

服务计算与区块链、物联网、云计算等新兴技术跨界融合,催生出海量异构多模态的应用程序接口 (application programming interface, API)服务,如何有效地推荐符合用户开发需求的API服务成为当前服务计算领域的热点问题[1],服务推荐受到学术界和工业界的广泛关注. 早期服务推荐方法大多基于协同过滤的思想[2-3],根据用户或服务的相似度进行推荐. 此类方法缺乏对用户特征和服务特征的深度挖掘,推荐准确度较低. 一些研究者结合聚类技术、主题模型和因子分解机等方法[4-7]进行改进. 虽然上述方法在一定程度上提高了推荐精确度和效率,但是仍存在以下缺陷: 1)当输入维度较高时,大部分服务推荐方法难以有效挖掘API服务之间隐式高阶关联; 2)在考虑用户行为相似性时,现有方法大多将用户与服务之间复杂的多行为交互(如调用、组合)同质化,视其为单一行为类型.
图神经网络可以较好地提取网络结构信息,是推荐系统目前的研究重点[8-10]. 受限于图结构的度数要求,普通图神经网络只能将高阶服务关联转换为二元关系, 容易造成原始服务信息的丢失. 超图可以利用超边连接任意数量的服务节点,实现更为合理的服务特征建模[10]. 以超图学习为基础,结合多行为推荐思想, 本研究提出基于超图卷积神经网络的多行为感知服务推荐方法(multi-behavior aware service recommendation method based on hypergraph graph convolution neural network, MBSRHGNN). 该方法构建多重超图结构对服务组合特征以及多行为依赖关系进行建模;利用双通道超图卷积网络捕获隐含的用户-服务特征;将API服务转化为嵌入向量,结合超图信号产生推荐服务的概率分布. 本研究创新点如下:1)构建行为感知超图和服务组合超图,根据超图功能结构特性,设计双通道超图卷积网络. 在超图卷积过程中,采用Chebyshev卷积算子和HG-DiffPool池化方法降低计算复杂度,减少模型过拟合风险. 2)引入多行为推荐方法对服务推荐场景中的多行为交互进行建模,结合超图自注意力机制优化目标行为表示,克服传统推荐方法中多行为交互同质化的缺陷.
1. 相关工作
协同过滤[2-3]在服务推荐场景中的应用较为广泛,较为经典的是由Zheng等[2]提出的一种混合式协同过滤服务推荐方法. 该方法综合考虑用户相似性和服务相似性,采用线性组合加权的方式进行服务推荐,但是传统的协同过滤服务推荐方法在应用时存在冷启动以及可拓展性差的问题. 现有研究[4-6]表明服务功能聚类技术能够有效缩小服务搜索空间,优化API服务推荐流程. 此类方法大多利用向量空间模型将服务描述文档映射至高维特征空间,并结合余弦距离、欧式距离、马氏距离等方法计算服务相似度. Agarwal等[4]使用长度特征权重矢量化表示API服务,结合功能词频进行服务聚类. 由于向量空间模型存在特征维度过高、语义稀疏的问题,一些工作结合自然语言处理技术来发掘服务间的语义关联[5-6]. 笔者[5]提出一种融合功能语义关联计算与密度峰值检测的Mashup服务聚类方法,利用功能语义权重来计算服务语义特征. 服务间语义关联的发掘需要高质量语料,然而现实中的服务描述文本容易导致大部分主题模型难以准确捕捉服务描述间的隐式语义关联[6].
2. MBSRHGNN方法
2.1. MBSRHGNN模型整体架构
本研究提出的服务推荐模型MBSRHGNN的整体框架如图1所示,主要由以下3个模块构成. 1)多重超图构建:将爬取到的真实服务数据转化为行为感知序列和服务划分集,根据多行为交互类型和服务组合信息构建多重超图. 2)双通道超图卷积网络:基于双通道超图卷积网络捕获全局多行为依赖和高阶服务组合关联. 在行为感知卷积通道上,引入自注意力机制动态学习行为权重,将服务推荐与多行为推荐方法相结合. 在服务组合卷积通道上,增加HG-DiffPool超图池化层来降低服务特征维度. 在此模块中,self-attention为超图自注意力机制,Chebyshev Conv指的是Chebyshev近似后的卷积操作. 3)语义编码推荐:通过基于Transformer的双向编码器 (bidirectional encoder representation from transformers,BERT)编码层将功能语义信息转化为语义向量. 根据语义向量与API服务的one-hot编码结果,产生语义嵌入. 结合全局多行为依赖和高阶服务组合关联得到全局序列特征,预测推荐服务的概率.
