[16]
XIE C, KOYEJO S, GUPTA I. Zeno++: robust fully asynchronous SGD [C]// International Conference on Machine Learning . Vienna: PMLR, 2020: 10495−10503.
[本文引用: 2]
[17]
SO J, GÜLER B, AVESTIMEHR A S Byzantine-resilient secure federated learning
[J]. IEEE Journal on Selected Areas in Communications , 2020 , 39 (7 ): 2168 - 2181
[本文引用: 1]
[18]
WANG H, MUÑOZ-GONZÁLEZ L, EKLUND D, et al. Non-IID data re-balancing at IoT edge with peer-to-peer federated learning for anomaly detection [C]// Proceedings of the 14th ACM Conference on Security and Privacy in Wireless and Mobile Networks . New York: Association for Computing Machinery, 2021: 153−163.
[本文引用: 1]
[19]
KANG J, XIONG Z, NIYATO D, et al Reliable federated learning for mobile networks
[J]. IEEE Wireless Communications , 2020 , 27 (2 ): 72 - 80
DOI:10.1109/MWC.001.1900119
[本文引用: 1]
[20]
GHOLAMI A, TORKZABAN N, BARAS J S. Trusted decentralized federated learning [C]// 2022 IEEE 19th Annual Consumer Communications and Networking Conference (CCNC) . Las Vegas: IEEE, 2022: 1−6.
[本文引用: 1]
[21]
ZHAO Y, ZHAO J, JIANG L, et al Privacy-preserving blockchain-based federated learning for IoT devices
[J]. IEEE Internet of Things Journal , 2020 , 8 (3 ): 1817 - 1829
[本文引用: 1]
[22]
LU Y, HUANG X, ZHANG K, et al Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles
[J]. IEEE Transactions on Vehicular Technology , 2020 , 69 (4 ): 4298 - 4311
DOI:10.1109/TVT.2020.2973651
[本文引用: 1]
[23]
肖丹. 去中心联邦学习中抗女巫和拜占庭攻击的研究[D]. 西安: 西安电子科技大学, 2022.
[本文引用: 1]
XIAO Dan. A study of resistance to witch and Byzantine attacks in decentralized federal learning [D]. Xi'an: Xi'an University of Electronic Science and Technology, 2022.
[本文引用: 1]
[24]
李丽萍. 基于模型聚合的分布式拜占庭鲁棒优化算法研究[D]. 安徽: 中国科学技术大学, 2020.
[本文引用: 1]
LI Liping. Research on distributed Byzantine robust optimization algorithm based on model aggregation [D]. Anhui: University of Science and Technology of China, 2020.
[本文引用: 1]
[25]
POLYAK B T Gradient methods for the minimisation of functionals
[J]. USSR Computational Mathematics and Mathematical Physics , 1963 , 3 (4 ): 864 - 878
DOI:10.1016/0041-5553(63)90382-3
[本文引用: 1]
[1]
MCMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [C]// Artificial Intelligence and Statistics . Lauderdale: PMLR, 2017: 1273−1282.
[本文引用: 4]
[2]
LI T, SAHU A K, ZAHEER M, et al Federated optimization in heterogeneous networks
[J]. Proceedings of Machine Learning and Systems , 2020 , 2 : 429 - 450
[本文引用: 1]
[26]
刘铁岩, 陈薇, 王太峰, 等. 分布式机器学习算法理论与实践[M]. 北京: 机械工业出版社, 2018.
[本文引用: 1]
[27]
KRIZHEVSKY A. Learning multiple layers of features from tiny images [D]. Toronto: University of Toronto, 2009.
[本文引用: 1]
[3]
GHOLAMI A, TORKZABAN N, BARAS J S, et al. Joint mobility-aware UAV placement and routing in multi-hop UAV relaying systems [C]// Ad Hoc Networks: 12th EAI International Conference . Paris: Springer International Publishing, 2021: 55−69.
[本文引用: 1]
[4]
GAO H, HUANG H. Periodic stochastic gradient descent with momentum for decentralized training [EB/OL]. (2020−08−24). https://arxiv.org/abs/2008.10435.
[本文引用: 2]
[28]
DENG L The mnist database of handwritten digit images for machine learning research [best of the web]
[J]. IEEE Signal Processing Magazine , 2012 , 29 (6 ): 141 - 142
DOI:10.1109/MSP.2012.2211477
[本文引用: 1]
[29]
CHEN T, LI M, LI Y, et al. Mxnet: a flexible and efficient machine learning library for heterogeneous distributed systems [EB/OL]. (2015−12−03). https://doi.org/10.48550/arXiv.1512.01274.
[本文引用: 1]
[5]
LI X, YANG W, WANG S, et al. Communication-efficient local decentralized sgd methods [EB/OL]. (2021−04−05). https://doi.org/10.48550/arXiv.1910.09126.
[6]
LU S, ZHANG Y, WANG Y. Decentralized federated learning for electronic health records [C]// 2020 54th Annual Conference on Information Sciences and Systems . Princeton: IEEE, 2020: 1−5.
