

随着数据科学的快速发展, 大量时序数据的采集和处理已成为普遍现象. 这些时序数据在金融、天气、机械等各个领域中都有广泛的应用, 例如金融行业中的股票价格和交易量、气象行业中的气温和降雨量、机械行业中的振动信号和温度等. 这些时序数据中蕴含着各种规律和模式, 如周期性、趋势性、异常点等, 这些规律和模式对领域专家和决策者的决策具有重要意义. 时序数据可视化作为一种直观的数据呈现方式, 对于人们理解时序数据的规律和模式至关重要. 时序可视化有助于数据科学家将其见解与非专业人士进行交流,使得非专业人士能够更好地理解时序数据, 从而支持数据知识的交流.
为了解决该问题, 本文提出基于迁移学习的交互式时序数据可视化创作方法. 该方法引入迁移学习,解决时序数据可视化创作时多个数据集之间的数据分布不一致的问题. 迁移学习通常是利用源域和目标域之间的相关性, 将源域的知识应用到目标域中, 从而提高目标域的性能. 在时序数据可视分析的场景下, 用户在源域进行的分析探索操作可以归为源域的知识. 本文将迁移成分分析应用于时序数据的特征, 开展跨域迁移. 通过将用户在选中的源域时序数据上的分析操作作为标签, 在源域上训练分类器, 再将其应用到其他的多个目标域时序数据上, 以实现多个领域时序数据的交互式可视化分析. 该方法不仅可以提高时序数据分析的效率, 而且可以减少分析人员的人力成本. 本文应用真实天气数据和轴承信号数据进行案例分析, 通过专家的评估和反馈来验证系统的有效性和实用性.
1. 相关工作
1.1. 时序数据可视探索
采用概览和细节图可视化大范围时序数据, 展示数据降维后的视图. 根据用户选择的感兴趣模式批量推荐对应的时序数据, 支持用户高效的探索.
1.2. 时序数据的模式推荐
在现实的时序数据分析场景中, 用户需要基于自己的分析经验, 将包含特定趋势或者若干组数据突变点的模式作为关注对象, 这些关注对象往往是复杂且多样的. 现有的模式推荐方法主要分为基于聚类的方法和基于相似度的方法.
当用户面对批量未标记的时序数据进行探索时, 层次聚类[16-17]是最广泛应用的聚类方法, 它具备强大的可视化能力和通用性. 层次聚类会根据序列之间的相似矩阵产生嵌套的层次结构, 用户可以根据聚类的情况大致了解时序数据的特征, 但该方法更适用于小规模数据,对于大规模数据可能效率不高. k-Means是更快的聚类方法, 系统根据聚类后的结果推荐相同簇下的时间序列. Rodrigues等[18-19]提出更多优化后的时间序列聚类算法. 除此之外, 系统通常根据时间序列的相似性程度来进行推荐. 基于形状的相似性是通过比较时序数据的对应点计算得到, 比如欧氏距离、动态时间规整、最长公共子序列等. 对于更长时间范围内的序列, 更多是基于高层次的结构来衡量它们的相似性. 例如Dempster等[20]使用随机卷积核对时间序列进行转换,利用转换后的特征训练线性分类器.
根据用户选择的部分时间序列, 采用导数动态时间规整算法衡量序列相似性, 推荐相似性较高的时间序列,更容易捕捉趋势变化相同的序列.
1.3. 交互式可视化创作
常见的系统结合交互和机器自动化, 用户可以交互式地选择可视化图表模板展示数据, 比如Microsoft Excel、DaraWrapper①、Plotly②等. 有些可视化工具可以自动推荐可视化图表类型, 例如Tableau、Power BI和Polestar[24], 但同时需要用户交互指定数据的映射方式. Lyra[25]、VisDesinger[26]、 InfoNice[27]等创作工具都是通过面板的设置来制定数据映射方式. DataInk通过更灵活的笔和触摸的交互操作绑定数据, 创作信息图[28]. 对于选取展示的数据洞见, 现有很多工作致力于自动挖掘数据中的模式, 呈现在可视化图表中, 比如SeeDB[29]、 DataShot[30]. 自动挖掘选择的数据模式较简单, 是从原始数据中得到的统计结果, 比如总和、极值、趋势或比例数据[31-33].
