

针对字体生成任务,Tian[4]提出Rewrite模型,生成的字体结构细节模糊. Tian在Pix2pix[5]网络的基础上提出zi2zi[6]模型,与Rewrite相比,zi2zi生成效果明显提升. Jiang等[7]提出DCFont,分别编码字体内容和风格特征,通过解码和特征重构生成字体. Chang等[8]提出DenseNet CycleGAN,将Cyc1eGAN[9]中的残差单元替换为密集连接网络,生成字体笔画错连、缺失的情况较严重. Ren等[10]通过引入自注意力机制及边缘损失,解决了已有模型生成汉字局部信息不明显、层级结构不鲜明的问题. Wu等[11]提出CalliGAN,利用汉字笔画信息,提升生成图像的细节特征. Park等[12]提出LFFont,学习局部组件风格,利用低秩矩阵分解组件级风格,但容易出现组件缺失,模型性能不稳定. Xie等[13]提出DGFont,引入特征变形卷积增强生成字体结构的完整性. Park等[14]提出MXFont,采用多头编码器特征提取,利用局部组件信息监督模型训练. Kong等[15]提出CG-GAN,设计组件感知模块,在字符组件级别进行监督.
为了减少生成字体笔画结构的丢失和细节模糊的问题,稳定模型训练,提高生成字体图像的质量,本文提出基于改进生成对抗网络的书法字生成算法. 通过改进编码器卷积层结构,提高字体细节结构. 通过自注意力网络捕获字体笔画间的关系,学习丰富的上下文信息,分配不同特征的权重,增强风格特征的表征能力,使得生成字体的风格更加接近目标字体. 增加边缘损失函数,细化字体边缘信息,提高生成图像的质量. 通过生成2种不同风格的书法字,验证本文方法的有效性.
1. zi2zi生成对抗网络
图 1
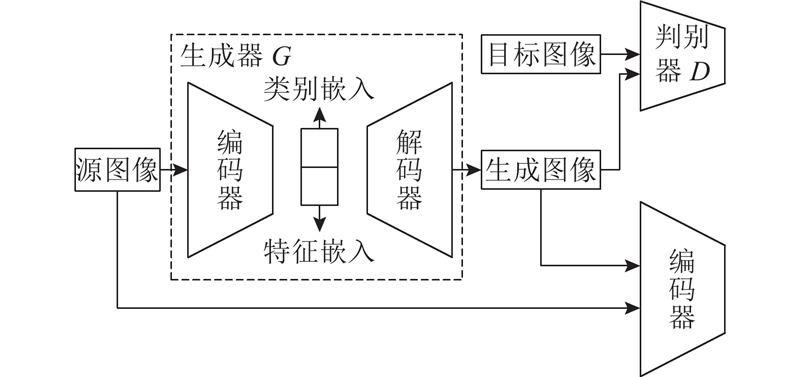
判别器(discriminator,D)判断输入图像是否真实,同时鉴别图像类别. 在网络训练过程中,期望生成器生成接近目标风格的字体图像,达到欺骗判别器的目的. 判别器能够判别生成的假字体图像,两者交替对抗训练,实现纳什平衡.
2. 改进的生成对抗网络
以zi2zi为基本网络模型,针对网络训练稳定性低、生成图像质量差、生成字体结构不清晰的问题,改进生成器与判别器的结构,设计新的损失函数. 改进后的网络整体结构如图2所示. 该网络包括内容编码器
图 2
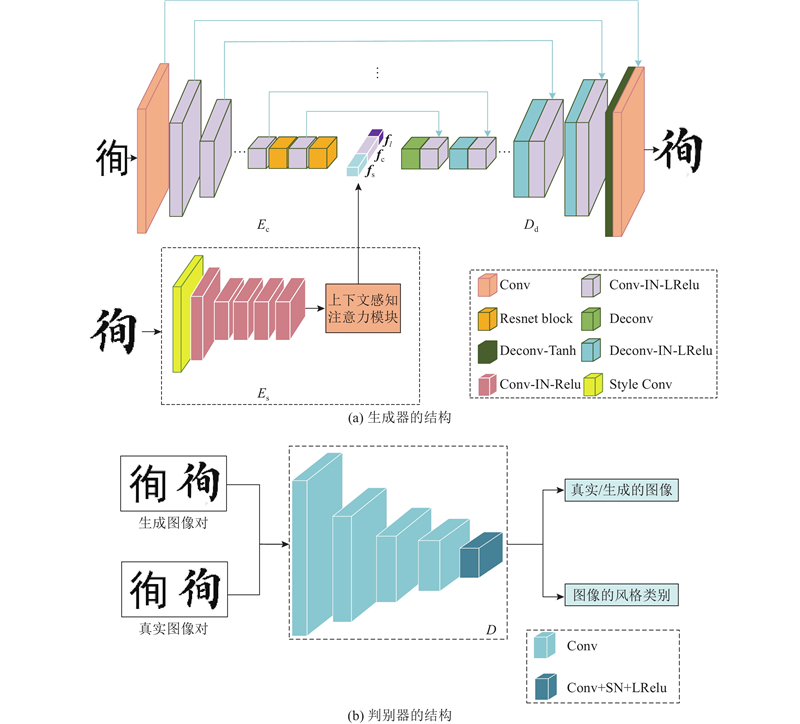
结合编码后的
2.1. 生成器结构
生成器由内容编码器
2.1.1. 残差单元