图 1
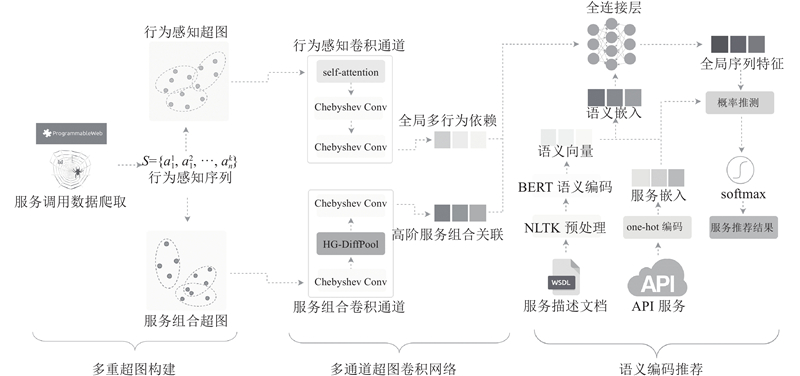
2.2. 多重超图构建
2.2.1. 行为感知超图构建
行为感知序列和服务划分集是构建行为感知超图的基础. 将用户交互的服务项按时间顺序排列,并记录下具体的交互行为类型,可以得到行为感知序列
构建行为感知超图
式中:
基于上述定义,节点度矩阵和超边度矩阵分别以
2.2.2. 服务组合超图构建
基于API服务之间的组合关联构建服务组合超图. 首先,定义服务组合集
当
服务组合超图的归一化邻接矩阵定义为
2.3. 双通道超图卷积网络
行为感知超图和服务组合超图结构不同、模态相异,难以用单一的超图卷积网络捕获其复杂异构的高阶关联信息. 因此,将超图上的近似谱卷积过程细分为2类卷积通道. 1)行为感知卷积通道:主要考虑多行为推荐方法和超图神经网络的结合,利用自注意力机制优化目标行为表示. 2)服务组合卷积通道:侧重于增强模型的泛化能力,降低高阶服务组合关联的特征维度,减少过拟合风险.
2.3.1. 超图上的近似谱卷积
根据谱分解理论与图信号处理的思路[14],将任意通道上的超图卷积过程定义为
式中:
由于涉及到多次特征分解和矩阵乘法运算,如式(5)定义的超图卷积过程计算代价较高,其复杂度与节点数量的平方成正比. 为此应用一阶Chebyshev多项式对卷积核
式中:
式中:
2.3.2. 超图自注意力机制
式(7)表明超图卷积过程中的信息转移概率由关联矩阵和度矩阵所确定. 在行为感知超图上,关联矩阵的权重大小在初始化时就已经指定,因此难以度量不同服务交互的重要性差异. 为了进一步比较行为感知卷积通道上不同服务交互行为对超图信号的影响,引入自注意力机制优化行为感知超图的关联矩阵表示. 注意力分数的计算方法和关联矩阵的优化过程为
式中:
式中:
超图自注意力机制提高了节点间信息传播过程的可解释性. 如图2(a)所示为一个基于真实服务数据构建的行为感知超图实例. 图中
图 2
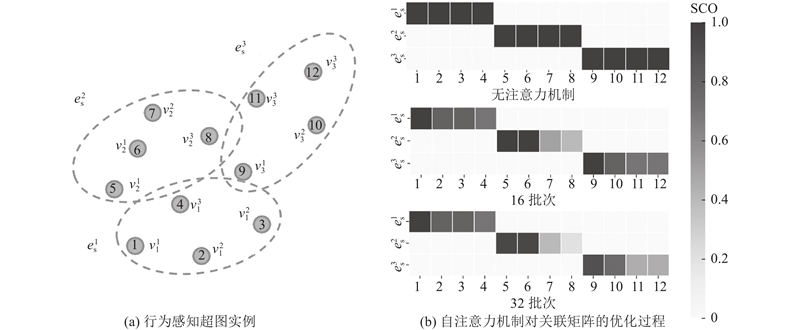
图 2 行为感知超图上的自注意力机制
Fig.2 Self-attention mechanism on behavior-aware hypergraph
引入超图自注意力机制后,行为感知超图通道上的超图卷积过程为
2.3.3. 超图池化方法HG-DiffPool
该方法将服务组合通道上的第
式中:
式中:
在完成对邻接矩阵的池化后,可以利用
式中:
2.4. 语义编码推荐
为了最大程度地利用服务语义信息,分2步构建API服务的嵌入向量. 首先利用one-hot编码将每个API服务转化为服务嵌入
行为感知序列的局部序列特征可以定义为
式中:
为了消除超图卷积神经网络中的过平滑效应,所有的高阶特征均取多层卷积的平均值作为最终结果[18]. 在得到推荐分数后,每个API服务被推荐的预测概率定义为
通过构造交叉熵损失函数来训练和学习MBSRHGNN模型:
式中:
3. 实验评估
3.1. 实验设置
