[1]
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems . Cambridge: MIT Press, 2014: 2672–2680.
[本文引用: 1]
[2]
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 1316–1324.
[本文引用: 7]
[3]
韩爽. 基于生成对抗网络的文本到图像生成技术研究[D]. 大庆: 东北石油大学, 2022.
[本文引用: 1]
HAN Shuang. Research on text-to-image generation techniques based on generative adversarial networks [D]. Daqing: Northeast Petroleum University, 2022.
[本文引用: 1]
[4]
QIAO T, ZHANG J, XU D, et al. Learn, imagine and create: text-to-image generation from prior knowledge [C]// Proceeding of the 33rd Conference on Neural Information Processing Systems . Vancouver: [s. n.], 2019: 887–897.
[5]
LIANG J, PEI W, LU F. CPGAN: content-parsing generative adversarial networks for text-to-image synthesis [C]// Proceeding of the 16th European Conference on Computer Vision . [S. l.]: Springer, 2020: 491–508.
[本文引用: 1]
[6]
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]// 2017 IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 5908–5916.
[本文引用: 4]
[7]
ZHANG H, XU T, LI H, et al StackGAN++: realistic image synthesis with stacked generative adversarial networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2018 , 41 (8 ): 1947 - 1962
[本文引用: 1]
[8]
QIAO T, ZHANG J, XU D, et al. MirrorGAN: learning text-to-image generation by redescription [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1505–1514.
[本文引用: 5]
[9]
TAO M, TANG H, WU F, et al. Df-GAN: a simple and effective baseline for text-to-image synthesis [C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans, 2022: 16515–16525.
[本文引用: 1]
[10]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03)[2023-09-17]. https://arxiv.org/pdf/2010.11929.pdf.
[本文引用: 1]
[11]
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// Proceedings of the 33rd International Conference on Machine Learning . New York: ACM, 2016: 1060–1069.
[本文引用: 1]
[12]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// 2017 IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2223–2232.
[本文引用: 1]
[13]
贺小峰, 毛琳, 杨大伟 文本生成图像中语义-空间特征增强算法
[J]. 大连民族大学学报 , 2022 , 24 (5 ): 401 - 406
[本文引用: 1]
HE Xiaofeng, MAO Lin, YANG Dawei Semantic-spatial feature enhancement algorithm for text-to-image generation
[J]. Journal of Dalian Minzu University , 2022 , 24 (5 ): 401 - 406
[本文引用: 1]
[14]
薛志杭, 许喆铭, 郎丛妍, 等 基于图像-文本语义一致性的文本生成图像方法
[J]. 计算机研究与发展 , 2023 , 60 (9 ): 2180 - 2190
XUE Zhihang, XU Zheming, LANG Congyan, et al Text-to-image generation method based on image-text semantic consistency
[J]. Journal of Computer Research and Development , 2023 , 60 (9 ): 2180 - 2190
[15]
吕文涵, 车进, 赵泽纬, 等. 基于动态卷积与文本数据增强的图像生成方法[EB/OL]. (2023-04-28)[2023-09-17]. https://doi.org/10.19678/j.issn.1000-3428.0066470.
[本文引用: 1]
[16]
SHEYNIN S, ASHUAL O, POLYAK A, et al. KNN-diffusion: image generation via large-scale retrieval [EB/OL]. (2022-10-02)[2023-09-17]. https://arxiv.org/pdf/2204.02849.pdf.
[本文引用: 3]
[17]
NICHOL A Q, DHARIWAL P, RAMESH A, et al. GLIDE: towards photorealistic image generation and editing with text-guided diffusion models [C]// International Conference on Machine Learning . Long Beach: IEEE, 2022: 16784–16804.
[本文引用: 1]
[18]
田枫, 孙小强, 刘芳, 等 融合双注意力与多标签的图像中文描述生成方法
[J]. 计算机系统应用 , 2021 , 30 (7 ): 32 - 40
[本文引用: 1]
TIAN Feng, SUN Xiaoqiang, LIU Fang, et al Chinese image caption with dual attention and multi-label image
[J]. Computer Systems and Applications , 2021 , 30 (7 ): 32 - 40
[本文引用: 1]
[19]
HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging [EB/OL]. (2015-08-09)[2023-09-17]. https://arxiv.org/pdf/1508.01991.pdf.
[本文引用: 1]
[20]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceeding of the 31st International Conference on Neural Information Processing Systems . Long Beach: [s.n.], 2017: 6000–6010.
[本文引用: 1]
[21]
MIRZA M, OSINDERO S. Conditional generative adversarial nets [EB/OL]. (2014-11-06)[2023-09-17]. https://arxiv.org/pdf/1411.1784.pdf.
[本文引用: 1]
[22]
WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD Birds-200-2011 dataset [EB/OL]. (2022-08-12)[2023-09-17]. https://authors.library.caltech.edu/27452/1/CUB_200_2011.pdf.
[本文引用: 1]
[23]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision . [S. l.]: Springer, 2014: 740–755.
[本文引用: 1]
[24]
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [J]. Proceedings of the 30th International Conference on Neural Information Processing Systems . Barcelona: [s. n.], 2016: 2234–2242.
[本文引用: 1]
[25]
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local nash equilibrium [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Long Beach: [s.n.], 2017: 6629–6640.
[本文引用: 1]
[26]
王家喻. 基于生成对抗网络的图像生成研究[D]. 合肥: 中国科学技术大学, 2021.
[本文引用: 1]
WANG Jiayu. Image generation based on generative adversarial networks [D]. Hefei: University of Science and Technology of China, 2021.
[本文引用: 1]
[27]
王蕾. 基于关联语义挖掘的文本生成图像算法研究[D]. 西安: 西安电子科技大学, 2020.
