[1]
刘喜平, 舒晴, 何佳壕, 等 基于自然语言的数据库查询生成研究综述
[J]. 软件学报 , 2022 , 33 (11 ): 4107 - 4136
[本文引用: 1]
LIU Xiping, SHU Qing, HE Jiahao, et al Survey on generating database queries based on natural language
[J]. Journal of Software , 2022 , 33 (11 ): 4107 - 4136
[本文引用: 1]
[2]
GUO J, ZHAN Z, GAO Y, et al. Towards complex text-to-SQL in cross-domain database with intermediate representation [C]// Proceedings of ACL . Florence: ACL, 2019: 4524-4535.
[本文引用: 2]
[3]
WANG K, SHEN W, YANG Y, et al. Relational graph attention network for aspect-based sentiment analysis [C]// Proceedings of ACL . [S. l. ]: ACL, 2020: 3229-3238.
[本文引用: 1]
[4]
XU X, LIU C, SONG D X. SQLNet: generating structured queries from natural language without reinforcement learning [EB/OL]. (2017-11-13) [2023-10-27]. https://arxiv.org/abs/1711.04436.
[本文引用: 1]
[5]
YU T, LI Z, ZHANG Z, et al. TypeSQL: knowledge-based type-aware neural text-to-SQL generation [C]// Proceedings of NAACL-HLT . New Orleans: ACL, 2018: 588-594.
[本文引用: 1]
[6]
LEI W, WANG W, MA Z, et al. Re-examining the role of schema linking in text-to-SQL [C]// Proceedings of EMNLP . [S. l.]: ACL, 2020: 6943-6954.
[本文引用: 3]
[7]
CHOI D, SHIN M C, KIM E, et al RYANSQL: recursively applying sketch-based slot fillings for complex text-to-SQL in cross-domain databases
[J]. Computational Linguistics , 2021 , 47 (2 ): 309 - 332
[本文引用: 2]
[8]
BOGIN B, BERANT J, GARDNER M. Representing schema structure with graph neural networks for text-to-SQL parsing [C]// Proceedings of ACL . Florence: ACL, 2019: 4560-4565.
[本文引用: 1]
[9]
BOGIN B, GARDNER M, BERANT J. Global reasoning over database structures for text-to-SQL parsing [C]// Proceedings of EMNLP-IJCNLP 2019 . Hong Kong: ACL, 2019: 3659-3664.
[本文引用: 1]
[10]
ZHONG V, XIONG C, SOCHER R. Seq2SQL: generating structured queries from natural language using reinforcement learning [EB/OL]. (2017-11-09) [2023-10-27]. https://arxiv.org/abs/1709.00103.
[本文引用: 1]
[11]
WANG B, SHIN R, LIU X, et al. RAT-SQL: relation-aware schema encoding and linking for text-to-SQL parsers [C]// Proceedings of ACL . [S. l. ]: ACL, 2020: 7567-7578.
[本文引用: 2]
[12]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 5998–6008.
[本文引用: 1]
[13]
LIN X V, SOCHER R, XIONG C. Bridging textual and tabular data for cross-domain text-to-SQL semantic parsing [C]// Findings of the ACL: EMNLP 2020 . [S. l.]: ACL, 2020: 4870-4888.
[本文引用: 1]
[14]
CAO R, CHEN L, CHEN Z, et al. Line graph enhanced text-to-SQL model with mixed local and non-local relations [C]// Proceedings of ACL-IJCNLP 2021 . [S. l.]: ACL, 2021: 2541-2555.
[本文引用: 2]
[15]
CAI R, YUAN J, XU B, et al Sadga: Structure-aware dual graph aggregation network for text-to-sql
[J]. Advances in Neural Information Processing Systems , 2021 , 34 : 7664 - 7676
[本文引用: 1]
[16]
HUI B, GENG R, WANG L, et al. S2SQL: injecting syntax to question-schema interaction graph encoder for Text-to-SQL parsers [C]// Findings of the ACL: ACL 2022 . Dublin: ACL, 2022: 1254-1262.
[本文引用: 1]
[17]
QI J, TANG J, HE Z, et al. Rasat: Integrating relational structures into pretrained seq2seq model for text-to-sql [C]// Proceedings of the 2022 Conference on EMNLP . Abu Dhabi: ACL, 2022: 3215-3229.
[本文引用: 8]
[18]
RAFFEL C, SHAZEER N, ROBERTS A, et al Exploring the limits of transfer learning with a unified text-to-text transformer
[J]. The Journal of Machine Learning Research , 2020 , 21 (1 ): 5485 - 5551
[本文引用: 1]
[19]
SHAW P, CHANG M W, PASUPAT P, et al. Compositional generalization and natural language variation: can a semantic parsing approach handle both? [C]// Proceedings of ACL-IJCNLP 2021 . [S. l. ]: ACL, 2021: 922–938.
[本文引用: 5]
[20]
SCHOLAK T, SCHUCHER N, BAHDANAU D. PICARD: parsing incrementally for constrained auto-regressive decoding from language models [C]// Proceedings of the 2021 Conference on EMNLP . Punta Cana: ACL, 2021: 9895-9901.
[本文引用: 5]
[21]
GAO C, LI B, ZHANG W, et al. Towards generalizable and robust Text-to-SQL parsing [C]// Findings of the ACL: EMNLP 2022 . Abu Dhabi: ACL, 2022: 2113-2125.
[本文引用: 8]
[22]
XIE T, WU C H, SHI P, et al. Unifiedskg: Unifying and multi-tasking structured knowledge grounding with text-to-text language models [C]// Proceedings of the 2022 Conference on EMNLP . Abu Dhabi: ACL, 2022: 602-631.
[本文引用: 5]
[23]
LI J, HUI B, CHENG R, et al. Graphix-T5: mixing pre-trained Transformers with graph-aware layers for text-to-SQL parsing [EB/OL]. (2023-01-18) [2023-10-27]. https://arxiv.org/abs/2301.07507.
[本文引用: 1]
[24]
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of NAACL-HLT 2019 . Minneapolis: ACL, 2019: 4171–4186.
[本文引用: 1]
[25]
YU T, ZHANG R, YANG K, et al. Spider: a large-scale human-labeled dataset for complex and cross-domain semantic parsing and Text-to-SQL task [C]// Proceedings of the 2018 Conference on EMNLP . Brussels: ACL, 2018: 3911–3921.