为了捕捉字体图像更多的局部特征,在内容编码器中加入残差单元,扩充卷积结构,形成卷积-残差交替模块. 内容编码器包括5层卷积层、5层卷积-残差交替编码结构,内容编码器的具体参数设置如表1所示. 卷积单元Conv-IN-LRelu表示Conv卷积操作、实例归一化( instance normalization,IN )、LRelu激活函数,卷积核为4,strides为步长,filters为卷积核数.
表 1 内容编码器的网络参数
Tab.1
| 网络层类型 | 网络参数 |
| 卷积层 | 4×4 Conv, 64 filters, 2 strides |
| 卷积单元层 | 4×4 Conv-IN-LRelu, 128 filters, 2 strides |
| 卷积单元层 | 4×4 Conv-IN-LRelu, 256 filters, 2 strides |
| 卷积单元层 | 4×4 Conv-IN-LRelu, 512 filters, 2 strides |
| 卷积单元层 | 4×4 Conv-IN-LRelu, 512 filters, 2 strides |
| 卷积单元层 | 4×4 Conv-IN-LRelu, 512 filters, 2 strides |
| 残差单元层 | Resnet Block 1×1 Conv, 512 filters,1stride |
| 卷积单元层 | 4×4 Conv-IN-LRelu, 512 filters, 2 strides |
| 残差单元层 | Resnet Block 1×1 Conv, 512 filters, 1 stride |
| 卷积层 | 4×4 Conv-LRelu, 512 filters, 2 strides |
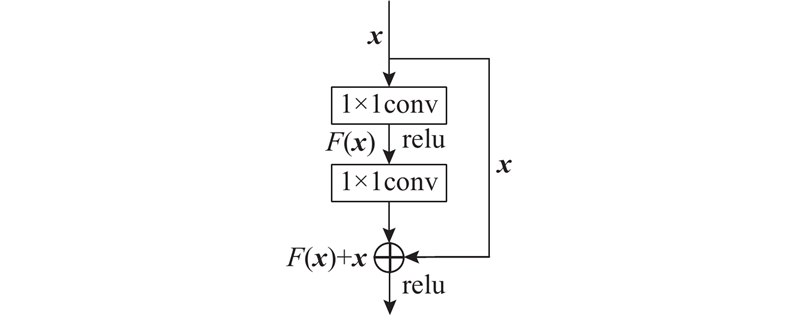
汉字笔画线条的粗细、长短、书写方向等局部细节信息影响汉字的字形与风格. 为了保存汉字细节的结构特征,减少参数量,使用1×1的卷积核,残差单元的结构如图3所示.
图 3
2.1.2. 上下文感知注意力模块
为了使得模型生成的字体图像风格与目标风格保持一致,本文算法中额外引入风格编码模块,该模块在训练过程中更多关注字体的风格样式. 风格编码器网络结构主要由6层卷积层和上下文感知注意力模块组成,上下文感知注意力模块如图4所示. 风格编码器的输入只进行卷积操作,卷积核为7,步长为1. 其他5层结构均为Conv卷积操作、实例归一化、Relu激活函数,卷积核为4,步长为2,卷积核数依次为64、128、256、256、256.
图 4

