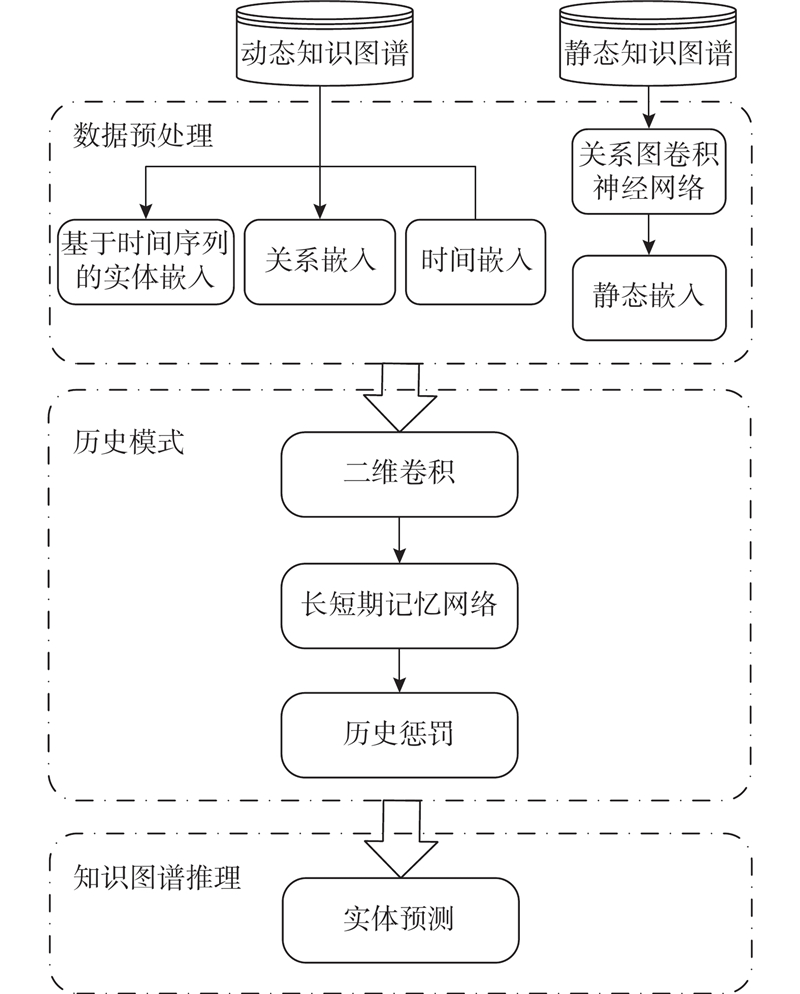
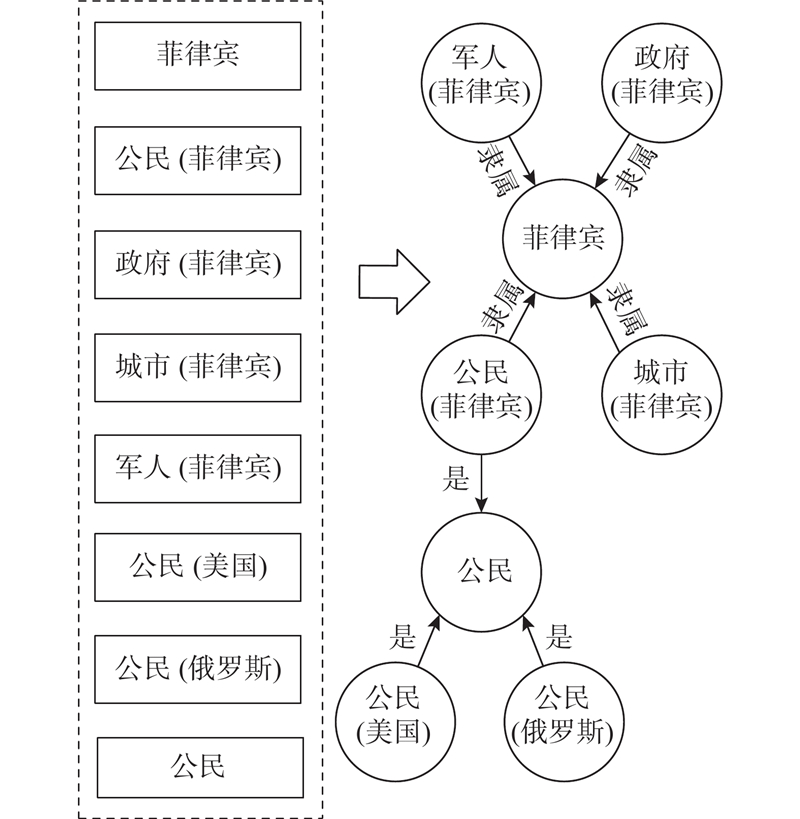
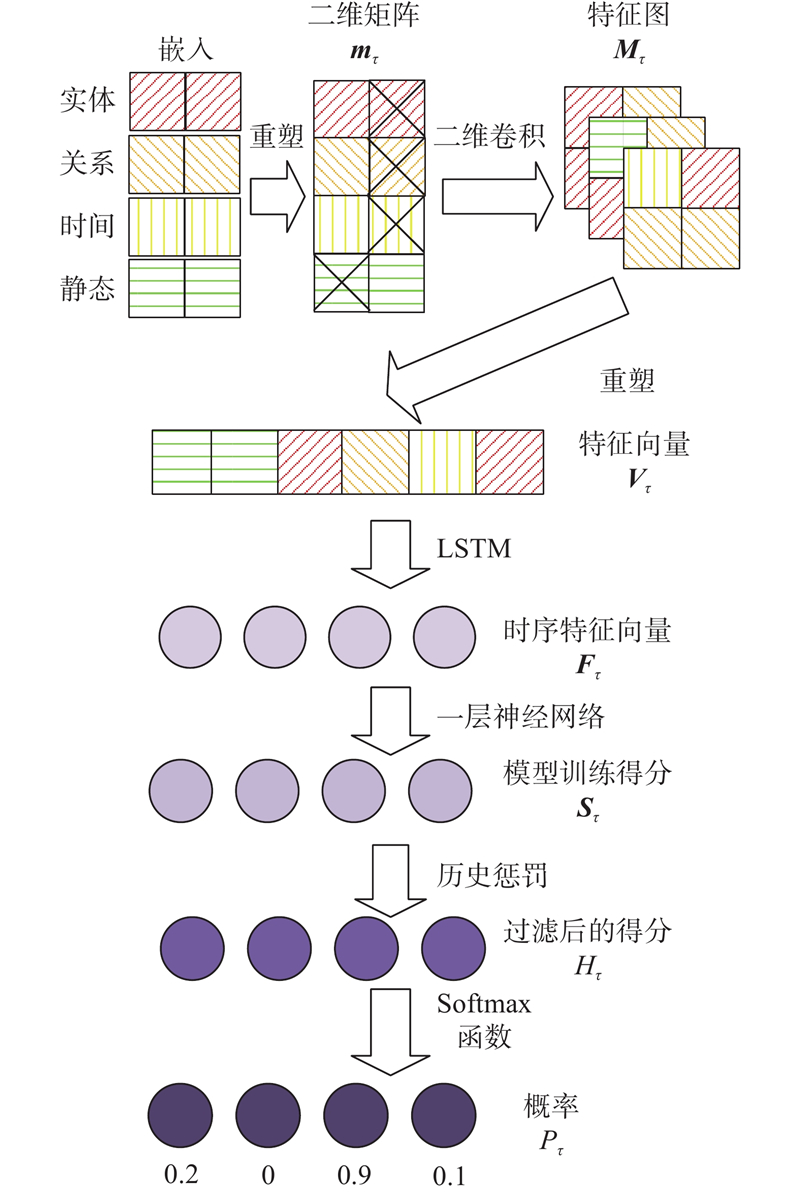
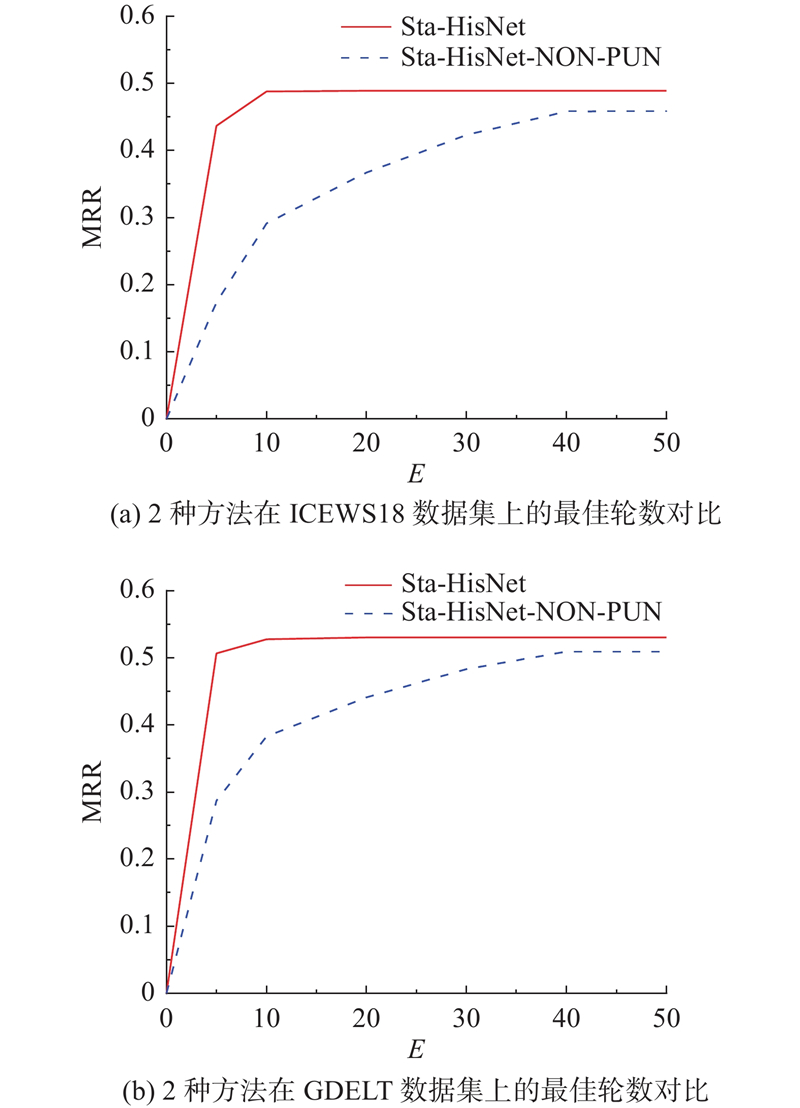
A static-historical network (Sta-HisNet) method combining static facts and repeating historical facts was proposed, aiming at the problem that existing dynamic knowledge graph reasoning methods tend to overlook the vast amount of static information and repeating historical facts present in the dynamic knowledge graphs. The hidden static connections between entities in the dynamic knowledge graph were used to form static facts, assisting in the inference of the dynamic knowledge graph. Historical facts were employed to construct a historical vocabulary, and the historical vocabulary was queried when predicting the future. Facts that had not occurred in history were punished, and the probability of predicting duplicate historical facts was increased. Experiments were conducted on two public datasets for dynamic knowledge graph reasoning. Comparative experiments were performed using five mainstream models as baselines. In entity prediction experiments, the mean reciprocal rank (MRR) was 0.489 1 and 0.530 3, and Hits@10 reached 0.588 7 and 0.616 5 respectively, demonstrating the effectiveness of the proposed method.
LIU Z, XIONG C, SUN M, et al. Entity-duet neural ranking: Understanding the role of knowledge graph semantics in neural information retrieval [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Columbus: ACL, 2008: 2395-2405.
