[1]
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [EB/OL]. (2017-02-22)[2022-04-01]. https://arxiv.org/pdf/1609.02907.pdf.
[本文引用: 1]
[2]
VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks [EB/OL]. (2018-02-04)[2022-04-01]. https://arxiv.org/pdf/1710.10903.pdf.
[本文引用: 1]
[3]
SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks [C]// European Semantic Web Conference . [S. l.]: Springer, 2018: 593-607.
[本文引用: 1]
[4]
KIRITCHENKO S, ZHU X, CHERRY C, et al. NRC-Canada-2014: detecting aspects and sentiment in customer reviews [C]// Proceedings of the 8th International Workshop on Semantic Evaluation. Dublin: Association for Computational Linguistics, 2014: 437-442.
[本文引用: 1]
[5]
WAGNER J, ARORA P, CORTES S, et al. DCU: aspect-based polarity classification for SemEval task 4 [C]// Proceedings of the 8th International Workshop on Semantic Evaluation. Dublin: Association for Computational Linguistics, 2014: 223–229.
[本文引用: 1]
[6]
TANG D, QIN B, LIU T. Aspect level sentiment classification with deep memory network [EB/OL]. (2016-09-24)[2022-04-01]. https://arxiv.org/pdf/1605.08900.pdf.
[本文引用: 1]
[7]
CHEN P, SUN Z, BING L, et al. Recurrent attention network on memory for aspect sentiment analysis [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics, 2017: 452-461.
[本文引用: 1]
[8]
MA D, LI S, ZHANG X, et al. Interactive attention networks for aspect-level sentiment classification [EB/OL]. (2017-09-04)[2022-04-01].https://arxiv.org/pdf/1709.00893.pdf.
[本文引用: 1]
[9]
ZENG B, YANG H, XU R, et al LCF: a local context focus mechanism for aspect-based sentiment classification
[J]. Applied Sciences , 2019 , 9 (16 ): 3389
DOI:10.3390/app9163389
[本文引用: 1]
[10]
SONG Y, WANG J, JIANG T, et al. Attentional encoder network for targeted sentiment classification [EB/OL]. (2019-04-01)[2022-04-01]. https://arxiv.org/pdf/1902.09314.pdf.
[本文引用: 1]
[12]
SONG W, WEN Z, XIAO Z, et al Semantics perception and refinement network for aspect-based sentiment analysis
[J]. Knowledge-Based Systems , 2021 , 214 : 106755
DOI:10.1016/j.knosys.2021.106755
[本文引用: 1]
[13]
宋威, 温子健 基于特征双重蒸馏网络的方面级情感分析
[J]. 中文信息学报 , 2021 , 35 (7 ): 126 - 133
[本文引用: 1]
SONG Wei, WEN Zi-jian Feature dual distillation network for aspect-based sentiment analysis
[J]. Journal of Chinese Information Processing , 2021 , 35 (7 ): 126 - 133
[本文引用: 1]
[14]
毛腾跃, 郑志鹏, 郑禄 基于改进自注意力机制的方面级情感分析
[J]. 中南民族大学学报:自然科学版 , 2022 , 41 (1 ): 94 - 100
[本文引用: 1]
MAO Teng-yue, ZHENG Zhi-peng, ZHENG Lu Aspect-level sentiment analysis based on improved self-attention mechanism
[J]. Journal of South-Central University for Nationalities: Natural Science Edition , 2022 , 41 (1 ): 94 - 100
[本文引用: 1]
[15]
SUN K, ZHANG R, MENSAH S, et al. Aspect-level sentiment analysis via convolution over dependency tree [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: Association for Computational Linguistics, 2019: 5679-5688.
[本文引用: 2]
[16]
HUANG B, CARLEY K M. Syntax-aware aspect level sentiment classification with graph attention networks [EB/OL]. (2019-09-05)[2022-04-01]. https://arxiv.org/pdf/1909.02606.pdf.
[本文引用: 1]
[17]
ZHANG C, LI Q, SONG D. Aspect-based sentiment classification with aspect-specific graph convolutional networks [EB/OL]. (2019-10-13)[2022-04-01]. https://arxiv.org/pdf/1909.03477.pdf.
[本文引用: 1]
[18]
WANG K, SHEN W, YANG Y, et al. Relational graph attention network for aspect-based sentiment analysis [EB/OL]. (2020-04-26)[2022-04-01]. https://arxiv.org/pdf/2004.12362.pdf.
[本文引用: 2]
[19]
TANG H, JI D, LI C, et al. Dependency graph enhanced dual-transformer structure for aspect-based sentiment classification [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . Online: Association for Computational Linguistics, 2020: 6578-6588.
[本文引用: 2]
[20]
VASWANI A, SHAZEER N, PARMAR N, et al Attention is all you need
[J]. Advances in Neural Information Processing systems , 2017 , 30
[本文引用: 1]
[21]
LI R, CHEN H, FENG F, et al. Dual graph convolutional networks for aspect-based sentiment analysis [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing . Online: Association for Computational Linguistics, 2021: 6319-6329.
