[1]
杨小林, 葛世荣, 祖洪斌, 等 带式输送机永磁智能驱动系统及其控制策略
[J]. 煤炭学报 , 2020 , 45 (6 ): 2116 - 2126
DOI:10.13225/j.cnki.jccs.zn20.0345
[本文引用: 1]
YANG Xiao-lin, GE Shi-rong, ZU Hong-bin, et al The permanent magnet intelligent drive system of belt conveyor and its control strategy
[J]. Journal of China Coal Society , 2020 , 45 (6 ): 2116 - 2126
DOI:10.13225/j.cnki.jccs.zn20.0345
[本文引用: 1]
[2]
PETRIKOVA I, MARVALOVA B, SAMAL S, et al Digital image correlation as a measurement tool for large deformations of a conveyor belt
[J]. Applied Mechanics and Materials , 2015 , 732 : 77 - 80
DOI:10.4028/www.scientific.net/AMM.732.77
[本文引用: 1]
[3]
曹虎奇 煤矿带式输送机撕带断带研究分析
[J]. 煤炭科学技术 , 2015 , 43 (Suppl.2 ): 130 - 134
[本文引用: 1]
CAO Hu-qi Research and analysis on tearing and breaking belt of coal mine belt conveyor
[J]. Coal Science and Technology , 2015 , 43 (Suppl.2 ): 130 - 134
[本文引用: 1]
[5]
PANG Y S, LODEWIJKS G. A novel embedded conductive detection system for intelligent conveyor belt monitoring [C]// IEEE International Conference on Service Operations and Logistics and Informatics. Shanghai: IEEE, 2006: 803-808.
[本文引用: 1]
[6]
LI X G, SHEN L F, MING Z X, et al Laser-based online machine vision detection for longitudinal rip of conveyor belt
[J]. Optik , 2018 , 168 : 360 - 369
DOI:10.1016/j.ijleo.2018.04.053
[本文引用: 1]
[7]
BLAZEJ R, JURDZIAK L, KOZLOWSKI T, et al The use of magnetic sensors in monitoring the condition of the core in steel cord conveyor belts-Tests of the measuring probe and the design of the diag belt system.
[J]. Measurement , 2018 , 123 : 48 - 53
DOI:10.1016/j.measurement.2018.03.051
[本文引用: 1]
[8]
YANG R Y, QIAO T Z, PANG Y S, et al Infrared spectrum analysis method for detection and early warning of longitudinal tear of mine conveyor belt
[J]. Measurement , 2020 , 165 : 107856
DOI:10.1016/j.measurement.2020.107856
[本文引用: 1]
[10]
王志星. 输送带纵向撕裂双目视觉在线检测系统研究与设计[D]. 太原: 太原理工大学, 2018: 33-40.
[本文引用: 1]
WANG Zhi-xing. Research and design of binocular vision online detection system for longitudinal tearing of conveyor belt [D]. Taiyuan: Taiyuan University of Technology, 2018: 33-40.
[本文引用: 1]
[11]
刘伟力. 输送带纵向撕裂机器视觉在线监控系统研究[D]. 太原: 太原理工大学, 2017: 39-46.
[本文引用: 1]
LIU Wei-li. Research on online monitoring system of conveyor belt longitudinal tearing based on machine vision [D]. Taiyuan: Taiyuan University of Technology, 2017: 39-46.
[本文引用: 1]
[12]
LI W W, LI C Q, YAN F L Research on belt tear detection algorithm based on multiple sets of laser line assistance
[J]. Measurement , 2021 , 174 (2 ): 109047
[本文引用: 1]
[13]
GIRSHICK R. Fast R-CNN [EB/OL]. [2021-09-15]. https://arxiv.org/abs/1504.08083.
[本文引用: 1]
[14]
HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN [EB/OL]. [2021-09-15]. https://arxiv.org/abs/1703.06870.
[本文引用: 1]
[15]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// European Conference on Computer Vision . Berlin: Springer, 2016: 21-37.
[本文引用: 1]
[16]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[17]
YANG J, LI S B, WANG Z, et al Real-time tiny part defect detection system in manufacturing using deep learning
[J]. IEEE Access , 2019 , 7 (1 ): 89278 - 89291
[本文引用: 1]
[18]
LI Z Y, ZHU X N, ZHOU J. Intelligent monitoring system of coal conveyor belt based on computer vision technology [C]// International Conference on Dependable Systems and Their Applications . Harbin: IEEE, 2020: 359-364.
[本文引用: 1]
[19]
蒋镕圻, 彭月平, 谢文宣, 等 嵌入scSE模块的改进YOLOv4小目标检测算法
[J]. 图学学报 , 2021 , 42 (4 ): 546 - 555
[本文引用: 1]
JIANG Rong-qi, PENG Yue-ping, XIE Wen-xuan, et al Improved YOLOv4 small target detection algorithm embedded with scSE module
[J]. Journal of Graphics , 2021 , 42 (4 ): 546 - 555
[本文引用: 1]
[20]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// European Conference on Computer Vision . Berlin: Springer, 2018: 3-19.
