[1]
石连红 放射科医生的透视眼—CT与核磁共振
[J]. 特别健康 , 2020 , 8 : 35
[本文引用: 1]
SHI Lian-hong The fluoroscopy eye of the radiologist -CI and MRI
[J]. Special Health , 2020 , 8 : 35
[本文引用: 1]
[2]
ELDAHSHAN E S A, MOHSEN H M, REVETT K, et al Computer-aided diagnosis of human brain tumor through MRI: a survey and a new algorithm
[J]. Expert Systems with Applications , 2014 , 41 (11 ): 5526 - 5545
DOI:10.1016/j.eswa.2014.01.021
[本文引用: 1]
[3]
CHEN J, YU H, FENG R, et al. Flow-Mixup: classifying multi-labeled medical images with corrupted labels [C]// BIBM . Piscataway: IEEE, 2020: 534-541.
[本文引用: 1]
[4]
于玉海, 林鸿飞, 孟佳娜, 等 跨模态多标签生物医学图像分类建模识别
[J]. 中国图像图形学报 , 2018 , 23 (6 ): 917 - 927
YU Yu-hai, LIN Hong-fei, MENG Jia-na, et al Cross- modal multi-label biomedical image classification modeling and recognition
[J]. Journal of Image and Graphics , 2018 , 23 (6 ): 917 - 927
[5]
LUO Y, TAO D, GENG B, et al Manifold regularized multitask learning for semi-supervised multilabel image classification
[J]. IEEE Transactions on Image Processing , 2013 , 22 (2 ): 523 - 536
DOI:10.1109/TIP.2012.2218825
[本文引用: 1]
[6]
WEI YUNCHAO, XIA WEI, LIN MIN, et al HCP: a flexible CNN framework for multi-label image classification
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2016 , 38 (9 ): 1901 - 1907
DOI:10.1109/TPAMI.2015.2491929
[本文引用: 1]
[7]
BENBARUCH E, RIDNIK T, ZAMIR N, et al. Asymmetric loss for multi-label classification [C]// ICCV . Piscataway: IEEE, 2021: 82- 91.
[本文引用: 1]
[8]
GUO G R, ARNALDO M, ELIE B A, et al Artificial intelligence in healthcare: review and prediction case studies
[J]. Engineering , 2020 , 6 (3 ): 291 - 301
DOI:10.1016/j.eng.2019.08.015
[本文引用: 1]
[9]
MILLER D D, BROWN E W Artificial intelligence in medical practice: the question to the answer
[J]. The American Journal of Medicine , 2018 , 131 (2 ): 129 - 133
DOI:10.1016/j.amjmed.2017.10.035
[本文引用: 1]
[10]
ESTEVA A, KUPREL B, NOVOA R A Dermatologist level classification of skin cancer with deep neural networks
[J]. Oncologie , 2017 , 19 (11/12 ): 407 - 408
DOI:10.1007/s10269-017-2730-4
[本文引用: 1]
[11]
MCKINNEY S M, SIENIEK M, GODBOLE V, et al International evaluation of an AI system for breast cancer screening
[J]. Nature , 2020 , 577 (7788 ): 89 - 94
DOI:10.1038/s41586-019-1799-6
[12]
ZHANG J W, HE J T, CHEN T F, et al Abnormal region detection in cervical smear images based on fully convolutional network
[J]. IET Image Processing , 2019 , 13 (4 ): 583 - 590
DOI:10.1049/iet-ipr.2018.6032
[本文引用: 1]
[13]
WANG X S, PENG Y F, LU L, et al. ChestX-ray8: hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases [C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2017: 3462-3471.
[本文引用: 4]
[14]
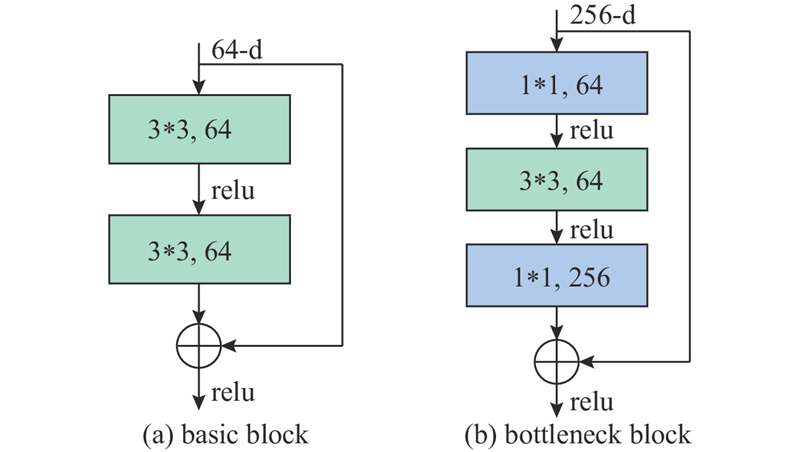
HE K M, ZHANG X Y, REN S Q. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2016: 770-778.
[本文引用: 1]
[15]
LI Y, ERIC P, DMITRY D, et al. Learning to diagnose from scratch by exploiting dependencies among labels [C]// IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2017: 7925-7937.
[本文引用: 2]
[16]
HUANG G, LIU Z, LAURENS V D M, et al. Densely connected convolutional networks [C]// IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2017: 2261-2269.
[本文引用: 1]
[17]
GUENDEL S, GRBIC S, GEORGESCU B, et al. Learning to recognize abnormalities in chest X-rays with location-aware Dense Networks [C]// Iberoamerican Congress on Pattern Recognition . Berlin: Springer, 2018: 757-765.
[本文引用: 2]
[18]
CHEN X L, GUPTA ABHINAV. Webly supervised learning of convolutional networks [C]// IEEE International Conference on Computer Vision . Piscataway: IEEE, 2016: 1431- 1439.
[本文引用: 1]
[19]
RAJPURKAR P, IRVIN J, ZHU K, et al. CheXNet: radiologist-level pneumonia detection on chest X-Rays with deep learning [C]// IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2017: 2698-2705.
[本文引用: 2]
[20]
LIU S L, ZHANG L, YANG X, et al. Query2Label: a simple transformer way to multi-label classification [C]// IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2021: 391-407.
