[1]
史钰祜, 张起贵 基于局部注意的快速视频目标检测方法
[J]. 计算机工程 , 2022 , 48 (5 ): 314 - 320
[本文引用: 2]
SHI Yuhu, ZHANG Qigui Method for fast video object detection based on local attention
[J]. Computer Engineering , 2022 , 48 (5 ): 314 - 320
[本文引用: 2]
[2]
ZHU X, WANG Y, DAI J, et al. Flow-guided feature aggregation for video object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Venice: IEEE, 2017: 408-417.
[本文引用: 1]
[3]
ZHU X, XIONG Y, DAI J, et al. Deep feature flow for video recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2349-2358.
[本文引用: 1]
[4]
FEICHTENHOFER C, PINZ A, ZISSERMAN A. Detect to track and track to detect [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Venice: IEEE, 2017: 3038-3046.
[本文引用: 1]
[5]
KANG K, LI H, YAN J, et al T-CNN: tubelets with convolutional neural networks for object detection from videos
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2017 , 28 (10 ): 2896 - 2907
[本文引用: 1]
[6]
HAN M, WANG Y, CHANG X, et al. Mining inter-video proposal relations for video object detection [C]// Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 431-446.
[本文引用: 1]
[7]
HE F, GAO N, JIA J, et al. QueryProp: object query propagation for high-performance video object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2022, 36(1): 834-842.
[本文引用: 2]
[8]
JIAO L, ZHANG R, LIU F, et al New generation deep learning for video object detection: a survey
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2022 , 33 (8 ): 3195 - 3215
DOI:10.1109/TNNLS.2021.3053249
[本文引用: 1]
[9]
WU H, CHEN Y, WANG N, et al. Sequence level semantics aggregation for video object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9217-9225.
[本文引用: 1]
[10]
CHEN Y, CAO Y, HU H, et al. Memory enhanced global-local aggregation for video object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10337-10346.
[本文引用: 2]
[11]
JIANG Z, LIU Y, YANG C, et al. Learning where to focus for efficient video object detection [C]// Proceedings of European Conference on Computer Vision . Berlin: Springer, 2020: 18-34.
[本文引用: 2]
[12]
RUSSAKOVSKY O, DENG J, SU H, et al Imagenet large scale visual recognition challenge
[J]. International Journal of Computer Vision , 2015 , 115 (3 ): 211 - 252
DOI:10.1007/s11263-015-0816-y
[本文引用: 2]
[13]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580-587.
[本文引用: 1]
[14]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2016: 779-788.
[本文引用: 1]
[15]
李凯, 林宇舜, 吴晓琳, 等 基于多尺度融合与注意力机制的小目标车辆检测
[J]. 浙江大学学报: 工学版 , 2022 , 56 (11 ): 2241 - 2250
[本文引用: 1]
LI Kai, LIN Yushun, WU Xiaolin, et al Small target vehicle detection based on multi-scale fusion technology and attention mechanism
[J]. Journal of ZheJiang University: Engineering Science , 2022 , 56 (11 ): 2241 - 2250
[本文引用: 1]
[16]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Honolulu: IEEE, 2017: 6517–6525.
[本文引用: 1]
[17]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-04-08)[2023-07-31]. https://arxiv.org/abs/1804.02767.
[本文引用: 1]
[18]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the European Conference on Computer Vision . [S. l. ]: Springer, 2016: 21-37.
[本文引用: 1]
[19]
YAN B, FAN P, LEI X, et al A real-time apple targets detection method for picking robot based on improved YOLOv5
[J]. Remote Sensing , 2021 , 13 (9 ): 1619 - 1627
DOI:10.3390/rs13091619
[本文引用: 1]
[20]
GE Z, LIU S, WANG F, et al. Yolox: exceeding yolo series in 2021 [EB/OL]. (2021-08-06)[2023-07-31]. https://arxiv.org/abs/2107.08430.
