[1]
SU H, MAJI S, KALOGERAKIS E, et al. Multi-view convolutional neural networks for 3d shape recognition [C]// Proceedings of the IEEE International Conference on Computer Vision . Piscataway: IEEE, 2015: 945- 953.
[本文引用: 2]
[2]
QI C R, SU H, MO K, et al. Pointnet: deep learning on point sets for 3d classification and segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2017: 652-660.
[本文引用: 2]
[3]
FENG Y, FENG Y, YOU H, et al. Meshnet: mesh neural network for 3d shape representation [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Menlo Park: AAAI, 2019, 33(1): 8279-8286.
[本文引用: 2]
[4]
KLOKOV R, LEMPITSKY V. Escape from cells: deep kd-networks for the recognition of 3d point cloud models [C]// Proceedings of the IEEE International Conference on Computer Vision . Piscataway: IEEE, 2017: 863- 872.
[本文引用: 1]
[5]
HAN Z, LU H, LIU Z, et al 3D2SeqViews: aggregating sequential views for 3D global feature learning by CNN with hierarchical attention aggregation
[J]. IEEE Transactions on Image Processing , 2019 , 28 (8 ): 3986 - 3999
[本文引用: 1]
[6]
LI B, LU Y, LI C, et al A comparison of 3D shape retrieval methods based on a large-scale benchmark supporting multimodal queries
[J]. Computer Vision and Image Understanding , 2015 , 131 : 1 - 27
DOI:10.1016/j.cviu.2014.10.006
[本文引用: 1]
[7]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Advances in Neural Information Processing Systems . Long Beach: [s. n. ], 2017: 5998--6008.
[本文引用: 1]
[8]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale [C]// International Conference on Learning Representations . Vienna: [s. n. ], 2021.
[本文引用: 1]
[10]
OSADA R, FUNKHOUSER T, CHAZELLE B, et al Shape distributions
[J]. ACM Transactions on Graphics , 2002 , 21 (4 ): 807 - 832
DOI:10.1145/571647.571648
[本文引用: 1]
[11]
TABIA H, DAOUDI M, VANDEBORRE J P, et al A new 3D-matching method of nonrigid and partially similar models using curve analysis
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2010 , 33 (4 ): 852 - 858
[本文引用: 1]
[12]
AVETISYAN A, DAI A, NIEßNER M. End-to-end cad model retrieval and 9dof alignment in 3d scans [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Piscataway: IEEE, 2019: 2551-2560.
[本文引用: 1]
[13]
SARKAR K, HAMPIHOLI B, VARANASI K, et al. Learning 3d shapes as multi-layered height-maps using 2d convolutional networks [C]// Proceedings of the European Conference on Computer Vision . Berlin: Springer, 2018: 71-86.
[本文引用: 1]
[14]
YANG Z, WANG L. Learning relationships for multi-view 3D object recognition [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Piscataway: IEEE, 2019: 7505-7514.
[本文引用: 1]
[16]
SFIKAS K, PRATIKAKIS I, THEOHARIS T Ensemble of PANORAMA-based convolutional neural networks for 3D model classification and retrieval
[J]. Computers and Graphics , 2018 , 71 : 208 - 218
DOI:10.1016/j.cag.2017.12.001
[本文引用: 1]
[17]
PÉREZ-RÚA J M, VIELZEUF V, PATEUX S, et al. MFAS: multimodal fusion architecture search [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2019: 6966-6975.
[本文引用: 1]
[18]
ZHANG Q, LIU Y, BLUM R S, et al Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: a review
[J]. Information Fusion , 2018 , 40 : 57 - 75
DOI:10.1016/j.inffus.2017.05.006
[本文引用: 2]
[19]
HOU M, TANG J, ZHANG J, et al. Deep multimodal multilinear fusion with high-order polynomial pooling [C]// Advances in Neural Information Processing Systems . Vancouver: [s. n.], 2019.
[本文引用: 2]
[20]
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]// 3rd International Conference on Learning Representations . San Diego: IEEE, 2015.
[本文引用: 1]
[21]
MATURANA D, SCHERER S. Voxnet: a 3d convolutional neural network for real-time object recognition [C]// 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems . New York: IEEE, 2015: 922-928.
[本文引用: 2]
[22]
FENG Y, FENG Y, YOU H, et al. Meshnet: mesh neural network for 3d shape representation [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Menlo Park: AAAI, 2019: 8279-8286.
[本文引用: 1]
[23]
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Minneapolis: [s. n. ], 2019: 4171—4186.
[本文引用: 1]
[24]
WU Z, SONG S, KHOSLA A, et al. 3d shapenets: a deep representation for volumetric shapes [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2015: 1912-1920.
[本文引用: 1]
[25]
FENG Y, ZHANG Z, ZHAO X, et al. Gvcnn: group-view convolutional neural networks for 3d shape recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2018: 264-272.
