

深度学习中的监督学习需要有标注的数据,但是现实世界中已经标注的数据只占小部分,许多场景中的数据是未标注的,甚至是难以标注的. 为了解决数据类别标签缺失的问题,零样本学习(zero shot learning, ZSL)最早用于图像分类任务. Lampert等[1]认为人天生具有零样本学习的能力,通过已知事物和未知事物间统一的知识联系,就能将在已知数据上学习到的能力迁移到未知数据的处理中去. 零样本学习在训练阶段和测试阶段用到的数据类别不相交,必须借助语义信息建立统一的知识联系,比如专家标注的属性向量、词向量和文本描述等[2-4]. Chao等[5]将零样本学习拓展到广义的零样本学习 (generalized zero shot learning, GZSL),在测试阶段中模型应对训练阶段已出现的类别数据具有分类能力.
对于广义的零样本学习,由于在训练阶段已经学习过部分类别的知识,模型容易对已训练的类别过拟合,体现在把数据分到已训练过的类别,而不是训练阶段未见的类别从而降低分类的准确率. 此外,零样本学习的效果受限于类语义向量的类别区分能力,消除对可见类别的偏好关键在于建立图像的视觉特征和语义属性描述之间的对应关系. Sung等[6]提出关系网络(relation nework)来学习视觉特征和类语义特征之间的非线性相似度. 在优化深度特征嵌入的过程中,只是简单地将视觉特征和语义特征拼接起来进而通过关系网络学习非线性相似度,没有深入探究其他有助于知识迁移和增强模型泛化能力的工作. 因此,本研究选取文献[6]作为基线模型,在此框架下开展工作,提升零样本的图像分类表现.
在零样本学习中,通常以若干个专家标注的属性来表示一种类别,并将这些属性向量的组合称之为类语义向量. 比如在AWA1数据集[1]中是以“black”、“brown”、“water”和“eats fish”等属性来描述“otter”,而单独用“black”或“water”这样的属性并不能代表“otter”这一类别,并且现有数据集也没有提供可以唯一标识每一个类别的属性. 如果没有这样的唯一属性,当2个类别的属性描述有较多重叠时,模型容易将2个类别混淆,比如“otter”具有“black”、“brown”、“water”和“eats fish”等属性,而“polar bear”具有“white”、“water”和“eats fish”等属性. 假如训练阶段出现过“otter”,那么“polar bear”在测试阶段的图像分类时,模型可能将“polar bear”的图像分到 “otter”,因为两者的类语义十分相似,而模型又更容易拟合训练阶段已经出现过的 “otter”. 对此,本研究提出构造每个类别的唯一属性作为类语义的全局监督标记与数据集中现有的属性向量结合使用,增强类语义之间的区分性.
在零样本图像分类过程中,除了凭借属性描述来判断图像属于哪一类别,视觉特征本身也具有类别区分性. 由于图像和专家标注的属性本身属于不同的模态,各自又从不同的途径独立获得,视觉特征和类语义特征的本质不同,类别区分性也不同,在空间中的流形结构也不一样. 在两者流形结构不同的情况下,度量学习过程将十分困难和复杂,模型容易对可见类别过拟合,而对未见类别的泛化能力变差. 为了解决这个问题,受Jiang等[7]提出的双字典结构对齐算法得到启发,本研究中的视觉特征分类网络和语义特征分类网络分别被用于学习视觉空间和语义空间特征的类别分布,并且对齐两者的分布信息. 生成对抗网络(generative adversarial network, GAN)被用于消除视觉特征和类语义特征存在的本质差异,辅助对齐两者的分布状态. 在利用关系网络学习2种特征间的非线性相似度时,文献[8-11]的研究直接沿用文献[6]中拼接的方式合并视觉特征和类语义特征,却没有探究更适合零样本图像分类的特征合并方式,而不同的特征合并方式对分类效果的影响较为明显. 本研究提出采用按位加的方式对2种特征进行合并,同时对拼接、按位乘和按位加3种特征合并方式对分类效果的影响进行讨论和分析.
1. 深度监督对齐的零样本图像分类
本研究提出的DSAN方法框架如图1所示,训练阶段 (图1(a))主要包括4个模块:1)最左边的虚线框中为深度特征嵌入模块,提出类语义的全局标记,与专家标注的属性向量拼接后作为类语义向量. 类语义向量由一个深度特征嵌入网络将其变换到和视觉特征同样维度的公共空间中,获得类语义的高维特征表示. 2)第2个虚线框中为特征分布对齐模块,采用视觉特征分类网络和语义特征分类网络,用于共享和对齐2种空间中的特征分布信息. 3)第3个虚线框中为模态分类学习模块采用模态分类网络,用于对输入的视觉特征和类语义特征进行二元分类,构成GAN中的判别网络;第1个模块中的深度语义特征嵌入网络则构成GAN中的生成网络,从而可以采用对抗训练的方式消除视觉特征和类语义特征之间的本质差异. 第1模块中的深度视觉特征提取网络为预训练的深度神经网络,在训练过程中参数是固定的,因此该网络不构成GAN中的生成网络. 4)最右边的虚线框中为深度非线性相似度学习模块,以按位加的方式合并视觉特征和类语义特征,作为关系网络的输入,接着由关系网络输出两者之间的关系分数.