[本文引用: 2]
[21]
于楠晶, 范晓飚, 邓天民, 等 基于多头自注意力的复杂背景船舶检测算法
[J]. 浙江大学学报: 工学版 , 2022 , 56 (12 ): 2392 - 2402
[本文引用: 1]
YU Nanjing, FAN Xiaobiao, DENG Tianmin, et al Ship detection algorithm in complex backgrounds via multi-head self-attention
[J]. Journal of ZheJiang University: Engineering Science , 2022 , 56 (12 ): 2392 - 2402
[本文引用: 1]
[22]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// In Proceedings of the 31st International Conference on Neural Information Processing Systems . Red Hook: Curran Associates Inc. , 2017: 6000–6010.
[本文引用: 1]
[23]
NEUBECK A, VAN G L. Efficient non-maximum suppression [C]// 18th International Conference on Pattern Recognition . Hong Kong: IEEE, 2006: 850-855.
[本文引用: 1]
[24]
张娜, 戚旭磊, 包晓安, 等 基于25预测定位的单阶段目标检测算法
[J]. 浙江大学学报: 工学版 , 2022 , 56 (4 ): 783 - 794
[本文引用: 1]
ZHANG Na, QI Xulei, BAO Xiaoan, et al Single-stage object detection algorithm based on optimizing position prediction
[J]. Journal of ZheJiang University: Engineering Science , 2022 , 56 (4 ): 783 - 794
[本文引用: 1]
[25]
SUN G, HUA Y, HU G, et al. Mamba: multi-level aggregation via memory bank for video object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2021: 2620-2627.
[本文引用: 1]
[26]
WANG H, TANG J, LIU X, et al. PTSEFormer: progressive temporal-spatial enhanced TransFormer towards video object detection [C]// Proceedings of the European Conference on Computer Vision . Tel Aviv: Springer, 2022: 732-747.
[本文引用: 2]
[27]
EFRAIMIDIS P S, SPIRAKIS P G Weighted random sampling with a reservoir
[J]. Information Processing Letters , 2006 , 97 (5 ): 181 - 185
DOI:10.1016/j.ipl.2005.11.003
[本文引用: 1]
[28]
TAN M, LE Q. Efficientnet: rethinking model scaling for convolutional neural networks [C]// International Conference on Machine Learning . Long Beach: [s. n.], 2019: 6105-6114.
[本文引用: 1]
[29]
ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2020: 12993-13000.
[本文引用: 1]
[30]
KIM J, KOH J, LEE B, et al. Video object detection using object's motion context and spatio-temporal feature aggregation [C]// 25th International Conference on Pattern Recognition . Milan: IEEE, 2021: 1604-1610.
[本文引用: 1]
[31]
蔡强, 李韩玉, 李楠, 等 基于时序信息和注意力机制的视频目标检测
[J]. 计算机仿真 , 2021 , 38 (12 ): 380 - 385
DOI:10.3969/j.issn.1006-9348.2021.12.078
[本文引用: 1]
CAI Qiang, LI Hanyu, LI Nan, et al Video object detection with temporal information and attention mechanism
[J]. Computer Simulation , 2021 , 38 (12 ): 380 - 385
DOI:10.3969/j.issn.1006-9348.2021.12.078
[本文引用: 1]
[32]
EHTESHAMI B B, HABIBIAN A, PORIKLI F, et al. SALISA: saliency-based input sampling for efficient video object detection [C]// Proceedings of the European Conference on Computer Vision . Tel Aviv: Springer, 2022: 300–316.