本文将用户交互与算法相结合,用于数据选择的可视化创作阶段. 系统根据用户交互式选择部分小范围的感兴趣数据, 自动地批量推荐数据,根据推荐数据生成时序可视化图像.
2. 数据及处理流程
介绍时序数据的处理流程和建模, 包括时序数据的迁移成分分析、源域和目标域的模式推荐方法.
对时序数据进行形式化定义, 给定长度为
2.1. 迁移成分分析
在现实场景的数据中, 源域
图 1
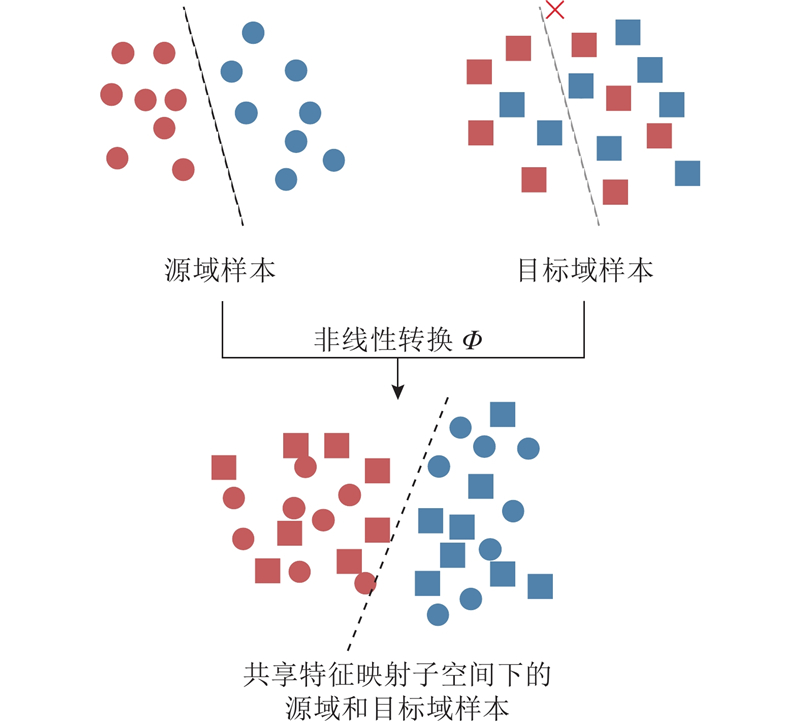
需要找到合适的非线性转换方式
1) 最小化边缘分布
2) 最大限度地保留
采用最大均值差异(maximum mean discrepancy, MMD)距离[34]来定义分布
式中:
显式定义非线性转换并计算特征之间的距离是比较困难的. 引入Pan等[35]提出的迁移成分分析(transfer component analysis, TCA). TCA通过引入核矩阵,将式(1)的求解转化为内核学习问题, 得到源域和目标域在最优共享特征子空间下的表示.
2.2. 时序数据的模式推荐
2.2.1. 源域时序数据的模式推荐
用户基于自己的分析经验, 关注时序数据中的特定趋势. 对源域中大范围的时序数据进行全面探索, 逐一标注模式对用户来说是费力且低效率的. 为了提高效率, 利用时序数据片段的相似性进行模式推荐, 根据用户对少量感兴趣的模式的标注, 推荐整个源域上相似的模式.
动态时间规整(dynamic time warping, DTW)算法的计算结果仅反映时序数据片段在数值上的接近程度, 考虑到用户在模式探索时受形状、趋势因素的影响, 采用导数动态时间规整(derivative dynamic time warping, DDTW)算法. 相较于DTW, DDTW的算法结果不仅受时序数据的数值接近程度的影响, 还受时序数据的形状特征和变化趋势的影响. 此外, DDTW算法在数据缺失和存在异常值的情况下有较强的鲁棒性, 可以对非等长的时序数据或包含异常值的时序数据进行相似性分析.
针对用户的感兴趣时序数据片段
式中:
2.2.2. 目标域时序数据的模式推荐
将用户探索后的时序数据作为源域, 多个未探索的时序数据作为目标域集合, 利用TCA算法缩小源域和多个目标域的差异性, 使得用户在源域的探索模式能够在目标域上复现, 大量减少了时序数据探索的工作量, 提高了在不同目标域时序数据上的探索效率.
