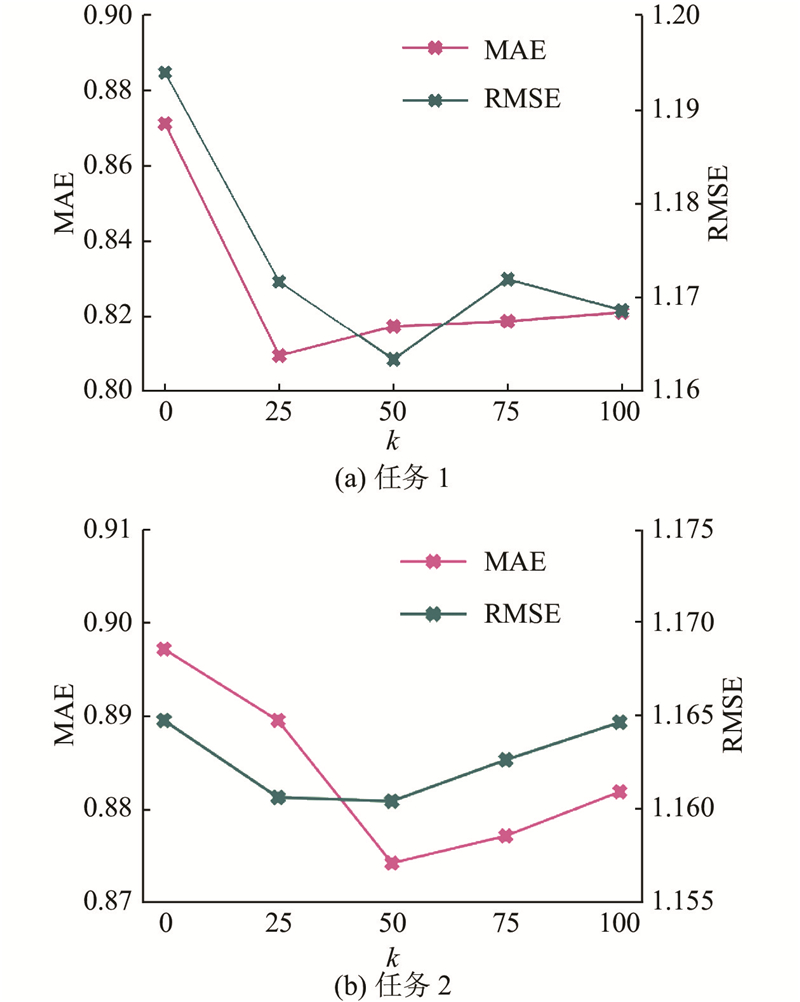
此外,$ k $的大小控制为每个用户从源域中检索的潜在交互商品的数量. 为了探究$ k $对模型性能的影响,当$ \beta = 20 {\text{%}} $,$ M $=6时探索CDR-ART的性能随$ k $调整所产生的变化. 实验结果如图3所示.
Fig.3
Influence of number of potential interactive item on performance
从图3可知,与不引入辅助交互商品序列($ k $ = 0)相比,通过引入潜在交互商品序列,可以有效地提升模型的性能. 当$ k $较小时,过少的潜在交互商品无法有效地丰富用户在源域中的兴趣偏好,带来次优的结果. 尽管通过引入去噪选择模块可以有效地缓解辅助序列中的噪音问题,但当$ k $过大时,过多的潜在交互商品数量可能引入额外噪音,影响模型的性能. 选择合适的$ k $可以提高模型性能. 在本文的实验场景中,$ k $设置为25或50,表现相对较好. 为了简化参数的设置,在本文的其他实验中,$ k $被固定为50.
HE X, LIAO L, ZHANG H, et al. Neural collaborative filtering [C]// Proceedings of the 26th International Conference on World Wide Web . Perth: ACM, 2017: 173-182.
FU W, PENG Z, WANG S, et al. Deeply fusing reviews and contents for cold start users in cross-domain recommendation systems [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu: AAAI, 2019: 94-101.
MAN T, SHEN H, JIN X, et al. Cross-domain recommendation: an embedding and mapping approach [C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne: Morgan Kaufmann, 2017: 2464-2470.
KANG S K, HWANG J, LEE D, et al. Semi-supervised learning for cross-domain recommendation to cold-start users [C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing: ACM, 2019: 1563-1572.
ZHU F, WANG Y, CHEN C, et al. A deep framework for cross-domain and cross-system recommendations [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: Morgan Kaufmann, 2018: 3662-4402.
ZHU Y, TANG Z, LIU Y, et al. Personalized transfer of user preferences for cross-domain recommendation [C]// Proceedings of the 15th ACM International Conference on Web Search and Data Mining. [S. l. ]: ACM, 2022: 1507-1515.
