[1]
HU L, DUAN F, DING K, et al Research on surface detects on line detection system for steel plate using computer vision
[J]. Iron and Steel , 2005 , 40 (2 ): 59 - 61
[本文引用: 1]
[2]
WANG J, LI Q, GAN J, et al Surface defect detection via entity sparsity pursuit with intrinsic priors
[J]. IEEE Transactions on Industrial Informatics , 2020 , 16 (1 ): 141 - 150
DOI:10.1109/TII.2019.2917522
[本文引用: 1]
[3]
SAMSUDIAN S S, AROF H, HARUN S W, et al Steel surface defect classification using multi-resolution empirical mode decomposition and LBP
[J]. Measurement Science and Technology , 2020 , 32 (1 ): 015601
[4]
MENTOURI Z, MOUSSAOUI A, BOUDJEHEM D, et al Steel strip surface defect identification using multiresolution binarized image features
[J]. Journal of Failure Analysis and Prevention , 2020 , 20 : 1917 - 1927
DOI:10.1007/s11668-020-01012-7
[本文引用: 1]
[5]
ZAGHDOUDI R, SERIDI H, BOUDIAF A, et al. Binary Gabor pattern (BGP) descriptor and principal component analysis (PCA) for steel surface defects classification [C]// 2020 International Conference on Advanced Aspects of Software Engineering .Constantine: IEEE, 2020: 1–7.
[本文引用: 1]
[6]
KNITTER-PIĄTKOWSKA A, DOBRZYCKI A Application of wavelet transform to damage identification in the steel structure elements
[J]. Applied Sciences , 2020 , 10 (22 ): 8198
[7]
MENTOURI Z, DOGHMANE H, GHERFI K, et al. Tool combination for the description of steel surface image and defect classification [C]// The 2nd International Conference on Embedded Systems and Artificial Intelligence . Fez:[s.n.], 2021: 1-13.
[本文引用: 1]
[8]
SARDA K, ACERNESE A, NOLÈ V, et al A multi-step anomaly detection strategy based on robust distances for the steel industry
[J]. IEEE Access , 2021 , 9 : 53827
DOI:10.1109/ACCESS.2021.3070659
[本文引用: 1]
[9]
TSAI D M, CHEN M C, LI W C, et al A fast regularity measure for surface defect detection
[J]. Machine Vision and Applications , 2012 , 23 : 869 - 886
DOI:10.1007/s00138-011-0403-3
[本文引用: 1]
[10]
BOUDANI F Z, NACEREDDINE N, LAICHE N. Content-based image retrieval for surface defects of hot rolled steel strip using wavelet-based LBP [C]// International Workshop on Artificial Intelligence and Pattern Recognition . [S.l.]: Springer, 2021: 404–413.
[本文引用: 1]
[11]
徐科, 宋敏, 杨朝霖, 等 隐马尔可夫树模型在带钢表面缺陷在线检测中的应用
[J]. 机械工程学报 , 2013 , 49 (22 ): 34 - 40
DOI:10.3901/JME.2013.22.034
[本文引用: 1]
XU Ke, SONG Min, YANG Chao-lin, et al Application of hidden Markov tree model to on-line detection of surface defects for steel strips
[J]. Journal of Mechanical Engineering , 2013 , 49 (22 ): 34 - 40
DOI:10.3901/JME.2013.22.034
[本文引用: 1]
[12]
TAO X, ZHANG D, MA W, et al Automatic metallic surface defect detection and recognition with convolutional neural networks
[J]. Applied Sciences , 2018 , 8 (9 ): 1575
[本文引用: 1]
[13]
HE Y, SONG K, MENG Q, et al An end-to-end steel surface defect detection approach via fusing multiple hierarchical features
[J]. IEEE Transactions on Instrumentation and Measurement , 2019 , 69 (4 ): 1493 - 1504
[本文引用: 1]
[14]
DONG H, SONG K, HE Y, et al PGA-net: pyramid feature fusion and global context attention network for automated surface defect detection
[J]. IEEE Transactions on Industrial Informatics , 2019 , 16 (12 ): 7448 - 7458
[本文引用: 1]
[15]
