[1]
程训, 余建波 基于机器视觉的加工刀具磨损监测方法
[J]. 浙江大学学报: 工学版 , 2021 , 55 (5 ): 896 - 904
[本文引用: 1]
CHEN Xun, YU Jian-bo Monitoring method for machining tool wear based on machine vision
[J]. Journal of Zhejiang University: Engineering Science , 2021 , 55 (5 ): 896 - 904
[本文引用: 1]
[2]
CHU M F, GONG R F, GAO S, et al Steel surface defects recognition based on multi-type statistical features and enhanced twin support vector machine
[J]. Chemometrics and Intelligent Laboratory Systems , 2017 , 171 : 140 - 150
DOI:10.1016/j.chemolab.2017.10.020
[本文引用: 1]
[3]
王典洪, 甘胜丰, 张伟民, 等 基于监督双限制连接 Isomap算法的带钢表面缺陷图像分类方法
[J]. 自动化学报 , 2014 , 40 (5 ): 883 - 891
[本文引用: 1]
WANG Dian-hong, GAN Sheng-feng, ZHANG Wei-min, et al Strip surface defect image classification based on double-limited and supervised-connect Isomap algorithm
[J]. Acta Automatica Sinica , 2014 , 40 (5 ): 883 - 891
[本文引用: 1]
[4]
WANG H Y, ZHANG J W, TIAN Y, et al A Simple guidance template-based defect detection method for strip steel surfaces
[J]. IEEE Transactions on Industrial Informatics , 2019 , 15 (5 ): 2798 - 2809
DOI:10.1109/TII.2018.2887145
[本文引用: 1]
[5]
KOYUNCU I, ÇETIN O, KATIRCIOĞLU F, et al. Edge dedection application with FPGA based Sobel operator [C]// Signal Processing and Communications Applications Conference . Malatya: IEEE, 2015: 1829–1832.
[本文引用: 1]
[6]
HE Y, SONG K C, MENG Q G, et al An end-to-end steel surface defect detection approach via fusing multiple hierarchical features
[J]. IEEE Transactions on Instrumentation and Measurement , 2020 , 69 (4 ): 1493 - 1504
DOI:10.1109/TIM.2019.2915404
[本文引用: 1]
[7]
LIU Y, XU K, XU J W Periodic surface defect detection in steel plates based on deep learning
[J]. Applied Sciences-Basel , 2019 , 9 (15 ): 3127
DOI:10.3390/app9153127
[本文引用: 1]
[8]
金侠挺, 王耀南, 张辉, 等 基于贝叶斯 CNN和注意力网络的钢轨表面缺陷检测系统
[J]. 自动化学报 , 2019 , 45 (12 ): 2312 - 2327
[本文引用: 1]
JIN Xia-ting, WANG Yao-nan, ZHANG Hui DeepRail: automatic visual detection system for railway surface defect using Bayesian CNN and attention network
[J]. Acta Automatica Sinica , 2019 , 45 (12 ): 2312 - 2327
[本文引用: 1]
[9]
LIU J Q, ZHANG Z J, LIN Z Y, et al Characterization method of surface crack based on laser thermography
[J]. IEEE Access , 2021 , 9 : 76395 - 76402
DOI:10.1109/ACCESS.2021.3081435
[本文引用: 1]
[10]
GUNATILAKE A, PIYATHILAKA L, TRAN A, et al Stereo vision combined with laser profiling for mapping of pipeline internal defects
[J]. IEEE Sensors Journal , 2021 , 21 (10 ): 11926 - 11934
DOI:10.1109/JSEN.2020.3040396
[本文引用: 1]
[11]
孙彬, 王建华, 赫东锋, 等 基于激光测量的航发叶片表面几何缺陷识别技术
[J]. 自动化学报 , 2020 , 46 (3 ): 594 - 599
[本文引用: 1]
SUN Bin, WANG Jian-hua, HE Dong-feng, et al Identification of aero-engine blade surface geometric defects with laser measurement
[J]. Acta Automatica Sinica , 2020 , 46 (3 ): 594 - 599
[本文引用: 1]
[12]
ZHAO C, ZHU H, WANG X. Steel plate surface defect recognition method based on depth information [C]// Data Driven Control and Learning Systems Conference . Dali: IEEE, 2019: 322-327.
