

在复杂背景中快速准确地识别出输电线是实现无人机智能巡检的重要前提. 目前输电线识别主要有常规图像处理和基于深度学习的智能图像处理2种方法. 在常规图像处理方面,张从新等[3]通过形态学处理和Hough变换提取输电线,检测精度受背景噪声影响大. 赵乐等[4]采用Ratio算子检测输电线边缘,利用Hough变换提取输电线,识别精度高,但须根据背景设定检测阈值,适应性差. 周封等[5]结合RGB、灰度值和亮度值将图像分为6类,采用不同滤波器对图像进行预处理,通过Hough变换提取输电线. Li等[6]利用Sobel边缘检测和Hough变换提取输电线. Zhao等[7]基于Markov随机场区分输电线段与其他线段,采用分段拟合提取输电线.
常规图像处理输电线识别易受背景干扰,导致错检或漏检,识别精度低. 近年来,深度学习技术发展迅速,许多学者采用基于深度学习的智能图像处理方法识别输电线[8-9]. 许刚等[10]通过改进UNet分割输电线,采用自适应阈值提高网络鲁棒性. 黄巨挺等[11]构建U型编解码网络,编码器采用最大池化下采样,保存池化索引,解码器基于池化索引上采样,输电线识别速度快,但识别精度易受背景影响,泛化能力较差. 李运堂等[12]基于MobileNetV3构建编解码网络,复杂背景下输电线识别效果较好. Jaffari等[13]以UNet为基础,优化损失函数并添加辅助分类器,提高输电线识别精度,但背景复杂时易出现输电线漏检和误检. Li等[14]改进全卷积网络识别输电线,采用跳跃链接融合深、浅层特征提高识别精度. Yang等[15]在构建的编码解码网络中嵌入注意力机制,提高输电线识别精度.
随着“西电东送”工程的持续推进,多根线、长距离和多转向等复杂输电线路普遍存在. 现有常规图像处理和基于深度学习的智能图像处理大多以3根、平行和无转向的简单输电线为识别对象,应用于多根、交叉和有转向的复杂输电线识别时精度低,无法满足无人机智能巡检的实际需求. 因此,本研究构建新型编码解码网络实现复杂输电线的高精度高速度识别. 编码器采用改进MobileNetV3进行特征提取,高效利用计算资源. 解码器通过金字塔池化模块(pyramid pooling module, PPM)聚合不同区域的上下文信息. 编码器与解码器之间添加带有锐化块的跳跃链接,增强输电线边缘与背景对比度,加强输电线边缘特征提取. 引入混合损失函数解决图像中输电线像素少、背景像素多的类别不平衡问题. 利用迁移学习加快网络参数收敛,提高训练速度. 实验结果表明,相对于主流语义分割网络和其他输电线识别网络,新型编码解码网络分割精度更高,速度更快.
1. 新型编码解码网络
输电线在图像中像素数占比少,易受背景噪声干扰,识别难度大[13]. U2Net和PSPNet主流语义分割网络识别速度慢,常规MobileNetV3结构简单,识别速度较快,但精度低. 为了提高识别精度与速度,构建新型编码解码网络.
1.1. 整体结构
如图1所示,新型编码解码网络包括特征提取的编码器和特征恢复的解码器,通过带有锐化块(Sharp Block-A和Sharp Block-B)的跳跃链接将编码器第2、4、7、11和13层特征信息传递至解码器,加强复杂输电线的边缘特征提取,提高识别精度.
