Existing community search methods are difficult to deal with the complex and diverse search requirements of users and difficult to integrate network structure and node attributes to measure the correlation between nodes in high-dimensional and sparse heterogeneous information networks (HINs). In order to solve the problems, the community search problem of mutual information maximization over HINs was proposed, the definition of community with mutual information maximization was given, and a corresponding community search method, community search with mutual information maximization (CSMIM) was designed. The user's search requirements were defined as query constraints, and a query constraint deep graph infomax (QC-DGI) model was proposed to learn node embedding by extracting the structure, semantics and node attribute information in HINs to effectively calculate the mutual information between nodes. Then, according to the given query information, the mutual information maximization criterion was used to search the target community. In addition, an optimization strategy based on user feedback was proposed to realize the personalized calculation of mutual information from global to local, so as to improve the accuracy of search results. Finally, extensive experiments on real HINs dataset were performed, and experimental results prove that the proposed method can effectively search the community of a given node according to the search requirements, and has higher accuracy than the representative baseline methods.
Keywords:community search
;
heterogeneous information network
;
network representation learning
;
mutual information
;
query constraint
WANG Ya-feng, ZHOU Li-hua, CHEN Wei, WANG Li-zhen, CHEN Hong-mei. Community search with mutual information maximization over heterogeneous information networks. Journal of Zhejiang University(Engineering Science)[J], 2023, 57(2): 287-298 doi:10.3785/j.issn.1008-973X.2023.02.009
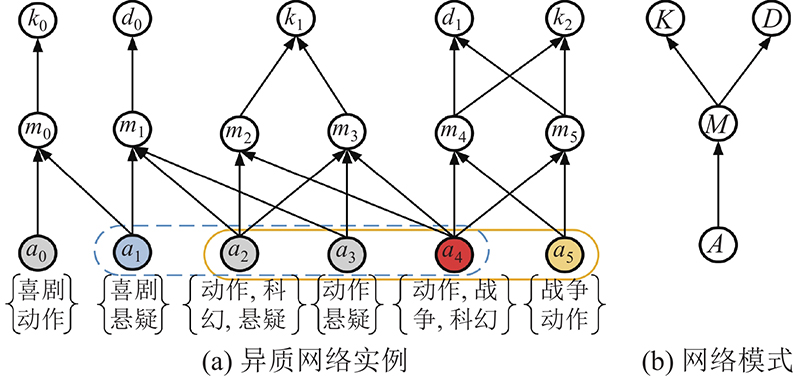
随着信息技术的不断发展,越来越多的研究者将包含多种对象类型且具有不同互连关系的网络数据建模为异质信息网络(heterogeneous information networks, HINs)[1],如互联网电影资料库(internet movie database, IMDB)[2]. 相较于仅包含一种类型的对象和连接的同质信息网络,HINs蕴含了更加丰富的语义信息,能实现对现实世界更完整的抽象.
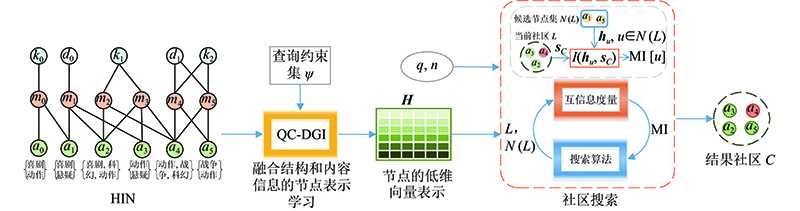
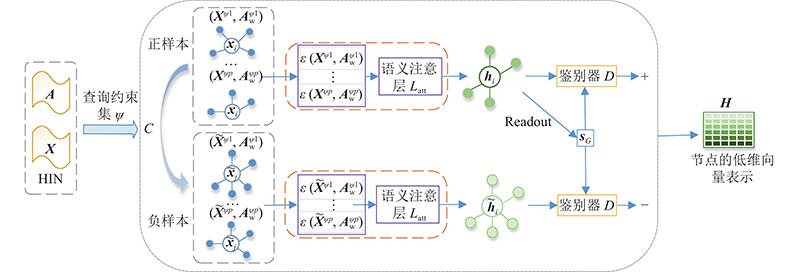
元路径[1]抽取了HINs的子结构,表达了多种对象间特定的语义关系,因此,针对问题1),本研究把每个搜索要求表示为一条元路径,并将其定义为查询约束,用于处理用户复杂多样的搜索要求.针对问题2),本研究利用互信息作为节点间融合网络结构和节点属性信息的相关性指标. 互信息(mutual information, MI)是衡量随机变量之间多维关系的综合度量,能够捕捉到变量间的非线性统计相关性[10-13],在社会网络分析中得到了应用,比如, CommDGI[14](deep community graph infomax)模型在社区检测中利用互信息最大化范式度量社区互信息;异质深度图互信息最大化[2] (heterogeneous deep graph infomax, HDGI)模型利用互信息融合网络结构和节点属性信息度量异质图局部与全局间的相关性. 基于CommDGI和HDGI的思想,本研究设计了应用于HINs的带查询约束的深度图互信息最大化(query constraint deep graph infomax, QC-DGI)模型,通过全面地提取HINs中的结构、语义和属性信息获得节点嵌入来计算节点间的互信息,同时使获得的节点嵌入包含查询约束的特征,有助于更精准地搜索出满足用户需求的社区.
