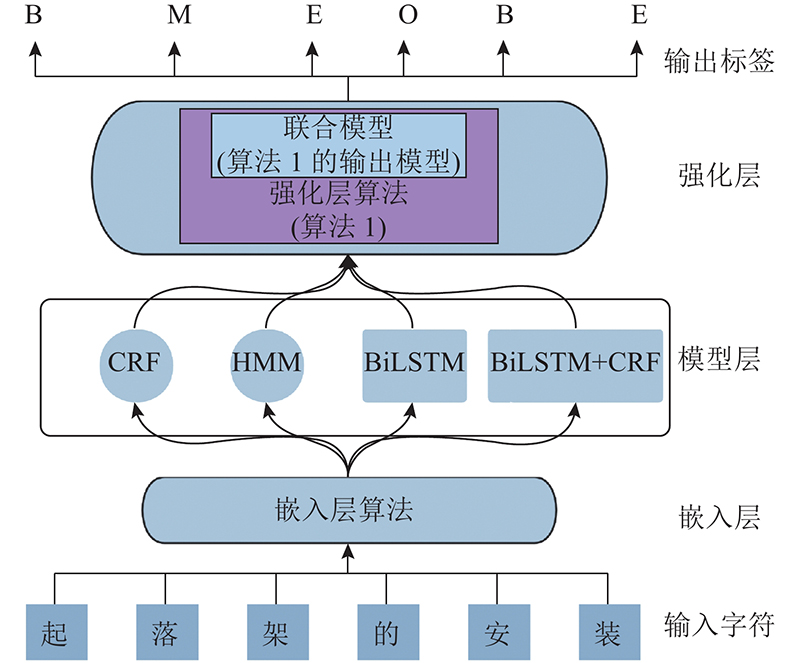
嵌入层完成文本的向量化. 本研究将字向量作为输入信号,即字向量 $ \boldsymbol{c}=[{ \boldsymbol{c}}_{1},\;{ \boldsymbol{c}}_{2},\;\cdots ,\;{ \boldsymbol{c}}_n] $ $ { \boldsymbol{c}}_i $ $ i $ n 为输入字的总个数. 字向量通过嵌入层后,得到字符向量 $ { \boldsymbol{x}}^{\mathrm{c}}= [{\boldsymbol{x}}_{1}^{\rm{c}}, \;{\boldsymbol{x}}_{2}^{\rm{c}},\;\cdots ,\;{\boldsymbol{x}}_n^{\rm{c}}] $ $ i $ $ { \boldsymbol{x}}_{ {i}}^{ {{\rm{c}}}} $
模型层是序列型标注模型集合,HMM是其中之一. 给定观测序列 $ \boldsymbol{x}={[ \boldsymbol{x}}_{1},\;{\boldsymbol{x}}_{2},\;\cdots,\;{\boldsymbol{x}}_{{n}}] $ $\boldsymbol{y}={[ \boldsymbol{y}}_{1},\;{\boldsymbol{y}}_{2},\;\cdots,\;{\boldsymbol{y}}_n]$ $ {P}\left( \boldsymbol{Y}| \boldsymbol{X}\right) $ $ {\boldsymbol{Y}}^{\mathrm{*}} $
(3) $\left. \begin{aligned} P\left( {{\boldsymbol{y|x}}} \right) = &\dfrac{1}{{Z{\boldsymbol{(x)}}}}{\rm{exp}}\left( {\sum\limits_{i,k} {{\lambda _k}{t_k}\left( {{{\boldsymbol{y}}_{i - 1}},{{\boldsymbol{y}}_i},{\boldsymbol{x}},i} \right)} + }\right.\\ &\left.{ \sum\limits_{i,l} {{\mu _l}{s_l}\left( {{{\boldsymbol{y}}_i},{\boldsymbol{x}},i} \right)} } \right) , \\ Z\left( {\boldsymbol{x}} \right) = &\sum\limits_{\boldsymbol{y}} {\rm{exp}}\left( {\sum\limits_{i,k} {{\lambda _k}{t_k}\left( {{{\boldsymbol{y}}_{i - 1}},{{\boldsymbol{y}}_i},{\boldsymbol{x}},i} \right)} + }\right.\\ &\left.{ \sum\limits_{i,l} {{\mu _l}{s_l}\left( {{{\boldsymbol{y}}_i},{\boldsymbol{x}},i} \right)} } \right). \end{aligned} \right\}$
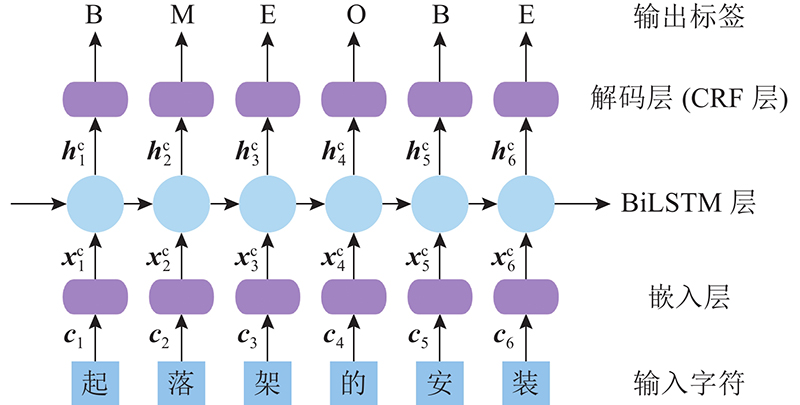
式中: $ {\boldsymbol{i}}_{j}^{{\rm{c}}} $ $ {\boldsymbol{f}}_{j}^{{\rm{c}}} $ $ {\boldsymbol{o}}_{j}^{{\rm{c}}} $ $ {{\text{W}}^{{\rm cT}}} $ $ {{\boldsymbol{b}}^{\rm{c}}} $ $ \sigma $ ${\boldsymbol{x}}^{\rm{c}}=[{\boldsymbol{x}}_{1}^{\rm{c}},\;{\boldsymbol{x}}_{2}^{\rm{c}},\;\cdots ,\;{\boldsymbol{x}}_n^{\rm{c}}]$ $\overrightarrow {\boldsymbol{h}^{\rm{c}}} = \left[ {\overrightarrow {{\boldsymbol{h}}_{\rm{1}}^{\rm{c}}} ,\;\overrightarrow {{\boldsymbol{h}}_{\rm{2}}^{\rm{c}}} ,\; \cdots, \overrightarrow {{\boldsymbol{h}}_n^{\rm{c}}} } \right]$ $\overleftarrow {{\boldsymbol{h}}^{\rm{c}}} = \left[ {\overleftarrow {{\boldsymbol{h}}_{\rm{1}}^{\rm{c}},}\; \overleftarrow {{\boldsymbol{h}}_{\rm{2}}^{\rm{c}}} ,\; \cdots ,\; \overleftarrow {{\boldsymbol{h}}_n^{\rm{c}}} } \right]$ . 每个字符的隐藏向量表示为
[1]
陈永佩, 杜震洪, 刘仁义, 等 一种引入实体的地理语义相似度混合计算模型
[J]. 浙江大学学报: 理学版 , 2018 , 45 (2 ): 196 - 204
[本文引用: 1]
CHEN Yong-pei, DU Zhen-hong, LIU Ren-yi, et al A hybrid geo-semantic similarity measurement model introducing geographic entities
[J]. Journal of Zhejiang University: Science Edition , 2018 , 45 (2 ): 196 - 204
[本文引用: 1]
[2]
陈善雄, 王小龙, 韩旭, 等 一种基于深度学习的古彝文识别方法
[J]. 浙江大学学报: 理学版 , 2019 , 46 (3 ): 261 - 269
[本文引用: 1]
CHEN Shan-xiong, WANG Xiao-long, HAN Xu, et al A recognition method of Ancient Yi character based on deep learning
[J]. Journal of Zhejiang University: Science Edition , 2019 , 46 (3 ): 261 - 269
[本文引用: 1]
[3]
张栋豪, 刘振宇, 郏维强, 等 知识图谱在智能制造领域的研究现状及其应用前景综述
[J]. 机械工程学报 , 2021 , 57 (5 ): 90 - 113
DOI:10.3901/JME.2021.05.090
[本文引用: 2]
ZHANG Dong-hao, LIU Zhen-yu, JIA Wei-qiang, et al A review on knowledge graph and its application prospects to intelligent manufacturing
[J]. Journal of Mechanical Engineering , 2021 , 57 (5 ): 90 - 113
DOI:10.3901/JME.2021.05.090
[本文引用: 2]
[4]
邱凌, 张安思, 李少波, 等 航空制造知识图谱构建研究综述
[J]. 计算机应用研究 , 2022 , 39 (4 ): 968 - 977
DOI:10.19734/j.issn.1001-3695.2021.09.0367
