

针对服务描述文档的特征分析已有大量研究,由于主题模型能够获取语义空间中的隐式层次语义信息,以主题模型为基础的聚类算法是现阶段研究的主要方向[4]. 服务描述文档的特征是文本短. 这种较短的、包含少许单词的文本,只能被获取少量的词共现信息,存在语义稀疏性问题. 常见主题模型如隐式狄利克雷分布(latent Dirichlet allocation, LDA)[5],由于稀疏性问题导致模型的短文本处理效果不佳[4,6-10]. 克服稀疏性问题的方法大致分为2种. 1)聚合一定数量的短文本,使其呈现伪文档形式后再进行处理,以此获得短文本间额外的语义信息. Mehrotra等[8]借助推特的用户信息和地点信息,将推特数据转变为伪文档后利用LDA处理,提高了推特信息的处理准确度. 伪文档处理方式通常需要借助一定的辅助信息,对服务描述文档来说,服务开发者赋予的如标签类的信息往往具有较强的主观性,将这些信息作为伪文档生成的额外依据时会影响伪文档的语义准确性. 2)显式地包含额外的词共现信息. 如Yan等[6]提出以词对(biterm)为基础,从语料集层面学习主题分布的词对主题模型 (biterm topic model, BTM). 然而使用BTM的生成策略生成的词对数量多,且存在大量无意义词对,使得模型的训练时间过长. 处理服务描述文档还会面临噪声干扰的问题[9-10]. 例如,将某服务的文档分词并去掉停用词后,得到的单词集合结果中包含与主题不相关的词(噪声词),干扰了主题的判定.
为了解决上述问题,本研究提出词向量与噪声过滤优化的词对主题模型(biterm topic model with word vector and noise filtering, BTM-VN). 1)以BTM为基础,在词对集合的层面上获取隐含的语义主题信息,用于解决服务描述文档的语义稀疏性问题. 2)使用基于主题分布信息的概率采样策略,寻找训练过程中对当前采样主题关联度高的代表词对,通过调节词对在采样过程中的权重信息,降低噪声干扰. 3)利用词向量进行词对的筛选,降低词对集合数量,提高主题模型训练的效率. 4)充分利用隐式语义信息,借助优化的密度峰值聚类算法(clustering by fast search and find of density peaks, DPC)对训练得到的文档-主题分布矩阵进行聚类操作,提高服务发现效率.
1. 相关工作
在解决稀疏性问题方面,肖巧翔等[11]提出人为增加文档词汇数的方法:1)筛选文档中TF-IDF值较高的词,借助Word2vec训练得到词向量信息;2)寻找与这些词汇相似度高的近义词来扩充原文档;3)以扩充后的语料作为输入,进行LDA模型训练. 该方法虽然增加了文档中的单词数量,但并没有优化原主题模型的结构,无法克服稀疏性对传统主题模型的影响. 利用TF-IDF选择得到的单词受数据集影响较大,实际的扩充效果并不理想. Zuo等[12]将短文本组合生成的伪文档作为主题模型的上层结构,引入稀疏性先验,结合采样方法计算伪文档的分布. 根据每个短文档对应的伪文档分布采样得到主题,完成主题模型的训练. 为了准确模拟稀疏的主题,Zhu等[13]将针板先验(spike and slab prior)引入词对模型,提高了模型的短文本处理效果. Zuo等[14]利用词向量信息替换原主题模型中的超参数,引入额外语义信息缓解稀疏问题.
在解决噪声问题方面,Nguyen等[15]借助预训练词向量的背景知识来估计当前词与主题的关联度,一定程度上降低了噪声词的干扰. Hu等[16]将服务文档中特定词性的单词保留,降低了服务功能主题判断的噪声词影响. 该方法依据人为经验指定保留的词性信息,不但在训练过程中缺少对不同词性词汇的额外处理,且缺少普适性. 狄利克雷与多项式分布混合模型(Dirichlet multinomial mixture model, DMM)[17]是利用全局文档主题分布、针对短文本优化的主题模型,在短文本场景下的训练效果相比LDA有所提升. 受此启发,Chen等[18]将同文档中的词对组合归为相同主题,并计算全局文档分布,以缓解短文本的主题偏移问题. Li等[9]将每个文档的主题分布定义为功能主题和公共主题的混合,在主题模型中定义噪声词的生成过程,利用公共主题收集噪声词,通过二次采样降低噪声词的干扰,提高了模型的噪声处理效果. 为了获取与主题相关度高的单词,Chen等[4]借助文献[10]的概率采样方法,在每次采样过程中计算代表词矩阵,用于修正语义空间中代表词的权重,以此降低噪声. 概率采样方法能够有效判别针对主题的代表词,减少噪声词. 该方法融入主题模型的采样过程,在不改变原模型生成过程的前提下进行优化,有较强的可操作性与可靠性.