[本文引用: 2]
[13]
EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network [C]// Conference on Neural Information Processing Systems . Montreal: [s. n.], 2014: 2366-2374.
[本文引用: 1]
[14]
YAO Y, LUO Z, LI S, et al. MVSNet: depth inference for unstructured multi-view stereo [C]// European Conference on Computer Vision . Munich: Springer, 2018: 785-801.
[本文引用: 1]
[15]
IM S, JEON H G, LIN S, et al. DPSNet: end-to-end deep plane sweep stereo [EB/OL]. [2022-03-04]. https://arxiv.org/pdf/1905.00538.pdf.
[本文引用: 1]
[16]
YU Z, GAO S. Fast-MVSNet: sparse-to-dense multi-view stereo with learned propagation and gauss-newton refinement [C]// Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1949-1958.
[本文引用: 1]
[17]
CHEN R, HAN S, XU J, et al. Point-based multi-view stereo network [C]// International Conference on Computer Vision . Seoul: IEEE, 2019: 1538-1547.
[本文引用: 1]
[18]
GU X, FAN Z, ZHU S, et al. Cascade cost volume for high-resolution multi-view stereo and stereo matching [C]// Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2492-2501.
[本文引用: 4]
[19]
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2117-2125.
[本文引用: 1]
[20]
HOU Q B, ZHOU D Q, FENG J S. Coordinate attention for efficient mobile network design [C]// Conference on Computer Vision and Pattern Recognition . Nashille: IEEE, 2021: 13708-13717.
[本文引用: 1]
[21]
HU J, SHEN L, SUN G, et al Squeeze-and-excitation networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (8 ): 2011 - 2023
DOI:10.1109/TPAMI.2019.2913372
[本文引用: 1]
[22]
ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise [C]// International Conference on Knowledge Discovery and Data Mining . Portland: [s. n.], 1996: 226-231.
[本文引用: 1]
[23]
GOOTTSCHALK S, LIN M C, MANOCHA D. OBBTree: a hierarchical structure for rapid interference detection [C]// Conference on Computer Graphics and Interactive Techniques . New Orleans: ACM, 1996, 30: 171-180.
[本文引用: 1]
[24]
AANAES H, JENSEN R R, VOGIATZIS G, et al Large-scale data for multiple-view stereopsis
[J]. International Journal of Computer Vision , 2016 , 120 (2 ): 153 - 168
DOI:10.1007/s11263-016-0902-9
[本文引用: 1]
[25]
SCHONBERGER J L, FRAHM J M. Structure-from-motion revisited [C]// Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2016: 4104-4113.
[本文引用: 1]
[26]
TOLA E, STRECHA C, FUA P Efficient large-scale multi-view stereo for ultra high-resolution image sets
[J]. Machine Vision and Applications , 2012 , 23 : 903 - 920
[本文引用: 1]
[27]
YAO Y, LUO Z X, LI S W, et al. Recurrent MVSNet for high-resolution multi-view stereo depth inference [C]// Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5525–5534.