[本文引用: 3]
[22]
LI Y, SUN X, WANG M. Embedding extra knowledge and a dependency tree based on a graph attention network for aspect-based sentiment analysis [C]// 2021 International Joint Conference on Neural Networks . Shenzhen: IEEE, 2021: 1-8.
[本文引用: 1]
[23]
张合桥, 苟刚, 陈青梅 基于图神经网络的方面级情感分析
[J]. 计算机应用研究 , 2021 , 38 (12 ): 3574 - 3580
[本文引用: 1]
ZHANG He-qiao, GOU Gang, CHEN Qing-mei Aspect-based sentiment analysis based on graph neural network
[J]. Application Research of Computers , 2021 , 38 (12 ): 3574 - 3580
[本文引用: 1]
[24]
韩虎, 吴渊航, 秦晓雅 面向方面级情感分析的交互图注意力网络模型
[J]. 电子与信息学报 , 2021 , 43 (11 ): 3282 - 3290
[本文引用: 2]
HAN Hu, WU Yuan-hang, QIN Xiao-ya An interactive graph attention networks model for aspect-level sentiment analysis
[J]. Journal of Electronics and Information Technology , 2021 , 43 (11 ): 3282 - 3290
[本文引用: 2]
[25]
夏鸿斌, 顾艳, 刘渊 面向特定方面情感分析的图卷积过度注意(ASGCN-AOA)模型
[J]. 中文信息学报 , 2022 , 36 (3 ): 146 - 153
[本文引用: 1]
XIA Hong-bin, GU Yan, LIU Yuan Graph convolution overattention(ASGCN-AOA) model for specific aspects of sentiment analysis
[J]. Journal of Chinese Information Processing , 2022 , 36 (3 ): 146 - 153
[本文引用: 1]
[26]
PONTIKI M, GALANIS D, PAVLOPOULOS J, et al, SemEval-2014 task 4: aspect based sentiment analysis [C]// Proceedings of the 8th International Workshop on Semantic Evaluation . Dublin: Association for Computational Linguistics, 2014: 27–35.
[本文引用: 1]
[27]
DONG L, WEI F, TAN C, et al. Adaptive recursive neural network for target-dependent twitter sentiment classification [C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics . Baltimore: Association for Computational Linguistics, 2014: 49–54.
[本文引用: 1]
[28]
