

在“相似的circRNA可能与相同的疾病有相似的关联”假设下,许多计算模型被用于挖掘潜在的circRNA-疾病关联,解决了传统生物实验耗时长且高成本的问题[10]. 这些模型可以大致分为3类:基于信息在网络中的传播、基于机器学习和基于深度学习. Fan等[11]提出使用异构网络的路径信息进行circRNA-疾病关联预测的KATZ度量计算模型(KATZHCDA). Li等[12]提出基于网络一致性投影的计算方模型(NCPCDA),利用多源相似性和一致性投影得到预测得分矩阵. Ding等[13]结合随机游走算法和逻辑回归方法开发了名为RWLR的计算模型. Lei等[14]提出名为ICFCDA的基于协作过滤推荐系统的计算模型. Deepthi等[15]提出计算模型AE-DNN,它依赖自动编码器和深度神经网络来预测新的circRNA-疾病关联. Xiao等[16]提出基于网络嵌入的自适应子空间学习方法(NSL2CD),同时在模型中加入综合加权图正则化项和L1范数约束来实现投影矩阵的平滑性和稀疏性. 不难看出,已有的计算模型还存在一些缺陷:1)模型使用的训练数据有限,这对模型的鲁棒性和覆盖范围有影响;2)模型主要基于单一的数据描述方法,没有将circRNA与疾病行为信息和属性信息结合起来,全面定义circRNA与疾病的特征,导致预测性能有限;3)研究者没有考虑编码-非编码基因-疾病关联的异质性,无法准确测量circRNA-disease关联信息.
为了改善现有计算模型不足,本研究提出基于融合相似性和三部图的circRNA与疾病关联预测模型(prediction of circRNA and disease association based on fusion similarity and tripartite graph, FSTPGCDA). 研究工作包括1)利用数据库得到circRNA序列信息、 circRNA-gene关联信息、circRNA-disease关联信息和疾病语义信息,把数据处理成circRNA-disease关联矩阵和circRNA-gene关联矩阵. 2)利用混沌博弈表示(chaotic game representation,CGR)[17]、语义相似性、Jaccard系数[18]与拉普拉斯特征映射[19]融合相似性计算相似性. 3)加权相似性得到融合相似性. 4)利用circRNA-disease关联信息和circRNA-gene关联信息构建gene-circRNA-disease三部图[20]. 5)通过融合相似性方法为三部图分配初始资源,使用贪心算法进行资源分配,得出最终circRNA-disease资源得分矩阵. 6)计算预测得分并排序,进行留一交叉验证(leave-one-out cross-validation, LOOCV)[21].
1. 三部图模型
1.1. 数据集
通过整合不同种类的生物关联信息,构建数据集D1、D2. 在D1中,circRNA-diseas关联从CircFunBase数据库[22]中下载;分别从circBase、circR2Disease和MeSH[23]中收集circRNA序列信息、circRNA-gene关联信息和疾病语义信息;剔除重复后,共收集2983个circRNA-diseas关联和2318个circRNA-gene关联信息. 在D2中,circRNA-diseas关联信息从circR2Cancer[24]数据库中下载;分别从circBase、miR2Disease[25]和MeSH中收集circRNA序列信息、circRNA-miRNA关联信息和疾病语义信;剔除重复后,共收集到647个circRNA-diseas关联信息和756个circRNA-miRNA关联信息. 数据集的关联信息及数据个数n如表1所示.
表 1 数据集关联信息
Tab.1
| 数据集 | n | ||||||
| circRNA | disease | gene | miRNA | circRNA−disease | circRNA−gene | circRNA−miRNA | |
| D1 | 2596 | 67 | 1716 | — | 2983 | 2318 | — |
| D2 | 514 | 62 | — | 461 | 647 | — | 756 |
1.2. 相似性计算
1.2.1. 融合相似性计算
本研究的数据集存在稀疏问题,使得计算的过程时间长,算法时间复杂度高. 与传统相似性度量方法相比,Jaccard相似性能够改善余弦相似性[26]只考虑单一变量而忽略其他信息量的弊端,适合在稀疏度过高的数据中使用. 拉普拉斯特征映射是基于图的降维算法,在降维后仍能保持原有的数据结构. 本研究将拉普拉斯特征映射和Jaccard结合进行相似性计算. 基本思路如下.