采用常见的有监督学习分类器, 如KNN、SVM, 选择展示对应时序数据集效果最好的分类器. 在训练过程中,分类器根据特征和标签之间的关系进行参数优化,实现对目标域时序数据的模式推荐.
整个流程如图2所示. 开展特征提取, 对源域时序数据特征和多个目标域时序数据特征进行迁移成分分析, 得到映射后的源域和目标域的时序特征. 源域样本分为2类, 即被用户选中的时序数据和未被选中的时序数据. 目标域的模式推荐问题被建模为二分类的问题, 可以利用传统的机器学习分类器, 以有标签的源域时序数据为训练数据, 预测目标域上时序数据的概率, 实现对目标域时序数据的模式推荐.
图 2
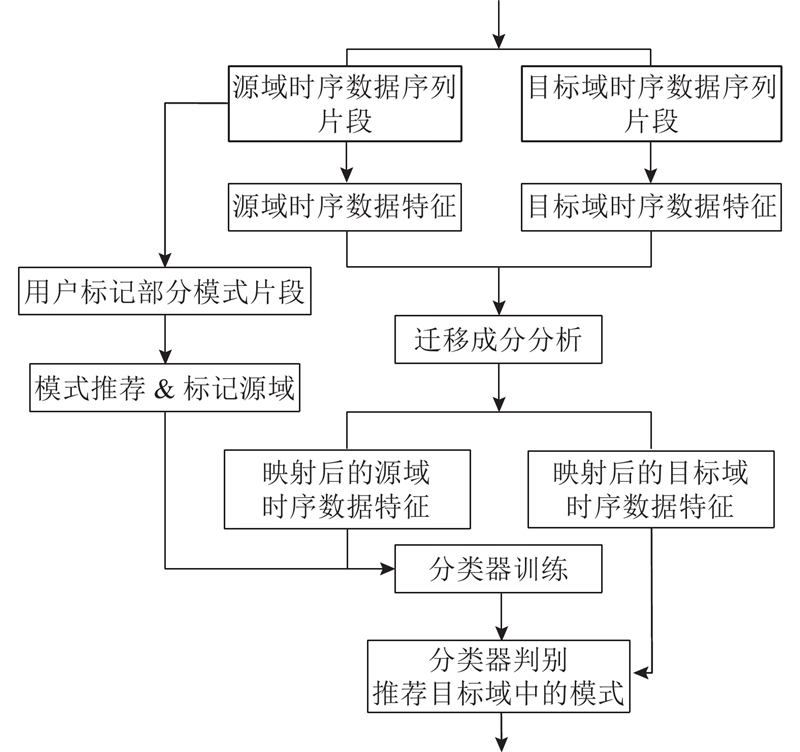
3. 可视分析系统
根据设计目标和任务,设计并实现了时序数据的交互式可视化生成系统. 如图3所示, 系统包含数据配置视图、时序数据分析视图和跨域辅助视图. 用户在选择需要分析的时序数据集合后, 根据对数据集中不同子集的描述, 确定具有代表性的时序数据作为源域. 在主要的时序数据分析视图中, 系统根据用户在源域时序数据可视化上的分析, 在其余多个目标域时序数据上生成对应的可视化结果. 跨域辅助视图的信息可以帮助用户交叉验证目标域时序数据上推荐的结果.
图 3
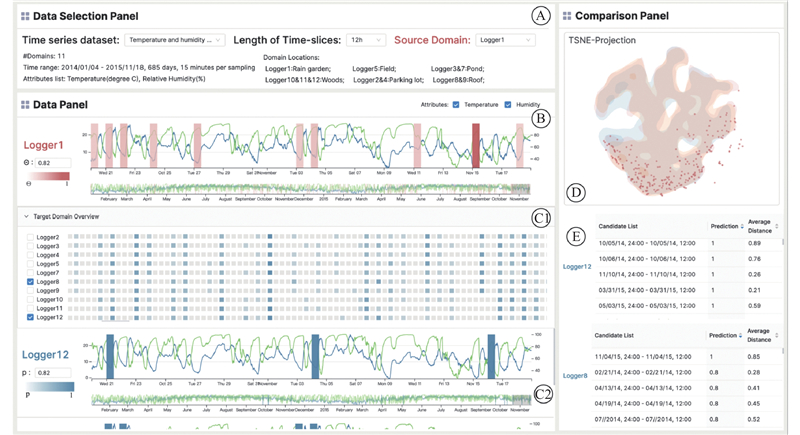
图 3 时序数据可视分析系统的界面概览
A-数据配置视图; B-源域时序数据视图; C1【-逻*辑*与-】amp;C2-目标域时序数据视图; D【-逻*辑*与-】amp;E-跨域辅助视图 Interface of time series data visual analysis system
3.1. 数据配置视图
数据配置视图是描述时序数据集合的基本数据信息和分析的入口, 如图3的A区域. 导入的数据集通常包含多个域的时序数据, 每个域的时序数据分布存在差异. 该视图会展示数据集中各个域共有的属性, 每个属性的基本描述和统计信息为用户选择源域时序数据提供信息辅助.