[本文引用: 3]
QIU Ling, ZHANG An-si, LI Shao-bo, et al Survey on building knowledge graphs for aerospace manufacturing
[J]. Application Research of Computers , 2022 , 39 (4 ): 968 - 977
DOI:10.19734/j.issn.1001-3695.2021.09.0367
[本文引用: 3]
[5]
徐增林, 盛泳潘, 贺丽荣, 等 知识图谱技术综述
[J]. 电子科技大学学报 , 2016 , 45 (4 ): 589 - 606
[本文引用: 1]
XU Zeng-lin, SHENG Yong-pan, HE Li-rong, et al Review on knowledge graph techniques
[J]. Journal of University of Electronic Science and Technology of China , 2016 , 45 (4 ): 589 - 606
[本文引用: 1]
[6]
杨贺羽. 基于深度学习的半监督式命名实体识别[D]. 沈阳: 沈阳工业大学, 2019.
[本文引用: 2]
YANG He-yu. Semi-supervised named entity recognition based on deep learning [D]. Shenyang: Shenyang University of Technology, 2019.
[本文引用: 2]
[7]
LI J, SUN A, HAN J, et al A survey on deep learning for named entity recognition
[J]. IEEE Transactions on Knowledge and Data Engineering , 2022 , 34 : 50 - 70
DOI:10.1109/TKDE.2020.2981314
[本文引用: 1]
[8]
RING M B. Child: a first stop towards continual learning [M]// THRUN S, PRATT L. Learning to learn . New York: Springer, 1998 : 261-292
[本文引用: 2]
[9]
LEVOW G. The third international Chinese language processing bakeoff: word segmentation and named entity recognition [C]// Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing . Sydney: Association for Computational Linguistics, 2006: 108-117.
[本文引用: 2]
[10]
OCKER F, PAREDIS C J J, VOGEL-HEUSER B Applying knowledge bases to make factories smarter
[J]. Automatisierungstechnik , 2019 , 67 (6 ): 504 - 517
DOI:10.1515/auto-2018-0138
[本文引用: 3]
[11]
肖勇, 郑楷洪, 王鑫, 等 基于联合神经网络学习的中文电力计量命名实体识别
[J]. 浙江大学学报: 理学版 , 2021 , 48 (3 ): 321 - 330
[本文引用: 1]
XIAO Yong, ZENG Kai-hong, WANG Xin, et al Chinese named entity recognition in electric power metering domain based on neural joint learning
[J]. Journal of Zhejiang University: Science Edition , 2021 , 48 (3 ): 321 - 330
[本文引用: 1]
[12]
CAMASTRA F, VINCIARELLI A. Markovian models for sequential data [M]// CAMASTRA F, VINCIARELLI A. Machine learning for audio, image and video analysis . London: Springer, 2008: 265-303.
[本文引用: 1]
[13]
SUTTON C, MCCALLUM A. An introduction to conditional random fields [EB/OL]. (2010-11-17). https://arxiv.org/pdf/1011.4088.pdf.
[本文引用: 2]
[14]
HAMMERTON J. Named entity recognition with long short-term memory [C]// Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003 . Stroudsburg: Association for Computational Linguistics, 2003: 172-175.
[本文引用: 2]
[15]
LAMPLE G, BALLESTEROS M, SUBRAMANIAN S, et al. Neural architectures for named entity recognition [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language . San Diego: Association for Computational Linguistics, 2016: 260–270.
[本文引用: 1]
[16]
CHEN A, PENG F, SHAN R, et al. Chinese named entity recognition with conditional probabilistic models [C]// Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing . Sydney: Association for Computational Linguistics, 2006: 173-176.
[本文引用: 1]
[17]
ZHOU J, QU W, FEN Z Chinese named entity recognition via joint identification and categorization
[J]. Chinese Journal of Electronics , 2013 , 22 (2 ): 225 - 230
[本文引用: 1]
[18]
ZHANG Y, WANG Y, YANG J Lattice LSTM for Chinese sentence representation
[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing , 2020 , 28 : 1506 - 1519
DOI:10.1109/TASLP.2020.2991544
[本文引用: 3]
[20]
《航空制造工程手册》总编委会. 航空制造工程手册: 飞机装配[M]. 北京: 航空工业出版社, 2010: 589–625.
