

目前人体定位追踪的技术主要有:全球定位系统(global positioning system,GPS)、计算机视觉、雷达、红外和射频识别(radio frequency identification,RFID)等. GPS是一种基于人造卫星的定位系统,可实现10 m以内的定位误差,然而,由于建筑物对信号的阻挡和室内定位精度要求高,GPS不能完全满足室内定位的需求. 可以采用计算机视觉的方法使用RGB-D摄像头对人员进行定位跟踪[1],但摄像头会涉及到侵犯用户隐私,而且易受光线的影响. 雷达是一种采用无线电信号反射来探测物体的技术,需要定制的硬件并且无法完成细粒度识别,不适合用于日常使用[2]. 红外技术利用人体热量的辐射来定位和跟踪[3],容易受环境温度影响且对细微移动不敏感,经常出现错误检测. RFID是通过电磁传输到射频兼容集成电路来存储和检索数据的方法[4],无须对设备进行改造,具有成本低、非侵入和细粒度等优点,非常适用于室内人员追踪,因此近几年被广泛应用于室内定位.
基于RFID有设备定位和追踪的研究,在过去十几年中已有学者提出了许多有效的方法. Ni等[5]根据功率信号与距离的关系建立模型,此法精度低且需要大量标签. Yang等[6]针对已知路径的定位,建立差分全息图. Shen等[7]利用旋转天线收集动态数据,获得更多定位信息,该方法缺点是旋转天线所占面积过大. 梁笑轩等[8]利用相控阵天线的非测距方法实现RFID标签定位. 马雪松等[9]和顾军华等[10]均改进了VIRE算法,但是均缺少实际的测试结果. Liu等[11]利用相位轮廓峰谷进行定位,缺点是需要天线移动才能实现,局限性强. 虽然有设备定位和追踪相比无设备受环境影响更小,实现起来相对容易,但是必须要求用户携带相应的传感器或通信设备,对于用户来说,经常会发生设备的遗忘和丢失问题,还须有意识地配合或者愿意佩戴设备,同意分享自己的位置信息,非常不便捷. 因此基于RFID无设备人员的定位追踪具有较明显的优势. Ruan等[12]建立了隐马尔科夫模型,使用Viterbi算法解析信号,构造发射矩阵和转移矩阵较困难. Liu等[13]提出相对相位包裹整数方法,并采用最小二乘法优化标签数和精度. Xiao等[14]和Han等[15]均使用成对的标签实现追踪定位,极大地增加了标签量. Ma等[16]提出改进粒子群的追踪定位算法,但是该方法必须要布置2个正交的标签阵列才能实现. 这些研究大多使用了较多的标签布置在环境中,未考虑多标签对环境和系统造成的影响,会让人在视觉上感到不适,还会产生标签碰撞而丢失许多数据[17].
现代社会老龄化加剧,独居老年人的监护是如今面临的重大问题. 人体的无设备追踪可以较直观地让监护者观察到老人的日常生活路线,该场景要求系统:1)不能侵犯用户的隐私,例如安装摄像头和监听器;2)以较小的误差追踪用户;3)无须用户佩戴定位装置,它会影响体验感;4)减小环境中的标签,过多标签在视觉上会令人不适. 上面提到的GPS、计算机视觉和雷达等方法不能满足该场景的应用,考虑到RFID使用便捷、读取距离较远和成本较低等优点,研究基于RFID的少标签无设备追踪方法,解决监护独居老人的生活路线问题. 以减小跟踪误差和标签数量为目标,设计从多个模型中择优的方法来减少标签,并通过实例验证方法的有效性.
1. 问题描述
RFID无设备人员追踪的任务可以描述为,在RFID监控区域内,阅读器天线发出射频信号,无源标签获得信号中的能量并反射给天线. 当有人体干扰射频信号时,原来的信号强度会衰减或增强,标签获得的能量会发生改变,利用这一特性建立人体移动与信号变化的模型,通过对输入信号序列处理后输出人体真实移动路径.
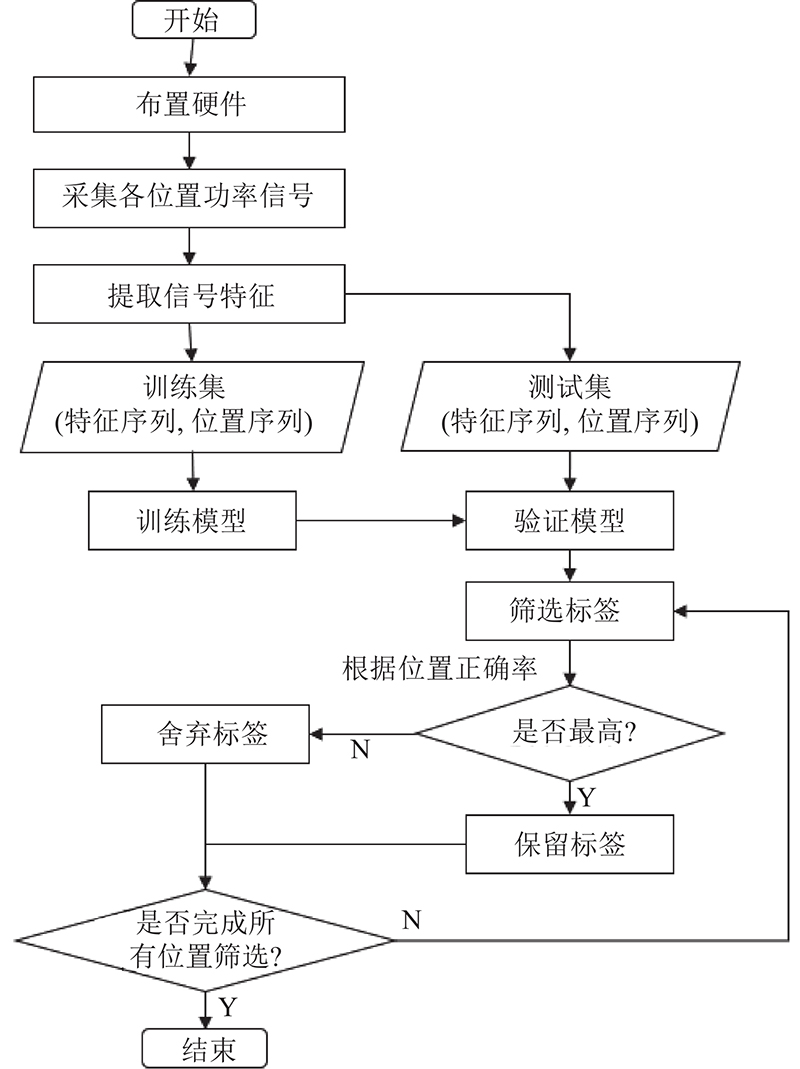
难点与关键技术:1)由于受环境影响,功率信号变化范围大且不稳定,如直接用来训练深度学习模型会使得跟踪效果较差;2)目前深度学习模型种类多,不同结构和训练方式效果不同,如何根据当前任务选择两者是一个难点;3)现有的研究大多未考虑标签使用量的问题,多数是因为系统本身受限,减少标签会造成系统追踪或定位误差提升,还会造成阅读器的漏读次数增加、环境过于复杂和系统计算量庞大等问题,如何使用数量相对少的标签是该研究的难点. 传统的追踪系统通常为一个整体,耦合度大,控制标签数量是一个非常棘手的问题. 本研究目的在于,建立低耦合度的系统,由若干个标签训练出的若干个模型组成,然后为每个位置选择出精度最高的标签,最后得到标签数量最优的追踪系统,择优标签方法流程图如图1所示. 为了使模型有良好的追踪效果,须找到合适的功率信号处理方式,使数据的分布由稀疏变为密集;分析不同模型结构的优劣,对比不同训练方式下的效果;通过对所有标签都建立模型,根据追踪效果择优,去除效果较差的标签. 最后在复杂的居住环境中进行测试,验证方法的有效性.