[本文引用: 1]
WANG Lei. Text-to-image synthesis based on semantic correlation mining [D]. Xi’an: Xidian University, 2020.
[本文引用: 1]
[28]
STAP D, BLEEKER M, IBRAHIMI S, et al. Conditional image generation and manipulation for user-specified content [EB/OL]. (2020-05-11)[2023-09-17]. https://arxiv.org/pdf/2005.04909.pdf.
[本文引用: 2]
[29]
ZHU M, PAN P, CHEN W, et al. DM-GAN: dynamic memory generative adversarial networks for text-to-image synthesis [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5802–5810.
[本文引用: 2]
[30]
YIN G, LIU B, SHENG L, et al. Semantics disentangling for text-to-image generation [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 2327–2336.
[本文引用: 1]
[31]
LIAO W, HU K, YANG M Y, et al. Text to image generation with semantic-spatial aware GAN [C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 18187–18196.
[本文引用: 2]
[32]
YE S, WANG H, TAN M, et al Recurrent affine transformation for text-to-image synthesis
[J]. IEEE Transactions on Multimedia , 2023 , 26 : 462 - 473
[本文引用: 2]
[33]
DING M, ZHENG W, HONG W, et al. Cogview2: faster and better text-to-image generation via hierarchical transformers [EB/OL]. (2022-05-27)[2023-09-17]. https://arxiv.org/pdf/2204.14217.pdf.
[本文引用: 2]
1
... 生成对抗网络[1 ] (generative adversarial networks,GAN)自问世以来,凭借其生成图像的真实性,将各个领域的生成类任务都带入快速发展时期. 文本生成图像方法在计算机辅助设计、辅助影视内容创作、图像编辑等领域的实用价值巨大,由此依据GAN改进的文本生成图像相关方法不断涌现[2 -5 ] . 为了确保从给定的文本描述中生成与语义一致的高质量图像,主流的文本生成图像方法[2 ,6 -8 ] 以堆叠式的GAN结构作为主干,通过额外加入如循环一致性网络[8 ] 、注意力机制网络[2 ] 的模型来学习高维空间中的文本特征与图像特征. ...
7
... 生成对抗网络[1 ] (generative adversarial networks,GAN)自问世以来,凭借其生成图像的真实性,将各个领域的生成类任务都带入快速发展时期. 文本生成图像方法在计算机辅助设计、辅助影视内容创作、图像编辑等领域的实用价值巨大,由此依据GAN改进的文本生成图像相关方法不断涌现[2 -5 ] . 为了确保从给定的文本描述中生成与语义一致的高质量图像,主流的文本生成图像方法[2 ,6 -8 ] 以堆叠式的GAN结构作为主干,通过额外加入如循环一致性网络[8 ] 、注意力机制网络[2 ] 的模型来学习高维空间中的文本特征与图像特征. ...
... [2 ,6 -8 ]以堆叠式的GAN结构作为主干,通过额外加入如循环一致性网络[8 ] 、注意力机制网络[2 ] 的模型来学习高维空间中的文本特征与图像特征. ...
... [2 ]的模型来学习高维空间中的文本特征与图像特征. ...
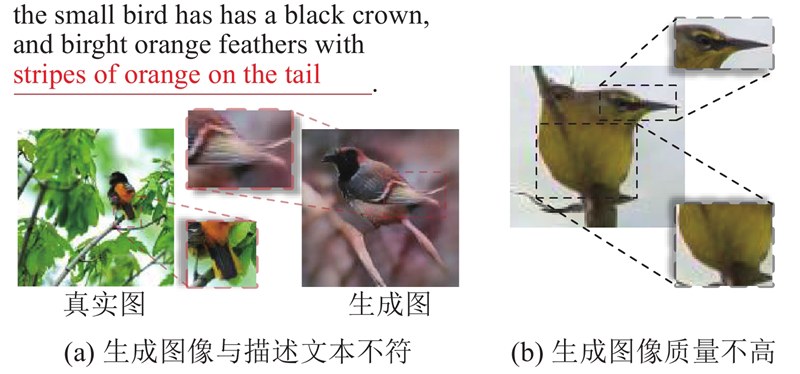
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
... 式中:$ L_G^2 $ $ L_D^2 $ $ L_G^{{\mathrm{DAMSM}}} $ [2 ] ,$ L_G^{{\mathrm{f}}} $ $ {\lambda _3} $ $ {\lambda _4} $
... 采用初始分数[24 ] (inception score,IS)、Fréchet初始距离[25 ] (Fréchet inception distance, FID)以及R-precision[2 ] RP来定性评估DFA-GAN模型的生成效果. IS通过计算生成图像的条件分布和边缘分布之间的Kullback-Leibler(KL)散度,来衡量图像的多样性和类别的一致性. IS的数值越大,表示生成图像的质量越高且更具多样性,表达式为 ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
1
... 在基于GAN的通过文本描述生成图像的方法中,通常先将整个文本描述编码为特征向量,经过与图像特征向量简单的拼接进行生成图像[3 ,18 ] ,导致文本特征与图像特征没有充分的结合. DFA-GAN在深度融合文本特征的图像生成阶段将文本特征和图像特征进行充分融合,以生成语义一致的图像. ...
1
... 在基于GAN的通过文本描述生成图像的方法中,通常先将整个文本描述编码为特征向量,经过与图像特征向量简单的拼接进行生成图像[3 ,18 ] ,导致文本特征与图像特征没有充分的结合. DFA-GAN在深度融合文本特征的图像生成阶段将文本特征和图像特征进行充分融合,以生成语义一致的图像. ...