图 1
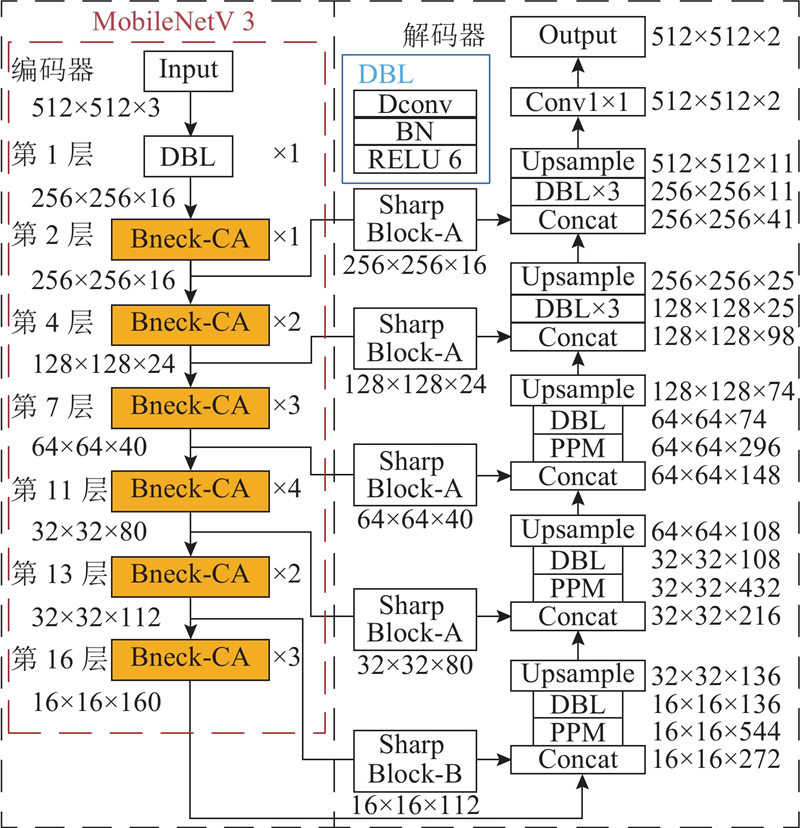
1.2. 编码器结构
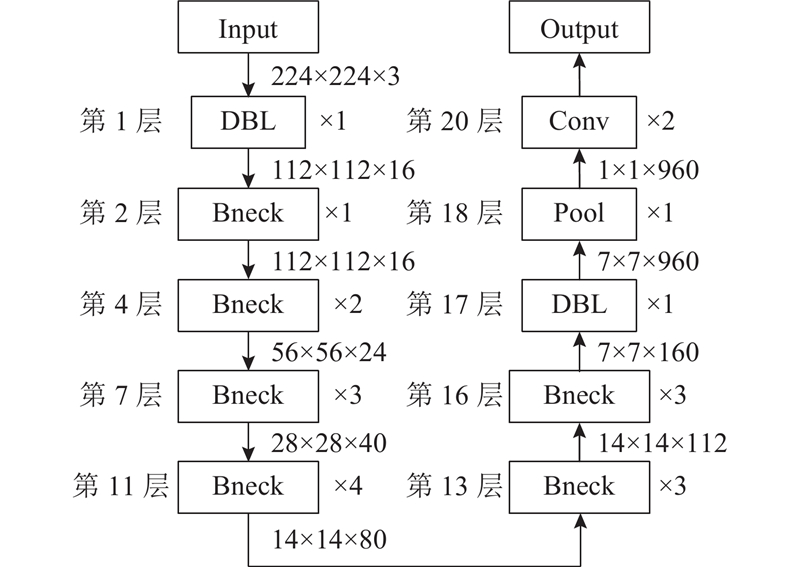
1.2.1. 常规MobileNetV3
图 2
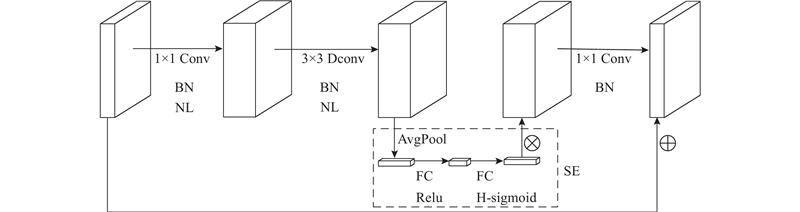
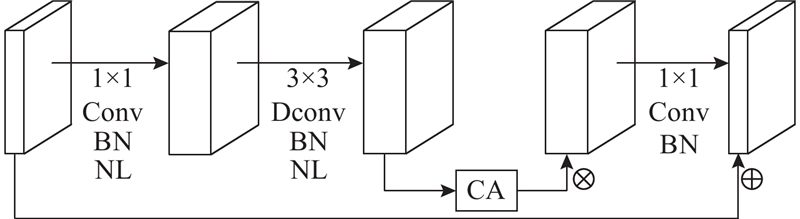
Bneck模块如图3所示,包括Conv、BN、非线性(non linear, NL)激活函数、Dconv以及挤压和激励(squeeze and excitation, SE)注意力机制.
