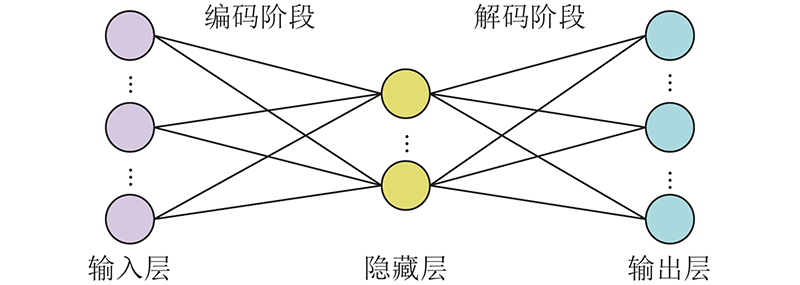
(3) $ \begin{split} {{\boldsymbol{\theta }}_0},{{\boldsymbol{\theta }}_0}' = &\mathop {\arg \min }\limits_{\theta ,\theta '} \frac{1}{m}\sum\limits_{i = 1}^m {L({{\boldsymbol{v}}^{(i)}}} ,{{\boldsymbol{z}}^{(i)}}) = \\ & \mathop {{\text{ }}\arg \min }\limits_{\theta ,\theta '} \frac{1}{m}\sum\limits_{i = 1}^m {L\left( {{{\boldsymbol{v}}^{(i)}},{d_{\theta '}}({e_\theta }({{\boldsymbol{v}}^{(i)}}))} \right)} . \end{split} $
其中, ${\rm{lu}}\;({\boldsymbol{x,y}}) $ $c\;({\boldsymbol{x,y}}) $ $s\;({\boldsymbol{x,y}}) $ $ {\rm{SSIM}}\;{\text{(}}{\boldsymbol{x}},{\boldsymbol{y}}{\text{)}} = {{\rm{SSIM}}} \;{\text{(}}{\boldsymbol{y}},{\boldsymbol{x}}{\text{)}} $ . 2)有界性: $ {\rm{SSIM}}\;{\text{(}}{\boldsymbol{x}},{\boldsymbol{y}}{\text{)}} \leqslant 1 $ . 3)最大值唯一: $ {\rm{SSIM}}\;{\text{(}}{\boldsymbol{x}},{\boldsymbol{y}}{\text{) = }}1 $ $ {\boldsymbol{x}} = {\boldsymbol{y}} $ $ {\rm{SSIM}}\;{\text{(}}{\boldsymbol{x}},{\boldsymbol{y}}{\text{)}} $
式中:m 为参与一次迭代的样本数;k 为类别数,MecNet为三分类网络,因此k 为3;第i 个训练样本的真实标签值表示为 $ [{y_0}^{(1)},{y_0}^{(2)},{y_0}^{(3)}] $ j 表示3个类别中的第j 类, $ {y_0}^{(j)} $ i 个训练样本真实标签值中第j 类的值, $ {y^{(j)}} $ j 类的概率. MecNet网络优化采用学习率自适应的Adam算法,MecNet网络优化停止的准则如下:当损失在1 000次循环内没有进一步改善时,终止训练.
[1]
付晓峰, 牛力, 胡卓群, 等 基于过渡帧概念训练的微表情检测深度网络
[J]. 浙江大学学报: 工学版 , 2020 , 54 (11 ): 2128 - 2137
[本文引用: 1]
FU Xiao-feng, NIU Li, HU Zhuo-qun, et al Deep micro-expression spotting network training based on concept of transition frame
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (11 ): 2128 - 2137
[本文引用: 1]
[2]
BEN X, REN Y, ZHANG J, et al Video-based facial micro-expression analysis: a survey of datasets, features and algorithms
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (9 ): 5826 - 5846
[本文引用: 1]
[3]
WEI J, LU G, YAN J A comparative study on movement feature in different directions for micro-expression recognition
[J]. Neurocomputing , 2021 , 449 : 159 - 171
DOI:10.1016/j.neucom.2021.03.063
[本文引用: 1]
[4]
ZHAO S, TAO H, ZHANG Y, et al A two-stage 3D CNN based learning method for spontaneous micro-expression recognition
[J]. Neurocomputing , 2021 , 448 : 276 - 289
DOI:10.1016/j.neucom.2021.03.058
[本文引用: 1]
[5]
LI Y, HUANG X, ZHAO G Joint local and global information learning with single apex frame detection for micro-expression recognition
[J]. IEEE Transactions on Image Processing , 2021 , 30 : 249 - 263
DOI:10.1109/TIP.2020.3035042
[本文引用: 3]
[6]
AOUAYEB M, HAMIDOUCHE W, SOLADIE C, et al Micro-expression recognition from local facial regions
[J]. Signal Processing: Image Communication , 2021 , 99 (116457 ): 1 - 9
[本文引用: 1]
[7]
LIU K, JIN Q, XU H, et al Micro-expression recognition using advanced genetic algorithm
[J]. Signal Processing: Image Communication , 2021 , 93 (116153 ): 1 - 10
[本文引用: 1]
[8]
GAN Y S, LIONG S T, YAU W C, et al OFF-ApexNet on micro-expression recognition system
[J]. Signal Processing: Image Communication , 2019 , 74 : 129 - 139
DOI:10.1016/j.image.2019.02.005
[本文引用: 2]
[9]
ZHOU L, MAO Q, XUE L. Dual-Inception network for cross-database micro-expression recognition [C]// 14th IEEE International Conference on Automatic Face and Gesture Recognition . Lille: IEEE, 2019: 1-5.