MRINI K, DERNONCOURT F, TRAN Q, et al. Rethinking self-attention: an interpretable self-attentive encoder-decoder parser [EB/OL]. (2020-10-29)[2022-04-01]. https://arxiv.org/pdf/1911.03875.pdf.
[本文引用: 1]
[29]
PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . Doha: Association for Computational Linguistics, 2014: 1532-1543.
[本文引用: 1]
[30]
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2019-05-24)[2022-04-01]. https://arxiv.org/pdf/1810.04805.pdf.
[本文引用: 1]
1
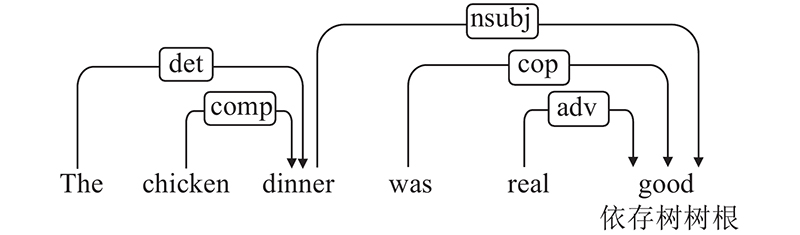
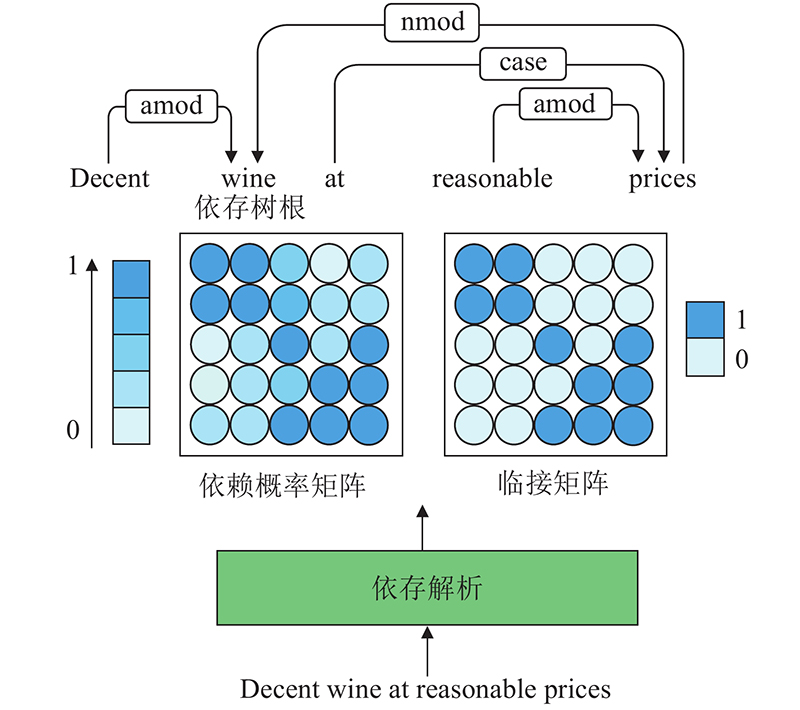
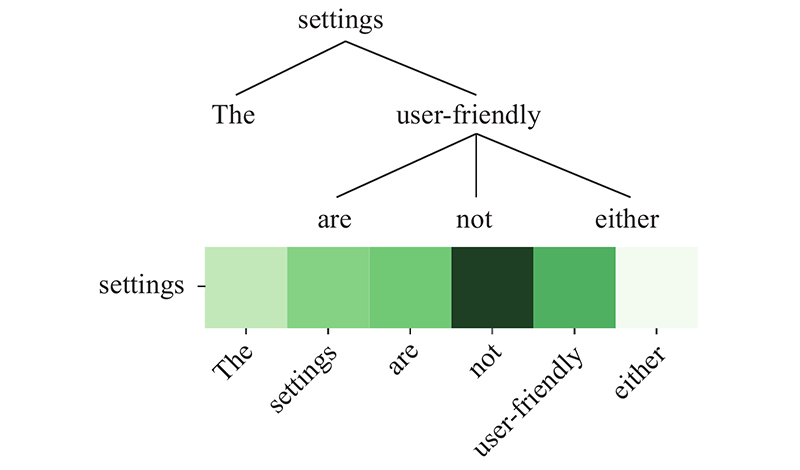
... 解决方面级情感分析任务的关键是如何准确地建立方面词与对应意见词的联系. 例句中“price”和“service”对应的意见词分别为“reasonable”和“poor”. 直观上,方面词与意见词在句法上关系密切. 为了更好地利用句法信息,研究者致力于在依存树上应用图卷积网络(graph convolutional network,GCN)[1 ] 和图注意力网络(graph attention network,GAN)[2 ] 获取方面词的情感特征. 依存解析可以将顺序结构的句子转化为1棵依存树,该树可以被视为1张图. 树中的每个节点对应句子中的1个单词,节点与节点之间由关系类型连接. 简单地将GCN应用于依存树上来解决方面级情感分析任务存在2个主要缺点:1)忽略了关系类型的重要性.Schlichtkrull等[3 ] 证实利用知识图谱中实体之间的关系能够有效提升模型推理性能.GCN 在进行卷积操作获取相邻节点的信息时,将每个相邻节点视为同等重要,导致有价值的信息与噪声具有相同的权重. 实际上,某些关系类型对应的节点可能不重要,甚至是噪声. 2)GCN的性能取决于依存解析的准确性. GCN在依存树上进行卷积操作以采集信息,结构错误的依存树会影响GCN采集信息的准确性导致其性能下降. 由于在线输入数据的句法不规范以及依存解析器的性能局限,基于GCN的模型在实际生产中的性能将不可避免地下降. ...
1
... 解决方面级情感分析任务的关键是如何准确地建立方面词与对应意见词的联系. 例句中“price”和“service”对应的意见词分别为“reasonable”和“poor”. 直观上,方面词与意见词在句法上关系密切. 为了更好地利用句法信息,研究者致力于在依存树上应用图卷积网络(graph convolutional network,GCN)[1 ] 和图注意力网络(graph attention network,GAN)[2 ] 获取方面词的情感特征. 依存解析可以将顺序结构的句子转化为1棵依存树,该树可以被视为1张图. 树中的每个节点对应句子中的1个单词,节点与节点之间由关系类型连接. 简单地将GCN应用于依存树上来解决方面级情感分析任务存在2个主要缺点:1)忽略了关系类型的重要性.Schlichtkrull等[3 ] 证实利用知识图谱中实体之间的关系能够有效提升模型推理性能.GCN 在进行卷积操作获取相邻节点的信息时,将每个相邻节点视为同等重要,导致有价值的信息与噪声具有相同的权重. 实际上,某些关系类型对应的节点可能不重要,甚至是噪声. 2)GCN的性能取决于依存解析的准确性. GCN在依存树上进行卷积操作以采集信息,结构错误的依存树会影响GCN采集信息的准确性导致其性能下降. 由于在线输入数据的句法不规范以及依存解析器的性能局限,基于GCN的模型在实际生产中的性能将不可避免地下降. ...
