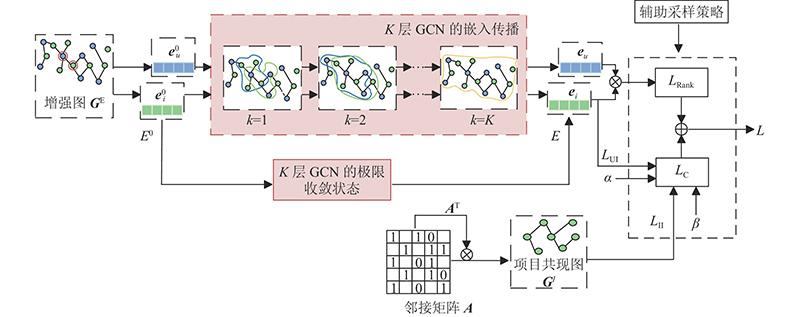
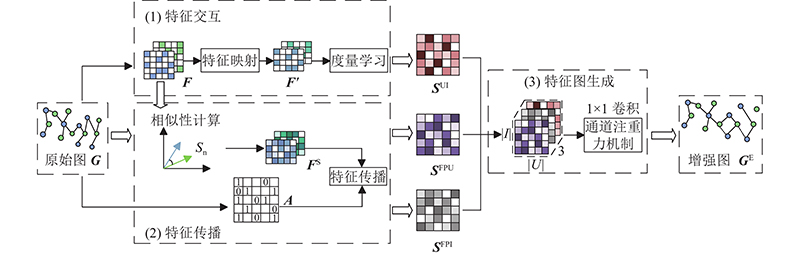
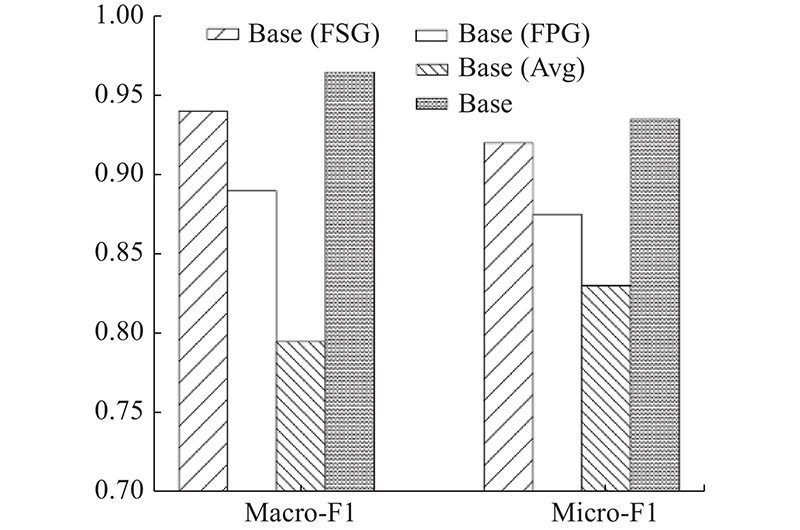
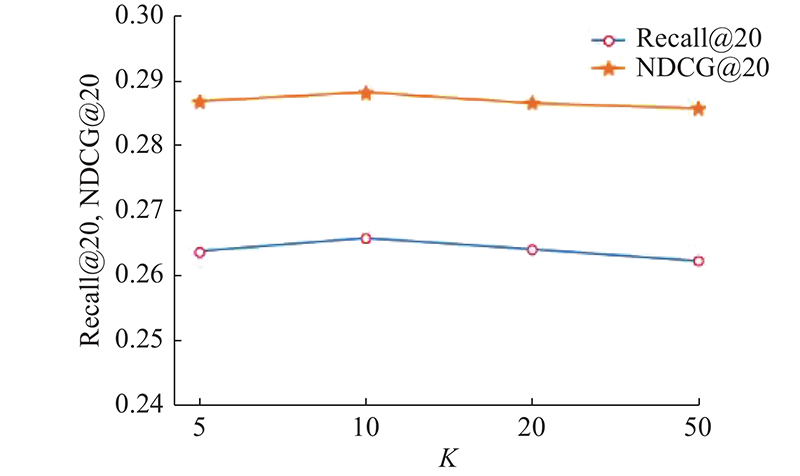
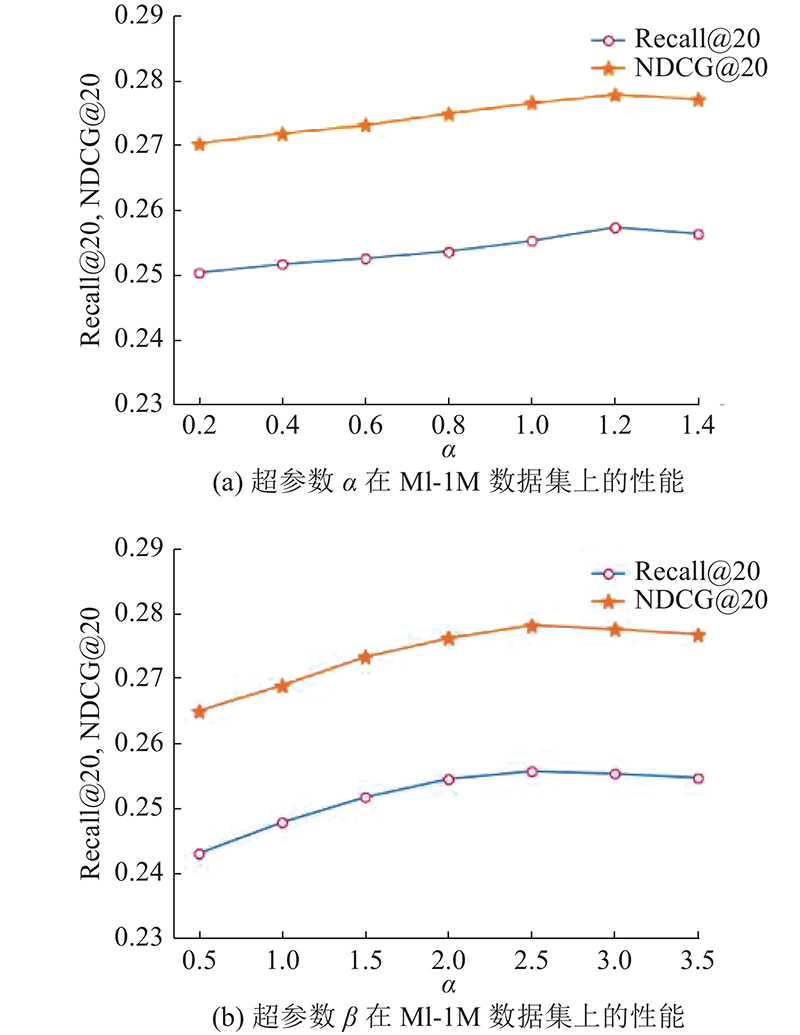
There are two significant problems with existing collaborative filtering (CF) models based on graph convolutional networks (GCNs). Most original graphs have noise and data sparsity problems that can seriously impair the model performance. In addition, for large user project graphs, the explicit message passing in traditional GCNs slows down the convergence speed during training and weakens the training efficiency of the model. A graph convolution collaborative filtering model combing graph enhancement and sampling strategies (EL-GCCF) was proposed to respond to the above two points. In the graph initialization learning module, the structural information and the feature information in the graph were integrated by generating two graph structures. The original graph was enhanced and the noise problem was effectively mitigated. Explicit message passing was skipped because of the multi-task constrained graph convolution. The over-smoothing problem in training was effectively mitigated and the training efficiency of the model was improved by using an auxiliary sampling strategy. Experimental results on two real datasets show that the EL-GCCF model outperforms many mainstream models and has higher training efficiency.
WANG X, HE X, WANG M, et al. Neural graph collaborative filtering [C]// Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Paris: ACM, 2019: 165-174.
SUN J, ZHANG Y, GUO W, et al. Neighbor interaction aware graph convolution networks for recommendation [C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Xi'an: ACM, 2020: 1289-1298.
VERMA V, QU M, KAWAGUCHI K, et al. Graphmix: improved training of gnns for semi-supervised learning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver : ACM, 2021, 35(11): 10024-10032.
HE X, DENG K, WANG X, et al. Lightgcn: simplifying and powering graph convolution network for recommendation [C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Xi'an: ACM, 2020: 639-648.
CHEN L, WU L, HONG R, et al. Revisiting graph based collaborative filtering: a linear residual graph convolutional network approach [C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: ACM, 2020, 34(1): 27-34.