[7]
YU H, JIN R, YANG S. On the linear speedup analysis of communication efficient momentum SGD for distributed non-convex optimization [C]// International Conference on Machine Learning . Long Beach: PMLR, 2019: 7184−7193.
[本文引用: 2]
[8]
LAMPORT L, SHOSTAK R, PEASE M. The Byzantine generals problem [M]// Concurrency: the works of leslie lamport . New York: Association for Computing Machinery, 2019: 203−226.
[本文引用: 2]
[9]
DAMASKINOS G, GUERRAOUI R, PATRA R, et al. Asynchronous Byzantine machine learning (the case of SGD) [C]// International Conference on Machine Learning . Stockholm: PMLR, 2018: 1145−1154.
[本文引用: 1]
[10]
CHEN Y, SU L, XU J Distributed statistical machine learning in adversarial settings: Byzantine gradient descent
[J]. Proceedings of the ACM on Measurement and Analysis of Computing Systems , 2017 , 1 (2 ): 1 - 25
[本文引用: 1]
[11]
YIN D, CHEN Y, KANNAN R, et al. Byzantine-robust distributed learning: towards optimal statistical rates [C]// International Conference on Machine Learning . Stockholm: PMLR, 2018: 5650−5659.
[本文引用: 1]
[12]
XIE C, KOYEJO O, GUPTA I. Phocas: dimensional byzantine-resilient stochastic gradient descent [EB/OL]. (2018−05−23). https://doi.org/10.48550/arXiv.1805.09682.
[13]
XIE C, KOYEJO O, GUPTA I. Generalized byzantine-tolerant sgd [EB/OL]. (2018−05−23). https://doi.org/10.48550/arXiv.1802.10116.
[14]
BLANCHARD P, EL MHAMDI E M, GUERRAOUI R, et al. Machine learning with adversaries: Byzantine tolerant gradient descent [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . New York: Curran Associates Inc, 2017: 118−128.
[本文引用: 2]
[15]
TAHMASEBIAN F, LOU J, XIONG L. Robustfed: a truth inference approach for robust federated learning [C]// Proceedings of the 31st ACM International Conference on Information and Knowledge Management . New York: Association for Computing Machinery, 2022: 1868−1877.
[本文引用: 2]
2
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
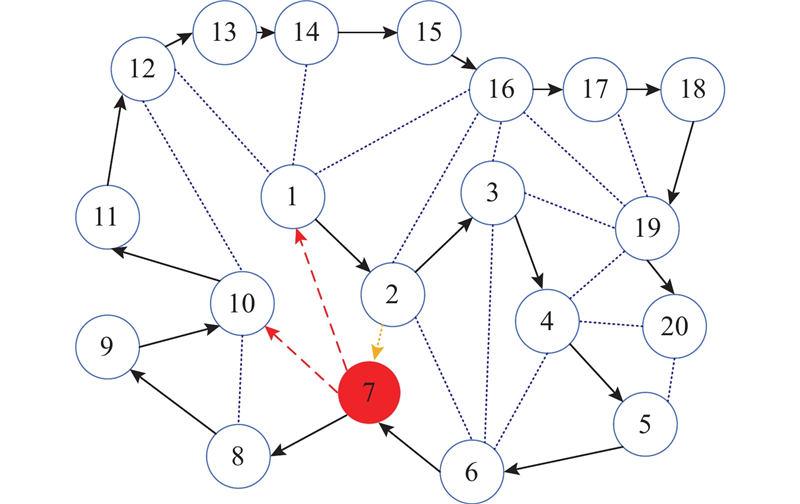
... 在传统机器学习中,为了验证一个用户诚实与否,一个朴素的想法是:在此用户数据集上执行学习任务并通过任务的表现来判定该节点的属性. 然而受制于联邦学习中的隐私设置,用户的个人数据是无法共享的. 由Zeno++算法[16 ] 启发,在由未知数量的拜占庭用户和诚实用户所构成的去中心化网络中进行联邦学习任务时,诚实用户可借助验证数据集和得分函数对下一未知属性用户传递给它的梯度信息进行“打分”,借此来实现分辨和排除拜占庭用户的目的. 对于任意候选梯度${\boldsymbol{g}}$ ${\boldsymbol{\theta}} $ $\gamma $ $\rho(\rho > 0)$
Byzantine-resilient secure federated learning
1
2020
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
1
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
Reliable federated learning for mobile networks
1
2020
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
1
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
Privacy-preserving blockchain-based federated learning for IoT devices
1
2020
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles
1
2020
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
1
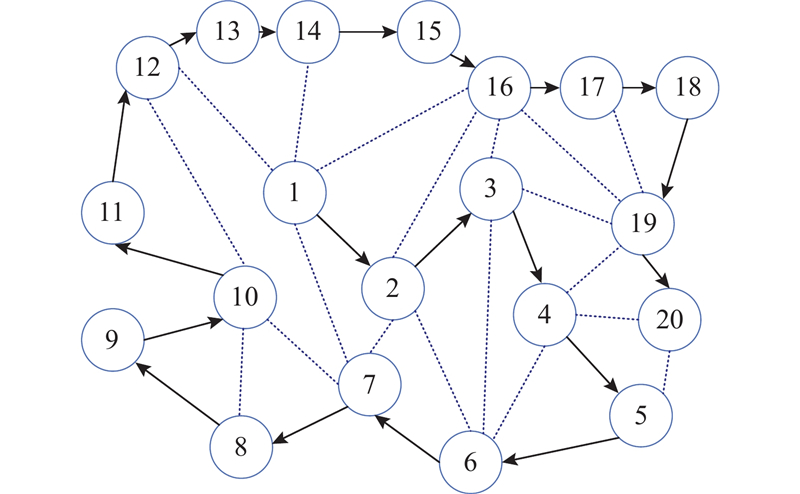
... 对于固定用户网络上的去中心化联邦学习,它的模型聚合路线是既定的. 未经身份认证的恶意节点可能发起拜占庭攻击,它试图在未训练模型的情况下发送本地模型,从而改变模型聚合路线,影响用户对模型聚合路线的共识,最终导致全局模型的实际训练过程偏离正确方向,进而影响全局模型的评估能力[23 ] . 在一个固定用户网络上的去中心化网络中,在无拜占庭节点时,拟定一条联邦学习模型训练和传输的路线:$1 \to 2 \to 3 \to \cdots \to 20$ 图2 所示,每个节点利用私有数据集对接收到的模型参数进行本地训练,并将模型参数发送给下一个节点来协作完成联邦学习任务. 所使用的环状聚合路线,不仅拥有低能耗、延迟低、简单易实现等优点,而且相较于广播形式,此种方式能够降低诚实用户“暴露”给恶意用户的风险. ...