[本文引用: 3]
[21]
NAKAYAMA H, KUBO T, KAMURA J, et al. Doccano: text annotation tool for human [CP/DK]. (2022-05-19). https://github.com/doccano/doccano.
[本文引用: 1]
[22]
PENG N, DREDZE M. Named entity recognition for Chinese social media with jointly trained embeddings [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing . Lisbon: Association for Computational Linguistics, 2015: 548–554.
[本文引用: 1]
[23]
彭春艳, 张晖, 包玲玉, 等 基于条件随机域的生物命名实体识别
[J]. 计算机工程 , 2009 , 35 (22 ): 197 - 199
DOI:10.3969/j.issn.1000-3428.2009.22.067
[本文引用: 1]
PENG Chun-yan, ZHANG Hui, BAO Ling-yu, et al Biological named entity recognition based on conditional random fields
[J]. Computer Engineering , 2009 , 35 (22 ): 197 - 199
DOI:10.3969/j.issn.1000-3428.2009.22.067
[本文引用: 1]
一种引入实体的地理语义相似度混合计算模型
1
2018
... 随着新一代人工智能技术的发展,从自然语言 中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题成为研究热点[1 -2 ] . 智能制造对制造大数据蕴含的知识和数据的关联分析能力的要求越来越高. 知识和数据是新一代信息技术与智能制造深度融合的基础[3 ] . 研究航空制造领域的知识图谱具有重要的理论意义和实用价值[4 ] . 在航空制造领域,航空装配是核心关键技术之一,它对装配工程人员的专业知识和专业能力要求很高. 如何在装配过程中为工程人员提供更全面、有效的知识支持工具和辅助决策工具,在提高装配效率的同时降低装配出错率?为此,研究者提出构建航空装配知识图谱. ...
一种引入实体的地理语义相似度混合计算模型
1
2018
... 随着新一代人工智能技术的发展,从自然语言 中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题成为研究热点[1 -2 ] . 智能制造对制造大数据蕴含的知识和数据的关联分析能力的要求越来越高. 知识和数据是新一代信息技术与智能制造深度融合的基础[3 ] . 研究航空制造领域的知识图谱具有重要的理论意义和实用价值[4 ] . 在航空制造领域,航空装配是核心关键技术之一,它对装配工程人员的专业知识和专业能力要求很高. 如何在装配过程中为工程人员提供更全面、有效的知识支持工具和辅助决策工具,在提高装配效率的同时降低装配出错率?为此,研究者提出构建航空装配知识图谱. ...
一种基于深度学习的古彝文识别方法
1
2019
... 随着新一代人工智能技术的发展,从自然语言 中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题成为研究热点[1 -2 ] . 智能制造对制造大数据蕴含的知识和数据的关联分析能力的要求越来越高. 知识和数据是新一代信息技术与智能制造深度融合的基础[3 ] . 研究航空制造领域的知识图谱具有重要的理论意义和实用价值[4 ] . 在航空制造领域,航空装配是核心关键技术之一,它对装配工程人员的专业知识和专业能力要求很高. 如何在装配过程中为工程人员提供更全面、有效的知识支持工具和辅助决策工具,在提高装配效率的同时降低装配出错率?为此,研究者提出构建航空装配知识图谱. ...
一种基于深度学习的古彝文识别方法
1
2019
... 随着新一代人工智能技术的发展,从自然语言 中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题成为研究热点[1 -2 ] . 智能制造对制造大数据蕴含的知识和数据的关联分析能力的要求越来越高. 知识和数据是新一代信息技术与智能制造深度融合的基础[3 ] . 研究航空制造领域的知识图谱具有重要的理论意义和实用价值[4 ] . 在航空制造领域,航空装配是核心关键技术之一,它对装配工程人员的专业知识和专业能力要求很高. 如何在装配过程中为工程人员提供更全面、有效的知识支持工具和辅助决策工具,在提高装配效率的同时降低装配出错率?为此,研究者提出构建航空装配知识图谱. ...
知识图谱在智能制造领域的研究现状及其应用前景综述
2
2021
... 随着新一代人工智能技术的发展,从自然语言 中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题成为研究热点[1 -2 ] . 智能制造对制造大数据蕴含的知识和数据的关联分析能力的要求越来越高. 知识和数据是新一代信息技术与智能制造深度融合的基础[3 ] . 研究航空制造领域的知识图谱具有重要的理论意义和实用价值[4 ] . 在航空制造领域,航空装配是核心关键技术之一,它对装配工程人员的专业知识和专业能力要求很高. 如何在装配过程中为工程人员提供更全面、有效的知识支持工具和辅助决策工具,在提高装配效率的同时降低装配出错率?为此,研究者提出构建航空装配知识图谱. ...
... 在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
知识图谱在智能制造领域的研究现状及其应用前景综述
2
2021
... 随着新一代人工智能技术的发展,从自然语言 中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题成为研究热点[1 -2 ] . 智能制造对制造大数据蕴含的知识和数据的关联分析能力的要求越来越高. 知识和数据是新一代信息技术与智能制造深度融合的基础[3 ] . 研究航空制造领域的知识图谱具有重要的理论意义和实用价值[4 ] . 在航空制造领域,航空装配是核心关键技术之一,它对装配工程人员的专业知识和专业能力要求很高. 如何在装配过程中为工程人员提供更全面、有效的知识支持工具和辅助决策工具,在提高装配效率的同时降低装配出错率?为此,研究者提出构建航空装配知识图谱. ...
... 在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
航空制造知识图谱构建研究综述
3
2022
... 随着新一代人工智能技术的发展,从自然语言 中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题成为研究热点[1 -2 ] . 智能制造对制造大数据蕴含的知识和数据的关联分析能力的要求越来越高. 知识和数据是新一代信息技术与智能制造深度融合的基础[3 ] . 研究航空制造领域的知识图谱具有重要的理论意义和实用价值[4 ] . 在航空制造领域,航空装配是核心关键技术之一,它对装配工程人员的专业知识和专业能力要求很高. 如何在装配过程中为工程人员提供更全面、有效的知识支持工具和辅助决策工具,在提高装配效率的同时降低装配出错率?为此,研究者提出构建航空装配知识图谱. ...
