[1]
李雅倩, 盖成远, 肖存军, 等 基于细化多尺度深度特征的目标检测网络
[J]. 电子学报 , 2020 , 48 (12 ): 2360 - 2366
DOI:10.3969/j.issn.0372-2112.2020.12.011
[本文引用: 1]
LI Ya-qian, GAI Cheng-yuan, XIAO Cun-jun, et al Object detection network based on refined multi-scale depth features
[J]. Acta Electronica Sinica , 2020 , 48 (12 ): 2360 - 2366
DOI:10.3969/j.issn.0372-2112.2020.12.011
[本文引用: 1]
[2]
郑浦, 白宏阳, 李伟, 等 复杂背景下的小目标检测算法
[J]. 浙江大学学报:工学版 , 2020 , 54 (9 ): 1777 - 1784
[本文引用: 1]
ZHENG Pu, BAI Hong-yang, LI Wei, et al Small target detection algorithm in complex background
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (9 ): 1777 - 1784
[本文引用: 1]
[3]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// 2014 IEEE Conference on Computer Vison and Pattern Recognition . Columbus: IEEE, 2014: 580-587.
[本文引用: 1]
[4]
GIRSHICK R. Fast R-CNN [C]// 2015 IEEE International Conference on Computer Vison . Santiago: IEEE, 2015: 1440-1448.
[本文引用: 1]
[5]
REN S, HE K GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 3]
[6]
CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection [C]// 2018 IEEE/CVF Conference on Computer Vison and Pattern Recognition . Salt Lake City: IEEE, 2018: 2603-2611.
[本文引用: 1]
[7]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// European Conference on Computer Vision . [S. l. ]: Springer, 2016: 21-37.
[本文引用: 4]
[8]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[9]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6517-6525.
[本文引用: 1]
[10]
REDMON J, FARHADI A. Yolov3: an incremental improvement. [EB/OL]. [2021-12-30]. https://arxiv.org/pdf/1804.02767.pdf.
[本文引用: 1]
[11]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// 2017 IEEE Conference on Computer Vison and Pattern Recognition . Honolulu: IEEE, 2017: 963-944.
[本文引用: 1]
[12]
LI Z X, ZHOU F Q. FSSD: feature fusion single shot multibox detector [EB/OL]. [2021-12-30]. https://arxiv.org/pdf/1712. 00960.pdf.
[本文引用: 2]
[13]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// 2017 IEEE International Conference on Computer Vison . Venice: IEEE, 2017: 2999-3007.
[本文引用: 3]
[14]
裴伟, 许晏铭, 朱永英, 等 改进的SSD航拍目标检测方法
[J]. 软件学报 , 2019 , 30 (3 ): 738 - 758
DOI:10.13328/j.cnki.jos.005695
[本文引用: 1]
PEI Wei, XU Yan-ming, ZHU Yong-ying, et al The target detection method of aerial photography images with improved SSD
[J]. Journal of Software , 2019 , 30 (3 ): 738 - 758
DOI:10.13328/j.cnki.jos.005695
[本文引用: 1]
[15]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 10778-10787.
[本文引用: 1]
[16]
GUO C, FAN B, ZHANG Q, et al. AugFPN: improving multi-scale feature learning for object detection [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 12592-12601.
[本文引用: 4]
[17]
ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression. [C]// AAAI Conference on Artificial Intelligence . NewYork: AAAI, 2020: 12993–13000.
[本文引用: 1]
[18]
SIMON Y K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2021-12-30]. https://arxiv.org/pdf/1409.1556.pdf.
[本文引用: 1]
[19]
陈科圻, 朱志亮, 邓小明, 等 多尺度目标检测的深度学习研究综述
[J]. 软件学报 , 2021 , 32 (4 ): 1201 - 1227
DOI:10.13328/j.cnki.jos.006166
[本文引用: 3]
CHEN Ke-qi, ZHU Zhi-liang, DENG Xiao-ming, et al Deep learning for multi-scale object detection: a survey
[J]. Journal of Software , 2021 , 32 (4 ): 1201 - 1227
DOI:10.13328/j.cnki.jos.006166
[本文引用: 3]
[20]
WANG K, LIEW J H, ZOU Y, et al. PANet: few-shot image semantic segmentation with prototype alignment [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9197-9206.
[本文引用: 1]
[21]
GHIASI G, LIN T Y, LE Q V. NAS-FPN: learning scalable feature pyramid architecture for object detection [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 7036-7045.
[本文引用: 1]
[22]
ZHANG Q, BAO X, WU B, et al Water meter pointer reading recognition method based on target-key point detection
[J]. Flow Measurement and Instrumentation , 2021 , 81 : 102012
DOI:10.1016/j.flowmeasinst.2021.102012
[本文引用: 1]
[23]
HE J, SHEN L, ALBANIE S, et al Squeeze-and-excitation networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (8 ): 2011 - 2023
DOI:10.1109/TPAMI.2019.2913372
[本文引用: 1]
[24]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// European Conference on Computer Vision. [S. l.]: Springer, 2018: 3-19.
[本文引用: 1]
[25]
ZHANG H, ZU K, LU J, et al. EPSANet: an efficient pyramid split attention block on convolutional neural network. [EB/OL]. [2021-12-30]. https://arxiv.org/pdf/ 2105.14447.pdf.
[本文引用: 1]
[26]
LIU W, RABINOVICH A, BERG A C. ParseNet: looking wider to see better. [EB/OL]. [2021-12-30]. https://arxiv.org/pdf/1506.04579.pdf.
[本文引用: 1]
[27]
刘颖, 刘红燕, 范九伦, 等 基于深度学习的小目标检测研究与应用综述
[J]. 电子学报 , 2020 , 48 (3 ): 590 - 601
DOI:10.3969/j.issn.0372-2112.2020.03.024
[本文引用: 1]
LIU Ying, LIU Hong-yan, FAN Jiu-lun, et al A Survey of research and application of small object detection based on deep learning
[J]. Acta Electronica Sinica , 2020 , 48 (3 ): 590 - 601
DOI:10.3969/j.issn.0372-2112.2020.03.024
[本文引用: 1]
[28]
QIN Z, LI Z, ZHANG Z, et al. ThunderNet: towards real-time generic object detection on mobile devices [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6718-6727.
[本文引用: 1]
[29]
CAO Y, CHEN K, LOY C C, et al. Prime sample attention in object detection [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11583-11591.
[本文引用: 1]
[30]
ZHOU P, NI B, GENG C, et al. Scale-transferrable object detection [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 528-537.
[本文引用: 3]
[31]
LI W, LIU G. A single-shot object detector with feature aggregation and enhancement [C]// 2019 IEEE International Conference on Image Processing . [S.l.]: IEEE, 2019: 3910-3914.
[本文引用: 4]
[32]
TIAN Z, SHEN C, CHEN H, et al. FCOS: fully convolutional one-stage object detection [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9627-9636.
[本文引用: 2]
[33]
ZHANG S, CHI C, YAO Y, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9759-9768.
[本文引用: 2]
[34]
田秀霞, 李华强, 张琴, 等 基于双通道R-FCN的图像篡改检测模型
[J]. 计算机学报 , 2021 , 44 (2 ): 370 - 383
DOI:10.11897/SP.J.1016.2021.00370
[本文引用: 1]
TIAN Xiu-xia, LI Hua-qiang, ZHANG Qin, et al Dual-channel R-FCN model for image forgery detection
[J]. Chinese Journal of Computers , 2021 , 44 (2 ): 370 - 383
DOI:10.11897/SP.J.1016.2021.00370
[本文引用: 1]
[35]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M, et al. YOLOv4: optimal speed and accuracy of object detection. [EB/OL]. [2021-12-30]. https://arxiv.org/pdf/2004.10934.pdf.
[本文引用: 3]
[36]
ZHANG S, WEN L, BIAN X, et al. Single-shot refinement neural network for object detection [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4203-4212.
[本文引用: 2]
基于细化多尺度深度特征的目标检测网络
1
2020
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
基于细化多尺度深度特征的目标检测网络
1
2020
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
复杂背景下的小目标检测算法
1
2020
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
复杂背景下的小目标检测算法
1
2020
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
1
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
1
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks
3
2017
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
... [
5 ]
ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0 表 4 VOC2007测试集不同类别目标检测精度结果 ...