2. BTM-VN建模
BTM-VN以词对模型BTM[6]为基础,把基于主题分布信息的概率采样过程,用于挖掘服务描述文档中与当前服务功能相关的词对,以降低噪声. 词对由2个单词组成,例如对于短语“top popular api”,可生成词对“top popular”、“top api”、“popular api”. 为了方便计算,词对中的2个单词默认无序,且属同个主题. 模型以词对集合作为语料输入,显式地增强文档语义信息,利用词向量精简词对,提高训练效率. 如图1所示为BTM-VN的图形表示. 图中,α、β为模型的超参数,θ为词对的狄利克雷主题分布,Φ为对应主题的狄利克雷词分布,z为由主题词分布获取的当前主题. wi、wj分别为构成词对的2个单词,η为词对筛选步骤的相似度阈值,μ为概率采样过程中使用的超参数,λ为词对判断矩阵中的元素.
图 1
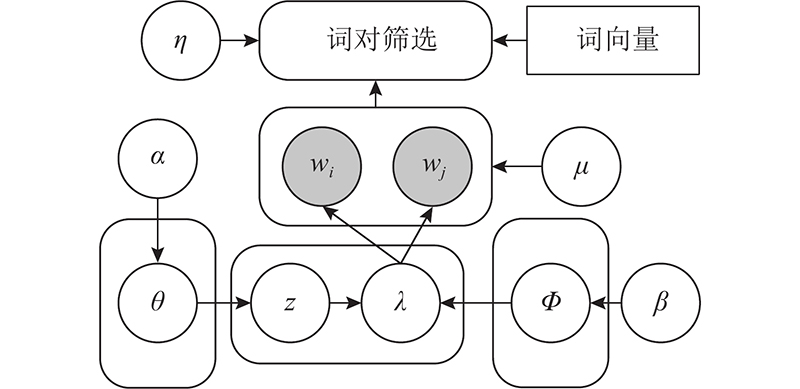
图 1 词向量与噪声过滤优化的词对主题模型图形表示
Fig.1 Graphical representation of biterm topic model with word vector and noise filtering
2.1. 代表词对选取
在采样过程中,找到与服务功能主题关联度较大的对象将有利于处理噪声问题. 对每次迭代采样的当前主题,主题模型使用概率采样方法,将被分配到该主题下的服务文档集合产生的所有词对作为一个整体进行处理. 当词对b被归为主题z的概率较大时,词对中往往包含原文档中与主题z关联度较大的词. 将这些与主题相关性高的词对定义为代表词对. 利用主题词分布Φ与主题分布z,计算判定概率λ,获取服务文档组成的词对集合中的代表词对. 在采样过程中增加代表词对的权重信息,能够抑制噪声词给采样结果带来的影响,使主题模型达到更好的训练结果.
应用BTM的词对同属思想,将词对-主题的条件概率表示为
式中:P(z)为当前文档被归于主题z的概率;P(w|z)为被归于主题z的文档中,出现词w的概率;zk为在所有主题中序号为k的主题; P(z|b)为词对b属于主题z的条件概率. 全局主题分布、主题词分布的概率计算式分别为
式中:|B|为总的词对数量,K为主题数,M为词汇表词汇个数. 结合式(1)~(3),得到
式中:nz为被归入主题z的词汇数量,
为了提高主题相关性高的词对在采样过程中的权重,引入概率采样策略[11]来判断当前词与主题的相关性,表达式为
算法1 代表词对矩阵计算cal_RB
输入: 经过筛选的词对集B_sim,词汇表voc,每个主题被归入词汇次数集合nz,每个词汇归入各个主题次数集合nwz,主题数k,超参数α与β
输出: 代表词对矩阵S
1. FUNCTION cal_RB
2.