图 1
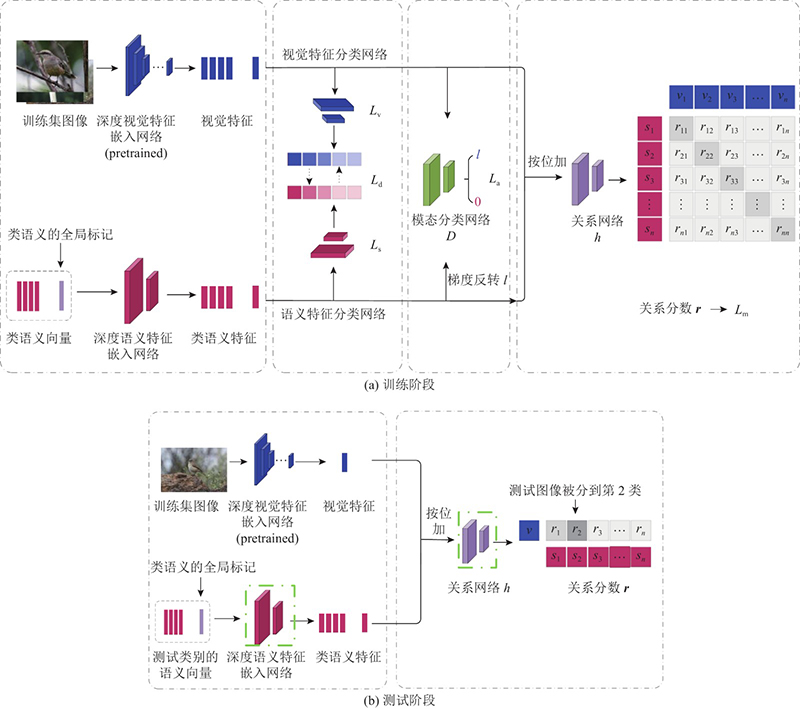
在测试阶段(图1(b))中,测试图像的视觉特征仍通过预训练的深度视觉特征嵌入网络得到. 测试类别的语义特征则由训练阶段保存的深度语义特征嵌入网络(粗虚线框中)得到. 两者以按位加的方式合并后,输入训练阶段保存的关系网络(粗虚线框中),获得测试图像与所有测试类别的语义特征之间的关系分数,测试图像与哪一个类语义的关系分数最大,那么就被分到哪一类.
1.1. 深度特征嵌入模块
对于原始图像采用深度预训练的神经网络提取深度视觉特征,记为
由于视觉特征的维度往往高于类语义特征,当视觉特征向语义空间投影时,会加重枢纽点问题(hubness problem)[12],体现在一些类语义更容易成为很多视觉特征投影点的最近邻(或枢纽点),而实际上这些投影点和类语义之间并没有类别关系. 为了减轻枢纽点问题,选取视觉空间作为公共度量空间,将类语义向量通过一个深度特征嵌入网络向视觉空间映射,获得类语义向量的高维特征表示
式中:
1.2. 特征分布对齐模块
视觉特征和类语义特征的来源不同,具有不同的区分性,在空间中的类结构不同,因此,利用2种分类网络实现视觉特征和类语义特征类别分布的对齐. 首先,构造一个语义特征分类网络,获得类语义在空间中的概率分布:
式中:
为了使不同类语义的概率分布之间区分度更明显,在类别标签监督下,采用均方差损失函数约束类语义的概率分布,则语义特征分类网络的优化目标为
式中:
同时构造视觉特征分类网络,利用视觉特征本身的类别区分性,获得视觉特征对每一个类别的概率分布:
式中:
以类别标签作为监督信息,以均方差损失函数约束获得的视觉特征概率分布. 因此,视觉特征分类网络的优化目标为
构造分布差异约束
式中:
1.3. 模态分类学习模块
文献[13]提出GAN是由2个相互竞争的深度神经网络组成,分别是生成网络(generator)和判别网络(discriminator). 生成网络用于生成假数据,而判别网络总是试图区分假数据和真实数据. 为了迷惑判别网络,生成网络只能生成更不易区分的假数据,整个过程就像是在对抗博弈,直到生成的假数据非常接近真实数据,此时判别网络被欺骗认为生成的假数据是真实数据. 因此,通过对抗训练的方式能够实现生成数据的分布最大程度上和真实数据的分布一致. 利用GAN的原理,通过对抗训练的方式消除视觉特征和类语义特征之间存在的本质差异. 为此构造一个模态分类网络作为GAN中的判别网络,用于判断输入该网络的特征为视觉特征还是类语义特征:
式中:D为模态分类网络,
方法框架中的深度语义特征嵌入网络构成了GAN中的生成网络. 在训练过程中,通过最大化模态分类网络的区分损失,使之不能再分清2种模态的特征,此时由深度语义特征嵌入网络生成的语义特征就可以被认为与视觉特征是无差异的. 为了使训练过程更加平稳,采用梯度反转[14]的方式,在生成网络和判别网络之间加入梯度反转操作,从而使得对抗约束的优化目标与训练阶段的总优化目标一致,即