[本文引用: 1]
基于机器视觉的加工刀具磨损监测方法
1
2021
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
基于机器视觉的加工刀具磨损监测方法
1
2021
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
Steel surface defects recognition based on multi-type statistical features and enhanced twin support vector machine
1
2017
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
基于监督双限制连接 Isomap算法的带钢表面缺陷图像分类方法
1
2014
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
基于监督双限制连接 Isomap算法的带钢表面缺陷图像分类方法
1
2014
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
A Simple guidance template-based defect detection method for strip steel surfaces
1
2019
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
1
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
An end-to-end steel surface defect detection approach via fusing multiple hierarchical features
1
2020
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
Periodic surface defect detection in steel plates based on deep learning
1
2019
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
基于贝叶斯 CNN和注意力网络的钢轨表面缺陷检测系统
1
2019
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
基于贝叶斯 CNN和注意力网络的钢轨表面缺陷检测系统
1
2019
... 基于机器视觉的检测方法大致分为二维检测和三维检测. 二维检测利用工业相机和光源设备采集钢板表面图像,通过图像处理、模式识别、机器学习对图像进行分析以获得钢板表面的质量状况. 程训等[1 ] 提出基于图像处理的刀具缺陷检测流程,通过改进边缘检测算法,控制检测误差不超过7%. Chu等[2 -3 ] 将机器学习方法应用于缺陷检测,实现了带钢表面缺陷的有效分类. 众多边缘检测算子的提出也大大促进了二维检测的发展[4 -5 ] . 随着深度学习的出现,深度神经网络(deep neural networks, DNN)可以提取高度抽象的信息,具有很强的特征表达能力,机器视觉检测任务的效率和准确性都极大提高. He等[6 ] 将多尺度特征提取融入Faster R-CNN, 进行了带钢表面缺陷的检测. Liu等[7 ] 提出结合注意力机制的长短期记忆网络的缺陷检测方法. 金侠挺等[8 ] 提出轻量级可伸缩的DeeperLab,实现了钢轨表面缺陷91.46%精度的分割. ...
Characterization method of surface crack based on laser thermography
1
2021
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
Stereo vision combined with laser profiling for mapping of pipeline internal defects
1
2021
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
基于激光测量的航发叶片表面几何缺陷识别技术
1
2020
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
基于激光测量的航发叶片表面几何缺陷识别技术
1
2020
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
2
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
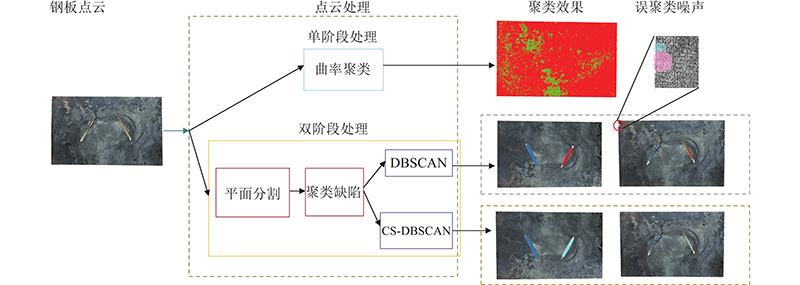
... 为了验证所提出的基于点云的缺陷提取流程的有效性,将平面分割+ CS-DBSCAN缺陷聚类方法a与一阶段基于法线夹角聚类的缺陷提取方法b[12 ] 进行对比,结果如图13 所示. 针对b方法,设置邻域点个数为16,计算每个点在该邻域内的平均法线夹角作为该点的法线夹角参量,设置夹角阈值为 ${\text{π}}/60$ $D = 0.04$ $P = 150$ . 由图13 可以看出,方法b无法对缺陷点云进行有效聚类,原因是稠密点云厚度并非单层,内部点云被包围因此无法得到有效的夹角参数. 方法a通过点云分割能够得到具有深度信息的缺陷点云以及一些表层的噪声点云,通过CS-DBSCAN对缺陷点云和噪声点云进行曲率差异稀疏化:将层状的噪声点云稀疏化处理,增大类间密度差异,平均类内密度差异,进一步提高聚类效果. 如实验所示,DBSCAN最后的聚类效果包含误识别的噪声,相比之下本研究提出的平面分割+CS-DBSCAN的点云处理方法能够对缺陷点云进行有效提取. ...