1
... 对于固定用户网络上的去中心化联邦学习,它的模型聚合路线是既定的. 未经身份认证的恶意节点可能发起拜占庭攻击,它试图在未训练模型的情况下发送本地模型,从而改变模型聚合路线,影响用户对模型聚合路线的共识,最终导致全局模型的实际训练过程偏离正确方向,进而影响全局模型的评估能力[23 ] . 在一个固定用户网络上的去中心化网络中,在无拜占庭节点时,拟定一条联邦学习模型训练和传输的路线:$1 \to 2 \to 3 \to \cdots \to 20$ 图2 所示,每个节点利用私有数据集对接收到的模型参数进行本地训练,并将模型参数发送给下一个节点来协作完成联邦学习任务. 所使用的环状聚合路线,不仅拥有低能耗、延迟低、简单易实现等优点,而且相较于广播形式,此种方式能够降低诚实用户“暴露”给恶意用户的风险. ...
1
... 考虑符号翻转(sign-flipping attack)攻击、常数向量攻击(same-value attack)、高斯噪声攻击(Gaussian-noise attack)和标签反转攻击(label-flipping attack). 在符号翻转攻击中,拜占庭节点翻转发送给其他节点的信息(本地梯度或者本地迭代值)的正负号,并且增大其幅度,即${{\boldsymbol{g}}^{\left( {t,i} \right)}} = \sigma \times \nabla f_{{i}}\left( {{{\boldsymbol{\theta}} ^{\left( {t,i - 1} \right)}};{z_i}} \right) $ $\sigma $ [24 ] . 在常数向量攻击中,拜占庭节点发送给其他节点的信息是由常数向量构成的,即${{\boldsymbol{g}}^{(t,i)}} = c \times {\bf{1}}$ ${\bf{1}} \in {{\bf{R}}^d}$ $c$ ${{\boldsymbol{g}}^{(t,i)}} = \nabla {f_i}\left({{\boldsymbol{\theta}} ^{(t,i - 1)}};\right. \left.{z_i}\right) - {\boldsymbol{n}}$ ${\boldsymbol{n}}$
1
... 考虑符号翻转(sign-flipping attack)攻击、常数向量攻击(same-value attack)、高斯噪声攻击(Gaussian-noise attack)和标签反转攻击(label-flipping attack). 在符号翻转攻击中,拜占庭节点翻转发送给其他节点的信息(本地梯度或者本地迭代值)的正负号,并且增大其幅度,即${{\boldsymbol{g}}^{\left( {t,i} \right)}} = \sigma \times \nabla f_{{i}}\left( {{{\boldsymbol{\theta}} ^{\left( {t,i - 1} \right)}};{z_i}} \right) $ $\sigma $ [24 ] . 在常数向量攻击中,拜占庭节点发送给其他节点的信息是由常数向量构成的,即${{\boldsymbol{g}}^{(t,i)}} = c \times {\bf{1}}$ ${\bf{1}} \in {{\bf{R}}^d}$ $c$ ${{\boldsymbol{g}}^{(t,i)}} = \nabla {f_i}\left({{\boldsymbol{\theta}} ^{(t,i - 1)}};\right. \left.{z_i}\right) - {\boldsymbol{n}}$ ${\boldsymbol{n}}$
Gradient methods for the minimisation of functionals
1
1963
... 定义2 PL不等式 .如果存在常数$\mu > 0$ $f(x)$ [25 ] ,那么$ \forall {\boldsymbol{x}} \in {{\bf{R}}^d} $
4
... 近年来,随着5G网络的高速发展以及物联网技术的广泛应用,移动设备的便携化和智能化已经是大势所趋,使用机器学习对移动设备的用户数据进行处理可提高应用程序的智能化,方便人们的日常工作与生活. 然而,传统的机器学习算法需要中央服务器对用户数据进行集中处理,不仅会耗费大量通信资源,而且存在数据泄露风险,使用户隐私安全产生隐患. 联邦学习(federated learning, FL)作为旨在提高通信效率和隐私性的新兴机器学习范式,可以让资源受限和地理分散的设备,利用本地数据合作训练全局模型,同时避免直接交换用户数据. 其中最经典的算法是联邦平均(FedAvg)算法[1 ] ,在中央服务器上重复聚合用户的本地训练模型来生成性能优秀的全局模型. 在联邦学习中,用户数据的处理和分析只在设备终端进行,终端用户传递的信息(本地梯度或者本地迭代值)使得窃听方即使获得传递的信息也不可能立刻推断出用户数据,以保护用户隐私. ...