式中:
1.4. 深度非线性相似度学习模块
以对应位置的元素相加(按位加)的方式合并类语义特征
式中:
在零样本的图像分类中,关系网络的输出
式中:
通过深度特征嵌入模块、特征分布对齐模块、模态分类学习模块和深度非线性相似度学习模块4个方面的工作后,得到训练阶段的总目标函数
式中:
2. 实验结果与分析
2.1. 数据集与参数设置
为验证所提方法在零样本图像分类中的表现,在实验中采用公开的5个基准数据集:Caltech UCSD Birds 200-2011[20],Animals with Attributes 1[1],Animals with Attributes 2[21],SUN Scene Recognition[22] 和Attribute Pascal and Yahoo[23],分别简记为CUB、AWA1、AWA2、SUN和APY. 其中,CUB数据集包含200个鸟类的11 788张图像,是一个中等规模的细粒度数据集,含有312个专家系统标注的属性向量. AWA1和AWA2数据集都属于粗粒度中等规模的数据集,分别含有30 475和37 322张图像,都只包含50类以及85个属性向量. SUN数据集包含717种不同场景的细粒度图像,共14 340张,以102个的属性向量标识每种场景. APY数据集是一个小规模粗粒度的数据集,共有32类的15 339张图像,每个类别采用64个属性进行标注.
表 1 零样本图像分类的数据集划分方式
Tab.1
| 数据集 | 图像数 | 属性个数 | 可见类别数 | 未见类别数 |
| CUB | 11 788 | 312 | 150 | 50 |
| AWA1 | 30 475 | 85 | 40 | 10 |
| AWA2 | 37 322 | 85 | 40 | 10 |
| SUN | 14 340 | 102 | 645 | 72 |
| APY | 15 339 | 64 | 20 | 12 |
在NVIDIA GEFORCE GTX 2080 GPU服务器上进行训练,采用PyTorch框架搭建分类模型,使用Adam优化器除了在SUN和APY数据集上学习率为
2.2. 评价指标
对于传统的零样本学习,采用统一的性能评价指标[21],以平均每类最高准确率评价分类结果,记为A:
式中:
对于广义的零样本学习,由于在测试阶段同时存在可见类别和未见类别的数据,以调和平均准确率作为评价指标,全面衡量方法在可见类别和见类别上的综合表现,记为H:
式中:S为测试集中所有可见类别的分类准确率,U为测试集中所有未见类别的分类准确率.
