

工业大数据预测大型装备的剩余使用寿命(remaining useful life, RUL)对于保障系统安全和可靠运行具有重要意义与工程价值. 作为典型的结构复杂和预测难度高的机电装备系统,航空涡轮风扇发动机的健康状况直接影响到整机飞行的安全性和可靠性. 实时采集分析多类型高维度状态监测数据实现航空涡扇发动机剩余使用寿命的精准预测,在制定有效的预知维护策略中起到关键支撑作用[1].
数据驱动的RUL预测方法可以分为统计学习与机器学习2类. 统计学习方法使用卡尔曼滤波[2]和维纳过程[3]等构建数理模型,机器学习方法则包括支持向量机[4]等浅层学习方法、深度信念网络[5]、卷积神经网络[6]和长短期记忆网络[7]等深度学习方法. 针对航空涡扇发动机高维状态监测数据的机器学习RUL预测方法可以进一步划分为:一类方法是基于深度神经网络[6]和支持向量机[8]等模型,直接构建状态特征向量与RUL的映射关系;另一类方法则是先将高维数据转化为一维时序健康曲线,再使用相似性匹配方法[9]预估剩余寿命. 集成学习作为机器学习方式采用多学习器统合决策,来提升模型泛化能力. Zhou等[10]提出选择性集成方法,从大量的个体学习器选择少量,使得更好的模型参与集成. 随着相关研究的深入,选择性集成方法逐渐完善并向聚类[11]、排序[12]和动态选择[13]等方向发展. 集成学习与深度学习的结合是当前研究热点之一,如Xia等[14]设计AdaBoost-bagging双集成算法提高网络性能;Zhang等[15]以DBN作为基础模型,以差异度与准确度2个方面为目标,使用多目标遗传算法搭建集成模型. 由于深度学习对结构复杂度的高敏感性,现有的集成框架很难在保证基础模型独立的同时兼顾准确度. 在关键的多样性产生方法上,学者采用单一扰动方案致使模型构造多样性不足且包含冗余个体,影响集成学习对深度学习的提升表现.
针对上述问题,本研究提出两阶段的选择性深度神经网络集成的RUL预测方法. 以涡扇发动机的高维度和多类型状态监测数据为输入,通过层次化的多方法联合扰动,从构造上保证深度神经网络候选集多样性;选择性集成部分使用遗传算法排除强扰动下性能不良个体,获取强泛化能力的优效子集,从而综合集成多样性和个体准确性实现预测精度提升.
1. 预测方法构建
1.1. 集成学习
集成学习通过训练构建多个基础学习器并依策略结合的方式决定输出结果. 对于回归任务设有N个
式中:
集成学习模型泛化预测能力由集成学习器在分布
回归问题集成学习的分歧分解理论可以对泛化误差公式做进一步转化[16]:
式中:
式(7)表明集成回归模型的预测能力(即泛化误差
1.2. 选择性集成
选择性集成理论可以将所有个体参与集成,但是不能保证泛化性能的提高,需要从中寻找参与集成的最优子集. 假定
考虑仅保留部分学习器参与集成时泛化误差的变化,设排除第
当
注意
式(15)即此时集成模型的泛化误差减小. 在实际工业应用中,选择性集成算法的实施通常需要在划定好的验证集上,按照标准测试基模型的性能保留部分高效并且用学习器参与集成.
1.3. 问题描述
2. 选择性深度神经网络集成方法
为解决上述涡扇发动机RUL预测问题,提出选择性神经网络集成模型,流程框架分为2个阶段,如图1所示. 第1阶段采用深度神经网络模型作为集成的个体学习器,设计多方法联合扰动的候选集多样性产生方案,基于方法组合根本上破环个体间耦合关系;第2阶段基于启发式算法以预测精度为目标,排除低性能冗余子组,保留优选多样化候选组合,最终以简单平均法组合学习器作为集成模型输出.
图 1
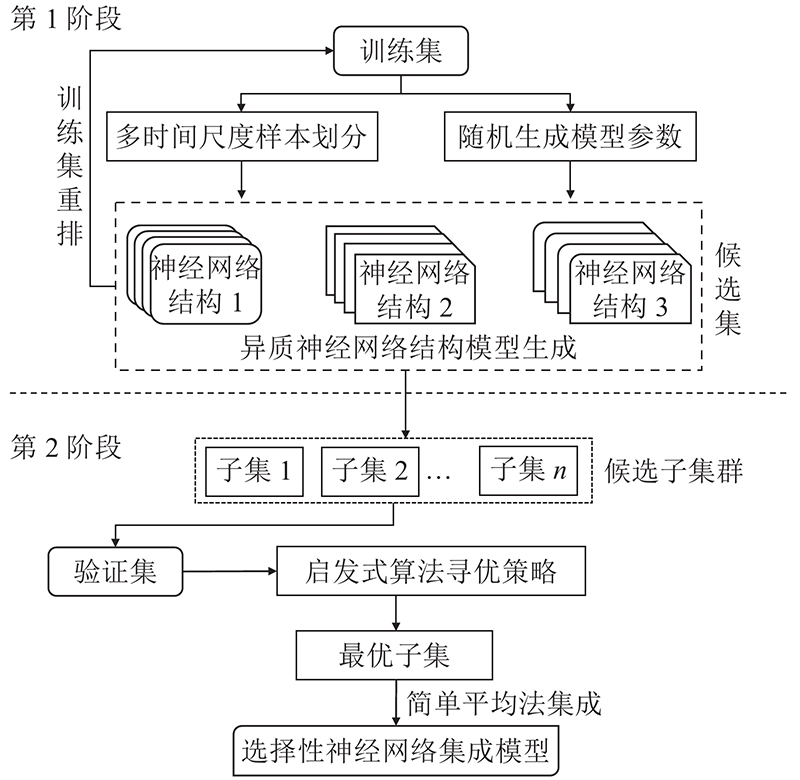
2.1. 多方法联合扰动下的候选集多样化产生方案
多样性是决定集成学习性能的关键指标,目前学界已从数据、参数和结构等角度,提出各类多样性提升方法,希望构造“好而不同”的学习器提升泛化预测能力[19]. 然而,现有研究多考虑单一多样性产生的方法,忽视方法间组合关系并且效果有限. 在模型构造的第1阶段,从模型结构多样性、时间尺度多样性和算法参数多样性出发,建立多方联合的模型训练扰动机制,最大化提升个体内部多样性,联合扰动方案共包括3个层面.