[本文引用: 1]
[26]
HAN Z, SHANG M, LIU Z, et al SeqViews2SeqLabels: learning 3D global features via aggregating sequential views by RNN with attention
[J]. IEEE Transactions on Image Processing , 2018 , 28 (2 ): 658 - 672
[本文引用: 1]
[27]
QI C R, YI L, SU H, et al. Pointnet++: deep hierarchical feature learning on point sets in a metric space [C]// Advances in Neural Information Processing Systems . Long Beach: [s. n. ], 2017: 5099-5108.
[本文引用: 1]
[28]
LI Y, BU R, SUN M, et al. Pointcnn: convolution on x- transformed points [C]// Advances in Neural Information Processing Systems . Montreal: [s. n. ], 2018: 828-838.
[本文引用: 1]
[29]
ZHANG K, HAO M, WANG J, et al. Linked dynamic graph CNN: learning on point cloud via linking hierarchical features [EB/OL]. [2022-11-08]. https://arxiv.org/abs/1904.10014.
[本文引用: 1]
[30]
LU Y, WU Y, LIU B, et al. Cross-modality person reidentification with shared-specific feature transfer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2020: 13379-13389.
[本文引用: 1]
[31]
KRISHNA K, MURTY M N Genetic K-means algorithm
[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) , 1999 , 29 (3 ): 433
DOI:10.1109/3477.764879
[本文引用: 2]
[32]
MURTAGH F, CONTRERAS P Algorithms for hierarchical clustering: an overview
[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 2012 , 2 (1 ): 86 - 97
DOI:10.1002/widm.53
[本文引用: 1]
[33]
KHAN K, REHMAN S U, AZIZ K, et al. DBSCAN: past, present and future [C]// 5th International Conference on the Applications of Digital Information and Web Technologies . New York: IEEE, 2014: 232-238.
[本文引用: 1]
[34]
GHULI P, SHUKLA A, KIRAN R, et al Multidimensional canopy clustering on iterative MapReduce framework using Elefig tool
[J]. IETE Journal of Research , 2015 , 61 (1 ): 14 - 21
DOI:10.1080/03772063.2014.988760
[本文引用: 1]
[35]
LU Y, TIAN Z, PENG P, et al GMM clustering for heating load patterns in-depth identification and prediction model accuracy improvement of district heating system
[J]. Energy and Buildings , 2019 , 190 : 49 - 60
DOI:10.1016/j.enbuild.2019.02.014
[本文引用: 1]
[36]
VAN DER MAATEN L, HINTON G Visualizing data using t-SNE
[J]. Journal of Machine Learning Research , 2008 , 9 (11 ): 2579 - 2605
[本文引用: 1]
[37]
WATTENBERG M, VIÉGAS F, JOHNSON I How to use t-SNE effectively
[J]. Distill , 2016 , 1 (10 ): e2
[本文引用: 1]
[38]
QIAN G, SURAL S, GU Y, et al. Similarity between Euclidean and cosine angle distance for nearest neighbor queries [C]// Proceedings of the 2004 ACM Symposium on Applied Computing . New York: ACM, 2004: 1232-1237.
[本文引用: 1]
2
... 近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据. 与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性. 目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1 ] 算法、用于处理三维模型点云数据的PointNet[2 ] 算法、处理三维网格数据的MeshNet[3 ] 算法等. 为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4 ] 算法使用kd-tree的树状结构探索点云模型的结构,SeqView2SeqLabels[5 ] 算法使用序列模型探索三维模型多视图数据之间的视图关联性. Li等[6 ] 发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息. 鉴于自然语言处理领域中Transformer模型[7 ] 在各项任务上的优秀表现,Dosovitskiy等[8 ] 将其迁移至计算机视觉领域中,用于处理图像和三维模型数据. ...
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
2
... 近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据. 与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性. 目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1 ] 算法、用于处理三维模型点云数据的PointNet[2 ] 算法、处理三维网格数据的MeshNet[3 ] 算法等. 为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4 ] 算法使用kd-tree的树状结构探索点云模型的结构,SeqView2SeqLabels[5 ] 算法使用序列模型探索三维模型多视图数据之间的视图关联性. Li等[6 ] 发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息. 鉴于自然语言处理领域中Transformer模型[7 ] 在各项任务上的优秀表现,Dosovitskiy等[8 ] 将其迁移至计算机视觉领域中,用于处理图像和三维模型数据. ...
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
2
... 近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据. 与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性. 目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1 ] 算法、用于处理三维模型点云数据的PointNet[2 ] 算法、处理三维网格数据的MeshNet[3 ] 算法等. 为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4 ] 算法使用kd-tree的树状结构探索点云模型的结构,SeqView2SeqLabels[5 ] 算法使用序列模型探索三维模型多视图数据之间的视图关联性. Li等[6 ] 发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息. 鉴于自然语言处理领域中Transformer模型[7 ] 在各项任务上的优秀表现,Dosovitskiy等[8 ] 将其迁移至计算机视觉领域中,用于处理图像和三维模型数据. ...