[本文引用: 1]
[21]
HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications [EB/OL]. [2021-09-18]. https://arxiv.org/abs /1704.04861.
[本文引用: 1]
[22]
ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices [EB/OL]. [2021-09-18]. https://arxiv.org/abs/1707. 01083v2.
[本文引用: 1]
[23]
薄景文, 张春堂, 樊春玲, 等 改进YOLOv3的矿石输送带杂物检测方法
[J]. 计算机工程与应用 , 2021 , 57 (21 ): 248 - 255
DOI:10.3778/j.issn.1002-8331.2105-0025
[本文引用: 1]
BO Jing-wen, ZHANG Chun-tang, FAN Chun-ling, et al Improved YOLOv3 method for detecting trash on ore conveyor belts
[J]. Computer Engineering and Applications , 2021 , 57 (21 ): 248 - 255
DOI:10.3778/j.issn.1002-8331.2105-0025
[本文引用: 1]
[24]
周宇杰, 徐善永, 黄友锐, 等 基于改进YOLOv4的输送带损伤检测方法
[J]. 工矿自动化 , 2021 , 47 (11 ): 61 - 65
DOI:10.13272/j.issn.1671-251x.17843
[本文引用: 1]
ZHOU Yu-jie, XU Shan-yong, HUANG You-rui, et al Conveyor belt damage detection method based on improved YOLOv4
[J]. Industry and Mine Automation , 2021 , 47 (11 ): 61 - 65
DOI:10.13272/j.issn.1671-251x.17843
[本文引用: 1]
[25]
JADERBERG M, KAREN S, ANDREW Z. Spatial transformer networks [J]. Advances in Neural Information Processing Systems , 2015 (28): 2017-2025.
[本文引用: 1]
[26]
WANG Q L, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11531-11539.
[本文引用: 1]
[27]
WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7794-7803.
[本文引用: 1]
[28]
BOCHKOVSKIY A, WANG C Y, LIAO H M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. [2021-10-11]. https://arxiv.org/pdf/2004.10934.
[本文引用: 1]
带式输送机永磁智能驱动系统及其控制策略
1
2020
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
带式输送机永磁智能驱动系统及其控制策略
1
2020
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
Digital image correlation as a measurement tool for large deformations of a conveyor belt
1
2015
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
煤矿带式输送机撕带断带研究分析
1
2015
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
煤矿带式输送机撕带断带研究分析
1
2015
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
矿用输送带纵向撕裂检测系统研究
1
2017
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
矿用输送带纵向撕裂检测系统研究
1
2017
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
1
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
Laser-based online machine vision detection for longitudinal rip of conveyor belt
1
2018
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
The use of magnetic sensors in monitoring the condition of the core in steel cord conveyor belts-Tests of the measuring probe and the design of the diag belt system.
1
2018
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
Infrared spectrum analysis method for detection and early warning of longitudinal tear of mine conveyor belt
1
2020
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
Multispectral visual detection method for conveyor belt longitudinal tear
1
2019
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
1
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
1
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
1
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
1
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
Research on belt tear detection algorithm based on multiple sets of laser line assistance
1
2021
... 矿井下带式输送机运行环境恶劣,输送带是承接物料关键的部分[1 -2 ] . 从采掘机械运到输送机落料口的煤块会伴随有尖锐棱角物体(如槽钢和角钢等),并且落料口与两条输送带之间的首尾衔接处存在高度差,尖锐物体可以直接穿透或撕开输送带[3 -4 ] . 纵向撕裂主要发生在机头和机尾装载点处,主要表现为出现较大裂纹或完全撕裂,产生运输隐患的同时降低运输效率,造成经济损失. 因此,研究输送带纵向撕裂的实时检测具有重要意义. 常见的输送带纵向撕裂检测方法有线圈检测法[5 ] 、X光探伤[6 ] 和磁力检测法[7 ] 等,煤矿运输环境复杂有干扰性,这些方法因为稳定性和准确性低而不能满足需求. 传统的机器学习由人工制定学习特征量,进行图像的特征提取,目前以机器视觉技术为基础的输送带纵向撕裂检测得到发展. Yang等[8 ] 提出红外和可见光融合的输送带纵向撕裂双目视觉检测方法,一定程度上提高了模型的检测精度;Hou等[9 ] 提出多光谱视觉检测输送带纵向撕裂的方法,识别准确率达到92.04%;王等[10 -11 ] 搭建输送带纵向撕裂的检测平台,利用FAST角点检测和Hough变换算法实现无接触检测;Li等[12 ] 提出基于多组激光的计算机视觉检测算法,准确分割激光条纹区域,定位检测输送带的撕裂区域. 上述方法普遍存在数据预处理复杂,只关注输送带单一维度面的撕裂,还伴随着检测速度慢以及精度低等问题. ...