1)以计算样本关联矩阵相似性为例,a、b关联矩阵记为
2)使用拉普拉斯特征映射将
式中:
1.2.2. circRNA相似性计算
现有序列比对算法只能量化位置信息或非线性信息,能够将这2类信息结合的算法鲜少. 为此基于CGR的方法利用Pearson相关系数[27]来量化位置与非线性信息之间的相似性和差异性. 1)将CGR空间划分为
2)分别对每个网格中横坐标x和纵坐标y进行累加,若点在网格内,量化位置信息为
3)计算每个网格
4)每个网格被描述为3个属性, 并融合属性构造描述第
式中:
如果RNA影响同一种人类疾病,它们的功能往往是相似的[28]. 从circRNA-gene关联矩阵中利用融合相似性计算得出circRNA-gene之间circRNA的相似性
通过从不同角度分析circRNA的特征,可以得到3个相似矩阵,包括
1.2.3. disease相似性计算
疾病语义相似. 根据MeSH数据库的语义信息将疾病表示为有向无环图(directed acyclic graph,DAG). DAG中的节点代表疾病,边代表疾病之间的关系. 如果疾病在病理上相似,则DAG的更多部分将被共享[29]. 计算疾病贡献值的模型为
式中:
式中:
1.2.4. gene相似性计算
从circRNA-gene关联矩阵中利用融合相似性计算得出circRNA-gene之间gene的相似性
1.3. gene-circRNA-disease三部图
1.3.1. 三部图介绍
由circRNA-disease和circRNA-gene构建三部图,加入circRNA相似性和disease相似性来对节点进行资源分配.
受使用用户、商品和标签三部图进行推荐的启发,构建gene-circRNA-disease三方图T(C,D,G,E),
图 1
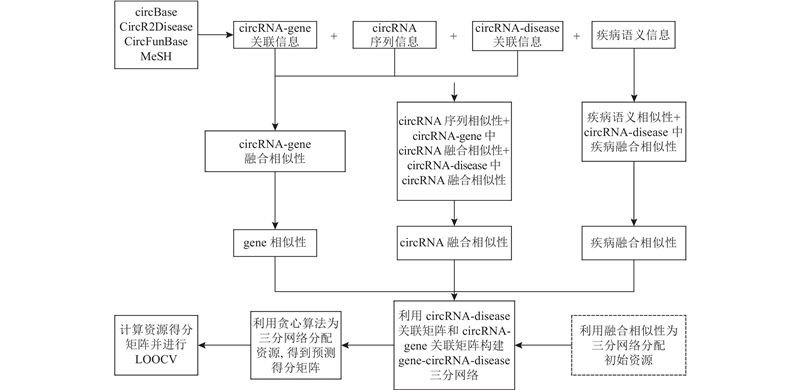
图 1 基于融合相似性和三部图的circRNA与疾病关联预测模型流程图
Fig.1 Flow chart of circRNA and disease association prediction model based on fusion similarity and tripartite graph
1.3.2. 三部图资源推荐
三分网络资源分配的贪心算法[30]流程如下. 1)对每个节点初始化资源. 根据相似性矩阵
2)对于每个节点,计算与其相邻的节点之间的收益值:
式中:
式中:
构建三部图时存在的孤立节点的处理过程:在贪心算法的过程中,比较孤立节点与已有资源的节点,并将资源分配给孤立节点的邻居节点,以提高整个网络的连通性. 计算每个节点的收益值:
式中:
2. 实验结果与分析
2.1. 评估指标
式中:
2.2. 模型预测能力评估
自身效果对比采用AUC、AUPR、TPR、精密度、F1评分和MCC评估指标,分别用LOOCV和5、10折对比. 对比结果如表2所示. 可以看出,各评估指标在交叉验证中差异不超0.1%,该模式具有较好的鲁棒性.