图 1
2. 功率信号特征提取
多径效应[18]会引起功率信号变化不稳定,导致其难以用来追踪人体,本研究找到一种将功率信号的分布由离散转变成密集的方式,目的是使模型更好地建立目标位置和信号之间的映射关系.
接收的信号强度指示(received signal strength indication, RSSI)为标签反射的功率信号,它在一定程度上反映了天线与标签之间的距离. 在理想环境中,利用RSSI可以建立起标签与天线之间的距离关系,不过,由于多径效应的影响,使用RSSI定位和追踪目标是一项巨大的挑战. 未经处理的RSSI无法直接作为训练的数据,因为在复杂的环境中其会呈现极度的不确定性,功率信号波动较大,直接将原始的信号用来建模是不可靠的[19],原因是RSSI不稳定,分布过于稀疏,须找到合适的信号特征,使数据更密集便于模型训练.
2.1. 区域划分
为了准确地追踪人体,而且考虑到追踪范围仅限于RFID的监控区域,采取相对定位方式,对监控区域进行网格划分,人体在监控区域内的位置可以由集合
2.2. 特征计算
为了将原始RSSI的分布变得更加密集,在不破坏数据真实值的情况下,提取一段RSSI的均值和方差,使其更密集. 当阅读器发现监控区域内有目标出现时,RSSI的分布开始变化,系统不断地采集这些RSSI并存入计算机中作为训练数据.由于监控区域内存在N个标签,即每个标签都会反射回1个信号给天线,可以得到1个RSSI矩阵,大小为N×T,其中T为采样数,N为标签数. 对RSSI进行平均值和方差的特征抽取,让测试者站在监控区域内的不同位置Li,Li∈ L*,然后天线不断地采集RSSI,读取软件使用VIKITEK公司提供的C#语言接口开发.
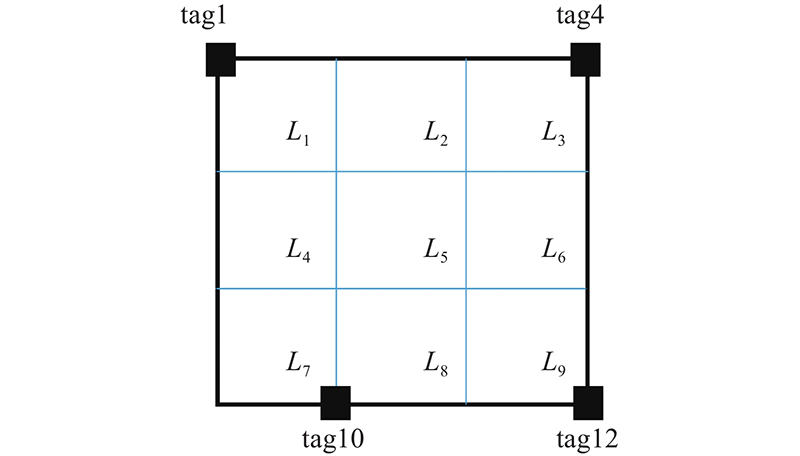
该系统使用N个列表对象来存储这些RSSI,代表每个标签收集到的RSSI. 考虑到使用的阅读器每秒对每个标签的平均读取数为60次,所以每当列表的长度超过30时(根据每0.5 s采集到的RSSI可以推断出1个位置编号),求这30个RSSI的平均值和方差,RSSI均值和方差的提取如图2所示. 图中,Avg为信号的均值,Var为方差. 提取一段时间内信号的均值和方差的目的在于:一段时间内RSSI的均值和方差可以较好地表达该段数据的分布情况,而且增加了数据的特征有利于训练,并且模型会将该段RSSI的分布与所在位置建立映射关系,训练出的模型能更好地量化RSSI特征与位置的关系.测试在1.8 m×1.8 m大小的区域进行,将其分为9个网格,网格大小为60 cm×60 cm,每个网格对应1个位置编号(L1~L9),在区域的外围放置12个相同型号的RFID超高频无源电子标签,天线摆放在距离区域1.5 m处. 该研究对所有位置进行了测试,在开始测试时,区域内没有任何人出现,研究人员控制阅读器下达读取指令,收集区域内12个标签的RSSI,持续5 min,对0.5 s内读取到的RSSI提取平均值和方差特征后存放在计算机硬盘中. 在收集完无人的情况后,让受试者站在区域内的每个网格内,重复之前的操作,测试人员在监控区域内采集信号,如图3所示. 该做法的目的是为了研究区域内有人和无人时的RSSI分布,以及人在不同位置时的RSSI分布.