[本文引用: 2]
[10]
YAN W J, LI X, WANG S J, et al CASME II: an improved spontaneous micro-expression database and the baseline evaluation
[J]. PLOS ONE , 2014 , 9 (1 ): 1 - 8
[本文引用: 1]
[11]
LI X, PFISTER T, HUANG X, et al. A spontaneous micro-expression database: inducement, collection and baseline [C]// 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Shanghai: IEEE, 2013: 1–6.
[本文引用: 1]
[12]
DAVISON A K, LANSLEY C, COSTEN N, et al SAMM: a spontaneous micro-facial movement dataset
[J]. IEEE Transactions on Affective Computing , 2018 , 9 (1 ): 116 - 129
DOI:10.1109/TAFFC.2016.2573832
[本文引用: 1]
[13]
HUANG S W, LIN C T, CHEN S P, et al. AugGAN: cross domain adaptation with GAN-based data augmentation [C]// European Conference on Computer Vision . Munich: Springer, 2018: 731-744.
[本文引用: 1]
[14]
SHI W, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1874-1883.
[本文引用: 1]
[15]
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [C]// 30th Conference on Neural Information Processing Systems. Barcelona: [s. n.], 2016: 1-9.
[本文引用: 1]
[16]
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity
[J]. IEEE Transactions on Image Processing , 2004 , 13 (4 ): 1 - 14
DOI:10.1109/TIP.2004.827769
[本文引用: 1]
[17]
SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning [C]// 31st AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2017: 4-12.
[本文引用: 1]
[18]
ZHAO G, PIETIKAINEN M Dynamic texture recognition using local binary patterns with an application to facial expressions
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2007 , 29 (6 ): 915 - 928
DOI:10.1109/TPAMI.2007.1110
[本文引用: 1]
[19]
LIONG S T, SEE J, WONG K, et al Less is more: micro-expression recognition from video using apex frame
[J]. Signal Processing: Image Communication , 2018 , 62 : 82 - 92
DOI:10.1016/j.image.2017.11.006
[本文引用: 1]
[20]
QUANG N V, CHUN J, TOKUYAMA T. CapsuleNet for micro-expression recognition [C]// 14th IEEE International Conference on Automatic Face and Gesture Recognition . Lille: IEEE, 2019: 1-7.
[本文引用: 1]
[21]
LIONG S T, GAN Y, SEE J, et al. Shallow triple stream three-dimensional CNN (STSTNet) for micro-expression recognition [C]// 14th IEEE International Conference on Automatic Face and Gesture Recognition . Lille: IEEE, 2019: 1-5.
[本文引用: 1]
[22]
LIU Y, DU H, ZHENG L, et al. A neural micro-expression recognizer [C]// 14th IEEE International Conference on Automatic Face and Gesture Recognition . Lille: IEEE, 2019: 1-4.