3. S← matrix which size is |B|*k //S为代表词对矩阵
4. FOR b∈B_sim
5. FORt∈[0,
6. p[b,t] ← (nz[t]+α)*(nwz[t][b.w1])*(nwz[t][b.w2]),according to Eq.(4) //根据式(4),计算词对b在主题z下的概率
7. END FOR
8. FORt∈[0,
9. λ[b.index][t] ← p[b,t] / max(p[b]),according to Eq.(7) //根据式(7),计算当前概率与最大概率的比值
10. IF λ[b.index][t] < 0.5 //基于伯努利分布计算
11. S[b.index][t] ← 0
12. ELSE
13. S[b.index][t] ← 1
14. END IF
15. END FOR
16. END FOR
17. RETURN S
18. END FUNCTION
2.2. 词向量优化
词向量能将单词映射到低维稠密的实数向量空间中,语义越相近的词在该空间中的距离就越近. 利用这一特点,可以通过计算向量距离来表示词语间的相似度[19]. 为了深入理解词与词之间的语义关系,利用词向量进行语义背景信息的模拟.
式中:η为相似度阈值,
算法2 词对筛选过程filter_B
输入: 词对集合B,词向量模型M,相似度阈值η
输出: 过滤后的词对集合B_sim
1. FUNCTION filter_B(B, M, η)
2. FOR b∈B do
3. sim ← similarity(M, b)
4. IFsim >= η do
5. add b into B_sim
6. END IF
7. END FOR
8. RETURN B_sim
9. END FUNCTION
10.
11. FUNCTION similarity (M, b)
12. IF b.w1 == b.w2 do
13. sim ← 1
14. ELSE IF w1 not in M or w2 not in M //考虑词缺失情况
15. sim ← 1
16. ELSE
17. sim ← M.sim(b)
18. END IF
19. RETURN sim
20. END FUNCTION
2.3. 模型训练
BTM-VN模型的采样式为
式中:μ为权重参数. 当
BTM-VN模型的具体训练流程如算法3所示. 在模型训练过程中,对服务文档生成的词对集合进行词向量筛选操作. 在采样过程中,计算代表词对矩阵,完成概率采样计算,将词对分配到对应的主题.计算并输出服务文档对应的文档主题分布. b.index为词对序号,b.topic为词对当前所属主题. 文档集合D为进行预处理后得到的文档分词结果集合,在行4~7中,遍历文档集合,将其转换为语料集的词对集合. 利用词向量模型和相似度阈值,筛选词对集合,获取精简后的词对集合B_sim(行8). 在行9词对的主题初始化过程中,给每个词对赋予一个随机的主题,并借助该主题和词对中单词的序号,增加nz与nwz中相应的值,方便后续计算. 采样过程始于行10,行19~27利用矩阵S中词对与主题的值判断代表词对,当
算法3 BTM-VN
输入: 文档分词集合D,相似度阈值η,权重参数μ,词向量模型M,词汇表voc,迭代数iteration,主题数k,超参数α与β
输出: 主题词分布phi与主题分布theta
1. B←blank list //存放词对集合
2. nz←zero matrix which size is k*1 //存放每个主题的词对数
3. nwz←zero matrix which size is k*|voc| //存放每个词汇被分入每个主题的次数
4. FOR d∈D
5. biterms ← change d to list of biterms //将分词文档转换为词对集合
6. add biterms into B
7. END FOR
8. B_sim ← filter_B(B, M, η),according to algorithm 2 //利用算法2,筛选词对信息