[本文引用: 1]
[21]
BELLO I, FEDUS W, DU X, et al Revisiting ResNets: improved training and scaling strategies
[J]. Advances in Neural Information Processing Systems , 2021 , 34 : 22614 - 22627
[本文引用: 1]
[22]
LIN T Y, GOYAL P, GIRSHICK R, et al Focal loss for dense object detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (2 ): 318 - 327
DOI:10.1109/TPAMI.2018.2858826
[本文引用: 1]
[23]
IRVIN J, RAJPURKAR P, KO M, et al. CheXpert: a large chest radiograph dataset with uncertainty labels and expert comparison [C]// 33rd AAAI Conference on Artificial Intelligence . Menlo Park: AAAI, 2019: 590-597.
[本文引用: 1]
[24]
YAN C, YAO J, LI R, et al. Weakly supervised deep learning for thoracic disease classification and localization on chest X-Rays [C]// Proc of ICBCB . New York: ACM, 2018: 103-110.
[本文引用: 1]
[25]
MA C, WANG H, HOI S C H. Multi-label thoracic disease image classification with cross-attention networks. international conference on medical image computing and computer-assisted intervention [C]// International Conference on Medical Image Computing and Computer Assisted Intervention . Berlin: Springer, 2019: 730-738.
[本文引用: 2]
[26]
TEIXEIRA V, BRAZ L, PEDRINI H, et al. DuaLAnet: dual lesion attention network for thoracic disease classification in chest X-rays [C]// International Conference on Systems, Signals and Image Processing . Piscataway: IEEE, 2020: 69-74.
[本文引用: 1]
[27]
LUO L, YU L, CHEN H, et al Deep mining external imperfect data for chest x-ray disease screening
[J]. IEEE Trans Med Image , 2020 , 39 (11 ): 3583 - 3594
DOI:10.1109/TMI.2020.3000949
[本文引用: 2]
[28]
GUAN Q, HUANG Y, LUO Y, et al Discriminative feature learning for thorax disease classification in chest X-ray images
[J]. IEEE Transactions on Image Processing , 2021 , 99 : 1 - 2
[本文引用: 1]
[29]
PHAM H H, LE T T, TRAN D Q, et al Interpreting chest x-rays via cnns that exploit hierarchical disease dependencies and uncertainty labels
[J]. Neurocomputing , 2021 , 437 : 186 - 194
DOI:10.1016/j.neucom.2020.03.127
[本文引用: 1]
[30]
KAMAL U, ZUNAED M, NIZAM N B, et al Anatomy X-Net: a semi-supervised anatomy aware convolutional neural network for thoracic disease classification
[J]. IEEE Journal of Biomedical and Health Informatics , 2021 , 26 (11 ): 5518 - 5528
[本文引用: 1]
[31]
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]// 16th IEEE International Conference on Computer Vision . Piscataway: IEEE, 2017: 618-626.
[本文引用: 1]
放射科医生的透视眼—CT与核磁共振
1
2020
... 近年来,新型冠状病毒感染对全球产生较大的影响,肺部病变诊疗受到越来越多人的重视. 目前医院中一般使用X光片对肺部疾病进行常规检查,这是因为X光片获取方式比较简单,普通医院就可以基于常规设备标准获得[1 ] . 胸部X光影像中有很多细小且相似的特点,人眼进行观察时,很容易区分不出. 在这种情况下,医生可以利用计算机辅助检测(computer-aided detection, CAD)系统对X光影像进行诊断[2 ] . 随着深度学习技术的发展,人们对使用人工智能改进CAD系统产生了极大的关注. ...
放射科医生的透视眼—CT与核磁共振
1
2020
... 近年来,新型冠状病毒感染对全球产生较大的影响,肺部病变诊疗受到越来越多人的重视. 目前医院中一般使用X光片对肺部疾病进行常规检查,这是因为X光片获取方式比较简单,普通医院就可以基于常规设备标准获得[1 ] . 胸部X光影像中有很多细小且相似的特点,人眼进行观察时,很容易区分不出. 在这种情况下,医生可以利用计算机辅助检测(computer-aided detection, CAD)系统对X光影像进行诊断[2 ] . 随着深度学习技术的发展,人们对使用人工智能改进CAD系统产生了极大的关注. ...
Computer-aided diagnosis of human brain tumor through MRI: a survey and a new algorithm
1
2014
... 近年来,新型冠状病毒感染对全球产生较大的影响,肺部病变诊疗受到越来越多人的重视. 目前医院中一般使用X光片对肺部疾病进行常规检查,这是因为X光片获取方式比较简单,普通医院就可以基于常规设备标准获得[1 ] . 胸部X光影像中有很多细小且相似的特点,人眼进行观察时,很容易区分不出. 在这种情况下,医生可以利用计算机辅助检测(computer-aided detection, CAD)系统对X光影像进行诊断[2 ] . 随着深度学习技术的发展,人们对使用人工智能改进CAD系统产生了极大的关注. ...
1
... 医学图像的诊断一般属于多标签分类任务[3 -6 ] . 由于医学影像成像的模糊性、部分病灶区域的不规则性和位置的不确定性,针对医学影像的多标签分类任务需要特别注意以下2点:1)如何定位感兴趣区域并从区域中有效提取特征;2)如何处理标签不平衡问题. 针对上述问题,提出可形变Transformer辅助的胸部X光影像疾病诊断算法. 该算法对Transformer模块和双注意力模块进行优化,可以高效地处理高分辨率的医学图像,在不影响诊断正确率的情况下,提升模型的计算效率,使其更有利于开展技术落地和应用场景的示范工作;在Transformer部分引入预训练模型的分类表征作为先验知识,指导目标影像表征信息的更新和多类信息的融合;此外,还引入非对称损失函数[7 ] ,以此来更好地处理正负样本不均衡问题. 本研究方法兼顾模型的分类精度和计算复杂度,通过公开数据集ChestX-14和CheXpert上的多组实验,证明了所提方法的正确性和有效性. 工作代码已经公开,代码链接为: https://github.com/hjbzsy/Q2L-ChestX/tre e/master . ...
跨模态多标签生物医学图像分类建模识别
0
2018
跨模态多标签生物医学图像分类建模识别
0
2018
Manifold regularized multitask learning for semi-supervised multilabel image classification
1
2013
... 由表1 可知,与对比算法相比,本研究算法有明显的性能提升,这主要是由于采用分辨率更高的医学影像信息,得益于压缩型双注意力模块和可形变Transformer网络对算法复杂度的降低. Wang等[13 ] 将ImageNet预训练后的卷积神经网络作为特征提取器,只对过渡层和分类层进行训练,最终取得较好的结果,但其并未对数据的冗余信息进行处理. Ma等[25 ] 提出一种多注意力网络,主干网络为ResNet101,并在主干网络中加入挤压激励模块来构建通道之间的依赖关系,还添加了空间注意力模块来融合整体与局部的信息. 此外为了处理类失衡的问题采用错分样例模块,这些方式使得算法取得较好的分类结果,但是缺乏对先验知识的应用,相对于本研究的算法性能仍有一定的差距. Luo等[27 ] 使用多个数据集进行训练,并对不同数据集之间存在的差异进行处理,解决了域和标签差异的问题. 与所提算法相比,文献[5 ]所提方法在部分疾病上的诊断效果较好. 由于本研究采用引入先验知识等操作,从整体诊断效果上看,所提算法效果仍然占优. ...