FRANCESCHI L, NIEPERT M, PONTIL M, et al. Learning discrete structures for graph neural networks [C]// International Conference on Machine Learning. Los Angeles: ACM, 2019: 1972-1982.
ZHANG Y, PAL S, COATES M, et al. Bayesian graph convolutional neural networks for semi-supervised classification [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Hawaii: ACM, 2019: 5829-5836.
WANG W, LUO J, SHEN C, et al. A graph convolutional matrix completion method for miRNA-disease association prediction [C]// International Conference on Intelligent Computing. Bari: IEEE, 2020: 201-215.
YU W, QIN Z. Graph convolutional network for recommendation with low-pass collaborative filters [C]// International Conference on Machine Learning. Vienna: ACM, 2020: 10936-10945.
CHEN M, WEI Z, HUANG Z, et al. Simple and deep graph convolutional networks [C]// International Conference on Machine Learning. Vienna: ACM, 2020: 1725-1735.
YING R, HE R, CHEN K, et al. Graph convolutional neural networks for web-scale recommender systems [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. London: ACM, 2018: 974-983.
WU F, SOUZA A, ZHANG T, et al. Simplifying graph convolutional networks [C]// International Conference on Machine Learning. Los Angeles: ACM, 2019: 6861-6871.
ZEILER M D, KRISHNAN D, TAYLOR G W, et al. Deconvolutional networks [C]// Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco: IEEE, 2010: 2528-2535. .
LUO D, CHENG W, YU W, et al. Learning to drop: robust graph neural network via topological denoising [C]// Proceedings of the 14th ACM International Conference on Web Search and Data Mining. Jerusalem: ACM, 2021: 779-787.
LERCHE L, JANNACH D. Using graded implicit feedback for bayesian personalized ranking [C]// Proceedings of the 8th ACM Conference on Recommender Systems. Silicon Valley: ACM, 2014: 353-356.
HE X, LIAO L, ZHANG H, et al. Neural collaborative filtering [C]// Proceedings of the 26th International Conference on World Wide Web. Perth: ACM, 2017: 173-182.
PEROZZI B, AL-RFOU R, SKIENA S. Deepwalk: online learning of social representations [C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York : ACM, 2014: 701-710.
GROVER A, LESKOVEC J. node2vec: scalable feature learning for networks [C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: ACM, 2016: 855-864.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}