Session-based recommendation algorithms only capture users’ short-term dynamic interests, ignoring the impact of long-term interests and social friends on their behavior. To address the problem, a recommendation algorithm combining social influence and long short-term preferences was proposed. Firstly, a novel heterogeneous relation graph was designed to organize users’ social relations and historical interaction behaviors. And a heterogeneous graph neural network based on the attention mechanism was proposed to learn the graph, and to obtain long-term preference for integrating social influence of users. Moreover, considering the problem of noise caused by inconsistent social influence, a weighted and pruning strategy was proposed to reduce noise interference and enrich the graph structure information. Then, a lossless session modeling method was used to capture users’ short-term preference. Finally, users’ short-term preference and long-term preference were adaptively fused to obtain a feature representation that reflects users’ global preferences. Experimental results on Gowalla and Delicious datasets show that the indicators of the proposed method are significantly improved compared with the existing advanced methods, which proves the effectiveness of the proposed algorithm.
Keywords:recommendation algorithm
;
social influence
;
long short-term preference
;
weighted and pruning strategy
;
heterogeneous relation graph
;
heterogeneous graph neural network
ZHOU Qing-song, CAI Xiao-dong, LIU Jia-liang. Personalized recommendation algorithm combining social influence and long short-term preference. Journal of Zhejiang University(Engineering Science)[J], 2023, 57(3): 495-502 doi:10.3785/j.issn.1008-973X.2023.03.007
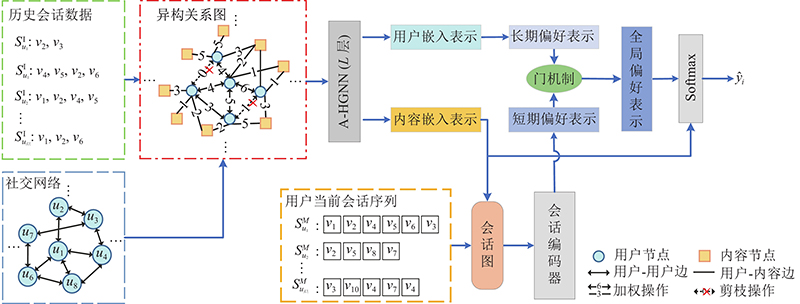
受文献[11]的启发,本研究针对现有基于会话的推荐方法忽略用户的长期偏好、社交好友对用户下一次交互行为的影响,以及现有社交推荐算法在构图或建模时假设每个好友邻居的影响力一致容易引入噪声的问题,提出结合社交影响和长短期偏好的个性化推荐算法(social influence and long short-term preferences for personalized recommendation,SLSPR). SLSPR构造包含用户历史交互行为及社交关系的异构关系图,用基于注意力机制的异构图神经网络挖掘异构关系图,学习出包含用户社交影响的长期偏好表示. 在构造异构关系图时,通过加权剪枝边给予模型更多的先验知识并过滤潜在噪声. 将结合了社交影响的长期偏好表示和利用无损的会话建模方法的短期偏好表示进行自适应特征融合,得到用户的全局偏好.
1. SLSPR模型
1.1. 问题定义
令 $ U{\text{ = \{ }}{u_1},{u_2},\cdots,{u_{|U|}}{\text{\} }} $、 $ V{\text{ = \{ }}{v_1},{v_2},\cdots,{v_{|V|}}{\text{\} }} $分别表示用户和内容的节点集合,其中 $ |U| $为用户数, $ |V| $为内容数. $ F = (U,{E^{\text{S}}}) $为用户的社交网络,其中 $ {E^{\text{S}}} $为社交联系的边集合. 用户 $ u \in U $的历史会话记录集 $ {S_u} = \{ S_u^1,S_u^2,\cdots,S_u^M\} $,其中 $ M $ 为 $ u $ 的会话总数. $ S_u^M = \{ v_u^1,v_u^2,\cdots,v_u^N\} $ 为 $ u $ 的当前会话,是由 $ u $ 交互过的按照时间戳排序的内容列表,其中 $ v_u^n \in V $为该会话中的第 $ n $个内容, $ N $ 为会话的长度. $ \hat {\boldsymbol{y}} $ 为用户下一次将交互的内容的概率分布.