CHEN F C, JAHANSHAHI M R NB-CNN: deep learning-based crack detection using convolutional neural network and naïve bayes data fusion
[J]. IEEE Transactions on Industrial Electronics , 2018 , 65 (5 ): 4392 - 4400
DOI:10.1109/TIE.2017.2764844
[本文引用: 1]
[16]
彭大芹, 刘恒, 许国良, 等 基于双向特征融合卷积神经网络的液晶面板缺陷检测算法
[J]. 广东通信技术 , 2019 , 39 (4 ): 66 - 73
[本文引用: 1]
PENG Da-qin, LIU Heng, XU Guo-liang, et al Defect detection algorithm of liquid crystal panel based on bidirectional feature fusion convolution neural network
[J]. Guangdong Communication Technology , 2019 , 39 (4 ): 66 - 73
[本文引用: 1]
[17]
ZHANG Y, QIU Z, YAO T, et al. Fully convolutional adaptation networks for semantic segmentation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6810–6818.
[本文引用: 1]
[18]
LIU D, ZHANG D, SONG Y, et al. Unsupervised instance segmentation in microscopy images via panoptic domain adaptation and task re-weighting [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 4242–4251.
[本文引用: 1]
[19]
ZHENG Y, HUANG D, LIU S, et al. Cross-domain object detection through coarse-to-fine feature adaptation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 13763–13772.
[本文引用: 1]
[20]
SINDAGI V A, SRIVASTAVA S Domain adaptation for automatic OLED panel defect detection using adaptive support vector data description
[J]. International Journal of Computer Vision , 2017 , 122 : 193 - 211
DOI:10.1007/s11263-016-0953-y
[本文引用: 1]
[21]
GOETZ A, DURMAZ A R, MÜLLER M, et al Addressing materials’ microstructure diversity using transfer learning
[J]. NPJ Computational Materials , 2022 , 8 : 27
DOI:10.1038/s41524-021-00695-2
[本文引用: 1]
[22]
FAN R, WANG H, BOCUS M J, et al. We learn better road pothole detection: from attention aggregation to adversarial domain adaptation [C]// European Conference on Computer Vision . [S.l.]: Springer, 2020: 285–300.
[本文引用: 1]
[23]
GUO C, LI C, GUO J, et al. Zero-reference deep curve estimation for low-light image enhancement [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1777–1786.
[本文引用: 1]
[24]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 1]
[25]
LONG M, CAO Y, WANG J, et al. Learning transferable features with deep adaptation networks[C]// Proceedings of the 32th International Conference on Machine Learning . Lille:[s.n.], 2015: 97-105.
[本文引用: 1]
[26]
LONG M, ZHU H, WANG J, et al. Deep transfer learning with joint adaptation networks [C]// Proceedings of the 34th International Conference on Machine Learning . Sydney:[s.n.], 2017: 2208–2217.
[本文引用: 1]
[27]
GANIN Y, LEMPITSKY V. Unsupervised domain adaptation by backpropagation [C]// Proceedings of the 32nd International Conference on Machine Learning . Lille:[s.n.], 2015: 1180–1189.
[本文引用: 1]
[28]
RAAB C, VATH P, MEIER P, et al. Bridging adversarial and statistical domain transfer via spectral adaptation networks [C]// Proceedings of the Asian Conference on Computer Vision .[S.l.]: Spring, 2020: 457–473.
[本文引用: 1]
[29]
CUI S, WANG S, ZHUO J, et al. Gradually vanishing bridge for adversarial domain adaptation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 12452–12461.
[本文引用: 1]
[30]
VAN DER MAATEN L, HINTON G Visualizing data using t-SNE
[J]. Journal of Machine Learning Research , 2008 , 9 (11 ): 2579 - 2605
[本文引用: 1]
[31]
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 618-626.
