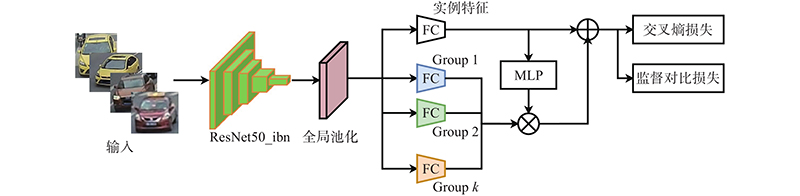
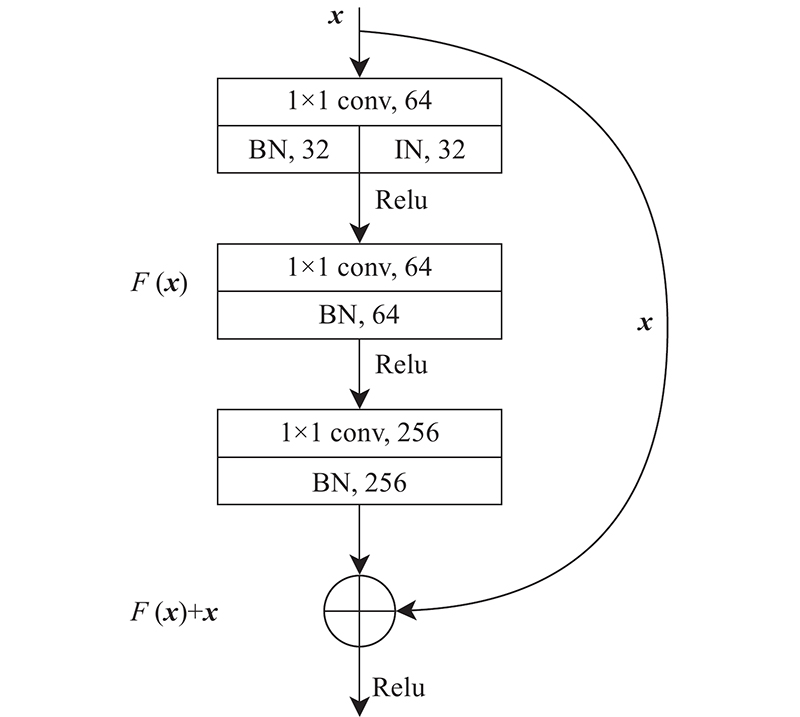
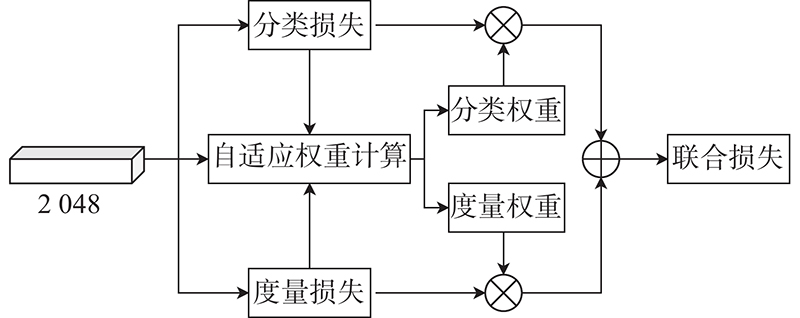
A vehicle re-identification algorithm based on attention mechanism and adaptive loss weights was proposed in order to solve the problem that the vehicle re-identification algorithms cannot adequately represent vehicle features due to intra-class differences and inter-class similarities. The improved backbone network ResNet50_ibn was used to avoid the influence of objective factors such as color, illumination and perspective, and extract invariant features about the target. An attention mechanism was introduced to build a group representation network, which fused the interdependence between features by extracting from different groups and extracted abundant feature information from different feature representations. The loss function was improved by adaptive loss weight, and the network was trained by using a multi-loss function strategy. The algorithm achieved 96.0% Rank-1, 79.8% mAP and 81.5% Rank-1, 80.9% mAP, respectively on the public datasets VeRi776 and VehicleID. The experimental results show that the features extracted by the algorithm are more discriminative. The comprehensive performance is better than other existing vehicle re-identification algorithms.
Keywords:vehicle re-identification
;
attention mechanism
;
adaptive loss weight
;
machine vision
;
deep learning
SU Yu-ting, LU Rong-xuan, ZHANG Wei. Vehicle re-identification algorithm based on attention mechanism and adaptive weight. Journal of Zhejiang University(Engineering Science)[J], 2023, 57(4): 712-718 doi:10.3785/j.issn.1008-973X.2023.04.008
LIU X, WU L, MA H, et al. Large-scale vehicle re-identification in urban surveillance videos [C]// Proceedings of the IEEE International Conference on Multimedia and Expo. Seattle: IEEE, 2016: 1-6.
ZAPLETAL D, HEROUT A. Vehicle re-identification for automatic video traffic surveillance [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. California: IEEE, 2016: 1568-1574.
CORMIER M, SOMMER L W, TEUTSCH M. Low resolution vehicle re-identification based on appearance features for wide area motion imagery [C]// Proceedings of the IEEE Winter Applications of Computer Vision Workshops. New York: IEEE, 2016: 1-7.
LUO H, GU Y, LIAO X, et al. Bag of tricks and a strong baseline for deep person re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Long Beach: IEEE, 2019: 1487-1495.
ZHENG Z, RUAN T, WEI Y, et al. VehicleNet: learning robust visual representation for vehicle re-identification [C]// Proceedings of the IEEE Transactions on Multimedia. New York: IEEE, 2021: 2683-2693.
JIN X, LAN C, ZENG W, et al. Uncertainty-aware multi-shot knowledge distillation for image-based object re-identification [C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI, 2020: 11165-11172.
KIM Y, PARK W, ROH M C, et al. GroupFace: learning latent groups and constructing group-based representations for face recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 5620-5629.
CHEN T S, LIU C T, WU C W. et al. Orientation-aware vehicle re-identification with semantics-guided part attention network [C]// European Conference on Computer Vision. Amsterdam: Elsevier, 2020: 330–346.
NGUYEN B X, NGUYEN B D, DO T, et al. Graph-based person signature for person re-identifications [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE, 2021: 3487-3496.
HUYNH S V, NGUYEN N H, NGUYEN N T, et al. A strong baseline for vehicle re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE, 2021: 4142-4149.
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
LIU H, TIAN Y, WANG Y, et al. Deep relative distance learning: tell the difference between similar vehicles [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2167-2175.
KINGMA D, BA J. Adam: a method for stochastic optimization [C]// International Conference on Learning Representations. San Diego: [s. n.], 2015: 1412-1426.
WANG Z, TANG L, LIU X, et al. Orientation invariant feature embedding and spatial temporal regularization for vehicle reidentification [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 832-837.
YI Z, LING S. Viewpoint-aware attentive multi-view inference for vehicle re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2017: 6489-6498.
HE B, LI J, ZHAO Y, et al. Part-regularized near-duplicate vehicle re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 3992-4000.
LIN W, Y LI, YANG X, et al. Multi-view learning for vehicle re-identification [C]// IEEE International Conference on Multimedia and Expo. Shanghai: IEEE, 2019: 832-837.
MENG D, LI L, LIU X, et al. Parsing-based view-aware embedding network for vehicle re-identification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 7101-7110.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}