1
... 生成对抗网络[1 ] (generative adversarial networks,GAN)自问世以来,凭借其生成图像的真实性,将各个领域的生成类任务都带入快速发展时期. 文本生成图像方法在计算机辅助设计、辅助影视内容创作、图像编辑等领域的实用价值巨大,由此依据GAN改进的文本生成图像相关方法不断涌现[2 -5 ] . 为了确保从给定的文本描述中生成与语义一致的高质量图像,主流的文本生成图像方法[2 ,6 -8 ] 以堆叠式的GAN结构作为主干,通过额外加入如循环一致性网络[8 ] 、注意力机制网络[2 ] 的模型来学习高维空间中的文本特征与图像特征. ...
4
... 生成对抗网络[1 ] (generative adversarial networks,GAN)自问世以来,凭借其生成图像的真实性,将各个领域的生成类任务都带入快速发展时期. 文本生成图像方法在计算机辅助设计、辅助影视内容创作、图像编辑等领域的实用价值巨大,由此依据GAN改进的文本生成图像相关方法不断涌现[2 -5 ] . 为了确保从给定的文本描述中生成与语义一致的高质量图像,主流的文本生成图像方法[2 ,6 -8 ] 以堆叠式的GAN结构作为主干,通过额外加入如循环一致性网络[8 ] 、注意力机制网络[2 ] 的模型来学习高维空间中的文本特征与图像特征. ...
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
... [
6 ]
3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17 在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
StackGAN++: realistic image synthesis with stacked generative adversarial networks
1
2018
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
5
... 生成对抗网络[1 ] (generative adversarial networks,GAN)自问世以来,凭借其生成图像的真实性,将各个领域的生成类任务都带入快速发展时期. 文本生成图像方法在计算机辅助设计、辅助影视内容创作、图像编辑等领域的实用价值巨大,由此依据GAN改进的文本生成图像相关方法不断涌现[2 -5 ] . 为了确保从给定的文本描述中生成与语义一致的高质量图像,主流的文本生成图像方法[2 ,6 -8 ] 以堆叠式的GAN结构作为主干,通过额外加入如循环一致性网络[8 ] 、注意力机制网络[2 ] 的模型来学习高维空间中的文本特征与图像特征. ...
... [8 ]、注意力机制网络[2 ] 的模型来学习高维空间中的文本特征与图像特征. ...
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
... [
8 ]
5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17 在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
1
... 尽管主流的文本生成图像方法取得了很多令人瞩目的成果,但仍然存在2个待解决的问题:1)堆叠式架构会导致网络中不同阶段的生成器相互纠缠,进而影响图像的生成质量;2)网络不能有效理解并融合文本特征和图像特征,导致生成图像与语义信息不一致. 有研究者使用以单级GAN为主干架构的模型去解决堆叠式架构生成图像质量低的问题,例如DF-GAN[9 ] . 但这类模型无法同时融合句特征和词特征,降低了生成图像和文本描述的一致性. 现有模型大多通过简单拼接文本特征和图像特征来学习融合文本特征和图像特征之间的特征,由于文本信息无法最大程度地融入生成图像,导致生成的图像与文本描述不一致. ...
1
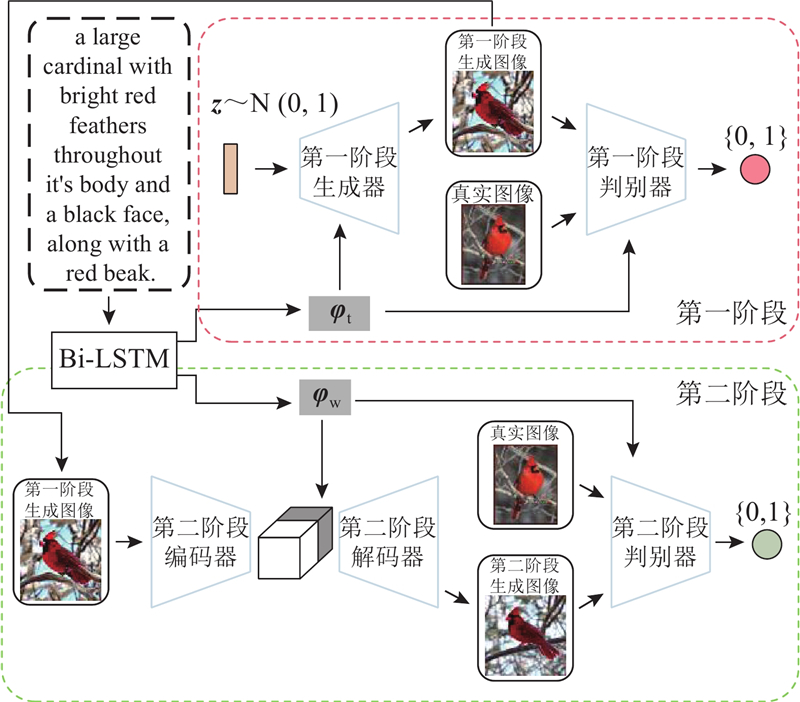
... 本研究提出深度融合注意力的生成对抗网络方法(generative adversarial network with deep fusion attention,DFA-GAN);采用两阶段模型生成图像,分别为深度融合文本特征的图像生成阶段和注意力机制优化图像生成阶段. 2个阶段都以单级GAN为主干,将第一阶段生成的初始模糊图像输入第二阶段,对初始图像进行高质量再生成. 为了解决堆叠式架构不同生成器之间相互纠缠导致最终生成低质量图像问题,分别训练DFA-GAN的2个阶段网络,同时网络模型都以单级GAN为主干架构,避免生成简单拼凑效果的图像. 在第一阶段的网络中,提出视觉文本融合模块(visual-text fusion block,VTFBlock)深度融合文本特征与图像特征,并在不同尺度的图像采样过程中,充分融合文本信息. 为了优化第一阶段生成的模糊图像,在第二阶段中采用改进的Vision Transformer[10 ] (ViT)对第一阶段的生成图像进行再编码,将ViT输出的图像特征与文本描述中的词特征融合,保证图像特征与文本特征在高维空间中保持语义一致. 使用ViT模型学习局部特征和全局特征之间的关联,不仅进行文本对应的图像区域优化,还进行图像整体优化,以确保DFA-GAN生成符合文本描述的高质量图像. ...