[本文引用: 1]
[26]
GAN Y, CHEN X, PURVER M. Exploring underexplored limitations of cross-domain Text-to-SQL generalization [C]// Proceedings of EMNLP . [S. l. ]: ACL, 2021: 8926–8931.
[本文引用: 1]
[27]
GAN Y, CHEN X, HUANG Q, et al. Towards robustness of Text-to-SQL models against synonym substitution [C]// Proceedings of ACL-IJCNLP. [S. l. ]: ACL , 2021: 2505-2515.
[本文引用: 1]
[28]
SHAZEER N, STERN M. Adafactor: adaptive learning rates with sublinear memory cost [C]// Proceedings of the 35th International Conference on Machine Learning , Stockholm: PMLR, 2018: 4596-4604.
[本文引用: 1]
[29]
YU T, WU C S, LIN X V, et al. GraPPa: grammar-augmented pre-training for table semantic parsing [EB/OL]. (2021-05-29) [2023-10-27]. https://arxiv.org/abs/2009.13845.
[本文引用: 1]
基于自然语言的数据库查询生成研究综述
1
2022
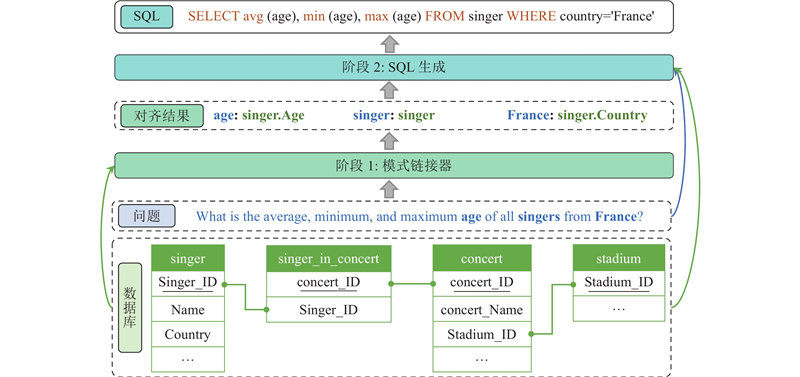
... Text-to-SQL任务需要模型理解NLQ中所涉及的表和列,理解数据库模式中各个元素之间的关系. 如何正确地将NLQ与数据库模式进行对齐是当前Text-to-SQL问题的瓶颈[1 ] . 将NLQ中描述的实体和关系映射到数据库模式,这在Text-to-SQL 任务中被称为模式链接(schema linking)[2 ] . 由于自然语言的表述具有多样性,问题中对数据库模式的表述不一定与实际的模式名称一致,且数据库中可能存在许多相似的模式名称,这都给模式链接增加了难度. 传统的模式链接方法包括规则或字符串匹配,后续的一些模型在编码阶段使用注意力模块,这些方法大多没有考虑句子的语法结构,无法捕捉词语间长距离的依赖关系,导致模型无法正确理解句子的含义,从而无法准确地识别句子中提及的数据库模式. 针对上述问题,本文提出两阶段框架. 首先使用模式链接器,利用数据库模式结构和问题句子的依存句法关系,在生成SQL之前对齐问题词和数据库模式,帮助后续模型过滤掉大部分不相关的模式项,降低训练和生成SQL的难度. 在第2阶段,将对齐信息注入到SQL生成器中,将它们视为附加上下文,增强SQL生成的结果. ...
基于自然语言的数据库查询生成研究综述
1
2022
... Text-to-SQL任务需要模型理解NLQ中所涉及的表和列,理解数据库模式中各个元素之间的关系. 如何正确地将NLQ与数据库模式进行对齐是当前Text-to-SQL问题的瓶颈[1 ] . 将NLQ中描述的实体和关系映射到数据库模式,这在Text-to-SQL 任务中被称为模式链接(schema linking)[2 ] . 由于自然语言的表述具有多样性,问题中对数据库模式的表述不一定与实际的模式名称一致,且数据库中可能存在许多相似的模式名称,这都给模式链接增加了难度. 传统的模式链接方法包括规则或字符串匹配,后续的一些模型在编码阶段使用注意力模块,这些方法大多没有考虑句子的语法结构,无法捕捉词语间长距离的依赖关系,导致模型无法正确理解句子的含义,从而无法准确地识别句子中提及的数据库模式. 针对上述问题,本文提出两阶段框架. 首先使用模式链接器,利用数据库模式结构和问题句子的依存句法关系,在生成SQL之前对齐问题词和数据库模式,帮助后续模型过滤掉大部分不相关的模式项,降低训练和生成SQL的难度. 在第2阶段,将对齐信息注入到SQL生成器中,将它们视为附加上下文,增强SQL生成的结果. ...
2
... Text-to-SQL任务需要模型理解NLQ中所涉及的表和列,理解数据库模式中各个元素之间的关系. 如何正确地将NLQ与数据库模式进行对齐是当前Text-to-SQL问题的瓶颈[1 ] . 将NLQ中描述的实体和关系映射到数据库模式,这在Text-to-SQL 任务中被称为模式链接(schema linking)[2 ] . 由于自然语言的表述具有多样性,问题中对数据库模式的表述不一定与实际的模式名称一致,且数据库中可能存在许多相似的模式名称,这都给模式链接增加了难度. 传统的模式链接方法包括规则或字符串匹配,后续的一些模型在编码阶段使用注意力模块,这些方法大多没有考虑句子的语法结构,无法捕捉词语间长距离的依赖关系,导致模型无法正确理解句子的含义,从而无法准确地识别句子中提及的数据库模式. 针对上述问题,本文提出两阶段框架. 首先使用模式链接器,利用数据库模式结构和问题句子的依存句法关系,在生成SQL之前对齐问题词和数据库模式,帮助后续模型过滤掉大部分不相关的模式项,降低训练和生成SQL的难度. 在第2阶段,将对齐信息注入到SQL生成器中,将它们视为附加上下文,增强SQL生成的结果. ...
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
1
... (2)提出基于依存关系图注意力网络的对齐方法,在问题依存句法分析的基础上重塑和修剪依存关系,构建关系图注意力网络(relational graph attention network, RGAT)[3 ] . 利用问题的语法结构和模式项之间的内部关系,指导模型学习问题与数据库的对齐关系. ...