通过多组实验来验证MBSRHGNN模型的有效性,给出实验数据集、基线方法、评估指标以及超参设置的介绍. 通过基线实验、消融实验、超参数实验回答以下3个问题:1)与现有的服务推荐方法、基于图神经网络的推荐方法和多行为推荐方法相比,模型的推荐性能如何?2)多重超图结构在模型中起何种作用?3)不同的超参数设置(例如:行为感知序列长度、特征向量维度大小)对模型的性能有什么影响?
3.1.1. 实验数据集
本研究爬取了2019—2020年ProgrammableWeb网站上真实的用户交互记录和服务信息进行实验. 其中包括3 102位用户的11 032条多行为交互记录,6 206种服务组合以及13 329项API服务信息. 为了验证MBSRHGNN模型和现有推荐方法在数据高度稀疏场景下的性能表现,将预处理后的数据划分为稀疏数据集和稠密数据集,表1所示为2种实验数据集的具体统计信息. 表中,μ为用户数量,ε为服务组合数量,λ为API服务数量,l为服务描述文档的平均长度,ς为API服务被调用数,ρ为数据集的密度,Z为交互类型。
表 1 实验中数据集的统计信息
Tab.1
| 数据集 | μ | ε | λ | l | ς | ρ | Z |
| 稀疏数据集 | 3516 | 6206 | 13329 | 42.35 | 523 | 0.039 | [view, follow,choose] |
| 稠密数据集 | 11032 | 6206 | 13329 | 43.46 | 3047 | 0.230 | [view, follow,choose] |
3.1.2. 基线方法
将MBSRHGNN模型与现有的10种推荐方法进行比较. 在实验过程中,各基线方法的参数设置基本保持和原文一致. 当出现梯度下降速度较慢、收敛时间过长、模型难以收敛等问题时,适当地调整学习率、批大小等参数. 基线方法中的前2种为服务推荐方法,第3、4种为基于图神经网络的推荐方法,其余方法为多行为推荐方法. 基线方法的详细介绍如下.
1)AFMRec[7]. 采用注意力分解机挖掘多维特征向量之间的隐式服务关联. 超参设置为:注意力网络大小64,批大小512,学习率0.001.
2)WR-MSN[5]. 基于密度峰值检测聚类算法进行服务聚类,利用服务邻域进行推荐. 超参设置为:词向量维度300,聚类划分数9,局部密度0.4.
3)DHCN[8]. 基于双通道超图卷积网络提取序列特征嵌入. 超参设置为:特征维度100,批大小128,学习率0.000 1.
4)HyperRec[19]. 将用户交互视为连接项目的超边,构建超图捕捉用户的动态短期兴趣. 超参设置为:特征维度64,批大小256,学习率0.001.
5)MBHT[12]. 利用多尺度 Transformer 结合低秩自注意力对多行为序列进行编码. 超参设置为:特征维度64,批大小32,学习率0.001.
6)MB-GCN[13]. 基于图卷积神经网络捕获用户—项目交互图上的多行为交互信息. 超参设置为:特征维度128,批大小64,学习率0.003.