[本文引用: 1]
基于局部注意的快速视频目标检测方法
2
2022
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
基于局部注意的快速视频目标检测方法
2
2022
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
1
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
1
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
1
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
T-CNN: tubelets with convolutional neural networks for object detection from videos
1
2017
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
1
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
2
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
New generation deep learning for video object detection: a survey
1
2022
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
1
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
2
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
2
... 视频目标检测是计算机视觉领域的一项基础任务,在社会安防、国防军事和智能交通等领域中有着广泛的应用需求[1 ] . 近年来,基于深度学习的视频目标检测算法取得了显著的进展,这些方法可以大致分为基于光流的方法[2 -3 ] 、基于视频目标跟踪的方法[4 -5 ] 和基于注意力机制的方法[6 -7 ] . 基于光流的算法使用额外的光流模型,显著增加了目标检测整体模型参数量;基于视频目标跟踪的方法使用了额外的任务,而不是让网络直接检测目标. 这2种方法的速度和准确性存在很大的不平衡[8 ] . 基于注意力机制的方法考虑图像特征聚合的计算成本,序列级语义聚合算法(sequence level semantics aggregation algorithm, SESLA)[9 ] 作为基于注意力机制的方法代表,根据区域级特征之间的语义相似性,提出长程特征聚合方案. Chen等[10 ] 设计全局-局部聚合模块,以更好地建模目标之间的关系. Jiang等[11 ] 提出称为可学习的时空采样(learnable spatio-temporal sampling, LSTS)模块,用于学习相邻帧特征之间语义层次的依赖关系. 现有方法大多因采用固定的采样策略,可能无法充分利用视频序列中的全局上下文信息. 另外,现有算法由于无法有效、准确地融合不同的尺度和多层级的特征,常常导致目标的误检、漏检问题. ...
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
Imagenet large scale visual recognition challenge
2
2015
... (3)在ImageNet VID数据集[12 ] 上进行实验,结果表明,所提出的MMNet具有检测速度较快、精度较高的优点,可以较好地解决视频目标检测算法检测精度和速度不平衡的问题,证明了该方法的有效性. ...
... 在ILSVRC2015挑战赛中引入的ImageNet VID数据集上进行模型训练与测试. ImageNet VID数据集包含30个基本类别,是ImageNet DET数据集[12 ] 中200个基本类别的子集. 具体来说,ImageNet VID数据集包含3 862个用于训练的视频、555个用于验证的视频和937个用于测试的视频,在训练集和验证集的视频帧上都被标记上真实值的检测框. 训练集的每段视频包含6~5 492帧图像,单帧图像均为720像素的高分辨率图像,所以仅训练集就达到100多万张图像,这种大规模的数据有利于拟合一个较好的模型,以完成视频目标检测任务. 为了使数据集富有多样性,挑选静态图像目标检测数据集ImageNet DET中相同数量的对应类别的图片作为训练数据集的补充. ...
1
... 基础的图像检测器主要分为单阶段和两阶段检测器. 基于区域的卷积神经网络(region based convolutional neural network, RCNN)[13 ] ,提出两阶段目标检测器的基本框架. 针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14 ] 提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15 ] . Joseph等在YOLO的基础上进行一系列改进,提出YOLO的v2[16 ] 和v3[17 ] 版本. Liu等[18 ] 提出另一种单阶段目标检测方法——单阶段多边框检测算法(single-stage multibox detector algorithm, SSD). Yan等[19 ] 提出YOLOv5,设计不同的CSP结构和多个版本,提高了网络特征的融合能力. ...
1
... 基础的图像检测器主要分为单阶段和两阶段检测器. 基于区域的卷积神经网络(region based convolutional neural network, RCNN)[13 ] ,提出两阶段目标检测器的基本框架. 针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14 ] 提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15 ] . Joseph等在YOLO的基础上进行一系列改进,提出YOLO的v2[16 ] 和v3[17 ] 版本. Liu等[18 ] 提出另一种单阶段目标检测方法——单阶段多边框检测算法(single-stage multibox detector algorithm, SSD). Yan等[19 ] 提出YOLOv5,设计不同的CSP结构和多个版本,提高了网络特征的融合能力. ...