上下文感知注意力模块将最后1层卷积得到的特征图输入到自注意力网络( self attention, SA ),对特征图中的像素间结构建立联系,输出的新特征向量与原始特征进行像素加的操作,提高同一类别的紧凑性. 此时的特征图
为了增强特征图中不同区域的表征能力,自动感知上下文信息的特征权重,使用上下文向量
式中:
通过像素乘操作,使得网络学习不同的特征权重. 将上下文注意力特征聚合到每一个位置上,得到上下文注意力特征作用于特征图的结果. 为了保留更多的空间细节信息,与原始特征图通过像素加操作进行不同层次的特征融合,得到特征向量
解码器的输入只进行反卷积操作,中间每层卷积层的结构为Deconv-IN-Relu,Deconv表示反卷积,最后一层进行反卷积操作. 使用Tanh激活函数,解码器中的卷积核为4,步长为2,卷积核数依次为512、512、512、512、256、128、64、1.
考虑到生成的图像与内容编码器的输入图像的结构相似,解码器中使用跳跃连接,保留图像的不同尺度信息,将内容编码器中的不同特征层按照通道维度拼接到解码器对应的相同分辨率位置. 通过将底层信息连接到对应的解码器层,最大程度地保留图像的底层信息,减少解码过程中位置和结构特征信息的丢失.
2.2. 判别器的结构
在原始的zi2zi训练过程中,生成器与判别器的损失振荡比较明显,训练不稳定,判别器不能有效地指导生成器训练收敛. 在判别器中,将实例归一化替换为谱归一化层(spectral normalization,SN),解决生成对抗网络训练不稳定的问题,加快模型收敛.
判别器的网络结构如图2(b)所示,由5层卷积层组成. 前4层结构由Conv-SN-Lrelu单元堆叠而成,其中卷积核为4,步长依次是2、2、2、1,卷积核数依次是64、128、256、512;最后一层为卷积核为4、步长为1的卷积操作.
2.3. 损失函数的设计
zi2zi网络损失函数包括对抗损失、像素损失、类别损失与一致性损失. 利用改进的网络模型,增加了边缘损失,提高了生成字体轮廓的清晰度. 对抗损失函数使得模型的生成结果尽可能与目标风格书法字逼近. 在训练过程中,判别器
式中:
像素级损失函数采用
式中:
风格类别损失函数通过优化损失函数,使得生成汉字的类别一致.
式中:
内容一致损失通过对源图像和生成图像内容编码,计算两者一致性损失,避免信息丢失,使得解码器尽可能地恢复正确的汉字.
式中:
与字体图像的背景及填充字体图像的像素相比,汉字边缘像素在决定汉字风格和语义信息时占有较大的比重,因此额外引入边缘损失来约束模型,生成更加清晰的轮廓. 利用Canny算子提取边缘特征,用
式中:
最终生成器与判别器的目标损失函数如下所示:
式中:
3. 实验结果与分析
3.1. 实验环境
实验环境为Ubuntu 18.04 LTS 64-bit操作系统,显卡为NVIDIA RTX 3060,基于深度学习框架pytorch,编程语言为python3.8. 实验参数的设置如下:批处理大小batch size为16,迭代轮数为50,优化器为Adam优化器,参数
3.2. 数据集
针对手写体生成图像,目前没有公开的数据集. 本文的目标风格图像为颜真卿楷书及赵孟頫行书风格的书法字体图像,从书法图像字库中爬虫获取,源风格字体为黑体,使用python中的Imagefont转换为字符图像. 训练样本数开始设置为1 000,样本量较少导致过拟合;后面逐渐增加训练样本数,提升了模型性能,解决了过拟合的问题,且当数据量为3 000~4 000时模型性能稳定. 随机选择4 413张颜真卿楷书作为训练图像,1 004张颜真卿楷书作为测试图像. 赵孟頫行书的训练图像为3 861张,测试图像为1 060张. 训练图像与测试图像中的汉字字符各不相同,数据集的样例如图5所示. 在实验中,数据集采用单通道图像,大小均为256像素×256像素.
图 5