1
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
1
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
文本生成图像中语义-空间特征增强算法
1
2022
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
文本生成图像中语义-空间特征增强算法
1
2022
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
基于图像-文本语义一致性的文本生成图像方法
0
2023
基于图像-文本语义一致性的文本生成图像方法
0
2023
1
... Reed等[11 ] 将GAN应用于文本生成图像任务提出的GAN-INT-CLS模型,引发基于GAN的文本生成图像方法的研究热潮. 在文本生成图像任务中,为了能够生成符合文本描述的高质量图像,不断有新的改进方法被提出,包括采用多层次体系嵌套GAN方法、加入注意力机制模型、利用循环一致性方法等. Zhang等[7 ] 采用多层次体系嵌套方法提出的StackGAN模型[6 ] 和StackGAN++模型提升了生成图像的分辨率,但由于没有深度的融合文本信息和图像信息,导致生成的图像与描述文本语义产生较大偏差,如图1 (a)所示. AttnGAN模型[2 ] 提出将文本描述中的词特征和图像特征以交叉注意力编码的方式进行融合,该模型同样采用多层次体系嵌套GAN作为主干,除了第一层GAN网络用于融合文本整体特征外,其余嵌套的GAN网络都是利用图像特征与词特征的注意力权重将文本特征动态地融合到图像特征中. 在AttnGAN模型取得的显著成果下,研究者在AttnGAN模型的基础上不断提出改进. MirrorGAN模型[8 ] 的提出受了CycleGAN模型[12 ] 的启发,循环一致性方法被引入文本生成图像任务中,极大提升了生成图像的文本图像语义一致性. 贺小峰等[13 -15 ] 提出的模型均以多层次体系嵌套GAN为主干,生成图像质量不高,如图1 (b)所示. ...
3
... DF-GAN模型以单级GAN为主干,由匹配感知梯度惩罚和单向输出组成的判别器使得生成图像能够又快又好地收敛到与文本匹配的真实数据上. 该模型能够深度融合文本图像块,帮助模型学习文本描述和图像之间的联系,以引导文本特征与图像特征融合. 由于单级GAN为主干,输入内容有限,DF-GAN模型不能同时关注整体文本信息与词级信息,导致生成图像与描述文本之间出现语义不一致的情况. Sheynin等[16 -17 ] 采用扩散模型和自回归模型来执行文本生成图像任务,相较于基于GAN的文本生成图像方法,这2种模型在生成的图像方面有着显著能力,不仅文本与图像的匹配度高,而且生成图像的质量高. 由于基于GAN的生成方法具备训练时间短、模型规模小的特点,值得持续研究和改进. ...
... 如表1 所示DFA-GAN模型在2个数据集上的表现都优于传统的文本生成图像方法. 第一阶段生成图像的IS数值已大于StackGAN模型、StackGAN++模型和AttnGAN模型的IS数值,仅比MirrorGAN模型低0.03. 经过第二阶段的训练后,最终的生成图像的IS比第一阶段的IS提升了约17.88%,比DF-GAN模型的提升了4.70%,比textStyleGAN模型[28 ] 的提升了11.72%. 相比已有的文本生成图像方法,DFA-GAN的IS并未有明显提升,本研究认为该网络在生成图像的真实性和多样性角度上与现有的基于GAN的文本生成图像方法基本一致. 对比CUB数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的降低了约31.83%, 比DF-GAN模型的降低了25.99%,比DM-GAN模型[29 ] 的降低了31.88%. 对比COCO数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的生成图像降低了约23.60%,比DF-GAN模型的小0.15. 同样是充分融合文本与图像特征生成图像,相比改进DF-GAN方法的SSA-GAN[31 ] 和RAT-GAN[32 ] ,DFA-GAN在各项数值上更加优秀,RAT-GAN在COCO数据集上的FID比DFA-GAN模型的降低了4.57,本研究认为这由于RAT-GAN更注重学习相关的复杂图像特征,而DFA-GAN模型更注重整体图像的一致性导致的. 由表可以看出,DFA-GAN模型不仅第一阶段的生成图像评价指标评分较为优异,而且模型在第二阶段的指标评分较第一阶段的有大幅提升,证明DFA-GAN模型分为2个阶段训练是有效的. DFA-GAN模型在CUB数据集上的评价指标较在COCO数据集上的更优,本研究认为产生这种情况的原因是CUB数据集中的内容相比COCO数据集的更集中于少数几个类别. 对于多目标的复杂场景,DFA-GAN模型对于图像中多个目标的特征提取学习的力度不够,不能学习到文本对应图像内容更深层次、更细节的特征. 除了生成对抗网络方法中的模型,表中还有采用自回归和扩散的模型. 对比COCO数据集的FID数值,DFA-GAN比采用自回归模型的CogView2[33 ] 大1.47,比采用扩散模型的KNN-Diffusion[16 ] 大2.51. 数据结果表明,虽然采用自回归和扩散模型方法能够生成真实、符合文本描述的图像,但是DFA-GAN模型不仅体积更小,计算成本也更低,其参数总量相对于CogView2和KNN-Diffusion更少. ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
1
... DF-GAN模型以单级GAN为主干,由匹配感知梯度惩罚和单向输出组成的判别器使得生成图像能够又快又好地收敛到与文本匹配的真实数据上. 该模型能够深度融合文本图像块,帮助模型学习文本描述和图像之间的联系,以引导文本特征与图像特征融合. 由于单级GAN为主干,输入内容有限,DF-GAN模型不能同时关注整体文本信息与词级信息,导致生成图像与描述文本之间出现语义不一致的情况. Sheynin等[16 -17 ] 采用扩散模型和自回归模型来执行文本生成图像任务,相较于基于GAN的文本生成图像方法,这2种模型在生成的图像方面有着显著能力,不仅文本与图像的匹配度高,而且生成图像的质量高. 由于基于GAN的生成方法具备训练时间短、模型规模小的特点,值得持续研究和改进. ...