... 传统的集中式联邦学习[1 -2 ] 虽然提高了数据隐私和通信效率,但存在扩展性差、带宽高、单点故障等问题. 此外,新一代通信网络采用去中心化的无基础设施通信方案和设备到设备的多跳链接技术以提高通信能力[3 ] . 为了解决上述困境,去中心化的联邦学习[4 -7 ] 被提出,然而由于联邦学习数据存储的特殊性以及对通信效率的考虑,许多分布式机器学习方法并不适用于去中心化联邦学习. 同时,联邦学习由于其分布式机器学习的本质,在面对对手攻击时更加脆弱. 拜占庭攻击[8 ] 是联邦学习面临的一种最常见的威胁,亟须设计一种“可证”为安全的拜占庭鲁棒算法. 在传统联邦学习中,通常假设所有参与联邦训练的终端都是“诚实”的,即所有传递给中央服务器的消息都是真实可靠的. 然而,在实际情况中上述假设并不成立,某些终端可能因为网络环境或者被恶意程序操控而发送错误信息. ...
... 通过迭代和计算整体期望,在经过T 轮全局训练后,可以得到理论1. 通过文献[26 ]中对正则化经验风险最小化优化算法的收敛速度的比较方法,本算法的第T 轮全局迭代输出的模型${{\boldsymbol{\theta}} ^{(T,N)}}$ ${{\boldsymbol{\theta}} ^ * }$ 0 ,所以本算法是收敛的. 同时,在有界梯度假设下,本算法具有线性收敛速率,这与FedAvg算法[1 ] 以及部分去中心化联邦学习优化算法[4 -7 ] 的收敛速率一致. 误差界限中的超参数$\rho $ $\rho $
... Accuracy of different robust algorithms on CIFAR_10(MNIST) dataset