1
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
1
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
3
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
... Text-to-SQL目前的主流数据集是Spider数据集[25 ] ,该数据集包含10 181条自然语言问题和5 693条SQL查询以及138个不同领域的200个数据库;其SQL语句覆盖了多表连接、分组、排序、嵌套查询等复杂操作,目前SOTA模型的准确度约为70%. Spider分为训练集、验证集和测试集,样本个数分别为7 000、1 034和2 134. 由于测试集未公开,使用验证集进行消融实验. 基于Spider数据集,SLSQL构建了模式链接语料库,对Spider训练集和验证集的每个实例注释了模式链接信息[6 ] . 使用SLSQL提供的标注数据训练模式链接器. ...
... 为了验证模型的鲁棒性,在 Spider-DK和Spider-Syn数据集上进行实验,模式链接器未重新训练,即仍然使用基于SLSQL[6 ] 标注的Spider数据集训练的结果,实验结果见表10 . 这2个数据集更贴合实际的应用场景,Spider-DK 结合了一些领域知识,Spider-Syn模拟了用户不熟悉数据库的模式,在问题中没有准确提及模式词的情况. 实验结果显示,本文方法具有鲁棒性,在2个数据集上的表现均超过基线模型. ...
RYANSQL: recursively applying sketch-based slot fillings for complex text-to-SQL in cross-domain databases
2
2021
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
... 最近一些工作使用Text-to-Text的预训练模型T5[18 ] ,取得了不错的效果,与基于图的方法不同,基于T5的方法对编码器和解码器都采用基于Transformer的架构,不需要预定义的图、模式链接关系和基于语法的解码器. Shaw等[19 ] 的研究表明,对T5进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B的结果可以与当时最先进的模型Ryansql[7 ] 的结果相当. Scholak等[20 ] 提出的PICARD模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能. PICARD的T5-Base模型可以超越没有PICARD的T5-Large模型. Gao等[21 ] 提出由任务分解、知识获取和知识组合构成的3阶段框架,提升了模型获取通用SQL知识的能力,使其更具有泛化能力和鲁棒性. RASAT[17 ] 通过在多头自注意力中加入边的嵌入,为T5提供结构信息. Xie等[22 ] 将其他结构化知识数据任务(structured knowledge grounding, SKG)的知识注入到T5的多任务训练中,提高Text-to-SQL的性能. GRAPHIX-T5[23 ] 在T5的基础上增加图形感知层,以增强多跳推理能力,在保持T5强大的上下文编码能力的基础上,提高T5的结构编码能力. 这些工作都表明,T5中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5在Text-to-SQL任务上获得优异的表现. ...
1
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
1
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
1
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
2
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
... SQL generation results on Spider-DK and Spider-Syn
Tab.10 模型 Spider-DK Spider-Syn EM/% EX/% EM/% EX/% RAT-SQL+BERT[11 ] 40.9 — 48.2 — RAT-SQL+GRAPPA[29 ] 38.5 — 49.1 — T5-Base[21 ] — — 40.8 43.8 T5-Large[21 ] — — 53.1 57.4 TKK(T5-Base)[21 ] — — 44.2 47.7 TKK(T5-Large)[21 ] — — 55.1 60.5 本文方法-T5-Base 39.3 46.6 49.8 54.6 本文方法-T5-Large 48.2 55.3 56.0 60.9
4. 结 语 本文提出两阶段的模型以解决Text-to-SQL问题,通过模式链接器识别问题中提及的数据库表、列和值,将对齐信息融合到基于T5的生成器中,指导SQL生成. 模式链接器基于关系图注意力网络,根据问题句法依存树和模式项之间的内部关系构造图. 在构造问题图时,对依存关系进行合并和传播,有助于模型捕获长距离的依赖关系. 模型将模式链接和SQL生成解耦,以降低Text-to-SQL问题的复杂性,在Spider及其变体上的实验证明了该模型的性能. 下一步将对模式链接模块继续进行优化,提高SQL生成的准确率. ...
1
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
1
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
2
... Text-to-SQL问题需要模型理解NLQ在哪些数据库模式上进行查询操作,因此要考虑NLQ和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等. SQLNet使用列注意力,将列的信息融入NLQ的单词表示[4 ] . TypeSQL通过数据库和知识库识别NLQ中的实体,将实体类型作为输入特征进行编码[5 ] . Guo等[2 ] 提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match). SLSQL对Spider数据集的模式链接进行标注,证明精确的模式链接可以提高SQL生成的性能[6 ] . Ryansql在编码时加入问题-列对齐层(question-column alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7 ] . Bogin等[8 ] 通过GNN建模数据库模式的图结构,提出GLOBAL-GNN[9 ] ,使用门控GCN选择与问题相关的列和表. 问题和数据库模式的联合编码有助于二者的对齐. Seq2SQL将列名、NLQ和SQL关键字序列通过Bi-LSTM编码[10 ] . Rat-SQL[11 ] 在Transformer[12 ] 的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理NLQ和模式项间各种预设的关系. BRIDGE[13 ] 为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型. LGESQL通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14 ] . ...
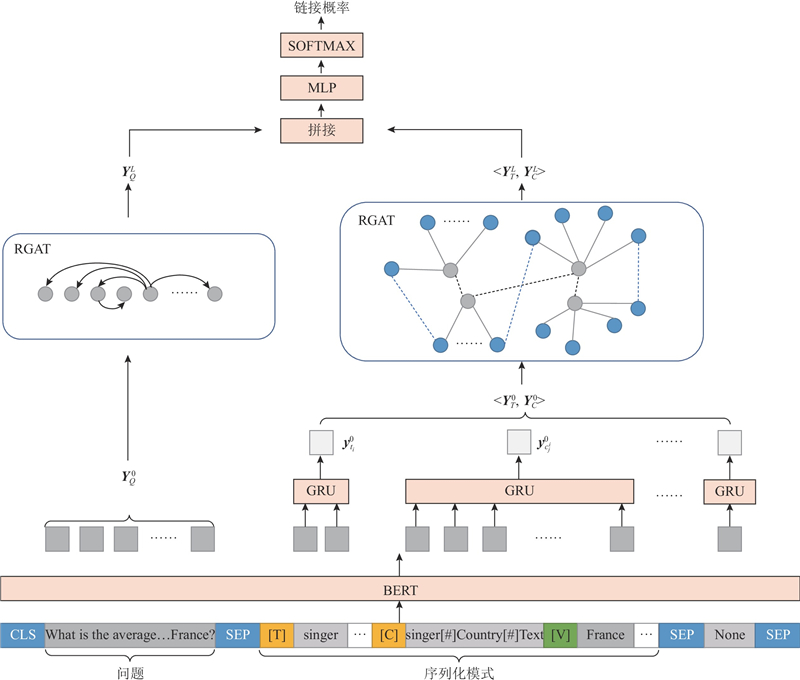
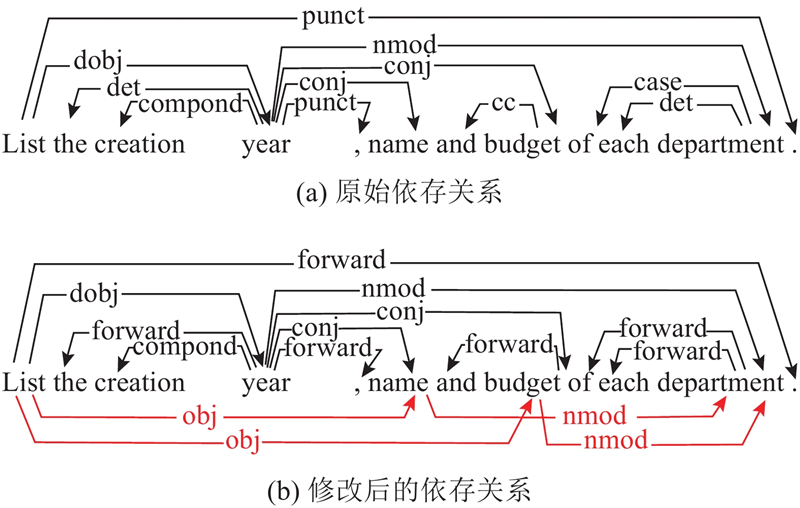
... 除上述修改,还添加了单词与自身的自连接关系. 将句子结点构成的图使用RGAT[14 ] 模型计算其表示${\boldsymbol{Y}}_Q^L$ L 为网络层数,公式如下: ...