图 2
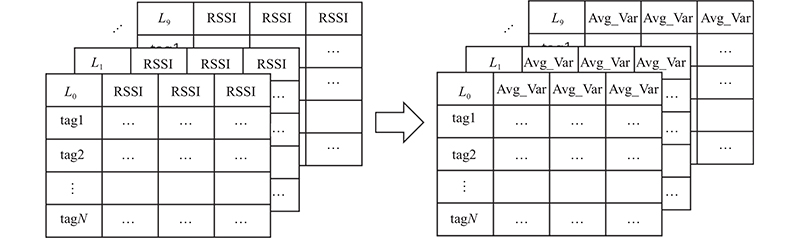
图 3
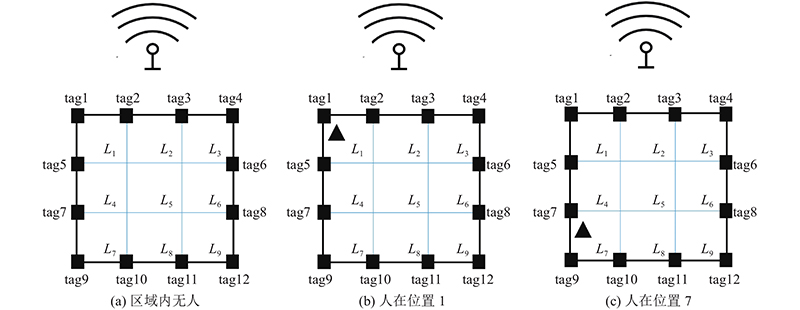
图 4
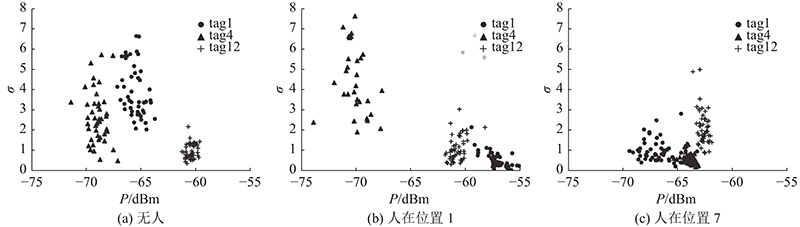
图 4 人对功率信号特征分布的影响
Fig.4 Human influence on distribution of power signal features
3. 模型选择
为了能更准确地解析RSSI时序序列,对各类模型进行分析,选择出最适合用于解决人体追踪的模型. 与一个静止的人员相比,动态的人员存在着不可预测性,对其定位更加具有挑战. 在监控区域内,人的移动会影响RSSI变化,由于RSSI变化的不稳定性,跟踪目标更加困难. 另一方面,由于人体的移动速度受限,下一时刻移动到的位置只可能在当前位置的附近,即缩小了下一时刻候选位置的范围. 总的来说,在跟踪人员的问题上,除了采集到的RSSI之外,系统还会根据当前人员的位置状态推断下一时刻的位置状态. 在人员跟踪的任务中,如何能将已知的RSSI矩阵X=[x1, x2
循环神经网络(recurrent neural network, RNN)具有输出序列的能力,作为生成模型,它在每一个时刻都会输出给定输入RSSI情况下所有位置状态的可能性,可以将输入序列转化为输出序列,且序列前后具有一定关联,本研究采用循环神经网络对RSSI矩阵进行解析. 循环神经网络结构如图5所示. 图中,h为隐层状态向量.给定单个输入RSSI矩阵和输出位置矩阵对(Xi,Yi),对数概率P(Yi | Xi)的表达式为
图 5
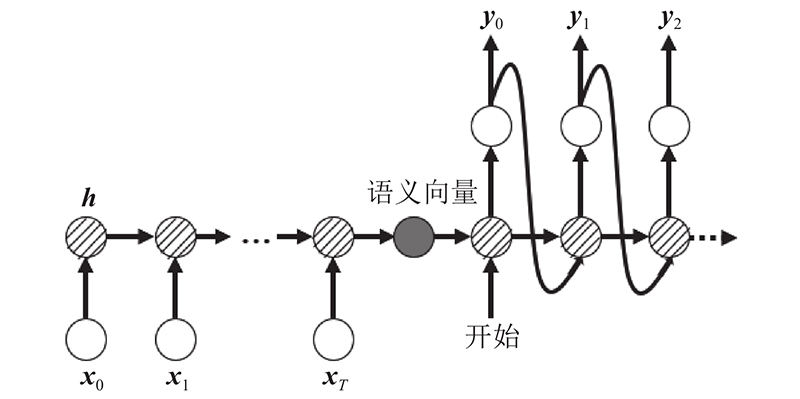
式中:Yi为由长度为T的位置状态y1, y2
式(1)的后部分由神经网络参数
式中:
3.1. seq2seq解析RSSI序列
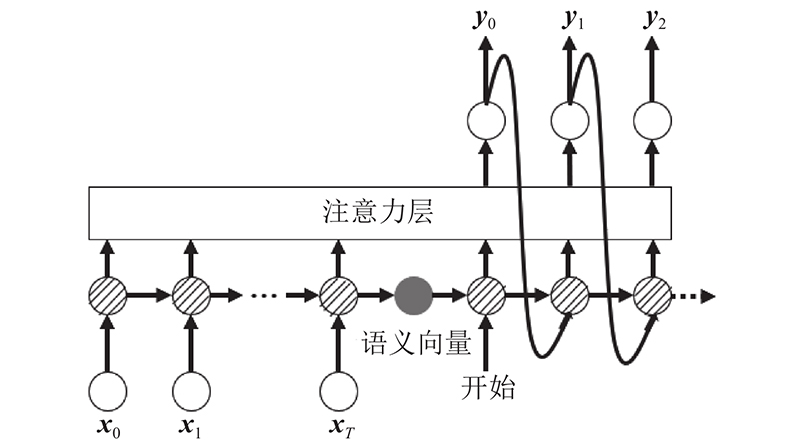
针对输入和输出序列的长度有时会不一致的问题,将2个循环神经网络进行连接得到seq2seq(sequence-to-sequence)模型,其优势在于高灵活性,适合用来解决追踪任务中序列长度不统一的问题.