融合双注意力与多标签的图像中文描述生成方法
1
2021
... 在基于GAN的通过文本描述生成图像的方法中,通常先将整个文本描述编码为特征向量,经过与图像特征向量简单的拼接进行生成图像[3 ,18 ] ,导致文本特征与图像特征没有充分的结合. DFA-GAN在深度融合文本特征的图像生成阶段将文本特征和图像特征进行充分融合,以生成语义一致的图像. ...
融合双注意力与多标签的图像中文描述生成方法
1
2021
... 在基于GAN的通过文本描述生成图像的方法中,通常先将整个文本描述编码为特征向量,经过与图像特征向量简单的拼接进行生成图像[3 ,18 ] ,导致文本特征与图像特征没有充分的结合. DFA-GAN在深度融合文本特征的图像生成阶段将文本特征和图像特征进行充分融合,以生成语义一致的图像. ...
1
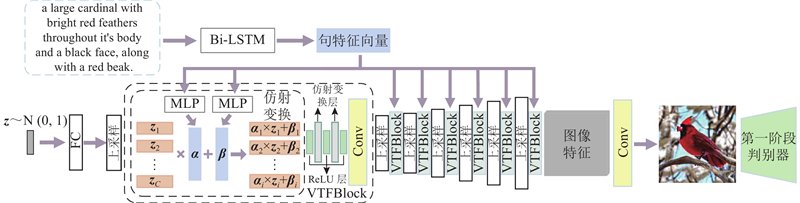
... 描述文本须进行预处理,文本编码器采用双向长短时记忆网络[19 ] (bi-directional long short-term memory,Bi-LSTM)来提取${{\bf\textit{φ}}_{\mathrm{t}}}$ z ${{\bf\textit{φ}}_{\mathrm{t}}}$ 图3 所示,该阶段生成器中共有7个上采样层,每个上采样层之间包含1个VTFBlock. VTFBlock由3个仿射变换层和ReLU层堆叠拼接组成,在经过上采样层逐层提取不同尺度的图像特征后,通过仿射变换将文本特征条件充分与不同尺度的图像特征融合,使得模型能够学习到文本语义与图像之间的深层次联系. 将ReLU层穿插式地加入VTFBlock,目的是在仿射变换造成的文本与图像线性关联中带入非线性的变化,从而更好地拟合文本特征与图像特征,这样不仅扩大了文本语义的表示空间,而且提升了视觉特征的多样性. ...
1
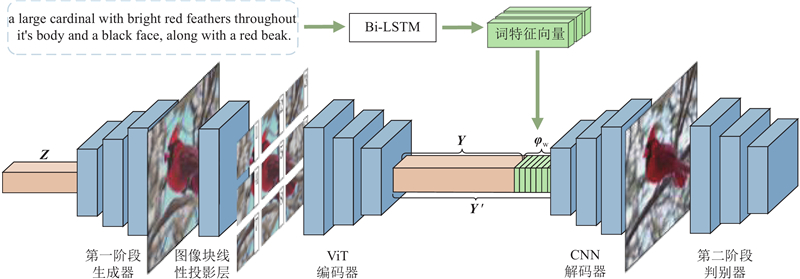
... 式中:$ {\boldsymbol{E}} \in {{\bf{R}}^{{p^2} \times C \times K}} $ $ {{\boldsymbol{E}}_{{\mathrm{pos}}}} \in {{\bf{R}}^{(N+1) \times K}} $ $ {\mathrm{LN}}\;( \cdot ) $ $N$ ${p^2}$ ${{\boldsymbol{x}}_{\mathrm{p}}} \in {{\bf{R}}^{N \times ({P^2} \times C)}}$ . 在Transformer结构[20 ] 中所有层都使用相同的潜在空间向量大小,为此将输入的图像块通过可训练的线性变换映射到K 维向量空间中. ViT编码器由 L 个Transformer编码器块组成,每个编码器块的输入$ {{{{\boldsymbol{y}}}}_{l - 1}} $ $ {{{{\boldsymbol{y}}}}_l } $ . 得到图像特征Y ${{\bf\textit{φ}}_{\mathrm{w}}}$ ${{{\boldsymbol{Y}}'}}$
1
... 式中:$L_G^1$ $L_D^1$ $ L_G^{{\mathrm{un}}} $ $ L_D^{{\mathrm{un}}} $ $ L_G^{{\mathrm{con}}} $ $ L_D^{{\mathrm{con}}} $ [21 ] ,作用是使生成图像更加贴合文本语义; $ L_G^{{\mathrm{cls}}} $ $ L_D^{{\mathrm{cls}}} $ $ {\lambda _1} $ $ {\lambda _2} $
1
... 在CUB鸟类数据集[22 ] 和COCO多目标场景数据集[23 ] 上评估DFA-GAN模型. CUB数据集有11 788张包含200种鸟类的图像,每张鸟类图像有10句相对应的描述文本. 该数据集中的图像均为鸟类的特写图像,图像的目标单一,背景简单. COCO数据集包含80 000张用于训练的图像和40 000张用于测试的图像,每张图像都对应5个描述文本的句子. 在COCO数据集中平均每张图像包含3.5个类别和7.7个实例目标,图像大多场景复杂,图像的目标小且多. ...