1
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
1
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
1
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
1
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
1
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
4
... 三维检测可以大致分为主动式检测和被动式检测. 主动式系统一般采用激光、结构光获取物体的三维信息. Liu等[9 ] 设计了基于反射的激光三维检测系统,进行了金属表面微裂纹缺陷的测量检测. Gunatilake等[10 ] 利用立体视觉和红外激光实现对管道内部缺陷毫米级的检测. 孙彬等[11 ] 采用激光设备结合截面线一阶导矢法实现对叶片型面3 µm 精度的缺陷识别. 被动式测量主要通过解析相机与相片的几何关系获取三维数据. Zhao等[12 ] 利用单目测量系统通过运动结构恢复算法重建出钢板三维模型,再对点云进行聚类以检测缺陷. 相较于传统的三维视觉,基于深度学习的方法能够以数据驱动的形式,通过多张RGB图像融合如相机位姿在内的参数实现重建,而无需非常复杂的数学过程. Eigen等[13 ] 通过卷积神经网络直接预测图像的深度信息. Yao等[14 ] 提出MVSNet,开启了用深度学习进行多视图三维重建的先河. Im等[15 ] 提出与MVSNet类似的深度平面扫描重建网络DPSNet. Fast-MVSNet[16 ] 、Point-MVSNet[17 ] 、CasMVSNet[18 ] 等网络的提出也极大促进了该领域的发展. ...
... 虽然工业零件表面缺陷检测的发展已经相对成熟但仍存在以下问题:1)大多数二维检测方法无法检测深度缺陷;2)三维缺陷检测大多依赖如结构光、激光扫描仪的主动式三维测量设备,该类设备安装复杂且价格昂贵,而被动检测方法耗时长,效率低. 针对上述问题,本研究提出基于多尺度特征增强的级联式三维重建网络(CasMVSNet[18 ] with multiscale feature enhancement, MFE-CasMVSNet)并结合点云数据处理技术应用于钢板表面缺陷检测,通过实验验证所提方法的有效性. ...
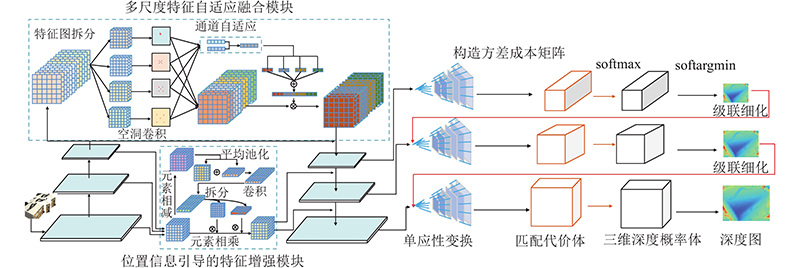
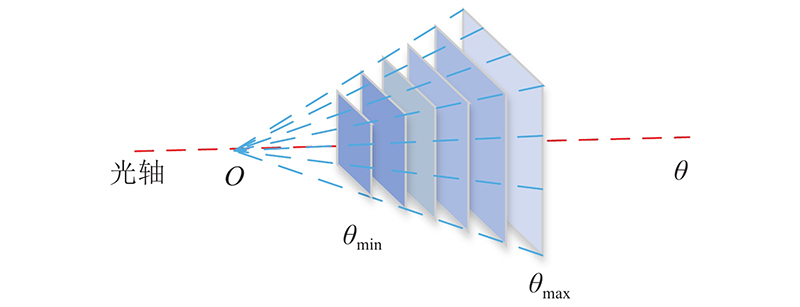
... 如图5 所示,构建匹配代价体借鉴经典的平面扫描法的多视角立体匹配思想[18 ] . 图中, $O$ $\theta $ ${\theta _{\min }}$ ${\theta _{\max }}$ $O$
... 式中: ${d_{{\rm{min}}}}$ ${d_{{\rm{max}}}}$ $d$ $O\left( d \right)$ $d$ [18 ] 的损失函数构造方法,将初始估计深度图、微调后的深度图与真实深度图之间的平均绝对差值作为训练的损失函数,对深度学习三维重建网络MFE-CasMVSNet进行训练. 级联结构第k 级的损失计算为损失函数: ...