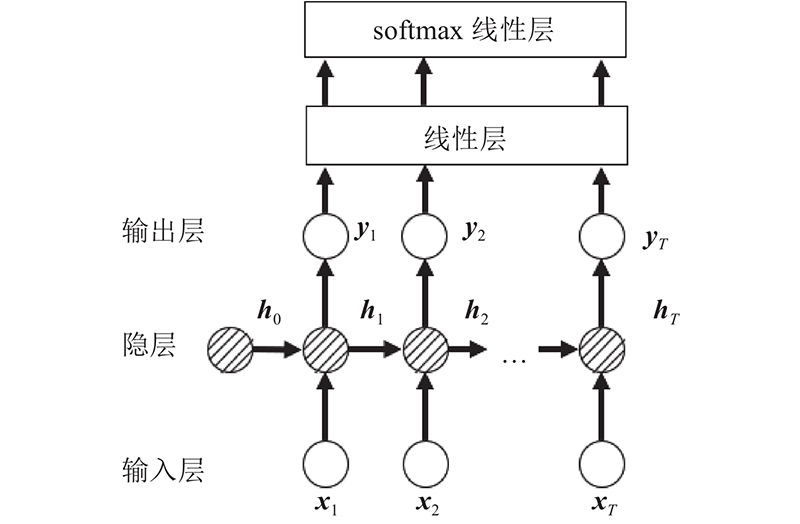
seq2seq结构如图6所示,其本质上是由一个编码器和解码器构成的[20],编码器和解码器都可以用循环神经网络或它的变种(长短期记忆网络(long short-term memory, LSTM)[21]或门控循环单元(gated recurrent unit, GRU)[22])充当,它的优势在于输入与输出长度可以不必相同,而且相比传统循环神经网络具有更好的记忆力,更加适合用于人员追踪任务. 为了使RSSI序列更好地适应模型的输入,RSSI序列须通过词嵌入[23]扩展成1个多维的列向量,随后经过编码器生成1个语义大小为H的隐层状态向量,由式(3)中的非线性函数激活产生,随后把hT传给解码器. hT向量记录着原始RSSI序列的所有信息,用于后续协助解码器获得更准确的位置序列S.
图 6
3.2. 添加注意力机制
由于seq2seq结构仍然存在不足,在处理较长的RSSI特征序列时,语义向量的长度限制就成了解析路径轨迹的瓶颈,原因是它装不下那么多原始的信息,会造成精度下降[23],另外,原始seq2seq模型的编码器只使用了最后1层的隐状态hT,造成对原始数据的利用率极低. 为了减小以上影响,对解码器引入注意力机制.
图 7
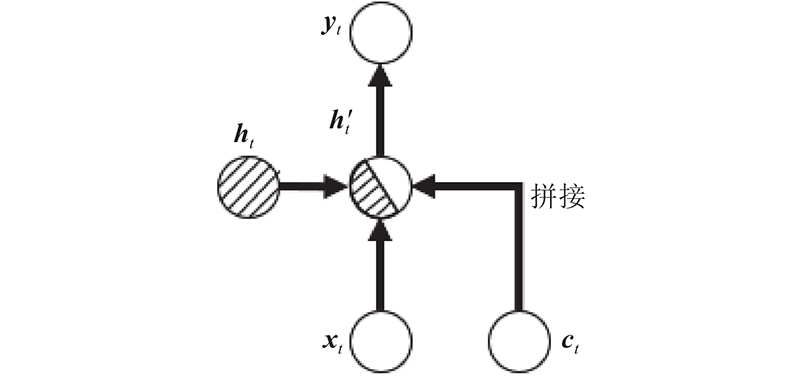
图 7 额外信息与隐层拼接的添加
Fig.7 Addition of additional information and splicing with hidden layers
图 8
式中:s'为编码器长度,
利用权值a(t)计算所有隐层状态加权和ct:
将得到的ct与解码器中t时刻原始的隐层向量ht进行拼接:
式中:Wc为全连接矩阵,目的是将拼接向量的维度降低.
将
式中:softmax
注意力计算过程如图9所示.
图 9
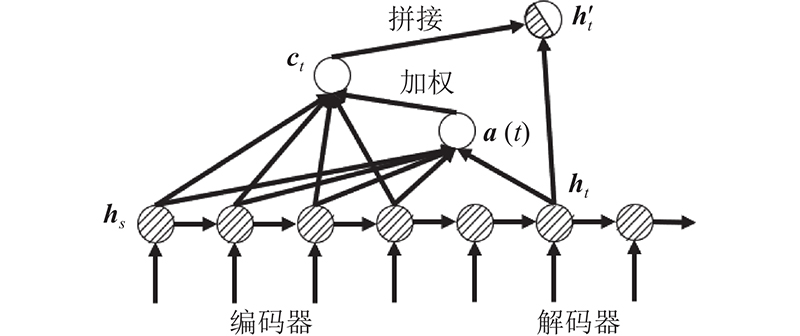
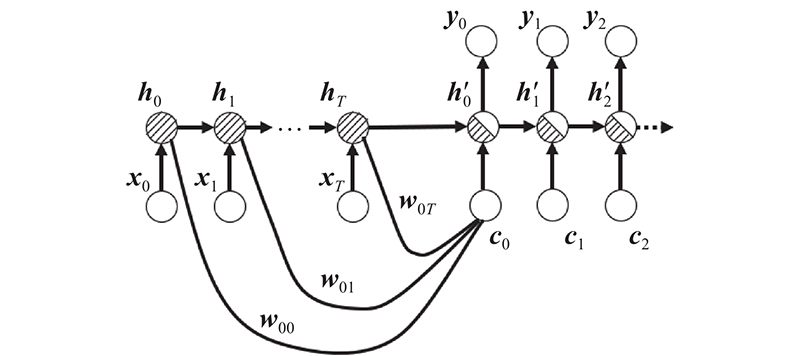
注意力机制相当于在seq2seq结构上进行了包装,计算解码器和编码器的分数和注意力向量ct,给解码器加入额外信息提高处理长路径序列的性能,seq2seq加注意力结构如图10所示.