Sadga: Structure-aware dual graph aggregation network for text-to-sql
1
2021
... Text-to-SQL相关工作中对句法特征的使用较少,然而句法依存信息反映了问题的语法结构,有助于模型理解问题. SADGA基于上下文结构和句法依存树构建问题图,基于数据库特定关系构建模式图,利用图神经网络分别对问题图和模式图进行编码,设计结构感知的聚合方法来学习问题图和模式图之间的映射关系[15 ] . 该方法直接使用原始句法依存信息,依存关系数目庞大,容易导致过拟合. S2 SQL[16 ] 在关系图注意网络中增加依存句法信息,RASAT[17 ] 在继承T5模型的预训练参数的基础上增加关系感知的自注意力,用于捕获模式结构、模式链接、问题依存结构、问题共指和数据库内容提及这5种关系. S2 SQL和RASAT均未对不同的句法依赖关系进行区分,仅保留依赖关系的方向. 本文根据Text-to-SQL 任务的特点,对原始句法依存树进行修改,合并了部分依存关系标签,对并列结构的部分关系进行传播,帮助模型更好地理解问题,改进模式链接的结果. ...
1
... Text-to-SQL相关工作中对句法特征的使用较少,然而句法依存信息反映了问题的语法结构,有助于模型理解问题. SADGA基于上下文结构和句法依存树构建问题图,基于数据库特定关系构建模式图,利用图神经网络分别对问题图和模式图进行编码,设计结构感知的聚合方法来学习问题图和模式图之间的映射关系[15 ] . 该方法直接使用原始句法依存信息,依存关系数目庞大,容易导致过拟合. S2 SQL[16 ] 在关系图注意网络中增加依存句法信息,RASAT[17 ] 在继承T5模型的预训练参数的基础上增加关系感知的自注意力,用于捕获模式结构、模式链接、问题依存结构、问题共指和数据库内容提及这5种关系. S2 SQL和RASAT均未对不同的句法依赖关系进行区分,仅保留依赖关系的方向. 本文根据Text-to-SQL 任务的特点,对原始句法依存树进行修改,合并了部分依存关系标签,对并列结构的部分关系进行传播,帮助模型更好地理解问题,改进模式链接的结果. ...
8
... Text-to-SQL相关工作中对句法特征的使用较少,然而句法依存信息反映了问题的语法结构,有助于模型理解问题. SADGA基于上下文结构和句法依存树构建问题图,基于数据库特定关系构建模式图,利用图神经网络分别对问题图和模式图进行编码,设计结构感知的聚合方法来学习问题图和模式图之间的映射关系[15 ] . 该方法直接使用原始句法依存信息,依存关系数目庞大,容易导致过拟合. S2 SQL[16 ] 在关系图注意网络中增加依存句法信息,RASAT[17 ] 在继承T5模型的预训练参数的基础上增加关系感知的自注意力,用于捕获模式结构、模式链接、问题依存结构、问题共指和数据库内容提及这5种关系. S2 SQL和RASAT均未对不同的句法依赖关系进行区分,仅保留依赖关系的方向. 本文根据Text-to-SQL 任务的特点,对原始句法依存树进行修改,合并了部分依存关系标签,对并列结构的部分关系进行传播,帮助模型更好地理解问题,改进模式链接的结果. ...
... 最近一些工作使用Text-to-Text的预训练模型T5[18 ] ,取得了不错的效果,与基于图的方法不同,基于T5的方法对编码器和解码器都采用基于Transformer的架构,不需要预定义的图、模式链接关系和基于语法的解码器. Shaw等[19 ] 的研究表明,对T5进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B的结果可以与当时最先进的模型Ryansql[7 ] 的结果相当. Scholak等[20 ] 提出的PICARD模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能. PICARD的T5-Base模型可以超越没有PICARD的T5-Large模型. Gao等[21 ] 提出由任务分解、知识获取和知识组合构成的3阶段框架,提升了模型获取通用SQL知识的能力,使其更具有泛化能力和鲁棒性. RASAT[17 ] 通过在多头自注意力中加入边的嵌入,为T5提供结构信息. Xie等[22 ] 将其他结构化知识数据任务(structured knowledge grounding, SKG)的知识注入到T5的多任务训练中,提高Text-to-SQL的性能. GRAPHIX-T5[23 ] 在T5的基础上增加图形感知层,以增强多跳推理能力,在保持T5强大的上下文编码能力的基础上,提高T5的结构编码能力. 这些工作都表明,T5中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5在Text-to-SQL任务上获得优异的表现. ...