1
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
1
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
1
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
1
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
Real-time tiny part defect detection system in manufacturing using deep learning
1
2019
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
1
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
嵌入scSE模块的改进YOLOv4小目标检测算法
1
2021
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
嵌入scSE模块的改进YOLOv4小目标检测算法
1
2021
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
1
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
1
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
1
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
改进YOLOv3的矿石输送带杂物检测方法
1
2021
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
改进YOLOv3的矿石输送带杂物检测方法
1
2021
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
基于改进YOLOv4的输送带损伤检测方法
1
2021
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
基于改进YOLOv4的输送带损伤检测方法
1
2021
... 深度学习中卷积神经网络凭借强大的特征提取能力和自主学习能力被广泛运用于矿井作业的检测任务,可快速实现目标的分类识别和定位. 目标检测算法主要包括Fast R-CNN[13 ] 系列和Mask R-CNN[14 ] 等为代表的二阶段检测,SSD[15 ] 和YOLO[16 ] 系列等为代表的一阶段检测算法. 由于输送带纵向撕裂检测的实时性要求较高,大多采用一阶段的目标检测算法. Yang等[17 ] 提出改进SSD网络的微小部件缺陷检测算法,确定系统的最优带速为7.67 m/min;Li等[18 ] 基于YOLOv3识别左右侧的托辊基座是否被遮盖,用于输送带跑偏监测;蒋等[19 ] 在YOLOv4算法中嵌入scSE注意力模块,提升小目标物体的检测准确率;Woo等[20 ] 提出CBAM混合域注意力机制,使模型沿着通道和空间2个独立维度依次推导. 为了降低模型复杂度的应用需求,一些轻量化的网络如MobileNet[21 ] 和ShuffleNet[22 ] 被提出,使网络模型在精度和速度间进行较好的平衡. 薄等[23 ] 利用Mobilenetv2改进YOLOv3,在neck部分引入CBAM用于输送带运输中的杂物检测,提升检测精度和速度,但整个模型内存占用较大,不利于应用到移动端设备. 周等[24 ] 改进YOLOv4检测输送带损伤,采用PANet结构进行4种尺度的特征层融合,提升检测精度达到96.68%的同时,忽略了算法增加的参数量并且计算复杂度较高. ...
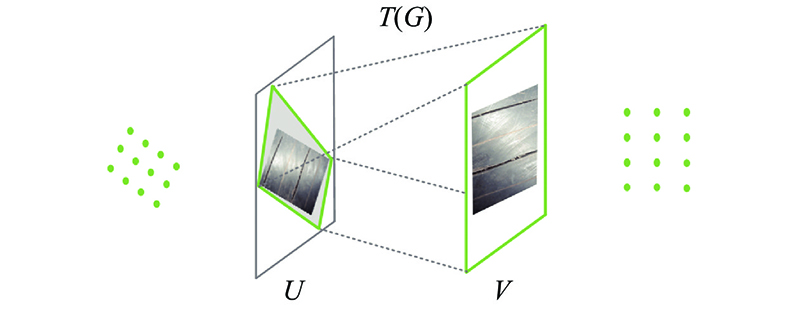
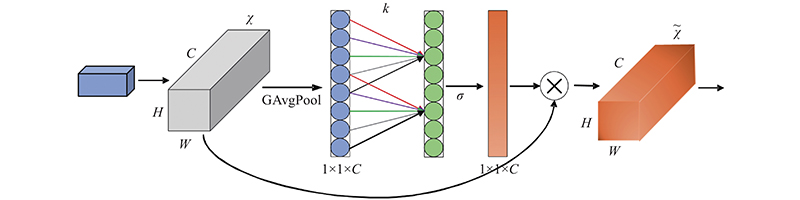
1
... 深度卷积神经网络中的注意力机制包括空间域注意力机制[25 ] 、通道域注意力机制[26 ] 和像素域注意力机制[27 ] 等,其中空间域注意力机制能够根据任务需求,自适应地对图像进行空间变换与对齐,通道域注意力机制专注通道间的信息,增强有益通道特征且抑制无用通道特征. ...
1
... 深度卷积神经网络中的注意力机制包括空间域注意力机制[25 ] 、通道域注意力机制[26 ] 和像素域注意力机制[27 ] 等,其中空间域注意力机制能够根据任务需求,自适应地对图像进行空间变换与对齐,通道域注意力机制专注通道间的信息,增强有益通道特征且抑制无用通道特征. ...