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
1
... 近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据. 与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性. 目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1 ] 算法、用于处理三维模型点云数据的PointNet[2 ] 算法、处理三维网格数据的MeshNet[3 ] 算法等. 为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4 ] 算法使用kd-tree的树状结构探索点云模型的结构,SeqView2SeqLabels[5 ] 算法使用序列模型探索三维模型多视图数据之间的视图关联性. Li等[6 ] 发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息. 鉴于自然语言处理领域中Transformer模型[7 ] 在各项任务上的优秀表现,Dosovitskiy等[8 ] 将其迁移至计算机视觉领域中,用于处理图像和三维模型数据. ...
3D2SeqViews: aggregating sequential views for 3D global feature learning by CNN with hierarchical attention aggregation
1
2019
... 近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据. 与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性. 目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1 ] 算法、用于处理三维模型点云数据的PointNet[2 ] 算法、处理三维网格数据的MeshNet[3 ] 算法等. 为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4 ] 算法使用kd-tree的树状结构探索点云模型的结构,SeqView2SeqLabels[5 ] 算法使用序列模型探索三维模型多视图数据之间的视图关联性. Li等[6 ] 发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息. 鉴于自然语言处理领域中Transformer模型[7 ] 在各项任务上的优秀表现,Dosovitskiy等[8 ] 将其迁移至计算机视觉领域中,用于处理图像和三维模型数据. ...
A comparison of 3D shape retrieval methods based on a large-scale benchmark supporting multimodal queries
1
2015
... 近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据. 与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性. 目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1 ] 算法、用于处理三维模型点云数据的PointNet[2 ] 算法、处理三维网格数据的MeshNet[3 ] 算法等. 为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4 ] 算法使用kd-tree的树状结构探索点云模型的结构,SeqView2SeqLabels[5 ] 算法使用序列模型探索三维模型多视图数据之间的视图关联性. Li等[6 ] 发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息. 鉴于自然语言处理领域中Transformer模型[7 ] 在各项任务上的优秀表现,Dosovitskiy等[8 ] 将其迁移至计算机视觉领域中,用于处理图像和三维模型数据. ...
1
... 近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据. 与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性. 目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1 ] 算法、用于处理三维模型点云数据的PointNet[2 ] 算法、处理三维网格数据的MeshNet[3 ] 算法等. 为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4 ] 算法使用kd-tree的树状结构探索点云模型的结构,SeqView2SeqLabels[5 ] 算法使用序列模型探索三维模型多视图数据之间的视图关联性. Li等[6 ] 发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息. 鉴于自然语言处理领域中Transformer模型[7 ] 在各项任务上的优秀表现,Dosovitskiy等[8 ] 将其迁移至计算机视觉领域中,用于处理图像和三维模型数据. ...
1
... 近年来,越来越多的工作者开始使用深度学习方法处理三维模型数据. 与传统非深度学习的三维模型算法相比,基于深度学习的方法在准确率及各项指标上具有更好的表现,泛化能力更强,能够处理更复杂的问题,在实际应用中更具有可行性. 目前已有众多基于深度学习算法处理不同格式三维模型数据的研究,如使用三维模型多视图作为输入的MVCNN[1 ] 算法、用于处理三维模型点云数据的PointNet[2 ] 算法、处理三维网格数据的MeshNet[3 ] 算法等. 为了进一步提升算法的性能,许多研究开始转变为挖掘三维数据中的更多信息,如KD-Networks[4 ] 算法使用kd-tree的树状结构探索点云模型的结构,SeqView2SeqLabels[5 ] 算法使用序列模型探索三维模型多视图数据之间的视图关联性. Li等[6 ] 发现单一模态下的三维模型表征能力是有限的,因此三维模型算法的研究方向逐渐转变为融合多模态的数据以获得更多信息. 鉴于自然语言处理领域中Transformer模型[7 ] 在各项任务上的优秀表现,Dosovitskiy等[8 ] 将其迁移至计算机视觉领域中,用于处理图像和三维模型数据. ...
SHREC’22 track: open-set 3D object retrieval
1
2022
... 与此同时,Feng等[9 ] 开始研究基于开集数据的三维模型算法. 目前已有算法大多是基于闭集数据的,而在闭集数据上的研究成果难以应用于开集数据,在面对未知类的三维模型时难以发挥其优势,因此现有算法在开集数据上的准确率及各项指标往往较低. 考虑到三维模型在多个领域的发展趋势,将来会有更多新类型的三维模型参与到应用中,因此开放域下的三维模型算法研究具有重大意义. ...
Shape distributions
1
2002
... Osada等[10 ] 提出基于三维模型形状分布的算法,该研究提出计算任意三维多边形模型形状特征的算法. Hedi等[11 ] 提出适用于非刚性模型和局部相似模型的三维目标的匹配算法,该算法使用在特征点周围提取的三维曲线来表示模型的曲面. 随着深度学习领域的发展,许多基于深度学习的算法被提出. Avetisyan等[12 ] 提出端到端三维模型检索的方法,该方法将不完整的3D扫描模型转换为具有完整对象几何结构的CAD重建模型. ...