图 3
1.2.2. 基于常规MobileNetV3改进的编码器结构
为了实现无人机智能巡检的高精度高速度需求,以常规MobileNetV3为基础,作如下改进.
1)常规MobileNetV3后4层(17~20层)参数多,计算量大. 采用前16层作为编码器主干特征提取网络,网络参数减少了43.23%,识别精度小幅降低,但识别速度明显提升.
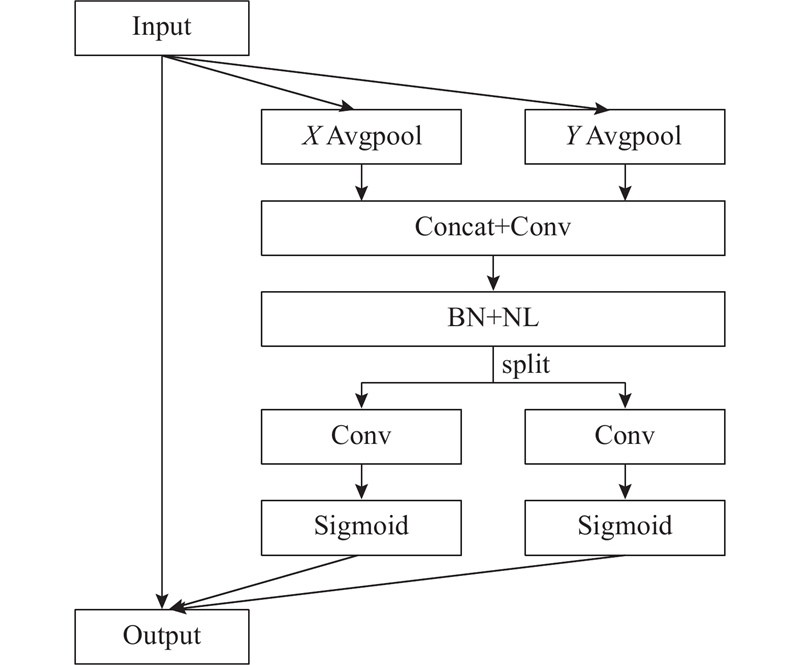
2)常规MobileNetV3中的注意力机制SE模块仅考虑特征图的通道信息而忽略了位置信息. 选用轻量级坐标注意力(coordinate attention, CA)模块替代SE模块,同时获取特征图的通道信息与位置信息,有助于网络更好地定位和识别输电线,网络参数仅增加了0.22%.
图 4
基于常规MobileNetV3改进的编码器包括1个DBL模块和15个Bneck-CA模块. 如图5所示,Bneck-CA模块包括Conv、BN、NL、Dconv和注意力机制CA模块,输入特征图通过1×1Conv、BN和NL升维后利用3×3Dconv、BN和NL进行特征提取,采用CA模块聚焦关键信息后再利用1×1Conv和BN降维,最后通过快捷链路与输入特征图堆叠获取输出特征图.