表 2 所提模型在不同测试方法下的评估指标对比
Tab.2
| 数据集 | 测试 | AUC% | AUPR% | TPR% | p% | F1 % | MCC% |
| D1 | LOOCV | 97.01 | 86.26 | 98.18 | 4.32 | 8.27 | 89.06 |
| D1 | 5折 | 97.01 | 86.27 | 98.09 | 4.35 | 8.30 | 89.11 |
| D1 | 10折 | 97.02 | 86.27 | 98.15 | 4.33 | 8.29 | 89.08 |
| D1 | 均值 | 97.01 | 86.27 | 98.14 | 4.33 | 8.29 | 89.08 |
| D2 | LOOCV | 94.46 | 78.01 | 93.85 | 5.40 | 10.22 | 86.68 |
| D2 | 5折 | 94.47 | 77.98 | 93.88 | 5.41 | 10.23 | 86.67 |
| D2 | 10折 | 94.47 | 78.03 | 93.87 | 5.41 | 10.25 | 86.68 |
| D2 | 均值 | 94.47 | 78.01 | 93.87 | 5.41 | 10.23 | 86.68 |
2.3. 本研究模型与其他模型的比较
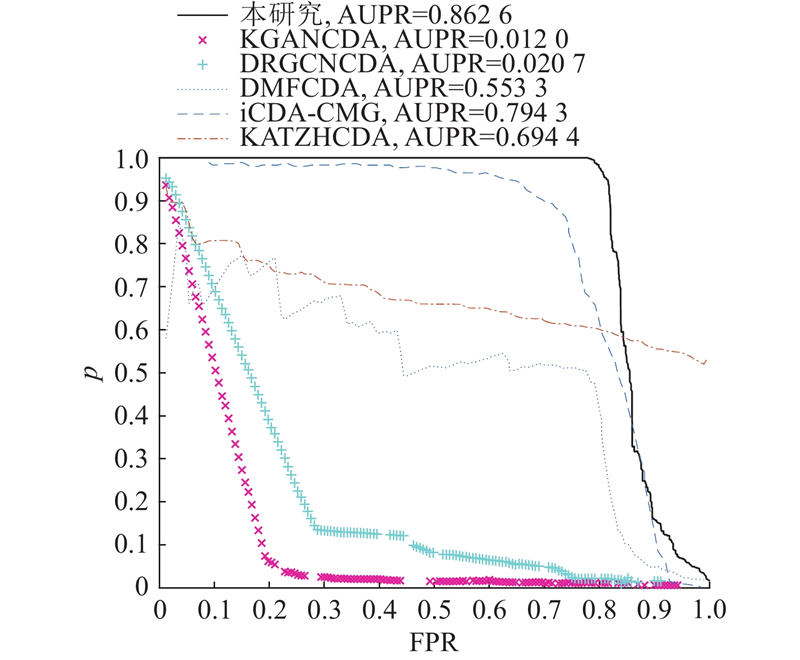
进行FSTPGCDA与KATZHCDA、iCDA-CMG[33]、DMFCDA[34]、KGANCDA[35]和DRGCNCDA[36]的模型性能对比实验. 不同模型的ROC曲线如图2所示. KATZHCDA、iCDA-CMG、DMFCDA、KGANCDA和DRGCNCDA的AUC分别为84.69%、86.25%、88.61%、87.14%和93.99%,FSTPGCDA的AUC为97.01%,优于其他5种方法. 不同方法的PR曲线如图3所示. KATZHCDA、iCDA-CMG、DMFCDA、KGANCDA和DRGCNCDA的AUPR分别为69.44%、79.43%、55.33%、1.20%和2.07%,FSTPGCDA的AUPR为86.26%,优于其他5种方法.
图 2
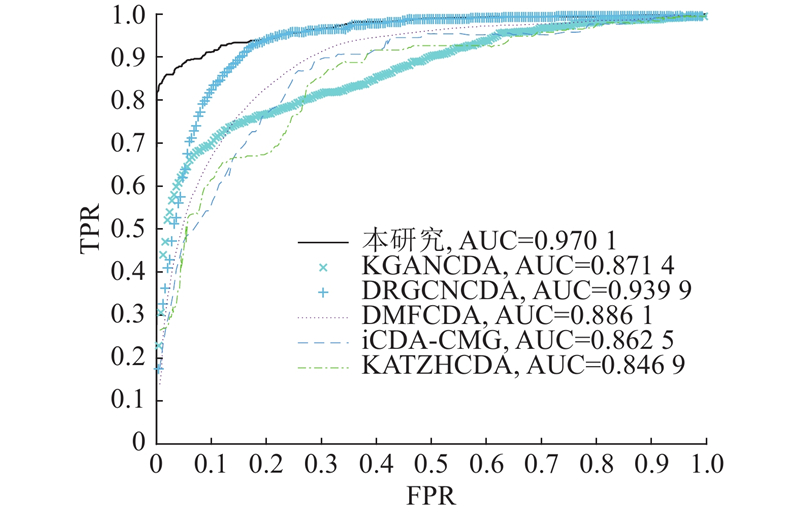
图 3
2.4. 不同相似性在本研究模型中的对比实验
为了验证不同相似性在FSTPGCDA的效果,将融合相似性与Jaccard相似性、余弦相似性、高斯核相似性和Pearson相似性对比,不同相似性在dataset1的相应ROC曲线如图4所示. Jaccard相似性、余弦相似性、高斯核相似性和Pearson相似性的AUC分别为96.16%、92. 42%、91.47%和80.25%,融合相似性的AUC为97.01%,优于其他相似性计算.
