Remote sensing image target detection combining multi-scale and attention mechanism
ZHANG Yun-zuo,, GUO Wei, CAI Zhao-quan, LI Wen-bo
1. School of Information Science and Technology, Shijiazhuang Tiedao University, Shijiazhuang 050043, China
2. Hebei Key Laboratory of Electromagnetic Environmental Effects and Information Processing, Shijiazhuang Tiedao University, Shijiazhuang 050043, China
3. Shanwei Institute of Technology, Shanwei 516600, China
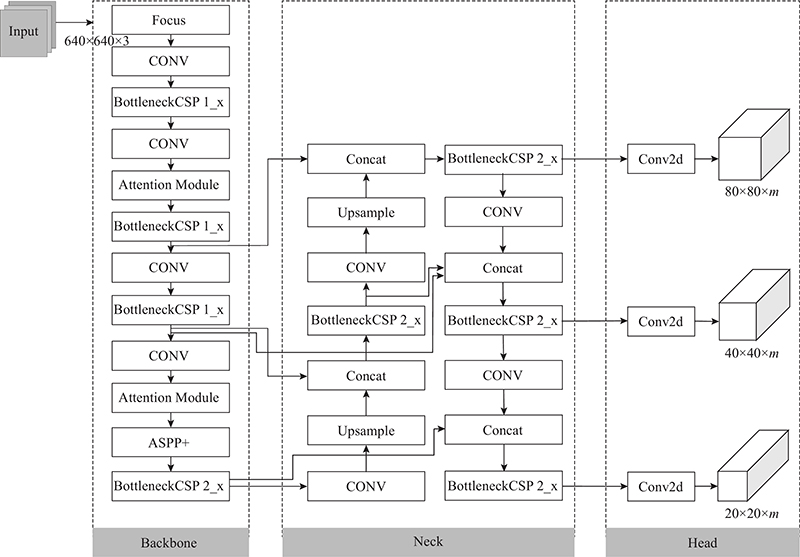
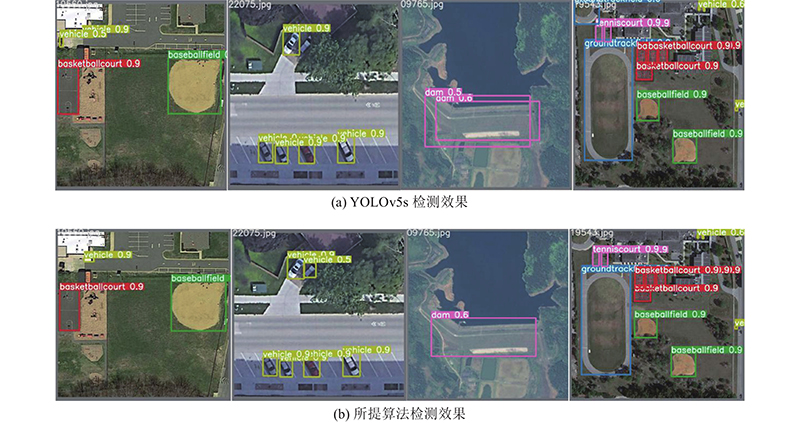
Remote sensing images have deficiencies such as complex backgrounds, significant differences in target scales, and dense distribution, resulting in poor detection of existing algorithms. A remote sensing image object detection algorithm that combined multi-scale and attention mechanisms was proposed. The receptive field of images of different sizes improved the atrous spatial pyramid pooling module. An attention module was proposed to improve the feature extraction ability for target regions of remote sensing images under complex backgrounds by learning the feature map channel information and the spatial location information. A weighted bidirectional feature pyramid network structure was introduced to combine with the backbone network to improve the fusion of multi-level features. A distance-based non-maximum suppression method was used for postprocessing, which improved the problem of easy overlapping of detection frames. Experimental results on DIOR and NWPU VHR-10 datasets showed that the mean average precision (mAP) of the proposed algorithm reached 71.6% and 91.6%, which were 2.9% and 1.5% higher than those of the mainstream YOLOv5s algorithm respectively. The algorithm achieved good detection results for complex remote sensing images.