9. give random topic to biterms,initialize nz and nwz //初始化
10. FOR I∈[0,
11. FOR b∈B_sim
12. nz[b.topic] ← nz[b.topic]−1
13. nwz[b.topic][b.w1] ← nwz[b.topic][b.w1]−1
14. nwz[b.topic][b.w2] ← nwz[b.topic][b.w2]−1
15. IFI == 0
16. b.topic ← sampling topic according to Eq.(12) when S=0 //利用公式(12)中
17. ELSE
18. topic_distribution ← zero matrix which size isk*1
19. FOR t∈[0,
20. IF S[b.index][t]==1
21. topic_distribution[t] ←sampling topic according to Eq.(12) when S=1 //利用公式(12)中
22. ELSE
23. topic_distribution[t] ←sampling topic according to Eq.(12) when S=0 //利用公式(12)中
24. END IF
25. END FOR
26. b.topic ← topic~topic_distribution //用主题分布轮盘赌选取主题
27. END IF
28. nz[b.topic] ← nz[b.topic]+1
29. nwz[b.topic][b.w1] ← nwz[b.topic][b.w1]+1
30. nwz[b.topic][b.w2] ← nwz[b.topic][b.w2]+1
31. END FOR
32. S ← cal_RB(B_sim, nz, nwz, α, β, k),according to algorithm 1 //利用算法1,计算矩阵S
33. END FOR
34. calculate phi and theta,according to Eq.(2) and Eq.(3)//计算主题词分布和主题分布
35. RETURN
2.4. 聚类流程
虽然直接利用文档-主题矩阵的最大分量对文档进行归类可以实现聚类,但为了充分利用主题分布蕴含的隐式语义信息,并考虑文档间的整体语义相似度,本研究将各文档的主题分布作为文档特征向量,利用基于相似度的聚类方法进行文档聚类处理.
Rodriguez等[22]提出DPC算法,认为聚类中心点相对于外围点有更大的密度,且与其他密度大的点之间有较大的距离. DPC算法通过计算各点的局部密度和密度距离来选择可能性较大的聚类中心,以获取初始的聚类中心点,减少陷入局部最优的情况,计算式为
式中:di,j为序号元素i、j的间距,dc为截断距离,ρ为局部密度,δ为密度距离. 式(15)根据式(13)的局部密度计算结果,分2种情况进行密度距离的计算. DPC算法利用局部密度与密度距离之积来判断聚类中心点.
使用DPC算法须设置合适的截断距离来计算局部密度. 人工方法设置依靠经验,缺少一定的理论依据,因此借助元素间的距离差值选取最佳截断距离,优化DPC. 当聚类中心点到除自身以外任意2点的距离之差最大时,较小的那个距离即为中心点到自身簇边缘的距离,此时距离值为该点的最佳截断距离值. 通过排序计算某元素到其他元素间的距离,找到这些距离间的差值最大值,得到合适的截断距离,计算式为
式中:|D|为元素总数. 对于元素i,其最佳截断距离为aj,即组合中较小的距离. 考虑到全局信息,选择所有元素对应的截断距离集合中最小的值作为全局截断距离.
3. 实验评估
3.1. 数据集与文本预处理
实验用数据集来自programmableWeb
3.2. 预处理词向量
词向量成功的关键除了需要大规模的训练语料[23],还须保证语法正确并贴合英文自然语言使用的习惯. 考虑到Google News语料规模庞大,覆盖主题多,使用Google News新闻语料进行词向量训练,并进一步得到300维的词向量预训练结果.