为了降低用户的选择成本, 系统在指定数据集后会默认配置最合适的时间切分片段长度和源域时序数据, 支持用户参考数据集信息后对这2个参数的修改.
3.2. 时序数据分析视图
在用户选定数据集和源域后, 在整个时序数据分析视图中可以将用户对源域的分析操作在多个目标域复现. 该视图分为源域时序数据视图和目标域时序数据视图两部分.
3.2.1. 源域时序数据视图
系统默认在图3的B区域展示该源域时序数据的所有属性分析变量. 用户可以根据分析需求, 选择更改展示和分析的属性变量. 在有限的屏幕空间中展示大尺度的时序数据对用户分析来说不友好. 系统采用概览和细节视图, 用户可以在完整的时间范围内选择小范围时间进行探索.
用户根据经验在小范围的源域时序数据上标注感兴趣的模式. 系统用DDTW计算片段之间的相似度,给用户推荐具有相同模式的时序数据片段. 概览时间轴上标注了系统推荐的时序数据片段, 方便用户快速定位; 细节时间轴上展示了根据相似度编码的背景颜色. 用户可以批量接受推荐片段或删除特定的推荐片段, 也可以继续手动标注得到系统的进一步推荐, 交互迭代地指定源域时序数据上的标签.
3.2.2. 目标域时序数据视图
3.3. 跨域辅助视图
除了可以通过直观的折线图曲线分析来了解时序数据中的模式, 系统还提供了经过迁移成分分析后多个域的特征向量的t-SNE投影视图, 如图3的D区域所示. 该视图可以更加直观地展示不同域的数据集之间的相似性和差异性, 帮助用户更好地理解时序数据中的模式. 考虑到投影的点的数量巨大, 选择使用带透明度的区域颜色填充来描述各个域的特征点分布.
在用户标记探索源域时序数据的阶段, 使用散点图展示用户标记的时序数据片段对应的特征点,支持灵活选择和悬停展示详细信息. 这些被推荐或被标记的片段会呈现在图3的E区域的列表中,可以按照相似程度升序或降序排列. 当用户的鼠标悬停在某个推荐片段时, 投影视图中该片段的投影点会被同时高亮. 类似地, 选中的多个目标域的推荐时间序列片段的特征点和基础数据信息会对应呈现在D区域的投影和E区域的列表中. 在辅助视图的帮助下, 用户可以完成时序数据分析视图上源域和目标域推荐片段的交叉验证.
4. 实验与分析
4.1. 案例1: 天气数据
该应用案例的数据来自马里兰州某地中心周围12个地点采集的温度和相对湿度数据集[36], 时间跨度为2013年11月至2015年11月. 该数据集涉及的12个地点的采集器被放置在不同的环境中, 比如铺沥青的路面、亮面屋顶、草地、森林等7种不同的环境, 采集器每隔15 min记录一次温度和湿度数据. 不同材料对热量的吸收和反射方式不同, 例如沥青和混凝土的热导率高于草坪, 这可能导致表面温度较高并且更多的热量向周围空气传递, 从而影响地表的温度和湿度. 该数据集中不同地的采集数据可以视为迁移学习中的多个域, 数据存在分布不一致的问题. 假设用户希望能够高效地批量探索分析数据集, 探索植被对环境温度和湿度的影响.