A new 3D-matching method of nonrigid and partially similar models using curve analysis
1
2010
... Osada等[10 ] 提出基于三维模型形状分布的算法,该研究提出计算任意三维多边形模型形状特征的算法. Hedi等[11 ] 提出适用于非刚性模型和局部相似模型的三维目标的匹配算法,该算法使用在特征点周围提取的三维曲线来表示模型的曲面. 随着深度学习领域的发展,许多基于深度学习的算法被提出. Avetisyan等[12 ] 提出端到端三维模型检索的方法,该方法将不完整的3D扫描模型转换为具有完整对象几何结构的CAD重建模型. ...
1
... Osada等[10 ] 提出基于三维模型形状分布的算法,该研究提出计算任意三维多边形模型形状特征的算法. Hedi等[11 ] 提出适用于非刚性模型和局部相似模型的三维目标的匹配算法,该算法使用在特征点周围提取的三维曲线来表示模型的曲面. 随着深度学习领域的发展,许多基于深度学习的算法被提出. Avetisyan等[12 ] 提出端到端三维模型检索的方法,该方法将不完整的3D扫描模型转换为具有完整对象几何结构的CAD重建模型. ...
1
... Sarkar等[13 ] 提出新的基于多层高度图(multi-layered height-maps, MLH)的三维形状全局表征算法,该方法中视图合并体系结构的引入融合了来自多个视图的视图关联信息. Yang等[14 ] 利用关系网络学习多视图之间的局部关联,采用增强模块作为网络中的关键结构,通过建模不同区域之间的相关性来增强多个视图的信息. Huang等[15 ] 提出新的基于视图的权重网络(view-based weight network, VWN),用于获取三维形状表征,其中基于视图的权重池层被设计用于特征聚合. 与基于多视图的方法相比,Sfikas等[16 ] 提出基于全景图的卷积神经网络算法,目的是通过使用三通道的全景图像构建增强图像表征,在捕获特征连续性的同时减少冗余信息. ...
1
... Sarkar等[13 ] 提出新的基于多层高度图(multi-layered height-maps, MLH)的三维形状全局表征算法,该方法中视图合并体系结构的引入融合了来自多个视图的视图关联信息. Yang等[14 ] 利用关系网络学习多视图之间的局部关联,采用增强模块作为网络中的关键结构,通过建模不同区域之间的相关性来增强多个视图的信息. Huang等[15 ] 提出新的基于视图的权重网络(view-based weight network, VWN),用于获取三维形状表征,其中基于视图的权重池层被设计用于特征聚合. 与基于多视图的方法相比,Sfikas等[16 ] 提出基于全景图的卷积神经网络算法,目的是通过使用三通道的全景图像构建增强图像表征,在捕获特征连续性的同时减少冗余信息. ...
View-based weight network for 3D object recognition
1
2020
... Sarkar等[13 ] 提出新的基于多层高度图(multi-layered height-maps, MLH)的三维形状全局表征算法,该方法中视图合并体系结构的引入融合了来自多个视图的视图关联信息. Yang等[14 ] 利用关系网络学习多视图之间的局部关联,采用增强模块作为网络中的关键结构,通过建模不同区域之间的相关性来增强多个视图的信息. Huang等[15 ] 提出新的基于视图的权重网络(view-based weight network, VWN),用于获取三维形状表征,其中基于视图的权重池层被设计用于特征聚合. 与基于多视图的方法相比,Sfikas等[16 ] 提出基于全景图的卷积神经网络算法,目的是通过使用三通道的全景图像构建增强图像表征,在捕获特征连续性的同时减少冗余信息. ...
Ensemble of PANORAMA-based convolutional neural networks for 3D model classification and retrieval
1
2018
... Sarkar等[13 ] 提出新的基于多层高度图(multi-layered height-maps, MLH)的三维形状全局表征算法,该方法中视图合并体系结构的引入融合了来自多个视图的视图关联信息. Yang等[14 ] 利用关系网络学习多视图之间的局部关联,采用增强模块作为网络中的关键结构,通过建模不同区域之间的相关性来增强多个视图的信息. Huang等[15 ] 提出新的基于视图的权重网络(view-based weight network, VWN),用于获取三维形状表征,其中基于视图的权重池层被设计用于特征聚合. 与基于多视图的方法相比,Sfikas等[16 ] 提出基于全景图的卷积神经网络算法,目的是通过使用三通道的全景图像构建增强图像表征,在捕获特征连续性的同时减少冗余信息. ...
1
... Pérez-Rúa等[17 ] 提出新的多模态融合网络结构,利用神经网络的方法指导融合操作. 该方法利用网络模型对各模态之间不同层次的输出进行评价,使用评价结果指导多模态融合进程. Zhang等[18 ] 提出基于稀疏表示的多模态融合算法,与传统的假定基函数的多尺度变换算法不同,基于稀疏表示的融合算法从1组训练图像中学习过完备字典(over-complete dictionary)进行图像融合,实现了对源图像更加稳定和有意义的表示. Hou等[19 ] 提出多模态融合算法,算法采用多项式张量池(polynomial tensor pooling, PTP)结构融合多模态特征,并以PTP为基本单元建立层次多项式融合网络(hierarchical polynomial fusion network, HPFN),递归地将局部关联信息进行传递,获得全局关联信息. ...
Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: a review
2
2018
... Pérez-Rúa等[17 ] 提出新的多模态融合网络结构,利用神经网络的方法指导融合操作. 该方法利用网络模型对各模态之间不同层次的输出进行评价,使用评价结果指导多模态融合进程. Zhang等[18 ] 提出基于稀疏表示的多模态融合算法,与传统的假定基函数的多尺度变换算法不同,基于稀疏表示的融合算法从1组训练图像中学习过完备字典(over-complete dictionary)进行图像融合,实现了对源图像更加稳定和有意义的表示. Hou等[19 ] 提出多模态融合算法,算法采用多项式张量池(polynomial tensor pooling, PTP)结构融合多模态特征,并以PTP为基本单元建立层次多项式融合网络(hierarchical polynomial fusion network, HPFN),递归地将局部关联信息进行传递,获得全局关联信息. ...
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
2
... Pérez-Rúa等[17 ] 提出新的多模态融合网络结构,利用神经网络的方法指导融合操作. 该方法利用网络模型对各模态之间不同层次的输出进行评价,使用评价结果指导多模态融合进程. Zhang等[18 ] 提出基于稀疏表示的多模态融合算法,与传统的假定基函数的多尺度变换算法不同,基于稀疏表示的融合算法从1组训练图像中学习过完备字典(over-complete dictionary)进行图像融合,实现了对源图像更加稳定和有意义的表示. Hou等[19 ] 提出多模态融合算法,算法采用多项式张量池(polynomial tensor pooling, PTP)结构融合多模态特征,并以PTP为基本单元建立层次多项式融合网络(hierarchical polynomial fusion network, HPFN),递归地将局部关联信息进行传递,获得全局关联信息. ...
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
1
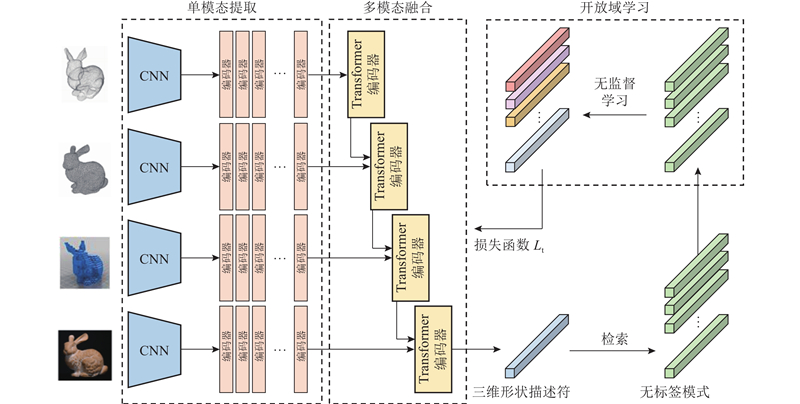
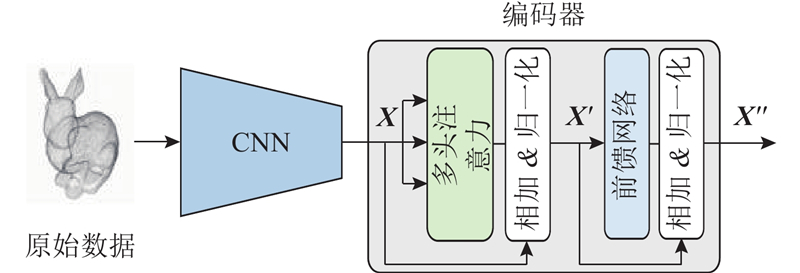
... 单模态特征提取网络的结构如图2 所示. 该网络用于处理不同模态的三维模型数据,包括多视图、点云、网格和体素数据. 设置4个支路用于分别提取不同模态的特征向量,其中多视图支路采用图像处理网络VggNet[20 ] ,多视图特征定义为 $ {{\boldsymbol{F}}_{\rm{i}}} $ . 点云支路使用VoxNet[21 ] 提取模型的局部特征 $ {{\boldsymbol{F}}_{\rm{p}}} $ . 网格支路使用MeshNet[22 ] 提取特征向量 $ {{\boldsymbol{F}}_{\rm{m}}} $ $ {{\boldsymbol{F}}_{\rm{v}}} $ . 在获得作为各模态的特征向量后,在每个支路后端分别设置多层堆叠的Transformer编码器结构,用于学习三维模型模态内的关联信息,并采用该结构更新特征向量. 每层编码器都包含2个子层,分别为自注意力层和前馈网络. ...