3.1.3. 评估指标与超参设置
为了保持和现有工作一致的评估设置,采用以下评估指标:命中率(hit ratio, HR)、归一化折损累计增益 (normalized discounted cumulative gain, NDCG)和平均倒数排名 (mean reciprocal rank, MRR). HR指标越高,说明服务推荐的精确性越好;NDCG指标与MRR指标越高,说明服务推荐的相关性越强.
在实验过程中, MBSRHGNN模型的主要超参设置如下:1)服务嵌入特征维度和语义嵌入特征维度在{16,32,64,96,128}中选择;2)行为感知序列长度在{10,20,30,40,60,100}中选取;3)学习率的取值为{0.001,0.003,0.006};4)在{0.05,0.10,0.15,0.20}调整学习率衰减系数;5)使用基于最小批的ADAM优化器优化模型参数,取最小批大小为128.
根据参数实验结果,模型性能在特征维度为96,序列长度为40时达到最优. 依据实际经验,学习率初始取值为0.006,根据模型收敛情况进行分段衰减. 此外,在模型训练过程中执行提前停止策略. 如果在连续10个时间段内,测试数据上的HR指标、NDCG指标和MRR指标没有增加,则提前终止训练.
3.2. 基线实验与分析
针对实验部分提出的问题1),将MBSRHGNN模型与基线方法进行比较,以验证性能优势. 每组基线实验在相同的实验设置下重复10次,取平均值作为最终实验结果,实验结果如表2所示. 表中,IMP为MBSRHGNN相较于最优基线方法的性能提升幅度,表中对所提出的MBSRHGNN方法进行加粗,具体分析如下.
表 2 MBSRHCNN模型与基线方法的对比实验结果
Tab.2
| 模型 | 稀疏数据集 | 稠密数据集 | |||||||||
| HR@5 | NDCG@5 | HR@10 | NDCG@10 | MRR | HR@5 | NDCG@5 | HR@10 | NDCG@10 | MRR | ||
| AFMRec | 0.381 | 0.358 | 0.384 | 0.352 | 0.372 | 0.412 | 0.407 | 0.428 | 0.404 | 0.383 | |
| WR-MSN | 0.335 | 0.312 | 0.321 | 0.303 | 0.314 | 0.465 | 0.452 | 0.442 | 0.431 | 0.428 | |
| DHCN | 0.342 | 0.303 | 0.352 | 0.323 | 0.328 | 0.383 | 0.336 | 0.371 | 0.342 | 0.334 | |
| HyperRec | 0.481 | 0.474 | 0.513 | 0.489 | 0.452 | 0.512 | 0.498 | 0.527 | 0.515 | 0.482 | |
| MBHT | 0.482 | 0.436 | 0.509 | 0.462 | 0.474 | 0.528 | 0.477 | 0.542 | 0.496 | 0.506 | |
| MB-GCN | 0.387 | 0.322 | 0.419 | 0.349 | 0.364 | 0.363 | 0.311 | 0.392 | 0.327 | 0.339 | |
| MBSRHGNN | 0.504 | 0.489 | 0.547 | 0.507 | 0.497 | 0.572 | 0.542 | 0.596 | 0.556 | 0.541 | |
| IMP/% | 4.5 | 3.2 | 4.8 | 3.8 | 4.9 | 8.3 | 8.8 | 5.6 | 7.9 | 7.8 | |
1)在服务推荐方法中,基于服务聚类的WR-MSN方法受数据稀疏性问题影响较大. 基于注意力分解机的AFMRec方法能较好地适应数据稀疏的推荐场景,HR@5指标达到了0.381. 在稠密数据集上,WR-MSN方法的推荐精确度和相关性提升较大. 对比AFMRec方法,WR-MSN方法的HR@5指标提高了12.8%,MRR指标提高了11.7%.
2)在基于图神经网络的推荐方法中,HyperRec方法的性能表现最佳. 在多行为推荐方法中, MBHT模型的HR@5、MRR指标在所有基准方法中最优. MBHT模型在多尺度Transformer的基础上融入超图卷积神经网络,并利用跨视图对比学习方法进一步提高用户交互嵌入向量的表征能力.