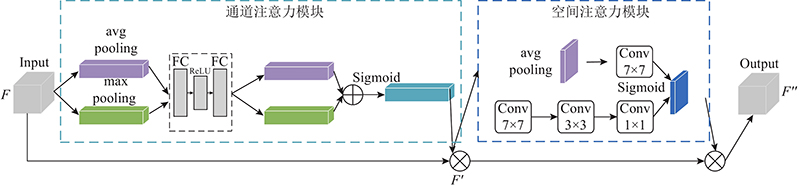
为了使网络更加关注重要信息,受压缩和激励网络(squeeze-and-excitation net,SENet)[16]和卷积注意力模块 (convolutional block attention module,CBAM)[17]的启发,提出一种注意力模块,该模块包括通道注意力和空间注意力2个子模块,如图3所示. 首先使用通道注意力模块重新校准每个通道的权重,使得网络关注重要特征,抑制不重要特征. 然后使用空间注意力模块突出目标区域的空间位置信息,引导网络专注于遥感图像目标区域,抑制无关背景的干扰. 在图3中,输入通道注意力模块的特征图为 $ F $,大小为 $ C \times H \times W $, $ C $、H和W分别为特征图的通道数、长和宽. 首先对输入特征图 $ F $进行平均池化(avg pooling)和最大池化(max pooling)的操作,有利于筛选辨识度高的特征[18];然后经过2个全连接层FC(fully connected layers)先降低特征图维度再升高维度,拟合通道之间的相关性;最后使用Sigmoid函数进行归一化处理,重新分配各个通道的特征权重,有利于学习目标区域对应的通道信息,进而使网络对遥感图像目标特征进行充分学习. 空间注意力模块增强对特征图的空间信息学习,以突出特征图中目标的相关区域. 在第1层空间注意力模块中,为获取更多的语义信息,首先对特征图 $ F' $进行平均池化操作,提取特征图的空间信息,然后使用7×7的卷积层连接,并通过Sigmoid函数增加非线性特征,得到特征图 ${M_{{\text{s}}1}}$,大小为 $ 1 \times H \times W $,计算公式为
FENG J, LIANG Y P, YE Z W, et al. Small object detection in optical remote sensing video with motion guided R-CNN [C]// IEEE International Geoscience and Remote Sensing Symposium. Waikoloa: IEEE, 2020: 272-275.
LI L L, CHENG L, GUO X H, et al. Deep adaptive proposal network in optical remote sensing images objective detection [C]// IEEE International Geoscience and Remote Sensing Symposium. Waikoloa: IEEE, 2020: 2651-2654.
BERTASIUS G, TORRESANI L, YU S X, et al. Convolutional random walk networks for semantic image segmentation [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 858-866.
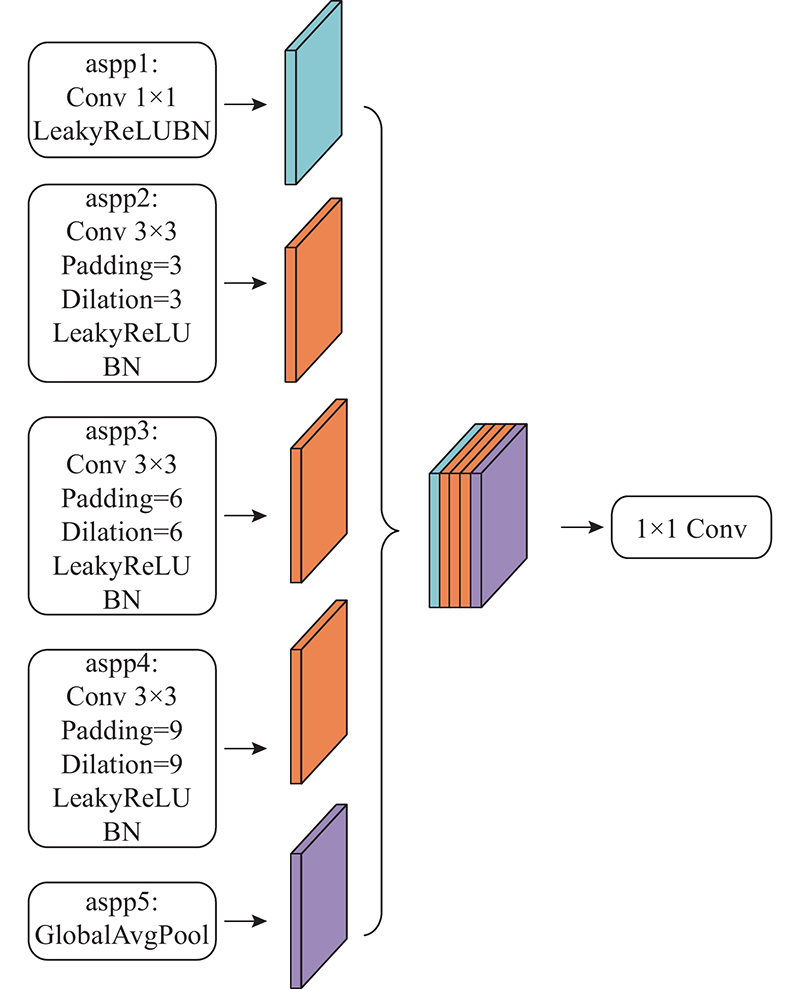
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. [2022-01-14]. https://arxiv.53yu. com/abs/1706.05587v3.