[本文引用: 2]
基于过渡帧概念训练的微表情检测深度网络
1
2020
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
基于过渡帧概念训练的微表情检测深度网络
1
2020
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
Video-based facial micro-expression analysis: a survey of datasets, features and algorithms
1
2022
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
A comparative study on movement feature in different directions for micro-expression recognition
1
2021
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
A two-stage 3D CNN based learning method for spontaneous micro-expression recognition
1
2021
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
Joint local and global information learning with single apex frame detection for micro-expression recognition
3
2021
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
... Comparison of proposed method with existing methods
Tab.5 方法 联合数据库 SMIC CASME II SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[18 ] 0.588 2 0.578 5 0.200 0 0.528 0 0.702 6 0.742 9 0.395 4 0.410 2 Bi-WOOF[19 ] 0.629 6 0.622 7 0.572 7 0.582 9 0.780 5 0.802 6 0.521 1 0.513 9 OFF-ApexNet[8 ] 0.719 6 0.709 6 0.681 7 0.669 5 0.876 4 0.868 1 0.540 9 0.539 2 CapsuleNet[20 ] 0.652 0 0.650 6 0.582 0 0.587 7 0.706 8 0.701 8 0.620 9 0.598 9 Dual-Inception[9 ] 0.732 2 0.727 8 0.664 5 0.672 6 0.862 1 0.856 0 0.586 8 0.566 3 STSTNet[21 ] 0.735 3 0.760 5 0.680 1 0.701 3 0.838 2 0.868 6 0.658 8 0.681 0 EMR[22 ] 0.788 5 0.782 4 0.746 1 0.753 0 0.829 3 0.820 9 0.775 4 0.715 2 LGCcon[5 ] — — — — 0.792 9 0.763 9 0.524 8 0.495 5 LGCconD[5 ] — — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3
4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...
... [
5 ]
— — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3 4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...
Micro-expression recognition from local facial regions
1
2021
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
Micro-expression recognition using advanced genetic algorithm
1
2021
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
OFF-ApexNet on micro-expression recognition system
2
2019
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
... Comparison of proposed method with existing methods
Tab.5 方法 联合数据库 SMIC CASME II SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[18 ] 0.588 2 0.578 5 0.200 0 0.528 0 0.702 6 0.742 9 0.395 4 0.410 2 Bi-WOOF[19 ] 0.629 6 0.622 7 0.572 7 0.582 9 0.780 5 0.802 6 0.521 1 0.513 9 OFF-ApexNet[8 ] 0.719 6 0.709 6 0.681 7 0.669 5 0.876 4 0.868 1 0.540 9 0.539 2 CapsuleNet[20 ] 0.652 0 0.650 6 0.582 0 0.587 7 0.706 8 0.701 8 0.620 9 0.598 9 Dual-Inception[9 ] 0.732 2 0.727 8 0.664 5 0.672 6 0.862 1 0.856 0 0.586 8 0.566 3 STSTNet[21 ] 0.735 3 0.760 5 0.680 1 0.701 3 0.838 2 0.868 6 0.658 8 0.681 0 EMR[22 ] 0.788 5 0.782 4 0.746 1 0.753 0 0.829 3 0.820 9 0.775 4 0.715 2 LGCcon[5 ] — — — — 0.792 9 0.763 9 0.524 8 0.495 5 LGCconD[5 ] — — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3
4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...
2
... 自动微表情识别可以应用在金融安全、临床诊断、谎言检测、情感监测等诸多领域[1 ] . 与宏表情相比,微表情所特有的持续时间短和肌肉运动幅度小的性质,使得微表情种类的判别准确率远远低于宏表情. Ben等[2 ] 强调宏表情和微表情之间的关键差异,利用这些差异进行较系统的调查研究——基于视频的微表情分析. 为了确定哪个方向的运动特征更容易区分微表情,Wei等[3 ] 选择18个方向,提出新的低维特征——单方向梯度直方图(histogram of single direction gradient,HSDG). 近三年来,使用卷积神经网络自动提取特征的方法代替传统的特征提取方法,已成为微表情识别最新的发展趋势. Zhao等[4 ] 提出基于连续三维卷积神经网络的微表情识别两阶段学习(即先验学习和目标学习)方法MERSiamC3D. Li等[5 ] 提出基于频域像素级变化率估计的顶点帧检测方法. Aouayeb等[6 ] 使用卷积神经网络和长短时记忆的复合架构,从局部面部区域学习时空特征,提取出微表情识别的局部特征. Liu等[7 ] 使用遗传算法寻找最优解,以促进计算过程产生更好的识别结果. 在遗传算法实现之前,直接采用基准预处理方法和特征提取器. Liong等[8 ] 引入源于OFF-ApexNet网络的光流特征,将光流与CNN结合在一起. Zhou等[9 ] 提出将2个Inception结构并联的Dual-Inception网络. ...