1
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
4
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
... Different types of target detection accuracy results on VOC2007 test set
Tab.4 算法 mAP/% aero bird boat bottle car person plant sheep train tv SSD300[7 ] 77.1 75.3 68.0 50.4 85.2 80.2 47.5 76.1 86.3 77.0 DSSD321[19 ] 81.9 80.5 68.4 53.9 86.2 79.7 51.7 78.0 87.2 79.4 STDN300[30 ] 81.1 76.4 69.2 52.4 84.2 76.8 51.8 78.4 87.5 77.8 FAENet300[31 ] 82.8 76.5 74.7 58.7 87.5 81.4 57.7 80.4 86.8 79.6 FEDet 84.0 79.3 75.6 59.1 86.7 80.0 59.2 79.5 87.9 79.9
SSD与FEDet在VOC2007数据集上的检测效果对比如图10 所示. 图10 (a)中有3张椅子,较为密集,FEDet更容易检测密集的目标. 图10 (b)中,SSD无法检测出被遮挡的椅子,FEDet检测成功,表明FEDet更容易检测被遮挡的目标. 图10 (c)中SSD无法检测出小目标物体,FEDet检测成功,表明FEDet适合小目标物体的检测. ...
... Experiment results of different algorithms on COCO dataset
Tab.5 算法 AP AP50 AP75 APS APM APL % SSD[7 ] 25.6 43.8 26.3 6.8 27.8 42.2 YOLOv3[35 ] 28.2 51.5 29.7 11.9 30.6 43.4 RefineDet[36 ] 29.4 49.2 31.3 10.0 32.0 44.4 FAENet[31 ] 28.3 47.9 29.7 10.5 30.9 41.9 FEDet 30.1 50.0 31.2 13.3 33.2 44.0
图 11 2种算法在COCO数据集上检测结果对比 ...
1
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
1
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
1
... 目标检测是图像识别领域重要的研究方向,在自动驾驶、安防监控邻域发挥着重要作用[1 ] . 主流的目标检测算法分为双阶段目标检测算法和单阶段目标检测算法[2 ] . 双阶段检测算法主要有RCNN[3 ] 系列, 包括Fast R-CNN[4 ] 、Faster R-CNN[5 ] 、Cascade R-CNN[ 6 ] 等. 双阶段检测算法在第一个阶段,通过区域候选网络(region proposal network,RPN)将生成的默认框区分为前景或背景以生成候选框;在第二阶段,对候选框进行预测得到最终检测结果. 双阶段目标检测算法先筛除大部分默认框,虽然其检测精度比单阶段检测算法的更高,但须执行2个步骤,导致算法的计算复杂度大幅增加,算法的检测速度降低. 单阶段检测算法主要有单阶段多边框检测算法(single-stage multi-box detector algorithm,SSD)[7 ] 系列和YOLO[8 -10 ] 系列. 单阶段检测算法直接对定义的默认框进行分类和偏移量预测. 由于正负样本不均衡,单阶段检测算法的检测精度较低,但算法只经过一次分类和回归,检测速度比双阶段检测算法快. SSD利用不同尺度的特征层检测不同大小的目标. 高分辨率的低层特征图检测小目标物体,低分辨率的高层特征图检测大目标物体的方法,在一定程度上缓解了多尺度检测问题. SSD对样本进行预测时采用难例挖掘策略,即选取正负样本比例为1∶3,这样一定程度上缓解了正负样本不均衡问题. ...
1
... 小目标检测是目标检测的难点,SSD在小目标物体繁多、应用场景复杂情况下的检测精度较低. 检测小目标物体需要精细的特征和足够的语义信息以便将物体与背景区分开,SSD的低级特征层虽然有精细的特征,但是语义信息不足. 许多检测器利用特征金字塔网络(feature pyramid network,FPN)[11 ] 来解决这个问题. Li等[12 ] 利用特征融合改进SSD,提出FSSD算法. 该模型借鉴FPN的概念,在保证检测速度的同时提升了模型的检测精度. Lin等[13 ] 提出的RetinaNet将FPN融入算法,不但用低层特征图补充了高级语义信息,还保留了低层细节信息. 不仅如此,RetinaNet中的Focal Loss[13 ] 损失函数,还让单阶段检测器的检测精度超过了双阶段检测器的. 裴伟等[14 ] 利用深度残差网络和特征融合改进SSD,使算法适于航拍目标检测. FPN存在2种损失:1)在特征融合之前,输入的特征图须先经过1×1卷积将通道数降为256,这个过程是造成通道信息丢失的主要原因,称为降维损失. 2)不同尺度特征图间存在语义鸿沟,直接将不同尺度特征图相加融合会导致混叠效应(aliasing effects)[15 ] ,陷入次优特征金字塔,称为融合损失. ...
2
... 小目标检测是目标检测的难点,SSD在小目标物体繁多、应用场景复杂情况下的检测精度较低. 检测小目标物体需要精细的特征和足够的语义信息以便将物体与背景区分开,SSD的低级特征层虽然有精细的特征,但是语义信息不足. 许多检测器利用特征金字塔网络(feature pyramid network,FPN)[11 ] 来解决这个问题. Li等[12 ] 利用特征融合改进SSD,提出FSSD算法. 该模型借鉴FPN的概念,在保证检测速度的同时提升了模型的检测精度. Lin等[13 ] 提出的RetinaNet将FPN融入算法,不但用低层特征图补充了高级语义信息,还保留了低层细节信息. 不仅如此,RetinaNet中的Focal Loss[13 ] 损失函数,还让单阶段检测器的检测精度超过了双阶段检测器的. 裴伟等[14 ] 利用深度残差网络和特征融合改进SSD,使算法适于航拍目标检测. FPN存在2种损失:1)在特征融合之前,输入的特征图须先经过1×1卷积将通道数降为256,这个过程是造成通道信息丢失的主要原因,称为降维损失. 2)不同尺度特征图间存在语义鸿沟,直接将不同尺度特征图相加融合会导致混叠效应(aliasing effects)[15 ] ,陷入次优特征金字塔,称为融合损失. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
3
... 小目标检测是目标检测的难点,SSD在小目标物体繁多、应用场景复杂情况下的检测精度较低. 检测小目标物体需要精细的特征和足够的语义信息以便将物体与背景区分开,SSD的低级特征层虽然有精细的特征,但是语义信息不足. 许多检测器利用特征金字塔网络(feature pyramid network,FPN)[11 ] 来解决这个问题. Li等[12 ] 利用特征融合改进SSD,提出FSSD算法. 该模型借鉴FPN的概念,在保证检测速度的同时提升了模型的检测精度. Lin等[13 ] 提出的RetinaNet将FPN融入算法,不但用低层特征图补充了高级语义信息,还保留了低层细节信息. 不仅如此,RetinaNet中的Focal Loss[13 ] 损失函数,还让单阶段检测器的检测精度超过了双阶段检测器的. 裴伟等[14 ] 利用深度残差网络和特征融合改进SSD,使算法适于航拍目标检测. FPN存在2种损失:1)在特征融合之前,输入的特征图须先经过1×1卷积将通道数降为256,这个过程是造成通道信息丢失的主要原因,称为降维损失. 2)不同尺度特征图间存在语义鸿沟,直接将不同尺度特征图相加融合会导致混叠效应(aliasing effects)[15 ] ,陷入次优特征金字塔,称为融合损失. ...
... [13 ]损失函数,还让单阶段检测器的检测精度超过了双阶段检测器的. 裴伟等[14 ] 利用深度残差网络和特征融合改进SSD,使算法适于航拍目标检测. FPN存在2种损失:1)在特征融合之前,输入的特征图须先经过1×1卷积将通道数降为256,这个过程是造成通道信息丢失的主要原因,称为降维损失. 2)不同尺度特征图间存在语义鸿沟,直接将不同尺度特征图相加融合会导致混叠效应(aliasing effects)[15 ] ,陷入次优特征金字塔,称为融合损失. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
改进的SSD航拍目标检测方法
1
2019
... 小目标检测是目标检测的难点,SSD在小目标物体繁多、应用场景复杂情况下的检测精度较低. 检测小目标物体需要精细的特征和足够的语义信息以便将物体与背景区分开,SSD的低级特征层虽然有精细的特征,但是语义信息不足. 许多检测器利用特征金字塔网络(feature pyramid network,FPN)[11 ] 来解决这个问题. Li等[12 ] 利用特征融合改进SSD,提出FSSD算法. 该模型借鉴FPN的概念,在保证检测速度的同时提升了模型的检测精度. Lin等[13 ] 提出的RetinaNet将FPN融入算法,不但用低层特征图补充了高级语义信息,还保留了低层细节信息. 不仅如此,RetinaNet中的Focal Loss[13 ] 损失函数,还让单阶段检测器的检测精度超过了双阶段检测器的. 裴伟等[14 ] 利用深度残差网络和特征融合改进SSD,使算法适于航拍目标检测. FPN存在2种损失:1)在特征融合之前,输入的特征图须先经过1×1卷积将通道数降为256,这个过程是造成通道信息丢失的主要原因,称为降维损失. 2)不同尺度特征图间存在语义鸿沟,直接将不同尺度特征图相加融合会导致混叠效应(aliasing effects)[15 ] ,陷入次优特征金字塔,称为融合损失. ...