图 5
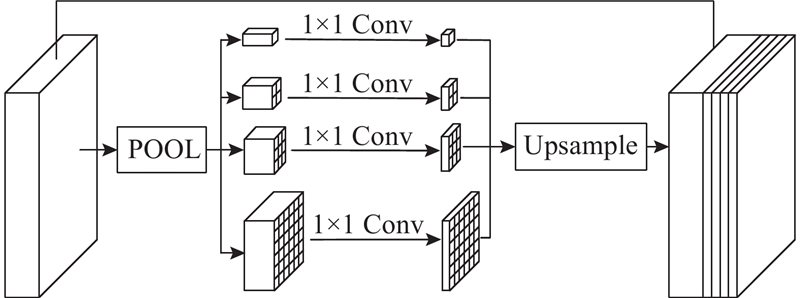
1.3. 构建解码器
图 6
深度可分离卷积通过逐深度卷积和逐点卷积提取特征,在逐深度卷积中,一个卷积核只计算一个输入特征图通道,卷积核数量与输入特征图通道数相同;逐点卷积为卷积核为1×1的普通卷积,卷积核数量与输出特征图通道数相同. 普通卷积的计算量为
式中:DK为逐深度卷积中卷积核大小,Q为输入特征图通道数,R为输出特征图通道数,DF为输入特征图大小.
深度可分离卷积的计算量为
以16×16的3通道输入特征图、4通道输出、3×3逐深度卷积核为例,深度可分离卷积的计算量约为普通卷积的1/3. 因此,深度可分离卷积占用计算资源少,计算效率高.
堆叠编码器第13层的锐化核卷积处理输出与第16层输出得到解码器输入,通过PPM聚合多尺度特征信息,采用DBL模块调整通道数,利用上采样恢复特征图尺寸至32×32×136;将编码器第11层引出的跳跃链接输出经锐化核卷积处理后和解码器第1次上采样输出堆叠,经过PPM、DBL和上采样后与编码器第7层锐化卷积处理后的跳跃链接输出堆叠;将堆叠后的特征图再次通过PPM、DBL和上采样后尺寸为128×128×74;引出编码器第4层添加锐化块的跳跃链接输出和解码器第3次上采样输出堆叠至128×128×98,通过3次DBL和上采样后与编码器第2层添加锐化块的跳跃链接输出堆叠,再通过3次DBL、上采样后采用1×1卷积调整通道数至输电线与背景2类别后输出,实现图像中输电线像素点和背景像素点的分类.
1.4. 改进跳跃链接
跳跃链接融合深层、浅层特征信息,增强特征复用能力. 锐化块(sharp block)通过锐化核与输入特征图卷积处理以增强输电线边缘与背景对比度. 通过在编码器与解码器之间添加带有锐化块的跳跃链接,减少复杂输电线边缘特征信息丢失,提高复杂输电线识别精度. 用于锐化卷积处理的锐化核K结合参考像素的8个邻像素,能够响应任何方向上的梯度变化. K的表达式如下:
将输入特征图与锐化核K卷积处理后与原输入特征图叠加,得到锐化卷积处理后的特征图:
式中:I为输入特征图,S为锐化卷积处理后的特征图,*表示卷积运算.
编码器引出跳跃链接输出的特征图尺寸为W×H×C,W、H和C分别表示特征图宽度、高度和通道数,使用锐化核K对每个特征图进行深度卷积,锐化块Sharp Block-A和Sharp Block-B步距分别为1和2,得到C个大小为W×H×1和W/2×H/2×1的特征图,再将C个特征图与输入特征图叠加得到锐化卷积处理后的特征图. 锐化核K不变,因此,在网络训练期间不产生额外的计算成本.
1.5. 混合损失函数
Focal Loss损失函数表达式为
式中:α、β分别取0.25和2.0,
Dice Loss损失函数表达式为
式中:
1.6. 特征图可视化
图 7

2. 复杂输电线数据集搭建
2.1. 数据集采集与扩充
目前多根、交叉和有转向等复杂输电线数据集较少,通过网络公开数据集获取,分别为百度飞桨输电线路数据集(
为了使新型编码解码网络具有更好的泛化能力,采用Mosaic进行数据扩充. 随机在4 000张输电线样本集中选取4张图片进行翻转、缩放以及色域变换后调整尺寸分别放至扩充图片左上、右上、左下和右下4个位置,如图8所示. 去除Mosaic数据扩充随机生成的模糊、缩放比例过大或过小等不适合网络训练的图像,共得到5 000张复杂输电线数据,按照8∶1∶1随机划分为训练集、验证集和测试集,训练集有4 000张,验证集和测试集各有500张.