1
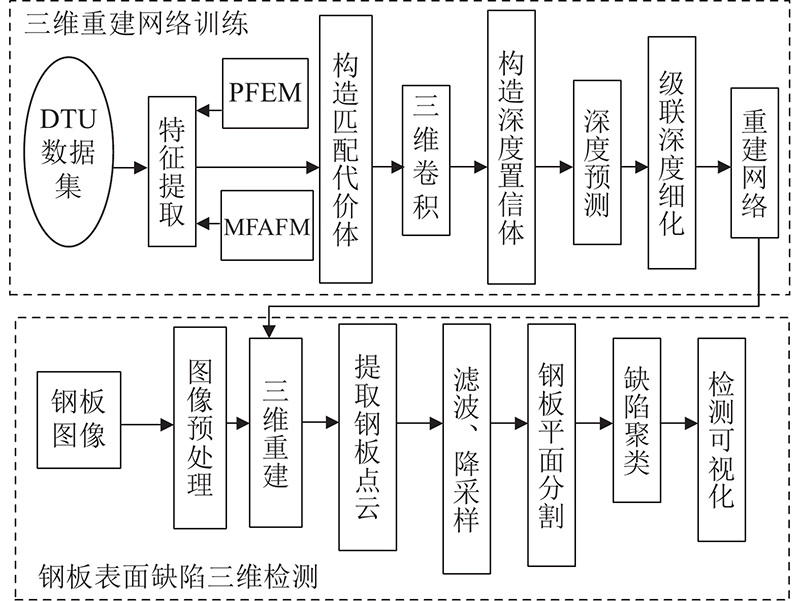
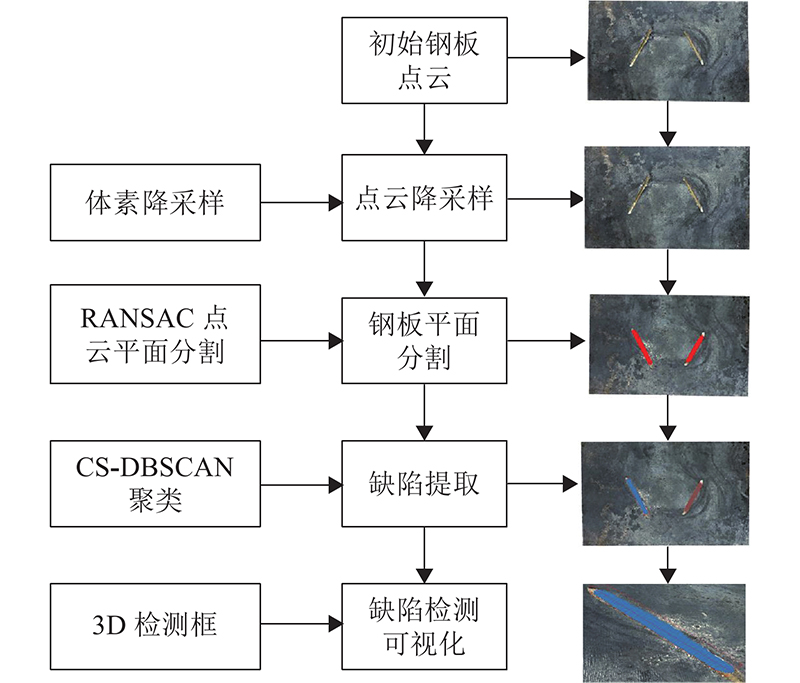
... 如图1 所示,基于MFE-CasMVSNet的钢板表面缺陷检测方法主要分为2个部分. 第一部分为三维成型网络的训练:采用三维重建数据集,1)通过PFEM、MFAFM模块结合FPN[19 ] 对输入图片进行特征提取,2)利用单应性变换构造匹配代价体(cost volume),通过回归函数得到像素的深度置信值,结合级联结构对深度信息进行细化,3)得到深度网络模型参数. 第二部分为钢板表面缺陷的三维检测流程:1)将多视角下的钢板图通过运动结构恢复算法(structure from motion,SFM)进行预处理得到如相机位姿在内的参数,利用MFE-CasMVSNet输出重建点云,通过k-means聚类和统计滤波对背景和噪声进行分割,得到钢板表面点云;2)通过基于随机一致采样(random sample consensus,RANSAC)的平面分割和基于曲率稀疏化的密度聚类方法(curvature-sparse-guided density-based spatial clustering of applications with noise,CS-DBSCAN),提取不同位置的缺陷点云;3)通过三维检测框进行缺陷可视化检测和定位. ...