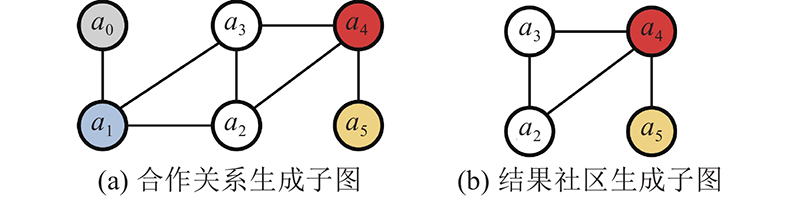
互信息越大的节点间的相关性越高,同一社区中的节点间应具有较高的互信息. 因此,本研究提出异质信息网络的互信息最大化社区搜索问题,给出互信息最大化的社区定义,设计相应的社区搜索方法,互信息最大化社区搜索(community search with mutual information maximization, CSMIM),根据给定的查询信息,利用QC-DGI模型和社区互信息最大化准则定位目标社区. 此外,社区搜索是一个过程化问题,在搜索社区过程中,用户可以根据每次搜索的结果进行调整,使搜索结果更加满足用户需求. 根据用户对社区的反馈,提出基于用户反馈训练局部互信息的交互式社区搜索优化策略,能更加精准地度量节点间的互信息,提高搜索结果的准确率.
7. find $v$ such that $ {\rm{MI}}[v] $ is maximum;
8. if $\left| C \right| < = n$ or ${{ I}_{{\rm{com}}}}(C \cup v) > = {{ I}_{{\rm{com}}}}\left( C \right)$ then
9. add $v$ to $C$ and update $N$;
10. else
11. break;
12. end if
13. end while
14. return $C$.
在算法1中,首先初始化目标社区 $C = \{ q\} $,外壳节点集 $N = \{ u|u \notin C,A_{\rm{w}}^\psi (q,u) \geqslant 1\} $(第1行),通过迭代添加外壳节点集合中与当前社区 $C$的互信息最大的节点 $v \in N$来扩展社区 $C$,直到其节点数达到 $k$或社区互信息不再增大(第2~13行),最后返回社区 $C$(第14行). 算法的时间复杂度为 $O({\left| V \right|^2} \times \log_2\; (\left| V \right|)+{\left| V \right|^2})$,其中 $\left| V \right|$为节点数. 具体来说,首先最外层while循环从外壳节点中找出加入社区的节点需要 $O(\left| V \right|)$,然后计算外壳节点中每个节点与当前社区的互信息(第5~6行)需要 $O(\left| V \right|)$,找互信息最大的节点(第8行)需要 $O(\left| V \right| \cdot \log_2\; (\left| V \right|))$.