... 知识图谱(knowledge graph, KG)来源于谷歌下一代智能语义搜索引擎技术[5 ] . 构建知识图谱的关键基础技术之一是命名实体识别技术(named entity recognition,NER),该技术可以分为基于词典与规则的方法、基于统计模型的方法和基于深度学习的方法3种类型[6 ] . 在知识图谱通用领域积累的语料多且构建经验丰富,其主流方法是基于深度学习的方法,通过神经网络实现端到端的NER[7 ] . 领域知识图谱的架构须考虑目标领域特有因素[4 ] ,尤其是当进入新的领域(如航空装配知识图谱)时,往往面临结构化语料不足,技术路径不清晰,领域知识图谱结构缺乏统一标准等问题. ...
... 在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
航空制造知识图谱构建研究综述
3
2022
... 随着新一代人工智能技术的发展,从自然语言 中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题成为研究热点[1 -2 ] . 智能制造对制造大数据蕴含的知识和数据的关联分析能力的要求越来越高. 知识和数据是新一代信息技术与智能制造深度融合的基础[3 ] . 研究航空制造领域的知识图谱具有重要的理论意义和实用价值[4 ] . 在航空制造领域,航空装配是核心关键技术之一,它对装配工程人员的专业知识和专业能力要求很高. 如何在装配过程中为工程人员提供更全面、有效的知识支持工具和辅助决策工具,在提高装配效率的同时降低装配出错率?为此,研究者提出构建航空装配知识图谱. ...
... 知识图谱(knowledge graph, KG)来源于谷歌下一代智能语义搜索引擎技术[5 ] . 构建知识图谱的关键基础技术之一是命名实体识别技术(named entity recognition,NER),该技术可以分为基于词典与规则的方法、基于统计模型的方法和基于深度学习的方法3种类型[6 ] . 在知识图谱通用领域积累的语料多且构建经验丰富,其主流方法是基于深度学习的方法,通过神经网络实现端到端的NER[7 ] . 领域知识图谱的架构须考虑目标领域特有因素[4 ] ,尤其是当进入新的领域(如航空装配知识图谱)时,往往面临结构化语料不足,技术路径不清晰,领域知识图谱结构缺乏统一标准等问题. ...
... 在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
知识图谱技术综述
1
2016
... 知识图谱(knowledge graph, KG)来源于谷歌下一代智能语义搜索引擎技术[5 ] . 构建知识图谱的关键基础技术之一是命名实体识别技术(named entity recognition,NER),该技术可以分为基于词典与规则的方法、基于统计模型的方法和基于深度学习的方法3种类型[6 ] . 在知识图谱通用领域积累的语料多且构建经验丰富,其主流方法是基于深度学习的方法,通过神经网络实现端到端的NER[7 ] . 领域知识图谱的架构须考虑目标领域特有因素[4 ] ,尤其是当进入新的领域(如航空装配知识图谱)时,往往面临结构化语料不足,技术路径不清晰,领域知识图谱结构缺乏统一标准等问题. ...
知识图谱技术综述
1
2016
... 知识图谱(knowledge graph, KG)来源于谷歌下一代智能语义搜索引擎技术[5 ] . 构建知识图谱的关键基础技术之一是命名实体识别技术(named entity recognition,NER),该技术可以分为基于词典与规则的方法、基于统计模型的方法和基于深度学习的方法3种类型[6 ] . 在知识图谱通用领域积累的语料多且构建经验丰富,其主流方法是基于深度学习的方法,通过神经网络实现端到端的NER[7 ] . 领域知识图谱的架构须考虑目标领域特有因素[4 ] ,尤其是当进入新的领域(如航空装配知识图谱)时,往往面临结构化语料不足,技术路径不清晰,领域知识图谱结构缺乏统一标准等问题. ...
2
... 知识图谱(knowledge graph, KG)来源于谷歌下一代智能语义搜索引擎技术[5 ] . 构建知识图谱的关键基础技术之一是命名实体识别技术(named entity recognition,NER),该技术可以分为基于词典与规则的方法、基于统计模型的方法和基于深度学习的方法3种类型[6 ] . 在知识图谱通用领域积累的语料多且构建经验丰富,其主流方法是基于深度学习的方法,通过神经网络实现端到端的NER[7 ] . 领域知识图谱的架构须考虑目标领域特有因素[4 ] ,尤其是当进入新的领域(如航空装配知识图谱)时,往往面临结构化语料不足,技术路径不清晰,领域知识图谱结构缺乏统一标准等问题. ...
... 命名实体识别任务可以被视为序列型标注任务. 在工业领域,基于词典与规则的方法应用效果较早取得良好的命名实体识别效果,但该方法依赖于人工设定的特征,使得研发和维护成本增加[6 ] . 基于词典与规则的方法在很多联合学习算法中依然被使用,如肖勇等[11 ] 提出的联合学习算法. 该方法除了需要大量人工来维护和更新相关字典外,还无法识别集外词. 基于统计算法的模型是成熟的序列型标注问题的处理方法之一,如基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)[12 ] 与条件随机场(conditional random field,CRF)[13 ] ,这2种模型都是在线性统计模型的基础上发展而来的. Sutton等[13 ] 根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
2
... 知识图谱(knowledge graph, KG)来源于谷歌下一代智能语义搜索引擎技术[5 ] . 构建知识图谱的关键基础技术之一是命名实体识别技术(named entity recognition,NER),该技术可以分为基于词典与规则的方法、基于统计模型的方法和基于深度学习的方法3种类型[6 ] . 在知识图谱通用领域积累的语料多且构建经验丰富,其主流方法是基于深度学习的方法,通过神经网络实现端到端的NER[7 ] . 领域知识图谱的架构须考虑目标领域特有因素[4 ] ,尤其是当进入新的领域(如航空装配知识图谱)时,往往面临结构化语料不足,技术路径不清晰,领域知识图谱结构缺乏统一标准等问题. ...