3.3. 词对筛选实验
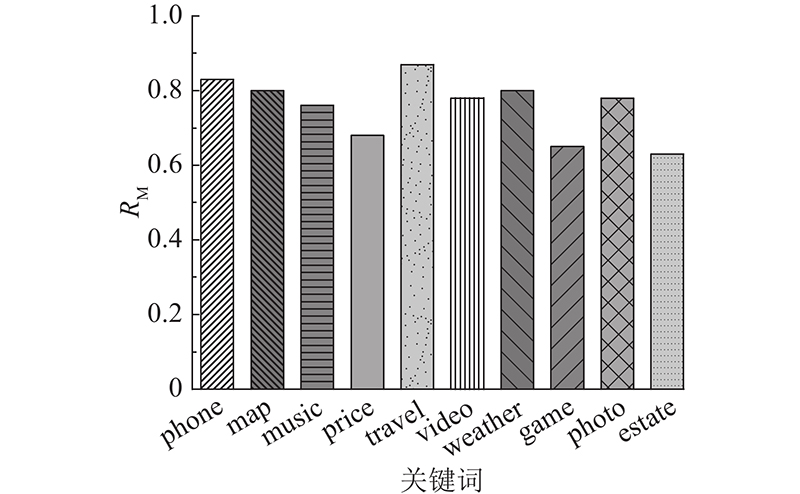
选取服务描述文档数据中的6类,生成包含类别关键词的词对集合. 筛选后的部分词对集合示例如表1所示. 可以看出,利用词对相似度进行词对筛选,可以留下关联性较强、共现时意义较大的词对组合. 如当“music”和“live”共现时,它们作为艺术类服务的可能性大大增加;“music”和“stay”的相关度较小,不能有效获取语义信息的词对将会被筛选剔除,以提高模型训练效率. 为了提高人工筛选词对集合的可靠性,人工筛选执行2次,分别安排不同人员进行筛选,在统一汇总的信息中保留相同的结果. 对比人工与BTM-VN实现的筛选结果,计算匹配率为
表 1 词对筛选结果示例表
Tab.1
| 类别 | 保留词对 | 剔除词对 |
| phone | phone app, survey phone, phone message | phone provide, follow phone, phone wind |
| map | map show, google map, spot map | map feed, map trend, map news |
| music | live music, music track, record music | aim music, stay music, cafe music |
| price | price cheap, price purchase, quality price | price fun, account price, create price |
| travel | travel tour, travel map, travel service | travel application, travel type, travel integration |
| video | video discography, globe video, video band | access video, video bring, base video |
式中:
图 2
3.4. 参数实验
BTM-VN通过相似度阈值η与权重参数μ调整模型训练的程度与结果. 为了观察参数变化对训练结果的影响,使用指标F1来代表聚类的准确程度,计算不同η取值情况下单次迭代的时间. 根据文献[1]得出聚类结果的准确率
式中:O为对服务进行预分类的结果,W为实验获得的分类结果. 当某个类计算与实验结果类的交集比率
如图3所示为不同主题数下的算法聚类效果. 图3(c)中,当η=0.05时,F1在μ=0.2时达到峰值;当μ>0.4时,模型训练产生负效果. 在主题数为6、8、10的实验中,均获得了类似的效果. 可以看出,当μ的取值合理时,能突出代表词对在主题采样过程中的作用,提高模型训练效果;μ过大时,主题中会出现被错误分配的词对,随着μ变大,这些出错的代表词对权重增加越大,模型训练效果越差. 观察η对模型精度的影响,在不同的主题数条件下,η=0.05时,获得的精度较高. 在训练过程中,μ仅和采样中的词对权重有关联,其变化并不影响算法耗时. 引入BTM算法进行模型训练时间的对比,η变化对训练时间t的影响如表2所示. 以η=0.05且主题数为6时为例,单次迭代所需的时间与BTM相比减少20%,精度与未进行词对筛选时的相比提高17%. 可见,由于词向量蕴含丰富的语义信息,利用词向量计算词对相似度并进行词对集合筛选的方法,可以在一定程度上去除无意义词对,提高模型精度. 当η=0.2时,时间消耗相比BTM减少78%,利用μ参数进行噪声处理的优化,精确度仅下降7%. 可见,当阈值取值过大时,过多的词对会被删除,进而影响语义的完整性,导致精度下降. 通过调节η、μ,可以在降低一定计算时间的同时增加算法精度,或者在大幅下降训练时间的同时尽量维持算法原有的训练精度.