3.3. 评价指标
3.4. 实验结果与分析
为了验证提出方法的有效性,设计消融实验,分析不同模块对实验结果的影响. 为了进一步比较改进算法的生成效果,选择CycleGAN、DenseNet CycleGAN、zi2zi、EMD[20]、CalliGAN、LFFont、MXFont算法作为对比算法,比较不同算法的生成结果,验证不同源字体对改进算法生成效果的影响.
3.4.1. 消融实验
图 6

图 6 不同模块的消融实验(目标字体:颜真卿楷书)
Fig.6 Ablation experiments of different module (target font: Yan Zhenqing regular script)
图 7

图 7 不同模块的消融实验(目标字体:赵孟頫行书)
Fig.7 Ablation experiments of different module (target font: Zhao Mengfu running script)
表 2 消融实验的评价指标(目标字体:颜真卿楷书)
Tab.2
| 网络模型 | SSIM | PSNR/dB | LPIPS |
| zi2zi | 0.6975 | 9.3097 | 0.2383 |
| zi2zi+残差 | 0.7115 | 9.8567 | 0.2452 |
| zi2zi+残差+风格编码 | 0.7394 | 10.8484 | 0.1842 |
| zi2zi+残差+风格编码+边缘损失 | 0.7425 | 10.8228 | 0.1821 |
表 3 消融实验的评价指标(目标字体:赵孟頫行书)
Tab.3
| 网络模型 | SSIM | PSNR/dB | LPIPS |
| zi2zi | 0.6917 | 8.5425 | 0.2947 |
| zi2zi+残差 | 0.6918 | 8.4810 | 0.2845 |
| zi2zi+残差+风格编码 | 0.7607 | 10.8883 | 0.2177 |
| zi2zi+残差+风格编码+边缘损失 | 0.7665 | 10.9052 | 0.2152 |
从图6可以看出,zi2zi生成字体存在笔画不连贯缺失、粘连,如“仄”、“宗”字笔画缺失,后3个字出现笔画粘连. 加入残差单元,生成字体的细节明显有所改善,减少了字体笔画缺失、模糊不清的情况,能够有效地提高模型的性能. 比较3、4行有无风格编码的生成结果可以看出,添加风格编码使得生成字体的风格特征更加接近目标风格,如“仄”、“旬”字. 边缘损失的对比结果如第4、5行所示,未使用边缘损失的笔画轮廓扭曲,如“仄”字的笔画“捺”、“旬”字的笔画“撇”、“英”字的笔画“捺”等. 第5行生成字体的结构更加完整. 笔画线条显得“遒劲有力”,笔画位置的关系更加准确,更加符合书法艺术字的特点. 实验结果表明,本文算法的不同模块对于提高生成效果是至关重要的.
比较表2的实验结果,依次在原有模型上使用不同的结构,评价指标有所提高. 与原始zi2zi相比,SSIM、PSNR分别提升了4.50%、1.51 dB,LPIPS降低了5.62%,证明能够提高模型性能.
从图7可以看出,原始模型生成的书法字笔画较粗,字体风格与目标风格相差较大. 笔画结构的错误较多,如“印”字不连贯,“炸”字粘连,“元”字出现多余的笔画. 残差单元能够减少笔画缺失、错连,如“印”、“元”字. 对比3、4行可以发现,加入风格编码,能够明显地改善字体的风格. 从表3可知,SSIM、PSNR分别提升了6.89%、2.41 dB,LPIPS降低了6.68%. 对比第4、5行的结果可以看出,边缘损失进一步提升了字体结构轮廓,验证了边缘损失的有效性. 表3的结果表明,利用本文算法中的不同结构,能够提升各项指标,与原始zi2zi相比,SSIM、PSNR分别提升了7.48%、2.36 dB,LPIPS降低了7.95%,模型性能有所提升.
3.4.2. 与其他算法的对比实验
图 8

图 8 不同算法的生成结果(目标字体:颜真卿楷书)
Fig.8 Results generated by different algorithms (target font: Yan Zhenqing regular script)
图 9