1
... 解决方面级情感分析任务的关键是如何准确地建立方面词与对应意见词的联系. 例句中“price”和“service”对应的意见词分别为“reasonable”和“poor”. 直观上,方面词与意见词在句法上关系密切. 为了更好地利用句法信息,研究者致力于在依存树上应用图卷积网络(graph convolutional network,GCN)[1 ] 和图注意力网络(graph attention network,GAN)[2 ] 获取方面词的情感特征. 依存解析可以将顺序结构的句子转化为1棵依存树,该树可以被视为1张图. 树中的每个节点对应句子中的1个单词,节点与节点之间由关系类型连接. 简单地将GCN应用于依存树上来解决方面级情感分析任务存在2个主要缺点:1)忽略了关系类型的重要性.Schlichtkrull等[3 ] 证实利用知识图谱中实体之间的关系能够有效提升模型推理性能.GCN 在进行卷积操作获取相邻节点的信息时,将每个相邻节点视为同等重要,导致有价值的信息与噪声具有相同的权重. 实际上,某些关系类型对应的节点可能不重要,甚至是噪声. 2)GCN的性能取决于依存解析的准确性. GCN在依存树上进行卷积操作以采集信息,结构错误的依存树会影响GCN采集信息的准确性导致其性能下降. 由于在线输入数据的句法不规范以及依存解析器的性能局限,基于GCN的模型在实际生产中的性能将不可避免地下降. ...
1
... 经典的方面级情感分析方法分为基于机器学习的方法和基于深度学习的方法. 基于机器学习的方法中比较经典的有支持向量机算法[4 -5 ] ,该算法的性能十分依赖人工设计的特征. 基于深度学习的方法无需人工设计特征,能够有效地捕捉方面词和上下文单词之间的语义关系,受到越来越多的关注. 基于深度学习的方法主要分为基于注意力的方法和基于句法的方法. ...
1
... 经典的方面级情感分析方法分为基于机器学习的方法和基于深度学习的方法. 基于机器学习的方法中比较经典的有支持向量机算法[4 -5 ] ,该算法的性能十分依赖人工设计的特征. 基于深度学习的方法无需人工设计特征,能够有效地捕捉方面词和上下文单词之间的语义关系,受到越来越多的关注. 基于深度学习的方法主要分为基于注意力的方法和基于句法的方法. ...
1
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
1
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
1
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
LCF: a local context focus mechanism for aspect-based sentiment classification
1
2019
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
1
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
Aspect-based sentiment classification with multi-attention network
1
2020
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
Semantics perception and refinement network for aspect-based sentiment analysis
1
2021
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
基于特征双重蒸馏网络的方面级情感分析
1
2021
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
基于特征双重蒸馏网络的方面级情感分析
1
2021
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
基于改进自注意力机制的方面级情感分析
1
2022
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
基于改进自注意力机制的方面级情感分析
1
2022
... 该类方法通过注意力机制使得模型能够找到与方面词对应的意见词,得到方面词的情感极性. Tang等[6 ] 提出深层记忆网络,解决了传统SVM以及LSTM在方面级情感分析中无法明确捕捉每个上下文单词的重要性的问题. Chen等[7 ] 将多重注意力与循环神经网络(recurrent neural network,RNN)相结合,获得了远距离的情感特征,减弱了近距离无关信息的影响. 为了更好地学习方面词和上下文单词的特征表示,Ma等[8 ] 提出交互注意力机制,弥补了单独只针对方面词建模的不足. Zeng等[9 ] 提出上下文动态掩码(context dynamic mask,CDM)和上下文动态权重(context dynamic weighting,CDW)2种方法,给予了局部上下文单词更多的关注,避免了远距离噪声的影响. Song等[10 ] 使用基于注意力的编码器来模拟上下文和目标的连接,解决使用RNN难以记录长期特征的问题. Xu等[11 ] 提出使用内部和级间注意机制的多注意力网络,解决了当方面词包含多个单词时基于注意力的模型会导致信息丢失的问题. Song等[12 ] 提出的语义感知和细化网络能够提取信息丰富的局部语义特征,解决了注意力机制容易引入噪声,不利于捕捉重要情感表示的问题. 宋威等[13 ] 使用门控机制构建双重蒸馏网络,解决注意力机制易致方面词与上下文单词的错误搭配而引入额外噪声的问题. 毛腾跃等[14 ] 改进自注意力机制,使其在训练时能够挖掘出句子中地低频情感词. 然而基于注意力的方法无法有效地利用句子中蕴含的句法信息,容易引入噪声. ...
2
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
... 将 ARGCN 模型与先进的基线模型进行比较:1)CDT[15 ] 在依存解析器生成的依存树上应用GCN提取方面词的情感特征;2)R-GAT[18 ] 重构依存树,去除冗余信息的同时使方面词作为依存树的根节点,扩展原始的GAN添加关系注意力机制;3)DGEDT[19 ] 使用GCN处理图特征并使用Transfor-mer处理平面特征,使用BiAffine机制融合2个模块的特征;4)DualGCN[21 ] 使用SynGCN捕获句法信息,利用SemGCN捕获语义信息,设计差异化正则器和正交正则器以提升模型性能;5)IGATs[24 ] 使用图注意力网络捕获句法依存信息,通过交互注意力机制对方面词和上下文单词之间的语义关系进行建模. ...