2
... 单模态特征提取网络的结构如图2 所示. 该网络用于处理不同模态的三维模型数据,包括多视图、点云、网格和体素数据. 设置4个支路用于分别提取不同模态的特征向量,其中多视图支路采用图像处理网络VggNet[20 ] ,多视图特征定义为 $ {{\boldsymbol{F}}_{\rm{i}}} $ . 点云支路使用VoxNet[21 ] 提取模型的局部特征 $ {{\boldsymbol{F}}_{\rm{p}}} $ . 网格支路使用MeshNet[22 ] 提取特征向量 $ {{\boldsymbol{F}}_{\rm{m}}} $ $ {{\boldsymbol{F}}_{\rm{v}}} $ . 在获得作为各模态的特征向量后,在每个支路后端分别设置多层堆叠的Transformer编码器结构,用于学习三维模型模态内的关联信息,并采用该结构更新特征向量. 每层编码器都包含2个子层,分别为自注意力层和前馈网络. ...
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
1
... 单模态特征提取网络的结构如图2 所示. 该网络用于处理不同模态的三维模型数据,包括多视图、点云、网格和体素数据. 设置4个支路用于分别提取不同模态的特征向量,其中多视图支路采用图像处理网络VggNet[20 ] ,多视图特征定义为 $ {{\boldsymbol{F}}_{\rm{i}}} $ . 点云支路使用VoxNet[21 ] 提取模型的局部特征 $ {{\boldsymbol{F}}_{\rm{p}}} $ . 网格支路使用MeshNet[22 ] 提取特征向量 $ {{\boldsymbol{F}}_{\rm{m}}} $ $ {{\boldsymbol{F}}_{\rm{v}}} $ . 在获得作为各模态的特征向量后,在每个支路后端分别设置多层堆叠的Transformer编码器结构,用于学习三维模型模态内的关联信息,并采用该结构更新特征向量. 每层编码器都包含2个子层,分别为自注意力层和前馈网络. ...
1
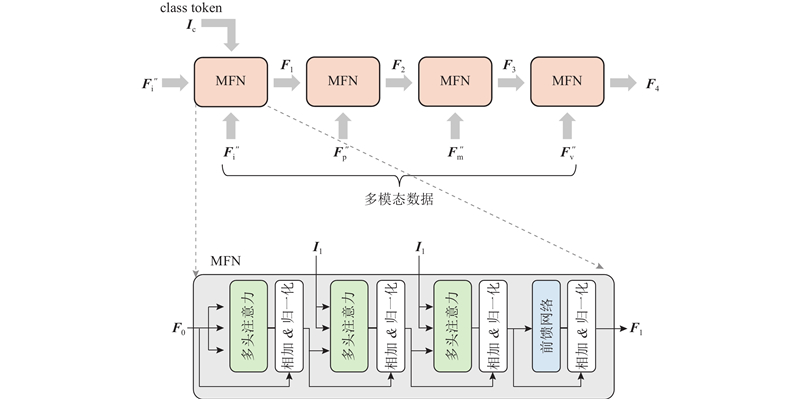
... 考虑到基于Transformer的BERT算法[23 ] 在输入数据中加入class token,专门用于进行分类任务,以消除网络对某个样本的偏向性. 鉴于BERT算法在表征任务上的先进性,本文算法设置了class token用于分类. 当 $ t $ $ t - 1 $ $ {{\boldsymbol{F}}_0} $ $ {{\boldsymbol{I}}_1} $ $ {{\boldsymbol{F}}_0} \in {\bf{R}}^{(N+1) d} $ . 网络最终层输出 $ {{\boldsymbol{F}}_{\rm{h}}} $
1
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
1
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
SeqViews2SeqLabels: learning 3D global features via aggregating sequential views by RNN with attention
1
2018
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
1
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
1
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
1
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
1
... Retrieval performance of various algorithms in unknown class data sets
Tab.1 方法 数据模态 mAP/% NN/% NDCG/% ANMRR/% 3D ShapeNets[24 ] 体素 71.41 93.05 84.83 30.38 MeshNet[3 ] 网格 82.15 96.55 87.52 27.20 MVCNN[1 ] 多视图 83.86 95.97 88.75 26.55 GVCNN[25 ] 多视图 84.94 97.01 88.63 25.83 SeqViews2SeqLabels[26 ] 多视图 83.55 97.47 86.52 26.45 VoxNet[21 ] 点云 76.86 95.32 85.12 32.55 PointNet[2 ] 点云 81.72 94.55 85.56 29.86 PointNet++[27 ] 点云 82.10 95.71 86.57 28.54 PointCNN[28 ] 点云 83.33 96.29 87.28 26.75 LDGCNN[29 ] 点云 83.98 96.15 88.92 26.25 MSIF[18 ] 多模态 85.12 96.81 88.79 27.37 HPFN[19 ] 多模态 85.45 97.03 89.24 26.72 SSFT[30 ] 多模态 85.89 97.44 89.83 26.63 本文方法 体素 77.25 93.85 85.01 29.81 本文方法 网格 82.86 96.79 87.61 27.46 本文方法 多视图 85.07 97.32 89.37 26.38 本文方法 点云 84.19 96.85 89.16 26.49 本文方法 多模态 86.23 97.82 90.13 26.17
使用编码器更新特征间关联性,借助多模态融合及无监督学习带来的信息优势,在开放域条件下取得了优秀的检索性能. 本文算法的mAP指标为86.23%,与之前的最佳方法GVCNN相比提升了1.29%,在对比实验中实现了最佳的检索性能,验证了本文算法在检索性能上的先进性. 从实验结果可知,即使只采用单模态形式,本文方法的检索性能也比相应模态的方法更好,主要原因是采用无监督算法能够显著提升模型在开放域上的性能表现. ...