改进的SSD航拍目标检测方法
1
2019
... 小目标检测是目标检测的难点,SSD在小目标物体繁多、应用场景复杂情况下的检测精度较低. 检测小目标物体需要精细的特征和足够的语义信息以便将物体与背景区分开,SSD的低级特征层虽然有精细的特征,但是语义信息不足. 许多检测器利用特征金字塔网络(feature pyramid network,FPN)[11 ] 来解决这个问题. Li等[12 ] 利用特征融合改进SSD,提出FSSD算法. 该模型借鉴FPN的概念,在保证检测速度的同时提升了模型的检测精度. Lin等[13 ] 提出的RetinaNet将FPN融入算法,不但用低层特征图补充了高级语义信息,还保留了低层细节信息. 不仅如此,RetinaNet中的Focal Loss[13 ] 损失函数,还让单阶段检测器的检测精度超过了双阶段检测器的. 裴伟等[14 ] 利用深度残差网络和特征融合改进SSD,使算法适于航拍目标检测. FPN存在2种损失:1)在特征融合之前,输入的特征图须先经过1×1卷积将通道数降为256,这个过程是造成通道信息丢失的主要原因,称为降维损失. 2)不同尺度特征图间存在语义鸿沟,直接将不同尺度特征图相加融合会导致混叠效应(aliasing effects)[15 ] ,陷入次优特征金字塔,称为融合损失. ...
1
... 小目标检测是目标检测的难点,SSD在小目标物体繁多、应用场景复杂情况下的检测精度较低. 检测小目标物体需要精细的特征和足够的语义信息以便将物体与背景区分开,SSD的低级特征层虽然有精细的特征,但是语义信息不足. 许多检测器利用特征金字塔网络(feature pyramid network,FPN)[11 ] 来解决这个问题. Li等[12 ] 利用特征融合改进SSD,提出FSSD算法. 该模型借鉴FPN的概念,在保证检测速度的同时提升了模型的检测精度. Lin等[13 ] 提出的RetinaNet将FPN融入算法,不但用低层特征图补充了高级语义信息,还保留了低层细节信息. 不仅如此,RetinaNet中的Focal Loss[13 ] 损失函数,还让单阶段检测器的检测精度超过了双阶段检测器的. 裴伟等[14 ] 利用深度残差网络和特征融合改进SSD,使算法适于航拍目标检测. FPN存在2种损失:1)在特征融合之前,输入的特征图须先经过1×1卷积将通道数降为256,这个过程是造成通道信息丢失的主要原因,称为降维损失. 2)不同尺度特征图间存在语义鸿沟,直接将不同尺度特征图相加融合会导致混叠效应(aliasing effects)[15 ] ,陷入次优特征金字塔,称为融合损失. ...
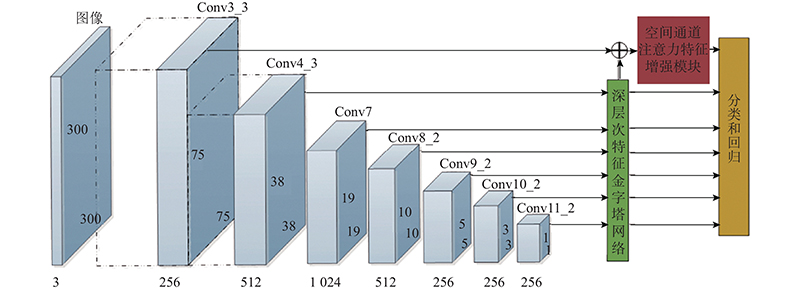
4
... 本研究提出基于优化特征与深层次融合的目标检测算法(single-stage object detection algorithm based on feature enhancement and deep fusion, FEDet). 1)在SSD基础上额外添加Conv3_3层特征图用于小目标预测,增加小目标默认框个数;利用空间通道注意力特征增强模块(spatial and channel attention feature enhancement, SCFE)优化Conv3_3层,增加Conv3_3层的非线性程度,突出该层覆盖小目标的细节信息,提升小目标检测效果. 2)改进FPN为深层次特征金字塔网络(DFPN),利用残差空间与通道特征增强(residual spatial and channel attention feature enhancement, RSCFE)结构补充FPN的降维信息损失;基于AugFPN的一致性监督(consistent supervision)[16 ] 方法,在特征金字塔中添加监督信号,减少FPN的融合信息损失;将DFPN作用于原SSD预测特征图,丰富特征图的语义信息,提升检测器精度. 3)在SSD的训练策略基础上,添加基于距离交并比的样本加权训练策略(distance intersection over union-prime sample attention,DIoU-Pisa),使用DIoU[17 ] 衡量预测框定位的精确度,对样本进行归一化加权,使网络注重训练定位良好且分类置信度高的样本,提升检测器的精度和鲁棒性. ...
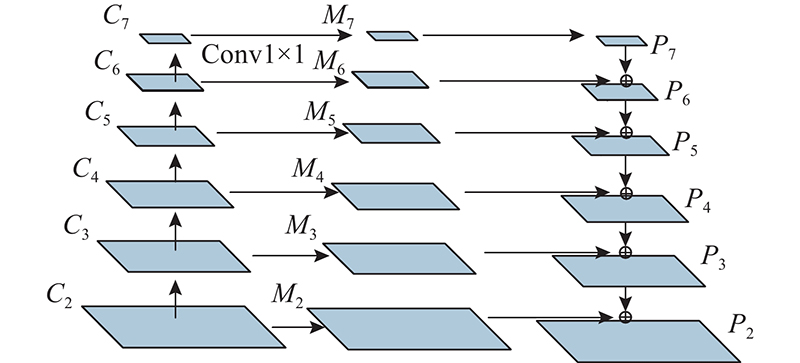
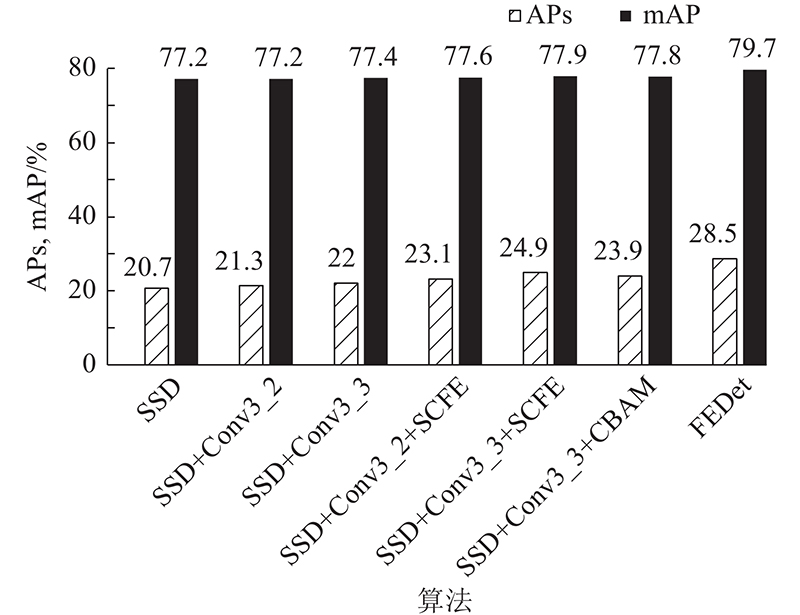
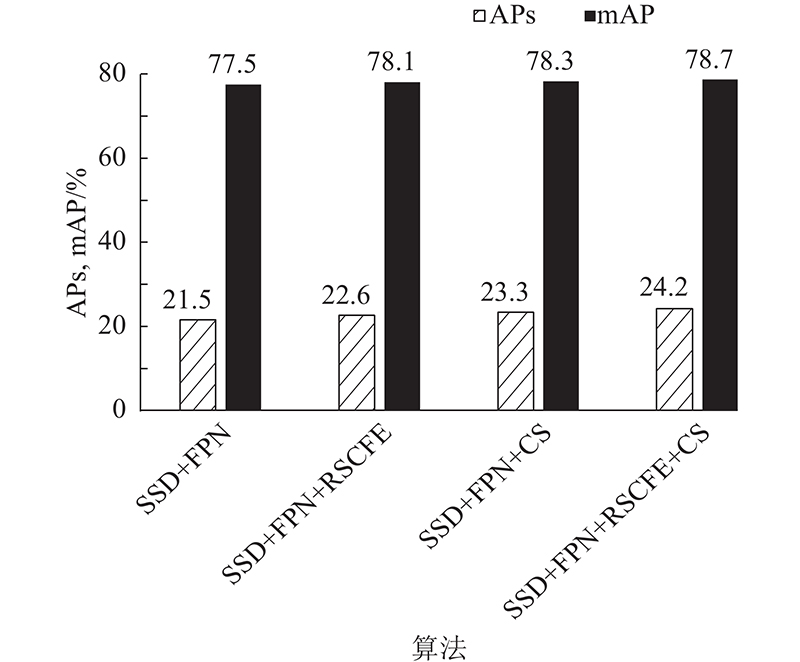
... SSD算法的多尺度特征金字塔存在明显缺陷,即低层特征图缺乏语义信息而高层特征图缺乏细节信息,导致SSD算法检测效果不佳,因此本研究利用FPN对用于预测的特征层Conv4_3、Conv7进行特征融合. 如图6 所示,C 2 ~C 7 分别表示原SSD预测特征层Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2,M 2 ~M 7 分别表示C 2 ~C 7 经过1×1卷积降维但未进行特征融合的特征图,P 2 ~P 7 表示自顶向下特征融合的特征图. 实验结果表明,由于FPN本身存在缺陷,FPN对SSD算法检测精度提升不明显. 为此,对FPN进行改进,使改进后的FPN能够显著提升算法检测精度. 针对FPN存在特征层降维的信息损失和不同特征层的语义鸿沟问题,本研究基于RSCFE和一致性监督(consistent supervision,CS)[16 ] 来改进FPN,实现深层次的特征融合. CS的作用是将P 2 ~P 7 金字塔生成的预测框映射到M 2 ~M 7 上,以生成感兴趣区域(region of intersect,ROI). 并将ROI用于预测,生成辅助损失,迫使M 2 ~M 7 特征图间生成相似的语义信息,缓解融合信息损失. 在测试阶段,无需使用损失函数,因此CS在该阶段不增加计算量. ...