Tab.1 鲁棒算法 A 无攻击 高斯噪声 标签反转 注:1) 前一个数据表示CIFAR-10数据集上的准确率,括号中数据表示MNIST数据集上的准确率. FedAvg[1 ] 70.25(99.29)1) 10.00(11.35) 51.37(94.58) Trim_mean[11 ] 70.78(99.34 ) 10.29(11.35) 46.74(94.47) Krum[14 ] 57.75(98.51) 57.24(97.34) 10.00(11.35) RobustFedt [15 ] 69.75(99.32) 54.67(98.34) 51.10(96.34) 可验证去中心化FL 70.79 (98.45)69.30 (98.37 )69.13 (98.33 )
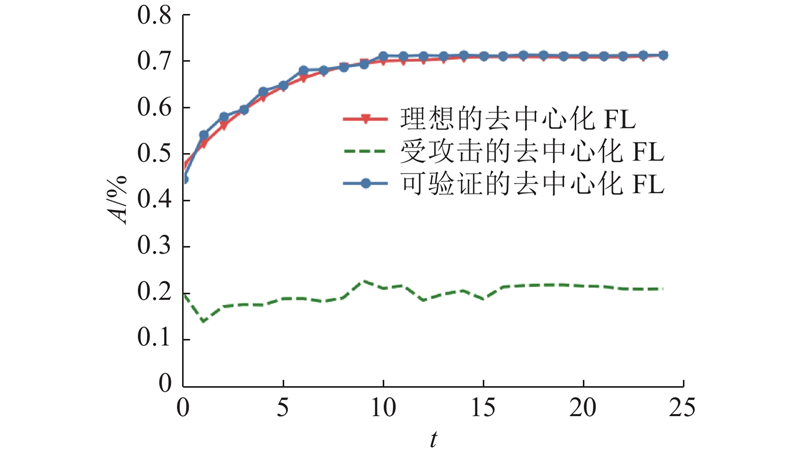
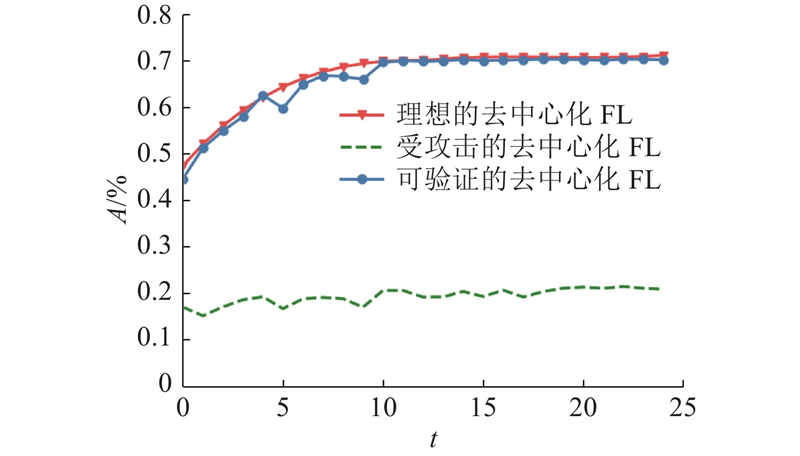
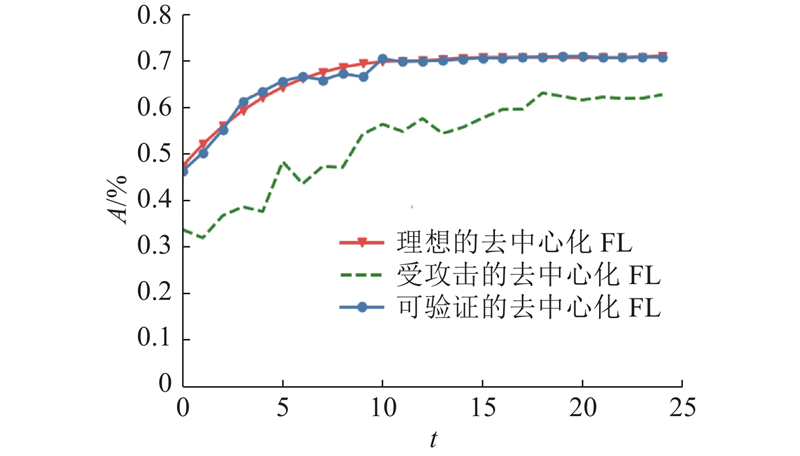
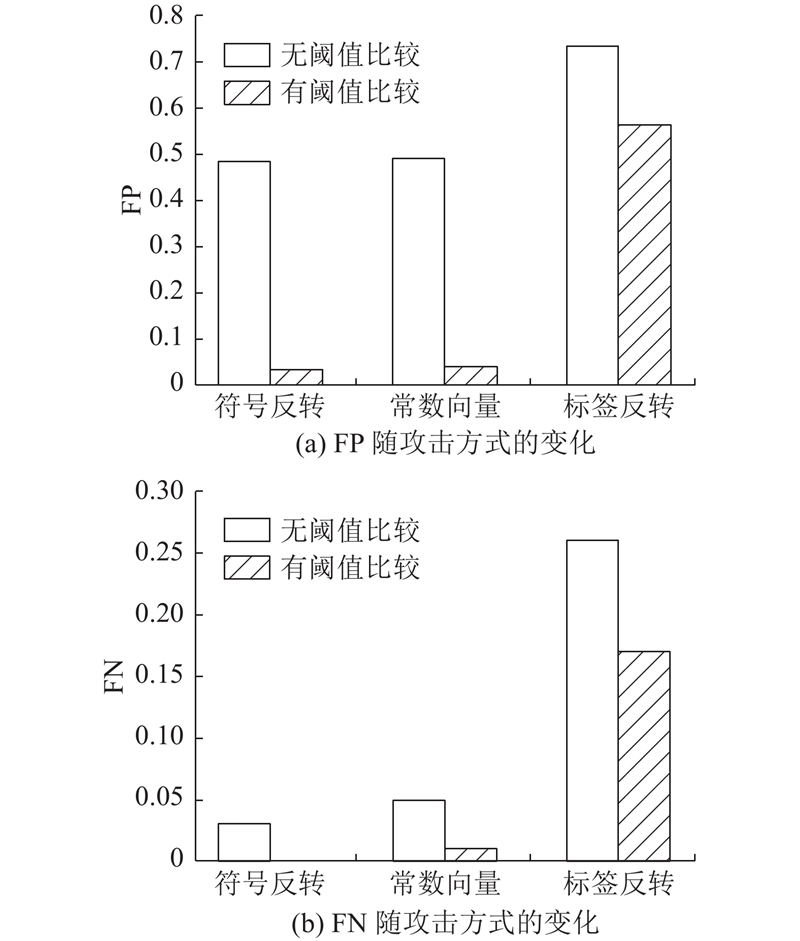
5. 结 语 针对抵抗拜占庭攻击的去中心化联邦学习,基于随机梯度下降算法(SGD)提出鲁棒梯度聚合方法. 通过结合验证数据集和SCORE函数,有效提高了算法对于拜占庭攻击的鲁棒性. 从理论上证明了所提算法的收敛性质,大量数值实验也说明可验证的去中心化FL算法能够确保:在存在未知数量和攻击方式的拜占庭用户的去中心化场景下,所训练的全局模型能够保持良好性能,并可以更准确地区分诚实节点与拜占庭节点. 在未来的工作中,将进一步研究如何把去中心化联邦学习与无线传输相结合,以提高联邦学习的通信效率和隐私性. ...