Genetic K-means algorithm
2
1999
... 采用无监督算法生产样本的伪标签作为分类参考,以实现网络参数的优化. 其中无监督算法选择了常见的K-means方法[31 ] . 为了探究聚类方法对网络模型检索性能的影响,开展无监督算法间的对比实验. ...
... Retrieval performance of proposed algorithm under different unsupervised algorithms
Tab.4 算法 mAP/% NN/% NDCG/% ANMRR/% K-means[31 ] 86.23 97.82 90.13 26.17 层级式聚类[32 ] 84.56 96.97 87.55 25.47 DBSCAN[33 ] 85.37 97.33 88.95 26.73 Canopy[34 ] 82.53 94.45 83.03 35.78 GMM[35 ] 83.42 95.98 86.27 28.70
3.7. 多模态表征对比实验 利用多模态融合得到表征能力更强的三维模型描述符,以提升检索性能. 为了验证多模态对三维描述符表征能力和网络检索性能的影响,开展多模态表征对比实验. ...
Algorithms for hierarchical clustering: an overview
1
2012
... Retrieval performance of proposed algorithm under different unsupervised algorithms
Tab.4 算法 mAP/% NN/% NDCG/% ANMRR/% K-means[31 ] 86.23 97.82 90.13 26.17 层级式聚类[32 ] 84.56 96.97 87.55 25.47 DBSCAN[33 ] 85.37 97.33 88.95 26.73 Canopy[34 ] 82.53 94.45 83.03 35.78 GMM[35 ] 83.42 95.98 86.27 28.70
3.7. 多模态表征对比实验 利用多模态融合得到表征能力更强的三维模型描述符,以提升检索性能. 为了验证多模态对三维描述符表征能力和网络检索性能的影响,开展多模态表征对比实验. ...
1
... Retrieval performance of proposed algorithm under different unsupervised algorithms
Tab.4 算法 mAP/% NN/% NDCG/% ANMRR/% K-means[31 ] 86.23 97.82 90.13 26.17 层级式聚类[32 ] 84.56 96.97 87.55 25.47 DBSCAN[33 ] 85.37 97.33 88.95 26.73 Canopy[34 ] 82.53 94.45 83.03 35.78 GMM[35 ] 83.42 95.98 86.27 28.70
3.7. 多模态表征对比实验 利用多模态融合得到表征能力更强的三维模型描述符,以提升检索性能. 为了验证多模态对三维描述符表征能力和网络检索性能的影响,开展多模态表征对比实验. ...
Multidimensional canopy clustering on iterative MapReduce framework using Elefig tool
1
2015
... Retrieval performance of proposed algorithm under different unsupervised algorithms
Tab.4 算法 mAP/% NN/% NDCG/% ANMRR/% K-means[31 ] 86.23 97.82 90.13 26.17 层级式聚类[32 ] 84.56 96.97 87.55 25.47 DBSCAN[33 ] 85.37 97.33 88.95 26.73 Canopy[34 ] 82.53 94.45 83.03 35.78 GMM[35 ] 83.42 95.98 86.27 28.70
3.7. 多模态表征对比实验 利用多模态融合得到表征能力更强的三维模型描述符,以提升检索性能. 为了验证多模态对三维描述符表征能力和网络检索性能的影响,开展多模态表征对比实验. ...
GMM clustering for heating load patterns in-depth identification and prediction model accuracy improvement of district heating system
1
2019
... Retrieval performance of proposed algorithm under different unsupervised algorithms
Tab.4 算法 mAP/% NN/% NDCG/% ANMRR/% K-means[31 ] 86.23 97.82 90.13 26.17 层级式聚类[32 ] 84.56 96.97 87.55 25.47 DBSCAN[33 ] 85.37 97.33 88.95 26.73 Canopy[34 ] 82.53 94.45 83.03 35.78 GMM[35 ] 83.42 95.98 86.27 28.70
3.7. 多模态表征对比实验 利用多模态融合得到表征能力更强的三维模型描述符,以提升检索性能. 为了验证多模态对三维描述符表征能力和网络检索性能的影响,开展多模态表征对比实验. ...