... 基于SSD添加FPN,并且利用2种方法改进FPN进行,提升模型mAP的同时提升小目标检测精度,2种方法的消融实验结果如图13 所示. FPN作用在Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2层上,对SSD算法检测精度略有提升. 先利用RSCFE结构改进FPN,使得mAP提升0.006,APS 提升0.011,说明RSCFE结构能够减少降维引起的信息损失;再利用Consistent Supervision(CS)[16 ] 方法改进FPN,算法mAP=78.3%,APS =23.3%. 共同运用2种方法即DFPN,使得SSD算法mAP=78.7%,并且小目标检测精度提升显著. 该实验结果表明,RSCFE和CS能有效补助FPN缺陷,大幅提升检测精度. ...
... 针对SSD检测器存在检测精度不高以及对小目标检测误差较大的问题,提出基于特征优化与深层次特征融合的目标检测器. 将空间通道注意力作用于SSD的Conv3_3层,提升小目标检测效果;利用残差空间通道信息增强和CS[16 ] 改进FPN,并将改进的FPN作用于SSD预测特征层;由于添加大量的默认框,采用DIoU-Pisa策略,侧重对定位良好并且分类置信度高的样本的训练. 在PASCAL VOC2007测试集上的实验表明,FEDet的检测精度为79.7%,相对于SSD,提升0.025,检测速度为39帧/s. 在COCO数据集上FEDet的mAP比SSD提高0.045,对小目标物体检测效果比原SSD更优. FEDet是高精度且有利于小目标检测的实时检测算法,适用于高精度的实时检测应用场景,但FEDet还存在骨干网络VGG16的特征提取能力不足的问题. 在SCFE不同结合方式的消融实验中,先通道后空间结合方式的精度为77.5%,下一步计划着重研究不同注意力机制的结合效果,以获得更好的检测结果. ...
1
... 本研究提出基于优化特征与深层次融合的目标检测算法(single-stage object detection algorithm based on feature enhancement and deep fusion, FEDet). 1)在SSD基础上额外添加Conv3_3层特征图用于小目标预测,增加小目标默认框个数;利用空间通道注意力特征增强模块(spatial and channel attention feature enhancement, SCFE)优化Conv3_3层,增加Conv3_3层的非线性程度,突出该层覆盖小目标的细节信息,提升小目标检测效果. 2)改进FPN为深层次特征金字塔网络(DFPN),利用残差空间与通道特征增强(residual spatial and channel attention feature enhancement, RSCFE)结构补充FPN的降维信息损失;基于AugFPN的一致性监督(consistent supervision)[16 ] 方法,在特征金字塔中添加监督信号,减少FPN的融合信息损失;将DFPN作用于原SSD预测特征图,丰富特征图的语义信息,提升检测器精度. 3)在SSD的训练策略基础上,添加基于距离交并比的样本加权训练策略(distance intersection over union-prime sample attention,DIoU-Pisa),使用DIoU[17 ] 衡量预测框定位的精确度,对样本进行归一化加权,使网络注重训练定位良好且分类置信度高的样本,提升检测器的精度和鲁棒性. ...
1
... SSD以VGG16[18 ] 为主干网络,由主干网络提取的多尺度特征图组成特征金字塔来检测不同尺寸的目标. 虽然这种检测策略提升了检测的准确度和对不同尺寸物体的泛化性能,但SSD的特征提取能力有限,且低层特征图缺少语义信息,因此对小目标物体检测误差较大. SSD是高效的全卷积实时检测网络,本研究将SSD作为基础网络,从以下两个方面对SSD进行改进:1)为了提高网络的特征提取能力,用特征提取能力更强的主干网络替换VGG16;2)为了提高特征的表征能力,对不同尺度特征图进行特征融合,以丰富特征图的语义信息并保留细节信息. DSSD[19 ] 以ResNet-101为主干网络,添加预测结构和反卷积结构,不仅提升了特征的表征能力,还引入了空间上下文信息. FSSD中的特征融合模块提升了低层特征图的表征能力. RetinaNet以ResNet-101为主干网络,融入FPN,Focal loss函数使模型更注重对难分样本的训练. 上述网络算法均有助于提升检测效果,但ResNet-101的网络较复杂,残差连接和卷积层较多,导致模型推理速度大幅下降,VGG16的特征提取能力不足,但推理速度较快,因此本研究以VGG16为主干网络. ...
多尺度目标检测的深度学习研究综述
3
2021
... SSD以VGG16[18 ] 为主干网络,由主干网络提取的多尺度特征图组成特征金字塔来检测不同尺寸的目标. 虽然这种检测策略提升了检测的准确度和对不同尺寸物体的泛化性能,但SSD的特征提取能力有限,且低层特征图缺少语义信息,因此对小目标物体检测误差较大. SSD是高效的全卷积实时检测网络,本研究将SSD作为基础网络,从以下两个方面对SSD进行改进:1)为了提高网络的特征提取能力,用特征提取能力更强的主干网络替换VGG16;2)为了提高特征的表征能力,对不同尺度特征图进行特征融合,以丰富特征图的语义信息并保留细节信息. DSSD[19 ] 以ResNet-101为主干网络,添加预测结构和反卷积结构,不仅提升了特征的表征能力,还引入了空间上下文信息. FSSD中的特征融合模块提升了低层特征图的表征能力. RetinaNet以ResNet-101为主干网络,融入FPN,Focal loss函数使模型更注重对难分样本的训练. 上述网络算法均有助于提升检测效果,但ResNet-101的网络较复杂,残差连接和卷积层较多,导致模型推理速度大幅下降,VGG16的特征提取能力不足,但推理速度较快,因此本研究以VGG16为主干网络. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
... Different types of target detection accuracy results on VOC2007 test set
Tab.4 算法 mAP/% aero bird boat bottle car person plant sheep train tv SSD300[7 ] 77.1 75.3 68.0 50.4 85.2 80.2 47.5 76.1 86.3 77.0 DSSD321[19 ] 81.9 80.5 68.4 53.9 86.2 79.7 51.7 78.0 87.2 79.4 STDN300[30 ] 81.1 76.4 69.2 52.4 84.2 76.8 51.8 78.4 87.5 77.8 FAENet300[31 ] 82.8 76.5 74.7 58.7 87.5 81.4 57.7 80.4 86.8 79.6 FEDet 84.0 79.3 75.6 59.1 86.7 80.0 59.2 79.5 87.9 79.9
SSD与FEDet在VOC2007数据集上的检测效果对比如图10 所示. 图10 (a)中有3张椅子,较为密集,FEDet更容易检测密集的目标. 图10 (b)中,SSD无法检测出被遮挡的椅子,FEDet检测成功,表明FEDet更容易检测被遮挡的目标. 图10 (c)中SSD无法检测出小目标物体,FEDet检测成功,表明FEDet适合小目标物体的检测. ...