HU J, SHEN L, SUN G. Squeeze-and-excitation network [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: Computer Vision Foundation, 2018: 7132-7141.
TAN M X, PANG R M, LE Q V. Efficientdet: scalable and efficient object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition. Seattle: Computer Vision Foundation, 2020: 10778-10787.
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2980-2988.
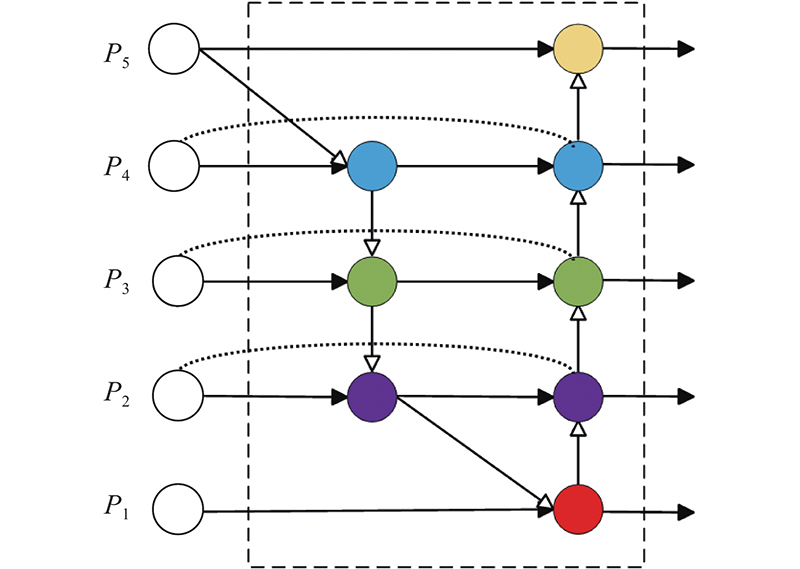
LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: Computer Vision Foundation, 2018: 8759-8768.
... 为了使网络更加关注重要信息,受压缩和激励网络(squeeze-and-excitation net,SENet)[16]和卷积注意力模块 (convolutional block attention module,CBAM)[17]的启发,提出一种注意力模块,该模块包括通道注意力和空间注意力2个子模块,如图3所示. 首先使用通道注意力模块重新校准每个通道的权重,使得网络关注重要特征,抑制不重要特征. 然后使用空间注意力模块突出目标区域的空间位置信息,引导网络专注于遥感图像目标区域,抑制无关背景的干扰. 在图3中,输入通道注意力模块的特征图为 $ F $,大小为 $ C \times H \times W $, $ C $、H和W分别为特征图的通道数、长和宽. 首先对输入特征图 $ F $进行平均池化(avg pooling)和最大池化(max pooling)的操作,有利于筛选辨识度高的特征[18];然后经过2个全连接层FC(fully connected layers)先降低特征图维度再升高维度,拟合通道之间的相关性;最后使用Sigmoid函数进行归一化处理,重新分配各个通道的特征权重,有利于学习目标区域对应的通道信息,进而使网络对遥感图像目标特征进行充分学习. 空间注意力模块增强对特征图的空间信息学习,以突出特征图中目标的相关区域. 在第1层空间注意力模块中,为获取更多的语义信息,首先对特征图 $ F' $进行平均池化操作,提取特征图的空间信息,然后使用7×7的卷积层连接,并通过Sigmoid函数增加非线性特征,得到特征图 ${M_{{\text{s}}1}}$,大小为 $ 1 \times H \times W $,计算公式为 ...