[本文引用: 1]
Research on surface detects on line detection system for steel plate using computer vision
1
2005
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
Surface defect detection via entity sparsity pursuit with intrinsic priors
1
2020
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
Steel surface defect classification using multi-resolution empirical mode decomposition and LBP
0
2020
Steel strip surface defect identification using multiresolution binarized image features
1
2020
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
1
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
Application of wavelet transform to damage identification in the steel structure elements
0
2020
1
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
A multi-step anomaly detection strategy based on robust distances for the steel industry
1
2021
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
A fast regularity measure for surface defect detection
1
2012
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
1
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
隐马尔可夫树模型在带钢表面缺陷在线检测中的应用
1
2013
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
隐马尔可夫树模型在带钢表面缺陷在线检测中的应用
1
2013
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
Automatic metallic surface defect detection and recognition with convolutional neural networks
1
2018
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
An end-to-end steel surface defect detection approach via fusing multiple hierarchical features
1
2019
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
PGA-net: pyramid feature fusion and global context attention network for automated surface defect detection
1
2019
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
NB-CNN: deep learning-based crack detection using convolutional neural network and na?ve bayes data fusion
1
2018
... 带钢是航空航天、机械和汽车等行业的主要原材料. 在带钢的生产过程中,由于工厂环境、轧辊的滚动速度与带钢运行速度不一、钢坯材料等因素的影响,其表面不可避免地存在一些缺陷[1 ] . 带钢表面缺陷会对相关产品的外观造成影响,降低产品的抗腐蚀性、抗疲劳强度. 基于视觉的带钢表面质量检测技术对于提升产品质量具有重要意义. 视觉检测技术是带钢表面质量检测的常用手段. 传统的缺陷识别方法依赖人工手动设计的视觉特征,主要包括统计法[2 -4 ] 、频谱法[5 -7 ] 、模型法[8 ] 等. Tsai等[9 ] 提出基于加权协方差矩阵的度量纹理规则性的方法,实现塑料和皮革产品的表面缺陷识别. Boudani等[10 ] 提出基于小波的带钢表面缺陷检测方法. 徐科等[11 ] 提出基于多尺度融合的小波域隐马尔科夫树模型,实现对带钢表面缺陷的识别. 基于深度学习的缺陷检测方法能够自动提取图像特征[12 ] . He等[13 ] 提出基于多级特征融合的带钢表面缺陷检测网络. Dong等[14 ] 提出基于多尺度特征融合和全局上下文注意力的缺陷分割网络. Chen等[15 ] 提出基于朴素贝叶斯和CNN的缺陷识别方法. ...
基于双向特征融合卷积神经网络的液晶面板缺陷检测算法
1
2019
... 虽然基于深度学习的目标识别方法在封闭场景下取得良好的效果,但它高度依赖大规模高质量标注数据,在很多场景下难以获得大规模高质量数据集. 以域适应为代表的迁移学习技术通过挖掘和迁移跨域相似场景中的共享知识,可以实现无监督模式下的目标识别[16 -17 ] . Liu等[18 ] 提出基于任务加权机制和图像修复的域适应网络,实现由荧光显微镜图像到真实组织病理学图像的分割. Zheng等[19 ] 提出基于注意力特征对齐和聚类的域适应网络,实现由正常天气场景到大雾天气场景的目标检测. Sindagi等[20 ] 提出基于支持向量描述的域适应缺陷检测模型,实现针对不同光照场景下的有机发光二极管的缺陷检测. Goetz等[21 ] 提出基于自编码器的域适应缺陷方法,实现跨场景下相钢显微图像中的板条形贝氏体检测. Fan等[22 ] 提出基于图像增强的域适应缺陷检测方法,利用新生成的不同纹理和背景道路缺陷图像,实现对复杂的道路坑洼场景的分割任务. ...