图 3
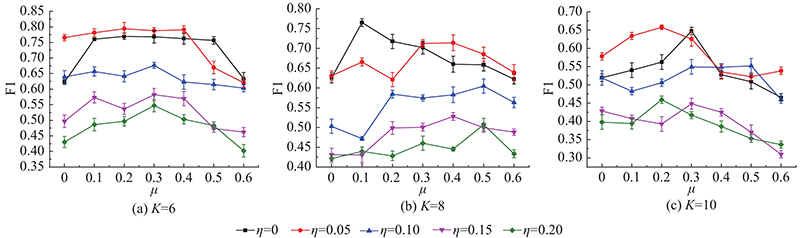
图 3 不同的权重与阈值对模型准确度的影响
Fig.3 Accuracy results with different weight and threshold
表 2 不同阈值情况下模型单次迭代耗时对比
Tab.2
| K | t/ms | ||||
| BTM | η=0.05 | η=0.1 | η=0.15 | η=0.2 | |
| 6 | 1 680 | 1 360 | 930 | 580 | 360 |
| 8 | 3 070 | 2 560 | 1 780 | 1 060 | 650 |
| 10 | 4 610 | 3 700 | 2 520 | 1 580 | 950 |
3.5. 主题一致性实验
利用LDA、BTM、BTM-VN和DMM共4种主题模型进行语料训练,获取各主题下的主题词. 为了更好地展示模型整体的主题一致性效果,利用主题词计算各个主题下的点交互信息(point-wise mutual information, PMI)[24]为
式中:wk,i为主题K中前n个主题词中的第i个单词,P(wk,i)为主题词wk,i在文档集合中出现的概率,P(wk,i,wk,j)为主题词wk,i、wk,j同时在文档中出现的概率. 利用PMI能够表示模型结果的主题一致性程度,主题一致性越高,表示模型的隐式主题划分越准确,模型训练结果越好. 如图4所示为4个主题模型计算得到的PMI. 可以看出,BTM-VN的PMI始终较高,且随着主题词数量取值变大,PMI较为稳定,这也印证了该模型训练结果主题的一致性.
图 4

图 4 多种主题模型在不同主题数和主题词提取数量情况下的主题一致性结果
Fig.4 Comparision of topic coherence results of various topic models with different topic models and topic word numbers
3.6. 对比实验
为了验证提出服务聚类算法的可行性,选取如下基准方法进行对比. 1) TF-IDF+Word2vec[25]在Word2vec获取的词向量结果的基础上,利用TF-IDF计算语料词汇权重,对词向量进行加权求和处理,获取文档向量并进行聚类操作. 2) LDA与LDA+sDPC使用传统的文档主题模型LDA得到文档的隐式主题分布结果,利用主题概率向量中的分量最大值作为文档聚类依据进行归类;LDA+sDPC算法利用优化DPC聚类方法(sDPC)对LDA训练结果进行聚类处理. 3) LDA+Word2vec扩容是文献[11]中的服务聚类方法. 该方法借助Word2vec,将原文档中TF-IDF值较高的关键词做同义词扩充,再利用LDA模型进行训练,获取文档主题分布并聚类,扩容词汇数设置为3个. 4) BTM与BTM+sDPC利用原始的BTM主题模型进行文档训练,以分量最大值为依据或使用sDPC算法进行聚类. 5) DMM与DMM+sDPC借助短文本优化主题模型DMM,采样训练得到文档主题分布,使用最大分量或sDPC算法聚类. 6) BTM-VN与BTM-VN+sDPC利用本研究提出的BTM-VN模型,调优后进行文档处理,获取文档主题分布矩阵作为特征向量,以分量最大值或sDPC算法获取聚类结果.