... 命名实体识别任务可以被视为序列型标注任务. 在工业领域,基于词典与规则的方法应用效果较早取得良好的命名实体识别效果,但该方法依赖于人工设定的特征,使得研发和维护成本增加[6 ] . 基于词典与规则的方法在很多联合学习算法中依然被使用,如肖勇等[11 ] 提出的联合学习算法. 该方法除了需要大量人工来维护和更新相关字典外,还无法识别集外词. 基于统计算法的模型是成熟的序列型标注问题的处理方法之一,如基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)[12 ] 与条件随机场(conditional random field,CRF)[13 ] ,这2种模型都是在线性统计模型的基础上发展而来的. Sutton等[13 ] 根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
A survey on deep learning for named entity recognition
1
2022
... 知识图谱(knowledge graph, KG)来源于谷歌下一代智能语义搜索引擎技术[5 ] . 构建知识图谱的关键基础技术之一是命名实体识别技术(named entity recognition,NER),该技术可以分为基于词典与规则的方法、基于统计模型的方法和基于深度学习的方法3种类型[6 ] . 在知识图谱通用领域积累的语料多且构建经验丰富,其主流方法是基于深度学习的方法,通过神经网络实现端到端的NER[7 ] . 领域知识图谱的架构须考虑目标领域特有因素[4 ] ,尤其是当进入新的领域(如航空装配知识图谱)时,往往面临结构化语料不足,技术路径不清晰,领域知识图谱结构缺乏统一标准等问题. ...
2
... 受持续学习[8 ] 思想的启发,本研究提出基于持续学习的命名实体识别技术框架. 该框架的目的是联合统计模型和深度学习模型,使联合模型可以共享实体类别,通过并行计算,自动决策在不同语料环境下识别效果更优的模型. 本文的研究思路是1)构建基于持续学习的命名实体识别技术框架,并通过在公开语料库(微软亚洲研究院标注并公布的MSRA[9 ] 语料库)上进行的实验,验证持续学习模型在不依赖人工设定特征的情况下,从零语料到大规模语料渐进式学习过程中的有效性. 2)结合航空装配领域专家的业务知识,通过复用已有相关领域知识库的本体共识[10 ] ,建立航空装配领域实体分类的规则. 3)通过从总装配和部件对接的实际场景展开的实验,证明所提框架的优异性. 4)以操纵拉杆和钢索的安装为具体实验案例,证明所提框架可以在航空装配领域实际场景的海量数据中提取核心价值数据. ...
... 在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
2
... 受持续学习[8 ] 思想的启发,本研究提出基于持续学习的命名实体识别技术框架. 该框架的目的是联合统计模型和深度学习模型,使联合模型可以共享实体类别,通过并行计算,自动决策在不同语料环境下识别效果更优的模型. 本文的研究思路是1)构建基于持续学习的命名实体识别技术框架,并通过在公开语料库(微软亚洲研究院标注并公布的MSRA[9 ] 语料库)上进行的实验,验证持续学习模型在不依赖人工设定特征的情况下,从零语料到大规模语料渐进式学习过程中的有效性. 2)结合航空装配领域专家的业务知识,通过复用已有相关领域知识库的本体共识[10 ] ,建立航空装配领域实体分类的规则. 3)通过从总装配和部件对接的实际场景展开的实验,证明所提框架的优异性. 4)以操纵拉杆和钢索的安装为具体实验案例,证明所提框架可以在航空装配领域实际场景的海量数据中提取核心价值数据. ...
... 通用领域的语料库丰富,维基百科开放了TB级别的语料. 相对通用语料库,领域语料库需要概念性的知识,还需要能够体现更为深层次关系的数据语料,须单独收集和标注. 一些专业领域已经有规模化、标准化的公开语料库,如微软亚洲研究院公布的新闻语料库[9 ] 、媒体社交语料库[22 ] 和人才简历语料库[18 ] ;也有一些领域的语料库非公开但相对成熟,如医学生物领域、国防军事领域和电力领域. 本研究构建的航空装配语料库中测试集实体字符占所有字符的32.15%,比通用语料库MSRA实体比例16.11%高. 航空装配领域语料库的特点如下:1)语料数量少;2)语料专业度高;3)噪声内容少,实体比例高;4)语料中命名实体边界模糊. 与通用语料库相比,航空装配语料库对命名实体识别的要求更高. ...
Applying knowledge bases to make factories smarter
3
2019
... 受持续学习[8 ] 思想的启发,本研究提出基于持续学习的命名实体识别技术框架. 该框架的目的是联合统计模型和深度学习模型,使联合模型可以共享实体类别,通过并行计算,自动决策在不同语料环境下识别效果更优的模型. 本文的研究思路是1)构建基于持续学习的命名实体识别技术框架,并通过在公开语料库(微软亚洲研究院标注并公布的MSRA[9 ] 语料库)上进行的实验,验证持续学习模型在不依赖人工设定特征的情况下,从零语料到大规模语料渐进式学习过程中的有效性. 2)结合航空装配领域专家的业务知识,通过复用已有相关领域知识库的本体共识[10 ] ,建立航空装配领域实体分类的规则. 3)通过从总装配和部件对接的实际场景展开的实验,证明所提框架的优异性. 4)以操纵拉杆和钢索的安装为具体实验案例,证明所提框架可以在航空装配领域实际场景的海量数据中提取核心价值数据. ...
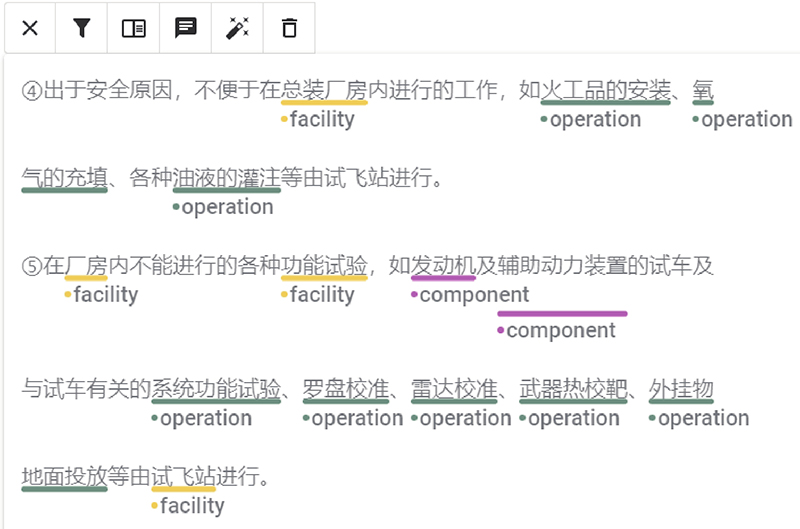
... 结合航空装配领域专家知识和相关书籍、文献资料,通过复用已有相关领域知识库的本体共识[10 ] , 在考虑中英文的差距后,将实体术语分为5类:定义组件实体(component)、固定设施实体(facility)、操作项目实体(operation)、工序步骤实体(step)和工具实体(tool). 这5类实体对应的本体(航空装配本体)与现有相关领域知识库的本体的对应关系如表2 所示. 中间介质工程本体(Intermediate Engineering Ontology, IEO)[10 ] 弥合了顶级本体(top-level ontologies)与现有领域知识库间的差距,为本研究复用已有相关领域知识库的本体共识的基础. 5类航空装配领域实体的具体描述如下:1)定义组成飞机的部件为组件实体,如“发动机”、“起落架”,组件实体示例如图1 所示;2)定义飞机组装过程中相对应的固定设施为固定设施实体,如“停机坪”、“主厂房”;3)定义人工操作的项目为操作项目实体,如“雷达校准”、“系统密封性实验”;4)定义飞机装配实际工序为工序步骤实体,如“总装配”、“部件装配”;5)定义装配过程中使用的具体工具为工具实体,如“千斤顶”、“动力保障设施”. 该实体分类方法,可以通过5个维度,具体重现装配实施细节,即时间(工序步骤实体)、地点(固定设施实体)、人工(操作项目实体)、工具(工具实体)和操作对象(组件实体). 在此基础上组成的知识图谱,可以完整还原装配知识的细节和逻辑关系,即在什么时间、什么地点、用什么工具、对什么部件、做什么. ...