3)所提的MBSRHGNN模型在不同密度的实验数据集上均取得了更好的推荐结果. 相较于最优的基准方法,MBSRHGNN的HR@5指标提高了4.5%~8.3%, NDCG@5指标和MRR指标分别提高了3.2%~8.8%和4.9%~6.9%,说明MBSRHGNN模型拥有更高的推荐精确度和推荐相关性.
MBSRHGNN模型的推荐性能优势具体分析如下:1)根据多重超图功能结构特性设计的双通道超图卷积网络能有效捕获高阶服务组合关联和全局多行为依赖;2)多行为权重并非事先指定,而是利用自注意力在模型训练过程中动态学习得到的;3)将API服务的one-hot编码与BERT语言模型相融合,克服了服务嵌入语义稀疏的问题.
3.3. 消融实验与分析
针对实验部分提出的问题2),构造3种MBSRHGNN的变体模型进行消融实验,变体模型的详细介绍如下:1)MH-Behavior:移除行为感知超图,屏蔽行为感知卷积通道上的超图信号. 2)MH-Mashup:移除服务组合超图,屏蔽服务组合卷积通道上的超图信号. 3)MH-HyperGraph:移除多重超图结构.
在消融实验过程中,所有变体模型取相同的超参数设定,在2类服务数据规模(见表1)下进行10次实验. 实验结果如图3所示,图中,E为模型训练批次. 可以看出:1)移除多重超图结构的MH-HyperGraph变体表现出较差的学习能力,各项指标没有随着训练轮次的增加而提升,综合推荐质量也较低;2)保留了部分超图结构的MH-Behavior和MH-Mashup变体表现出更强的数据样本学习能力. 从实验结果看,在经过30~40轮次训练后,两者的HR@5、NDCG@5和MRR指标均超过了MH-HyperGraph变体. 3)相较于各种变体,拥有多重超图结构的原模型MBSRHGNN表现出最好的推荐性能. 综上可知,所提的多重超图结构是有效的,能够实现对用户-服务特征的合理建模.
图 3
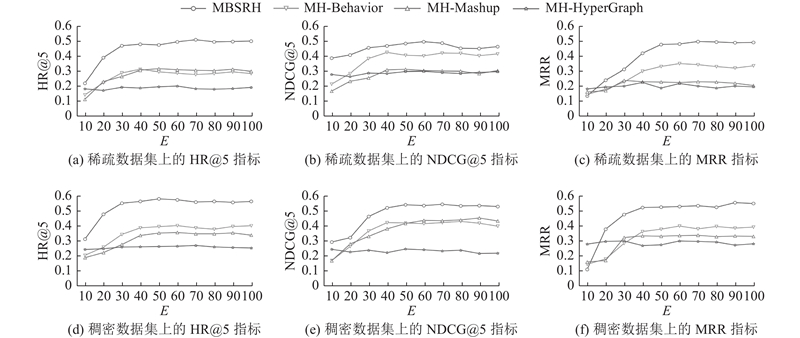
图 3 多重超图结构消融实验结果
Fig.3 Ablation experimental results of multi-hypergraph structure
3.4. 超参数实验与分析
针对实验部分提出的问题3),验证特征维度和行为感知序列长度对推荐性能的影响. 特征维度在{16,32,64,96,128}中选择,序列长度在{10,20,30,40,60,100}中选取. 超参数实验结果如图4所示. 图中dim为特征维度,seq为序列长度,prf为推荐性能.