基于多尺度融合与注意力机制的小目标车辆检测
1
2022
... 基础的图像检测器主要分为单阶段和两阶段检测器. 基于区域的卷积神经网络(region based convolutional neural network, RCNN)[13 ] ,提出两阶段目标检测器的基本框架. 针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14 ] 提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15 ] . Joseph等在YOLO的基础上进行一系列改进,提出YOLO的v2[16 ] 和v3[17 ] 版本. Liu等[18 ] 提出另一种单阶段目标检测方法——单阶段多边框检测算法(single-stage multibox detector algorithm, SSD). Yan等[19 ] 提出YOLOv5,设计不同的CSP结构和多个版本,提高了网络特征的融合能力. ...
基于多尺度融合与注意力机制的小目标车辆检测
1
2022
... 基础的图像检测器主要分为单阶段和两阶段检测器. 基于区域的卷积神经网络(region based convolutional neural network, RCNN)[13 ] ,提出两阶段目标检测器的基本框架. 针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14 ] 提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15 ] . Joseph等在YOLO的基础上进行一系列改进,提出YOLO的v2[16 ] 和v3[17 ] 版本. Liu等[18 ] 提出另一种单阶段目标检测方法——单阶段多边框检测算法(single-stage multibox detector algorithm, SSD). Yan等[19 ] 提出YOLOv5,设计不同的CSP结构和多个版本,提高了网络特征的融合能力. ...
1
... 基础的图像检测器主要分为单阶段和两阶段检测器. 基于区域的卷积神经网络(region based convolutional neural network, RCNN)[13 ] ,提出两阶段目标检测器的基本框架. 针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14 ] 提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15 ] . Joseph等在YOLO的基础上进行一系列改进,提出YOLO的v2[16 ] 和v3[17 ] 版本. Liu等[18 ] 提出另一种单阶段目标检测方法——单阶段多边框检测算法(single-stage multibox detector algorithm, SSD). Yan等[19 ] 提出YOLOv5,设计不同的CSP结构和多个版本,提高了网络特征的融合能力. ...
1
... 基础的图像检测器主要分为单阶段和两阶段检测器. 基于区域的卷积神经网络(region based convolutional neural network, RCNN)[13 ] ,提出两阶段目标检测器的基本框架. 针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14 ] 提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15 ] . Joseph等在YOLO的基础上进行一系列改进,提出YOLO的v2[16 ] 和v3[17 ] 版本. Liu等[18 ] 提出另一种单阶段目标检测方法——单阶段多边框检测算法(single-stage multibox detector algorithm, SSD). Yan等[19 ] 提出YOLOv5,设计不同的CSP结构和多个版本,提高了网络特征的融合能力. ...
1
... 基础的图像检测器主要分为单阶段和两阶段检测器. 基于区域的卷积神经网络(region based convolutional neural network, RCNN)[13 ] ,提出两阶段目标检测器的基本框架. 针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14 ] 提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15 ] . Joseph等在YOLO的基础上进行一系列改进,提出YOLO的v2[16 ] 和v3[17 ] 版本. Liu等[18 ] 提出另一种单阶段目标检测方法——单阶段多边框检测算法(single-stage multibox detector algorithm, SSD). Yan等[19 ] 提出YOLOv5,设计不同的CSP结构和多个版本,提高了网络特征的融合能力. ...
A real-time apple targets detection method for picking robot based on improved YOLOv5
1
2021
... 基础的图像检测器主要分为单阶段和两阶段检测器. 基于区域的卷积神经网络(region based convolutional neural network, RCNN)[13 ] ,提出两阶段目标检测器的基本框架. 针对两阶段检测器普遍存在的运算速度慢的缺点,YOLO[14 ] 提出单阶段检测器,不需要生成候选框,直接将边框的定位问题转化为回归问题,提升了检测速度[15 ] . Joseph等在YOLO的基础上进行一系列改进,提出YOLO的v2[16 ] 和v3[17 ] 版本. Liu等[18 ] 提出另一种单阶段目标检测方法——单阶段多边框检测算法(single-stage multibox detector algorithm, SSD). Yan等[19 ] 提出YOLOv5,设计不同的CSP结构和多个版本,提高了网络特征的融合能力. ...