Visualizing data using t-SNE
1
2008
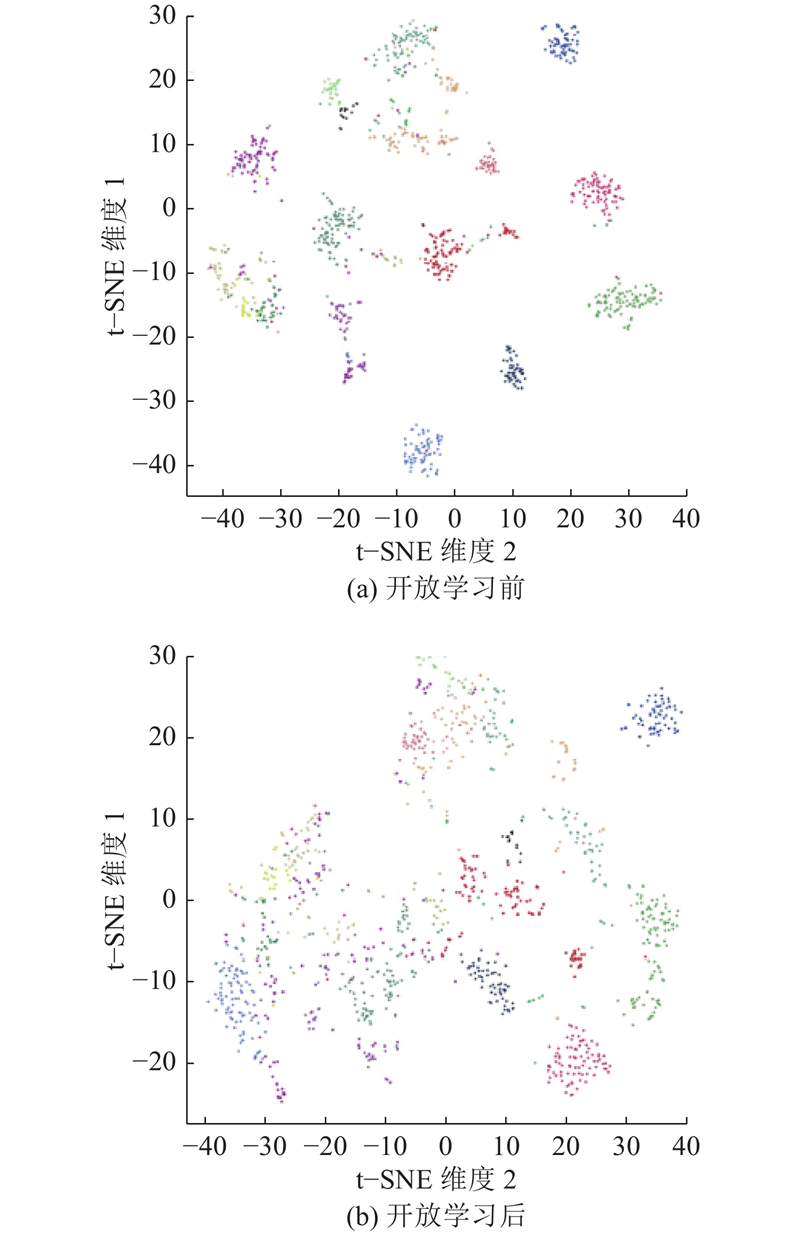
... 为了体现本文方法在检索任务上的优越性,开展可视化实验. 采用t-SNE(t-distributed stochastic neighbor embedding)方法进行可视化[36 ] ,具体而言,使用t-SNE方法将数据集中所有样本的高维特征进行降维,以获得每个样本的二维表示,近似地展示高维特征的分布情况[37 ] . 为了验证开放域条件下的检索性能,提取无标签数据集内的样本特征,其中包含20类的三维模型样本. ...
How to use t-SNE effectively
1
2016
... 为了体现本文方法在检索任务上的优越性,开展可视化实验. 采用t-SNE(t-distributed stochastic neighbor embedding)方法进行可视化[36 ] ,具体而言,使用t-SNE方法将数据集中所有样本的高维特征进行降维,以获得每个样本的二维表示,近似地展示高维特征的分布情况[37 ] . 为了验证开放域条件下的检索性能,提取无标签数据集内的样本特征,其中包含20类的三维模型样本. ...
1
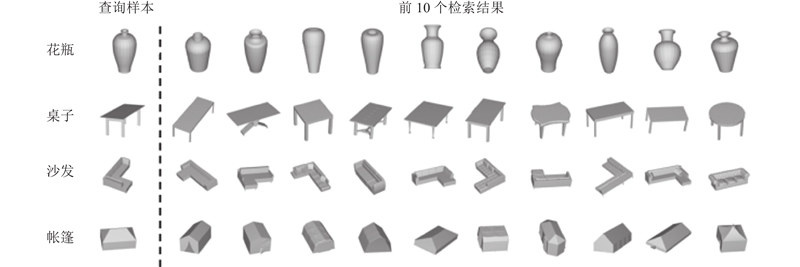
... 如图6 所示为本文算法在开放域条件下的部分检索效果图,展示了输入的三维模型样本以及数据集中与其最相似的10个三维模型. 提取输入三维模型的特征向量,将其与开放域数据集中所有样本的特征向量进行相似度比较;按照相似度从高到低的原则,对检索结果进行排序,将排序结果作为输出结果,其中使用的相似性度量方法为余弦距离[38 ] . 从结果可以看出,检索结果基本与输入的待检索样本一致,表明本文提出的表征模型能够实现对开放域未标注数据的有效探索和高效表征. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}