1
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
1
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
2
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
... 将 ARGCN 模型与先进的基线模型进行比较:1)CDT[15 ] 在依存解析器生成的依存树上应用GCN提取方面词的情感特征;2)R-GAT[18 ] 重构依存树,去除冗余信息的同时使方面词作为依存树的根节点,扩展原始的GAN添加关系注意力机制;3)DGEDT[19 ] 使用GCN处理图特征并使用Transfor-mer处理平面特征,使用BiAffine机制融合2个模块的特征;4)DualGCN[21 ] 使用SynGCN捕获句法信息,利用SemGCN捕获语义信息,设计差异化正则器和正交正则器以提升模型性能;5)IGATs[24 ] 使用图注意力网络捕获句法依存信息,通过交互注意力机制对方面词和上下文单词之间的语义关系进行建模. ...
2
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
... 将 ARGCN 模型与先进的基线模型进行比较:1)CDT[15 ] 在依存解析器生成的依存树上应用GCN提取方面词的情感特征;2)R-GAT[18 ] 重构依存树,去除冗余信息的同时使方面词作为依存树的根节点,扩展原始的GAN添加关系注意力机制;3)DGEDT[19 ] 使用GCN处理图特征并使用Transfor-mer处理平面特征,使用BiAffine机制融合2个模块的特征;4)DualGCN[21 ] 使用SynGCN捕获句法信息,利用SemGCN捕获语义信息,设计差异化正则器和正交正则器以提升模型性能;5)IGATs[24 ] 使用图注意力网络捕获句法依存信息,通过交互注意力机制对方面词和上下文单词之间的语义关系进行建模. ...
Attention is all you need
1
2017
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
3
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
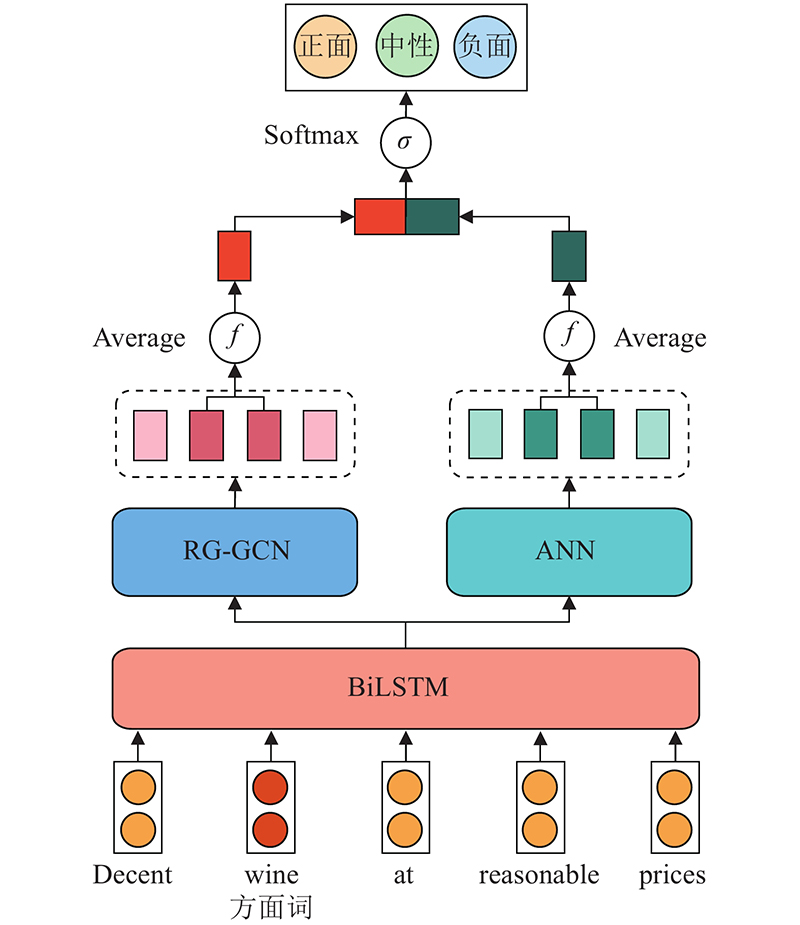
... 为了让 ARGCN 有更好的性能,RG-GCN 和 AAN 捕获的特征应该尽可能不相同.为此,引入差异正则化器[21 ] (differential regulazier)对特征进行约束,计算过程为 ...
... 将 ARGCN 模型与先进的基线模型进行比较:1)CDT[15 ] 在依存解析器生成的依存树上应用GCN提取方面词的情感特征;2)R-GAT[18 ] 重构依存树,去除冗余信息的同时使方面词作为依存树的根节点,扩展原始的GAN添加关系注意力机制;3)DGEDT[19 ] 使用GCN处理图特征并使用Transfor-mer处理平面特征,使用BiAffine机制融合2个模块的特征;4)DualGCN[21 ] 使用SynGCN捕获句法信息,利用SemGCN捕获语义信息,设计差异化正则器和正交正则器以提升模型性能;5)IGATs[24 ] 使用图注意力网络捕获句法依存信息,通过交互注意力机制对方面词和上下文单词之间的语义关系进行建模. ...