多尺度目标检测的深度学习研究综述
3
2021
... SSD以VGG16[18 ] 为主干网络,由主干网络提取的多尺度特征图组成特征金字塔来检测不同尺寸的目标. 虽然这种检测策略提升了检测的准确度和对不同尺寸物体的泛化性能,但SSD的特征提取能力有限,且低层特征图缺少语义信息,因此对小目标物体检测误差较大. SSD是高效的全卷积实时检测网络,本研究将SSD作为基础网络,从以下两个方面对SSD进行改进:1)为了提高网络的特征提取能力,用特征提取能力更强的主干网络替换VGG16;2)为了提高特征的表征能力,对不同尺度特征图进行特征融合,以丰富特征图的语义信息并保留细节信息. DSSD[19 ] 以ResNet-101为主干网络,添加预测结构和反卷积结构,不仅提升了特征的表征能力,还引入了空间上下文信息. FSSD中的特征融合模块提升了低层特征图的表征能力. RetinaNet以ResNet-101为主干网络,融入FPN,Focal loss函数使模型更注重对难分样本的训练. 上述网络算法均有助于提升检测效果,但ResNet-101的网络较复杂,残差连接和卷积层较多,导致模型推理速度大幅下降,VGG16的特征提取能力不足,但推理速度较快,因此本研究以VGG16为主干网络. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
... Different types of target detection accuracy results on VOC2007 test set
Tab.4 算法 mAP/% aero bird boat bottle car person plant sheep train tv SSD300[7 ] 77.1 75.3 68.0 50.4 85.2 80.2 47.5 76.1 86.3 77.0 DSSD321[19 ] 81.9 80.5 68.4 53.9 86.2 79.7 51.7 78.0 87.2 79.4 STDN300[30 ] 81.1 76.4 69.2 52.4 84.2 76.8 51.8 78.4 87.5 77.8 FAENet300[31 ] 82.8 76.5 74.7 58.7 87.5 81.4 57.7 80.4 86.8 79.6 FEDet 84.0 79.3 75.6 59.1 86.7 80.0 59.2 79.5 87.9 79.9
SSD与FEDet在VOC2007数据集上的检测效果对比如图10 所示. 图10 (a)中有3张椅子,较为密集,FEDet更容易检测密集的目标. 图10 (b)中,SSD无法检测出被遮挡的椅子,FEDet检测成功,表明FEDet更容易检测被遮挡的目标. 图10 (c)中SSD无法检测出小目标物体,FEDet检测成功,表明FEDet适合小目标物体的检测. ...
1
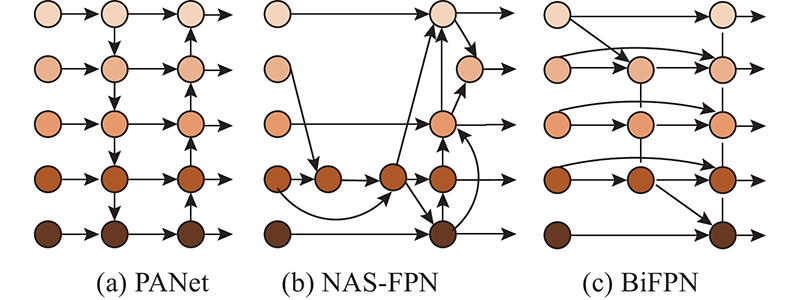
... FPN构造的横向连接和带有自顶向下融合的层级结构,在目标检测算法中被广泛使用. 由于FPN存在降维、融合损失,导致特征没有进行深层次的融合. 如图1 所示为3种改进的FPN的结构图. PANet[20 ] 添加从下向上再次融合的结构,使融合更进一步;NAS-FPN[21 ] 中的不规则融合路径和反复堆叠,提升了检测精度;BiFPN[22 ] 先在PANet的基础上给每个层级添加残差连接,然后进行反复堆叠特征融合,每个融合的特征层均被添加归一化权重以学习特征层的重要性、减少融合损失,达到更深层次特征融合的目的. 反复堆叠自顶向下、从下向上特征融合结构的方法虽然能够提升算法的检测精度,但是计算的复杂度大幅增加,造成算法的检测速度损失严重. 本研究用DFPN进行深度特征融合,以解决降维、融合损失,提升检测精度并保持实时检测的速度. ...
1
... FPN构造的横向连接和带有自顶向下融合的层级结构,在目标检测算法中被广泛使用. 由于FPN存在降维、融合损失,导致特征没有进行深层次的融合. 如图1 所示为3种改进的FPN的结构图. PANet[20 ] 添加从下向上再次融合的结构,使融合更进一步;NAS-FPN[21 ] 中的不规则融合路径和反复堆叠,提升了检测精度;BiFPN[22 ] 先在PANet的基础上给每个层级添加残差连接,然后进行反复堆叠特征融合,每个融合的特征层均被添加归一化权重以学习特征层的重要性、减少融合损失,达到更深层次特征融合的目的. 反复堆叠自顶向下、从下向上特征融合结构的方法虽然能够提升算法的检测精度,但是计算的复杂度大幅增加,造成算法的检测速度损失严重. 本研究用DFPN进行深度特征融合,以解决降维、融合损失,提升检测精度并保持实时检测的速度. ...
Water meter pointer reading recognition method based on target-key point detection
1
2021
... FPN构造的横向连接和带有自顶向下融合的层级结构,在目标检测算法中被广泛使用. 由于FPN存在降维、融合损失,导致特征没有进行深层次的融合. 如图1 所示为3种改进的FPN的结构图. PANet[20 ] 添加从下向上再次融合的结构,使融合更进一步;NAS-FPN[21 ] 中的不规则融合路径和反复堆叠,提升了检测精度;BiFPN[22 ] 先在PANet的基础上给每个层级添加残差连接,然后进行反复堆叠特征融合,每个融合的特征层均被添加归一化权重以学习特征层的重要性、减少融合损失,达到更深层次特征融合的目的. 反复堆叠自顶向下、从下向上特征融合结构的方法虽然能够提升算法的检测精度,但是计算的复杂度大幅增加,造成算法的检测速度损失严重. 本研究用DFPN进行深度特征融合,以解决降维、融合损失,提升检测精度并保持实时检测的速度. ...
Squeeze-and-excitation networks
1
2020
... He等[23 ] 提出SENet,通过压缩与激励操作构建通道之间的关系,完成通道特征重标定. Woo等[24 ] 提出的CBAM能够有效获取空间与通道信息,模型的特征提取能力得以提升. Zhang等[25 ] 采用轻量、高效的金字塔压缩模块(pyramid squeeze attention,PSA),该模块获取多尺度的空间特征并与通道注意力关联. 本研究所提SCFE模块通过捕获不同尺度空间特征来完成通道特征重标定,以此优化特征层. ...
1
... He等[23 ] 提出SENet,通过压缩与激励操作构建通道之间的关系,完成通道特征重标定. Woo等[24 ] 提出的CBAM能够有效获取空间与通道信息,模型的特征提取能力得以提升. Zhang等[25 ] 采用轻量、高效的金字塔压缩模块(pyramid squeeze attention,PSA),该模块获取多尺度的空间特征并与通道注意力关联. 本研究所提SCFE模块通过捕获不同尺度空间特征来完成通道特征重标定,以此优化特征层. ...
1
... He等[23 ] 提出SENet,通过压缩与激励操作构建通道之间的关系,完成通道特征重标定. Woo等[24 ] 提出的CBAM能够有效获取空间与通道信息,模型的特征提取能力得以提升. Zhang等[25 ] 采用轻量、高效的金字塔压缩模块(pyramid squeeze attention,PSA),该模块获取多尺度的空间特征并与通道注意力关联. 本研究所提SCFE模块通过捕获不同尺度空间特征来完成通道特征重标定,以此优化特征层. ...
1
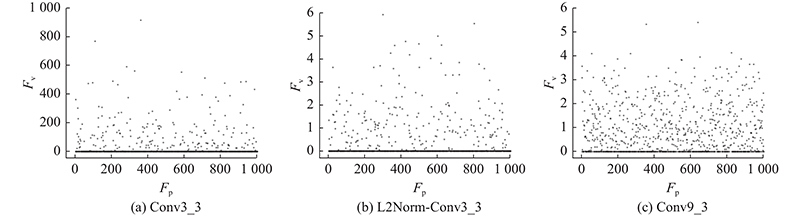
... 为了提高模型对小目标的检测效果,增加Conv3_3层用于小目标检测. 相比于Conv3_2层,Conv3_3层不仅特征表现力更好,而且更接近Conv4_3层,更有利于后续的特征融合. 虽然Conv3_3经过卷积次数少,含有覆盖小目标的细节信息更充足,但是Conv3_3层的数据与高层特征层(如Conv9_2层)的数据分布差异较大,较大的Conv3_3层数将使高层特征层无法影响分类和回归[26 ] ,导致模型训练效果不佳. 要让Conv3_3层与Conv4_3层的数值范围相同,须用L2 Normalization处理Conv3_3层. 分别在未经处理的Conv3_3、处理后的Conv3_3(L2Norm-Conv3_3 )、Conv9_2特征图中随机选取1 000个特征点,如图3 所示. 图中,F P 为特征点编号,F V 为特征数值. 可以看出,L2Norm-Conv3_3与Conv9_2的数值大小相近. 在SSD特征金字塔中,Conv3_3是底层特征图,与Conv4_3层一起被用于检测小占比目标;Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2均为高层特征层,它们缺乏细节信息但含有丰富的语义信息,被用于检测中大占比目标. ...