2.1.1. 异质神经网络结构
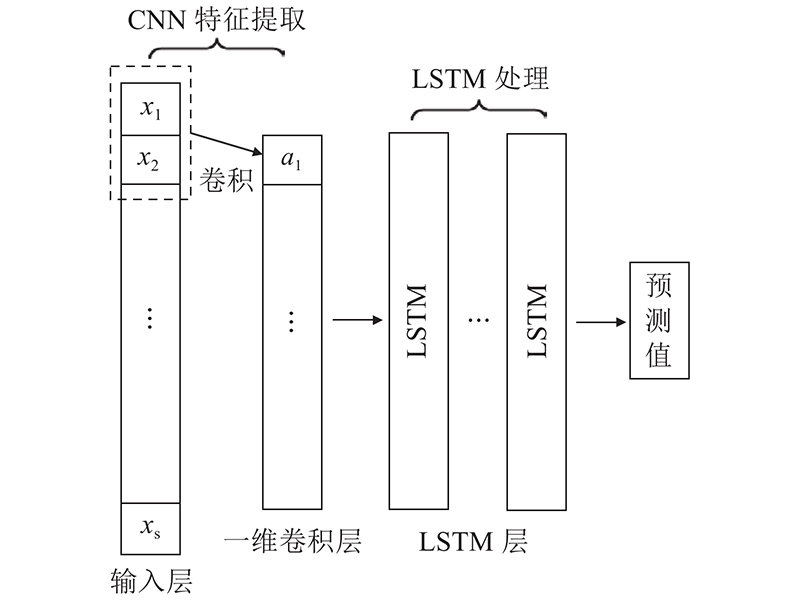
在模型结构层面上选取长短时记忆神经网络(long short term memory, LSTM)、卷积神经网络(convolutional neural networks, CNN)与CNN-LSTM组合网络的3种深度神经网络结构作异质集成. LSTM借助多个门控循环单元改变元胞所承载的信息,结构如图2所示. 其中,
图 2

CNN-LSTM组合神经网络参与集成结构如图3所示. CNN-LSTM通过 CNN提取深层次局部特征,并输入LSTM中进行长距离特征提取,再经变换输入全连接层从而获得预测结果. 在非线性的发动机退化过程中,LSTM和CNN等结构对数据的不同处理方式,使得它们对不同退化阶段的发动机RUL预测能力存在差异. 异质神经网络集成方法则充分利用这份差异,自适应据估计Adam提升个体间多样性的同时,综合模型各自预测优势,强化集成模型的整体鲁棒性.
图 3
2.1.2. 多时间尺度设计
在模型训练阶段时,某长度为S的训练数据,按选定时间尺度L滑动分割成(S-L)条长度为L的样本输入训练,时间窗将影响训练数据量及模型输入尺寸. 较长的时间窗长度能够更好地考虑运行状态的时序依赖性,充分利用退化信息,提升模型的预测能力[20]. 预测模型的时间窗长度不得大于测试样本的最短长度,这使得长时间尺度模型的应用能力受限. 针对上述问题,在集成模型框架下,将多时间尺度纳入扰动方案,预先划定备选时间窗长度
2.1.3. 算法参数的随机化
算法参数多样性方面,调整模型参数来产生多样性. 选择卷积核大小、卷积核数量和LSTM节点数等关键超参数,在一定的合理范围内随机波动,改变个体学习器输出的同时,增强候选集多样性. 在每个模型训练前进行数据集重排,避免训练集生成时产生的关联性. 上述多方法联合扰动方案可有效解决训练模型多样性不足问题,兼具2项优势:一项是摆脱固定时间尺度及部分关键参数的限制,极大地减少参数寻优过程的工作量;另一项是异质神经网络集成降低模型复杂度需求,提升深度效率.
2.2. 基于遗传算法的选择过程
第1阶段为最大程度激发集成多样性和构建强扰动下的候选子集,这里面包含性能过低和不应参与集成的冗余学习器. 因此选择性集成算法的第2阶段为选择阶段即依照设计指标,排除候选集中的不良个体保留最优子集. 对于候选神经网络集,假定已经有N个神经网络模型
图 4
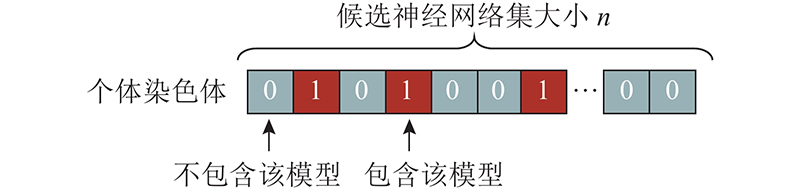
算法生成初始种群,并从训练集中抽取独立的验证集. 在验证集上,采用平均集成方法来计算染色体对应的神经网络子集的集成预测结果,利用预测结果的均方根误差RMSE的倒数作为适应度函数,经筛选、交叉和突变获取子代种群,循环选择过程. 在达到终止迭代代数后,选择最优个体即为被保留下来的集成模型,选择整体流程如算法1所示.