2.3. 传统零样本图像分类的准确率
表 2 不同数据集上传统零样本分类准确率表现对比1)
Tab.2
| 方法 | A | ||||
| CUB | AWA1 | AWA2 | SUN | APY | |
| 1)注:带“*”的实验数据由文献作者公开的源代码复现得到;“−”代表未测;表中其他算法的数据来自文献[21]公开的复现结果. | |||||
| SAE[25] | 33.3 | 53.0 | 54.1 | 40.3 | 8.3 |
| CDL[7] | 54.5 | 69.9 | − | 63.6 | 43.0 |
| GAZSL[15] | 55.8 | 68.2 | 70.2 | 61.3 | 41.1 |
| DCN[16] | 56.2 | 65.2 | − | 61.8 | 43.6 |
| f-CLSWGAN[18] | 57.3 | 68.2 | − | 60.8 | − |
| FD-fGAN[19] | 58.3 | 72.6 | − | 61.5 | − |
| Rnet[6] | 55.6 | 68.2 | 64.2 | 49.3* | 39.8* |
| SARN[8] | 53.8 | 68.0 | 64.2 | − | − |
| TCN[10] | 59.5 | 70.3 | 71.2 | 61.5 | 38.9 |
| CRnet[11] | 56.6* | 69.1* | 63.0* | 61.4* | 39.1* |
| DSAN | 57.4 | 71.8 | 72.3 | 62.4 | 41.5 |
文献[8-11]的研究同样以基线模型[6]为基础,从不同方面进行方法的改进,因此是本研究重点的比较算法. SARN[8]在文献[6]的基础上引入非局部注意力机制,以增强视觉特征和类语义特征之间关系的度量学习能力,然而识别准确率没有取得明显的改进. CPDN和DRN[9]中均采用类原型区分关系网络,提出类原型分散损失(class prototype scatter loss, CPSL),通过最大化相同类语义之间的关系分数,最小化不同类语义之间的关系分数,避免了度量空间的收缩以及缓解了枢纽点问题,有效提升广义零样本图像分类的表现. 但这2种算法均未报告传统零样本图像分类的测试结果,未公开源代码,因此作为传统零样本图像分类表现的对比算法暂不选取,只采用两者在广义零样本图像分类上公布的结果. TCN[10]以可见类别和未见类别语义之间的非线性相似度为重构系数,通过可见类别的语义重构未见类别的语义,利用对比学习的原理最大化类别一致的数据对,最小化类别不一致的数据对. 该方法有效解决广义的零样本学习中模型容易对可见类别产生偏好的问题,但训练阶段需要提前用到未见类别的语义信息. 而CRnet[11]则使用聚类的原理获得类语义特征的若干个聚类中心,然后依据每个类语义对这些聚类中心的偏移量将数据集中的类语义重新进行标定,在广义零样本的图像分类中取得了最佳表现. 在表2中,依据文献[11]作者公开的源代码复现该算法在不同数据集上关于传统零样本图像分类的测试结果.
由表2可知,在5个数据集上,本研究方法在传统零样本图像分类上的识别准确率均高于基线模型[6],分别提高了1.8%(CUB)、3.6%(AWA1)、8.1%(AWA2)、13.1%(SUN)和1.7%(APY),验证了所提方法的有效性. 同时,在AWA1、AWA2和SUN数据集上,本研究方法的分类表现分别高出现阶段对基线模型做出最佳改进的算法(TCN[10])1.5%、1.1%和0.9%. 而在APY数据集上,尽管本研究方法的分类准确率比DCN[16]低了2.1%,但仍然超过近年来改进基线模型的算法[8,10-11]中效果最好的CRnet[11] (39.1%). 在CUB数据集上,图像类别的粒度更细,一些类别的图像与同类图像的差异甚至大于和其他类别图像之间的差异. 实验结果显示,本研究方法在CUB数据集上的表现比当前最佳的TCN[10]算法低了2.1%,是因为CUB数据集中可见类别和未见类别的差异较大,导致训练的模型对未见类别不能很好地泛化. 通过比较2个算法可以得出,TCN[10]根据可见类别的语义重建未见类别的语义,通过这种方式让未见类别的语义参与到训练之中去,由于提前利用未见类别的语义信息,学到可见类别和未见类别之间的联系,因此增强了算法对未见类别的理解能力和泛化能力. 而本研究方法未在训练阶段利用未见类别的语义信息,可能是在图像分类挑战更大的CUB数据集上未取得最佳表现的原因. 对此,后续可以进一步探究在训练阶段学习可见类别和未见类别的语义相关性对分类效果的影响. 与基于生成模型的算法FD-fGAN[19]相比,本研究方法在SUN数据集上的分类效果低了0.9%,可能是因为基于生成模型的算法在训练阶段利用未见类别的语义生成未见类别图像的视觉特征,因此对未见类别具有较强的泛化能力. 但本研究方法的网络结构和训练过程都比这类算法更简单,并且分类效果也能超过一部分基于生成模型的算法,比如表2中的GAZSL[15],在5个测试数据集上,所提方法的分类表现分别高于该算法1.6% (CUB),3.6% (AWA1),2.1% (AWA2),1.1% (SUN)和0.4% (APY).