... 本文方法与其他模型在Spider验证集上的SQL生成结果对比如表8 所示. 表中,“GT”表示不使用模式链接器预测的模式链接结果,而是使用标注的模式链接结果,即Ground Truth. 根据实验结果可见,本文方法在不同规模的T5模型上展现了较好的性能. 在加入第一阶段预测的模式链接结果后,本文方法较文献[19 ]在原始T5上的结果有了较大提升,EM值在T5-Base上提升了11.4%,在T5-Large上的结果与T5-3B上的结果相当. EM反映预测查询是否和标准查询在所有组件上完全一致,然而同一查询可以有多种实现方法,例如“SELECT a FROM t ORDER BY b DESC LIMIT 1”与“SELECT a FROM t WHERE b = (SELECT MAX(b) FROM t)”是完全等价的,因此EM存在将正例判负的情况,造成了EM和EX之间差距较大. 本文在T5-Large上的EX值超过了同规模的所有基线模型,甚至比Unifiedskg[22 ] 在T5-3B上的结果高1%. 实验证明,使用准确的模式链接信息可以显著提升模型的性能,在使用标注的模式链接结果后,本文方法在T5-Large上的结果甚至超过了RASAT[17 ] 在T5-3B上的结果. ...
... Comparison of SQL generation results
Tab.8 模型 EM/% EX/% T5-Base[19 ] 57.1 — T5-3B[19 ] 70.0 — Unifiedskg(T5-Base)[22 ] 58.1 60.1 Unifiedskg(T5-Large) [22 ] 66.6 68.3 Unifiedskg(T5-3B)[22 ] 71.8 74.4 T5-Base+PICARD[20 ] 68.5 68.4 T5-Large+PICARD[20 ] 69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9
为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
17 ]
66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
17 ]
72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
17 ]
75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... Comparison of EX accuracy on different difficulty levels
Tab.9 模型 EX/% easy medium hard extra hard TKK(T5-Large)[21 ] 89.5 76.5 52.9 45.2 T5-3B+PICARD[20 ] 95.2 85.4 67.2 50.6 RASAT(T5-3B)+PICARD[17 ] 96.0 86.5 67.8 53.6 本文方法-T5-Large 89.1 81.6 62.6 51.8 本文方法-T5-Large+GT 92.7 87.2 71.3 56.6
为了验证模型的鲁棒性,在 Spider-DK和Spider-Syn数据集上进行实验,模式链接器未重新训练,即仍然使用基于SLSQL[6 ] 标注的Spider数据集训练的结果,实验结果见表10 . 这2个数据集更贴合实际的应用场景,Spider-DK 结合了一些领域知识,Spider-Syn模拟了用户不熟悉数据库的模式,在问题中没有准确提及模式词的情况. 实验结果显示,本文方法具有鲁棒性,在2个数据集上的表现均超过基线模型. ...
Exploring the limits of transfer learning with a unified text-to-text transformer
1
2020
... 最近一些工作使用Text-to-Text的预训练模型T5[18 ] ,取得了不错的效果,与基于图的方法不同,基于T5的方法对编码器和解码器都采用基于Transformer的架构,不需要预定义的图、模式链接关系和基于语法的解码器. Shaw等[19 ] 的研究表明,对T5进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B的结果可以与当时最先进的模型Ryansql[7 ] 的结果相当. Scholak等[20 ] 提出的PICARD模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能. PICARD的T5-Base模型可以超越没有PICARD的T5-Large模型. Gao等[21 ] 提出由任务分解、知识获取和知识组合构成的3阶段框架,提升了模型获取通用SQL知识的能力,使其更具有泛化能力和鲁棒性. RASAT[17 ] 通过在多头自注意力中加入边的嵌入,为T5提供结构信息. Xie等[22 ] 将其他结构化知识数据任务(structured knowledge grounding, SKG)的知识注入到T5的多任务训练中,提高Text-to-SQL的性能. GRAPHIX-T5[23 ] 在T5的基础上增加图形感知层,以增强多跳推理能力,在保持T5强大的上下文编码能力的基础上,提高T5的结构编码能力. 这些工作都表明,T5中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5在Text-to-SQL任务上获得优异的表现. ...
5
... 最近一些工作使用Text-to-Text的预训练模型T5[18 ] ,取得了不错的效果,与基于图的方法不同,基于T5的方法对编码器和解码器都采用基于Transformer的架构,不需要预定义的图、模式链接关系和基于语法的解码器. Shaw等[19 ] 的研究表明,对T5进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B的结果可以与当时最先进的模型Ryansql[7 ] 的结果相当. Scholak等[20 ] 提出的PICARD模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能. PICARD的T5-Base模型可以超越没有PICARD的T5-Large模型. Gao等[21 ] 提出由任务分解、知识获取和知识组合构成的3阶段框架,提升了模型获取通用SQL知识的能力,使其更具有泛化能力和鲁棒性. RASAT[17 ] 通过在多头自注意力中加入边的嵌入,为T5提供结构信息. Xie等[22 ] 将其他结构化知识数据任务(structured knowledge grounding, SKG)的知识注入到T5的多任务训练中,提高Text-to-SQL的性能. GRAPHIX-T5[23 ] 在T5的基础上增加图形感知层,以增强多跳推理能力,在保持T5强大的上下文编码能力的基础上,提高T5的结构编码能力. 这些工作都表明,T5中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5在Text-to-SQL任务上获得优异的表现. ...
... 其中spani Q 中连续的若干个单词. “spani t k i t k j $ c_m^n $ j $ c_m^n $ [19 ] 的工作,数据库模式S 序列化为如下形式: ...
... 本文方法与其他模型在Spider验证集上的SQL生成结果对比如表8 所示. 表中,“GT”表示不使用模式链接器预测的模式链接结果,而是使用标注的模式链接结果,即Ground Truth. 根据实验结果可见,本文方法在不同规模的T5模型上展现了较好的性能. 在加入第一阶段预测的模式链接结果后,本文方法较文献[19 ]在原始T5上的结果有了较大提升,EM值在T5-Base上提升了11.4%,在T5-Large上的结果与T5-3B上的结果相当. EM反映预测查询是否和标准查询在所有组件上完全一致,然而同一查询可以有多种实现方法,例如“SELECT a FROM t ORDER BY b DESC LIMIT 1”与“SELECT a FROM t WHERE b = (SELECT MAX(b) FROM t)”是完全等价的,因此EM存在将正例判负的情况,造成了EM和EX之间差距较大. 本文在T5-Large上的EX值超过了同规模的所有基线模型,甚至比Unifiedskg[22 ] 在T5-3B上的结果高1%. 实验证明,使用准确的模式链接信息可以显著提升模型的性能,在使用标注的模式链接结果后,本文方法在T5-Large上的结果甚至超过了RASAT[17 ] 在T5-3B上的结果. ...