HCP: a flexible CNN framework for multi-label image classification
1
2016
... 医学图像的诊断一般属于多标签分类任务[3 -6 ] . 由于医学影像成像的模糊性、部分病灶区域的不规则性和位置的不确定性,针对医学影像的多标签分类任务需要特别注意以下2点:1)如何定位感兴趣区域并从区域中有效提取特征;2)如何处理标签不平衡问题. 针对上述问题,提出可形变Transformer辅助的胸部X光影像疾病诊断算法. 该算法对Transformer模块和双注意力模块进行优化,可以高效地处理高分辨率的医学图像,在不影响诊断正确率的情况下,提升模型的计算效率,使其更有利于开展技术落地和应用场景的示范工作;在Transformer部分引入预训练模型的分类表征作为先验知识,指导目标影像表征信息的更新和多类信息的融合;此外,还引入非对称损失函数[7 ] ,以此来更好地处理正负样本不均衡问题. 本研究方法兼顾模型的分类精度和计算复杂度,通过公开数据集ChestX-14和CheXpert上的多组实验,证明了所提方法的正确性和有效性. 工作代码已经公开,代码链接为: https://github.com/hjbzsy/Q2L-ChestX/tre e/master . ...
1
... 医学图像的诊断一般属于多标签分类任务[3 -6 ] . 由于医学影像成像的模糊性、部分病灶区域的不规则性和位置的不确定性,针对医学影像的多标签分类任务需要特别注意以下2点:1)如何定位感兴趣区域并从区域中有效提取特征;2)如何处理标签不平衡问题. 针对上述问题,提出可形变Transformer辅助的胸部X光影像疾病诊断算法. 该算法对Transformer模块和双注意力模块进行优化,可以高效地处理高分辨率的医学图像,在不影响诊断正确率的情况下,提升模型的计算效率,使其更有利于开展技术落地和应用场景的示范工作;在Transformer部分引入预训练模型的分类表征作为先验知识,指导目标影像表征信息的更新和多类信息的融合;此外,还引入非对称损失函数[7 ] ,以此来更好地处理正负样本不均衡问题. 本研究方法兼顾模型的分类精度和计算复杂度,通过公开数据集ChestX-14和CheXpert上的多组实验,证明了所提方法的正确性和有效性. 工作代码已经公开,代码链接为: https://github.com/hjbzsy/Q2L-ChestX/tre e/master . ...
Artificial intelligence in healthcare: review and prediction case studies
1
2020
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
Artificial intelligence in medical practice: the question to the answer
1
2018
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
Dermatologist level classification of skin cancer with deep neural networks
1
2017
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
International evaluation of an AI system for breast cancer screening
0
2020
Abnormal region detection in cervical smear images based on fully convolutional network
1
2019
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
4
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
... [13 ]设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
... Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
Tab.1 疾病种类 $\overline{{\rm{AUC}}} $ Wang等[13 ] Yao等[15 ] CheXNet[19 ] Guendel等[17 ] Yan等[24 ] Ma等[25 ] DuaLAnet[26 ] Luo等[27 ] DAM Deformab- 肺不张 0.700 3 0.733 0.779 5 0.767 0.792 4 0.777 0.783 0.789 1 0.803 6 0.820 1 心脏肿大 0.810 0 0.856 0.881 6 0.883 0.881 4 0.894 0.884 0.906 9 0.884 7 0.911 5 积液 0.758 5 0.806 0.826 8 0.828 0.841 5 0.829 0.832 0.841 8 0.879 8 0.890 2 渗透 0.661 4 0.673 0.689 4 0.709 0.709 5 0.696 0.708 0.718 4 0.704 1 0.714 4 肿块 0.693 3 0.718 0.830 7 0.821 0.847 0 0.838 0.837 0.837 6 0.828 4 0.864 9 肺结节 0.668 7 0.777 0.781 4 0.758 0.810 5 0.771 0.800 0.798 5 0.732 6 0.772 5 肺炎 0.658 0 0.689 0.735 4 0.731 0.737 9 0.722 0.735 0.741 9 0.745 4 0.762 1 气胸 0.799 3 0.805 0.851 3 0.846 0.875 9 0.862 0.866 0.906 3 0.884 6 0.903 3 肺实变 0.703 2 0.711 0.754 2 0.745 0.759 8 0.750 0.746 0.768 1 0.796 6 0.810 0 水肿 0.805 2 0.806 0.849 6 0.835 0.847 8 0.846 0.841 0.861 0 0.883 9 0.895 8 肺气肿 0.833 0 0.842 0.924 9 0.895 0.942 2 0.908 0.937 0.939 6 0.920 5 0.914 2 纤维变性 0.785 9 0.743 0.821 9 0.818 0.832 6 0.827 0.820 0.838 1 0.800 6 0.808 2 胸膜增厚 0.683 5 0.724 0.792 5 0.761 0.808 3 0.779 0.796 0.803 6 0.784 2 0.814 6 疝气 0.871 7 0.775 0.932 3 0.896 0.934 1 0.934 0.895 0.937 1 0.862 1 0.875 7 $\overline{{\rm{AUC}}}_{\rm{all}} $ 0.745 1 0.761 0.818 0 0.807 0.830 2 0.817 0.820 0.834 9 0.822 1 0.839 8
表 2 CheXpert数据集上模型对各类疾病分类的性能对比 ...
... 由表1 可知,与对比算法相比,本研究算法有明显的性能提升,这主要是由于采用分辨率更高的医学影像信息,得益于压缩型双注意力模块和可形变Transformer网络对算法复杂度的降低. Wang等[13 ] 将ImageNet预训练后的卷积神经网络作为特征提取器,只对过渡层和分类层进行训练,最终取得较好的结果,但其并未对数据的冗余信息进行处理. Ma等[25 ] 提出一种多注意力网络,主干网络为ResNet101,并在主干网络中加入挤压激励模块来构建通道之间的依赖关系,还添加了空间注意力模块来融合整体与局部的信息. 此外为了处理类失衡的问题采用错分样例模块,这些方式使得算法取得较好的分类结果,但是缺乏对先验知识的应用,相对于本研究的算法性能仍有一定的差距. Luo等[27 ] 使用多个数据集进行训练,并对不同数据集之间存在的差异进行处理,解决了域和标签差异的问题. 与所提算法相比,文献[5 ]所提方法在部分疾病上的诊断效果较好. 由于本研究采用引入先验知识等操作,从整体诊断效果上看,所提算法效果仍然占优. ...