基于深度学习的小目标检测研究与应用综述
1
2020
... 小目标的定义主要有2种[27 ] :1)当目标物体的像素点小于32×32时,目标物体可以当作绝对小目标物体;2)当目标物体尺寸不超过原图尺寸的10%时,目标物体可以当作相对小目标物体. 本研究所提模型的输入尺寸为300×300,因此Conv3_3、Conv4_3生成的默认框适合用于检测小目标. Conv3_3上生成的默认框比Conv4_3更小、更多,以增加小目标默认框的方式增加训练数据量,能够提升小目标检测的精度. Conv3_3层富含覆盖小目标的细节信息,但缺乏语义信息,影响小目标检测的效果. 增加非线性程度的模型能够拟合更复杂的函数,提取更高级的语义信息,提升模型检测精度和鲁棒性. 将Conv3_3与特征融合后的Conv4_3相加,再经过空间通道特征增强模块增强,得到新的Conv3_3. 新的Conv3_3既能够增加语义信息,又能够突出细节信息,利于检测小目标. ...
基于深度学习的小目标检测研究与应用综述
1
2020
... 小目标的定义主要有2种[27 ] :1)当目标物体的像素点小于32×32时,目标物体可以当作绝对小目标物体;2)当目标物体尺寸不超过原图尺寸的10%时,目标物体可以当作相对小目标物体. 本研究所提模型的输入尺寸为300×300,因此Conv3_3、Conv4_3生成的默认框适合用于检测小目标. Conv3_3上生成的默认框比Conv4_3更小、更多,以增加小目标默认框的方式增加训练数据量,能够提升小目标检测的精度. Conv3_3层富含覆盖小目标的细节信息,但缺乏语义信息,影响小目标检测的效果. 增加非线性程度的模型能够拟合更复杂的函数,提取更高级的语义信息,提升模型检测精度和鲁棒性. 将Conv3_3与特征融合后的Conv4_3相加,再经过空间通道特征增强模块增强,得到新的Conv3_3. 新的Conv3_3既能够增加语义信息,又能够突出细节信息,利于检测小目标. ...
1
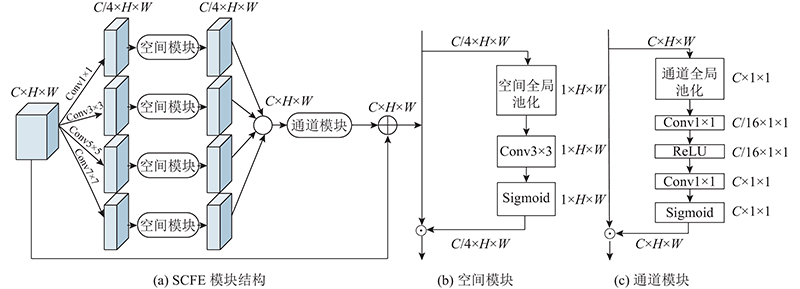
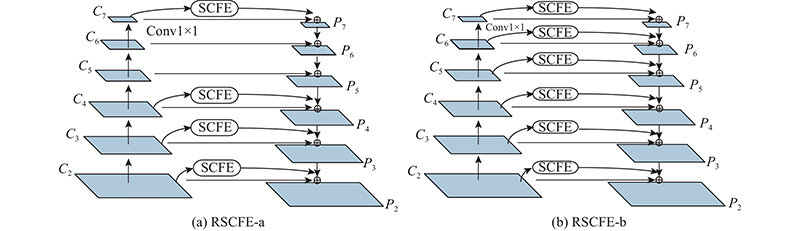
... 在FPN中,须先对输入的多尺度特征图C 2 ~C 7 进行1×1卷积的降维操作,以统一各特征图的通道数,方便后续的特征融合,得到M 2 ~M 7 . 在降维过程中,各特征图损失了许多通道信息,在后续自顶向下的特征融合过程中,低层特征图可由来自高层特征图的语义信息增强特征表现力,而顶层特征图没有其他层的信息补充. 如表2 所示,FPN的C 2 、C 3 、C 4 层经过1×1卷积分别得到M 2 、M 3 、M 4 ,通道数减少,信息损失较为严重. 表中,T C 为C 层通道数,T M 为M 层为通道数. 参考Qin等[28 ] 通过结合全局池化提取的全局上下文特征来减轻信息丢失的方法,将SCFE模块中的短连接剪除后当作残差连接,作用于C 2 、C 3 、C 4 、C 7 和P 2 、P 3 、P 4 、P 7 之间,补充特征图的空间信息和全局通道信息,从而减少信息丢失,如图7 (a). 设计如图7 (b)的连接结构,以检测精度为评估标准进行实验. 图7 的2种残差连接方式检测精度相差无几,同时图7 (a)连接结构更简洁,参数量更少,因此本研究采用如图7 (a)连接方式. ...
1
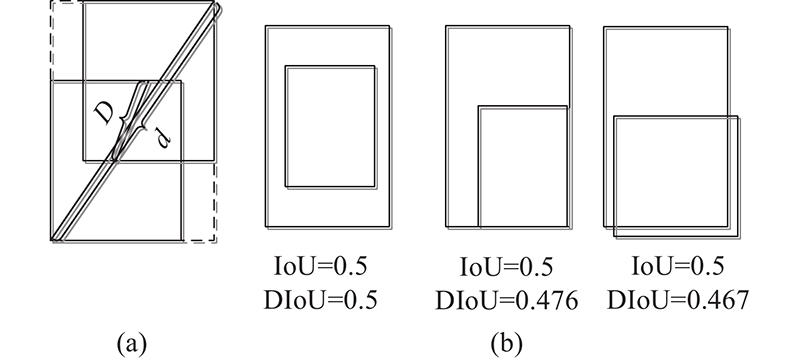
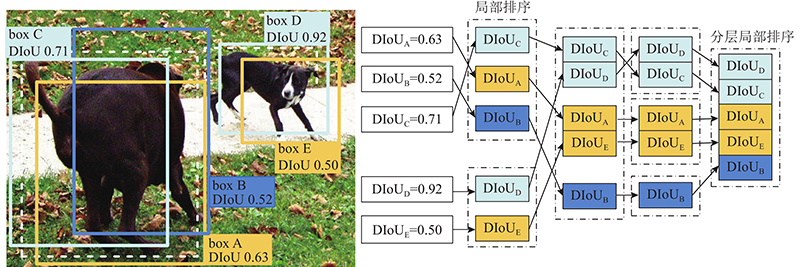
... 原SSD采用难例挖掘策略训练样本,该策略虽然能够缓解正负样本不均衡问题,但没有侧重训练对模型训练有效的样本. 本研究添加主要样本训练策略(prime sample attention,Pisa)[29 ] 对分类和回归后的样本进行加权. Pisa将真实框IoU较高的正样本和分类置信度较高的负样本认定为影响的模型训练效果的主要因素,还认定分类和回归的目标相关. Pisa根据IoU分层局部排序和置信度分层局部排序的结果对样本重加权,以表示出不同样本的重要程度. 在IoU分层局部排序中, Pisa用IoU表示样本和真实框的重叠度,据此进行分组并局部排序. 由于IoU无法反映2个物体的重叠方式,本研究提出基于DIoU的主要样本训练(DIoU prime sample attention,DIoU-Pisa),用DIoU表示样本和真实框的重叠度. 相比于IoU,DIoU添加了表示样本框与真实框的中心点间的距离的惩罚项,表达式为 ...