基于双向特征融合卷积神经网络的液晶面板缺陷检测算法
1
2019
... 虽然基于深度学习的目标识别方法在封闭场景下取得良好的效果,但它高度依赖大规模高质量标注数据,在很多场景下难以获得大规模高质量数据集. 以域适应为代表的迁移学习技术通过挖掘和迁移跨域相似场景中的共享知识,可以实现无监督模式下的目标识别[16 -17 ] . Liu等[18 ] 提出基于任务加权机制和图像修复的域适应网络,实现由荧光显微镜图像到真实组织病理学图像的分割. Zheng等[19 ] 提出基于注意力特征对齐和聚类的域适应网络,实现由正常天气场景到大雾天气场景的目标检测. Sindagi等[20 ] 提出基于支持向量描述的域适应缺陷检测模型,实现针对不同光照场景下的有机发光二极管的缺陷检测. Goetz等[21 ] 提出基于自编码器的域适应缺陷方法,实现跨场景下相钢显微图像中的板条形贝氏体检测. Fan等[22 ] 提出基于图像增强的域适应缺陷检测方法,利用新生成的不同纹理和背景道路缺陷图像,实现对复杂的道路坑洼场景的分割任务. ...
1
... 虽然基于深度学习的目标识别方法在封闭场景下取得良好的效果,但它高度依赖大规模高质量标注数据,在很多场景下难以获得大规模高质量数据集. 以域适应为代表的迁移学习技术通过挖掘和迁移跨域相似场景中的共享知识,可以实现无监督模式下的目标识别[16 -17 ] . Liu等[18 ] 提出基于任务加权机制和图像修复的域适应网络,实现由荧光显微镜图像到真实组织病理学图像的分割. Zheng等[19 ] 提出基于注意力特征对齐和聚类的域适应网络,实现由正常天气场景到大雾天气场景的目标检测. Sindagi等[20 ] 提出基于支持向量描述的域适应缺陷检测模型,实现针对不同光照场景下的有机发光二极管的缺陷检测. Goetz等[21 ] 提出基于自编码器的域适应缺陷方法,实现跨场景下相钢显微图像中的板条形贝氏体检测. Fan等[22 ] 提出基于图像增强的域适应缺陷检测方法,利用新生成的不同纹理和背景道路缺陷图像,实现对复杂的道路坑洼场景的分割任务. ...
1
... 虽然基于深度学习的目标识别方法在封闭场景下取得良好的效果,但它高度依赖大规模高质量标注数据,在很多场景下难以获得大规模高质量数据集. 以域适应为代表的迁移学习技术通过挖掘和迁移跨域相似场景中的共享知识,可以实现无监督模式下的目标识别[16 -17 ] . Liu等[18 ] 提出基于任务加权机制和图像修复的域适应网络,实现由荧光显微镜图像到真实组织病理学图像的分割. Zheng等[19 ] 提出基于注意力特征对齐和聚类的域适应网络,实现由正常天气场景到大雾天气场景的目标检测. Sindagi等[20 ] 提出基于支持向量描述的域适应缺陷检测模型,实现针对不同光照场景下的有机发光二极管的缺陷检测. Goetz等[21 ] 提出基于自编码器的域适应缺陷方法,实现跨场景下相钢显微图像中的板条形贝氏体检测. Fan等[22 ] 提出基于图像增强的域适应缺陷检测方法,利用新生成的不同纹理和背景道路缺陷图像,实现对复杂的道路坑洼场景的分割任务. ...