2.4. 广义零样本图像分类的准确率
表 3 不同数据集上广义零样本分类表现对比
Tab.3
| 方法 | CUB | AWA1 | AWA2 | SUN | APY | ||||||||||||||
| U | S | H | U | S | H | U | S | H | U | S | H | U | S | H | |||||
| SAE[25] | 7.8 | 54.0 | 13.6 | 1.8 | 77.1 | 3.5 | 1.1 | 82.2 | 2.2 | 8.8 | 18.0 | 11.8 | 0.4 | 80.9 | 0.9 | ||||
| DEM[12] | 19.6 | 57.9 | 29.2 | 32.8 | 84.7 | 47.3 | 30.5 | 86.4 | 45.1 | 20.5 | 34.3 | 25.6 | 75.1 | 11.1 | 19.4 | ||||
| CDL[7] | 23.5 | 55.2 | 32.9 | 28.1 | 73.5 | 40.6 | − | − | − | 21.5 | 34.7 | 26.5 | 19.8 | 48.6 | 28.1 | ||||
| GAZSL[15] | 31.7 | 61.3 | 41.8 | 29.6 | 84.2 | 43.8 | 35.4 | 86.9 | 50.3 | 22.1 | 39.3 | 28.3 | 14.2 | 78.6 | 24.0 | ||||
| DCN[16] | 28.4 | 60.7 | 38.7 | 25.5 | 84.2 | 39.1 | − | − | − | 25.5 | 37.0 | 30.2 | 14.2 | 75.0 | 23.9 | ||||
| SE-GZSL[17] | 41.5 | 53.3 | 46.7 | 56.3 | 67.8 | 61.5 | 58.3 | 68.1 | 62.8 | 40.9 | 30.5 | 34.9 | − | − | − | ||||
| f-CLSWGAN[18] | 43.7 | 57.7 | 49.7 | 57.9 | 61.4 | 59.6 | − | − | − | 42.6 | 36.6 | 39.4 | − | − | − | ||||
| FD-fGAN[19] | 47.0 | 57.1 | 51.6 | 54.2 | 76.2 | 63.3 | − | − | − | 42.7 | 38.1 | 40.3 | − | − | − | ||||
| Rnet[6] | 38.1 | 61.1 | 47.0 | 31.4 | 91.3 | 46.7 | 30.0 | 93.4 | 45.3 | 14.0* | 23.3* | 17.5* | 9.8* | 62.5* | 17.0* | ||||
| SARN[8] | 37.4 | 64.6 | 47.1 | 33.1 | 90.8 | 48.5 | 35.9 | 92.9 | 51.8 | − | − | − | − | − | − | ||||
| TCN[10] | 52.6 | 52.0 | 52.3 | 49.4 | 76.5 | 60.0 | 61.2 | 65.8 | 63.4 | 31.2 | 37.3 | 34.0 | 24.1 | 64.0 | 35.1 | ||||
| CRnet[11] | 45.5 | 56.8 | 50.5 | 58.1 | 74.7 | 65.4 | 52.6 | 78.8 | 63.1 | 34.1 | 36.5 | 35.3 | 32.4 | 68.4 | 44.0 | ||||
| CPDN[9] | 46.6 | 58.9 | 52.0 | 49.1 | 82.7 | 61.6 | 44.6 | 85.4 | 58.6 | − | − | − | − | − | − | ||||
| DRN[9] | 46.9 | 58.8 | 52.2 | 50.1 | 81.4 | 62.1 | 44.9 | 85.3 | 58.8 | − | − | − | − | − | − | ||||
| DSAN | 46.9 | 56.6 | 51.3 | 58.1 | 77.1 | 66.2 | 58.6 | 78.8 | 67.2 | 33.2 | 41.1 | 36.7 | 34.1 | 71.6 | 46.2 | ||||
由表3可知,本研究方法在CUB数据集上的H值相较于基线模型Rnet[6]提升了4.3%,与表现最好的算法TCN[10]仅相差1.0%;在AWA1、AWA2、SUN和APY数据集上的H值均表现最佳,分别高于现阶段最优H值的0.8%、3.8%、1.4%和2.2%. 在CUB、AWA1和AWA2上对未见类别的分类准确率U值与基线模型Rnet[6]相比分别提高了8.8%,26.7%和28.6%. 在SUN数据集上,对可见类别和未见类别的分类准确率比CRnet[11]分别高了3.2%和1.7%;虽然在APY数据集上对未见类别的分类准确率比CRnet[11] 低于0.9%,但对可见类别的分类准确率高了4.6%,H值总体也上升. 通过实验证明出本研究方法有效提升广义零样本图像分类的准确率,有利于可见类别和未见类别间的知识迁移.