JIANG T, LIU T, GE T, et al. Encoding temporal information for time-aware link prediction [C]// Proceedings of the Conference on Empirical Methods in Natural Language Processing. Austin: ACL, 2016: 2350-2354.
BORDES A, USUNIER N, GARCIADURAN A, et al. Translating embeddings for modeling multi-relational data [C]// Proceedings ofthe Neural Information Processing Systems. Lake Tahoe: NIP, 2013: 2787-2795.
WANG Z, ZHANG J, FENG J, et al. Knowledge graph embedding by translating on hyperplanes [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Quebec: AAAI, 2014, 28(1): 1112-1119.
DAI S, LIANG Y, LIU S, et al. Learning entity and relation embeddings with entity description for knowledge graph completion [C]// Proceedings of the 4th International Conference on Artificial Intelligence Technologies and Applications. Chengdu: JPCS, 2018: 202-205.
TROUILLON T, WELBL J, RIEDEL S, et al. Complex embeddings for simple link prediction [C]// Proceedings of the International Conference on Machine Learning. Hong Kong: ACM, 2016: 2071-2080.
SOCHER R, CHEN D, MANNING C D, et al. Reasoning with neural tensor networks for knowledge base completion [C]// Proceedings of the Neural Information Processing Systems. Lake Tahoe: NIP, 2013: 926-934.
SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks [C]// Proceedings of the European Semantic Web Conference. Heraklion: ESWC, 2018: 593-607.
LEBLAY J, CHEKOL M W. Deriving validity time in knowledge graph [C]// Proceedings of the 27th Internation Conference on World Wide Web. Lyons: ACM, 2018: 1771-1776.