... [10 ]弥合了顶级本体(top-level ontologies)与现有领域知识库间的差距,为本研究复用已有相关领域知识库的本体共识的基础. 5类航空装配领域实体的具体描述如下:1)定义组成飞机的部件为组件实体,如“发动机”、“起落架”,组件实体示例如图1 所示;2)定义飞机组装过程中相对应的固定设施为固定设施实体,如“停机坪”、“主厂房”;3)定义人工操作的项目为操作项目实体,如“雷达校准”、“系统密封性实验”;4)定义飞机装配实际工序为工序步骤实体,如“总装配”、“部件装配”;5)定义装配过程中使用的具体工具为工具实体,如“千斤顶”、“动力保障设施”. 该实体分类方法,可以通过5个维度,具体重现装配实施细节,即时间(工序步骤实体)、地点(固定设施实体)、人工(操作项目实体)、工具(工具实体)和操作对象(组件实体). 在此基础上组成的知识图谱,可以完整还原装配知识的细节和逻辑关系,即在什么时间、什么地点、用什么工具、对什么部件、做什么. ...
基于联合神经网络学习的中文电力计量命名实体识别
1
2021
... 命名实体识别任务可以被视为序列型标注任务. 在工业领域,基于词典与规则的方法应用效果较早取得良好的命名实体识别效果,但该方法依赖于人工设定的特征,使得研发和维护成本增加[6 ] . 基于词典与规则的方法在很多联合学习算法中依然被使用,如肖勇等[11 ] 提出的联合学习算法. 该方法除了需要大量人工来维护和更新相关字典外,还无法识别集外词. 基于统计算法的模型是成熟的序列型标注问题的处理方法之一,如基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)[12 ] 与条件随机场(conditional random field,CRF)[13 ] ,这2种模型都是在线性统计模型的基础上发展而来的. Sutton等[13 ] 根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
基于联合神经网络学习的中文电力计量命名实体识别
1
2021
... 命名实体识别任务可以被视为序列型标注任务. 在工业领域,基于词典与规则的方法应用效果较早取得良好的命名实体识别效果,但该方法依赖于人工设定的特征,使得研发和维护成本增加[6 ] . 基于词典与规则的方法在很多联合学习算法中依然被使用,如肖勇等[11 ] 提出的联合学习算法. 该方法除了需要大量人工来维护和更新相关字典外,还无法识别集外词. 基于统计算法的模型是成熟的序列型标注问题的处理方法之一,如基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)[12 ] 与条件随机场(conditional random field,CRF)[13 ] ,这2种模型都是在线性统计模型的基础上发展而来的. Sutton等[13 ] 根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
1
... 命名实体识别任务可以被视为序列型标注任务. 在工业领域,基于词典与规则的方法应用效果较早取得良好的命名实体识别效果,但该方法依赖于人工设定的特征,使得研发和维护成本增加[6 ] . 基于词典与规则的方法在很多联合学习算法中依然被使用,如肖勇等[11 ] 提出的联合学习算法. 该方法除了需要大量人工来维护和更新相关字典外,还无法识别集外词. 基于统计算法的模型是成熟的序列型标注问题的处理方法之一,如基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)[12 ] 与条件随机场(conditional random field,CRF)[13 ] ,这2种模型都是在线性统计模型的基础上发展而来的. Sutton等[13 ] 根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
2
... 命名实体识别任务可以被视为序列型标注任务. 在工业领域,基于词典与规则的方法应用效果较早取得良好的命名实体识别效果,但该方法依赖于人工设定的特征,使得研发和维护成本增加[6 ] . 基于词典与规则的方法在很多联合学习算法中依然被使用,如肖勇等[11 ] 提出的联合学习算法. 该方法除了需要大量人工来维护和更新相关字典外,还无法识别集外词. 基于统计算法的模型是成熟的序列型标注问题的处理方法之一,如基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)[12 ] 与条件随机场(conditional random field,CRF)[13 ] ,这2种模型都是在线性统计模型的基础上发展而来的. Sutton等[13 ] 根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
... [13 ]根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
2
... 命名实体识别任务可以被视为序列型标注任务. 在工业领域,基于词典与规则的方法应用效果较早取得良好的命名实体识别效果,但该方法依赖于人工设定的特征,使得研发和维护成本增加[6 ] . 基于词典与规则的方法在很多联合学习算法中依然被使用,如肖勇等[11 ] 提出的联合学习算法. 该方法除了需要大量人工来维护和更新相关字典外,还无法识别集外词. 基于统计算法的模型是成熟的序列型标注问题的处理方法之一,如基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)[12 ] 与条件随机场(conditional random field,CRF)[13 ] ,这2种模型都是在线性统计模型的基础上发展而来的. Sutton等[13 ] 根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
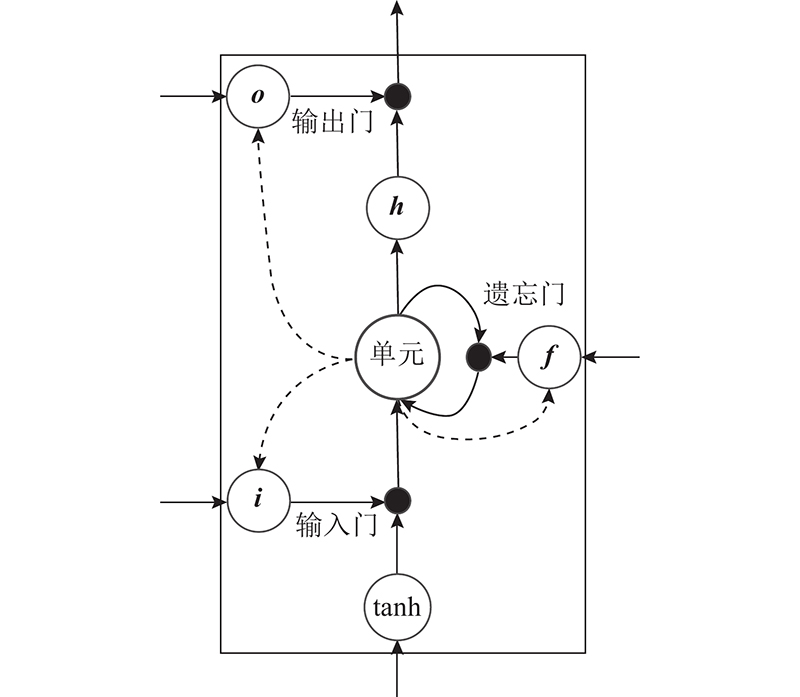
... LSTM是特殊的RNN,弥补了传统 RNN的不足,可以在捕获长距离序列信息的同时遗忘无关信息,适用于NER任务. 如图4 所示为LSTM单元的基本结构,通常 LSTM 单元包含遗忘门、输入门和输出门,这些门控制信息遗忘和传递给下一时间步骤的信息比例[14 ] . LSTM函数表达式为 ...