本研究方法在CUB数据集上的H值均低于TCN[10]、CPDN[9]和DRN[9]所报告的H值,是因为3种算法在训练阶段均提前用到未见类别的语义信息,学到了可见类别和未见类别之间的联系. 在本研究方法以及表3中的Rnet[6]、SARN[8]和CRnet[11]在训练阶段均未使用未见类别的语义信息,也没有学习可见类别和未见类别的语义之间的关系,所以在CUB这个分类难度更大的数据集上,这些方法的H值都比TCN[10]、CPDN[9]和DRN[9]略低. 但在训练阶段提前使用未见类别的语义信息会给模型的应用带来一些局限性,假如增加新类别的图像需要测试,为了识别这些新类别的图像,就必须加上新类别的语义来重新训练模型. 在实际生活中,算法不可能提前知道所有测试图像的信息(包括测试图像的类语义),因此这类算法在实际应用中需要不断地重复训练和更新来满足新的识别需求,同时消耗大量计算资源. 虽然Rnet[6]、SARN[8]、CRnet[11]和本研究方法效果比它们略低一点,但不会有这种局限性. 在广义零样本图像分类场景下,本研究方法和基于生成模型的算法相比仍具有竞争力,对可见类别的分类准确率和H值均能超过GAZSL[15]、DCN[16]和SE-GZSL[17]. 虽然在SUN数据集上的H值比f-CLSWGAN[19]低了4.1%,但在CUB和AWA1数据集上的H值分别高于该算法的值1.6%和6.6%.
2.5. 不同特征合并方式的影响
利用关系网络学习非线性相似度需要将类语义特征和视觉特征合并为一个向量作为输入,常见的操作有拼接、按位乘和按位加3种方式. 为了探究不同特征合并方式对实验结果的影响,仅使用
图 2
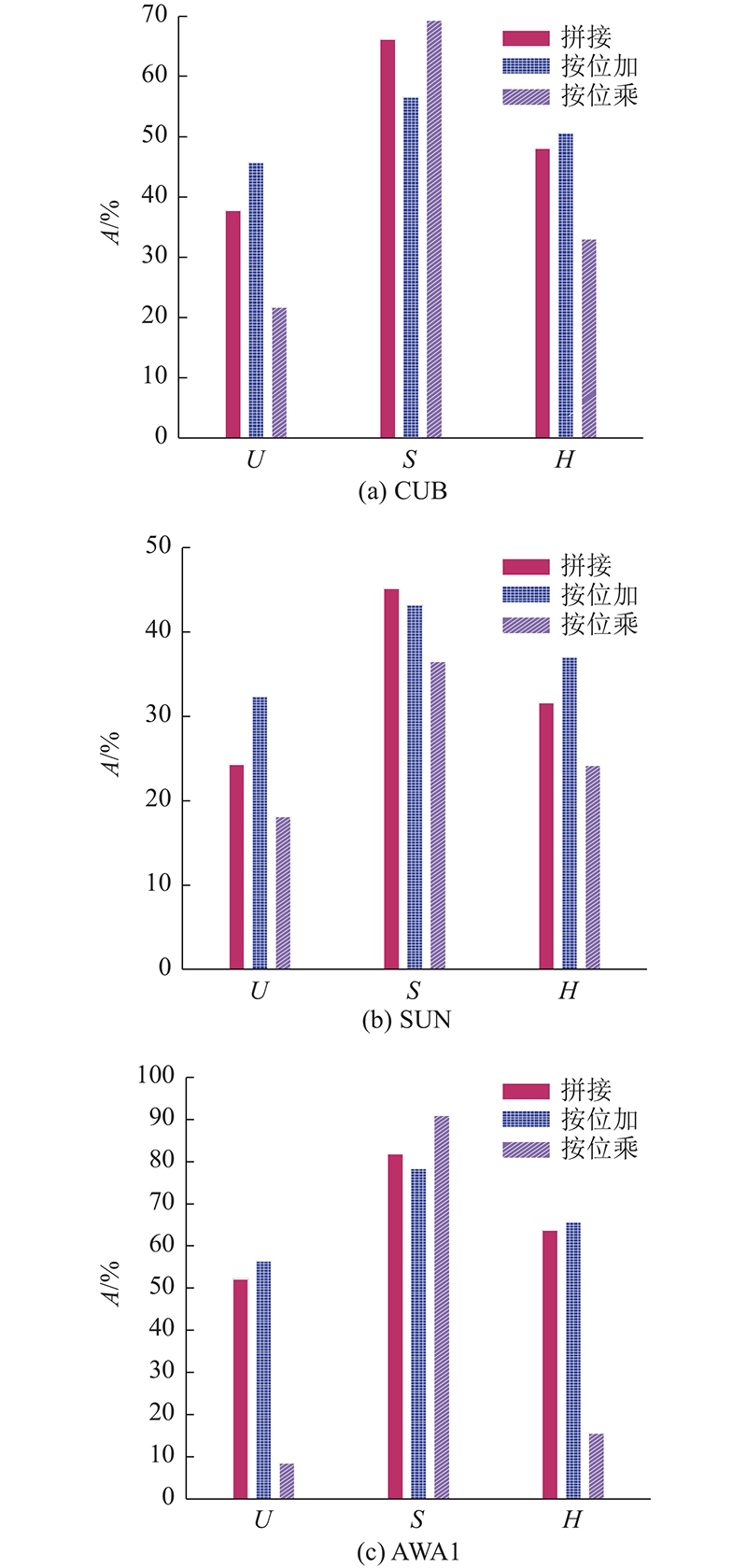
由图2可知,对于不同的特征合并方式,按位加在CUB、SUN和AWA1数据集上对未见类别的分类准确率(U值)和H值均为最高,拼接次之,按位乘效果最差. 而在SUN数据集上,三者的U值和H值差异最明显,说明按位加的特征合并方式更有利于学到视觉特征和类语义特征之间的对应关系,并将知识和先验迁移泛化到未见类别的分类中去.