1
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
2
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
... Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
Tab.1 疾病种类 $\overline{{\rm{AUC}}} $ Wang等[13 ] Yao等[15 ] CheXNet[19 ] Guendel等[17 ] Yan等[24 ] Ma等[25 ] DuaLAnet[26 ] Luo等[27 ] DAM Deformab- 肺不张 0.700 3 0.733 0.779 5 0.767 0.792 4 0.777 0.783 0.789 1 0.803 6 0.820 1 心脏肿大 0.810 0 0.856 0.881 6 0.883 0.881 4 0.894 0.884 0.906 9 0.884 7 0.911 5 积液 0.758 5 0.806 0.826 8 0.828 0.841 5 0.829 0.832 0.841 8 0.879 8 0.890 2 渗透 0.661 4 0.673 0.689 4 0.709 0.709 5 0.696 0.708 0.718 4 0.704 1 0.714 4 肿块 0.693 3 0.718 0.830 7 0.821 0.847 0 0.838 0.837 0.837 6 0.828 4 0.864 9 肺结节 0.668 7 0.777 0.781 4 0.758 0.810 5 0.771 0.800 0.798 5 0.732 6 0.772 5 肺炎 0.658 0 0.689 0.735 4 0.731 0.737 9 0.722 0.735 0.741 9 0.745 4 0.762 1 气胸 0.799 3 0.805 0.851 3 0.846 0.875 9 0.862 0.866 0.906 3 0.884 6 0.903 3 肺实变 0.703 2 0.711 0.754 2 0.745 0.759 8 0.750 0.746 0.768 1 0.796 6 0.810 0 水肿 0.805 2 0.806 0.849 6 0.835 0.847 8 0.846 0.841 0.861 0 0.883 9 0.895 8 肺气肿 0.833 0 0.842 0.924 9 0.895 0.942 2 0.908 0.937 0.939 6 0.920 5 0.914 2 纤维变性 0.785 9 0.743 0.821 9 0.818 0.832 6 0.827 0.820 0.838 1 0.800 6 0.808 2 胸膜增厚 0.683 5 0.724 0.792 5 0.761 0.808 3 0.779 0.796 0.803 6 0.784 2 0.814 6 疝气 0.871 7 0.775 0.932 3 0.896 0.934 1 0.934 0.895 0.937 1 0.862 1 0.875 7 $\overline{{\rm{AUC}}}_{\rm{all}} $ 0.745 1 0.761 0.818 0 0.807 0.830 2 0.817 0.820 0.834 9 0.822 1 0.839 8
表 2 CheXpert数据集上模型对各类疾病分类的性能对比 ...
1
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
2
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
... Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
Tab.1 疾病种类 $\overline{{\rm{AUC}}} $ Wang等[13 ] Yao等[15 ] CheXNet[19 ] Guendel等[17 ] Yan等[24 ] Ma等[25 ] DuaLAnet[26 ] Luo等[27 ] DAM Deformab- 肺不张 0.700 3 0.733 0.779 5 0.767 0.792 4 0.777 0.783 0.789 1 0.803 6 0.820 1 心脏肿大 0.810 0 0.856 0.881 6 0.883 0.881 4 0.894 0.884 0.906 9 0.884 7 0.911 5 积液 0.758 5 0.806 0.826 8 0.828 0.841 5 0.829 0.832 0.841 8 0.879 8 0.890 2 渗透 0.661 4 0.673 0.689 4 0.709 0.709 5 0.696 0.708 0.718 4 0.704 1 0.714 4 肿块 0.693 3 0.718 0.830 7 0.821 0.847 0 0.838 0.837 0.837 6 0.828 4 0.864 9 肺结节 0.668 7 0.777 0.781 4 0.758 0.810 5 0.771 0.800 0.798 5 0.732 6 0.772 5 肺炎 0.658 0 0.689 0.735 4 0.731 0.737 9 0.722 0.735 0.741 9 0.745 4 0.762 1 气胸 0.799 3 0.805 0.851 3 0.846 0.875 9 0.862 0.866 0.906 3 0.884 6 0.903 3 肺实变 0.703 2 0.711 0.754 2 0.745 0.759 8 0.750 0.746 0.768 1 0.796 6 0.810 0 水肿 0.805 2 0.806 0.849 6 0.835 0.847 8 0.846 0.841 0.861 0 0.883 9 0.895 8 肺气肿 0.833 0 0.842 0.924 9 0.895 0.942 2 0.908 0.937 0.939 6 0.920 5 0.914 2 纤维变性 0.785 9 0.743 0.821 9 0.818 0.832 6 0.827 0.820 0.838 1 0.800 6 0.808 2 胸膜增厚 0.683 5 0.724 0.792 5 0.761 0.808 3 0.779 0.796 0.803 6 0.784 2 0.814 6 疝气 0.871 7 0.775 0.932 3 0.896 0.934 1 0.934 0.895 0.937 1 0.862 1 0.875 7 $\overline{{\rm{AUC}}}_{\rm{all}} $ 0.745 1 0.761 0.818 0 0.807 0.830 2 0.817 0.820 0.834 9 0.822 1 0.839 8
表 2 CheXpert数据集上模型对各类疾病分类的性能对比 ...
1
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
2
... 随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8 -9 ] ,MAI的相关技术也在很多医疗领域产生重要影响[10 -12 ] . 在MAI的研究工作中,学者们在胸部X光图片分类问题上取得一系列新的研究进展. 在CheXNet-8数据集上Wang等[13 ] 测试了4种网络算法,在对比4种算法分类结果的同时,得出性能最好的网络为ResNet[14 ] ,而后又在ResNet基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用. Li等[15 ] 采用长短期记忆网络(long-short term memory network, LSTM)来研究14类疾病病理标签的相关性. 在DenseNet[16 ] 的基础上,添加LSTM学习各个疾病病理标签之间的相关信息,并将DenseNet网络中稠密块的卷积个数设为4个来降低算法复杂度,同时使用Wang等[13 ] 设计的加权损失函数进行实验,最终模型取得较好的效果. Guendel等[17 ] 同时使用2个数据集进行训练,将CheXray-14数据集和PLCO数据集混合,在DenseNet基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果. Chen等[18 ] 根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果. Rajpurkar等[19 ] 提出CheXNet算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14类肺部疾病的诊断取得了更好的结果. ...
... Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
Tab.1 疾病种类 $\overline{{\rm{AUC}}} $ Wang等[13 ] Yao等[15 ] CheXNet[19 ] Guendel等[17 ] Yan等[24 ] Ma等[25 ] DuaLAnet[26 ] Luo等[27 ] DAM Deformab- 肺不张 0.700 3 0.733 0.779 5 0.767 0.792 4 0.777 0.783 0.789 1 0.803 6 0.820 1 心脏肿大 0.810 0 0.856 0.881 6 0.883 0.881 4 0.894 0.884 0.906 9 0.884 7 0.911 5 积液 0.758 5 0.806 0.826 8 0.828 0.841 5 0.829 0.832 0.841 8 0.879 8 0.890 2 渗透 0.661 4 0.673 0.689 4 0.709 0.709 5 0.696 0.708 0.718 4 0.704 1 0.714 4 肿块 0.693 3 0.718 0.830 7 0.821 0.847 0 0.838 0.837 0.837 6 0.828 4 0.864 9 肺结节 0.668 7 0.777 0.781 4 0.758 0.810 5 0.771 0.800 0.798 5 0.732 6 0.772 5 肺炎 0.658 0 0.689 0.735 4 0.731 0.737 9 0.722 0.735 0.741 9 0.745 4 0.762 1 气胸 0.799 3 0.805 0.851 3 0.846 0.875 9 0.862 0.866 0.906 3 0.884 6 0.903 3 肺实变 0.703 2 0.711 0.754 2 0.745 0.759 8 0.750 0.746 0.768 1 0.796 6 0.810 0 水肿 0.805 2 0.806 0.849 6 0.835 0.847 8 0.846 0.841 0.861 0 0.883 9 0.895 8 肺气肿 0.833 0 0.842 0.924 9 0.895 0.942 2 0.908 0.937 0.939 6 0.920 5 0.914 2 纤维变性 0.785 9 0.743 0.821 9 0.818 0.832 6 0.827 0.820 0.838 1 0.800 6 0.808 2 胸膜增厚 0.683 5 0.724 0.792 5 0.761 0.808 3 0.779 0.796 0.803 6 0.784 2 0.814 6 疝气 0.871 7 0.775 0.932 3 0.896 0.934 1 0.934 0.895 0.937 1 0.862 1 0.875 7 $\overline{{\rm{AUC}}}_{\rm{all}} $ 0.745 1 0.761 0.818 0 0.807 0.830 2 0.817 0.820 0.834 9 0.822 1 0.839 8
表 2 CheXpert数据集上模型对各类疾病分类的性能对比 ...
1
... 目前主流的分类方法大多是对不同的卷积神经网络做出改进,通过提高特征提取能力来提高分类精度. 随着Transformer在计算机视觉领域的发展,Liu等[20 ] 提出Query2label模型,该模型先对图片通过一个骨干网络提取特征图,然后将图片特征和标签特征送入Transformer解码器,把图片特征作为Key和Value,标签特征作为Query,利用Transformer解码器内部的交叉注意模块,预测相关标签的存在性,在自然图像分类任务上取得了较好的效果. 本研究设计一种结合可形变Transformer与压缩型双注意力模块的多标签胸部疾病分类模型,将Transformer应用到医学图像领域,以期获得较好的分类效果. ...
Revisiting ResNets: improved training and scaling strategies
1
2021
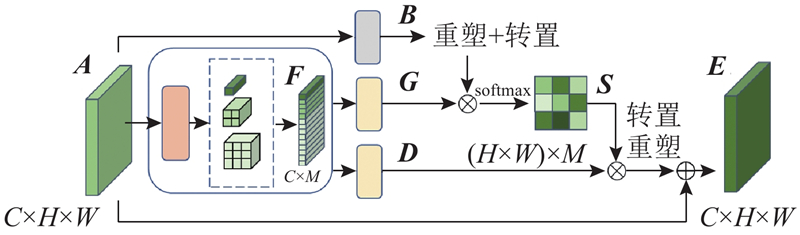
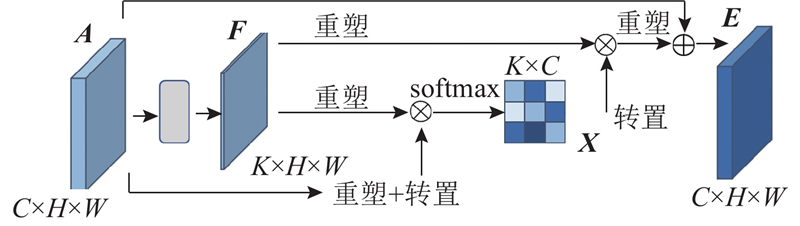
... 在特征提取阶段,首先使用扩展后的ResNet50获得较高分辨率的初始特征图[21 ] ,接着通过压缩型双注意力模块加强特征表示;在类别预测阶段,使用标签嵌入作为查询,通过可形变Transformer解码器内部的交叉注意力模块,自适应地从上游传来的特征图中提取与类别相关的特征,以预测相关标签的存在性. 引入预训练模型的分类表征来指导影像数据在不同类别下的表征,最终传入分类器,获得预测结果. 此外还引入非对称损失函数以改善数据集中正负样本不均衡的问题. ...
Focal loss for dense object detection
1
2020
... 为了解决数据集中正负样本不均衡的问题,采用非对称损失函数. 在焦点损失函数[22 ] 的基础上,解耦正样本和负样本的指数因子,可以更好地控制正样本和负样本对损失函数的贡献. 本研究使用的是简化后的非对称损失函数,可以看作一种非对称聚焦损失函数,即 ...
1
... CheXpert数据集是吴恩达团队于2019年公开的一个大型胸部X光片数据集[23 ] ,其中包含65 240位病人的224 316张胸片. 该数据集中每张胸片共标注了14个标签,其中12个是心脏肥大、肺不张、肺实变等12种疾病特征,另外2个标签分别为未发现病灶和辅助设备. 此外,每种类别有3种标记,包括阳性、阴性以及不确定,不确定为医生仅通过X光片还判断不出是否患有某种疾病. ...