1)计算每个邻居节点和 $ u $之间的注意力权重,以表征不同邻居节点对 $ u $的影响大小,计算式为
$ \alpha _{{E_x}}^{l+1}(n,u){\text{ = Soft}}\left( {{{({\boldsymbol{q}}_{{E_x}}^{l{\text+}1})}^{\text{T}}}\sigma \left( {{\boldsymbol{W}}_{{E_x}}^{l+1}({{\boldsymbol{h}}^l}\left[ n \right]\parallel {{\boldsymbol{h}}^l}\left[ u \right])} \right)+{\boldsymbol{b}}_{{E_x}}^{l+1}} \right). $
式中: $ n \in N_u^G $为 $ u $在异构关系图 $ G $中的邻居节点, ${{\boldsymbol{h}}^l}\left[ u \right]$、 ${{\boldsymbol{h}}^l}\left[ n \right]$分别为 $ u $和 $ n $在A-HGNN第 $ l $层的嵌入表示, $ {E_x} \in \{ {E_{_{{UU}}}},{E_{_{{UV}}}}\} $为特定的边类型, $ {\boldsymbol{q}}_{{E_x}}^{l{\text{+}}1} \in {{\bf{R}}^d} $、 $ {\boldsymbol{W}}_{{E_x}}^{l{\text{+}}1} \in {{\bf{R}}^{d \times 2d}} $均为可学习的参数, $ {\boldsymbol{b}}_{{{{E}}_x}}^{l{\text{+}}1} \in {{\bf{R}}^d} $为对应边 $ {E_x} $的特征向量, $ \parallel $为向量拼接, $ \sigma $为Sigmoid激活函数, $ {\text{Soft}} $为Softmax函数.
2)基于注意力权重聚合 $ u $所有邻居节点的信息,得到 $ u $的邻居聚合信息嵌入表示,计算式为
$ {{\boldsymbol{n}}^{l+1}}\left[ u \right] = \sum\limits_{n \in N_u^G} {\alpha _{{E_x}}^{l+1}} (n,u){{\boldsymbol{h}}^{l+1}}\left[ n \right]. $
对 $ u $的嵌入表示 $ {{\boldsymbol{h}}^l}\left[ u \right] $和其邻居聚合信息嵌入表示 $ {{\boldsymbol{n}}^{l+1}}\left[ u \right] $进行融合以更新嵌入表示,计算式为
$ {{\boldsymbol{h}}^{l+1}}\left[ u \right] = {\text{ReLU}}\left( {{{\boldsymbol{W}}^{l+1}}({{\boldsymbol{n}}^{l+1}}\left[ u \right]\parallel {{\boldsymbol{h}}^l}\left[ u \right])+{{\boldsymbol{b}}^{l+1}}} \right). $
式中: ${{\boldsymbol{W}}^{l+1}} \in {{\bf{R}}^{d \times 2d}}$、 ${{\boldsymbol{b}}^{l+1}} \in {{\bf{R}}^d}$均为可学习的参数. 对式(5)~(7)迭代计算 $ L $次,在第 $ L $层获得用户节点的嵌入表示 $ {{\boldsymbol{h}}^L}\left[ u \right] $. 由于 $ {{\boldsymbol{h}}^L}\left[ u \right] $融合了好友的兴趣特征和自身的长期兴趣特征,为了表示方便,表述为融合社交影响的用户长期偏好表示 $ {\boldsymbol{h}}_{{\text{sL}}}^u $.