图 4
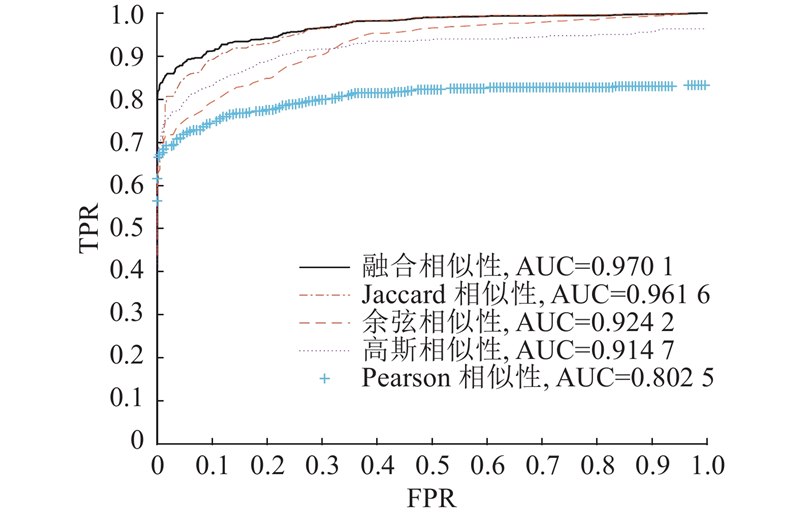
图 4 所提模型不同相似性的ROC对比
Fig.4 ROC comparison of different similarity for proposed model
2.5. 案例研究
为了评估FSTPGCDA的实用价值,进行膀胱癌案例研究,膀胱癌在circFunBase和circR2Disease数据集中有足够的数据,能够避免模型缺陷导致的偏差. 根据相应的预测得分,通过按降序排列选择前15个分数,并通过PubMed进行验证,验证结果为PMID号. 膀胱癌是发生在膀胱黏膜上的恶性肿瘤,是泌尿系统最常见的恶性肿瘤,占中国泌尿生殖系肿瘤发病率的第一位[37]. 膀胱癌筛查模型的研究,对膀胱癌早期发现和高危人群预警具有重要意义. 在癌前病变阶段进行筛检,早诊早治,可降低膀胱癌发病率和病死率. 进一步研究膀胱癌与circRNA之间关联有助于提高膀胱癌的诊断和治疗水平. 选择预测分数前15名的CircRNA进行验证,有14个得到验证. 如表3所示,hsa_circ_0001946(排名第1)对应的CDR1基因,与Purkinje细胞质抗原34和62 kd反应的抗Yo (I型)自身抗体在一例膀胱移行细胞癌并发副肿瘤性小脑变性和抗Yo抗体反应的患者的血清和脑脊液中被发现. 肿瘤切除后抗体滴度下降[38]. hsa_circ_0028173(排名第8)在膀胱癌细胞中,这些 DEmRNA 在甘油酯代谢、p53 信号通路和卵母细胞减数分裂中显着富集. circRNA相互作用对可能在BC中发挥重要作用[39]. hsa_circ_0000144(排名第9)下调环状RNA hsa_circ_0000144通过刺激miR-217和抑制RUNX2表达抑制膀胱癌进展[40]. 以CDR1基因为例进行进一步分析,验证该基因是否与膀胱癌相关. 如图5所示,在研究中,将所有膀胱癌患者样本分为高表达组和低表达组,通过生存分析看到CDR1基因高表达组膀胱癌患者的生存天数相对较短. 图中,TS为生存时间,PS为生存概率. 如图6所示,进一步的结果表明,这些基因在癌症样本中的表达明显低于正常样本. 图中,R为每百万份转录数. 基于以上结果,最终得出这些基因的表达与膀胱癌患者的生存时间和临床病理特征显著负相关. 此外,BLCA富集分析也显示,CDR1基因低表达组对人类来说主要在蛋白质消化吸收、EMC受体相互作用、心肌病、癌症中枢碳代谢、黑色素瘤等疾病过程中富集,如图7所示. 图中,ER为富集率.