1
... Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
Tab.1 疾病种类 $\overline{{\rm{AUC}}} $ Wang等[13 ] Yao等[15 ] CheXNet[19 ] Guendel等[17 ] Yan等[24 ] Ma等[25 ] DuaLAnet[26 ] Luo等[27 ] DAM Deformab- 肺不张 0.700 3 0.733 0.779 5 0.767 0.792 4 0.777 0.783 0.789 1 0.803 6 0.820 1 心脏肿大 0.810 0 0.856 0.881 6 0.883 0.881 4 0.894 0.884 0.906 9 0.884 7 0.911 5 积液 0.758 5 0.806 0.826 8 0.828 0.841 5 0.829 0.832 0.841 8 0.879 8 0.890 2 渗透 0.661 4 0.673 0.689 4 0.709 0.709 5 0.696 0.708 0.718 4 0.704 1 0.714 4 肿块 0.693 3 0.718 0.830 7 0.821 0.847 0 0.838 0.837 0.837 6 0.828 4 0.864 9 肺结节 0.668 7 0.777 0.781 4 0.758 0.810 5 0.771 0.800 0.798 5 0.732 6 0.772 5 肺炎 0.658 0 0.689 0.735 4 0.731 0.737 9 0.722 0.735 0.741 9 0.745 4 0.762 1 气胸 0.799 3 0.805 0.851 3 0.846 0.875 9 0.862 0.866 0.906 3 0.884 6 0.903 3 肺实变 0.703 2 0.711 0.754 2 0.745 0.759 8 0.750 0.746 0.768 1 0.796 6 0.810 0 水肿 0.805 2 0.806 0.849 6 0.835 0.847 8 0.846 0.841 0.861 0 0.883 9 0.895 8 肺气肿 0.833 0 0.842 0.924 9 0.895 0.942 2 0.908 0.937 0.939 6 0.920 5 0.914 2 纤维变性 0.785 9 0.743 0.821 9 0.818 0.832 6 0.827 0.820 0.838 1 0.800 6 0.808 2 胸膜增厚 0.683 5 0.724 0.792 5 0.761 0.808 3 0.779 0.796 0.803 6 0.784 2 0.814 6 疝气 0.871 7 0.775 0.932 3 0.896 0.934 1 0.934 0.895 0.937 1 0.862 1 0.875 7 $\overline{{\rm{AUC}}}_{\rm{all}} $ 0.745 1 0.761 0.818 0 0.807 0.830 2 0.817 0.820 0.834 9 0.822 1 0.839 8
表 2 CheXpert数据集上模型对各类疾病分类的性能对比 ...
2
... Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
Tab.1 疾病种类 $\overline{{\rm{AUC}}} $ Wang等[13 ] Yao等[15 ] CheXNet[19 ] Guendel等[17 ] Yan等[24 ] Ma等[25 ] DuaLAnet[26 ] Luo等[27 ] DAM Deformab- 肺不张 0.700 3 0.733 0.779 5 0.767 0.792 4 0.777 0.783 0.789 1 0.803 6 0.820 1 心脏肿大 0.810 0 0.856 0.881 6 0.883 0.881 4 0.894 0.884 0.906 9 0.884 7 0.911 5 积液 0.758 5 0.806 0.826 8 0.828 0.841 5 0.829 0.832 0.841 8 0.879 8 0.890 2 渗透 0.661 4 0.673 0.689 4 0.709 0.709 5 0.696 0.708 0.718 4 0.704 1 0.714 4 肿块 0.693 3 0.718 0.830 7 0.821 0.847 0 0.838 0.837 0.837 6 0.828 4 0.864 9 肺结节 0.668 7 0.777 0.781 4 0.758 0.810 5 0.771 0.800 0.798 5 0.732 6 0.772 5 肺炎 0.658 0 0.689 0.735 4 0.731 0.737 9 0.722 0.735 0.741 9 0.745 4 0.762 1 气胸 0.799 3 0.805 0.851 3 0.846 0.875 9 0.862 0.866 0.906 3 0.884 6 0.903 3 肺实变 0.703 2 0.711 0.754 2 0.745 0.759 8 0.750 0.746 0.768 1 0.796 6 0.810 0 水肿 0.805 2 0.806 0.849 6 0.835 0.847 8 0.846 0.841 0.861 0 0.883 9 0.895 8 肺气肿 0.833 0 0.842 0.924 9 0.895 0.942 2 0.908 0.937 0.939 6 0.920 5 0.914 2 纤维变性 0.785 9 0.743 0.821 9 0.818 0.832 6 0.827 0.820 0.838 1 0.800 6 0.808 2 胸膜增厚 0.683 5 0.724 0.792 5 0.761 0.808 3 0.779 0.796 0.803 6 0.784 2 0.814 6 疝气 0.871 7 0.775 0.932 3 0.896 0.934 1 0.934 0.895 0.937 1 0.862 1 0.875 7 $\overline{{\rm{AUC}}}_{\rm{all}} $ 0.745 1 0.761 0.818 0 0.807 0.830 2 0.817 0.820 0.834 9 0.822 1 0.839 8
表 2 CheXpert数据集上模型对各类疾病分类的性能对比 ...
... 由表1 可知,与对比算法相比,本研究算法有明显的性能提升,这主要是由于采用分辨率更高的医学影像信息,得益于压缩型双注意力模块和可形变Transformer网络对算法复杂度的降低. Wang等[13 ] 将ImageNet预训练后的卷积神经网络作为特征提取器,只对过渡层和分类层进行训练,最终取得较好的结果,但其并未对数据的冗余信息进行处理. Ma等[25 ] 提出一种多注意力网络,主干网络为ResNet101,并在主干网络中加入挤压激励模块来构建通道之间的依赖关系,还添加了空间注意力模块来融合整体与局部的信息. 此外为了处理类失衡的问题采用错分样例模块,这些方式使得算法取得较好的分类结果,但是缺乏对先验知识的应用,相对于本研究的算法性能仍有一定的差距. Luo等[27 ] 使用多个数据集进行训练,并对不同数据集之间存在的差异进行处理,解决了域和标签差异的问题. 与所提算法相比,文献[5 ]所提方法在部分疾病上的诊断效果较好. 由于本研究采用引入先验知识等操作,从整体诊断效果上看,所提算法效果仍然占优. ...