内容节点只存在用户与内容之间的边 $ {E_{_{{UV}}}} $,其邻居信息的聚合过程和节点信息的更新过程与用户节点类似. 在第 $ L $层可以获得内容节点 $ v $的嵌入表示 $ {{\boldsymbol{h}}^L}\left[ v \right] $,由于 $ {{\boldsymbol{h}}^L}\left[ v \right] $在异构关系图中聚合了不同用户及其社交好友的交互行为特征,具备更深层次的语义信息,为了表示方便,将 $ {{\boldsymbol{h}}^L}\left[ v \right] $表述为具有丰富语义的内容嵌入表示 ${\boldsymbol{ h}}_{\rm{R}}^v $.
LI J, REN P, CHEN Z, et al. Neural attentive session-based recommendation [C]// Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. Singapore: ACM, 2017: 1419-1428.
LIU Q, ZENG Y, MOKHOSI R, et al. STAMP: short-term attention/memory priority model for session-based recommendation [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. London: ACM, 2018: 1831-1839.
HAMILTON W, YING Z, LESKOVEC J. Inductive representation learning on large graphs [C]// Proceedings of the 31st International Conference Neural Information Processing Systems. Long Beach: [s. n.], 2017: 1025-1035.
WU S, TANG Y, ZHU Y, et al. Session-based recommendation with graph neural networks [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu: AAAI, 2019: 346-353.
CHEN T, WONG R C W. Handling information loss of graph neural networks for session-based recommendation [C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S. l.]: ACM, 2020: 1172-1180.
PANG Y, WU L, SHEN Q, et al. Heterogeneous global graph neural networks for personalized session-based recommendation [C]// Proceeding of the 15th ACM International Conference on Web Search and Data Mining. [S. l.]: ACM, 2022: 775-783.
MA H, ZHOU D, LIU C, et al. Recommender systems with social regularization [C]// Proceedings of the 4th ACM International Conference on Web Search and Data Mining. Hong Kong: ACM, 2011: 287-296.
ZHAO T, MCAULEY J, KING I. Leveraging social connections to improve personalized ranking for collaborative filtering [C]// Proceedings of the 23rd ACM International Conference on Information and Knowledge Management. Shanghai: ACM, 2014: 261-270.
XIAO L, MIN Z, YONGFENG Z, et al. Learning and transferring social and item visibilities for personalized recommendation [C]// Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. Singapore: ACM, 2017: 337-346.
FAN W, MA Y, LI Q, et al. Graph neural networks for social recommendation [C]// The World Wide Web Conference. San Francisco: [s. n.], 2019: 417-426.
SONG W, XIAO Z, WANG Y, et al. Session-based social recommendation via dynamic graph attention networks [C]// Proceedings of the 12th ACM International Conference on Web Search and Data Mining. Melbourne: ACM, 2019: 555-563.
FU B, ZHANG W, HU G, et al. Dual side deep context-aware modulation for social recommendation [C]// Proceedings of the Web Conference2021. Ljubljana: [s. n.], 2021: 2524-2534.
YU Z, LIAN J, MAHMOODY A, et al. Adaptive user modeling with long and short-term preferences for personalized recommendation [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao: [s. n.], 2019: 4213-4219.
... 受文献[11]的启发,本研究针对现有基于会话的推荐方法忽略用户的长期偏好、社交好友对用户下一次交互行为的影响,以及现有社交推荐算法在构图或建模时假设每个好友邻居的影响力一致容易引入噪声的问题,提出结合社交影响和长短期偏好的个性化推荐算法(social influence and long short-term preferences for personalized recommendation,SLSPR). SLSPR构造包含用户历史交互行为及社交关系的异构关系图,用基于注意力机制的异构图神经网络挖掘异构关系图,学习出包含用户社交影响的长期偏好表示. 在构造异构关系图时,通过加权剪枝边给予模型更多的先验知识并过滤潜在噪声. 将结合了社交影响的长期偏好表示和利用无损的会话建模方法的短期偏好表示进行自适应特征融合,得到用户的全局偏好. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}