1
... 深度卷积神经网络中的注意力机制包括空间域注意力机制[25 ] 、通道域注意力机制[26 ] 和像素域注意力机制[27 ] 等,其中空间域注意力机制能够根据任务需求,自适应地对图像进行空间变换与对齐,通道域注意力机制专注通道间的信息,增强有益通道特征且抑制无用通道特征. ...
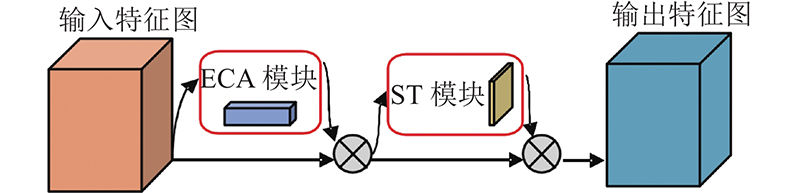
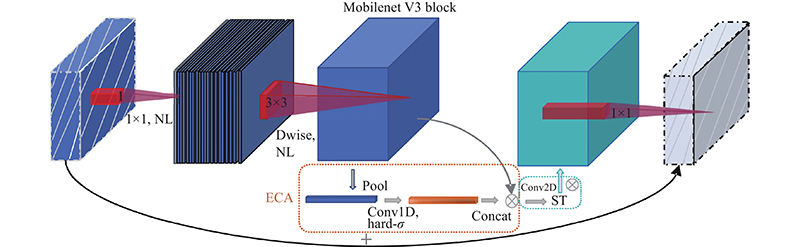
1
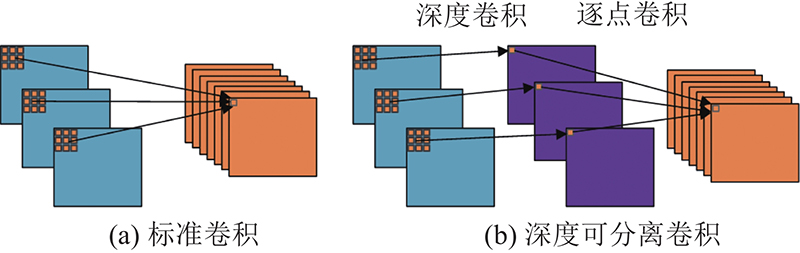
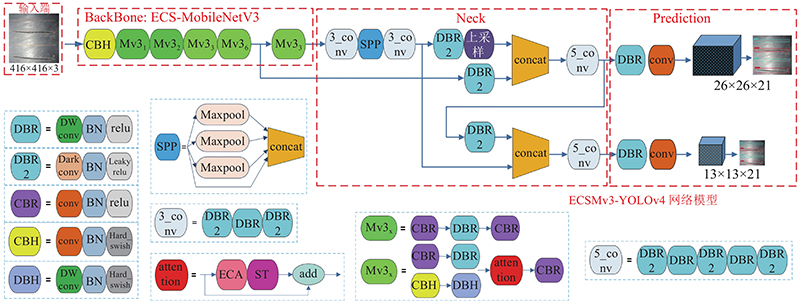
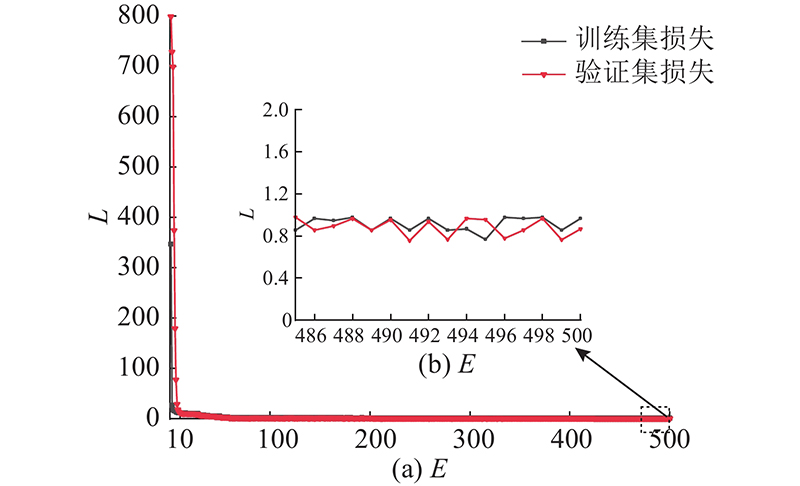
... 在原始YOLOv4算法[28 ] 中的CSPDarknet-53网络结构包含52个标准卷积层和1个全连接层,网络层数较多,模型复杂度高并且训练困难. 因此,在原始YOLOv4的基础上,提出轻量级的实时目标检测神经网络模型ECSMv3-YOLOv4来提高模型的推理速度,并且融入混合域注意力机制的MobileNetv3网络(ECSMv3)结构如表1 所示. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}