1
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
基于图神经网络的方面级情感分析
1
2021
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
基于图神经网络的方面级情感分析
1
2021
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
面向方面级情感分析的交互图注意力网络模型
2
2021
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
... 将 ARGCN 模型与先进的基线模型进行比较:1)CDT[15 ] 在依存解析器生成的依存树上应用GCN提取方面词的情感特征;2)R-GAT[18 ] 重构依存树,去除冗余信息的同时使方面词作为依存树的根节点,扩展原始的GAN添加关系注意力机制;3)DGEDT[19 ] 使用GCN处理图特征并使用Transfor-mer处理平面特征,使用BiAffine机制融合2个模块的特征;4)DualGCN[21 ] 使用SynGCN捕获句法信息,利用SemGCN捕获语义信息,设计差异化正则器和正交正则器以提升模型性能;5)IGATs[24 ] 使用图注意力网络捕获句法依存信息,通过交互注意力机制对方面词和上下文单词之间的语义关系进行建模. ...
面向方面级情感分析的交互图注意力网络模型
2
2021
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
... 将 ARGCN 模型与先进的基线模型进行比较:1)CDT[15 ] 在依存解析器生成的依存树上应用GCN提取方面词的情感特征;2)R-GAT[18 ] 重构依存树,去除冗余信息的同时使方面词作为依存树的根节点,扩展原始的GAN添加关系注意力机制;3)DGEDT[19 ] 使用GCN处理图特征并使用Transfor-mer处理平面特征,使用BiAffine机制融合2个模块的特征;4)DualGCN[21 ] 使用SynGCN捕获句法信息,利用SemGCN捕获语义信息,设计差异化正则器和正交正则器以提升模型性能;5)IGATs[24 ] 使用图注意力网络捕获句法依存信息,通过交互注意力机制对方面词和上下文单词之间的语义关系进行建模. ...
面向特定方面情感分析的图卷积过度注意(ASGCN-AOA)模型
1
2022
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
面向特定方面情感分析的图卷积过度注意(ASGCN-AOA)模型
1
2022
... Sun等[15 -16 ] 将GCN、GAN应用在依存树上生成方面词的情感特征表示,能够有效利用依存解析的信息减弱噪声的影响. Zhang等[17 ] 采用带有注意机制的 GCN来获取与方面词相关的上下文特征,减弱了句法不相关的上下文单词对情感极性预测的影响. Wang等[18 ] 以方面词为根节点重构依存树,有效地降低了依存树的冗余度. Tang等[19 ] 进行了GCN和Transformer[20 ] 之间的特征交互学习,使得模型能够获得更好的顺序特征和图型特征. Li等[21 ] 使用2个GCN分别同时提取句法信息和语义信息,减弱了在线数据句法复杂性引入错误对GCN的影响. Li等[22 ] 将GAN嵌入外部知识和句法关系,可以更好地整合句法关系来理解句子. 张合桥等[23 ] 提出结合句子依存树和单词序列信息建立句子关系图模型,解决了模型缺乏解释相关句法约束和远程单词依赖的问题. 韩虎等[24 ] 提出交互图注意力网络模型,考虑了方面词和上下文单词的位置信息,解决了注意力权重分配不合理的问题. 夏鸿斌等[25 ] 将注意-过度注意机制引入图卷积神经网络中,以发掘居中长距离单词与相关句法约束间的依存关系. 上文中基于句法的深度学习方法并未有效利用依存解析产生的关系类型信息,并且性能易受依存解析准确性的影响. ...
1
... 在 数据集SemEval 2014[26 ] 、Twitter[27 ] 上评估模型的性能,其中SemEval 2014包含2个数据集:Restaurant、Laptop. 数据集的样本标签分布如表1 所示. 表中,N tr 为训练集样本标签的数量;N te 为测试集样本标签的数量. ...
1
... 在 数据集SemEval 2014[26 ] 、Twitter[27 ] 上评估模型的性能,其中SemEval 2014包含2个数据集:Restaurant、Laptop. 数据集的样本标签分布如表1 所示. 表中,N tr 为训练集样本标签的数量;N te 为测试集样本标签的数量. ...