1
... 虽然基于深度学习的目标识别方法在封闭场景下取得良好的效果,但它高度依赖大规模高质量标注数据,在很多场景下难以获得大规模高质量数据集. 以域适应为代表的迁移学习技术通过挖掘和迁移跨域相似场景中的共享知识,可以实现无监督模式下的目标识别[16 -17 ] . Liu等[18 ] 提出基于任务加权机制和图像修复的域适应网络,实现由荧光显微镜图像到真实组织病理学图像的分割. Zheng等[19 ] 提出基于注意力特征对齐和聚类的域适应网络,实现由正常天气场景到大雾天气场景的目标检测. Sindagi等[20 ] 提出基于支持向量描述的域适应缺陷检测模型,实现针对不同光照场景下的有机发光二极管的缺陷检测. Goetz等[21 ] 提出基于自编码器的域适应缺陷方法,实现跨场景下相钢显微图像中的板条形贝氏体检测. Fan等[22 ] 提出基于图像增强的域适应缺陷检测方法,利用新生成的不同纹理和背景道路缺陷图像,实现对复杂的道路坑洼场景的分割任务. ...
Domain adaptation for automatic OLED panel defect detection using adaptive support vector data description
1
2017
... 虽然基于深度学习的目标识别方法在封闭场景下取得良好的效果,但它高度依赖大规模高质量标注数据,在很多场景下难以获得大规模高质量数据集. 以域适应为代表的迁移学习技术通过挖掘和迁移跨域相似场景中的共享知识,可以实现无监督模式下的目标识别[16 -17 ] . Liu等[18 ] 提出基于任务加权机制和图像修复的域适应网络,实现由荧光显微镜图像到真实组织病理学图像的分割. Zheng等[19 ] 提出基于注意力特征对齐和聚类的域适应网络,实现由正常天气场景到大雾天气场景的目标检测. Sindagi等[20 ] 提出基于支持向量描述的域适应缺陷检测模型,实现针对不同光照场景下的有机发光二极管的缺陷检测. Goetz等[21 ] 提出基于自编码器的域适应缺陷方法,实现跨场景下相钢显微图像中的板条形贝氏体检测. Fan等[22 ] 提出基于图像增强的域适应缺陷检测方法,利用新生成的不同纹理和背景道路缺陷图像,实现对复杂的道路坑洼场景的分割任务. ...
Addressing materials’ microstructure diversity using transfer learning
1
2022
... 虽然基于深度学习的目标识别方法在封闭场景下取得良好的效果,但它高度依赖大规模高质量标注数据,在很多场景下难以获得大规模高质量数据集. 以域适应为代表的迁移学习技术通过挖掘和迁移跨域相似场景中的共享知识,可以实现无监督模式下的目标识别[16 -17 ] . Liu等[18 ] 提出基于任务加权机制和图像修复的域适应网络,实现由荧光显微镜图像到真实组织病理学图像的分割. Zheng等[19 ] 提出基于注意力特征对齐和聚类的域适应网络,实现由正常天气场景到大雾天气场景的目标检测. Sindagi等[20 ] 提出基于支持向量描述的域适应缺陷检测模型,实现针对不同光照场景下的有机发光二极管的缺陷检测. Goetz等[21 ] 提出基于自编码器的域适应缺陷方法,实现跨场景下相钢显微图像中的板条形贝氏体检测. Fan等[22 ] 提出基于图像增强的域适应缺陷检测方法,利用新生成的不同纹理和背景道路缺陷图像,实现对复杂的道路坑洼场景的分割任务. ...
1
... 虽然基于深度学习的目标识别方法在封闭场景下取得良好的效果,但它高度依赖大规模高质量标注数据,在很多场景下难以获得大规模高质量数据集. 以域适应为代表的迁移学习技术通过挖掘和迁移跨域相似场景中的共享知识,可以实现无监督模式下的目标识别[16 -17 ] . Liu等[18 ] 提出基于任务加权机制和图像修复的域适应网络,实现由荧光显微镜图像到真实组织病理学图像的分割. Zheng等[19 ] 提出基于注意力特征对齐和聚类的域适应网络,实现由正常天气场景到大雾天气场景的目标检测. Sindagi等[20 ] 提出基于支持向量描述的域适应缺陷检测模型,实现针对不同光照场景下的有机发光二极管的缺陷检测. Goetz等[21 ] 提出基于自编码器的域适应缺陷方法,实现跨场景下相钢显微图像中的板条形贝氏体检测. Fan等[22 ] 提出基于图像增强的域适应缺陷检测方法,利用新生成的不同纹理和背景道路缺陷图像,实现对复杂的道路坑洼场景的分割任务. ...