算法1 基于遗传算法的选择性集成过程
输入:候选神经网络集C,验证集V
初始化参数:初始种群大小n,终止迭代数m,交叉概率p,变异概率q
选择过程:
1. 按时间尺度将验证集V与候选神经网络集C匹配;
2. 生成初始种群,即多个候选子集
3. 在验证集V上按简单平均集成计算初始总群个体的预测结果;
4. 以RMSE的倒数计算适应度函数f;
5. 使用轮盘赌算法进行筛选;
6. 交叉变异,生成子代;
7. While 未达到终止迭代代数:对子代重复步骤3、4、5、6;
8. 计算子代中的最优个体.
输出:基于遗传算法选择的神经网络集
考虑到已对参与集成的神经网络做出选择的同时,在组合选择后的网络集时继续用加权集成容易导致过拟合[22],因此以简单平均集成结果作为预测结果输出.
3. 预测案例分析
3.1. 数据集分析
表 1 涡扇发动机状态参量描述
Tab.1
| 物理特性描述 | 单位 | 物理特性描述 | 单位 |
| 风扇入口总温度 | 兰氏度 | 风扇转换转速 | r/min |
| 低压压缩机温度 | 兰氏度 | 核心机转换转速 | r/min |
| 高压压缩机温度 | 兰氏度 | 抽汽焓 | − |
| 旁路管道总压强 | 磅力/平方英寸 | 需求风扇转速 | r/min |
| 高压压缩机压强 | 磅力/平方英寸 | 旁通比 | − |
| 低压涡轮温度 | 兰氏度 | 燃烧室油气比 | − |
| 风扇进口压强 | 磅力/平方英寸 | 需求风扇转换转速 | r/min |
| 物理风扇转速 | r/min | 高压涡轮冷气流量 | 磅/s |
| 物理核心机转速 | r/min | 低压涡轮冷气流量 | 磅/s |
| 发动机压力比 | − | 飞行高度 | 千英尺 |
| 高压压缩机静压 | 磅力/平方英寸 | 马赫数 | − |
| 燃料流量与静压比 | 秒脉冲数/ (磅力/平方英寸) | 节流器角度 | (°) |
利用C-MAPSS提供的仿真数据集FD001及FD003进行数据实验,包含训练集设备与测试集设备. FD001数据集仅含1种故障模式,FD003则包括2类故障,数据信息如表2所示.
表 2 FD001及FD003数据集描述
Tab.2
| 名称 | 训练发 动机数 | 测试发 动机数 | 训练样 本数 | 测试样 本数 | 传感 器数 | 运行 参数 |
| FD001 | 100 | 100 | 20 630 | 13 095 | 21 | 3 |
| FD003 | 100 | 100 | 24 720 | 16 596 | 21 | 3 |
3.2. 数据预处理
为了保证各维度参数不受量纲影响,对数据进行归一化,数据集总特征维数为24,采用下式将数据限定在[0, 1.0]:
式中:
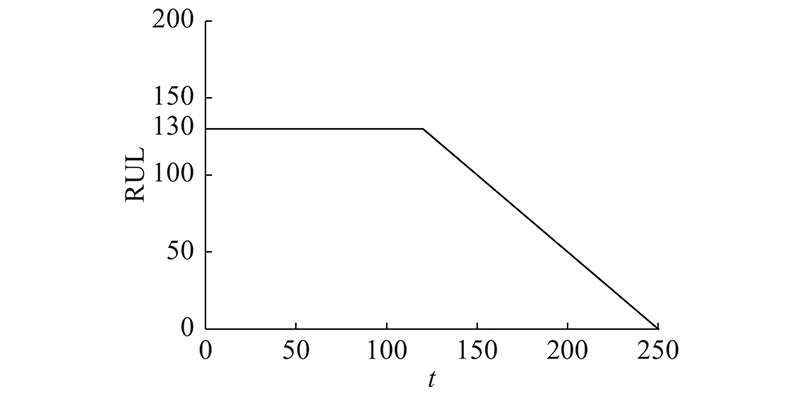
数据集提供21维传感器参数与3维运行参数,由于FD001及FD003均仅有1种运行状态,故运行参数不计考虑. 在对21维传感器参数进行分析处理后,发现仅有14维参数具有衰退型或增长型趋势,而剩余7维参数则无明显趋势,不能作为预测的有效数据,部分示例如图5所示. 其中,a为涡轮冷气流量,b为压缩机静压,c为风扇入口总温度.