2
... 采用YOLOX-S单阶段检测器作为基础检测器,因为其具有高性能、高效性和多尺度特征表示的优势. YOLOX-S是YOLOX系列[20 ] 的标准化版本之一,是对YOLOv5系列中的YOLOv5-S进行一系列改进得到的. YOLOX-S作为轻量级模型,在保持较高检测精度的同时,具有较小的模型体积和内存占用. YOLOX通过使用多尺度特征表示来提高目标检测的准确性,使用解耦检测头和简化的最优传输样本匹配方案(simplified optimal transport assignment, SimOTA)技术,能够在不同尺度上检测目标物体,综合利用多层级的特征表示,使得YOLOX在处理视频中不同尺度的目标物体时更具优势. ...
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
基于多头自注意力的复杂背景船舶检测算法
1
2022
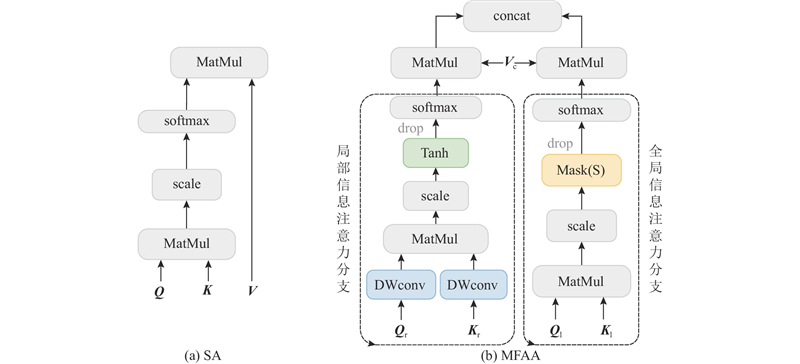
... 注意力机制是从大量信息中筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息. 标准的自注意力机制(self-attention, SA)是注意力机制的变体,减少了对外部信息的依赖,擅长捕捉数据或特征的内部相关性[21 ] ,结构如图1 (a)所示. ...
基于多头自注意力的复杂背景船舶检测算法
1
2022
... 注意力机制是从大量信息中筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息. 标准的自注意力机制(self-attention, SA)是注意力机制的变体,减少了对外部信息的依赖,擅长捕捉数据或特征的内部相关性[21 ] ,结构如图1 (a)所示. ...
1
... 注意力函数的输出为值 ${{\boldsymbol{V}}}$ [22 ] 得到,计算过程为 ...
1
... 构建的视频目标检测网络MMNet的框架如图2 所示,输入为一系列连续的视频帧,输出标记目标类别和位置的视频帧. 将输入的视频帧通过混合加权参考帧采样,得到一系列随机参考帧和关键帧的前后连续帧. 将得到的视频帧入到单阶段检测器YOLOX-S中进行特征提取,输出初步的分类和回归的预测特征 ${{{\boldsymbol{X}}}_{\rm{c}}}$ ${{{\boldsymbol{X}}}_{\rm{r}}}$ . 由于大多数初步预测结果的置信度较低,需要从特征图中选择高质量的特征. 使用topK算法,根据置信度分数由高到低排序,挑选出前750个预测特征. 使用非最大抑制(non-maximum suppression, NMS)算法[23 ] ,通过不断检索分类置信度最高的检测框,使用交集-重叠来表示2个边界框之间的内在关联,将大于人工给定阈值的边界框视作冗余检测框删去,以减少冗余[24 ] . 将选择后的特征输入多级特征聚合注意力模块,在不同尺度上聚合分类和回归的特征后进行最终分类. ...
