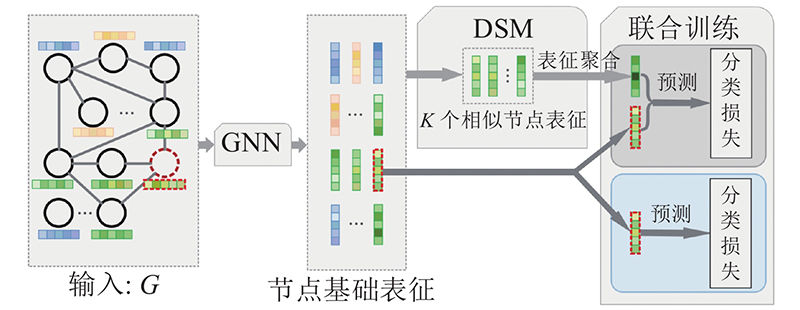
In reality, the structure of most graphs could be noisy, i.e., including some noisy edges or ignoring some edges that exist between nodes in practice. To solve these challenges, a novel differentiable similarity module (DSM), which boosted node representations by digging implict association between nodes to improve the accuracy of node classification, was presented. Basic representation of each target node was learnt by DSM using an ordinary graph neural network (GNN), similar node sets were selected in terms of node representation similarity and the basic representation of the similar nodes was integrated to boost the target node’s representation. Mathematically, DSM is differentiable, so it is possible to combine DSM as plug-in with arbitrary GNNs and train them in an end-to-end fashion. DSM enables to exploit the implicit edges between nodes and make the learned representations more robust and discriminative. Experiments were conducted on several public node classification datasets. Results demonstrated that with GNNs equipped with DSM, the classification accuracy can be significantly improved, for example, GAT-DSM outperformed GAT by significant margins of 2.9% on Cora and 3.5% on Citeseer.
ZENG Ju-xiang, WANG Ping-hui, DING Yi-dong, LAN Lin, CAI Lin-xi, GUAN Xiao-hong. Graph neural network based node embedding enhancement model for node classification. Journal of Zhejiang University(Engineering Science)[J], 2023, 57(2): 219-225 doi:10.3785/j.issn.1008-973X.2023.02.001
本研究实验所使用的数据集为开源的引文网络Cora、Citeseer和Pubmed[20]. 在这3个引文网络中,每个节点表示一篇论文,节点初始特征为该论文对应的词袋特征向量;每条边均为无向边,表示所连接的2篇论文之间具有引用关系;节点的标签代表论文的主题. 如表1所示为3个数据集的重要信息. 表中, $ N 、 M 、 D 、C $分别为节点数、边数、初始特征维度和类别数.
YAO L, MAO C, LUO Y. Graph convolutional networks for text classification [C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2019: 7370-7377.
ZHANG Z, CUI P, ZHU W
Deep learning on graphs: a survey
[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34 (1): 249- 270
ZHU D, ZHANG Z, CUI P, et al. Robust graph convolutional networks against adversarial attacks [C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2019.
HENAFF M, BRUNA J, LECUN Y. Deep convolutional networks on graph-structured data [EB/OL]. [2022-04-02]. http://arxiv.org/abs/1506.05163.
ZHANG Y, PAL S, COATES M J, et al. Bayesian graph convolutional neural networks for semi-supervised classification [C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2019: 5829-5836.
HAMILTON W, YING Z, LESKOVEC J. Inductive Representation learning on large graphs [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: Curran Associates, Inc., 2017: 1024-1034.
VELICKOVIC P, CUCURULL G, CASANOVA A, et al. Graph attention networks [C]// Proceedings of International Conference on Learning Representations 2018. Vancouver: [s.n.], 2018.
DUVENAUD D K, MACLAURIN D, IPARRAGUIRRE J, et al. Convolutional networks on graphs for learning molecular fingerprints [C]// Proceedings of the 29th International Conference on Neural Information Processing Systems. New York: Curran Associates, Inc., 2015: 2224-2232.
NIEPERT M, AHMED M, KUTZKOV K. Learning convolutional neural networks for graphs [C]// Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016: 2014-2023.
WANG X, JI H, SHI C, et al. Heterogeneous graph attention network [C]// Proceedings of the World Wide Web Conference 2019. New York: ACM, 2019: 2022-2032.
BRUNA J, ZAREMBA W, SZLAM A, et al. Spectral networks and locally connected networks on graphs [C]// Proceedings of the 31st International Conference on Machine Learning. New York: ACM, 2014.
DEFFERRARD M E L, BRESSON X, VANDERGHEYNST P. Convolutional neural networks on graphs with fast localized spectral filtering [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: Curran Associates, Inc., 2016: 3844-3852.
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [C]// Proceedings of International Conference on Learning Representations 2017. Toulon: [s.n.], 2017.
ABADI M I N, BARHAM P, CHEN J, et al. TensorFlow: a system for large-scale machine learning [C]// Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation. Berkeley: USENIX, 2016: 265-283.
PEROZZI B, AL-RFOU R, SKIENA S. DeepWalk: online learning of social representations [C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 701-710.
VERMA V, QU M, KAWAGUCHI K, et al. GraphMix: improved training of GNNs for semi-supervised learning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [s.l.]: AAAI, 2021: 10024-10032.
ZENG J, WANG P, LAN L, et al. Accurate and scalable graph neural networks for billion-scale graphs [C]// Proceedings of the 38th International Conference on Data Engineering. Kuala Lumpur: IEEE, 2022: 110-122.
WANG H, HE M, WEI Z, et al. Approximate graph propagation [C]// Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2021: 1686-1696.
... 本研究实验所使用的数据集为开源的引文网络Cora、Citeseer和Pubmed[20]. 在这3个引文网络中,每个节点表示一篇论文,节点初始特征为该论文对应的词袋特征向量;每条边均为无向边,表示所连接的2篇论文之间具有引用关系;节点的标签代表论文的主题. 如表1所示为3个数据集的重要信息. 表中, $ N 、 M 、 D 、C $分别为节点数、边数、初始特征维度和类别数. ...
1
... 实验中所有方法的代码都基于Tensorflow框架实现[21]. 所有的实验均在具有32 G RAM和4块NVIDIA Tesla V100 GPU的X86_64设备上进行. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}