图 5
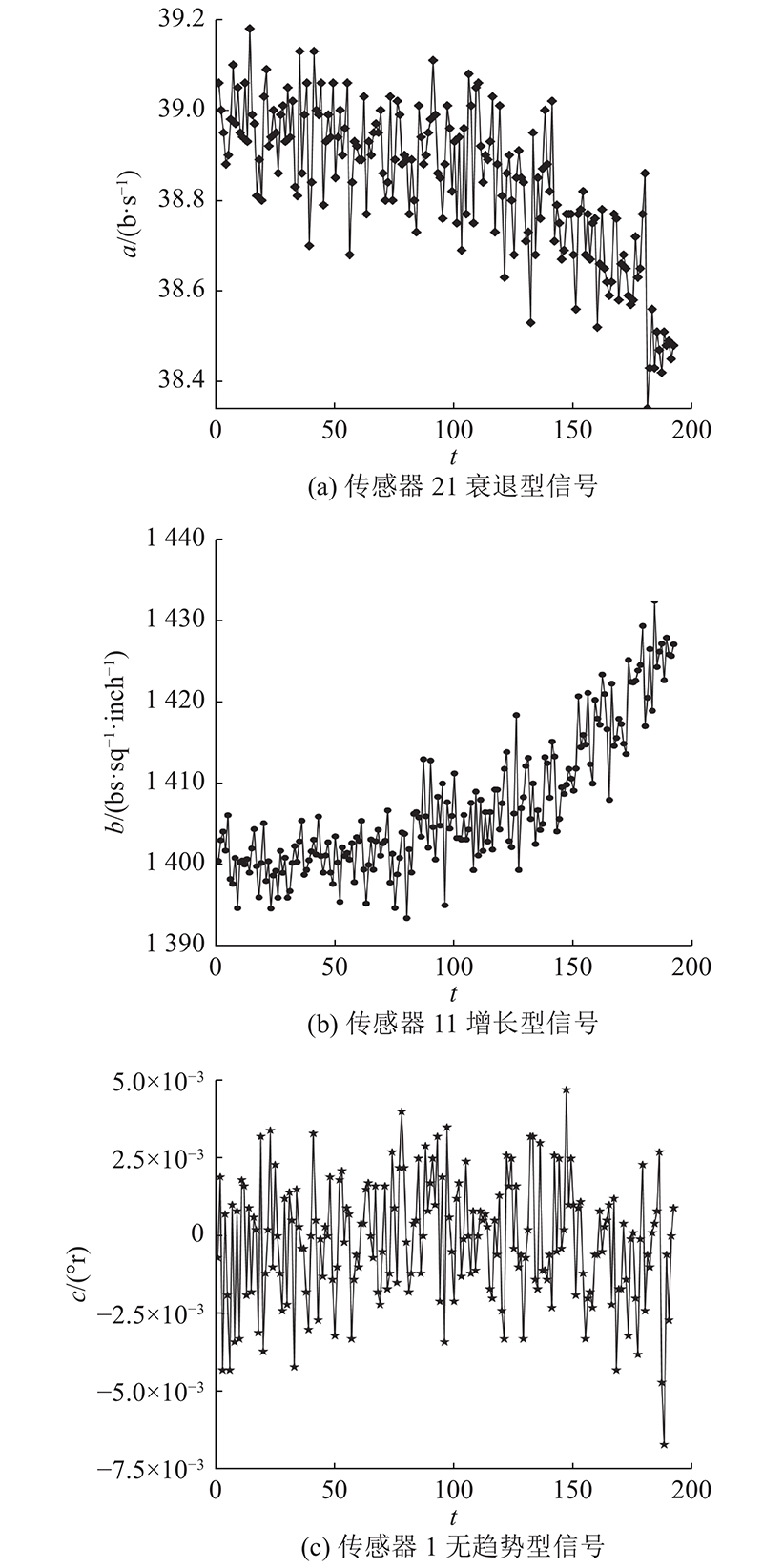
图 6
3.3. 参数与结构设置
在开始选择性深度神经网络集成模型的训练前,设定多方法联合扰动下的候选集多样性产生方案中的各项参数.
3.3.1. 备选时间窗长度
2个数据集测试样本的最短周期数为31,由于预测模型的时间窗长度应短于测试样本,因此设置最短时间窗尺度为30个运行周期;考虑发动机退化过程普遍长度,设置最长尺度为120. 结合数据量、收敛速度与运算时间等因素,等距设置4个时间尺度,即当前备选时间窗组为
3.3.2. 异质神经网络结构设计
选取4种长度的时间窗后,选择配合不同的神经网络结构进行训练,以构造异质候选集,各类网络结构的时间窗参数选择依特点及优势而定. 时间窗较短的网络模型可获取的数据量有限,难以获取样本内部的长程时序依赖关系,采用LSTM网络可更好地捕捉历史时间序列间关联特征. 时间窗较长模型蕴含样本信息更为丰富,采用CNN网络可有效提取局部抽象特征,反馈关键信息给预测模型. CNN-LSTM则综合两者特征. 因此,4种时间尺度网络结构如图7所示. 时间窗30的模型采用双层LSTM结构. 数据输入首层LSTM后,返回全部输出结果,再输入第2层,返回最后一个时间步结果做输出;时间窗为60的模型采用CNN-LSTM组合结构,数据首先输入1D-CNN及池化层后返回结果,随后输入LSTM网络中;时间窗为90与120使用CNN结构,在双层CNN之后添加平铺层与池化层. 所有的网络结构后均设置连接2个全连接层,第1个全连接层使用ReLU作为激活函数作为隐蔽层,以更好地线性划分特征;第2个采用线性激活函数,作为输出层. 选用均方误差MSE作为所有模型的损失函数,以及自适应据估计Adam算法(adaptive moment estimation)作为最小化损失优化器. 此外,为了防止深度网络模型常出现的过拟合问题,引入Dropout与Early stopping 这2种正则化手段.