3. 社区搜索方法优化
3.1. 交互式互信息最大化社区搜索
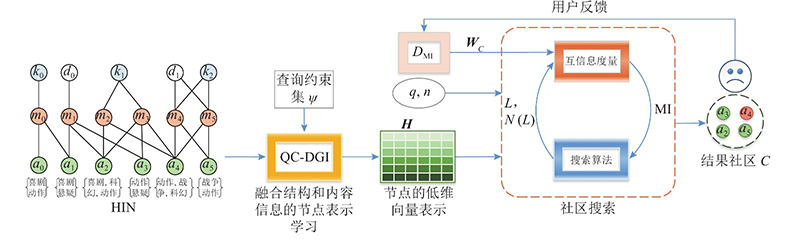
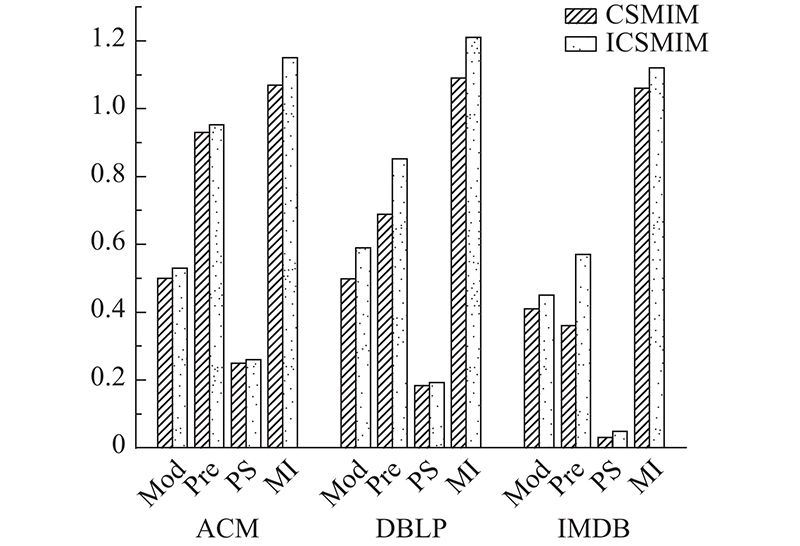
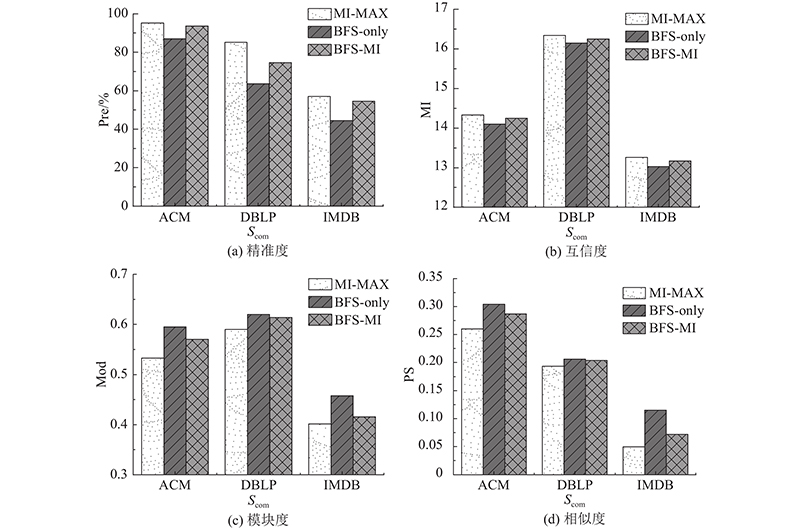
通常,社区搜索是一个逐步优化的过程,用户可以根据每次定位的结果进行调整. 为了使搜索结果更加精准,本研究设计了异质信息网络的用户交互式互信息最大化社区搜索方法(interactive community search with mutual information maximization, ICSMIM),其基本框架如图5所示. ICSMIM搜索通过多轮迭代完成. 第1轮依据CSMIM方法定位社区,用户可以依据定位的社区标记出希望在社区中或不在社区中的节点,生成标记节点集,基于标记节点集指导下一轮的训练和搜索;接下来的每一轮,根据用户反馈,ICSMIM都会通过训练一个有监督的鉴别器 ${{D} _{{\rm M}{\rm I}}}$估计社区互信息,直至定位出用户满意的社区.