图 8

2.2. 数据集标注
采用图像标注工具Labelme标注复杂输电线数据集,得到包含复杂输电线位置、形状信息的Json文件,将Json文件转为png格式的标签文件后与原图jpg格式组合,制成PASCAL VOC格式数据集,标注实例如图9所示.
图 9

3. 实验与结果分析
3.1. 实验环境
深度学习框架为Pytorch-GPU V1.10.0,GPU运算平台为CUDA10.1,显卡为Nvidia GeForce RTX 2080 Ti,显存为11 GB,处理器为Inter Core i7-9700k 3.60 GHz八核八线程,内存为32 GB;图像处理库为opencv-python4.6.0.66和pillow9.2.0,数组运算库为numpy1.23.1,绘图工具库为matplotlib3.2.2,编程语言为Python3.9.12,操作系统为Windows10.
3.2. 评价指标
选用主流语义分割评价指标验证新型编码解码网络性能[22].
1)平均像素精度(mean pixel accuracy, MPA):各类别中网络正确预测像素所占比例的均值.
式中:n为输电线类别,n=1;pii表示正确预测的像素数;pij表示i类被预测为j类的像素数.
2)平均交并比(mean intersection over union, MIOU):各类别预测值与标签值的重合度均值.
式中:pji表示j类被预测为i类的像素数.
3)每秒传输帧数(frames per second, FPS):网络一秒钟预测图片的数量.
式中:J为预测图片数量,Δt为预测时间.
3.3. 网络训练
表 1 新型编码解码网络训练参数
Tab.1
| 训练参数 | 数值 |
| Batch_size | 8 |
| Initial_lr | 0.0001 |
| Epoch | 500 |
| Cuda | True |
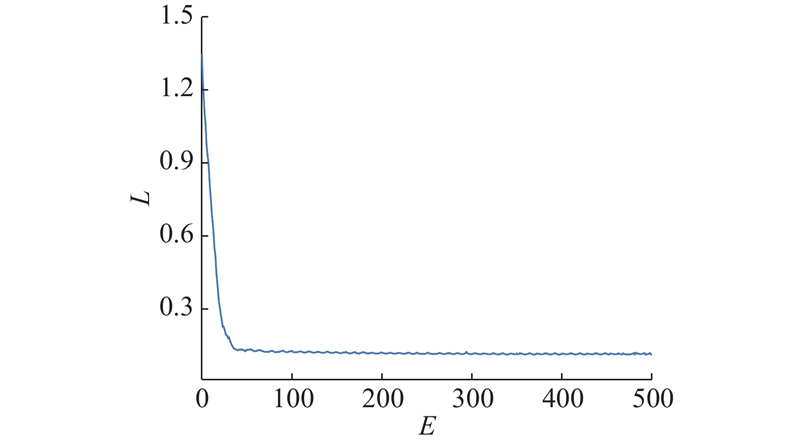
网络训练迭代500次,训练过程中损失变化如图10所示. 图中,E为迭代次数,L为损失值. 可以看到,随着迭代次数增加,损失值不断降低,前50次迭代的损失值下降速度快,迭代500次后损失值趋于稳定,收敛于0.1附近,表明新型编码解码网络已取得较好的训练结果.
图 10
3.4. 消融实验结果分析
为了验证新型编码解码网络性能,进行消融对比实验,各实验数据集和训练参数相同,测试集识别结果如表2所示.