1
... 在CUB鸟类数据集[22 ] 和COCO多目标场景数据集[23 ] 上评估DFA-GAN模型. CUB数据集有11 788张包含200种鸟类的图像,每张鸟类图像有10句相对应的描述文本. 该数据集中的图像均为鸟类的特写图像,图像的目标单一,背景简单. COCO数据集包含80 000张用于训练的图像和40 000张用于测试的图像,每张图像都对应5个描述文本的句子. 在COCO数据集中平均每张图像包含3.5个类别和7.7个实例目标,图像大多场景复杂,图像的目标小且多. ...
1
... 采用初始分数[24 ] (inception score,IS)、Fréchet初始距离[25 ] (Fréchet inception distance, FID)以及R-precision[2 ] RP来定性评估DFA-GAN模型的生成效果. IS通过计算生成图像的条件分布和边缘分布之间的Kullback-Leibler(KL)散度,来衡量图像的多样性和类别的一致性. IS的数值越大,表示生成图像的质量越高且更具多样性,表达式为 ...
1
... 采用初始分数[24 ] (inception score,IS)、Fréchet初始距离[25 ] (Fréchet inception distance, FID)以及R-precision[2 ] RP来定性评估DFA-GAN模型的生成效果. IS通过计算生成图像的条件分布和边缘分布之间的Kullback-Leibler(KL)散度,来衡量图像的多样性和类别的一致性. IS的数值越大,表示生成图像的质量越高且更具多样性,表达式为 ...
1
... 式中:$ {{\boldsymbol{\mu }}} $ $ {\overset{\frown}{{{\boldsymbol{\mu}} }}} $ $ \displaystyle\sum {{{\boldsymbol{x}}}} $ $ \displaystyle\sum {{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{{\boldsymbol{x}}} }}} $ [26 ] .RP衡量生成图像与对应文本描述之间的生成准确率. 评估生成图像与文本描述是否对应,须将提取的图像特征和文本特征的检索结果进行排序. RP的数值越大,表示生成图像与给定文本描述越相关. ...
1
... 式中:$ {{\boldsymbol{\mu }}} $ $ {\overset{\frown}{{{\boldsymbol{\mu}} }}} $ $ \displaystyle\sum {{{\boldsymbol{x}}}} $ $ \displaystyle\sum {{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{{\boldsymbol{x}}} }}} $ [26 ] .RP衡量生成图像与对应文本描述之间的生成准确率. 评估生成图像与文本描述是否对应,须将提取的图像特征和文本特征的检索结果进行排序. RP的数值越大,表示生成图像与给定文本描述越相关. ...
1
... 实验将在2个数据集中对比不同模型的图像生成效果. 为了计算IS和FID,从测试数据集中随机选择文本描述交由每个模型,生成分辨率为256×256的30 000张图像进行对比[27 ] . ...
1
... 实验将在2个数据集中对比不同模型的图像生成效果. 为了计算IS和FID,从测试数据集中随机选择文本描述交由每个模型,生成分辨率为256×256的30 000张图像进行对比[27 ] . ...
2
... 如表1 所示DFA-GAN模型在2个数据集上的表现都优于传统的文本生成图像方法. 第一阶段生成图像的IS数值已大于StackGAN模型、StackGAN++模型和AttnGAN模型的IS数值,仅比MirrorGAN模型低0.03. 经过第二阶段的训练后,最终的生成图像的IS比第一阶段的IS提升了约17.88%,比DF-GAN模型的提升了4.70%,比textStyleGAN模型[28 ] 的提升了11.72%. 相比已有的文本生成图像方法,DFA-GAN的IS并未有明显提升,本研究认为该网络在生成图像的真实性和多样性角度上与现有的基于GAN的文本生成图像方法基本一致. 对比CUB数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的降低了约31.83%, 比DF-GAN模型的降低了25.99%,比DM-GAN模型[29 ] 的降低了31.88%. 对比COCO数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的生成图像降低了约23.60%,比DF-GAN模型的小0.15. 同样是充分融合文本与图像特征生成图像,相比改进DF-GAN方法的SSA-GAN[31 ] 和RAT-GAN[32 ] ,DFA-GAN在各项数值上更加优秀,RAT-GAN在COCO数据集上的FID比DFA-GAN模型的降低了4.57,本研究认为这由于RAT-GAN更注重学习相关的复杂图像特征,而DFA-GAN模型更注重整体图像的一致性导致的. 由表可以看出,DFA-GAN模型不仅第一阶段的生成图像评价指标评分较为优异,而且模型在第二阶段的指标评分较第一阶段的有大幅提升,证明DFA-GAN模型分为2个阶段训练是有效的. DFA-GAN模型在CUB数据集上的评价指标较在COCO数据集上的更优,本研究认为产生这种情况的原因是CUB数据集中的内容相比COCO数据集的更集中于少数几个类别. 对于多目标的复杂场景,DFA-GAN模型对于图像中多个目标的特征提取学习的力度不够,不能学习到文本对应图像内容更深层次、更细节的特征. 除了生成对抗网络方法中的模型,表中还有采用自回归和扩散的模型. 对比COCO数据集的FID数值,DFA-GAN比采用自回归模型的CogView2[33 ] 大1.47,比采用扩散模型的KNN-Diffusion[16 ] 大2.51. 数据结果表明,虽然采用自回归和扩散模型方法能够生成真实、符合文本描述的图像,但是DFA-GAN模型不仅体积更小,计算成本也更低,其参数总量相对于CogView2和KNN-Diffusion更少. ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
2