... Comparison of proposed method with existing methods
Tab.5 方法 联合数据库 SMIC CASME II SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[18 ] 0.588 2 0.578 5 0.200 0 0.528 0 0.702 6 0.742 9 0.395 4 0.410 2 Bi-WOOF[19 ] 0.629 6 0.622 7 0.572 7 0.582 9 0.780 5 0.802 6 0.521 1 0.513 9 OFF-ApexNet[8 ] 0.719 6 0.709 6 0.681 7 0.669 5 0.876 4 0.868 1 0.540 9 0.539 2 CapsuleNet[20 ] 0.652 0 0.650 6 0.582 0 0.587 7 0.706 8 0.701 8 0.620 9 0.598 9 Dual-Inception[9 ] 0.732 2 0.727 8 0.664 5 0.672 6 0.862 1 0.856 0 0.586 8 0.566 3 STSTNet[21 ] 0.735 3 0.760 5 0.680 1 0.701 3 0.838 2 0.868 6 0.658 8 0.681 0 EMR[22 ] 0.788 5 0.782 4 0.746 1 0.753 0 0.829 3 0.820 9 0.775 4 0.715 2 LGCcon[5 ] — — — — 0.792 9 0.763 9 0.524 8 0.495 5 LGCconD[5 ] — — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3
4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...
CASME II: an improved spontaneous micro-expression database and the baseline evaluation
1
2014
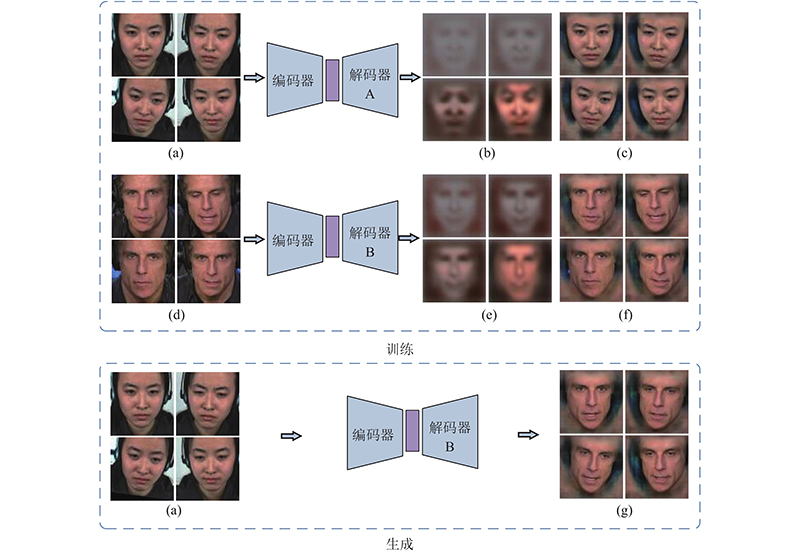
... 目前的微表情种类判别已经向多人种、多数据库方向发展. 第2届国际微表情识别大赛(MEGC 2019)使用CASME II数据库[10 ] 、SMIC数据库[11 ] 和SAMM数据库[12 ] ,组成微表情联合数据库,训练和评估模型性能. 类似于AugGAN[13 ] 利用白天的街景数据生成晚上的数据、利用夏天的数据生成冬天的数据和利用晴天的数据生成雾霾天气的数据,提高了行人识别的准确率. 本文使用CASME II亚洲人微表情样本生成欧美人微表情样本,提高了模型在多数据库下的微表情种类判别准确率. ...
1
... 目前的微表情种类判别已经向多人种、多数据库方向发展. 第2届国际微表情识别大赛(MEGC 2019)使用CASME II数据库[10 ] 、SMIC数据库[11 ] 和SAMM数据库[12 ] ,组成微表情联合数据库,训练和评估模型性能. 类似于AugGAN[13 ] 利用白天的街景数据生成晚上的数据、利用夏天的数据生成冬天的数据和利用晴天的数据生成雾霾天气的数据,提高了行人识别的准确率. 本文使用CASME II亚洲人微表情样本生成欧美人微表情样本,提高了模型在多数据库下的微表情种类判别准确率. ...