图 4
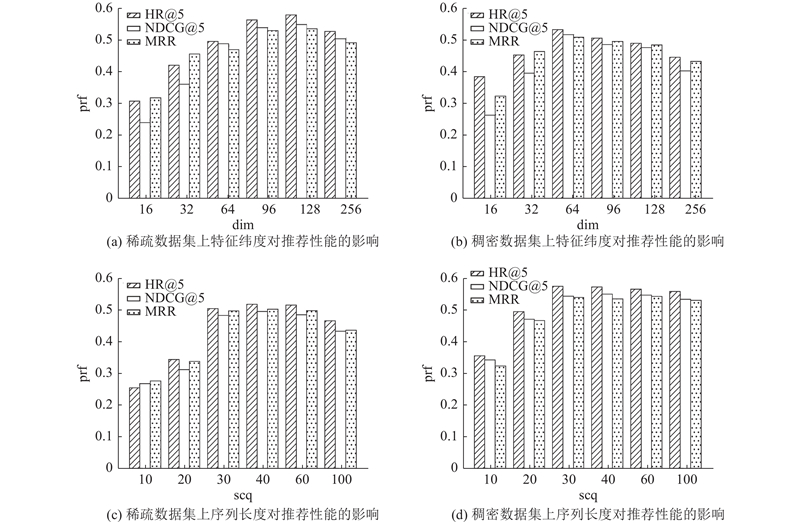
图 4 不同特征维度设置下的服务推荐性能表现
Fig.4 Service recommendation performance under different feature dimension settings
3.4.1. 特征维度对推荐性能的影响
特征维度决定服务嵌入和语义嵌入的表征能力,并且对模型的学习能力也有重要的影响. 过小的特征维度将导致模型不能充分地学习数据样本间的非线性关系,造成欠拟合问题. 随着特征维度的增高,模型的学习能力逐渐增强,但是过强的学习能力容易造成过拟合现象. 特征维度不是越大越好. 对比图4(a)、(b),当特征维度取值较低时,模型的推荐性能较差. 随着特征维度的上升,模型的推荐性能逐渐增强. 当特征维度取值为128时,模型在稀疏数据集上的推荐性能达到最优. 当特征维度取值为64时,模型在稠密数据集上的推荐性能达到最优. 随着特征维度的上升,模型的推荐性能略有下降,MBSRHGNN模型具有一定的鲁棒性,推荐性能不会因为超参数细微的变化发生大幅波动.
3.4.2. 序列长度对推荐性能的影响
行为感知序列长度主要对多重超图构建过程有较大的影响. 当行为感知序列较短时,产生的服务划分数量会变少,并且与服务组合集的相交部分也会变小,导致构建的行为感知超图和服务组合超图变得更为稀疏,不利于全局多行为依赖和高阶服务组合关联的提取. 当行为感知序列较长时,虽然能够引入更多的用户交互样本,但是也会带来一定的噪声,造成推荐准确率的下降. 对比图4(c)、(d)可以看出,序列长度的合理取值应该在[30,60]. 在稀疏数据集上,用户交互的API服务数量较少, 需要更长的序列来引入额外的交互信息. 在稠密数据集上,交互信息较丰富,即使序列长度较短,模型也有较高的推荐质量.
4. 结 语
本研究提出基于超图卷积神经网络的多行为感知服务推荐方法. 通过自注意力机制,为不同的服务交互行为赋予权重. 相比较于普通的图神经网络,通过多重超图结构能够有效地表示全局多行为依赖和高阶服务组合关联2种特征. 在不同稀疏度的数据集上,本研究相比其他主流推荐方法在精度评价指标和相关度评价指标上能够获得更好的效果. 不足之处在于提出的多重超图结构仍不够完善,没有考虑服务质量信息,超图信号与嵌入向量的融合过程还有待改进. 在下一阶段的工作主要包括: 丰富多重超图结构,以便可以更准确、合理地表示服务特征;探索超图信号与嵌入向量的自适应地融合方法;在图神经网络框架的基础上,构造不同类型的神经网络,从多个侧面提取、整合服务特征.
参考文献
融合 SOM 功能聚类与 DeepFM 质量预测的 API 服务推荐方法
[J].DOI:10.11897/SP.J.1016.2019.01367 [本文引用: 1]
An API service recommendation method via combining self-organization map-based functionality clustering and deep factorization machine-based quality prediction
[J].DOI:10.11897/SP.J.1016.2019.01367 [本文引用: 1]
Enhancing web service clustering using Length Feature Weight Method for service description document vector space representation
[J].DOI:10.1016/j.eswa.2020.113682 [本文引用: 3]
融合功能语义关联计算与密度峰值检测的Mashup服务聚类方法
[J].
Mashup service clustering method via integrating functional semantic association calculation and density peak detection
[J].
面向服务聚类的短文本优化主题模型
[J].
Short text optimized topic model for service clustering
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}