SINGH A P, GORDON G J. Relational learning via collective matrix factorization [C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas: ACM, 2008: 650-658.
PAN W, XIANG E, LIU N, et al. Transfer learning in collaborative filtering for sparsity reduction [C]// Proceedings of the AAAI conference on artificial intelligence. Atlanta: AAAI, 2010: 230-235.
CAO J, CONG X, LIU T, et al. Item similarity mining for multi-market recommendation [C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. Madrid: ACM, 2022: 2249-2254.
LI P, TUZHILIN A. Ddtcdr: deep dual transfer cross domain recommendation [C]// Proceedings of the 13th International Conference on Web Search and Data Mining. Houston: ACM, 2020: 331-339.
ZHAO C, ZHAO H, HE M, et al. Cross-domain recommendation via user interest alignment [C]// Proceedings of the ACM Web Conference. Austin: ACM, 2023: 887-896.
XIE R, LIU Q, WANG L, et al. Contrastive cross-domain recommendation in matching [C]// Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Washington: ACM, 2022: 4226-4236.
CAO J, LIN X, CONG X, et al. Disencdr: learning disentangled representations for cross-domain recommendation [C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. Madrid: ACM, 2022: 267-277.
LI C, XIE Y, YU C, et al. One for all, all for one: learning and transferring user embeddings for cross-domain recommendation [C]// Proceedings of the 16th ACM International Conference on Web Search and Data Mining. Singapore: ACM, 2023: 366-374.
LI C, LIU Z, WU M, et al. Multi-interest network with dynamic routing for recommendation at Tmall [C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing: ACM, 2019: 2615-2623.
SABOUR S, FROSST N, HINTON G E. Dynamic routing between capsules [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Long Beach: Curran Associates, 2017: 3859–3869.
CEN Y, ZHANG J, ZOU X, et al. Controllable multi-interest framework for recommendation [C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S. l. ]: ACM, 2020: 2942-2951.
CHAI Z, CHEN Z, LI C, et al. User-aware multi-interest learning for candidate matching in recommenders [C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. Madrid: ACM, 2022: 1326-1335.
LI J, ZHU J, BI Q, et al. MINER: multi-interest matching network for news recommendation [C]// Findings of the Association for Computational Linguistics. Dublin: ACL, 2022: 343-352.
WANG H, ZHANG F, XIE X, et al. DKN: deep knowledge-aware network for news recommendation [C]// Proceedings of the 2018 World Wide Web Conference. Lyon: ACM, 2018: 1835-1844.
FAN Z, XU K, ZHANG D, et al. Graph collaborative signals denoising and augmentation for recommendation [C]// Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. Taipei: ACM, 2023: 2037-2041.
WANG C, WANG Z, LIU Y, et al. Target interest distillation for multi-interest recommendation [C]// Proceedings of the 31st ACM International Conference on Information and Knowledge Management. Atlanta: ACM, 2022: 2007-2016.
WANG F, WANG Y, LI D, et al. Enhancing CTR prediction with context-aware feature representation learning [C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. Madrid: ACM, 2022: 343-352.
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...
1
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...
1
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...
1
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...
1
... 近年来,越来越多的研究人员关注跨域推荐研究. Singh等[10]提出通过建模跨领域的全局用户嵌入表示来解决目标域中用户的冷启动问题. Pan等[11]提出的整合迁移学习的协同过滤(transfer learning in collaborative filtering,CST)通过使用源域中用户的嵌入表示作为目标域用户嵌入表示的初始表征,并进行微调,提高目标域中对用户推荐的准确性. 在Man等[6]的工作中指出,通过2个域中的共享用户来学习用户嵌入表示的映射函数,能够有效地实现跨域知识迁移. Zhu等[8]提出在学习映射函数的同时,可以通过考虑不同领域中用户交互的稀疏程度来指导训练过程. Cao等[12]通过探索不同领域中相似的商品,从商品的角度来解决跨域推荐问题. 在Li等[13]提出的深度双向迁移的跨域推荐(deep dual transfer cross domain recommendation,DDTCDR)中指出之前的工作没有考虑用户和商品的双向潜在关系,提出双元学习策略,实现了领域与领域之间的对偶迁移. 在Zhu等[9]提出的用户偏好个性化迁移的跨域推荐(personalized transfer of user preferences for cross-domain recommendation,PTUPCDR)工作中,对源域中的用户交互序列进行个性化偏好的提取,并使用元网络将用户兴趣偏好从源域迁移到目标域,实现了个性化的跨域推荐. 在自监督信号挖掘及利用上,Zhao等[14]通过引入自监督学习来挖掘跨领域的用户对商品的兴趣不变性,实现跨域场景下用户兴趣对齐. Xie等[15]提出对比跨域推荐模型(contrastive cross-domain recommendation,CCDR),通过引入对比学习,更好地实现表征学习及跨域迁移. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}