表 2 消融实验结果对比
Tab.2
| 方法 | MPA/% | MIOU/% | FPS/(帧·s−1) |
| 方法1 | 89.63 | 81.77 | 22 |
| 方法2 | 88.17 | 80.92 | 28 |
| 方法3 | 88.93 | 81.38 | 27 |
| 方法4 | 88.27 | 80.87 | 35 |
| 方法5 | 89.68 | 82.15 | 34 |
| 方法6 | 90.72 | 82.77 | 32 |
| 方法7 | 91.58 | 83.34 | 31 |
| 方法8 | 91.97 | 84.02 | 31 |
| 方法9 | 92.18 | 84.27 | 32 |
方法1:采用MobileNetV3作为编码器,解码器为普通卷积、批量归一化和上采样,利用类别交叉熵损失函数计算网络损失;方法2:去除MobileNetV3后4层作为编码器,未更改注意力机制,解码器和损失函数不变;方法3:在方法2的基础上更改损失函数为混合损失函数LT;方法4:编码器和损失函数不变,解码器中采用深度可分离卷积替代普通卷积;方法5:在方法4的编码器中更改注意力机制,采用CA模块替代SE模块,混合损失函数LT和解码器不变;方法6:编码器和混合损失函数LT与方法5一致,解码器中添加金字塔池化模块;方法7:在方法6网络的编码器与解码器之间添加跳跃链接;方法8:以方法7为基础,在跳跃链接中添加锐化块;方法9:采用迁移学习机制,将通过开源PASCAL VOC数据集预训练得到的预训练权重迁移至方法8网络进行训练.
分析表2消融实验结果可以看出,方法2相对于方法1,虽然MPA和MIOU有小幅下降,但识别速度提升了6帧/s;方法3相对于方法2识别速度相差1帧/s,但MPA与MIOU分别提升了0.76%和0.46%;方法4的识别速度相对于方法2、3有明显提升,表明解码器中采用深度可分离卷积替代普通卷积后虽然识别精度有所下降,但识别速度显著提升;方法5中MPA和MIOU相对于方法4分别提升了1.41%和1.28%,表明选用的注意力机制CA模块结合特征图的通道信息与空间信息,能显著提高识别精度;在解码器中添加金字塔池化模块聚合不同区域的上下文信息,方法6相对于方法5在识别速度上降低2帧/s,但识别精度提升明显;单纯使用跳跃链接融合深层、浅层特征信息易受背景噪声影响,方法8在跳跃链接中添加锐化块,加强复杂输电线边缘特征提取,提高识别精度;方法9表明采用迁移学习能够加快网络收敛,有助于提高网络识别精度与速度.
3.5. 不同网络识别结果对比
为了验证新型编码解码网络的有效性,选取当前主流语义分割网络PSPNet[18]、U2Net[24]以及文献[12]、[13]输电线识别网络进行对比实验. PSPNet通过ResNet101进行特征提取,得到尺寸为输入图像1/8的特征图后经过金字塔池化模块聚合上下文信息,再利用卷积、上采样和Softmax处理获取预测结果;U2Net采用6个编码块进行特征提取,5个解码块进行特征恢复,将第6个编码块输出和5个解码块输出堆叠后得到网络预测结果;文献[12]中网络利用常规MobileNetV3作为编码器进行特征提取,在解码器中引入金字塔池化和上采样进行特征恢复获取预测结果;文献[13]中网络以UNet为基础,添加辅助分类器,结合UNet输出和辅助分类器输出获得预测结果.
5种网络的实验环境与数据集相同,测试集部分识别结果如图11所示. 可以看出,PSPNet在草地、人行道、沙石、森林和马路等背景下,识别多根、交叉和有转向等复杂输电线效果较差,输电线边缘锯齿化明显,并且出现输电线识别断裂的情况;U2Net在森林、沙石背景下识别输电线效果较好,但在复杂背景下识别效果较差,如将人行道边缘、缝隙线状物误检为输电线;文献[12]中网络在人行道背景下出现漏检,并且在输电线转向处出现识别断裂的情况,识别复杂输电线效果较差;文献[13]中网络在森林、草地背景下识别输电线效果较好,但当背景复杂时,易出现误检和漏检,如将人行道边缘、塔杆误检为输电线. 新型编码解码网络可以有效抑制人行道边缘、缝隙和塔杆等复杂背景影响,准确识别出多根、交叉和有转向等复杂输电线.