1
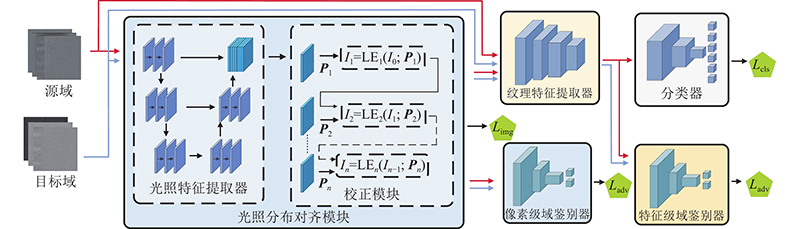
... 受Guo等[23 ] 提出的低光照图像增强方法的启发,设计无参考像素级光照分布对齐模块,旨在实现源域和目标域数据在光照子空间下的光照分布对齐. 对于给定的两域图像,模块先提取图像的像素级光照特征,再对图像中的每个像素估计非线性校正参数,并建立不同光照场景下的图像到光照子空间的映射曲线,最后通过光照分布对齐模块和像素级域鉴别器进行对抗训练,实现源域和目标域的光照分布对齐. 光照分布对齐模块由光照特征提取器和光照校正模块2个部分组成. 对于源域输入图像 ${{\boldsymbol{I}}_{\text{s}}}$ ${{\boldsymbol{I}}_{\text{t}}}$ ${\boldsymbol{P}}$ ${\boldsymbol{P}}$ $3 \times 3$ ${\boldsymbol{P}}$ ${{\boldsymbol{I}}_{{\text{sn}}}}$ ${{\boldsymbol{I}}_{{\text{tn}}}}$ . 光照校正模块包含多层光照校正函数,每层校正函数以光照特征 ${\boldsymbol{P}}$
1
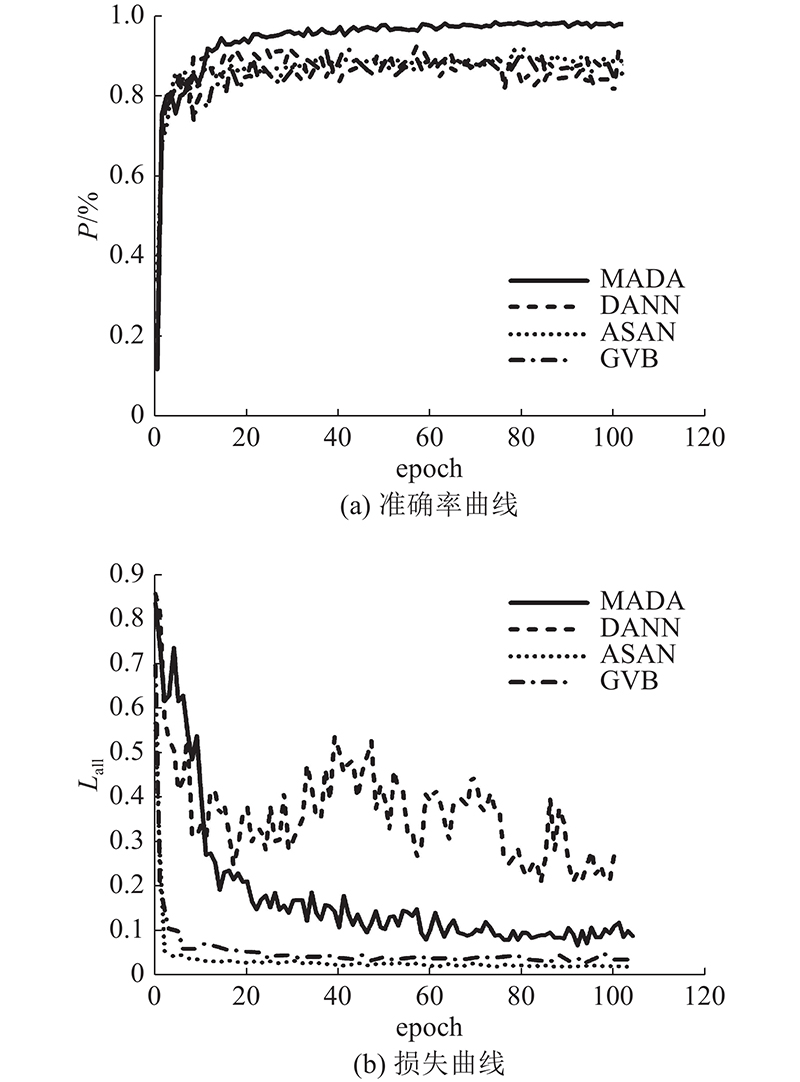
... 分别在HSDD和SSDD数据集上进行所提方法的有效性实验验证,并将所提方法与基于Resnet50[24 ] 的直推方法和现有的领域自适应方法进行比较. 对比的域适应方法包括基于MK-MMD的DAN[25 ] 方法、基于JMMD的JAN[26 ] 方法、基于领域鉴别器的DANN[27 ] 方法、基于统计的ASAN[28 ] 方法和基于桥连接的GVB[29 ] 等. ...
1
... 分别在HSDD和SSDD数据集上进行所提方法的有效性实验验证,并将所提方法与基于Resnet50[24 ] 的直推方法和现有的领域自适应方法进行比较. 对比的域适应方法包括基于MK-MMD的DAN[25 ] 方法、基于JMMD的JAN[26 ] 方法、基于领域鉴别器的DANN[27 ] 方法、基于统计的ASAN[28 ] 方法和基于桥连接的GVB[29 ] 等. ...