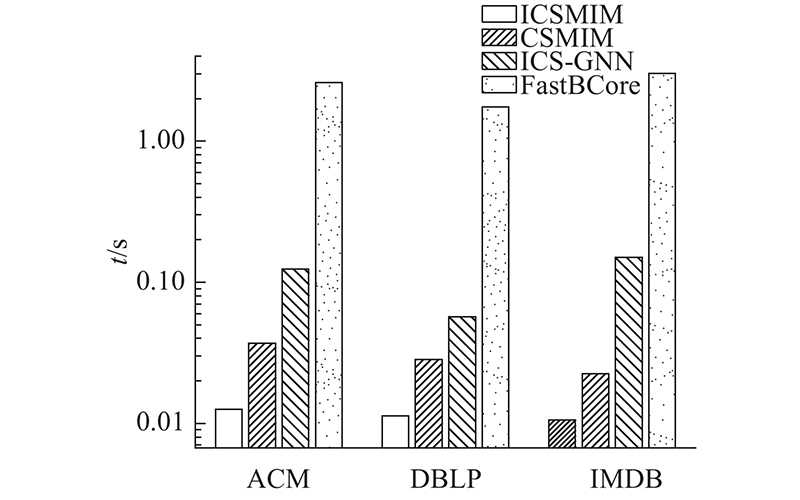
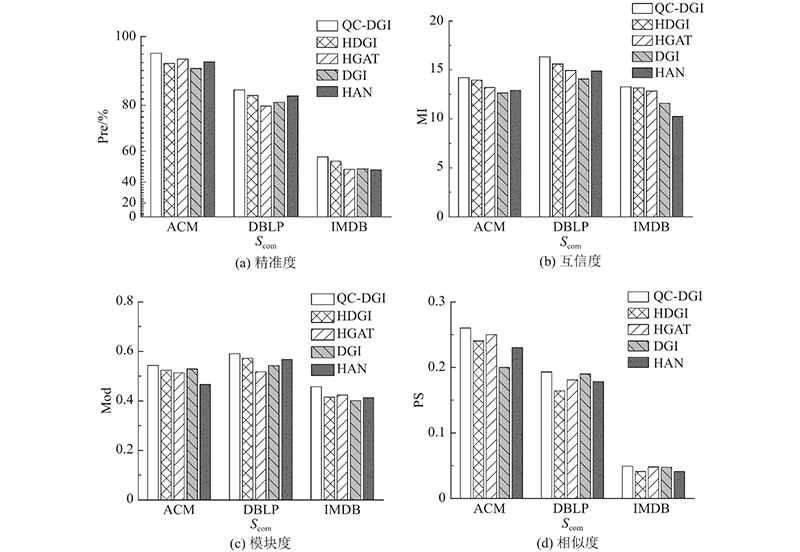
2)对比方法. 与2种社区搜索方法进行比较,包括基于图神经网络训练得分的交互式社区搜索方法(interactive community search via graph neural network, ICS-GNN[11])和基于社区结构(k, ${\mathcal{P}}$)-core的社区搜索方法FastBCore[5].
REN Y, LIU B, HUANG C, et al. Heterogeneous deep graph infomax [C]// 8th International Conference on Learning Representations. New Orleans: ICLR, 2020.
WANG C, PAN S, HU R, et al. Attributed graph clustering: a deep attentional embedding approach [C]// Proceedings of the 28th International Joint Conferences on Artificial Intelligence Organization. Macao: IJCAI, 2019: 3670-3676.
YANG Y, FANG Y, LIN X, et al. Effective and efficient truss computation over large heterogeneous information networks[C]// 2020 IEEE 36th International Conference on Data Engineering (ICDE). [s.l.]: IEEE, 2020: 901-912.
QIAO L, ZHANG Z, YUAN Y, et al. Keyword-centric community search over large heterogeneous information networks [C]// 26th International Conference on Database Systems for Advanced Applications. Taipei: DASFAA, 2021: 158-173.
JIANG Y, RONG Y, CHENG H, et al. Query-driven graph convolutional networks for attributed community search [C]// 48th International Conference on Very Large Databases. Sydney: PVLDB, 2022.
BELGHAZI M I, BARATIN A, RAJESWAR S, et al. MINE: mutual information neural estimation [C]// Proceedings of the 35th International Conference on Machine Learning. Stockholm: ICML, 2018: 531-540.
ZHANG T, XIONG Y, ZHANG J, et al. CommDGI [C]// Proceedings of the 29th ACM International Conference on Information and Knowledge Management. New York: ACM, 2020: 1843-1852.
VELIČKOVIĆ P, FEDUS W, HAMILTON W L, et al. Deep graph infomax [C]// 7th International Conference on Learning Representations. New Orleans: ICLR, 2019.
HJELM R D, FEDOROV A, LAVOIE-MARCHILDON S, et al. Learning deep representations by mutual information estimation and maximization [C]// 7th International Conference on Learning Representations. New Orleans: ICLR, 2019.
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [C]// 5th International Conference on Learning Representations. Toulon: ICLR, 2017.
... 随着信息技术的不断发展,越来越多的研究者将包含多种对象类型且具有不同互连关系的网络数据建模为异质信息网络(heterogeneous information networks, HINs)[1],如互联网电影资料库(internet movie database, IMDB)[2]. 相较于仅包含一种类型的对象和连接的同质信息网络,HINs蕴含了更加丰富的语义信息,能实现对现实世界更完整的抽象. ...