Federated optimization in heterogeneous networks
1
2020
... 传统的集中式联邦学习[1 -2 ] 虽然提高了数据隐私和通信效率,但存在扩展性差、带宽高、单点故障等问题. 此外,新一代通信网络采用去中心化的无基础设施通信方案和设备到设备的多跳链接技术以提高通信能力[3 ] . 为了解决上述困境,去中心化的联邦学习[4 -7 ] 被提出,然而由于联邦学习数据存储的特殊性以及对通信效率的考虑,许多分布式机器学习方法并不适用于去中心化联邦学习. 同时,联邦学习由于其分布式机器学习的本质,在面对对手攻击时更加脆弱. 拜占庭攻击[8 ] 是联邦学习面临的一种最常见的威胁,亟须设计一种“可证”为安全的拜占庭鲁棒算法. 在传统联邦学习中,通常假设所有参与联邦训练的终端都是“诚实”的,即所有传递给中央服务器的消息都是真实可靠的. 然而,在实际情况中上述假设并不成立,某些终端可能因为网络环境或者被恶意程序操控而发送错误信息. ...
1
... 通过迭代和计算整体期望,在经过T 轮全局训练后,可以得到理论1. 通过文献[26 ]中对正则化经验风险最小化优化算法的收敛速度的比较方法,本算法的第T 轮全局迭代输出的模型${{\boldsymbol{\theta}} ^{(T,N)}}$ ${{\boldsymbol{\theta}} ^ * }$ 0 ,所以本算法是收敛的. 同时,在有界梯度假设下,本算法具有线性收敛速率,这与FedAvg算法[1 ] 以及部分去中心化联邦学习优化算法[4 -7 ] 的收敛速率一致. 误差界限中的超参数$\rho $ $\rho $
1
... 在本次实验中,总数据集为CIFAR-10[27 ] 和MNIST[28 ] ,前者包含了60000张$32 \times 32$ $28 \times 28$
1
... 传统的集中式联邦学习[1 -2 ] 虽然提高了数据隐私和通信效率,但存在扩展性差、带宽高、单点故障等问题. 此外,新一代通信网络采用去中心化的无基础设施通信方案和设备到设备的多跳链接技术以提高通信能力[3 ] . 为了解决上述困境,去中心化的联邦学习[4 -7 ] 被提出,然而由于联邦学习数据存储的特殊性以及对通信效率的考虑,许多分布式机器学习方法并不适用于去中心化联邦学习. 同时,联邦学习由于其分布式机器学习的本质,在面对对手攻击时更加脆弱. 拜占庭攻击[8 ] 是联邦学习面临的一种最常见的威胁,亟须设计一种“可证”为安全的拜占庭鲁棒算法. 在传统联邦学习中,通常假设所有参与联邦训练的终端都是“诚实”的,即所有传递给中央服务器的消息都是真实可靠的. 然而,在实际情况中上述假设并不成立,某些终端可能因为网络环境或者被恶意程序操控而发送错误信息. ...
2
... 传统的集中式联邦学习[1 -2 ] 虽然提高了数据隐私和通信效率,但存在扩展性差、带宽高、单点故障等问题. 此外,新一代通信网络采用去中心化的无基础设施通信方案和设备到设备的多跳链接技术以提高通信能力[3 ] . 为了解决上述困境,去中心化的联邦学习[4 -7 ] 被提出,然而由于联邦学习数据存储的特殊性以及对通信效率的考虑,许多分布式机器学习方法并不适用于去中心化联邦学习. 同时,联邦学习由于其分布式机器学习的本质,在面对对手攻击时更加脆弱. 拜占庭攻击[8 ] 是联邦学习面临的一种最常见的威胁,亟须设计一种“可证”为安全的拜占庭鲁棒算法. 在传统联邦学习中,通常假设所有参与联邦训练的终端都是“诚实”的,即所有传递给中央服务器的消息都是真实可靠的. 然而,在实际情况中上述假设并不成立,某些终端可能因为网络环境或者被恶意程序操控而发送错误信息. ...
... 通过迭代和计算整体期望,在经过T 轮全局训练后,可以得到理论1. 通过文献[26 ]中对正则化经验风险最小化优化算法的收敛速度的比较方法,本算法的第T 轮全局迭代输出的模型${{\boldsymbol{\theta}} ^{(T,N)}}$ ${{\boldsymbol{\theta}} ^ * }$ 0 ,所以本算法是收敛的. 同时,在有界梯度假设下,本算法具有线性收敛速率,这与FedAvg算法[1 ] 以及部分去中心化联邦学习优化算法[4 -7 ] 的收敛速率一致. 误差界限中的超参数$\rho $ $\rho $
The mnist database of handwritten digit images for machine learning research [best of the web]
1
2012
... 在本次实验中,总数据集为CIFAR-10[27 ] 和MNIST[28 ] ,前者包含了60000张$32 \times 32$ $28 \times 28$
1
... 在一台装备了NVIDIA GeForce GTX 1660 SUPER显卡的主机上,基于Mxnet[29 ] 平台,利用卷积神经网络(convolutional neural networks,CNN)对算法进行实验仿真. 此卷积神经网络包含4个卷积层和4个全连接层,并在卷积层之间嵌入Batch Norm层和Dropout层来防止神经网络的过拟合. 在实验过程中,利用测试数据集上的准确率作为衡量模型性能的标准. 同时,采用假阳率、假阴率来表示被采用的信息是错误信息、被抛弃的信息是正确信息的概率. ...