图 7
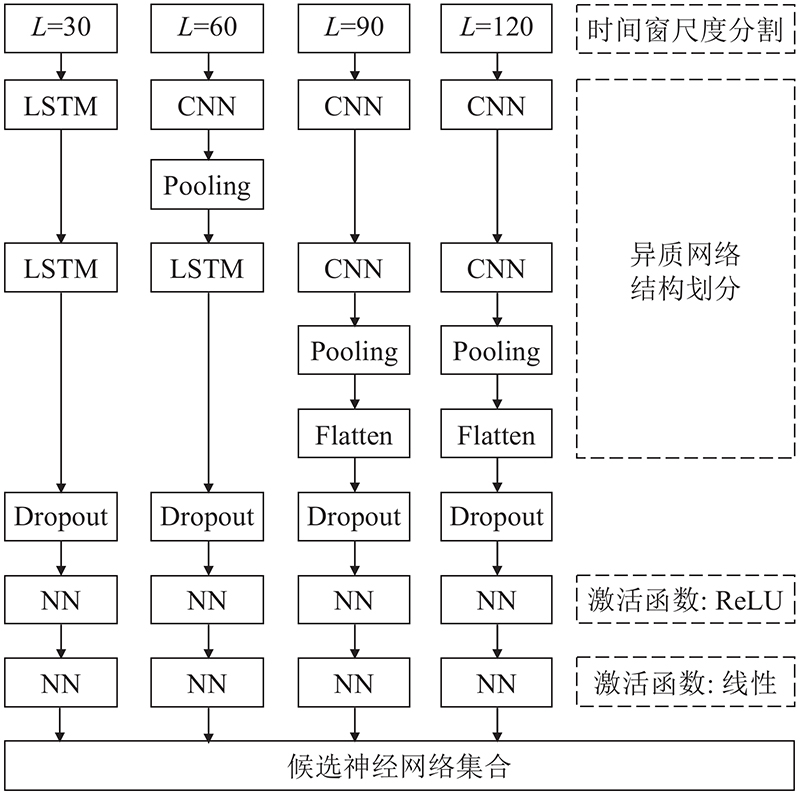
图 7 异质神经网络结构示意
Fig.7 Schematic diagram of Heterogeneous neural network structure
3.3.3. 神经网络与遗传算法参数
设置算法参数如表3所示. 在保证模型的基础准确性时,神经网络批尺寸、训练时期数及遗传算法超参数等通用参数维持常值应该不变. LSTM节点数和卷积核数等结构参数则如上文所述由随机化生成,满足多样性条件的同时,也避免复杂参数寻优过程.
表 3 神经网络与遗传算法关键参数设置
Tab.3
| 参数 | 数值 |
| 批尺寸 | 128 |
| 训练时期数 | 100或达到early stopping停止条件 |
| LSTM节点数 | [20,40] |
| 卷积核数 | [50,100] |
| 卷积核大小 | [1,3] |
| 隐蔽层节点数 | 30 |
| Dropout | 0.5 |
| 遗传算法初始种群大小 | 100 |
| 终止迭代代数 | 1 000 |
| 交叉概率 | 0.7 |
3.3.4. 算法模型复杂度
随机化参数设定为中间值时4类基神经网络模型,复杂度如表4所示. 模型参数量表中的空间复杂度,即模型访存量;每秒浮点运算数FLOPs表时间复杂度,衡量算法运行速度. 4类基模型复杂度均较低,并且随输入时间尺度扩大而增加.
表 4 各类用于集成的基模型复杂度
Tab.4
| 基模型 | 模型参数量 | FLOPs/G |
| LSTM(时间窗30) | 34 501 | 4.72×10−4 |
| CNN-LSTM(60) | 74 776 | 3.53×10−2 |
| CNN(90) | 317 417 | 3.88×10−1 |
| CNN(120) | 553 741 | 5.52×10−1 |
3.4. 测试集划分与匹配
对FD001与FD003数据集依照多时间尺度做出划分,统计测试集各样本运行周期长度,以30、60、90和120这4个跨度将测试集分割为4个测试子集,统计分割后的各子集样本数量如表5. 此外,每轮选择过程都将从训练集中随机选取10%的训练样本作为遗传算法的验证样本集.
表 5 FD001与FD003测试集分割后数据量
Tab.5
| 测试集名称 | | | | |
| FD001 | 63 | 11 | 14 | 12 |
| FD003 | 65 | 16 | 13 | 6 |
候选神经网络集也应分为4类,依时间尺度与测试子集匹配:第1类包含全部时间窗长度的模型,模型数最多,但仅能用于运行周期长度在120以上的数据;第2类包含时间窗为0、60、90的模型,用于周期在120到90的数据;第3类是30与60,用于90到60以上数据;第4类仅含时间窗30的模型,用于长度60到30全部数据(测试数据中运行周期均超过30).
3.5. 训练、选择与预测实现
对于4组不同时间尺度,且结构不同的模型分别进行训练,每组生成多个等量的学习器,构成候选神经网络集. 神经网络集容量过小将影响集成模型的预测精度,但候选集扩容则会使模型训练及选择耗时以几何级数增长. 以FD001为例,通过数据实验进行最佳容量寻优,如图8所示,横坐标表候选容量,选择不同容量(40、60、80、120、100、160)对比,当总容量大于80时,模型精度提升并不显著. 综合运算效率考虑,确定候选集总容量为80,即每组训练20个神经网络模型.