图 10
3.3. 分析模型训练的方式
为了降低训练时间,提升模型效果,使用6种训练方式,最后选择了训练时间短、正确率高的训练方式. 模型的编码器和解码器的2个部分被联合训练,训练目标是最大化对数似然函数. 神经网络的训练任务通常是使用梯度下降法来寻找一组模型参数
训练模型所使用的损失函数如下:
式中:M为数据量. 使用损失函数是为了更好地反映模型的训练情况,模型损失函数的值越低越好.
seq2seq结构在训练时存在一个问题,模型的解码器会使用上一时刻的输出yt−1作为当前时刻t的输入,即yt−1→xt.如果某一时刻的位置预测错误,那么这个错误的位置编号会作为输入传入模型,并且可能被迅速放大,发生蝴蝶效应.因此,本研究使用scheduled sampling方法[24],以弥合位置序列预测任务的训练和推断之间的差距,让模型逐步处理自己的错误,从而提升泛化能力. 基本思想为在每个训练期间随机决定取值,使用抛硬币确定输入,如图11所示,图中,yt−1为真实值,y' t−1为模型推测值. 在不同的训练次数epoch使用不同的p,有p的概率选取yt−1,1−p的概率选取y' t−1. 总是使用自身的推断结果会表现得很糟糕,而偶尔使用自身推测结果有助于消除过拟合[21]. 本研究采用以下4种方式来表示p随着epoch的变化,如图12所示.设k为总的epoch,i为当前epoch,4种衰减变化的表达式如下:
图 11
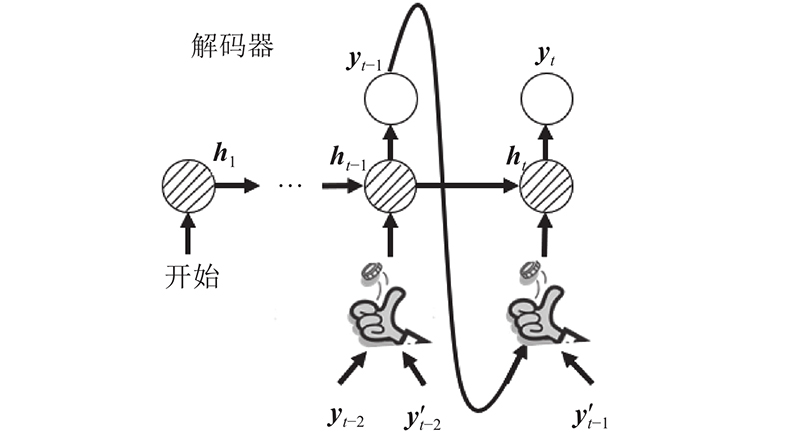
图 11 抛硬币确定输入方法的示意图
Fig.11 Schematic diagram of tossing coin to determine input
图 12
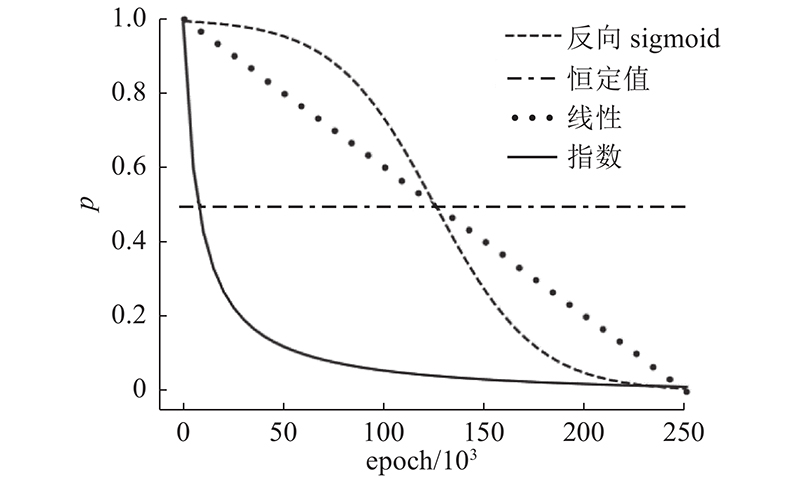
1)线性衰减:
2)指数衰减:
3)反向sigmoid衰减:
4)恒定不变:p=0.5. 该情况下p的值不会变化,选择yt−1或y' t−1的概率为50%.
表 1 不同训练方式的序列正确率
Tab.1
| 训练方式 | A/% | ttrain/min |
| 自身推断 | 86.36 | 145.6 |
| 真实标签 | 86.60 | 145.6 |
| 线性衰减 | 88.53 | 123.6 |
| 指数衰减 | 87.25 | 181.4 |
| 恒定值 | 87.55 | 145.6 |
| 反向sigmoid衰减 | 86.23 | 163.5 |
4. 标签布局方式选择
在一个天线的监控区域内放置过多的标签会带来诸多问题,如增加阅读器的读取负担、环境过于复杂和系统的稳定性较弱. 针对这些问题,提出筛选最优标签的方法,根据位置的分类正确率择优选择标签.
在RFID天线信号覆盖的区域内,考虑到一开始不知何种标签布局方式才是最好的,因此采取标签的布局方式如下:在区域外围的所有交点处放置标签. 评判一个标签的布局方式是否良好,主要有2个方面:电子标签的个数和位置分类的正确率.