对源域数据的探索. 用户根据数据配置视图A中对数据集的描述,选择被放置在植被最丰富的雨水花园的Logger1的时序数据为源域进行分析. 用户在概览时间轴上刷选探索, 注意到某些日子的上午会出现温度短暂降到低点后回升, 相对湿度短暂上升后急剧下降的情况, 2条曲线在这个时间段内呈现为开口的菱形形状. 用户手动在细节时间轴上刷选了感兴趣的时间范围2015-11-15 0:00 —2015-11-15 12:00. 系统根据相似度计算,向用户推荐Logger1的时序数据上具有相似模式的时间片段. 用户粗略浏览了推荐的时序片段, 注意到大部分的推荐片段的投影点都聚集在一起, 但仍有少部分点比较分散. 通过手动调整相似度阈值和人为拒绝了部分序列的推荐, 用户完成了对源域数据的探索, 也可以理解为用户完成了对源域时序数据的标记, 被标记的片段均拥有相同的模式.
对目标域数据的批量探索. 系统自动对源域和目标域的特征进行迁移成分分析, 将映射后的特征集合降维投影在右侧的D视图中. 在用户确认源域的模式后, 系统在C1视图为用户提供了其余多个目标域上的模式推荐情况总览. Logger10、Logger11和Logger12这3个采集器都位于植被情况类似的森林中, 所以这3个目标域的推荐大致是相同的. 用户概览推荐情况后, 选择其中的Logger8和Logger12为目标域进行后续分析. 用户可以通过投影视图(见图3的D区域)验证, 3个域的特征经过迁移成分分析后数据分布基本一致. 用户折叠了目标域的概览视图, 联合分析系统对Logger8和Logger12的模式推荐, 主要基于投影视图中各个域的推荐点的分布对应调整了每个域接受的预测阈值. 由此完成整个分析流程.
4.2. 案例2: 轴承信号数据
该案例的数据来自美国凯斯西储大学的轴承故障信号数据集[37], 选择12 kHz采样频率下的驱动端轴承故障数据, 采用总共12种处于不同工况下的信号时序数据作为数据集: 4种电机负载(0、735、1 470、2 205 W)、3种故障的尺寸(0.178、0.356、 0.533 mm). 每一种信号时序数据拼接了轴承在对应的负载和尺寸下的4种不同健康状态的信号, 包括外圈故障、内圈故障、滚动故障和正常状态. 通过该案例,展示了在该系统下用户能够有效且高效地进行故障诊断处理.
对源域数据的探索. 用户根据经验,选择其中一个时序数据(负载为2 205 W, 故障尺寸为0.178 mm, 以下简称工况1)作为源域数据. 经过B视图上直接的系统推荐片段和源域D视图上源域特征的投影视图之间的交叉验证, 用户选中一批故障为滚动故障的时序数据片段. 如图4(a)所示, 同为滚动故障的时序数据片段的特征点集中于一个条带.
图 4

图 4 轴承信号数据的t-SNE投影比较
Fig.4 t-SNE projection comparison for bearing signal data
4.3. 专家评估
以半结构化的方式,对2位专家分别进行访谈. 在专家使用系统前, 向专家简要地介绍了系统每个视图的功能和使用流程, 该环节大约持续10 min. 在确保介绍完成后每位专家都能够理解系统的操作方式后,进入下一个环节. 让专家进行30 min的自由探索环节. 期间记录了系统的使用情况, 收集了他们在使用时的感受及期望的改进.
操作流程及系统设计. 由于系统设计不复杂, 专家表示经过简单介绍系统交互和功能后能够快速上手且不易出错, 在流程上注重了易用性. 概览和细节的时间轴能够支持专家对大范围时序数据的快速定位和高效探索. 其中一位专家还表示, 投影视图在流程中起到比较关键的作用, 不仅能够反映推荐的时序数据片段是否符合自己预先定义的模式, 而且能够展示对齐后的源域和目标域数据分布, 使人更加信任分类器的推荐结果. 另一位专家声称, 时序数据视图、投影视图和列表视图的交互联动能帮助自己快速筛选推荐的模式片段, 高效地批量处理多个时序数据.
预期的改进. 专家指出了一些不足之处, 首先是投影视图的交互设计上, 当选中探索的域过多时,多条网格状的等高线和推荐点之间会互相影响. 当时序数据的属性维度大幅增加时, 现有系统的可视设计将不再支持, 需要更简洁、有效的可视设计. 推荐模式效果的表现在一定程度上依赖最初的特征提取算法, 这在当前的系统中是根据数据集的特性提前计算得到的. 专家希望能够提供一些常用的特征提取算法作为候选项, 进行横向的对比, 选择表现更好的算法进行后续探索.