1
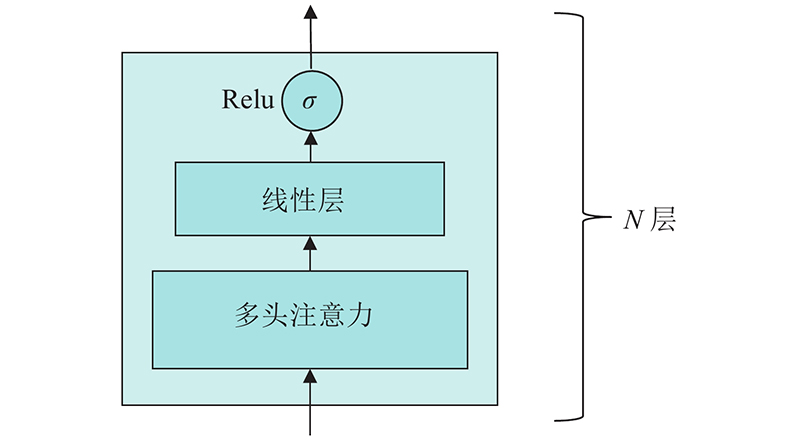
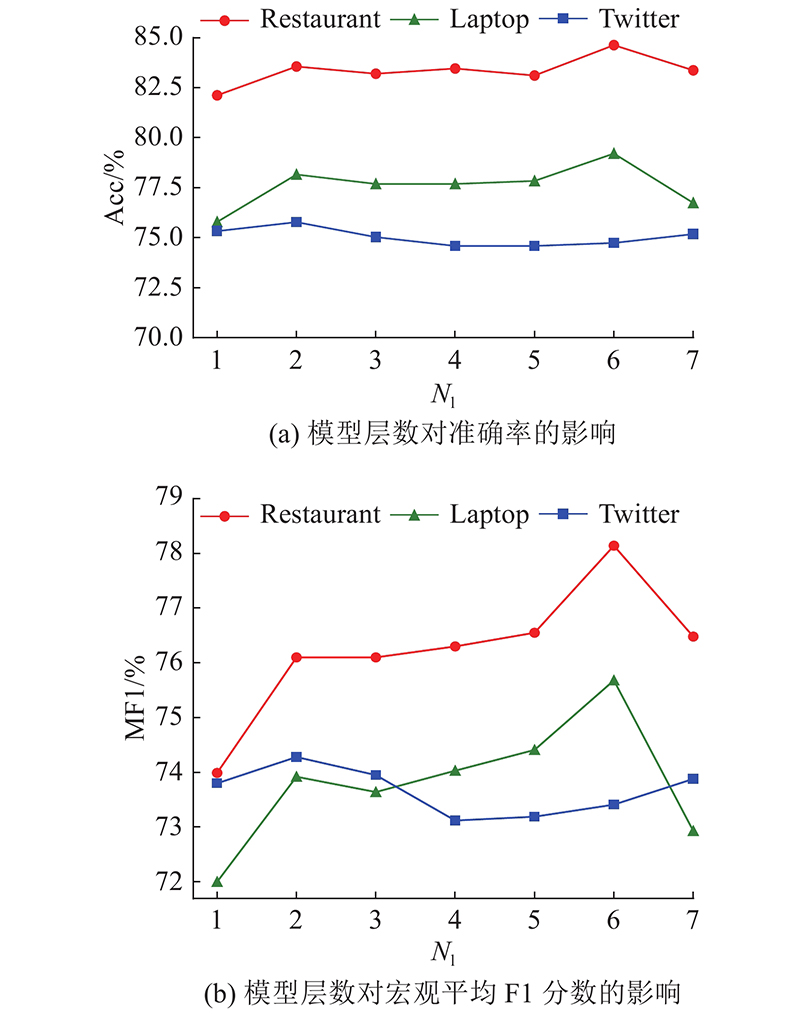
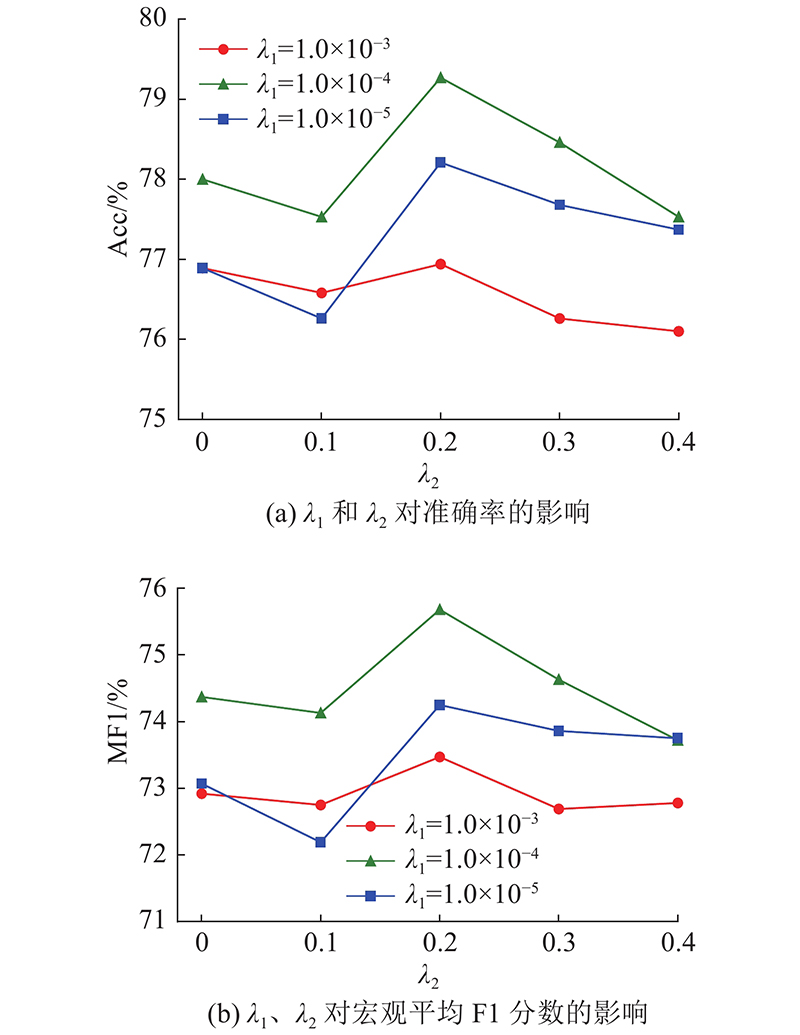
... 使用LAL-Parser[28 ] 作为依存解析器,300维的GLoVe[29 ] 词嵌入向量用于初始化词嵌入矩阵. 在实验中不仅使用词嵌入,还使用位置嵌入、词性嵌入和关系嵌入,其中关系嵌入被RG-GCN用于计算节点信息的权重,这3个嵌入向量的维度均设置为30. 拼接词嵌入、位置嵌入和词性嵌入中获得的向量作为嵌入层的输出和 BiLSTM 的输入. BiLSTM、RG-GCN和AAN输出的隐藏状态向量的维度均设置为100. 为了缓解过拟合,将BiLSTM、RG-GCN和AAN的随机失活(dropout)参数 设置为 0.7. 实验全程保持 RG-GCN 和 AAN 的层数相同. 对于数据集Restaurant 、 Laptop,设置RG-GCN 和 AAN 的层数为 6;对于 Twitter 数据集,设置层数为 2. 模型中所有参数的初始化值服从均匀分布. 使用 Adam 优化器并设置其学习率为 ${1.0 \times 10^{ - 3}}$ . 设置模型训练轮数为50,批次大小为16. 设置正则化系数 ${\lambda _1}$ ${\lambda _2}$ ${1.0 \times 10^{ - 4}}$ . 对于ARGCN +BERT[30 ] ,使用英文版的“bert-base-uncased”预训练模型,设置RG-GCN和AAN的层数为6,其余参数与ARGCN模型的参数一致. ...
1
... 使用LAL-Parser[28 ] 作为依存解析器,300维的GLoVe[29 ] 词嵌入向量用于初始化词嵌入矩阵. 在实验中不仅使用词嵌入,还使用位置嵌入、词性嵌入和关系嵌入,其中关系嵌入被RG-GCN用于计算节点信息的权重,这3个嵌入向量的维度均设置为30. 拼接词嵌入、位置嵌入和词性嵌入中获得的向量作为嵌入层的输出和 BiLSTM 的输入. BiLSTM、RG-GCN和AAN输出的隐藏状态向量的维度均设置为100. 为了缓解过拟合,将BiLSTM、RG-GCN和AAN的随机失活(dropout)参数 设置为 0.7. 