1
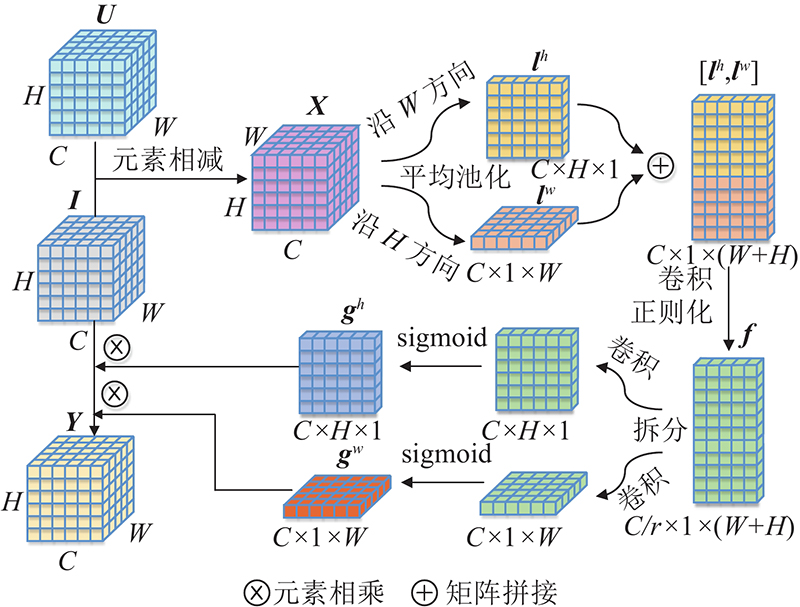
... 传统的自适应特征增强方法一般采用全局池化方法将全局信息压缩在单维度的通道映射中,重点关注通道信息而难以保留每个通道特征图内部的位置信息[20 ] . 为了获得更好的特征增强效果,PFEM将差值特征编码的全局二维池化过程分解为2个一维特征编码过程,将输入的特征图分别沿空间的2个方向聚集特征,被压缩的方向可以捕获长距离的依赖关系,同时可以保留另一方向上的具体位置信息. 对输入的特征图 ${\boldsymbol{X}}$ $W$ $H$ ${{\boldsymbol{l}}^h}$ ${{\boldsymbol{l}}^w}$ . 高度为 $h$ $c$
Squeeze-and-excitation networks
1
2020
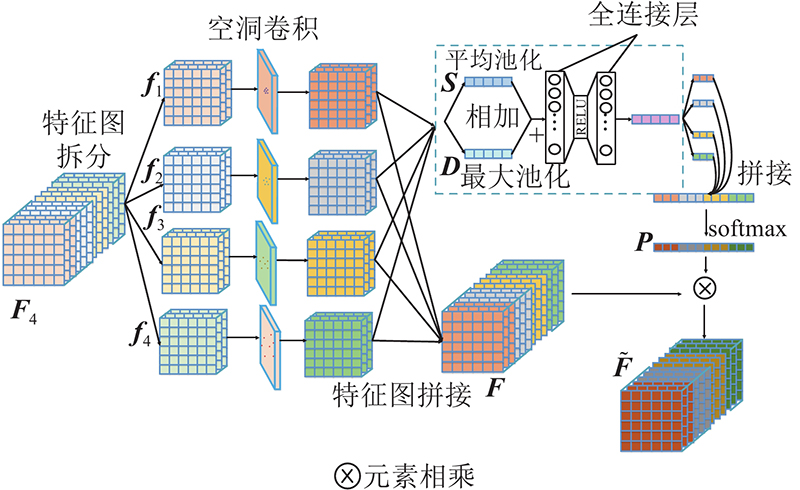
... 对经过多尺度空洞卷积后的4个特征组块 ${\tilde {\boldsymbol{f}}_i}$ [21 ] 采用平均池化对特征进行压缩映射,由于最大池化能够收集独特特征的重要线索,帮助实现更加精细化的特征提取,本研究用平均池化结果 ${{\boldsymbol{S}}_i}$ ${{\boldsymbol{D}}_i}$ ${{\boldsymbol{P}}_i}$ . 为了实现更好的自适应融合多尺度的特征信息,将上述每个特征块组的全局信息映射 ${{\boldsymbol{P}}_i}$ $ {\boldsymbol{P}}={\rm{softmax}}\;({{\boldsymbol{P}}}_{1}\oplus {{\boldsymbol{P}}}_{2}\oplus {{\boldsymbol{P}}}_{3}\oplus {{\boldsymbol{P}}}_{4}) $ . 得到自适应融合后的特征图 ...