... 元路径[1]抽取了HINs的子结构,表达了多种对象间特定的语义关系,因此,针对问题1),本研究把每个搜索要求表示为一条元路径,并将其定义为查询约束,用于处理用户复杂多样的搜索要求.针对问题2),本研究利用互信息作为节点间融合网络结构和节点属性信息的相关性指标. 互信息(mutual information, MI)是衡量随机变量之间多维关系的综合度量,能够捕捉到变量间的非线性统计相关性[10-13],在社会网络分析中得到了应用,比如, CommDGI[14](deep community graph infomax)模型在社区检测中利用互信息最大化范式度量社区互信息;异质深度图互信息最大化[2] (heterogeneous deep graph infomax, HDGI)模型利用互信息融合网络结构和节点属性信息度量异质图局部与全局间的相关性. 基于CommDGI和HDGI的思想,本研究设计了应用于HINs的带查询约束的深度图互信息最大化(query constraint deep graph infomax, QC-DGI)模型,通过全面地提取HINs中的结构、语义和属性信息获得节点嵌入来计算节点间的互信息,同时使获得的节点嵌入包含查询约束的特征,有助于更精准地搜索出满足用户需求的社区. ...
... 随着信息技术的不断发展,越来越多的研究者将包含多种对象类型且具有不同互连关系的网络数据建模为异质信息网络(heterogeneous information networks, HINs)[1],如互联网电影资料库(internet movie database, IMDB)[2]. 相较于仅包含一种类型的对象和连接的同质信息网络,HINs蕴含了更加丰富的语义信息,能实现对现实世界更完整的抽象. ...
... 元路径[1]抽取了HINs的子结构,表达了多种对象间特定的语义关系,因此,针对问题1),本研究把每个搜索要求表示为一条元路径,并将其定义为查询约束,用于处理用户复杂多样的搜索要求.针对问题2),本研究利用互信息作为节点间融合网络结构和节点属性信息的相关性指标. 互信息(mutual information, MI)是衡量随机变量之间多维关系的综合度量,能够捕捉到变量间的非线性统计相关性[10-13],在社会网络分析中得到了应用,比如, CommDGI[14](deep community graph infomax)模型在社区检测中利用互信息最大化范式度量社区互信息;异质深度图互信息最大化[2] (heterogeneous deep graph infomax, HDGI)模型利用互信息融合网络结构和节点属性信息度量异质图局部与全局间的相关性. 基于CommDGI和HDGI的思想,本研究设计了应用于HINs的带查询约束的深度图互信息最大化(query constraint deep graph infomax, QC-DGI)模型,通过全面地提取HINs中的结构、语义和属性信息获得节点嵌入来计算节点间的互信息,同时使获得的节点嵌入包含查询约束的特征,有助于更精准地搜索出满足用户需求的社区. ...
... 随着信息技术的不断发展,越来越多的研究者将包含多种对象类型且具有不同互连关系的网络数据建模为异质信息网络(heterogeneous information networks, HINs)[1],如互联网电影资料库(internet movie database, IMDB)[2]. 相较于仅包含一种类型的对象和连接的同质信息网络,HINs蕴含了更加丰富的语义信息,能实现对现实世界更完整的抽象. ...
... 元路径[1]抽取了HINs的子结构,表达了多种对象间特定的语义关系,因此,针对问题1),本研究把每个搜索要求表示为一条元路径,并将其定义为查询约束,用于处理用户复杂多样的搜索要求.针对问题2),本研究利用互信息作为节点间融合网络结构和节点属性信息的相关性指标. 互信息(mutual information, MI)是衡量随机变量之间多维关系的综合度量,能够捕捉到变量间的非线性统计相关性[10-13],在社会网络分析中得到了应用,比如, CommDGI[14](deep community graph infomax)模型在社区检测中利用互信息最大化范式度量社区互信息;异质深度图互信息最大化[2] (heterogeneous deep graph infomax, HDGI)模型利用互信息融合网络结构和节点属性信息度量异质图局部与全局间的相关性. 基于CommDGI和HDGI的思想,本研究设计了应用于HINs的带查询约束的深度图互信息最大化(query constraint deep graph infomax, QC-DGI)模型,通过全面地提取HINs中的结构、语义和属性信息获得节点嵌入来计算节点间的互信息,同时使获得的节点嵌入包含查询约束的特征,有助于更精准地搜索出满足用户需求的社区. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}