1
... 分别在HSDD和SSDD数据集上进行所提方法的有效性实验验证,并将所提方法与基于Resnet50[24 ] 的直推方法和现有的领域自适应方法进行比较. 对比的域适应方法包括基于MK-MMD的DAN[25 ] 方法、基于JMMD的JAN[26 ] 方法、基于领域鉴别器的DANN[27 ] 方法、基于统计的ASAN[28 ] 方法和基于桥连接的GVB[29 ] 等. ...
1
... 分别在HSDD和SSDD数据集上进行所提方法的有效性实验验证,并将所提方法与基于Resnet50[24 ] 的直推方法和现有的领域自适应方法进行比较. 对比的域适应方法包括基于MK-MMD的DAN[25 ] 方法、基于JMMD的JAN[26 ] 方法、基于领域鉴别器的DANN[27 ] 方法、基于统计的ASAN[28 ] 方法和基于桥连接的GVB[29 ] 等. ...
1
... 分别在HSDD和SSDD数据集上进行所提方法的有效性实验验证,并将所提方法与基于Resnet50[24 ] 的直推方法和现有的领域自适应方法进行比较. 对比的域适应方法包括基于MK-MMD的DAN[25 ] 方法、基于JMMD的JAN[26 ] 方法、基于领域鉴别器的DANN[27 ] 方法、基于统计的ASAN[28 ] 方法和基于桥连接的GVB[29 ] 等. ...
1
... 分别在HSDD和SSDD数据集上进行所提方法的有效性实验验证,并将所提方法与基于Resnet50[24 ] 的直推方法和现有的领域自适应方法进行比较. 对比的域适应方法包括基于MK-MMD的DAN[25 ] 方法、基于JMMD的JAN[26 ] 方法、基于领域鉴别器的DANN[27 ] 方法、基于统计的ASAN[28 ] 方法和基于桥连接的GVB[29 ] 等. ...