图 8
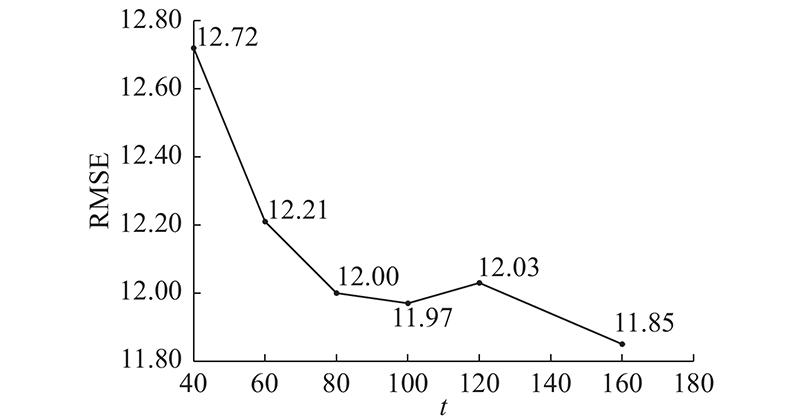
图 8 不同容量的集成模型实验结果
Fig.8 Predict value of ensemble models with different capacity
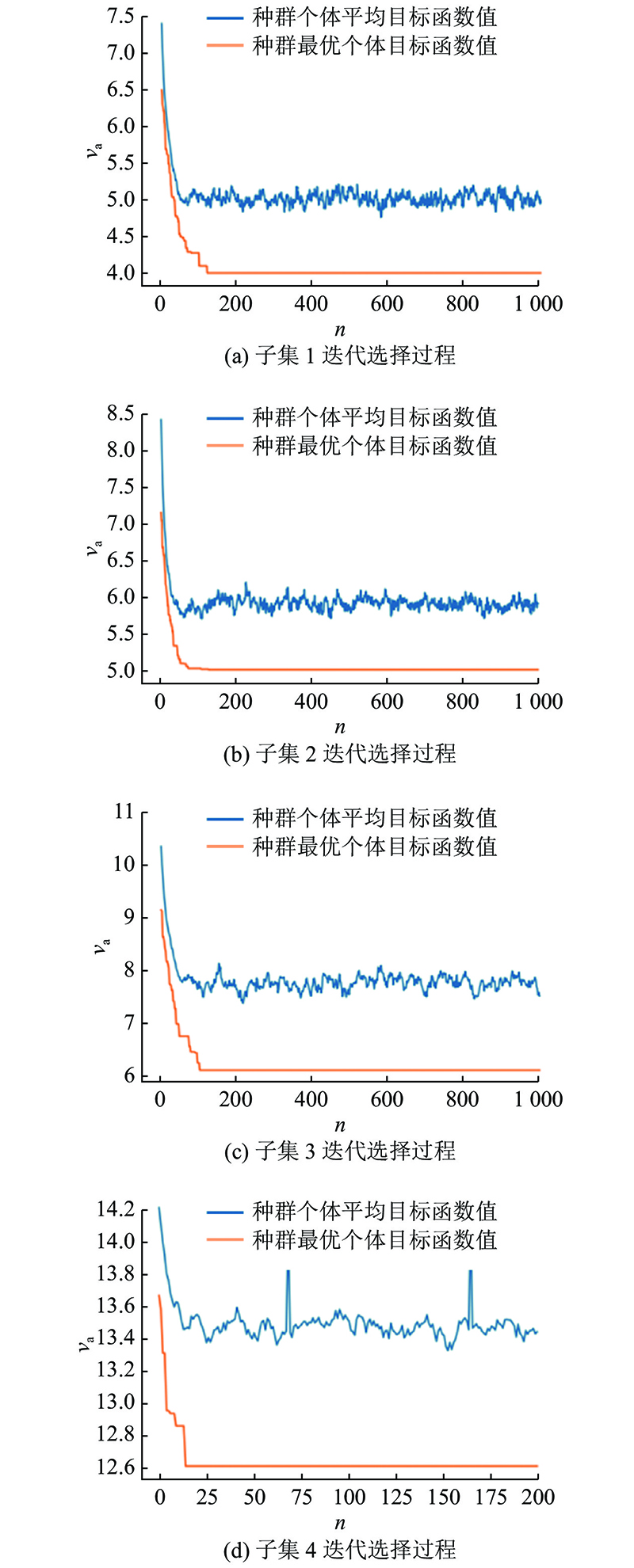
依照设定好的模型参数与结构,进行训练与选择过程. 4类候选神经网络子集容量分别为(80、60、40、20),在验证集上的进化选择过程如图9. 其中,横坐标为迭代次数n,纵坐标为图标函数值va,收敛速度随候选神经网络子集容量变大而变慢,最大子集约在150代左右得到最优解.