在监控区域内,每个标签自身都有解析RSS信号的能力,并且对每个位置的解析能力各有不同,为了比较哪一种时序模型单元作为模型的编码器和解码器效果更好,使用RNN、LSTM和GRU这3种最常见的时序模型进行对比. 选择一个3.2 m2、网大小为60 cm×60 cm的区域作为测试区域,系统须训练3N个模型(N为标签个数).在训练完成后观察每一个模型在测试数据集上的表现,测试集是一个含有4000条序列的数据集. 统计所有标签的分类正确率(分别以RNN、GRU和LSTM作为结构单元),如表2~4所示,篇幅受限仅展示部分数据. 当1个标签模型使用不同类型的单元结构作为编码器和解码器时,最终对各个位置的分类正确率均较相近,不过也有个别标签模型对某个位置的正确率相差较大.不同单元在测试集上的错误数量n如图13所示,图中没有数据的部分则表示错误数为0. GRU和LSTM相似(错误数均大于10),RNN表现较好(错误数为5),但也仅在L3和L4,其余位置上的差距不大,所以通过错误数量不能直接区分出3种单元的优劣. 不过通过每个标签在不同位置上的正确率,可以为每个位置编号筛选出1个对其分类正确率最高的标签,称其为“最优标签”,最优标签的布局很明显即是1个区域内的最优标签布局,最后比较3种类型单元训练出的模型各自剩余最优标签的个数. 3种单元在4000条序列和24000个位置上的测试结果如表5所示. 表中,As、Ap分别为序列、位置正确率,No为最优标签个数. 考虑到较少的标签个数可以减少训练模型的时间、计算成本和提高系统稳定性,在相同的区域内尽量使用较少的标签来完成任务,而三者的最终解析正确率相差较小,因此最终选择最优标签个数最少的GRU单元作为编码器和解码器,筛选后的标签布局如图14所示.
表 2 所有标签的分类正确率(RNN作为结构单元)
Tab.2
| 位置 | 标签 | |||||
| tag1 | tag2 | tag3 | tag4 | tag5 | tag6 | |
| L1 | 97.34 | 98.29 | 99.33 | 99.90 | 85.16 | 99.76 |
| L2 | 98.96 | 95.41 | 94.64 | 98.10 | 94.89 | 99.03 |
| L3 | 99.32 | 98.59 | 95.19 | 99.61 | 93.49 | 98.40 |
| L4 | 99.76 | 94.23 | 88.29 | 98.22 | 96.07 | 99.76 |
| L5 | 100.00 | 95.58 | 93.57 | 99.93 | 99.71 | 98.72 |
表 3 所有标签的分类正确率(GRU作为结构单元)
Tab.3
| 位置 | 标签 | |||||
| tag1 | tag2 | tag3 | tag4 | tag5 | tag6 | |
| L1 | 97.05 | 99.38 | 98.81 | 99.38 | 84.44 | 99.71 |
| L2 | 99.17 | 95.79 | 92.68 | 97.79 | 94.72 | 99.55 |
| L3 | 99.47 | 97.13 | 92.42 | 99.12 | 95.14 | 99.12 |
| L4 | 99.73 | 95.53 | 90.54 | 97.40 | 96.41 | 99.69 |
| L5 | 99.81 | 96.21 | 93.48 | 99.78 | 99.66 | 99.37 |
表 4 所有标签的分类正确率(LSTM作为结构单元)
Tab.4
| 位置 | 标签 | |||||
| tag1 | tag2 | tag3 | tag4 | tag5 | tag6 | |
| L1 | 97.05 | 99.38 | 98.81 | 99.38 | 84.44 | 99.71 |
| L2 | 99.17 | 95.79 | 92.68 | 97.79 | 94.72 | 99.55 |
| L3 | 99.47 | 97.13 | 92.42 | 99.12 | 95.14 | 99.12 |
| L4 | 99.73 | 95.53 | 90.54 | 97.40 | 96.41 | 99.69 |
| L5 | 99.81 | 96.21 | 93.48 | 99.78 | 99.66 | 99.37 |
表 5 3种单元在4000条序列和24000个位置的测试结果
Tab.5
| 网络单元 | As/% | Ap/% | No/个 |
| GRU | 99.55 | 99.93 | 4 |
| LSTM | 99.25 | 99.88 | 5 |
| RNN | 99.88 | 99.98 | 6 |
图 13
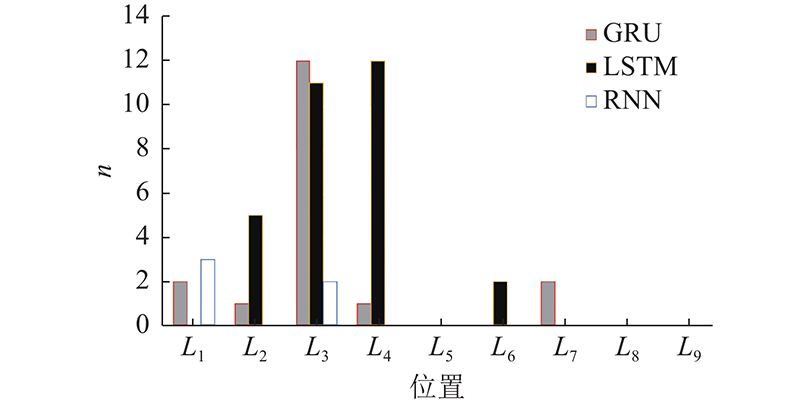
图 14
5. 验证测试
为了验证基于注意力模型的标签筛选方法的有效性,在有较多影响因素的日常环境中测试. 在设计测试环境时,应考虑区域的划分,以及天线的位置,保证尽可能地覆盖所有区域.
测试的基本情况如下:1)在约80 m2的住宅环境中,将每个天线信号覆盖的区域(监控区域)划分成大小不同的矩形子区域,子区域的大小决定了网格的密度和最终的定位误差. 2)标签选择放置在区域边缘,将其贴在墙面上,高度为1 m. 目的是防止家具或其他物体遮挡射频信号. 3)实验使用ImpinjM4无源标签(左)和VFR4读写器(右),如图15所示.读取软件的运行环境为CPU: Intel(R) Core(TM) i5-8300H CPU @ 2.30 GHz,RAM: 8 GB,OS: Win10. 4)实验在一个日常生活环境中进行(由于洗手间的隐私性,不进行测试). 为了测试本研究的追踪方法,共对3条路径进行测试,测试环境中的3条路径如图16所示. 3条路径文字描述如下.