1
... Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
Tab.1 疾病种类 $\overline{{\rm{AUC}}} $ Wang等[13 ] Yao等[15 ] CheXNet[19 ] Guendel等[17 ] Yan等[24 ] Ma等[25 ] DuaLAnet[26 ] Luo等[27 ] DAM Deformab- 肺不张 0.700 3 0.733 0.779 5 0.767 0.792 4 0.777 0.783 0.789 1 0.803 6 0.820 1 心脏肿大 0.810 0 0.856 0.881 6 0.883 0.881 4 0.894 0.884 0.906 9 0.884 7 0.911 5 积液 0.758 5 0.806 0.826 8 0.828 0.841 5 0.829 0.832 0.841 8 0.879 8 0.890 2 渗透 0.661 4 0.673 0.689 4 0.709 0.709 5 0.696 0.708 0.718 4 0.704 1 0.714 4 肿块 0.693 3 0.718 0.830 7 0.821 0.847 0 0.838 0.837 0.837 6 0.828 4 0.864 9 肺结节 0.668 7 0.777 0.781 4 0.758 0.810 5 0.771 0.800 0.798 5 0.732 6 0.772 5 肺炎 0.658 0 0.689 0.735 4 0.731 0.737 9 0.722 0.735 0.741 9 0.745 4 0.762 1 气胸 0.799 3 0.805 0.851 3 0.846 0.875 9 0.862 0.866 0.906 3 0.884 6 0.903 3 肺实变 0.703 2 0.711 0.754 2 0.745 0.759 8 0.750 0.746 0.768 1 0.796 6 0.810 0 水肿 0.805 2 0.806 0.849 6 0.835 0.847 8 0.846 0.841 0.861 0 0.883 9 0.895 8 肺气肿 0.833 0 0.842 0.924 9 0.895 0.942 2 0.908 0.937 0.939 6 0.920 5 0.914 2 纤维变性 0.785 9 0.743 0.821 9 0.818 0.832 6 0.827 0.820 0.838 1 0.800 6 0.808 2 胸膜增厚 0.683 5 0.724 0.792 5 0.761 0.808 3 0.779 0.796 0.803 6 0.784 2 0.814 6 疝气 0.871 7 0.775 0.932 3 0.896 0.934 1 0.934 0.895 0.937 1 0.862 1 0.875 7 $\overline{{\rm{AUC}}}_{\rm{all}} $ 0.745 1 0.761 0.818 0 0.807 0.830 2 0.817 0.820 0.834 9 0.822 1 0.839 8
表 2 CheXpert数据集上模型对各类疾病分类的性能对比 ...
Deep mining external imperfect data for chest x-ray disease screening
2
2020
... Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
Tab.1 疾病种类 $\overline{{\rm{AUC}}} $ Wang等[13 ] Yao等[15 ] CheXNet[19 ] Guendel等[17 ] Yan等[24 ] Ma等[25 ] DuaLAnet[26 ] Luo等[27 ] DAM Deformab- 肺不张 0.700 3 0.733 0.779 5 0.767 0.792 4 0.777 0.783 0.789 1 0.803 6 0.820 1 心脏肿大 0.810 0 0.856 0.881 6 0.883 0.881 4 0.894 0.884 0.906 9 0.884 7 0.911 5 积液 0.758 5 0.806 0.826 8 0.828 0.841 5 0.829 0.832 0.841 8 0.879 8 0.890 2 渗透 0.661 4 0.673 0.689 4 0.709 0.709 5 0.696 0.708 0.718 4 0.704 1 0.714 4 肿块 0.693 3 0.718 0.830 7 0.821 0.847 0 0.838 0.837 0.837 6 0.828 4 0.864 9 肺结节 0.668 7 0.777 0.781 4 0.758 0.810 5 0.771 0.800 0.798 5 0.732 6 0.772 5 肺炎 0.658 0 0.689 0.735 4 0.731 0.737 9 0.722 0.735 0.741 9 0.745 4 0.762 1 气胸 0.799 3 0.805 0.851 3 0.846 0.875 9 0.862 0.866 0.906 3 0.884 6 0.903 3 肺实变 0.703 2 0.711 0.754 2 0.745 0.759 8 0.750 0.746 0.768 1 0.796 6 0.810 0 水肿 0.805 2 0.806 0.849 6 0.835 0.847 8 0.846 0.841 0.861 0 0.883 9 0.895 8 肺气肿 0.833 0 0.842 0.924 9 0.895 0.942 2 0.908 0.937 0.939 6 0.920 5 0.914 2 纤维变性 0.785 9 0.743 0.821 9 0.818 0.832 6 0.827 0.820 0.838 1 0.800 6 0.808 2 胸膜增厚 0.683 5 0.724 0.792 5 0.761 0.808 3 0.779 0.796 0.803 6 0.784 2 0.814 6 疝气 0.871 7 0.775 0.932 3 0.896 0.934 1 0.934 0.895 0.937 1 0.862 1 0.875 7 $\overline{{\rm{AUC}}}_{\rm{all}} $ 0.745 1 0.761 0.818 0 0.807 0.830 2 0.817 0.820 0.834 9 0.822 1 0.839 8
表 2 CheXpert数据集上模型对各类疾病分类的性能对比 ...
... 由表1 可知,与对比算法相比,本研究算法有明显的性能提升,这主要是由于采用分辨率更高的医学影像信息,得益于压缩型双注意力模块和可形变Transformer网络对算法复杂度的降低. Wang等[13 ] 将ImageNet预训练后的卷积神经网络作为特征提取器,只对过渡层和分类层进行训练,最终取得较好的结果,但其并未对数据的冗余信息进行处理. Ma等[25 ] 提出一种多注意力网络,主干网络为ResNet101,并在主干网络中加入挤压激励模块来构建通道之间的依赖关系,还添加了空间注意力模块来融合整体与局部的信息. 此外为了处理类失衡的问题采用错分样例模块,这些方式使得算法取得较好的分类结果,但是缺乏对先验知识的应用,相对于本研究的算法性能仍有一定的差距. Luo等[27 ] 使用多个数据集进行训练,并对不同数据集之间存在的差异进行处理,解决了域和标签差异的问题. 与所提算法相比,文献[5 ]所提方法在部分疾病上的诊断效果较好. 由于本研究采用引入先验知识等操作,从整体诊断效果上看,所提算法效果仍然占优. ...