1
... 为了使网络更加关注重要信息,受压缩和激励网络(squeeze-and-excitation net,SENet)[16]和卷积注意力模块 (convolutional block attention module,CBAM)[17]的启发,提出一种注意力模块,该模块包括通道注意力和空间注意力2个子模块,如图3所示. 首先使用通道注意力模块重新校准每个通道的权重,使得网络关注重要特征,抑制不重要特征. 然后使用空间注意力模块突出目标区域的空间位置信息,引导网络专注于遥感图像目标区域,抑制无关背景的干扰. 在图3中,输入通道注意力模块的特征图为 $ F $,大小为 $ C \times H \times W $, $ C $、H和W分别为特征图的通道数、长和宽. 首先对输入特征图 $ F $进行平均池化(avg pooling)和最大池化(max pooling)的操作,有利于筛选辨识度高的特征[18];然后经过2个全连接层FC(fully connected layers)先降低特征图维度再升高维度,拟合通道之间的相关性;最后使用Sigmoid函数进行归一化处理,重新分配各个通道的特征权重,有利于学习目标区域对应的通道信息,进而使网络对遥感图像目标特征进行充分学习. 空间注意力模块增强对特征图的空间信息学习,以突出特征图中目标的相关区域. 在第1层空间注意力模块中,为获取更多的语义信息,首先对特征图 $ F' $进行平均池化操作,提取特征图的空间信息,然后使用7×7的卷积层连接,并通过Sigmoid函数增加非线性特征,得到特征图 ${M_{{\text{s}}1}}$,大小为 $ 1 \times H \times W $,计算公式为 ...
基于弱语义注意力的遥感图像可解释目标检测
1
2021
... 为了使网络更加关注重要信息,受压缩和激励网络(squeeze-and-excitation net,SENet)[16]和卷积注意力模块 (convolutional block attention module,CBAM)[17]的启发,提出一种注意力模块,该模块包括通道注意力和空间注意力2个子模块,如图3所示. 首先使用通道注意力模块重新校准每个通道的权重,使得网络关注重要特征,抑制不重要特征. 然后使用空间注意力模块突出目标区域的空间位置信息,引导网络专注于遥感图像目标区域,抑制无关背景的干扰. 在图3中,输入通道注意力模块的特征图为 $ F $,大小为 $ C \times H \times W $, $ C $、H和W分别为特征图的通道数、长和宽. 首先对输入特征图 $ F $进行平均池化(avg pooling)和最大池化(max pooling)的操作,有利于筛选辨识度高的特征[18];然后经过2个全连接层FC(fully connected layers)先降低特征图维度再升高维度,拟合通道之间的相关性;最后使用Sigmoid函数进行归一化处理,重新分配各个通道的特征权重,有利于学习目标区域对应的通道信息,进而使网络对遥感图像目标特征进行充分学习. 空间注意力模块增强对特征图的空间信息学习,以突出特征图中目标的相关区域. 在第1层空间注意力模块中,为获取更多的语义信息,首先对特征图 $ F' $进行平均池化操作,提取特征图的空间信息,然后使用7×7的卷积层连接,并通过Sigmoid函数增加非线性特征,得到特征图 ${M_{{\text{s}}1}}$,大小为 $ 1 \times H \times W $,计算公式为 ...
基于弱语义注意力的遥感图像可解释目标检测
1
2021
... 为了使网络更加关注重要信息,受压缩和激励网络(squeeze-and-excitation net,SENet)[16]和卷积注意力模块 (convolutional block attention module,CBAM)[17]的启发,提出一种注意力模块,该模块包括通道注意力和空间注意力2个子模块,如图3所示. 首先使用通道注意力模块重新校准每个通道的权重,使得网络关注重要特征,抑制不重要特征. 然后使用空间注意力模块突出目标区域的空间位置信息,引导网络专注于遥感图像目标区域,抑制无关背景的干扰. 在图3中,输入通道注意力模块的特征图为 $ F $,大小为 $ C \times H \times W $, $ C $、H和W分别为特征图的通道数、长和宽. 首先对输入特征图 $ F $进行平均池化(avg pooling)和最大池化(max pooling)的操作,有利于筛选辨识度高的特征[18];然后经过2个全连接层FC(fully connected layers)先降低特征图维度再升高维度,拟合通道之间的相关性;最后使用Sigmoid函数进行归一化处理,重新分配各个通道的特征权重,有利于学习目标区域对应的通道信息,进而使网络对遥感图像目标特征进行充分学习. 空间注意力模块增强对特征图的空间信息学习,以突出特征图中目标的相关区域. 在第1层空间注意力模块中,为获取更多的语义信息,首先对特征图 $ F' $进行平均池化操作,提取特征图的空间信息,然后使用7×7的卷积层连接,并通过Sigmoid函数增加非线性特征,得到特征图 ${M_{{\text{s}}1}}$,大小为 $ 1 \times H \times W $,计算公式为 ...
Object detection based on multiple information fusion net





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}