... 如表1 所示DFA-GAN模型在2个数据集上的表现都优于传统的文本生成图像方法. 第一阶段生成图像的IS数值已大于StackGAN模型、StackGAN++模型和AttnGAN模型的IS数值,仅比MirrorGAN模型低0.03. 经过第二阶段的训练后,最终的生成图像的IS比第一阶段的IS提升了约17.88%,比DF-GAN模型的提升了4.70%,比textStyleGAN模型[28 ] 的提升了11.72%. 相比已有的文本生成图像方法,DFA-GAN的IS并未有明显提升,本研究认为该网络在生成图像的真实性和多样性角度上与现有的基于GAN的文本生成图像方法基本一致. 对比CUB数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的降低了约31.83%, 比DF-GAN模型的降低了25.99%,比DM-GAN模型[29 ] 的降低了31.88%. 对比COCO数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的生成图像降低了约23.60%,比DF-GAN模型的小0.15. 同样是充分融合文本与图像特征生成图像,相比改进DF-GAN方法的SSA-GAN[31 ] 和RAT-GAN[32 ] ,DFA-GAN在各项数值上更加优秀,RAT-GAN在COCO数据集上的FID比DFA-GAN模型的降低了4.57,本研究认为这由于RAT-GAN更注重学习相关的复杂图像特征,而DFA-GAN模型更注重整体图像的一致性导致的. 由表可以看出,DFA-GAN模型不仅第一阶段的生成图像评价指标评分较为优异,而且模型在第二阶段的指标评分较第一阶段的有大幅提升,证明DFA-GAN模型分为2个阶段训练是有效的. DFA-GAN模型在CUB数据集上的评价指标较在COCO数据集上的更优,本研究认为产生这种情况的原因是CUB数据集中的内容相比COCO数据集的更集中于少数几个类别. 对于多目标的复杂场景,DFA-GAN模型对于图像中多个目标的特征提取学习的力度不够,不能学习到文本对应图像内容更深层次、更细节的特征. 除了生成对抗网络方法中的模型,表中还有采用自回归和扩散的模型. 对比COCO数据集的FID数值,DFA-GAN比采用自回归模型的CogView2[33 ] 大1.47,比采用扩散模型的KNN-Diffusion[16 ] 大2.51. 数据结果表明,虽然采用自回归和扩散模型方法能够生成真实、符合文本描述的图像,但是DFA-GAN模型不仅体积更小,计算成本也更低,其参数总量相对于CogView2和KNN-Diffusion更少. ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
1
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
2
... 如表1 所示DFA-GAN模型在2个数据集上的表现都优于传统的文本生成图像方法. 第一阶段生成图像的IS数值已大于StackGAN模型、StackGAN++模型和AttnGAN模型的IS数值,仅比MirrorGAN模型低0.03. 经过第二阶段的训练后,最终的生成图像的IS比第一阶段的IS提升了约17.88%,比DF-GAN模型的提升了4.70%,比textStyleGAN模型[28 ] 的提升了11.72%. 相比已有的文本生成图像方法,DFA-GAN的IS并未有明显提升,本研究认为该网络在生成图像的真实性和多样性角度上与现有的基于GAN的文本生成图像方法基本一致. 对比CUB数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的降低了约31.83%, 比DF-GAN模型的降低了25.99%,比DM-GAN模型[29 ] 的降低了31.88%. 对比COCO数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的生成图像降低了约23.60%,比DF-GAN模型的小0.15. 同样是充分融合文本与图像特征生成图像,相比改进DF-GAN方法的SSA-GAN[31 ] 和RAT-GAN[32 ] ,DFA-GAN在各项数值上更加优秀,RAT-GAN在COCO数据集上的FID比DFA-GAN模型的降低了4.57,本研究认为这由于RAT-GAN更注重学习相关的复杂图像特征,而DFA-GAN模型更注重整体图像的一致性导致的. 由表可以看出,DFA-GAN模型不仅第一阶段的生成图像评价指标评分较为优异,而且模型在第二阶段的指标评分较第一阶段的有大幅提升,证明DFA-GAN模型分为2个阶段训练是有效的. DFA-GAN模型在CUB数据集上的评价指标较在COCO数据集上的更优,本研究认为产生这种情况的原因是CUB数据集中的内容相比COCO数据集的更集中于少数几个类别. 对于多目标的复杂场景,DFA-GAN模型对于图像中多个目标的特征提取学习的力度不够,不能学习到文本对应图像内容更深层次、更细节的特征. 除了生成对抗网络方法中的模型,表中还有采用自回归和扩散的模型. 对比COCO数据集的FID数值,DFA-GAN比采用自回归模型的CogView2[33 ] 大1.47,比采用扩散模型的KNN-Diffusion[16 ] 大2.51. 数据结果表明,虽然采用自回归和扩散模型方法能够生成真实、符合文本描述的图像,但是DFA-GAN模型不仅体积更小,计算成本也更低,其参数总量相对于CogView2和KNN-Diffusion更少. ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
Recurrent affine transformation for text-to-image synthesis
2
2023
... 如表1 所示DFA-GAN模型在2个数据集上的表现都优于传统的文本生成图像方法. 第一阶段生成图像的IS数值已大于StackGAN模型、StackGAN++模型和AttnGAN模型的IS数值,仅比MirrorGAN模型低0.03. 经过第二阶段的训练后,最终的生成图像的IS比第一阶段的IS提升了约17.88%,比DF-GAN模型的提升了4.70%,比textStyleGAN模型[28 ] 的提升了11.72%. 相比已有的文本生成图像方法,DFA-GAN的IS并未有明显提升,本研究认为该网络在生成图像的真实性和多样性角度上与现有的基于GAN的文本生成图像方法基本一致. 对比CUB数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的降低了约31.83%, 比DF-GAN模型的降低了25.99%,比DM-GAN模型[29 ] 的降低了31.88%. 对比COCO数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的生成图像降低了约23.60%,比DF-GAN模型的小0.15. 同样是充分融合文本与图像特征生成图像,相比改进DF-GAN方法的SSA-GAN[31 ] 和RAT-GAN[32 ] ,DFA-GAN在各项数值上更加优秀,RAT-GAN在COCO数据集上的FID比DFA-GAN模型的降低了4.57,本研究认为这由于RAT-GAN更注重学习相关的复杂图像特征,而DFA-GAN模型更注重整体图像的一致性导致的. 由表可以看出,DFA-GAN模型不仅第一阶段的生成图像评价指标评分较为优异,而且模型在第二阶段的指标评分较第一阶段的有大幅提升,证明DFA-GAN模型分为2个阶段训练是有效的. DFA-GAN模型在CUB数据集上的评价指标较在COCO数据集上的更优,本研究认为产生这种情况的原因是CUB数据集中的内容相比COCO数据集的更集中于少数几个类别. 对于多目标的复杂场景,DFA-GAN模型对于图像中多个目标的特征提取学习的力度不够,不能学习到文本对应图像内容更深层次、更细节的特征. 除了生成对抗网络方法中的模型,表中还有采用自回归和扩散的模型. 对比COCO数据集的FID数值,DFA-GAN比采用自回归模型的CogView2[33 ] 大1.47,比采用扩散模型的KNN-Diffusion[16 ] 大2.51. 数据结果表明,虽然采用自回归和扩散模型方法能够生成真实、符合文本描述的图像,但是DFA-GAN模型不仅体积更小,计算成本也更低,其参数总量相对于CogView2和KNN-Diffusion更少. ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...