3
... 采用目标检测公开数据集PASCAL VOC对FEDet进行性能评估. 评估指标分别为平均检测精度mAP和检测速度s . 本研究的网络模型和SSD网络将VOC 2007、VOC 2012的训练集和验证集作为训练集,共16 551张图片,测试在VOC2007的测试集上进行,共4 952张图片. 对比方法包括1)双阶段经典算法Faster R-CNN,2)单阶段算法经典算法SSD、YOLOv2和YOLOv3,3)以SSD为基础改进的DSSD、FSSD、尺度变换目标检测器[30 ] (scale-transferrable object detection,STDN)、高精度单阶段算法RetinaNet和特征聚合与增强的单阶段算法[31 ] (single-shot object detector with feature aggregation and enhancement, FAENet),4)单阶段无锚框检测算法FCOS[32 ] 和ATSS[33 ] 算法. 如表3 所示为各方法在PASCAL VOC2007测试集上的检测结果. 其中SSD、FAENet、FCOS和ATSS由开源代码实验得到. 由表可知,双阶段检测算法的检测精度普遍高于单阶段算法,但其检测速度较为缓慢. FEDet属于单阶段算法,mAP =79.7%、s =39帧/s,比DSSD321和RetinaNet的检测性能高,比YOLOV2, YOLOv3[35 ] , SSD300, STDN300和FSSD300的精度高,与FAENet的检测性能相近. 与单阶段无锚框算法FCOS和ATSS相比,FEDet的平均检测精度分别高0.019和0.015. STDN是兼顾速度与精度的算法,FEDet的检测速度与STDN300相近,但精度比STDN高0.016. 与SSD相比,FEDet的检测速度稍有下降,但依然能达到实时检测要求. 如表4 所示,为了进一步验证FEDet有效提高检测效果,选择与FEDet输入图片尺寸差异不大的单阶段算法,测试在VOC2007数据集上各类别的平均检测精度. 在10个类别中,FEDet在检测aero、boat、bottle、plant、train、tv类别时的精度是测试算法中最高,在检测 bottle、plant这些小目标出现频次较高的类别中,FEDet相比于SSD有改善最显著,同时比性能最优的FAENet精度更高. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
... Different types of target detection accuracy results on VOC2007 test set
Tab.4 算法 mAP/% aero bird boat bottle car person plant sheep train tv SSD300[7 ] 77.1 75.3 68.0 50.4 85.2 80.2 47.5 76.1 86.3 77.0 DSSD321[19 ] 81.9 80.5 68.4 53.9 86.2 79.7 51.7 78.0 87.2 79.4 STDN300[30 ] 81.1 76.4 69.2 52.4 84.2 76.8 51.8 78.4 87.5 77.8 FAENet300[31 ] 82.8 76.5 74.7 58.7 87.5 81.4 57.7 80.4 86.8 79.6 FEDet 84.0 79.3 75.6 59.1 86.7 80.0 59.2 79.5 87.9 79.9
SSD与FEDet在VOC2007数据集上的检测效果对比如图10 所示. 图10 (a)中有3张椅子,较为密集,FEDet更容易检测密集的目标. 图10 (b)中,SSD无法检测出被遮挡的椅子,FEDet检测成功,表明FEDet更容易检测被遮挡的目标. 图10 (c)中SSD无法检测出小目标物体,FEDet检测成功,表明FEDet适合小目标物体的检测. ...
4
... 采用目标检测公开数据集PASCAL VOC对FEDet进行性能评估. 评估指标分别为平均检测精度mAP和检测速度s . 本研究的网络模型和SSD网络将VOC 2007、VOC 2012的训练集和验证集作为训练集,共16 551张图片,测试在VOC2007的测试集上进行,共4 952张图片. 对比方法包括1)双阶段经典算法Faster R-CNN,2)单阶段算法经典算法SSD、YOLOv2和YOLOv3,3)以SSD为基础改进的DSSD、FSSD、尺度变换目标检测器[30 ] (scale-transferrable object detection,STDN)、高精度单阶段算法RetinaNet和特征聚合与增强的单阶段算法[31 ] (single-shot object detector with feature aggregation and enhancement, FAENet),4)单阶段无锚框检测算法FCOS[32 ] 和ATSS[33 ] 算法. 如表3 所示为各方法在PASCAL VOC2007测试集上的检测结果. 其中SSD、FAENet、FCOS和ATSS由开源代码实验得到. 由表可知,双阶段检测算法的检测精度普遍高于单阶段算法,但其检测速度较为缓慢. FEDet属于单阶段算法,mAP =79.7%、s =39帧/s,比DSSD321和RetinaNet的检测性能高,比YOLOV2, YOLOv3[35 ] , SSD300, STDN300和FSSD300的精度高,与FAENet的检测性能相近. 与单阶段无锚框算法FCOS和ATSS相比,FEDet的平均检测精度分别高0.019和0.015. STDN是兼顾速度与精度的算法,FEDet的检测速度与STDN300相近,但精度比STDN高0.016. 与SSD相比,FEDet的检测速度稍有下降,但依然能达到实时检测要求. 如表4 所示,为了进一步验证FEDet有效提高检测效果,选择与FEDet输入图片尺寸差异不大的单阶段算法,测试在VOC2007数据集上各类别的平均检测精度. 在10个类别中,FEDet在检测aero、boat、bottle、plant、train、tv类别时的精度是测试算法中最高,在检测 bottle、plant这些小目标出现频次较高的类别中,FEDet相比于SSD有改善最显著,同时比性能最优的FAENet精度更高. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
... Different types of target detection accuracy results on VOC2007 test set
Tab.4 算法 mAP/% aero bird boat bottle car person plant sheep train tv SSD300[7 ] 77.1 75.3 68.0 50.4 85.2 80.2 47.5 76.1 86.3 77.0 DSSD321[19 ] 81.9 80.5 68.4 53.9 86.2 79.7 51.7 78.0 87.2 79.4 STDN300[30 ] 81.1 76.4 69.2 52.4 84.2 76.8 51.8 78.4 87.5 77.8 FAENet300[31 ] 82.8 76.5 74.7 58.7 87.5 81.4 57.7 80.4 86.8 79.6 FEDet 84.0 79.3 75.6 59.1 86.7 80.0 59.2 79.5 87.9 79.9
SSD与FEDet在VOC2007数据集上的检测效果对比如图10 所示. 图10 (a)中有3张椅子,较为密集,FEDet更容易检测密集的目标. 图10 (b)中,SSD无法检测出被遮挡的椅子,FEDet检测成功,表明FEDet更容易检测被遮挡的目标. 图10 (c)中SSD无法检测出小目标物体,FEDet检测成功,表明FEDet适合小目标物体的检测. ...
... Experiment results of different algorithms on COCO dataset
Tab.5 算法 AP AP50 AP75 APS APM APL % SSD[7 ] 25.6 43.8 26.3 6.8 27.8 42.2 YOLOv3[35 ] 28.2 51.5 29.7 11.9 30.6 43.4 RefineDet[36 ] 29.4 49.2 31.3 10.0 32.0 44.4 FAENet[31 ] 28.3 47.9 29.7 10.5 30.9 41.9 FEDet 30.1 50.0 31.2 13.3 33.2 44.0
图 11 2种算法在COCO数据集上检测结果对比 ...