在此对实验结果进一步解释,如果将视觉特征和类语义特征合并后的特征记为
零样本学习的关键在于建立局部视觉特征和语义属性之间准确的对应关系,而不仅仅是整张图像的视觉特征和类语义特征的对应,整个训练过程也是学习如何将图像的各种视觉特征和属性描述相对应,从而在测试集上利用未见类别的属性描述将未见类别的视觉特征分类. 因此,拼接方式在零样本图像分类中的知识迁移能力有限. 在按位加方式下,对应相加的2个通道,随着训练的进行,信息会趋于一致,即代表“spotted wing”的视觉信息最终将会与代表“spotted wing”的语义属性相加. 因为训练是朝着有利于分类的方向进行,假设两者的信息不对应,那么按位加合并的信息是混乱的,也就是不利于分类,不符合整体优化的方向,所以训练过程中两者对应通道的信息会趋于一致,神经网络学习到了图像区域的视觉信息和语义属性的对应关系. 在按位乘方式下,神经网络也能学习到按通道对应的信息. 按位乘方式相比于按位加方式更大程度上改变了原有信息,产生的新特征会使原有信号发生畸变,降低信息的准确度. 为进一步验证上述推理,同时探究随着训练的进行,模型在不同特征合并方式下分类效果的变化,画出训练过程中H值的变化曲线,如图3所示,其中,I为迭代次数.
图 3
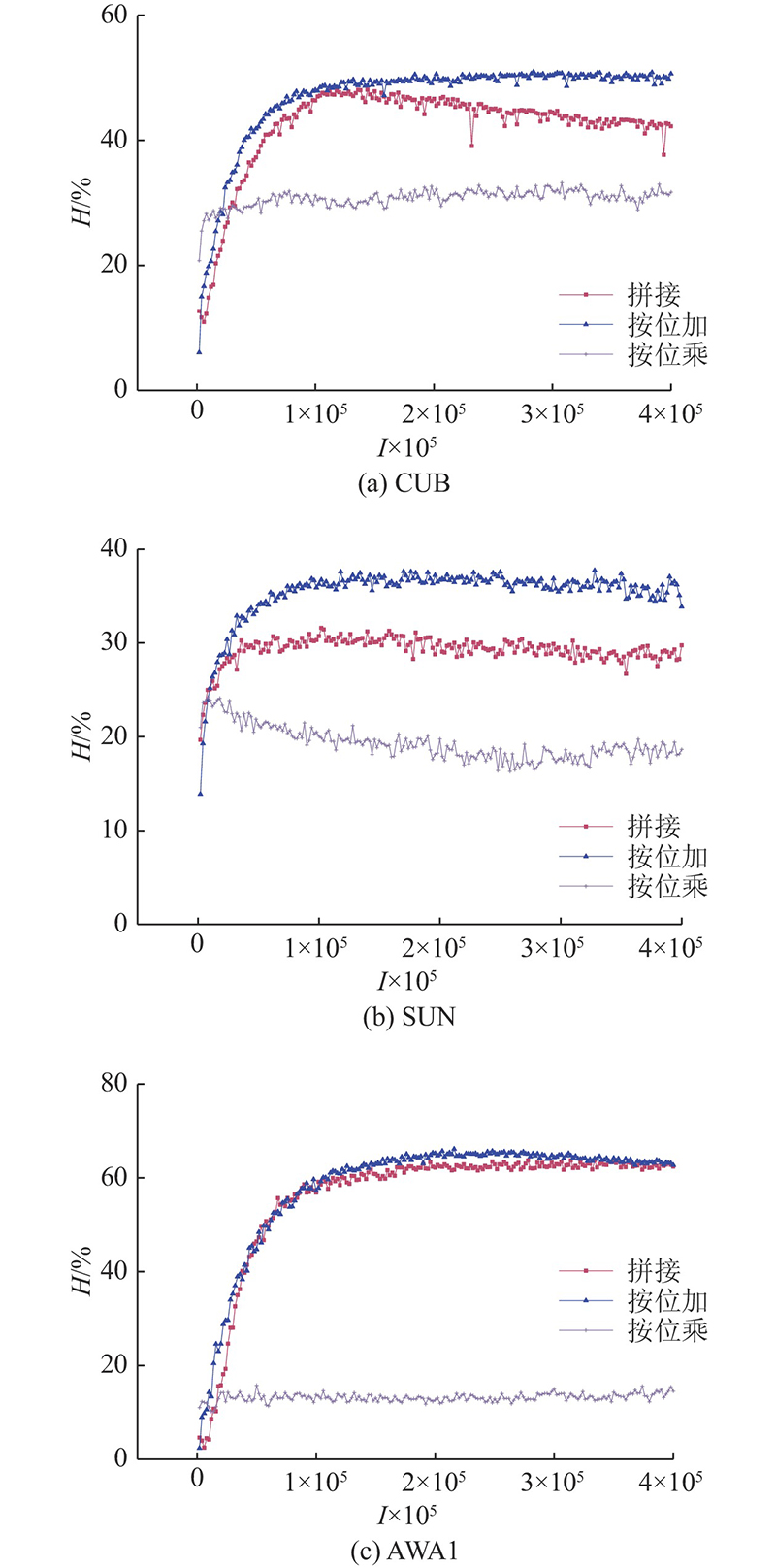
图 3 不同合并方式下H值在训练过程中的变化曲线
Fig.3 Comparison of H change curves of different merging ways during training
2.6. 消融实验
为了验证类语义的全局标记、分布差异约束和对抗约束的有效性,本研究在基线模型[6]的框架下,以按位加方式为基准,在公开的5个数据集上分别进行实验,如表4所示. 实验结果表明,类语义的全局标记、分布差异约束和对抗约束均能提高模型对未见类别的分类准确率以及H值. 其中,类语义全局标记在AWA1、AWA2和APY数据集上的
表 4 不同组件的消融实验结果
Tab.4
| 方法 | CUB | AWA1 | AWA2 | SUN | APY | ||||||||||||||
| U | S | H | U | S | H | U | S | H | U | S | H | U | S | H | |||||
| 按位加 | 44.7 | 55.9 | 49.7 | 56.1 | 77.7 | 65.2 | 54.1 | 80.4 | 64.7 | 31.3 | 43.3 | 36.3 | 31.1 | 67.4 | 42.5 | ||||
| 语义全局标记 | 45.8 | 57.5 | 51.0 | 58.1 | 79.6 | 67.2 | 54.9 | 83.8 | 66.3 | 32.6 | 42.0 | 36.7 | 34.3 | 68.0 | 45.6 | ||||