1
... 传统的DBSCAN[22 ] 算法对密度不均匀的缺陷点云聚类效果较差,为此本研究提出基于曲率稀疏化的密度聚类算法(CS-DBSCAN),通过曲率信息对点云进行差异稀疏化操作,提高聚类效率和精度. 算法步骤如下. ...
1
... 2)计算三维检测框的三阶方向矩阵. 采用主成分分析,获取三维检测框的主轴方向. 通过计算协方差矩阵表示各个维度偏离均值的程度. 求主轴方向的特征向量[23 ] : ...
Large-scale data for multiple-view stereopsis
1
2016
... 实验使用的数据集来自DTU[24 ] 多视图数据集,是专门针对多视图三维重建而拍摄的大型室内数据集. 该数据集包括124个不同的场景,每个场景都是从49或者64个角度拍摄,包含7种不同的光照条件. ...
1
... 实验将与传统的基于图像几何的三维重建方法COLMAP[25 ] 、Tola[26 ] ,以及基于深度学习的方法RMVSNet[27 ] 、CasMVSNet在DTU数据集上进行对比实验,结果如表2 所示. 表中,Acc、Com、OR分别为三维重建的精度、完整度和总体重建水平,GPU、t R 分别为三维重建所消耗的显卡资源和运行时间,分数越低代表效果越好. 可以看出,MFE-CasMVSNet在精度和完整度上超过传统方法. 本研究所提方法相较基准方法 CasMVSNet在精确度、完整度、整体上分别提高了2.5%、2.3%、2.3%,较好地说明了本研究所提方法的有效性. 相较于MVSNet、RMVSNet,MFE-CasMVSNet消耗的空间资源和时间资源更少;相较于CasMVSNet,MFE-CasMVSNet增加的消耗也在可接受的范围. ...
Efficient large-scale multi-view stereo for ultra high-resolution image sets
1
2012
... 实验将与传统的基于图像几何的三维重建方法COLMAP[25 ] 、Tola[26 ] ,以及基于深度学习的方法RMVSNet[27 ] 、CasMVSNet在DTU数据集上进行对比实验,结果如表2 所示. 表中,Acc、Com、OR分别为三维重建的精度、完整度和总体重建水平,GPU、t R 分别为三维重建所消耗的显卡资源和运行时间,分数越低代表效果越好. 可以看出,MFE-CasMVSNet在精度和完整度上超过传统方法. 本研究所提方法相较基准方法 CasMVSNet在精确度、完整度、整体上分别提高了2.5%、2.3%、2.3%,较好地说明了本研究所提方法的有效性. 相较于MVSNet、RMVSNet,MFE-CasMVSNet消耗的空间资源和时间资源更少;相较于CasMVSNet,MFE-CasMVSNet增加的消耗也在可接受的范围. ...
1
... 实验将与传统的基于图像几何的三维重建方法COLMAP[25 ] 、Tola[26 ] ,以及基于深度学习的方法RMVSNet[27 ] 、CasMVSNet在DTU数据集上进行对比实验,结果如表2 所示. 表中,Acc、Com、OR分别为三维重建的精度、完整度和总体重建水平,GPU、t R 分别为三维重建所消耗的显卡资源和运行时间,分数越低代表效果越好. 可以看出,MFE-CasMVSNet在精度和完整度上超过传统方法. 本研究所提方法相较基准方法 CasMVSNet在精确度、完整度、整体上分别提高了2.5%、2.3%、2.3%,较好地说明了本研究所提方法的有效性. 相较于MVSNet、RMVSNet,MFE-CasMVSNet消耗的空间资源和时间资源更少;相较于CasMVSNet,MFE-CasMVSNet增加的消耗也在可接受的范围. ...












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}