2
... 采用目标检测公开数据集PASCAL VOC对FEDet进行性能评估. 评估指标分别为平均检测精度mAP和检测速度s . 本研究的网络模型和SSD网络将VOC 2007、VOC 2012的训练集和验证集作为训练集,共16 551张图片,测试在VOC2007的测试集上进行,共4 952张图片. 对比方法包括1)双阶段经典算法Faster R-CNN,2)单阶段算法经典算法SSD、YOLOv2和YOLOv3,3)以SSD为基础改进的DSSD、FSSD、尺度变换目标检测器[30 ] (scale-transferrable object detection,STDN)、高精度单阶段算法RetinaNet和特征聚合与增强的单阶段算法[31 ] (single-shot object detector with feature aggregation and enhancement, FAENet),4)单阶段无锚框检测算法FCOS[32 ] 和ATSS[33 ] 算法. 如表3 所示为各方法在PASCAL VOC2007测试集上的检测结果. 其中SSD、FAENet、FCOS和ATSS由开源代码实验得到. 由表可知,双阶段检测算法的检测精度普遍高于单阶段算法,但其检测速度较为缓慢. FEDet属于单阶段算法,mAP =79.7%、s =39帧/s,比DSSD321和RetinaNet的检测性能高,比YOLOV2, YOLOv3[35 ] , SSD300, STDN300和FSSD300的精度高,与FAENet的检测性能相近. 与单阶段无锚框算法FCOS和ATSS相比,FEDet的平均检测精度分别高0.019和0.015. STDN是兼顾速度与精度的算法,FEDet的检测速度与STDN300相近,但精度比STDN高0.016. 与SSD相比,FEDet的检测速度稍有下降,但依然能达到实时检测要求. 如表4 所示,为了进一步验证FEDet有效提高检测效果,选择与FEDet输入图片尺寸差异不大的单阶段算法,测试在VOC2007数据集上各类别的平均检测精度. 在10个类别中,FEDet在检测aero、boat、bottle、plant、train、tv类别时的精度是测试算法中最高,在检测 bottle、plant这些小目标出现频次较高的类别中,FEDet相比于SSD有改善最显著,同时比性能最优的FAENet精度更高. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
2
... 采用目标检测公开数据集PASCAL VOC对FEDet进行性能评估. 评估指标分别为平均检测精度mAP和检测速度s . 本研究的网络模型和SSD网络将VOC 2007、VOC 2012的训练集和验证集作为训练集,共16 551张图片,测试在VOC2007的测试集上进行,共4 952张图片. 对比方法包括1)双阶段经典算法Faster R-CNN,2)单阶段算法经典算法SSD、YOLOv2和YOLOv3,3)以SSD为基础改进的DSSD、FSSD、尺度变换目标检测器[30 ] (scale-transferrable object detection,STDN)、高精度单阶段算法RetinaNet和特征聚合与增强的单阶段算法[31 ] (single-shot object detector with feature aggregation and enhancement, FAENet),4)单阶段无锚框检测算法FCOS[32 ] 和ATSS[33 ] 算法. 如表3 所示为各方法在PASCAL VOC2007测试集上的检测结果. 其中SSD、FAENet、FCOS和ATSS由开源代码实验得到. 由表可知,双阶段检测算法的检测精度普遍高于单阶段算法,但其检测速度较为缓慢. FEDet属于单阶段算法,mAP =79.7%、s =39帧/s,比DSSD321和RetinaNet的检测性能高,比YOLOV2, YOLOv3[35 ] , SSD300, STDN300和FSSD300的精度高,与FAENet的检测性能相近. 与单阶段无锚框算法FCOS和ATSS相比,FEDet的平均检测精度分别高0.019和0.015. STDN是兼顾速度与精度的算法,FEDet的检测速度与STDN300相近,但精度比STDN高0.016. 与SSD相比,FEDet的检测速度稍有下降,但依然能达到实时检测要求. 如表4 所示,为了进一步验证FEDet有效提高检测效果,选择与FEDet输入图片尺寸差异不大的单阶段算法,测试在VOC2007数据集上各类别的平均检测精度. 在10个类别中,FEDet在检测aero、boat、bottle、plant、train、tv类别时的精度是测试算法中最高,在检测 bottle、plant这些小目标出现频次较高的类别中,FEDet相比于SSD有改善最显著,同时比性能最优的FAENet精度更高. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
基于双通道R-FCN的图像篡改检测模型
1
2021
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
基于双通道R-FCN的图像篡改检测模型
1
2021
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
3
... 采用目标检测公开数据集PASCAL VOC对FEDet进行性能评估. 评估指标分别为平均检测精度mAP和检测速度s . 本研究的网络模型和SSD网络将VOC 2007、VOC 2012的训练集和验证集作为训练集,共16 551张图片,测试在VOC2007的测试集上进行,共4 952张图片. 对比方法包括1)双阶段经典算法Faster R-CNN,2)单阶段算法经典算法SSD、YOLOv2和YOLOv3,3)以SSD为基础改进的DSSD、FSSD、尺度变换目标检测器[30 ] (scale-transferrable object detection,STDN)、高精度单阶段算法RetinaNet和特征聚合与增强的单阶段算法[31 ] (single-shot object detector with feature aggregation and enhancement, FAENet),4)单阶段无锚框检测算法FCOS[32 ] 和ATSS[33 ] 算法. 如表3 所示为各方法在PASCAL VOC2007测试集上的检测结果. 其中SSD、FAENet、FCOS和ATSS由开源代码实验得到. 由表可知,双阶段检测算法的检测精度普遍高于单阶段算法,但其检测速度较为缓慢. FEDet属于单阶段算法,mAP =79.7%、s =39帧/s,比DSSD321和RetinaNet的检测性能高,比YOLOV2, YOLOv3[35 ] , SSD300, STDN300和FSSD300的精度高,与FAENet的检测性能相近. 与单阶段无锚框算法FCOS和ATSS相比,FEDet的平均检测精度分别高0.019和0.015. STDN是兼顾速度与精度的算法,FEDet的检测速度与STDN300相近,但精度比STDN高0.016. 与SSD相比,FEDet的检测速度稍有下降,但依然能达到实时检测要求. 如表4 所示,为了进一步验证FEDet有效提高检测效果,选择与FEDet输入图片尺寸差异不大的单阶段算法,测试在VOC2007数据集上各类别的平均检测精度. 在10个类别中,FEDet在检测aero、boat、bottle、plant、train、tv类别时的精度是测试算法中最高,在检测 bottle、plant这些小目标出现频次较高的类别中,FEDet相比于SSD有改善最显著,同时比性能最优的FAENet精度更高. ...
... Comparison of mean average precision on VOC2007 test set
Tab.3 算法 主干网络 mAP/% S /(帧·s−1 ) Faster R-CNN[5 ] VGGNet 73.2 7.0 Faster R-CNN[5 ] ResNet-101 78.8 2.3 R-FCN[34 ] ResNet-101 80.5 9.0 Cascade R-CNN[6 ] VGGNet 79.6 4.2 YOLOV2[9 ] DarkNet-19 73.7 81.0 SSD300[7 ] VGGNet 77.2 46.0 DSSD321[19 ] ResNet-101 78.6 9.5 STDN300[30 ] DenseNet-169 78.1 41.5 FSSD300[12 ] VGGNet 78.8 65.0 YOLOv3[35 ] DarkNet-53 79.4 37.0 RetinaNet[13 ] ResNet-101 79.4 12.4 FAENet300[31 ] VGGNet 80.1 65.0 FCOS[32 ] ResNet-50 77.8 17.6 ATSS[33 ] ResNet-50 78.2 14.9 FEDet VGGNet 79.7 39.0
表 4 VOC2007测试集不同类别目标检测精度结果 ...
... Experiment results of different algorithms on COCO dataset
Tab.5 算法 AP AP50 AP75 APS APM APL % SSD[7 ] 25.6 43.8 26.3 6.8 27.8 42.2 YOLOv3[35 ] 28.2 51.5 29.7 11.9 30.6 43.4 RefineDet[36 ] 29.4 49.2 31.3 10.0 32.0 44.4 FAENet[31 ] 28.3 47.9 29.7 10.5 30.9 41.9 FEDet 30.1 50.0 31.2 13.3 33.2 44.0
图 11 2种算法在COCO数据集上检测结果对比 ...
2
... COCO数据集具有比PASCAL VOC数据集更丰富的目标种类,更复杂的场景和更多的小目标物体. 为了进一步验证FEDet的小目标检测效果,使用COCO2017训练集进行训练,共约110 000张图片,在COCO2017验证集上进行测试,共5 000张图片. COCO数据集有41%的小目标物体,因此将Conv4_3层上的默认框相对于图片的最小尺寸由0.20减小为0.15. 对比方法包括SSD、YOLOv3、RefineDet[36 ] 和FAENet. 其中YOLOv3和RefineDet分别通过增加默认框个数和进行特征融合的方式提高小目标检测精度,与FEDet相似. FAENet是专门针对小目标的单阶段检测算法. FEDet、SSD、FAENet输入的图片尺寸均为300×300, YOLOv3、RefineDet输入的图片尺寸均为320×320. 其中SSD、RefineDet、FAENet的实验结果由开源代码实验得到. 如表5 所示为不同算法在COCO测试集上的检测精度. 表中,AP为当IoU∈(0.50,0.95)时的平均精度,AP50 为当 IoU=0.50时的平均精度,AP75 为当 IoU=0.75时的平均检测精度;APS 为对目标面积不超过32×32的检测精度,即小目标检测;APM 为对目标面积大于等于32×32和小于96×96的检测精度,即中目标检测;APL 为对目标面积大于等于96×96的检测精度,即大目标检测. FEDet的AP=30.1%、AP50 =50.0%、AP75 =31.2%. FEDet的APS =13.3%,相比于SSD提高0.065,相比于YOLOv3,RefineDet和FAENet也有所提高. FEDet的APM =33.2%、APL =44.0%. 实验结果表明,FEDet在复杂场景下对小目标检测效果有提升. SSD与FEDet在COCO数据集上的检测效果对比如图11 所示. ...
... Experiment results of different algorithms on COCO dataset
Tab.5 算法 AP AP50 AP75 APS APM APL % SSD[7 ] 25.6 43.8 26.3 6.8 27.8 42.2 YOLOv3[35 ] 28.2 51.5 29.7 11.9 30.6 43.4 RefineDet[36 ] 29.4 49.2 31.3 10.0 32.0 44.4 FAENet[31 ] 28.3 47.9 29.7 10.5 30.9 41.9 FEDet 30.1 50.0 31.2 13.3 33.2 44.0
图 11 2种算法在COCO数据集上检测结果对比 ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}