表 3 前15个与膀胱癌有关联的circRNA
Tab.3
| 排名 | circRNA | PMID号 |
| 1 | hsa_circ_0001946 | 10360776 |
| 2 | hsa_circ_0003266 | 24314030 |
| 3 | hsa_circ_0000284 | 28794202 |
| 4 | hsa_circ_0011385 | 32015691 |
| 5 | hsa_circ_0000520 | 33991457 |
| 6 | hsa_circ_0061265 | — |
| 7 | hsa_circ_0005273 | 30458784 |
| 8 | hsa_circ_0028173 | 33789319 |
| 9 | hsa_circ_0000144 | 33030352 |
| 10 | hsa_circ_0009361 | 33244270 |
| 11 | hsa_circ_0000658 | 35148461 |
| 12 | hsa_circ_0012634 | 36445493 |
| 13 | hsa_circ_0072088 | 33928018 |
| 14 | hsa_circ_0001336 | 30815697 |
| 15 | hsa_circ_0058058 | 12939746 |
图 5
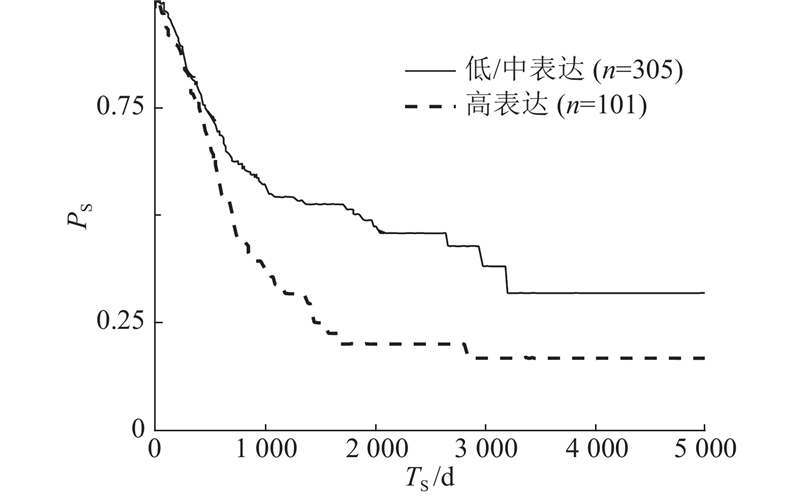
图 5 CDR1基因在胃癌患者的生存分析图
Fig.5 Survival analysis of CDR1 gene in patients with gastric cancer
图 6
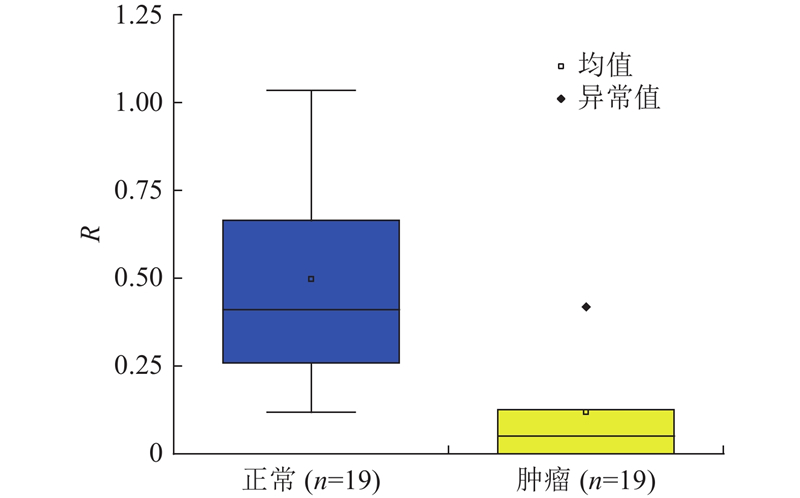
图 6 CDR1基因在正常和肿瘤样本中的分化表达
Fig.6 Differentiation and expression of CDR1 gene in normal and tumor sample
图 7
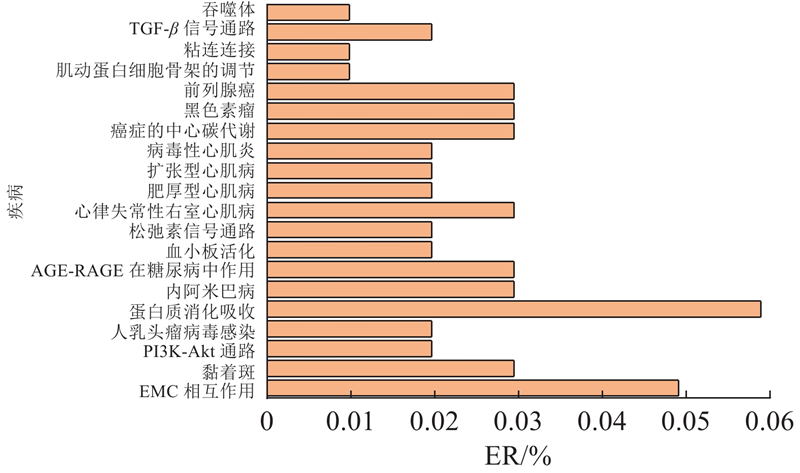
3. 结 语
在生物医学研究中,预测circRNA与疾病关联有利于理解疾病的发病机制,进一步提高疾病诊断、治疗、预后和预防的质量. 本研究提出新的计算模型FSTPGCDA,通过整合实验验证的circRNA序列信息、circRNA-disease关联信息、circRNA-gene关联信息和疾病语义信息来识别潜在的circRNA-disease关联. 基于gene-circRNA-disease三部图的资源分配模型,能够更好地描述编码非编码基因疾病关联的异质性,丰富资源分配过程中的生物信息. 先用各种相似性和融合相似性计算得到各自相似性,通过加权融合相似性得到融合相似性矩阵,解决了数据高度稀疏性,以便更好地预测得分. 