| 分布差异约束 | 45.1 | 61.4 | 52.0 | 61.5 | 76.4 | 68.2 | 55.4 | 80.9 | 65.8 | 32.2 | 43.1 | 36.9 | 33.4 | 66.2 | 44.4 | ||||
| 对抗约束 | 46.0 | 57.8 | 51.2 | 60.4 | 75.3 | 67.0 | 56.0 | 82.4 | 66.7 | 33.1 | 43.0 | 37.4 | 33.9 | 68.9 | 45.4 | ||||
3. 结 语
本研究提出一种深度监督对齐的零样本图像分类方法,构造类语义的全局监督标记的同时,与属性向量联合使用,提高了类语义的区分能力. 视觉特征和语义特征分类网络被分别用于学习视觉特征和类语义特征的类别分布,并且提出以分布差异约束共享和对齐两者的分布信息,以便于进行度量学习,此外,对抗训练的方式也被用于消除图像和语义属性之间的本质差异. 通过分析拼接、按位乘和按位加3种特征合并方式对关系网络学习视觉特征和类语义特征间的非线性相似度的影响,证明了在零样本图像分类中,按位加方式最为有效. 由于只是用预训练的深度神经网络简单提取图像的视觉特征,今后的研究可以引入注意力机制等进一步优化视觉嵌入特征的质量,也可以加强可见类别和未见类别之间的语义关联学习.
参考文献
A survey of zero-shot learning: settings, methods, and applications
[J].
零样本图像分类综述: 十年进展
[J].
A decadal survey of zero-shot image classification
[J].
零样本图像分类综述
[J].DOI:10.3778/j.issn.1673-9418.2010092 [本文引用: 1]
A survey of zero-shot image classification
[J].DOI:10.3778/j.issn.1673-9418.2010092 [本文引用: 1]
Class-prototype discriminative network for generalized zero-shot learning
[J].DOI:10.1109/LSP.2020.2968213 [本文引用: 7]
Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly
[J].
The sun attribute database: beyond categories for deeper scene understanding
[J].DOI:10.1007/s11263-013-0695-z [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}