基于25预测定位的单阶段目标检测算法
1
2022
... 构建的视频目标检测网络MMNet的框架如图2 所示,输入为一系列连续的视频帧,输出标记目标类别和位置的视频帧. 将输入的视频帧通过混合加权参考帧采样,得到一系列随机参考帧和关键帧的前后连续帧. 将得到的视频帧入到单阶段检测器YOLOX-S中进行特征提取,输出初步的分类和回归的预测特征 ${{{\boldsymbol{X}}}_{\rm{c}}}$ ${{{\boldsymbol{X}}}_{\rm{r}}}$ . 由于大多数初步预测结果的置信度较低,需要从特征图中选择高质量的特征. 使用topK算法,根据置信度分数由高到低排序,挑选出前750个预测特征. 使用非最大抑制(non-maximum suppression, NMS)算法[23 ] ,通过不断检索分类置信度最高的检测框,使用交集-重叠来表示2个边界框之间的内在关联,将大于人工给定阈值的边界框视作冗余检测框删去,以减少冗余[24 ] . 将选择后的特征输入多级特征聚合注意力模块,在不同尺度上聚合分类和回归的特征后进行最终分类. ...
基于25预测定位的单阶段目标检测算法
1
2022
... 构建的视频目标检测网络MMNet的框架如图2 所示,输入为一系列连续的视频帧,输出标记目标类别和位置的视频帧. 将输入的视频帧通过混合加权参考帧采样,得到一系列随机参考帧和关键帧的前后连续帧. 将得到的视频帧入到单阶段检测器YOLOX-S中进行特征提取,输出初步的分类和回归的预测特征 ${{{\boldsymbol{X}}}_{\rm{c}}}$ ${{{\boldsymbol{X}}}_{\rm{r}}}$ . 由于大多数初步预测结果的置信度较低,需要从特征图中选择高质量的特征. 使用topK算法,根据置信度分数由高到低排序,挑选出前750个预测特征. 使用非最大抑制(non-maximum suppression, NMS)算法[23 ] ,通过不断检索分类置信度最高的检测框,使用交集-重叠来表示2个边界框之间的内在关联,将大于人工给定阈值的边界框视作冗余检测框删去,以减少冗余[24 ] . 将选择后的特征输入多级特征聚合注意力模块,在不同尺度上聚合分类和回归的特征后进行最终分类. ...
1
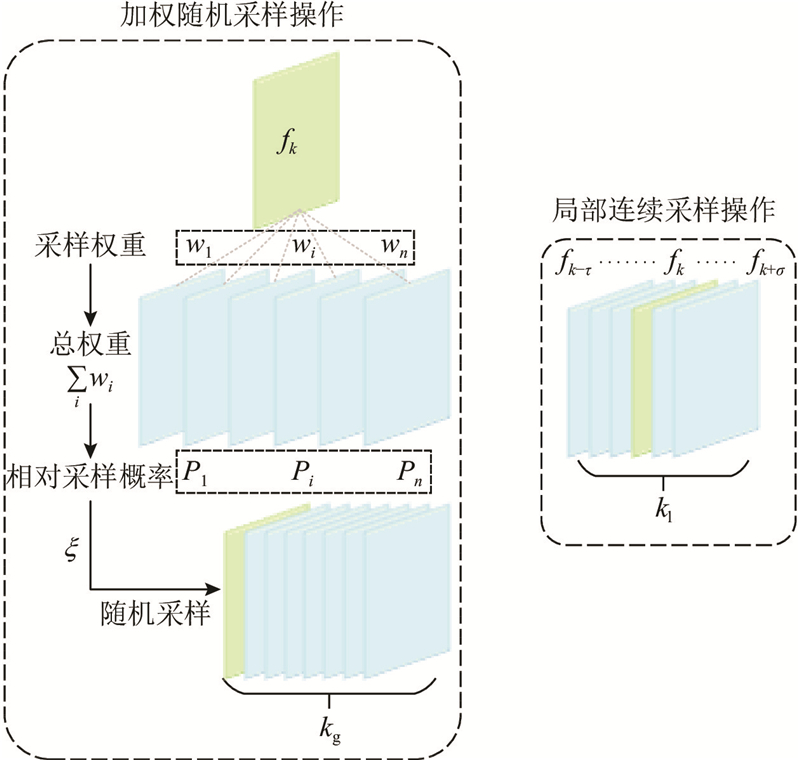
... 研究能够平衡检测准确性和效率的采样策略,对于视频目标检测任务至关重要. 主流的采样方法一般采用全局随机采样[25 ] 或者局部采样[26 ] . 这2种采样方法都存在因为特征捕获不全面导致的特征聚合不足的问题. 全局采样方法缺乏来自相邻帧的空间和时间信息,失去了视频的时间维度优势;局部采样在目标运动速度较快或者遮挡严重的情况下,为关键帧检测提供的有效信息少. 为了解决这些问题,更好地增强互补特征,设计混合加权参考帧采样策略,引入全局的特征信息和前后帧时间信息,进行特征集成增强. ...