1
... 命名实体识别任务可以被视为序列型标注任务. 在工业领域,基于词典与规则的方法应用效果较早取得良好的命名实体识别效果,但该方法依赖于人工设定的特征,使得研发和维护成本增加[6 ] . 基于词典与规则的方法在很多联合学习算法中依然被使用,如肖勇等[11 ] 提出的联合学习算法. 该方法除了需要大量人工来维护和更新相关字典外,还无法识别集外词. 基于统计算法的模型是成熟的序列型标注问题的处理方法之一,如基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)[12 ] 与条件随机场(conditional random field,CRF)[13 ] ,这2种模型都是在线性统计模型的基础上发展而来的. Sutton等[13 ] 根据标注语料,用最大似然法(maximum likelihood estimate)设定模型的参数和特征. 基于统计算法的模型不再依赖人工设定参数和特征,可以有效适应新任务和新领域. 深度学习算法在NER领域的应用取得丰富的成果. Hammerton[14 ] 提出的基于单向长短期记忆神经网络(long-short term memory,LSTM)的NER模型,将深度学习与NER任务结合起来. Lample等[15 ] 提出的基于双向长短期记忆神经网络(bidirectional long-short term memory,BiLSTM)结合CRF层的NER模型,在大多数命名实体识别任务中可以提升F1值,从此BiLSTM-CRF模型成为NER任务中核心模型之一. 如表1 所示为具有代表性的NER模型在MSRA语料集上的实验结果. 表中,P 为准确率,R 为召回率,F1为F1值. ...
1
... Experimental results of named entity recognition models on MSRA corpus
Tab.1 模型 P /% R /% F1/% CRF(2006)[16 ] 91.22 81.71 86.20 CRF(2013)[17 ] 91.86 88.75 90.28 BiLSTM+CRF[18 ] 92.97 90.80 91.87 Lattice LSTM[18 ] 93.57 92.79 93.18 BERT-BiGRU-CRF[19 ] 95.31 95.54 95.43
在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
Chinese named entity recognition via joint identification and categorization
1
2013
... Experimental results of named entity recognition models on MSRA corpus
Tab.1 模型 P /% R /% F1/% CRF(2006)[16 ] 91.22 81.71 86.20 CRF(2013)[17 ] 91.86 88.75 90.28 BiLSTM+CRF[18 ] 92.97 90.80 91.87 Lattice LSTM[18 ] 93.57 92.79 93.18 BERT-BiGRU-CRF[19 ] 95.31 95.54 95.43
在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
Lattice LSTM for Chinese sentence representation
3
2020
... Experimental results of named entity recognition models on MSRA corpus
Tab.1 模型 P /% R /% F1/% CRF(2006)[16 ] 91.22 81.71 86.20 CRF(2013)[17 ] 91.86 88.75 90.28 BiLSTM+CRF[18 ] 92.97 90.80 91.87 Lattice LSTM[18 ] 93.57 92.79 93.18 BERT-BiGRU-CRF[19 ] 95.31 95.54 95.43
在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
... [
18 ]
93.57 92.79 93.18 BERT-BiGRU-CRF[19 ] 95.31 95.54 95.43 在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
... 通用领域的语料库丰富,维基百科开放了TB级别的语料. 相对通用语料库,领域语料库需要概念性的知识,还需要能够体现更为深层次关系的数据语料,须单独收集和标注. 一些专业领域已经有规模化、标准化的公开语料库,如微软亚洲研究院公布的新闻语料库[9 ] 、媒体社交语料库[22 ] 和人才简历语料库[18 ] ;也有一些领域的语料库非公开但相对成熟,如医学生物领域、国防军事领域和电力领域. 本研究构建的航空装配语料库中测试集实体字符占所有字符的32.15%,比通用语料库MSRA实体比例16.11%高. 航空装配领域语料库的特点如下:1)语料数量少;2)语料专业度高;3)噪声内容少,实体比例高;4)语料中命名实体边界模糊. 与通用语料库相比,航空装配语料库对命名实体识别的要求更高. ...