实验设置各主题模型的主题数K为数据集类别数,超参数α=0.1、β=0.01;设置BTM-VN的参数μ=0.3、η=0.05.如图5所示为模型在多种准确度评判指标下的实验结果. 由图可以得到如下结论. 1) 合理使用词向量模型引入的额外语义信息,能够较好克服短文本语义稀疏性问题. 如利用TF-IDF+Word2vec方法,词向量能够模拟大量背景知识获得单词间的语义信息,在计算相似度时有较高的可靠性,该方法的准确度效果与LDA方法近似. LDA+Word2vec利用词向量模型寻找近义词扩充原文档,模型的准确率、召回率和F1比LDA模型的低. 利用Word2vec拓展原文档的方法虽然通过词向量获取了相似度高的单词,但其仅利用词频信息选择被扩展的单词集合,未考虑这些单词在主题模型训练过程中是否应当获取较高的权重,导致实验结果不理想. 在BTM-VN中,以词向量模型模拟背景知识进行筛选,在一定的阈值条件下能筛选合适的词对集合,大大减少模型训练时间且不影响训练结果. 2) 基于代表词对的概率采样方法能克服噪声干扰,提高模型效果. 与BTM相比,BTM-VN模型的准确率、召回率和F1分别提高25.7%,25.9%和25.8%;与LDA相比,BTM-VN模型的准确率,召回率和F1分别提高51.85%,54.3%和55.5%;与DMM相比,BTM-VN模型的准确率、召回率和F1分别提高20%,12.5%和14.3%. 综合而言,LDA对短文本的适应性效果最差. DMM模型效果在各方面的表现优于BTM模型,这是由于DMM模型在采样时将短文本作为整体进行主题的采样,降低了噪声词对不同主题信息的干扰. BTM-VN考虑完整的语义信息,能够更好地处理噪声,与BTM、DMM相比噪声处理的效果都有较大提升. 3) sDPC聚类算法能有效提高服务聚类的效果. 分析实验结果,在准确率方面,利用sDPC算法对LDA结果进行处理后提升5.7%,BTM的结果提升4.1%,BTM-VN的结果提升7%,DMM提升4.2%. 可以看出,考虑整体隐式主题语义结果,利用sDPC对同一主题模型的训练结果矩阵进行聚类操作后,得到的结果相较于简单使用最大分量进行聚类更好.
图 5

图 5 各类方法在服务数据集上的聚类准确度表现对比
Fig.5 Comparison of clustering performance of various methods on service datasets
4. 结 语
本研究提出针对服务描述文档优化的主题模型BTM-VN. 相对于传统的主题模型,BTM-VN考虑服务文档短文本的特点,针对短文本的稀疏性与噪声问题做出了优化,达到更好的隐式主题获取效果. 本研究使用的实验数据多为短文本自然语言形式的服务描述文档,利用基准算法进行对比实验,验证了所提算法对短文本数据集的适应性及其在服务聚类环境下的可行性. 从对比实验可以看出,所提算法在各项准确度指标的表现上都优于现有算法. 未来计划在词对筛选方法上再进行优化,减小词对删减过多导致的准确度下降. 此外,为了获得模型的最佳效果,本研究须对参数进行调优操作,在后续工作中,希望能够找到自适应方法来简化参数的选取工作.
参考文献
融合 SOM 功能聚类与 DeepFM 质量预测的 API 服务推荐方法
[J].DOI:10.11897/SP.J.1016.2019.01367 [本文引用: 3]
An API service recommendation method via combining self-organization map-based functionality clustering and deep factorization machine-based quality prediction
[J].DOI:10.11897/SP.J.1016.2019.01367 [本文引用: 3]
Specificity-aware ontology generation for improving Web service clustering
[J].DOI:10.1587/transinf.2017EDP7395 [本文引用: 1]
基于多重关系主题模型的Web服务聚类方法
[J].DOI:10.11897/SP.J.1016.2019.00820 [本文引用: 3]
Multi-relational topic model-based approach for Web services clustering
[J].DOI:10.11897/SP.J.1016.2019.00820 [本文引用: 3]
A nonparametric model for online topic discovery with word embeddings
[J].DOI:10.1016/j.ins.2019.07.048 [本文引用: 3]
Latent dirichlet allocation
[J].
Filtering out the noise in short text topic modeling
[J].DOI:10.1016/j.ins.2018.04.071 [本文引用: 2]
基于 Word2Vec 和 LDA 主题模型的 Web 服务聚类方法
[J].
Web services clustering based on Word2Vec and LDA topic model
[J].
Topic modeling of short texts: a pseudo-document view with word embedding enhancement
[J].
Improving topic models with latent feature word representations
[J].DOI:10.1162/tacl_a_00140 [本文引用: 1]
A Dirichlet process biterm-based mixture model for short text stream clustering
[J].DOI:10.1007/s10489-019-01606-1 [本文引用: 1]
Clustering by fast search and find of density peaks
[J].DOI:10.1126/science.1242072 [本文引用: 1]
基于Word2Vec的一种文档向量表示
[J].DOI:10.11896/j.issn.1002-137X.2016.06.043 [本文引用: 1]
Document vector representation based on Word2Vec
[J].DOI:10.11896/j.issn.1002-137X.2016.06.043 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}