2
... 研究能够平衡检测准确性和效率的采样策略,对于视频目标检测任务至关重要. 主流的采样方法一般采用全局随机采样[25 ] 或者局部采样[26 ] . 这2种采样方法都存在因为特征捕获不全面导致的特征聚合不足的问题. 全局采样方法缺乏来自相邻帧的空间和时间信息,失去了视频的时间维度优势;局部采样在目标运动速度较快或者遮挡严重的情况下,为关键帧检测提供的有效信息少. 为了解决这些问题,更好地增强互补特征,设计混合加权参考帧采样策略,引入全局的特征信息和前后帧时间信息,进行特征集成增强. ...
... 式中: ${L_{{\rm{cls}}}}$ ${L_{{\rm{bbox}}}}$ ${L_{{\rm{obj}}}}$ $\alpha $ $\lambda $ $\mu $ [26 ] . ...
Weighted random sampling with a reservoir
1
2006
... 式中: ${w_i}$ ${P_i}$ [27 ] . ...
1
... 分别聚合 ${{{\boldsymbol{Q}}}_{\rm{r}}}$ ${{{\boldsymbol{K}}}_{\rm{r}}}$ [28 ] 得到 ${{{\boldsymbol{Q}}}_{\rm{l}}}$ ${{{\boldsymbol{K}}}_{\rm{l}}}$ ${{\rm{Tanh}}} $ ${{\rm{Tanh}}} $
1
... 之前研究中常用的交并比(intersection over union,IoU)损失函数是基于预测框和标注框之间的交并比,在视频目标检测任务中使用,可能出现失去梯度方向,从而无法优化的情况. 选用DIoU(distant-IoU)损失函数[29 ] 作为检测框损失函数,表达式如下所示: ...
1
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
基于时序信息和注意力机制的视频目标检测
1
2021
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
基于时序信息和注意力机制的视频目标检测
1
2021
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...
1
... Experiment results of different algorithms on ImageNet VID verification set
Tab.2 网络模型 主干网络 t /ms AP50/% FGFA[1 ] ResNet-101 104.2 76.3 MEGA[10 ] ResNet-101 230.4 82.9 VOD-MT[30 ] VGG-16 — 73.2 LSTS[11 ] ResNet-101 43.5 77.2 TIAM[31 ] ResNet-101 — 74.9 QueryProp[7 ] ResNet-50 21.9(T) 80.3 SALISA[32 ] EfficientNet-B3 — 75.4 YOLOX-S[20 ] Modified CSP v5 9.4 69.5 MMNet Modified CSP v5 11.5 77.8
从表2 可以看出,MMNet在ImageNet VID数据集上取得了77.8%的AP50和11.5 ms/帧的速度. 与基准方法YOLOX-S相比,速度只损失了2.1 ms/帧,精度提高了8.3%. MMNet在精度上的表现优于FGFA、VOD-MT、LSTS、TIAM和SALISA算法. 与检测结果更精确的MEGA和QueryProp算法相比,MMNet的检测速度有大幅度的提升. 结果表明,MMNet提高了视频目标检测的精度,极大地加快了视频检测速度,证明改进算法是精确、高效的. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}