利用融合相似性矩阵为三部图分配初始资源,利用贪心算法为三部图进行资源分配,产生推荐该算法有效地减少了资源分配过程中的不可知偏差. 在LOOCV、5折和10折对比实验中,不同评估指标的评估结果表明,相比其他参与对比的模型,FSTPGCDA具有较好的预测能力和鲁棒性. 案例研究的分析进一步证明,FSTGPCDA有助于在实践中识别潜在的circRNA疾病关联. 下一步计划整合gene-disease关联或采用的其他生物信息,增加更多的经过实验验证的circRNA-disease关联,从资源分配方面进行致病机制的具体分析.
参考文献
基于多数据融合的circRNA–疾病关联关系预测
[J].DOI:10.1360/SSI-2019-0142 [本文引用: 1]
Prediction of circRNA-disease association based on multiple biological data
[J].DOI:10.1360/SSI-2019-0142 [本文引用: 1]
Induction of tumor apoptosis through a circular RNA enhancing Foxo3 activity
[J].
Using circular RNA as a novel type of biomarker in the screening of gastric cancer
[J].
The landscape of circular RNA in cancer
[J].DOI:10.1016/j.cell.2018.12.021
Loss of a mammalian circular RNA locus causes miRNA deregulation and affects brain function
[J].DOI:10.1126/science.aam8526 [本文引用: 1]
circBase: a database for circular RNAs
[J].
CircR2Disease: a manually curated database for experimentally supported circular RNAs associated with various diseases
[J].
circRNA disease: a manually curated database of experimentally supported circRNA-disease associations
[J].DOI:10.1038/s41419-018-0503-3 [本文引用: 1]
Circ2Traits: a comprehensive database for circular RNA potentially associated with disease and traits
[J].