图 9
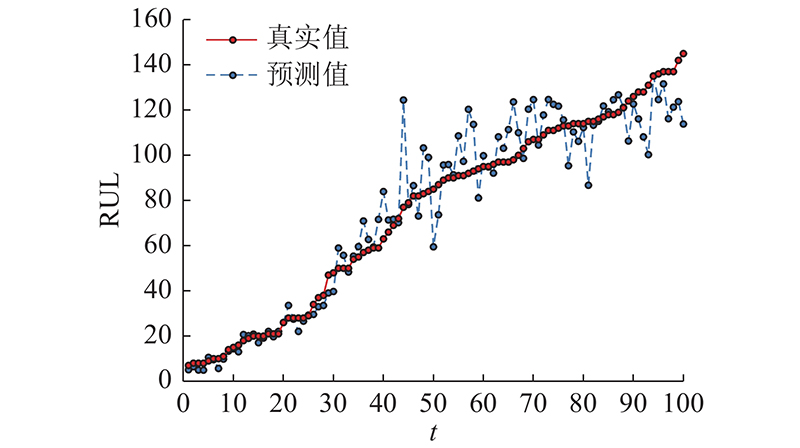
在选择后的模型以平均集成方式应用于测试集. 图10为FD001测试样本预测结果,测试发动机编号按RUL标签从小到大排序,以便观察分析. 总体而言,模型取得良好的预测结果,RUL值较小区域代表发动机寿命末期,模型预测能力极强. 对于RUL处在80~100个周期的退化中期样本,如44号发动机RUL为77,样本长度为71,状态处于变化阶段,预测产生部分波动.
图 10
4. 分析与讨论
4.1. 预测效果分析
为定量衡量预测结果,使用均方根误差RMSE与评分函数Scoring Function[5](SCORE)作为评价标准. 不同于均方根误差,评分函数SCORE给予模型滞后更大的惩罚权重,如式(17)所示,其中n为涡扇发动机台数,
以20轮实验的平均结果作为最终的评价指标,并与现有文献的方法对比,如表6所示. 文献[6]及[25]分别搭建深度卷积神经网络与深度长短时记忆网络模型;文献[26]利用CNN和LSTM神经网络相结合,提取更有效的时空特征进行预测;文献[27]以RNN自编码器获取HI曲线,并基于相似性方法预测;文献[15]使用DBN网络配合多目标进化算法的集成神经网络方法;文献[28]使用非精确健康曲线配合相似度匹配方法. 结果表明,所提方法在RMSE指标上具有较大的预测优势,在SCORE指标上也取得良好的结果. 数据表明方法可以有效地强化个体模型的预测能力,并通过综合多样化神经网络的预测结果来减小整体的泛化误差.
表 6 不同预测方法精度对比
Tab.6
| 预测方法 | RMSE | SCORE | |||
| FD001 | FD003 | FD001 | FD003 | ||
| Deep-CNN[6] | 12.61 | 12.64 | 274.00 | 284.10 | |
| Deep-LSTM[25] | 16.14 | 16.18 | 338.00 | 852.00 | |
| CNN-LSTM[26] | 16.13 | 17.12 | 303.00 | 1 420.00 | |
| RNN-SPI[27] | 13.58 | 19.16 | 228.00 | 1 727.00 | |
| MODBNE[15] | 15.04 | 19.41 | 334.00 | 683.40 | |
| RULCLIPPER[28] | 13.27 | 16.00 | 216.00 | 317.00 | |
| 选择性神经网络集成 | 12.00 | 13.08 | 282.00 | 314.80 | |
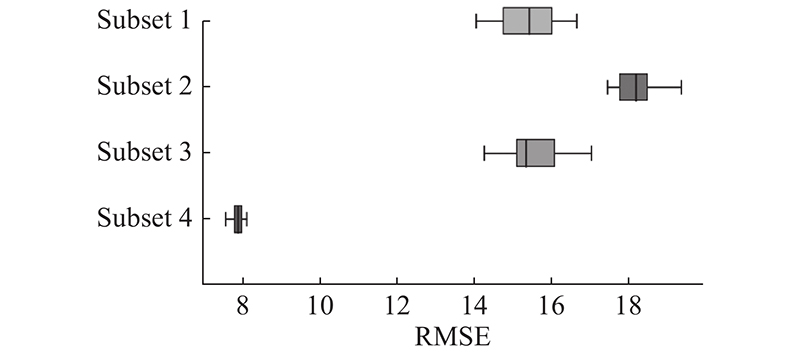
比较依时间尺度划分的4个测试子集上RMSE,图11为FD001各子集结果:子集1即运行周期长度在120以上的数据集的预测误差较低,且20轮实验的波动较小,代表模型在该测试子集上有着强而稳定的预测能力. 这表明子集1由于运行周期长,所含信息多,并且候选模型集范围最大,更便于集成模型充分发挥预测能力.
图 11
4.2. 集成效应分析
4.2.1. 集成学习方法的效应分析
为验证所提方法对个体学习器预测能力的提升效果,选择2.1节所述的3种结构,在保持超参数设置不变前提下以RMSE和SCORE作为评定指标作比较,结果如表7. 数据表明,所述的2个阶段方法成功兼顾了集成多样性与准确性,显著提高预测精度,2个数据集的RMSE提升幅度达到8%~23%, SCORE指标也有着良好的提升表现.
表 7 集成模型与个体学习器预测能力比较
Tab.7
| 方法 | RMSE | SCORE | |||
| FD001 | FD003 | FD001 | FD003 | ||
| LSTM | 14.28 | 16.97 | 362.00 | 674.00 | |
| CNN | 13.32 | 14.23 | 324.00 | 350.00 | |
| CNN-LSTM[ | 14.01 | 17.19 | 354.00 | 731.00 | |
| 选择性神经网络集成 | 12.00 | 13.08 | 282.00 | 314.00 | |
4.2.2. 多方法联合扰动方案的效应分析
通过异质神经网络、多时间尺度和算法参数随机化3种方式,设计联合扰动的多样性产生方案. 为验证方案效果,进行数据对比实验,如表8所示. 对比方案采用CNN结构为个体集成,时间窗长度设为30并保持超参数及模型候选集大小不变. 在数据中不采用多方法联合扰动方案的选择性集成效果不佳,相较单一的CNN模型的预测能力提升十分有限;相反,应用联合扰动方案的预测精度显著提升,证明方法多样性产生效果良好.