2
... 传统的集中式联邦学习[1 -2 ] 虽然提高了数据隐私和通信效率,但存在扩展性差、带宽高、单点故障等问题. 此外,新一代通信网络采用去中心化的无基础设施通信方案和设备到设备的多跳链接技术以提高通信能力[3 ] . 为了解决上述困境,去中心化的联邦学习[4 -7 ] 被提出,然而由于联邦学习数据存储的特殊性以及对通信效率的考虑,许多分布式机器学习方法并不适用于去中心化联邦学习. 同时,联邦学习由于其分布式机器学习的本质,在面对对手攻击时更加脆弱. 拜占庭攻击[8 ] 是联邦学习面临的一种最常见的威胁,亟须设计一种“可证”为安全的拜占庭鲁棒算法. 在传统联邦学习中,通常假设所有参与联邦训练的终端都是“诚实”的,即所有传递给中央服务器的消息都是真实可靠的. 然而,在实际情况中上述假设并不成立,某些终端可能因为网络环境或者被恶意程序操控而发送错误信息. ...
... 通过迭代和计算整体期望,在经过T 轮全局训练后,可以得到理论1. 通过文献[26 ]中对正则化经验风险最小化优化算法的收敛速度的比较方法,本算法的第T 轮全局迭代输出的模型${{\boldsymbol{\theta}} ^{(T,N)}}$ ${{\boldsymbol{\theta}} ^ * }$ 0 ,所以本算法是收敛的. 同时,在有界梯度假设下,本算法具有线性收敛速率,这与FedAvg算法[1 ] 以及部分去中心化联邦学习优化算法[4 -7 ] 的收敛速率一致. 误差界限中的超参数$\rho $ $\rho $
2
... 传统的集中式联邦学习[1 -2 ] 虽然提高了数据隐私和通信效率,但存在扩展性差、带宽高、单点故障等问题. 此外,新一代通信网络采用去中心化的无基础设施通信方案和设备到设备的多跳链接技术以提高通信能力[3 ] . 为了解决上述困境,去中心化的联邦学习[4 -7 ] 被提出,然而由于联邦学习数据存储的特殊性以及对通信效率的考虑,许多分布式机器学习方法并不适用于去中心化联邦学习. 同时,联邦学习由于其分布式机器学习的本质,在面对对手攻击时更加脆弱. 拜占庭攻击[8 ] 是联邦学习面临的一种最常见的威胁,亟须设计一种“可证”为安全的拜占庭鲁棒算法. 在传统联邦学习中,通常假设所有参与联邦训练的终端都是“诚实”的,即所有传递给中央服务器的消息都是真实可靠的. 然而,在实际情况中上述假设并不成立,某些终端可能因为网络环境或者被恶意程序操控而发送错误信息. ...
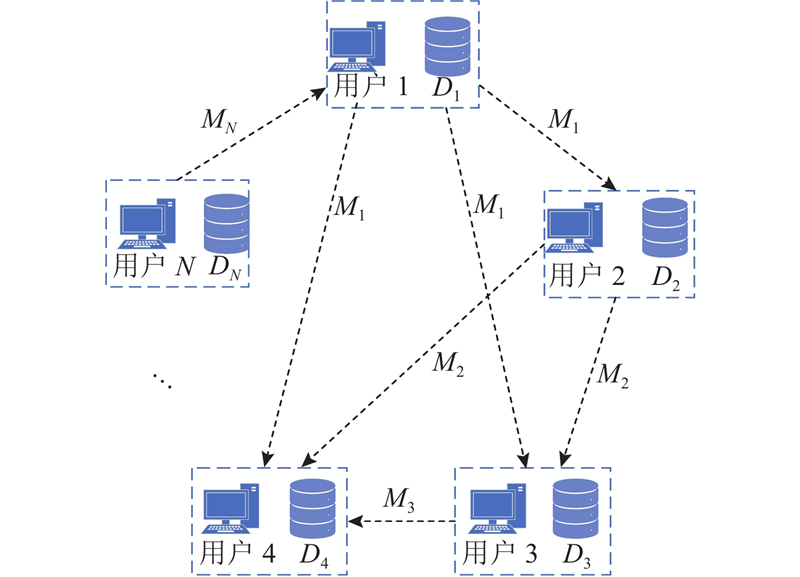
... 代理用户使用随机梯度下降(stochastic gradient descent, SGD)和先发送后验证的方法在用户的数据集上优化损失函数以训练本地模型. 在第$t$ $i$ ${{\boldsymbol{m}}^{(t,i)}}$ $i+1$ . 如果用户$i$ ${{\boldsymbol{m}}^{(t,i)}} = {{\boldsymbol{\theta}} ^{(t,i)}}$ . 然而,恶意用户传递的信息并不是在其本地数据集上运行SGD计算所得到的结果而是任意信息$ {{\boldsymbol{g}}^{(t,i)}} $ . 根据文献[8 ]中的定义,其表达式如下: ...