Prediction of RNA-protein interactions by combining deep convolutional neural network with feature selection ensemble method
[J].DOI:10.1016/j.jtbi.2018.10.029 [本文引用: 1]
Prediction of CircRNA-disease associations using KATZ model based on heterogeneous networks
[J].DOI:10.7150/ijbs.28260 [本文引用: 1]
NCPCDA: network consistency projection for circRNA-disease association prediction
[J].DOI:10.1039/C9RA06133A [本文引用: 1]
Predicting novel CircRNA-disease associations based on random walk and logistic regression model
[J].DOI:10.1016/j.compbiolchem.2020.107287 [本文引用: 1]
Predicting circRNA-disease associations based on improved collaboration filtering recommendation system with multiple data
[J].DOI:10.3389/fgene.2019.00897 [本文引用: 1]
An ensemble approach for circRNA-disease association prediction based on autoencoder and deep neural network
[J].DOI:10.1016/j.gene.2020.145040 [本文引用: 1]
NSL2CD: identifying potential circRNA-disease associations based on network embedding and subspace learning
[J].DOI:10.1093/bib/bbab177 [本文引用: 1]
Chaos game representation of gene structure
[J].DOI:10.1093/nar/18.8.2163 [本文引用: 1]
IMS-CDA: prediction of circrna-disease associations from the integration of multisource similarity information with deep stacked autoencoder model
[J].DOI:10.1109/TCYB.2020.3022852 [本文引用: 1]
一种基于网络表示学习的miRNA-疾病关联预测方法
[J].DOI:10.19734/j.issn.1001-3695.2020.07.0176 [本文引用: 1]
miRNA-disease association prediction based on network representation learning method
[J].DOI:10.19734/j.issn.1001-3695.2020.07.0176 [本文引用: 1]
基于HeteSim的疾病关联长非编码RNA预测
[J].DOI:10.7544/issn1000-1239.2019.20180834 [本文引用: 1]
Prediction of disease association long non-coding RNA based on HeteSim
[J].DOI:10.7544/issn1000-1239.2019.20180834 [本文引用: 1]
CircFunBase: a database for functional circular RNAs
[J].
Investigating semantic similarity measures across the Gene Ontology: the relationship between sequence and annotation
[J].DOI:10.1093/bioinformatics/btg153 [本文引用: 1]
CircR2Cancer: a manually curated database of associations between circRNAs and cancers
[J].DOI:10.1093/database/baaa085 [本文引用: 1]
miR2Disease: a manually curated database for microRNA deregulation in human disease
[J].
lncRNA-disease association prediction based on latent factor model and projection
[J].DOI:10.1038/s41598-021-99493-5 [本文引用: 1]
Correlation coefficients: appropriate use and interpretation
[J].DOI:10.1213/ANE.0000000000002864 [本文引用: 1]
Circular RNAs function as ceRNAs to regulate and control human cancer progression
[J].DOI:10.1186/s12943-018-0827-8 [本文引用: 1]
图自动编码器上二阶段融合实现的环状RNA-疾病关联预测
[J].
circRNA-disease association prediction by two-stage fusion of graph auto-encoder
[J].
A greedy regression algorithm with coarse weights offers novel advantages
[J].DOI:10.1038/s41598-022-09415-2 [本文引用: 1]
基于集成回归决策树的lncRNA-疾病关联预测方法
[J].
Ensemble regression decision trees-based lncRNA-disease association prediction
[J].
基于语义与全局双重注意力机制的长链非编码RNA-疾病关联预测模型
[J].
Long non-coding RNA-disease association prediction model based on semantic and global dual attention mechanisms
[J].
iCDA-CMG: identifying circRNA-disease associations by federating multi-similarity fusion and collective matrix completion
[J].DOI:10.1007/s00438-020-01741-2 [本文引用: 1]
Deep matrix factorization improves prediction of human circRNA-disease associations
[J].DOI:10.1109/JBHI.2020.2999638 [本文引用: 1]
KGANCDA: predicting circRNA-disease associations based on knowledge graph attention network
[J].DOI:10.1093/bib/bbab494 [本文引用: 1]
DRGCNCDA: predicting circRNA-disease interactions based on knowledge graph and disentangled relational graph convolutional network
[J].DOI:10.1016/j.ymeth.2022.10.002 [本文引用: 1]
Bladder cancer: current challenges and future directions
[J].DOI:10.3390/medicina57080749 [本文引用: 1]
Association of anti-Yo (type I) antibody with paraneoplastic cerebellar degeneration in the setting of transitional cell carcinoma of the bladder: detection of Yo antigen in tumor tissue and fall in antibody titers following tumor removal
[J].DOI:10.1002/1531-8249(199906)45:6<805::AID-ANA18>3.0.CO;2-G [本文引用: 1]
Identification of circRNA-miRNA-mRNA regulatory network in bladder cancer by integrated analysis
[J].
Prognostic role of circular RNAs expression in bladder carcinoma: a meta-analysis
[J].DOI:10.1089/gtmb.2020.0079 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}