5. 结 语
本文提出基于迁移学习的交互式时序数据可视化创作方法,解决不同数据集之间数据分布不一致的问题. 该方法利用源域和目标域之间的相关性来提高目标域的性能, 通过将用户在源域开展的分析操作作为标签, 在源域训练分类器. 将该分类器应用于其他多个目标域的时序数据上, 实现多个领域时序数据的交互式可视化分析. 本文的案例研究和专家访谈验证了系统的有效性和实用性,为批量时序数据分析提供了新的思路.
目前的工作存在不足之处, 比如TCA的性能受噪声的影响较大,当存在大量噪声时,TCA的降维效果可能会变差, 而且TCA的参数设置需要根据具体的数据调整, 计算开销大后会影响交互分析的效率. 在未来工作中将探索更多的迁移学习方法,例如利用多源域迁移、无源域迁移的方法, 提高方法的效果和可靠性. 扩展本文提出的方法,将其应用到更多样化的场景中,例如金融、医疗、能源等领域. 这将帮助进一步验证方法的通用性,评估本文方法在不同领域中的效果和可靠性.
参考文献
TranAD: deep transformer networks for anomaly detection in multivariate time series data
[J].
TimeClassifier: a visual analytic system for the classification of multi-dimensional time series data
[J].DOI:10.1007/s00371-015-1112-0 [本文引用: 1]
Visual exploration of frequent patterns in multivariate time series
[J].DOI:10.1177/1473871611430769 [本文引用: 1]
TimeNotes: a study on effective chart visualization and interaction techniques for time-series data
[J].
Visualization of urban mobility data from intelligent transportation systems
[J].DOI:10.3390/s19020332 [本文引用: 1]
Exploratory analysis of time series data: detection of partial similarities, clustering, and visualization
[J].
TimeCluster: dimension reduction applied to temporal data for visual analytics
[J].DOI:10.1007/s00371-019-01673-y [本文引用: 1]
Clustering multivariate time series using hidden Markov models
[J].DOI:10.3390/ijerph110302741 [本文引用: 1]
A hybrid algorithm for clustering of time series data based on affinity search technique
[J].
Incorporation of human knowledge into data embeddings to improve pattern significance and interpretability
[J].
HCDC: a novel hierarchical clustering algorithm based on density-distance cores for data sets with varying density
[J].DOI:10.1016/j.is.2022.102159 [本文引用: 1]
Implementing a novel deep learning technique for rainfall forecasting via climatic variables: an approach via hierarchical clustering analysis
[J].DOI:10.1016/j.scitotenv.2022.158760 [本文引用: 1]
Hierarchical clustering of time-series data streams
[J].DOI:10.1109/TKDE.2007.190727 [本文引用: 1]
Self-supervised time series clustering with model-based dynamics
[J].
ROCKET: exceptionally fast and accurate time series classification using random convolutional kernels
[J].DOI:10.1007/s10618-020-00701-z [本文引用: 1]
Keshif: rapid and expressive tabular data exploration for novices
[J].
Charticulator: interactive construction of bespoke chart layouts
[J].
Lyra: an interactive visualization design environment
[J].DOI:10.1111/cgf.12391 [本文引用: 1]
iVisDesigner: expressive interactive design of information visualizations
[J].DOI:10.1109/TVCG.2014.2346291 [本文引用: 1]
DataShot: automatic generation of fact sheets from tabular data
[J].
Retrieve-then-adapt: example-based automatic generation for proportion-related infographics
[J].
Calliope: automatic visual data story generation from a spreadsheet
[J].DOI:10.1109/TVCG.2020.3030403 [本文引用: 1]
Integrating structured biological data by kernel maximum mean discrepancy
[J].DOI:10.1093/bioinformatics/btl242 [本文引用: 1]
Domain adaptation via transfer component analysis
[J].
In situ air temperature and humidity measurements over diverse land covers in Greenbelt, Maryland, november 2013–november 2015
[J].DOI:10.5194/essd-8-415-2016 [本文引用: 1]
Rolling element bearing diagnostics using the case western reserve university data: a benchmark study
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}