... Comparison of SQL generation results
Tab.8 模型 EM/% EX/% T5-Base[19 ] 57.1 — T5-3B[19 ] 70.0 — Unifiedskg(T5-Base)[22 ] 58.1 60.1 Unifiedskg(T5-Large) [22 ] 66.6 68.3 Unifiedskg(T5-3B)[22 ] 71.8 74.4 T5-Base+PICARD[20 ] 68.5 68.4 T5-Large+PICARD[20 ] 69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9
为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
19 ]
70.0 — Unifiedskg(T5-Base)[22 ] 58.1 60.1 Unifiedskg(T5-Large) [22 ] 66.6 68.3 Unifiedskg(T5-3B)[22 ] 71.8 74.4 T5-Base+PICARD[20 ] 68.5 68.4 T5-Large+PICARD[20 ] 69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
5
... 最近一些工作使用Text-to-Text的预训练模型T5[18 ] ,取得了不错的效果,与基于图的方法不同,基于T5的方法对编码器和解码器都采用基于Transformer的架构,不需要预定义的图、模式链接关系和基于语法的解码器. Shaw等[19 ] 的研究表明,对T5进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B的结果可以与当时最先进的模型Ryansql[7 ] 的结果相当. Scholak等[20 ] 提出的PICARD模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能. PICARD的T5-Base模型可以超越没有PICARD的T5-Large模型. Gao等[21 ] 提出由任务分解、知识获取和知识组合构成的3阶段框架,提升了模型获取通用SQL知识的能力,使其更具有泛化能力和鲁棒性. RASAT[17 ] 通过在多头自注意力中加入边的嵌入,为T5提供结构信息. Xie等[22 ] 将其他结构化知识数据任务(structured knowledge grounding, SKG)的知识注入到T5的多任务训练中,提高Text-to-SQL的性能. GRAPHIX-T5[23 ] 在T5的基础上增加图形感知层,以增强多跳推理能力,在保持T5强大的上下文编码能力的基础上,提高T5的结构编码能力. 这些工作都表明,T5中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5在Text-to-SQL任务上获得优异的表现. ...
... Comparison of SQL generation results
Tab.8 模型 EM/% EX/% T5-Base[19 ] 57.1 — T5-3B[19 ] 70.0 — Unifiedskg(T5-Base)[22 ] 58.1 60.1 Unifiedskg(T5-Large) [22 ] 66.6 68.3 Unifiedskg(T5-3B)[22 ] 71.8 74.4 T5-Base+PICARD[20 ] 68.5 68.4 T5-Large+PICARD[20 ] 69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9
为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
20 ]
69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
20 ]
75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... Comparison of EX accuracy on different difficulty levels
Tab.9 模型 EX/% easy medium hard extra hard TKK(T5-Large)[21 ] 89.5 76.5 52.9 45.2 T5-3B+PICARD[20 ] 95.2 85.4 67.2 50.6 RASAT(T5-3B)+PICARD[17 ] 96.0 86.5 67.8 53.6 本文方法-T5-Large 89.1 81.6 62.6 51.8 本文方法-T5-Large+GT 92.7 87.2 71.3 56.6
为了验证模型的鲁棒性,在 Spider-DK和Spider-Syn数据集上进行实验,模式链接器未重新训练,即仍然使用基于SLSQL[6 ] 标注的Spider数据集训练的结果,实验结果见表10 . 这2个数据集更贴合实际的应用场景,Spider-DK 结合了一些领域知识,Spider-Syn模拟了用户不熟悉数据库的模式,在问题中没有准确提及模式词的情况. 实验结果显示,本文方法具有鲁棒性,在2个数据集上的表现均超过基线模型. ...
8
... 最近一些工作使用Text-to-Text的预训练模型T5[18 ] ,取得了不错的效果,与基于图的方法不同,基于T5的方法对编码器和解码器都采用基于Transformer的架构,不需要预定义的图、模式链接关系和基于语法的解码器. Shaw等[19 ] 的研究表明,对T5进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B的结果可以与当时最先进的模型Ryansql[7 ] 的结果相当. Scholak等[20 ] 提出的PICARD模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能. PICARD的T5-Base模型可以超越没有PICARD的T5-Large模型. Gao等[21 ] 提出由任务分解、知识获取和知识组合构成的3阶段框架,提升了模型获取通用SQL知识的能力,使其更具有泛化能力和鲁棒性. RASAT[17 ] 通过在多头自注意力中加入边的嵌入,为T5提供结构信息. Xie等[22 ] 将其他结构化知识数据任务(structured knowledge grounding, SKG)的知识注入到T5的多任务训练中,提高Text-to-SQL的性能. GRAPHIX-T5[23 ] 在T5的基础上增加图形感知层,以增强多跳推理能力,在保持T5强大的上下文编码能力的基础上,提高T5的结构编码能力. 这些工作都表明,T5中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5在Text-to-SQL任务上获得优异的表现. ...
... Comparison of SQL generation results
Tab.8 模型 EM/% EX/% T5-Base[19 ] 57.1 — T5-3B[19 ] 70.0 — Unifiedskg(T5-Base)[22 ] 58.1 60.1 Unifiedskg(T5-Large) [22 ] 66.6 68.3 Unifiedskg(T5-3B)[22 ] 71.8 74.4 T5-Base+PICARD[20 ] 68.5 68.4 T5-Large+PICARD[20 ] 69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9
为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
21 ]
70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... Comparison of EX accuracy on different difficulty levels
Tab.9 模型 EX/% easy medium hard extra hard TKK(T5-Large)[21 ] 89.5 76.5 52.9 45.2 T5-3B+PICARD[20 ] 95.2 85.4 67.2 50.6 RASAT(T5-3B)+PICARD[17 ] 96.0 86.5 67.8 53.6 本文方法-T5-Large 89.1 81.6 62.6 51.8 本文方法-T5-Large+GT 92.7 87.2 71.3 56.6
为了验证模型的鲁棒性,在 Spider-DK和Spider-Syn数据集上进行实验,模式链接器未重新训练,即仍然使用基于SLSQL[6 ] 标注的Spider数据集训练的结果,实验结果见表10 . 这2个数据集更贴合实际的应用场景,Spider-DK 结合了一些领域知识,Spider-Syn模拟了用户不熟悉数据库的模式,在问题中没有准确提及模式词的情况. 实验结果显示,本文方法具有鲁棒性,在2个数据集上的表现均超过基线模型. ...