图 15

图 16
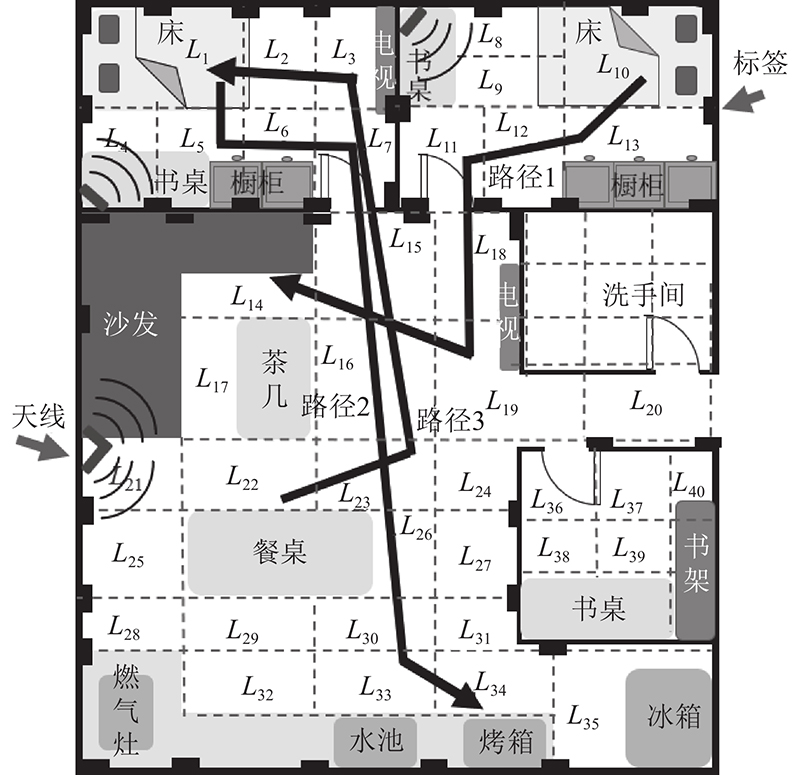
1)路径1:L10→L13→L12→L11→L18→L19→L16→L15→L14表示用户从卧室的床上起来到沙发上;
2)路径2:L1→L5→L6→L7→L15→L16→L23→L26→L30→L33→L34表示用户从书房的书桌起身回卧室;
3)路径3:L39→L36→L19→L16→L15→L7→L3→L2→L1表示用户从床上起来去烤箱拿烘烤完的食物.
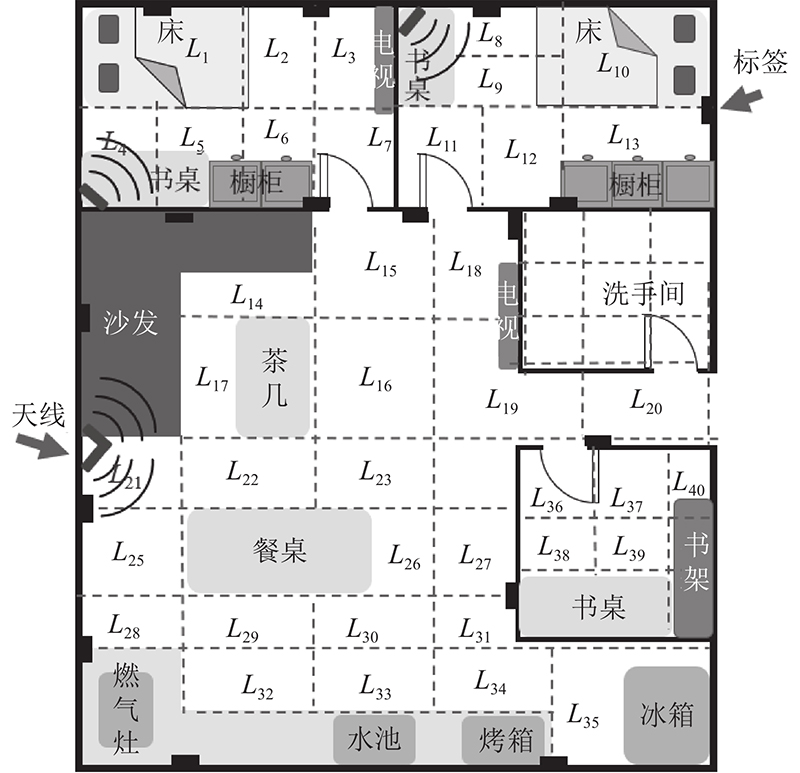
测试人员对每个路径重复测试30次,使用不同类型的单元作为模型的编码器和解码器(scheduled sampling的训练方式均为线性衰减),紧接着对每个天线的监控区域进行最优标签的筛选,择优后最优标签布局如图17所示. 在使用GRU、LSTM和RNN作为编码器和解码器时,模型的平均跟踪误差分别为0.19 、0.22、0.28 m.实验使用多种p的衰减方式,得到不同训练方式的跟踪误差,其中p以线性衰减的方式得到的效果最好,为0.19 m.
图 17
与当前较先进的RFID跟踪系统比较,Wallsense、Twins和KNN-HMM的平均跟踪误差分别为0.24、0.75、0.64 m,可以看出,seq2seq加注意力模型得到的平均跟踪误差最低. 在标签用量方面,统计上述3种方法在图16的测试环境中所需要的标签数量,与本研究所提出的方法对比,择优标签方法的标签用量比Wallsense、Twins和KNN-HMM分别少了大约71.4%、82.8%和66.7%,说明该方法在标签用量上有较大的减少.
6. 结果分析
Twins方法的实现,须将2个标签进行绑定,视作1个标签,即增加了1倍的标签量,而择优标签方法只要在一定距离内放置1个标签即可. Wallsense的标签布置方法和本研究的方法类似,但标签布置得过于密集,择优标签的方法可以根据需要去掉阵列中的标签,而不会影响最终结果. KNN-HMM方法不仅要将标签布置在区域外围,其内部也需要布置一定量的标签,而择优标签的方法仅须在区域外围布置标签即可.
本研究所提出的择优标签方法,其核心为采集每一个标签反射的RSSI,并提取特征. 提取RSSI特征能更好地利用海量数据,增加模型的学习能力. 将数据分成70%的训练集和30%的测试集,随后各自建立深度学习模型. 在筛选标签阶段,根据各标签模型预测能力的不同,采取“优胜劣汰”机制,保留预测某一位置正确率最高的标签,并将该标签模型与位置对应. 此法可以有效地去除那些解析预测能力弱的标签. 在择优完成后,在实际使用阶段,系统优先使用被选中的标签模型进行人员追踪. 例如:tag1标签模型对应的位置是L3(记为“tag1-L3”),tag2对应L1(记为“tag2-L1”). 若tag1标签模型预测人体的位置是L1,则系统视为预测错误并继续判断下一个模型(tag2)的结果. 若tag1预测结果为L3,则系统视为预测正确.