Discriminative feature learning for thorax disease classification in chest X-ray images
1
2021
... Comparison of model performance on CheXpert dataset for classification of various diseases
Tab.2 疾病种类 $\overline { {\text{AUC} } } $ U-Ignore U-Zeros U-Ones Guan等[28 ] Pham等[29 ] Irvin等[30 ] Deformab-CDAM-D 肺不张 0.818 0.811 0.858 0.847 0.825 0 0.858 0 0.863 5 心脏肿大 0.828 0.840 0.832 0.868 0.855 0 0.832 0 0.865 5 肺实变 0.938 0.932 0.899 0.923 0.937 0 0.899 0 0.907 9 水肿 0.934 0.929 0.941 0.924 0.930 0 0.941 0 0.942 9 胸膜增厚 0.928 0.931 0.934 0.926 0.923 0 0.934 0 0.951 1 $ \overline {{\text{AUC}}}_{\rm{all}} $ 0.889 2 0.888 6 0.892 8 0.898 0.894 0 0.893 0 0.906 1
由表1 可知,与对比算法相比,本研究算法有明显的性能提升,这主要是由于采用分辨率更高的医学影像信息,得益于压缩型双注意力模块和可形变Transformer网络对算法复杂度的降低. Wang等[13 ] 将ImageNet预训练后的卷积神经网络作为特征提取器,只对过渡层和分类层进行训练,最终取得较好的结果,但其并未对数据的冗余信息进行处理. Ma等[25 ] 提出一种多注意力网络,主干网络为ResNet101,并在主干网络中加入挤压激励模块来构建通道之间的依赖关系,还添加了空间注意力模块来融合整体与局部的信息. 此外为了处理类失衡的问题采用错分样例模块,这些方式使得算法取得较好的分类结果,但是缺乏对先验知识的应用,相对于本研究的算法性能仍有一定的差距. Luo等[27 ] 使用多个数据集进行训练,并对不同数据集之间存在的差异进行处理,解决了域和标签差异的问题. 与所提算法相比,文献[5 ]所提方法在部分疾病上的诊断效果较好. 由于本研究采用引入先验知识等操作,从整体诊断效果上看,所提算法效果仍然占优. ...
Interpreting chest x-rays via cnns that exploit hierarchical disease dependencies and uncertainty labels
1
2021
... Comparison of model performance on CheXpert dataset for classification of various diseases
Tab.2 疾病种类 $\overline { {\text{AUC} } } $ U-Ignore U-Zeros U-Ones Guan等[28 ] Pham等[29 ] Irvin等[30 ] Deformab-CDAM-D 肺不张 0.818 0.811 0.858 0.847 0.825 0 0.858 0 0.863 5 心脏肿大 0.828 0.840 0.832 0.868 0.855 0 0.832 0 0.865 5 肺实变 0.938 0.932 0.899 0.923 0.937 0 0.899 0 0.907 9 水肿 0.934 0.929 0.941 0.924 0.930 0 0.941 0 0.942 9 胸膜增厚 0.928 0.931 0.934 0.926 0.923 0 0.934 0 0.951 1 $ \overline {{\text{AUC}}}_{\rm{all}} $ 0.889 2 0.888 6 0.892 8 0.898 0.894 0 0.893 0 0.906 1
由表1 可知,与对比算法相比,本研究算法有明显的性能提升,这主要是由于采用分辨率更高的医学影像信息,得益于压缩型双注意力模块和可形变Transformer网络对算法复杂度的降低. Wang等[13 ] 将ImageNet预训练后的卷积神经网络作为特征提取器,只对过渡层和分类层进行训练,最终取得较好的结果,但其并未对数据的冗余信息进行处理. Ma等[25 ] 提出一种多注意力网络,主干网络为ResNet101,并在主干网络中加入挤压激励模块来构建通道之间的依赖关系,还添加了空间注意力模块来融合整体与局部的信息. 此外为了处理类失衡的问题采用错分样例模块,这些方式使得算法取得较好的分类结果,但是缺乏对先验知识的应用,相对于本研究的算法性能仍有一定的差距. Luo等[27 ] 使用多个数据集进行训练,并对不同数据集之间存在的差异进行处理,解决了域和标签差异的问题. 与所提算法相比,文献[5 ]所提方法在部分疾病上的诊断效果较好. 由于本研究采用引入先验知识等操作,从整体诊断效果上看,所提算法效果仍然占优. ...
Anatomy X-Net: a semi-supervised anatomy aware convolutional neural network for thoracic disease classification
1
2021
... Comparison of model performance on CheXpert dataset for classification of various diseases
Tab.2 疾病种类 $\overline { {\text{AUC} } } $ U-Ignore U-Zeros U-Ones Guan等[28 ] Pham等[29 ] Irvin等[30 ] Deformab-CDAM-D 肺不张 0.818 0.811 0.858 0.847 0.825 0 0.858 0 0.863 5 心脏肿大 0.828 0.840 0.832 0.868 0.855 0 0.832 0 0.865 5 肺实变 0.938 0.932 0.899 0.923 0.937 0 0.899 0 0.907 9 水肿 0.934 0.929 0.941 0.924 0.930 0 0.941 0 0.942 9 胸膜增厚 0.928 0.931 0.934 0.926 0.923 0 0.934 0 0.951 1 $ \overline {{\text{AUC}}}_{\rm{all}} $ 0.889 2 0.888 6 0.892 8 0.898 0.894 0 0.893 0 0.906 1
由表1 可知,与对比算法相比,本研究算法有明显的性能提升,这主要是由于采用分辨率更高的医学影像信息,得益于压缩型双注意力模块和可形变Transformer网络对算法复杂度的降低. Wang等[13 ] 将ImageNet预训练后的卷积神经网络作为特征提取器,只对过渡层和分类层进行训练,最终取得较好的结果,但其并未对数据的冗余信息进行处理. Ma等[25 ] 提出一种多注意力网络,主干网络为ResNet101,并在主干网络中加入挤压激励模块来构建通道之间的依赖关系,还添加了空间注意力模块来融合整体与局部的信息. 此外为了处理类失衡的问题采用错分样例模块,这些方式使得算法取得较好的分类结果,但是缺乏对先验知识的应用,相对于本研究的算法性能仍有一定的差距. Luo等[27 ] 使用多个数据集进行训练,并对不同数据集之间存在的差异进行处理,解决了域和标签差异的问题. 与所提算法相比,文献[5 ]所提方法在部分疾病上的诊断效果较好. 由于本研究采用引入先验知识等操作,从整体诊断效果上看,所提算法效果仍然占优. ...
1
... 通过加权梯度类激活映射(Grad-CAM)方法来证实模型的有效性[31 ] ,生成病灶定位热图,使网络在识别肺部疾病时有位置依据. Grad-CAM方法对模型参数进行加载,然后采用梯度加权平均的方式处理特征图权重,进而可以生成热图. 图7 展示了8种疾病的医生标注图与其对应热图,热图中颜色越红的地方表示越接近病灶区域,医生标注的病变位置为长方形边框. 经过图7 的对比可以发现,热图所确定的位置基本与专业放射科医生标出的位置相同,这表明模型根据X光片诊断肺部疾病时依据的特征信息是可靠的. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}