1
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
Distributed statistical machine learning in adversarial settings: Byzantine gradient descent
1
2017
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
1
... Accuracy of different robust algorithms on CIFAR_10(MNIST) dataset
Tab.1 鲁棒算法 A 无攻击 高斯噪声 标签反转 注:1) 前一个数据表示CIFAR-10数据集上的准确率,括号中数据表示MNIST数据集上的准确率. FedAvg[1 ] 70.25(99.29)1) 10.00(11.35) 51.37(94.58) Trim_mean[11 ] 70.78(99.34 ) 10.29(11.35) 46.74(94.47) Krum[14 ] 57.75(98.51) 57.24(97.34) 10.00(11.35) RobustFedt [15 ] 69.75(99.32) 54.67(98.34) 51.10(96.34) 可验证去中心化FL 70.79 (98.45)69.30 (98.37 )69.13 (98.33 )
5. 结 语 针对抵抗拜占庭攻击的去中心化联邦学习,基于随机梯度下降算法(SGD)提出鲁棒梯度聚合方法. 通过结合验证数据集和SCORE函数,有效提高了算法对于拜占庭攻击的鲁棒性. 从理论上证明了所提算法的收敛性质,大量数值实验也说明可验证的去中心化FL算法能够确保:在存在未知数量和攻击方式的拜占庭用户的去中心化场景下,所训练的全局模型能够保持良好性能,并可以更准确地区分诚实节点与拜占庭节点. 在未来的工作中,将进一步研究如何把去中心化联邦学习与无线传输相结合,以提高联邦学习的通信效率和隐私性. ...
2
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
... Accuracy of different robust algorithms on CIFAR_10(MNIST) dataset
Tab.1 鲁棒算法 A 无攻击 高斯噪声 标签反转 注:1) 前一个数据表示CIFAR-10数据集上的准确率,括号中数据表示MNIST数据集上的准确率. FedAvg[1 ] 70.25(99.29)1) 10.00(11.35) 51.37(94.58) Trim_mean[11 ] 70.78(99.34 ) 10.29(11.35) 46.74(94.47) Krum[14 ] 57.75(98.51) 57.24(97.34) 10.00(11.35) RobustFedt [15 ] 69.75(99.32) 54.67(98.34) 51.10(96.34) 可验证去中心化FL 70.79 (98.45)69.30 (98.37 )69.13 (98.33 )
5. 结 语 针对抵抗拜占庭攻击的去中心化联邦学习,基于随机梯度下降算法(SGD)提出鲁棒梯度聚合方法. 通过结合验证数据集和SCORE函数,有效提高了算法对于拜占庭攻击的鲁棒性. 从理论上证明了所提算法的收敛性质,大量数值实验也说明可验证的去中心化FL算法能够确保:在存在未知数量和攻击方式的拜占庭用户的去中心化场景下,所训练的全局模型能够保持良好性能,并可以更准确地区分诚实节点与拜占庭节点. 在未来的工作中,将进一步研究如何把去中心化联邦学习与无线传输相结合,以提高联邦学习的通信效率和隐私性. ...
2
... 在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9 ] . 拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响. 利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10 -14 ] ,但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用. Tahmasebian等[15 ] 结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法. Xie等[16 ] 提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度. 然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息. So等[17 ] 提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性. Wang等[18 ] 提出点对点算法P2PK-SMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型. 受Kang等[19 ] 的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20 ] 提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性. 同样,Zhao等[21 ] 使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全. Lu等[22 ] 将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning, DRL)进行节点选择,以提高效率. 然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用. ...
... Accuracy of different robust algorithms on CIFAR_10(MNIST) dataset
Tab.1 鲁棒算法 A 无攻击 高斯噪声 标签反转 注:1) 前一个数据表示CIFAR-10数据集上的准确率,括号中数据表示MNIST数据集上的准确率. FedAvg[1 ] 70.25(99.29)1) 10.00(11.35) 51.37(94.58) Trim_mean[11 ] 70.78(99.34 ) 10.29(11.35) 46.74(94.47) Krum[14 ] 57.75(98.51) 57.24(97.34) 10.00(11.35) RobustFedt [15 ] 69.75(99.32) 54.67(98.34) 51.10(96.34) 可验证去中心化FL 70.79 (98.45)69.30 (98.37 )69.13 (98.33 )
5. 结 语 针对抵抗拜占庭攻击的去中心化联邦学习,基于随机梯度下降算法(SGD)提出鲁棒梯度聚合方法. 通过结合验证数据集和SCORE函数,有效提高了算法对于拜占庭攻击的鲁棒性. 从理论上证明了所提算法的收敛性质,大量数值实验也说明可验证的去中心化FL算法能够确保:在存在未知数量和攻击方式的拜占庭用户的去中心化场景下,所训练的全局模型能够保持良好性能,并可以更准确地区分诚实节点与拜占庭节点. 在未来的工作中,将进一步研究如何把去中心化联邦学习与无线传输相结合,以提高联邦学习的通信效率和隐私性. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}