表 8 是否包含联合扰动多样性方法结果比较
Tab.8
| 方法 | RMSE | SCORE | |||
| FD001 | FD003 | FD001 | FD003 | ||
| 无多样性方法 | 12.96 | 14.47 | 292.00 | 340.00 | |
| 多扰动多样性提升 | 12.00 | 13.08 | 282.00 | 314.00 | |
4.2.3. 选择过程的效应分析
使用遗传算法完成集成前筛选,是本方法的关键工作之一,以无选择集成输出结果为对比,验证选择过程效果,结果如表9所示. 结果表明,无论是在RMSE还是在SCORE上,经过选择集成的结果均优于无选择过程,这证明当前的选择集成策略有效地排除性能不佳的冗余个体,确保基模型准确性. 由于FD003数据复杂度更高,基模型预测能力波动偏差大,故选择过程的提升效果更为明显.
表 9 是否选择集成过程结果比较
Tab.9
| 方法 | RMSE | SCORE | |||
| FD001 | FD003 | FD001 | FD003 | ||
| 无选择过程 | 12.26 | 13.99 | 288.00 | 343.00 | |
| 选择性集成 | 12.00 | 13.08 | 282.00 | 314.00 | |
5. 结 语
面对航空涡扇发动机为代表的复杂装备具有的高维度多类型状态数据特点,提出选择性深度神经网络集成方法,该方法突破单扰动限制,以层次化的多方法联合扰动方案,将时间尺度引入扰动方法中,并将选择性集成技术引入涡扇发动机RUL预测场景,保证模型高效精简. 此外,二阶段的选择性集成架构无需限制候选基模型结构与能力,并能够自适应性选择模型参数和时间尺度,方法具有普遍适用性和迁移性. 算例表明,本方法极大提高模型的泛化预测能力,在集成学习方法、多方法联合扰动方案和选择过程的效应方面均具有技术优势,可为复杂装备维护决策提供有力支撑. 在未来工作中,可考虑对遗传算法的适应度函数开展改进研究,探索将多样性指标纳入选择标准之中,以及调整和优化基学习器的网络深度及复杂度,进一步提高方法预测精度和泛化预测能力.
参考文献
Recent advances in prognostics and health management for advanced manufacturing paradigms
[J].
基于改进多新息扩展卡尔曼滤波的电池SOC估计
[J].
Estimation of state of charge of battery based on improved multi-innovation extended Kalman filter
[J].
An adaptive prediction model for the remaining life of an Li-Ion battery based on the fusion of the two-phase wiener process and an extreme learning machine
[J].DOI:10.3390/electronics10050540 [本文引用: 1]
A hybrid ARIMA–SVM model for the study of the remaining useful life of aircraft engines
[J].
Using deep learning-based approach to predict remaining useful life of rotating components
[J].
Remaining useful life estimation in prognostics using deep convolution neural networks
[J].
Robustness testing framework for RUL prediction Deep LSTM networks
[J].
Direct remaining useful life estimation based on support vector regression
[J].DOI:10.1109/TIE.2016.2623260 [本文引用: 1]
An evidential similarity-based regression method for the prediction of equipment remaining useful life in presence of incomplete degradation trajectories
[J].
Ensembling neural networks: many could be better than all
[J].DOI:10.1016/S0004-3702(02)00190-X [本文引用: 1]
半监督约束集成的快速密度峰值聚类算法
[J].
Semi-supervised constraint ensemble clustering by fast search and find of density peaks
[J].
Statistical instance based pruning in ensembles of independent classifiers
[J].
Ensemble selection by GRASP
[J].DOI:10.1007/s10489-013-0510-0 [本文引用: 1]
Dual-ensemble multi-feedback neural network for gearbox fault diagnosis
[J].
Multi-objective deep belief networks ensemble for remaining useful life estimation in prognostics
[J].DOI:10.1109/TNNLS.2016.2582798 [本文引用: 3]
Diversity creation methods: a survey and categorization
[J].DOI:10.1016/j.inffus.2004.04.004 [本文引用: 1]
Multi-stage fault diagnosis framework for rolling bearing based on OHF Elman AdaBoost-bagging algorithm
[J].
Multiscale similarity ensemble framework for remaining useful life prediction
[J].DOI:10.1016/j.measurement.2021.110565 [本文引用: 1]
基于Stacking集成学习的急诊患者到达预测
[J].DOI:10.19495/j.cnki.1007-5429.2019.06.022 [本文引用: 1]
Emergency patient arrival forecast based on stacking ensemble learning
[J].DOI:10.19495/j.cnki.1007-5429.2019.06.022 [本文引用: 1]
An ensemble framework based on convolutional bi-directional LSTM with multiple time windows for remaining useful life estimation
[J].DOI:10.1016/j.compind.2019.103182 [本文引用: 1]
基于多时间尺度相似性的涡扇发动机寿命预测
[J].
Remaining useful life prediction of turbofan engine based on similarity in multiple time scales
[J].
Neural network ensembles, cross validation, and active learning
[J].
Convolution and long short-term memory hybrid deep neural networks for remaining useful life prognostics
[J].DOI:10.3390/app9194156 [本文引用: 2]
An improved similarity-based prognostic algorithm for RUL estimation using an RNN autoencoder scheme
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}