... SQL generation results on Spider-DK and Spider-Syn
Tab.10 模型 Spider-DK Spider-Syn EM/% EX/% EM/% EX/% RAT-SQL+BERT[11 ] 40.9 — 48.2 — RAT-SQL+GRAPPA[29 ] 38.5 — 49.1 — T5-Base[21 ] — — 40.8 43.8 T5-Large[21 ] — — 53.1 57.4 TKK(T5-Base)[21 ] — — 44.2 47.7 TKK(T5-Large)[21 ] — — 55.1 60.5 本文方法-T5-Base 39.3 46.6 49.8 54.6 本文方法-T5-Large 48.2 55.3 56.0 60.9
4. 结 语 本文提出两阶段的模型以解决Text-to-SQL问题,通过模式链接器识别问题中提及的数据库表、列和值,将对齐信息融合到基于T5的生成器中,指导SQL生成. 模式链接器基于关系图注意力网络,根据问题句法依存树和模式项之间的内部关系构造图. 在构造问题图时,对依存关系进行合并和传播,有助于模型捕获长距离的依赖关系. 模型将模式链接和SQL生成解耦,以降低Text-to-SQL问题的复杂性,在Spider及其变体上的实验证明了该模型的性能. 下一步将对模式链接模块继续进行优化,提高SQL生成的准确率. ...
... [
21 ]
— — 53.1 57.4 TKK(T5-Base)[21 ] — — 44.2 47.7 TKK(T5-Large)[21 ] — — 55.1 60.5 本文方法-T5-Base 39.3 46.6 49.8 54.6 本文方法-T5-Large 48.2 55.3 56.0 60.9 4. 结 语 本文提出两阶段的模型以解决Text-to-SQL问题,通过模式链接器识别问题中提及的数据库表、列和值,将对齐信息融合到基于T5的生成器中,指导SQL生成. 模式链接器基于关系图注意力网络,根据问题句法依存树和模式项之间的内部关系构造图. 在构造问题图时,对依存关系进行合并和传播,有助于模型捕获长距离的依赖关系. 模型将模式链接和SQL生成解耦,以降低Text-to-SQL问题的复杂性,在Spider及其变体上的实验证明了该模型的性能. 下一步将对模式链接模块继续进行优化,提高SQL生成的准确率. ...
... [
21 ]
— — 44.2 47.7 TKK(T5-Large)[21 ] — — 55.1 60.5 本文方法-T5-Base 39.3 46.6 49.8 54.6 本文方法-T5-Large 48.2 55.3 56.0 60.9 4. 结 语 本文提出两阶段的模型以解决Text-to-SQL问题,通过模式链接器识别问题中提及的数据库表、列和值,将对齐信息融合到基于T5的生成器中,指导SQL生成. 模式链接器基于关系图注意力网络,根据问题句法依存树和模式项之间的内部关系构造图. 在构造问题图时,对依存关系进行合并和传播,有助于模型捕获长距离的依赖关系. 模型将模式链接和SQL生成解耦,以降低Text-to-SQL问题的复杂性,在Spider及其变体上的实验证明了该模型的性能. 下一步将对模式链接模块继续进行优化,提高SQL生成的准确率. ...
... [
21 ]
— — 55.1 60.5 本文方法-T5-Base 39.3 46.6 49.8 54.6 本文方法-T5-Large 48.2 55.3 56.0 60.9 4. 结 语 本文提出两阶段的模型以解决Text-to-SQL问题,通过模式链接器识别问题中提及的数据库表、列和值,将对齐信息融合到基于T5的生成器中,指导SQL生成. 模式链接器基于关系图注意力网络,根据问题句法依存树和模式项之间的内部关系构造图. 在构造问题图时,对依存关系进行合并和传播,有助于模型捕获长距离的依赖关系. 模型将模式链接和SQL生成解耦,以降低Text-to-SQL问题的复杂性,在Spider及其变体上的实验证明了该模型的性能. 下一步将对模式链接模块继续进行优化,提高SQL生成的准确率. ...
5
... 最近一些工作使用Text-to-Text的预训练模型T5[18 ] ,取得了不错的效果,与基于图的方法不同,基于T5的方法对编码器和解码器都采用基于Transformer的架构,不需要预定义的图、模式链接关系和基于语法的解码器. Shaw等[19 ] 的研究表明,对T5进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B的结果可以与当时最先进的模型Ryansql[7 ] 的结果相当. Scholak等[20 ] 提出的PICARD模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能. PICARD的T5-Base模型可以超越没有PICARD的T5-Large模型. Gao等[21 ] 提出由任务分解、知识获取和知识组合构成的3阶段框架,提升了模型获取通用SQL知识的能力,使其更具有泛化能力和鲁棒性. RASAT[17 ] 通过在多头自注意力中加入边的嵌入,为T5提供结构信息. Xie等[22 ] 将其他结构化知识数据任务(structured knowledge grounding, SKG)的知识注入到T5的多任务训练中,提高Text-to-SQL的性能. GRAPHIX-T5[23 ] 在T5的基础上增加图形感知层,以增强多跳推理能力,在保持T5强大的上下文编码能力的基础上,提高T5的结构编码能力. 这些工作都表明,T5中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5在Text-to-SQL任务上获得优异的表现. ...
... 本文方法与其他模型在Spider验证集上的SQL生成结果对比如表8 所示. 表中,“GT”表示不使用模式链接器预测的模式链接结果,而是使用标注的模式链接结果,即Ground Truth. 根据实验结果可见,本文方法在不同规模的T5模型上展现了较好的性能. 在加入第一阶段预测的模式链接结果后,本文方法较文献[19 ]在原始T5上的结果有了较大提升,EM值在T5-Base上提升了11.4%,在T5-Large上的结果与T5-3B上的结果相当. EM反映预测查询是否和标准查询在所有组件上完全一致,然而同一查询可以有多种实现方法,例如“SELECT a FROM t ORDER BY b DESC LIMIT 1”与“SELECT a FROM t WHERE b = (SELECT MAX(b) FROM t)”是完全等价的,因此EM存在将正例判负的情况,造成了EM和EX之间差距较大. 本文在T5-Large上的EX值超过了同规模的所有基线模型,甚至比Unifiedskg[22 ] 在T5-3B上的结果高1%. 实验证明,使用准确的模式链接信息可以显著提升模型的性能,在使用标注的模式链接结果后,本文方法在T5-Large上的结果甚至超过了RASAT[17 ] 在T5-3B上的结果. ...