DASGUPTA S S, RAY S N, TALUKDAR P. Hyte: hyperplane-based temporally aware knowledge graph embedding [C]// Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels: ACL, 2018: 2001-2011.
TRIVEDI R, DAI H, WANG Y, et al. Know-evolve: Deep temporal reasoning for dynamic knowledge graphs [C]// Proceedings of the 34th International Conference on Machine Learning-Volume 70. Sydney: ACM, 2017: 3462-3471.
JIN W, ZHANG C, SZEKELY P, et al. Recurrent event network for reasoning over temporal knowledge graphs [C]// Proceedings of the Conference on Empirical Methods in Natural Language Processing. Hong Kong: ACL, 2019: 8352-8364.
LI Z, GUAN S, JIN X, et al. Complex evolutional pattern learning for temporal knowledge graph reasoning [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Dublin: ACL, 2022: 290-296.
LI Z X, JIN X L, LI W, et al. Temporal knowledge graph reasoning based on evolutional representation learning [C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. Montréal: ACM, 2021: 408-417.
ZHU C, CHEN M, FAN C, et al. Learning from History: modeling temporal knowledge graphs with sequential copy-generation networks [EB/OL]. [2022-09-01]. https://arxiv.org/abs/2012.08492.
WARD M D, BEGER A, CUTLER J, et al. Comparing GDELT and ICEWS event data [C]// Proceedings of the ISA Annual Convention. San Francisco: ISA, 2013: 1-49.
LEETARU K, SCHRODT P A. Gdelt: global data on events, location, and tone, 1979–2012 [C]// Proceedings of theISA Annual Convention. San Francisco: ISA, 2013, 2(4): 1-49.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}