实验全程保持 RG-GCN 和 AAN 的层数相同. 对于数据集Restaurant 、 Laptop,设置RG-GCN 和 AAN 的层数为 6;对于 Twitter 数据集,设置层数为 2. 模型中所有参数的初始化值服从均匀分布. 使用 Adam 优化器并设置其学习率为 ${1.0 \times 10^{ - 3}}$ . 设置模型训练轮数为50,批次大小为16. 设置正则化系数 ${\lambda _1}$ ${\lambda _2}$ ${1.0 \times 10^{ - 4}}$ . 对于ARGCN +BERT[30 ] ,使用英文版的“bert-base-uncased”预训练模型,设置RG-GCN和AAN的层数为6,其余参数与ARGCN模型的参数一致. ...
1
... 使用LAL-Parser[28 ] 作为依存解析器,300维的GLoVe[29 ] 词嵌入向量用于初始化词嵌入矩阵. 在实验中不仅使用词嵌入,还使用位置嵌入、词性嵌入和关系嵌入,其中关系嵌入被RG-GCN用于计算节点信息的权重,这3个嵌入向量的维度均设置为30. 拼接词嵌入、位置嵌入和词性嵌入中获得的向量作为嵌入层的输出和 BiLSTM 的输入. BiLSTM、RG-GCN和AAN输出的隐藏状态向量的维度均设置为100. 为了缓解过拟合,将BiLSTM、RG-GCN和AAN的随机失活(dropout)参数 设置为 0.7. 实验全程保持 RG-GCN 和 AAN 的层数相同. 对于数据集Restaurant 、 Laptop,设置RG-GCN 和 AAN 的层数为 6;对于 Twitter 数据集,设置层数为 2. 模型中所有参数的初始化值服从均匀分布. 使用 Adam 优化器并设置其学习率为 ${1.0 \times 10^{ - 3}}$ . 设置模型训练轮数为50,批次大小为16. 设置正则化系数 ${\lambda _1}$ ${\lambda _2}$ ${1.0 \times 10^{ - 4}}$ . 对于ARGCN +BERT[30 ] ,使用英文版的“bert-base-uncased”预训练模型,设置RG-GCN和AAN的层数为6,其余参数与ARGCN模型的参数一致. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}