图 11

图 11 5种网络输电线识别结果
Fig.11 Power line recognition results of five types of networks
表 3 5种网络识别结果对比
Tab.3
4. 结 语
针对现有常规图像处理和基于深度学习的智能图像处理识别多根、交叉和有转向等复杂输电线精度低、速度慢问题,构建新型高效的输电线识别编码解码网络. 通过带有锐化块的跳跃链接融合深层、浅层特征信息,有效降低输电线边缘特征信息丢失,提高识别精度;利用混合损失函数,加强网络对输电线的特征学习,解决图像中输电线像素少,特征提取困难问题. 实验结果表明,新型编码解码网络的识别精度与速度均优于PSPNet、U2Net、文献[12]和文献[13]中网络的,能有效抑制人行道边缘、缝隙和塔杆等复杂背景影响,快速准确识别出多根、交叉和有转向等复杂输电线. 后续计划将网络代码移植到嵌入式设备上进行实验,进一步提高网络的可应用性.
参考文献
基于多级特征并联的轻量级图像语义分割
[J].
Lightweight image semantic segmentation based on multi-level feature cascaded network
[J].
基于双注意力机制和迁移学习的跨领域推荐模型
[J].DOI:10.11897/SP.J.1016.2020.01924 [本文引用: 1]
A cross-domain recommendation model based on dual attention mechanism and transfer learning
[J].DOI:10.11897/SP.J.1016.2020.01924 [本文引用: 1]
A review on state-of-the-art power line inspection techniques
[J].DOI:10.1109/TIM.2020.3031194 [本文引用: 1]
Development of power transmission line detection technology based on unmanned aerial vehicle image vision
[J].
复杂地物背景下电力线的快速提取算法
[J].
Research on fast extraction algorithm of power line in complex ground object background
[J].
复杂背景下电力线自动提取算法
[J].
Automatic extraction algorithm of power line in complex background
[J].
基于颜色空间变量的输电线图像分类及特征提取
[J].DOI:10.7667/PSPC170283 [本文引用: 1]
Image classification and feature extraction of transmission line based on color space variable
[J].DOI:10.7667/PSPC170283 [本文引用: 1]
Online monitoring of overhead power lines against tree intrusion via a low-cost camera and mobile edge computing approach
[J].
Power line extraction from aerial images using object-based markov random field with anisotropic weighted penalty
[J].DOI:10.1109/ACCESS.2019.2939025 [本文引用: 1]
基于深度学习的图像语义分割方法综述
[J].
Review of image semantic segmentation based on deep learning
[J].
Supervised semantic segmentation based on deep learning: a survey
[J].DOI:10.1007/s11042-022-12842-y [本文引用: 1]
轻量化航拍图像电力线语义分割
[J].
Research on lightweight neural network of aerial powerline image segmentation
[J].
基于编码解码结构的移动端电力线语义分割方法
[J].DOI:10.11772/j.issn.1001-9081.2020122037 [本文引用: 1]
Semantic segmentation method of power line on mobile terminals based on encoder-decoder structure
[J].DOI:10.11772/j.issn.1001-9081.2020122037 [本文引用: 1]
基于新型编解码网络的复杂背景航拍图像输电线识别
[J].
Power line recognition from aerial images with complex background based on new codec network
[J].
A novel focal phi loss for power line segmentation with auxiliary classifier U-Net
[J].DOI:10.1109/JSEN.2021.3063942 [本文引用: 8]
Transmission line detection in aerial images: an instance segmentation approach based on multitask neural networks
[J].
Vision-based power line segmentation with an attention fusion network
[J].DOI:10.1109/JSEN.2022.3157336 [本文引用: 1]
U2-Net: going deeper with nested U-structure for salient object detection
[J].
Real-time object detector based MobileNetV3 for UAV applications
[J].
Deep multimodal fusion for semantic image segmentation: a survey
[J].
Focal loss for dense object detection
[J].DOI:10.1109/TPAMI.2018.2858826 [本文引用: 1]
SdBAN: salient object detection using bilateral attention network with dice coefficient loss
[J].DOI:10.1109/ACCESS.2020.2999627 [本文引用: 1]
Visual analytics for explainable deep learning
[J].DOI:10.1109/MCG.2018.042731661 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}