图 9 不同算法的生成结果(目标字体:赵孟頫行书)
Fig.9 Results generated by different algorithms (target font: Zhao Mengfu running script)
图8中,CycleGAN和DenseNet CycleGAN算法的生成效果最差,完全没有学习到目标风格样式,甚至丢失字体的笔画结构,可读性差. 原始的zi2zi结构损坏,部分笔画存在扭曲的现象,同时笔画不连贯缺失,粘连的现象较严重. EMD方法具备内容编码与风格编码的结构设计,不同的是EMD在内容编码与风格编码时都只用普通的卷积结构去提取特征,生成的字体辨识度极低. CalliGAN生成的字体结构基本完整,可以学会目标字体的风格,但生成的字体图像模糊,产生较多的噪点,辨识度低,边缘结构不清晰. LFFont容易出现结构变形,如“用”、“胄”. MXFont生成的图像质量较高,但该模型的性能不稳定,部分字体结构丢失,如“崽”、“巡”. 利用本文算法缓解了笔画丢失的问题,生成的字体图像几乎没有变形,可读性高,字体的位置关系相对准确,分布一致,更加接近目标字体. 实验结果表明,本文算法的生成效果主观上优于其他7种算法.
与笔画较工整的楷书相比,行书字体形态丰富,书写更加灵活,结构更加不规则,因此生成任务更加困难. 图9中,CycleGAN和DenseNet CycleGAN生成的字体笔画丢失,辨识度低. 利用原始zi2zi算法生成的行书字体笔画粘连严重. EMD生成的字体难以辨认,丢失汉字结构和笔画细节的信息. CalliGAN生成的字体噪点较多,字体扭曲. LFFont容易出现结构丢失,如“圯”. MXFont生成的字体可识别性较高,但整体上笔画较粗,与目标风格字体有差距,利用本文算法生成的字体图像清晰,风格与目标字体最接近.
表 4 不同算法的评价指标(目标字体:颜真卿楷书)
Tab.4
| 算法 | SSIM | PSNR/dB | LPIPS |
| CycleGAN | 0.5492 | 7.2531 | 0.3300 |
| DenseNet CycleGAN | 0.4958 | 7.2698 | 0.3472 |
| zi2zi | 0.6728 | 9.0505 | 0.2289 |
| EMD | 0.5567 | 8.7037 | 0.3229 |
| CalliGAN | 0.6254 | 9.2908 | 0.2385 |
| LFFont | 0.6016 | 9.1077 | 0.2311 |
| MXFont | 0.6151 | 9.3029 | 0.2497 |
| 本文算法 | 0.7249 | 10.6253 | 0.1868 |
表 5 不同算法的评价指标(目标字体:赵孟頫行书)
Tab.5
| 算法 | SSIM | PSNR/dB | LPIPS |
| CycleGAN | 0.5617 | 7.1628 | 0.3712 |
| DenseNet CycleGAN | 0.5317 | 6.9037 | 0.3608 |
| zi2zi | 0.6348 | 7.7615 | 0.3223 |
| EMD | 0.5614 | 8.4337 | 0.3595 |
| CalliGAN | 0.5737 | 7.8590 | 0.3271 |
| LFFont | 0.5941 | 8.1400 | 0.3025 |
| MXFont | 0.6078 | 7.8666 | 0.3087 |
| 本文算法 | 0.7039 | 9.5221 | 0.2603 |
3.4.3. 不同源字体的生成结果
图 10

图 11

表 6 不同源字体生成目标字体的评价指标
Tab.6
| 源字体 | 目标字体 | SSIM | PSNR/dB | LPIPS |
| 楷体 | 楷书 | 0.7044 | 10.1207 | 0.1965 |
| 楷体 | 行书 | 0.6914 | 9.2937 | 0.2503 |
| 宋体 | 楷书 | 0.7153 | 10.4740 | 0.2042 |
| 宋体 | 行书 | 0.6971 | 9.5003 | 0.2495 |
3.4.4. 模型稳定性的分析
为了稳定模型训练,加速训练过程,在判别器中将实例归一化替换为谱归一化层. zi2zi算法与本文算法训练过程中的损失曲线变化如图12所示. 图中,
图 12

4. 结 语
本文提出基于改进生成对抗网络的书法字生成算法,有效提升了书法字的生成效果. 在网络结构设计中,以zi2zi为基础网络,通过设计编码器结构,增强了网络的特征提取能力;通过添加上下文感知注意力模块,显著提升了生成书法字的风格效果. 在模型训练中,设计损失函数进一步提升了生成字体的结构完整性,利用谱归一化增强了模型的训练稳定性. 通过自建2种不同书法字体的数据集,验证了本文算法的有效性. 实验结果表明,利用提出算法生成的字体细节清晰,结构完整,字体风格更加逼真,字体图像质量高. 利用本文方法生成的颜真卿楷书与赵孟頫行书的PSNR分别达到10.63、9.52 dB,SSIM分别达到0.724 9、0.703 9,LPIPS分别达到0.186 8、0.260 3,生成效果较对比算法有明显的提升. 本文算法生成的是单一风格字体,在接下来的研究工作中将优化模型,实现一对多风格的生成,增加模型的多样性.
参考文献
基于深度学习的中文字体风格转换研究综述
[J].
Review of Chinese font style conversion based on deep learning
[J].
基于田字格变换的自监督汉字字体生成
[J].
Self-supervised font generation of Chinese characters based on Tian Zige transformation
[J].
基于深度学习的汉字生成方法
[J].DOI:10.3778/j.issn.1002-8331.2103-0297 [本文引用: 1]
Chinese character generation method based on deep learning
[J].DOI:10.3778/j.issn.1002-8331.2103-0297 [本文引用: 1]
SAFont: automatic font synthesis using self-attention mechanisms
[J].
Image quality assessment: from error visibility to structural similarity
[J].DOI:10.1109/TIP.2003.819861 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}