... Comparison of SQL generation results
Tab.8 模型 EM/% EX/% T5-Base[19 ] 57.1 — T5-3B[19 ] 70.0 — Unifiedskg(T5-Base)[22 ] 58.1 60.1 Unifiedskg(T5-Large) [22 ] 66.6 68.3 Unifiedskg(T5-3B)[22 ] 71.8 74.4 T5-Base+PICARD[20 ] 68.5 68.4 T5-Large+PICARD[20 ] 69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9
为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
22 ]
66.6 68.3 Unifiedskg(T5-3B)[22 ] 71.8 74.4 T5-Base+PICARD[20 ] 68.5 68.4 T5-Large+PICARD[20 ] 69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
... [
22 ]
71.8 74.4 T5-Base+PICARD[20 ] 68.5 68.4 T5-Large+PICARD[20 ] 69.1 72.9 T5-3B+PICARD[20 ] 75.5 79.3 TKK(T5-Base)[21 ] 61.5 64.2 TKK(T5-Large)[21 ] 70.6 73.2 RASAT(T5-Base)[17 ] 60.4 61.3 RASAT(T5-Large)[17 ] 66.7 69.2 RASAT(T5-3B) [17 ] 72.6 76.6 RASAT(T5-3B) +PICARD [17 ] 75.3 80.5 本文方法-T5-Base 68.5 71.6 本文方法-T5-Base+GT 76.3 75.2 本文方法-T5-Large 69.9 75.4 本文方法-T5-Large+GT 79.2 80.9 为了显示模型在不同难度的查询上的生成能力,按照Spider数据集的样本划分规则,将查询分为4个级别:容易 (easy)、中等 (medium)、难 (hard)、很难 (extra hard),实验结果如表9 所示. 由实验结果可见,准确的模式链接可以提升难度较大的SQL生成问题的结果. 由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究. ...
1
... 最近一些工作使用Text-to-Text的预训练模型T5[18 ] ,取得了不错的效果,与基于图的方法不同,基于T5的方法对编码器和解码器都采用基于Transformer的架构,不需要预定义的图、模式链接关系和基于语法的解码器. Shaw等[19 ] 的研究表明,对T5进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B的结果可以与当时最先进的模型Ryansql[7 ] 的结果相当. Scholak等[20 ] 提出的PICARD模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能. PICARD的T5-Base模型可以超越没有PICARD的T5-Large模型. Gao等[21 ] 提出由任务分解、知识获取和知识组合构成的3阶段框架,提升了模型获取通用SQL知识的能力,使其更具有泛化能力和鲁棒性. RASAT[17 ] 通过在多头自注意力中加入边的嵌入,为T5提供结构信息. Xie等[22 ] 将其他结构化知识数据任务(structured knowledge grounding, SKG)的知识注入到T5的多任务训练中,提高Text-to-SQL的性能. GRAPHIX-T5[23 ] 在T5的基础上增加图形感知层,以增强多跳推理能力,在保持T5强大的上下文编码能力的基础上,提高T5的结构编码能力. 这些工作都表明,T5中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5在Text-to-SQL任务上获得优异的表现. ...
1
... 混合序列X 经基于Transformer的双向编码器(bidirectional encoder representation from transformers, BERT)[24 ] 编码,得到问题词和每个模式项单词的嵌入表示. 由于列名和表名都可能由多个单词组成,需要再经过一个门控循环单元(gate recurrent unit,GRU),得到每个列和表的初始表示. ...
1
... Text-to-SQL目前的主流数据集是Spider数据集[25 ] ,该数据集包含10 181条自然语言问题和5 693条SQL查询以及138个不同领域的200个数据库;其SQL语句覆盖了多表连接、分组、排序、嵌套查询等复杂操作,目前SOTA模型的准确度约为70%. Spider分为训练集、验证集和测试集,样本个数分别为7 000、1 034和2 134. 由于测试集未公开,使用验证集进行消融实验. 基于Spider数据集,SLSQL构建了模式链接语料库,对Spider训练集和验证集的每个实例注释了模式链接信息[6 ] . 使用SLSQL提供的标注数据训练模式链接器. ...
1
... 为了验证模型的鲁棒性,在Spider-DK[26 ] 和Spider-Syn[27 ] 数据集上进行实验. Spider-DK在Spider样本的基础上加入领域知识,用于评估模型融合知识的能力. Spider-Syn对Spider数据集中的问题进行同义词替换,特别是与数据库模式和值相关的问题词,评估模型对词汇变化的鲁棒性. ...
1
... 为了验证模型的鲁棒性,在Spider-DK[26 ] 和Spider-Syn[27 ] 数据集上进行实验. Spider-DK在Spider样本的基础上加入领域知识,用于评估模型融合知识的能力. Spider-Syn对Spider数据集中的问题进行同义词替换,特别是与数据库模式和值相关的问题词,评估模型对词汇变化的鲁棒性. ...
1
... 生成器的参数如下:实验使用的T5版本为T5-Base和T5-Large,采用Adafactor[28 ] 进行参数优化. T5-Base的batch_size为8,learn_rate为10−4 ;T5-Large的batch_size为4,learn_rate为5×10−5 . ...
1
... SQL generation results on Spider-DK and Spider-Syn
Tab.10 模型 Spider-DK Spider-Syn EM/% EX/% EM/% EX/% RAT-SQL+BERT[11 ] 40.9 — 48.2 — RAT-SQL+GRAPPA[29 ] 38.5 — 49.1 — T5-Base[21 ] — — 40.8 43.8 T5-Large[21 ] — — 53.1 57.4 TKK(T5-Base)[21 ] — — 44.2 47.7 TKK(T5-Large)[21 ] — — 55.1 60.5 本文方法-T5-Base 39.3 46.6 49.8 54.6 本文方法-T5-Large 48.2 55.3 56.0 60.9
4. 结 语 本文提出两阶段的模型以解决Text-to-SQL问题,通过模式链接器识别问题中提及的数据库表、列和值,将对齐信息融合到基于T5的生成器中,指导SQL生成. 模式链接器基于关系图注意力网络,根据问题句法依存树和模式项之间的内部关系构造图. 在构造问题图时,对依存关系进行合并和传播,有助于模型捕获长距离的依赖关系. 模型将模式链接和SQL生成解耦,以降低Text-to-SQL问题的复杂性,在Spider及其变体上的实验证明了该模型的性能. 下一步将对模式链接模块继续进行优化,提高SQL生成的准确率. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}