2
... 如表1 所示DFA-GAN模型在2个数据集上的表现都优于传统的文本生成图像方法. 第一阶段生成图像的IS数值已大于StackGAN模型、StackGAN++模型和AttnGAN模型的IS数值,仅比MirrorGAN模型低0.03. 经过第二阶段的训练后,最终的生成图像的IS比第一阶段的IS提升了约17.88%,比DF-GAN模型的提升了4.70%,比textStyleGAN模型[28 ] 的提升了11.72%. 相比已有的文本生成图像方法,DFA-GAN的IS并未有明显提升,本研究认为该网络在生成图像的真实性和多样性角度上与现有的基于GAN的文本生成图像方法基本一致. 对比CUB数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的降低了约31.83%, 比DF-GAN模型的降低了25.99%,比DM-GAN模型[29 ] 的降低了31.88%. 对比COCO数据集的FID数值,DFA-GAN模型第二阶段比第一阶段的生成图像降低了约23.60%,比DF-GAN模型的小0.15. 同样是充分融合文本与图像特征生成图像,相比改进DF-GAN方法的SSA-GAN[31 ] 和RAT-GAN[32 ] ,DFA-GAN在各项数值上更加优秀,RAT-GAN在COCO数据集上的FID比DFA-GAN模型的降低了4.57,本研究认为这由于RAT-GAN更注重学习相关的复杂图像特征,而DFA-GAN模型更注重整体图像的一致性导致的. 由表可以看出,DFA-GAN模型不仅第一阶段的生成图像评价指标评分较为优异,而且模型在第二阶段的指标评分较第一阶段的有大幅提升,证明DFA-GAN模型分为2个阶段训练是有效的. DFA-GAN模型在CUB数据集上的评价指标较在COCO数据集上的更优,本研究认为产生这种情况的原因是CUB数据集中的内容相比COCO数据集的更集中于少数几个类别. 对于多目标的复杂场景,DFA-GAN模型对于图像中多个目标的特征提取学习的力度不够,不能学习到文本对应图像内容更深层次、更细节的特征. 除了生成对抗网络方法中的模型,表中还有采用自回归和扩散的模型. 对比COCO数据集的FID数值,DFA-GAN比采用自回归模型的CogView2[33 ] 大1.47,比采用扩散模型的KNN-Diffusion[16 ] 大2.51. 数据结果表明,虽然采用自回归和扩散模型方法能够生成真实、符合文本描述的图像,但是DFA-GAN模型不仅体积更小,计算成本也更低,其参数总量相对于CogView2和KNN-Diffusion更少. ...
... Comparison of evaluation indexes of text-to-image generation methods in two datasets
Tab.1 模型 CUB COCO IS FID FID StackGAN[6 ] 3.70 35.51 74.05 StackGAN++[6 ] 3.84 — — AttnGAN[2 ] 4.36 24.37 35.49 MirrorGAN[8 ] 4.56 18.34 34.71 textStyleGAN[28 ] 4.78 — — DM-GAN[29 ] 4.75 16.09 32.64 SD-GAN[30 ] 4.67 — — DF-GAN[8 ] 5.10 14.81 19.32 SSA-GAN[31 ] 5.17 15.61 19.37 RAT-GAN[32 ] 5.36 13.91 14.60 CogView2[33 ] — — 17.70 KNN-Diffusion[16 ] — — 16.66 DFA-GAN-第一阶段 4.53 16.07 25.09 DFA-GAN-第二阶段 5.34 10.96 19.17
在CUB数据集上进行消融实验,将传统网络AttnGAN和DF-GAN分别与DFA-GAN第二阶段网络组合后与DFA-GAN进行对比,结果如表2 所示. 与原网络相比,AttnGAN加入DFA-GAN第二阶段网络的IS数值增加了0.75,同样DF-GAN的IS指标也提升了0.22,进一步说明DFA-GAN第二阶段网络可以优化生成图像的质量. 对比RP的数值,DF-GAN在加入DFA-GAN第二网络后由原本的44.83提升至70.80. DFA-GAN的IS数值与传统网络的基本一致,但RP高于传统网络,本研究认为原因是该网络更关注文本图像一致性. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}