基于BERT嵌入的中文命名实体识别方法
1
2020
... Experimental results of named entity recognition models on MSRA corpus
Tab.1 模型 P /% R /% F1/% CRF(2006)[16 ] 91.22 81.71 86.20 CRF(2013)[17 ] 91.86 88.75 90.28 BiLSTM+CRF[18 ] 92.97 90.80 91.87 Lattice LSTM[18 ] 93.57 92.79 93.18 BERT-BiGRU-CRF[19 ] 95.31 95.54 95.43
在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
基于BERT嵌入的中文命名实体识别方法
1
2020
... Experimental results of named entity recognition models on MSRA corpus
Tab.1 模型 P /% R /% F1/% CRF(2006)[16 ] 91.22 81.71 86.20 CRF(2013)[17 ] 91.86 88.75 90.28 BiLSTM+CRF[18 ] 92.97 90.80 91.87 Lattice LSTM[18 ] 93.57 92.79 93.18 BERT-BiGRU-CRF[19 ] 95.31 95.54 95.43
在智能制造和航空制造领域,张栋豪等[3 -4 ] 提供了领域知识图谱构建的综述性技术方案与可行技术路线,其中NER为构建知识图谱的核心任务. 航空装配领域的NER是新领域,面临少语料甚至零语料的挑战. 持续学习的思想给新领域NER任务提供了技术路径. Ring[8 ] 在观察儿童学习知识并将知识运用在新领域后,提出持续学习的概念:持续学习是基于复杂环境与行为进行不断学习的过程,它可以在学得技能之上建立更复杂技能. 由此可知,持续学习架构为模型提供的应该是渐进的(continual)、有层次的(hierarchical)和不断进步的(incremental)学习能力. 持续学习(continual learning)是强化学习(reinforcement learning)的进一步推广,其允许使用已经训练好的模型,当遇到新的环境或任务时,通过对效果评估给予奖励,让模型进化后适合更加复杂的任务. 基于持续学习的思想,本研究构建的框架满足以下特点:1)具备主动学习的能力,能够感知环境变化(语料数量变化),能够对周围环境中的奖励(比上次训练获得更高的F1值)做出反应. 2)学习过程是渐进式的,系统能够在解决问题的同时进行学习;训练集不固定,学习发生在各个时间段,现在学习的技能可以在以后使用. 3)学习过程也是分层式的. 现在学习的技能可以在稍后进行修改甚至重新建立. 4)技能具有“黑盒”特性. 技能内部结构不需要被理解或操作,即不依赖人工设定特征,与现实世界有且只有一个人机交互界面,通过该界面技能系统可以完成任务并得到奖励. ...
3
... 本研究的应用数据来自文献[20 ],该文献供从事飞机装配工作的工艺人员和飞机工程设计工作的设计人员使用,具备极高的专业度和可信度. 本研究对文献[20 ]中篇名为“飞机总装配与调试”的内容进行标注;将章名为“总装配工艺流程设计”的内容作为总装配的语料数据来源,章名为“部件对接”的内容作为部件对接的语料数据来源,章名为“操纵拉杆和钢索的安装”的内容作为具体装配场景中实验用例的语料数据来源. 标注步骤为1)对文献[20 ]相应章节进行光学字符识别(optical character recognition,OCR);2)进行清洗数据,剔除图片和表格;3)将语料输入二次开发的人机交互工具进行实体标注. ...
... ],该文献供从事飞机装配工作的工艺人员和飞机工程设计工作的设计人员使用,具备极高的专业度和可信度. 本研究对文献[20 ]中篇名为“飞机总装配与调试”的内容进行标注;将章名为“总装配工艺流程设计”的内容作为总装配的语料数据来源,章名为“部件对接”的内容作为部件对接的语料数据来源,章名为“操纵拉杆和钢索的安装”的内容作为具体装配场景中实验用例的语料数据来源. 标注步骤为1)对文献[20 ]相应章节进行光学字符识别(optical character recognition,OCR);2)进行清洗数据,剔除图片和表格;3)将语料输入二次开发的人机交互工具进行实体标注. ...
... ]中篇名为“飞机总装配与调试”的内容进行标注;将章名为“总装配工艺流程设计”的内容作为总装配的语料数据来源,章名为“部件对接”的内容作为部件对接的语料数据来源,章名为“操纵拉杆和钢索的安装”的内容作为具体装配场景中实验用例的语料数据来源. 标注步骤为1)对文献[20 ]相应章节进行光学字符识别(optical character recognition,OCR);2)进行清洗数据,剔除图片和表格;3)将语料输入二次开发的人机交互工具进行实体标注. ...
1
... 在航空装配领域专家的指导下,使用BMEO标记方案进行基于字符的NER标记:B为实体的开始字符,M为实体的中间字符,E为实体的结束字符,O为非命名实体的字符. 如图2 所示,本研究在Doccano[21 ] 文本标注工具的基础上,二次开发出更适合渐进式持续学习任务的人机交互工具. 二次开发的核心目的是使人机交互工具利用已经训练好的模型,预先进行实体标注,将标注任务转化为审阅任务. 该工具可以大幅度提高标注效率、显著降低人工误差,直观展示标注结果. 本研究标注字符14 430个,包含空格和标点符号,其中包括总装配和部件对接部分的语料库AA-1(10 640个字符)、操纵拉杆和钢索的安装案例语料库AA-2(3 790个字符). 语料库实体数量n ce 统计如表3 所示. ...
1
... 通用领域的语料库丰富,维基百科开放了TB级别的语料. 相对通用语料库,领域语料库需要概念性的知识,还需要能够体现更为深层次关系的数据语料,须单独收集和标注. 一些专业领域已经有规模化、标准化的公开语料库,如微软亚洲研究院公布的新闻语料库[9 ] 、媒体社交语料库[22 ] 和人才简历语料库[18 ] ;也有一些领域的语料库非公开但相对成熟,如医学生物领域、国防军事领域和电力领域. 本研究构建的航空装配语料库中测试集实体字符占所有字符的32.15%,比通用语料库MSRA实体比例16.11%高. 航空装配领域语料库的特点如下:1)语料数量少;2)语料专业度高;3)噪声内容少,实体比例高;4)语料中命名实体边界模糊. 与通用语料库相比,航空装配语料库对命名实体识别的要求更高. ...
基于条件随机域的生物命名实体识别
1
2009
... CRF是无向图模型,其最简单的形式是线性链CRF,适合用于线性数据序列的标注[23 ] . 与HMM不同,CRF的条件概率由2个部分组成:1)在输入状态 $ {\boldsymbol{x}}_{i} $ $ {\boldsymbol{y}}_i $ $ {\boldsymbol{y}}_{i-1} $ $ {\boldsymbol{y}}_i $
基于条件随机域的生物命名实体识别
1
2009
... CRF是无向图模型,其最简单的形式是线性链CRF,适合用于线性数据序列的标注[23 ] . 与HMM不同,CRF的条件概率由2个部分组成:1)在输入状态 $ {\boldsymbol{x}}_{i} $ $ {\boldsymbol{y}}_i $ $ {\boldsymbol{y}}_{i-1} $ $ {\boldsymbol{y}}_i $




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}