Visualizing data using t-SNE
1
2008
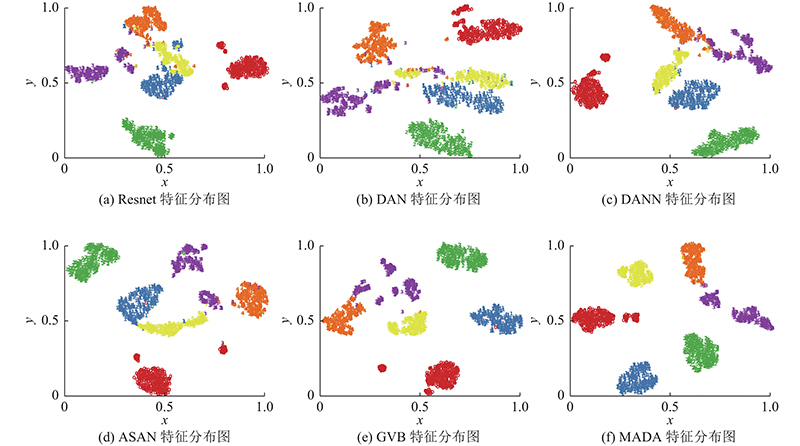
... 如图4 所示,为了进一步验证所提方法的有效性,利用T-SNE方法将MADA方法与不同对比方法对目标域数据集HSDD_N2的特征进行可视化.t-SNE[30 ] 方法能够将模型学习到的目标域高维特征向量映射为二维特征向量,并在二维嵌入空间中对目标域特征分布进行可视化. 在HSDD_N1⇒ HSDD_N2迁移任务中,对比基于直推的Resnet50方法、DAN、JAN、DANN、ASAN和MADA方法. 基于Resnet50的直推方法对划痕和油点缺陷提取的特征在嵌入空间中的类间距离较小. DAN方法对边缘缺陷提取的特征在嵌入空间中的类内距离较基于Resnet50的直推方法更小,但对划痕、网纹和油点缺陷提取的特征在嵌入空间中的相似度依然较高. 针对划痕、油点和油污缺陷,DANN方法较DAN方法在嵌入空间中的类内距离更为紧凑,但边缘和网纹缺陷提取的特征相似度较高. 针对网纹缺陷,ASAN方法对提取的特征的类内间距较DANN和DAN方法更小,但渐变与油点缺陷在嵌入空间中存在远离聚类中心的异常样本. GVB方法较ASAN方法拉近了油点缺陷特征的类内距离,但边缘缺陷提取的特征的散度较大. 所提方法对目标域所有缺陷特征在嵌入空间中的类内距相比其他方法更为紧凑,类间距更大,验证了MADA方法对目标域数据提取的特征的具有类别区分性. ...
1
... 为了验证所提方法是否提取目标域缺陷的特征表示,利用Grad-CAM[31 ] 方法对模型所提取的目标域特征进行可视化. Grad-CAM方法通过中间层对某一类别的偏导数得到特征权重,并利用特征权重对特征图进行加权求和,得到模型类别对图像不同区域的关注程度. 不同域适应方法在SSDD_1⇒SSDD_3迁移任务中对目标域SSDD_3的可视化结果如图5 所示. 可以看出,DAN方法易于受到背景纹理的干扰,并且凹坑和划痕类别的关注区域没有集中在缺陷区域. JAN方法对于划痕类别的识别效果优于DAN方法,所关注区域集中在划痕缺陷区域,但对于2道划痕的关注权重不同. DANN方法相较于JAN方法对凹坑和片状类别的关注区域更集中在缺陷区域. ASAN方法对划痕类别的识别效果优于DANN方法,对于划痕区域有更高的关注度. GVB方法相较于ASAN方法对划痕类别的关注区域更集中在缺陷本身,并对2道划痕有相同的权重. MADA方法的关注区域更加集中在缺陷范围内,并且背景区域有更低的关注程度,验证了MADA方法能够更关注目标域的缺陷区域,对跨场景的带钢缺陷识别具有良好的泛化性能. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}