图 18
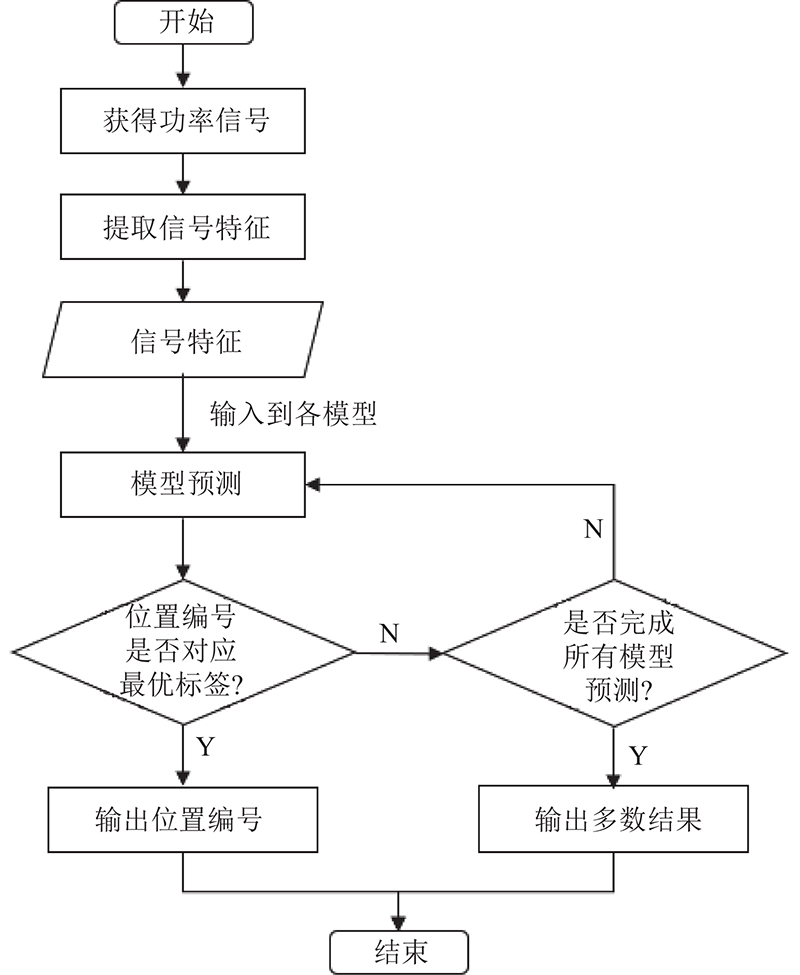
图 18 标签择优后的追踪阶段流程图
Fig.18 Flow chart of tracking stage after optimal tag selection
7. 结 论
为了解决现有人体追踪系统追踪误差大、硬件部署对环境改变大、用户佩戴设备不便等问题,开展了使用RFID实现低误差和少标签方法的研究. 主要研究成果如下.
(1)分析人体对标签反射功率信号的影响,发现人在不同位置上时,每个标签的RSSI特征分布在“均值-方差”二维空间中呈聚集状态.
(2)seq2seq加注意力模型能够较好地学习出RSSI与位置之间的关系,输入与输出序列长度不必统一,且不会出现序列位置跳跃的情况.
(3)提出筛选“最优标签”的方法. 该方法将标签数量作为参数考虑在内,在保证精度的情况下,能有效地减少标签冗余.
不过,多目标会造成RSSI缠绕,存在无法追踪多人轨迹的问题,在后续研究中,还须分析多目标移动与RSSI的关系,寻找一种适合处理多目标的方法,来完成1人以上的轨迹追踪.
参考文献
Recognition and location of typical automotive parts based on the RGB-D camera
[J].DOI:10.1007/s40747-020-00182-z [本文引用: 1]
Detection and localization of people inside vehicle using impulse radio ultra-wideband radar sensor
[J].
Fusion of smartphone motion sensors for physical activity recognition
[J].DOI:10.3390/s140610146 [本文引用: 1]
Survey of wireless indoor positioning techniques and systems
[J].DOI:10.1109/TSMCC.2007.905750 [本文引用: 1]
ANTspin: efficient absolute localization method of RFID tags via spinning antenna
[J].DOI:10.3390/s19092194 [本文引用: 1]
CVIRE-RFID室内定位算法
[J].DOI:10.3969/j.issn.1003-7241.2017.12.012 [本文引用: 1]
CVIRE-RFID indoor positioning algorithm
[J].DOI:10.3969/j.issn.1003-7241.2017.12.012 [本文引用: 1]
基于克里金插值的自适应VIRE室内定位算法研究
[J].DOI:10.3778/j.issn.1002-8331.1709-0242 [本文引用: 1]
Research on adaptive VIRE indoor positioning algorithm based on Kriging interpolation
[J].DOI:10.3778/j.issn.1002-8331.1709-0242 [本文引用: 1]
STPP: spatial-temporal phase profiling-based method for relative RFID tag localization
[J].
RFID 3-D indoor localization for tag and tag-free target based on interference
[J].
One more tag enables fine-grained RFID localization and tracking
[J].
Twins: device-free object tracking using passive tags
[J].
WallSense: device-free indoor localization using wall-mounted UHF RFID tags
[J].DOI:10.3390/s19010068 [本文引用: 2]
多径效应对测向误差的影响
[J].DOI:10.3969/j.issn.1002-7300.2010.01.009 [本文引用: 1]
The influence of multipath effect on direction finding error
[J].DOI:10.3969/j.issn.1002-7300.2010.01.009 [本文引用: 1]
位置指纹算法关键参数的提取
[J].
Extraction of key parameters of location fingerprint algorithm
[J].
A neural model for context-dependent sequence learning
[J].DOI:10.1007/s11063-005-2838-x [本文引用: 1]
LSTM: a search space odyssey
[J].
Short-term residential load forecasting based on LSTM recurrent neural network
[J].DOI:10.1109/TSG.2017.2753802 [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}