SAMM: a spontaneous micro-facial movement dataset
1
2018
... 目前的微表情种类判别已经向多人种、多数据库方向发展. 第2届国际微表情识别大赛(MEGC 2019)使用CASME II数据库[10 ] 、SMIC数据库[11 ] 和SAMM数据库[12 ] ,组成微表情联合数据库,训练和评估模型性能. 类似于AugGAN[13 ] 利用白天的街景数据生成晚上的数据、利用夏天的数据生成冬天的数据和利用晴天的数据生成雾霾天气的数据,提高了行人识别的准确率. 本文使用CASME II亚洲人微表情样本生成欧美人微表情样本,提高了模型在多数据库下的微表情种类判别准确率. ...
1
... 目前的微表情种类判别已经向多人种、多数据库方向发展. 第2届国际微表情识别大赛(MEGC 2019)使用CASME II数据库[10 ] 、SMIC数据库[11 ] 和SAMM数据库[12 ] ,组成微表情联合数据库,训练和评估模型性能. 类似于AugGAN[13 ] 利用白天的街景数据生成晚上的数据、利用夏天的数据生成冬天的数据和利用晴天的数据生成雾霾天气的数据,提高了行人识别的准确率. 本文使用CASME II亚洲人微表情样本生成欧美人微表情样本,提高了模型在多数据库下的微表情种类判别准确率. ...
1
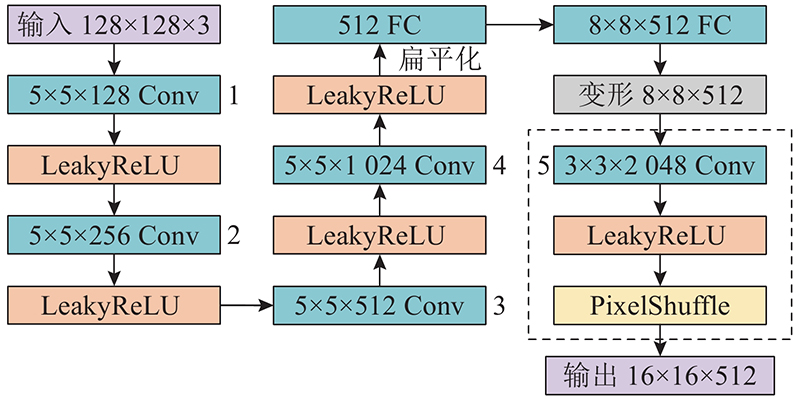
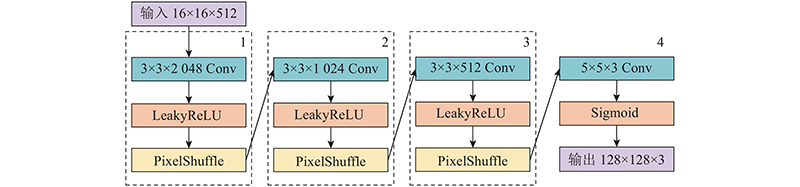
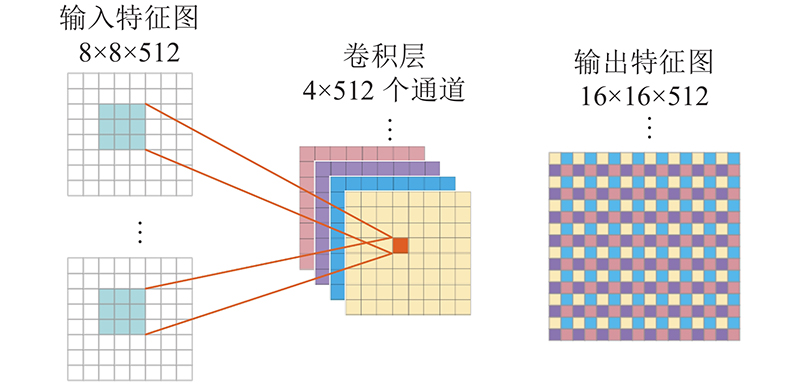
... 在卷积神经网络中,特征图经过卷积运算之后,尺寸会变小或者保持不变. 在自编码器网络中,存在需要放大特征图尺寸的情形,因此设计“卷积-激活-像素重组”特征图上采样模块. 常用的神经网络特征图上采样方法有上池化(uppooling)、解卷积(deconvolution)和子像素卷积神经网络(efficient sub-pixel convolution neural network,ESPCN)[14 ] 等. 以上方法中,解卷积和ESPCN效果最好,生成的图像质量最高. ESPCN不会出现解卷积方法中的棋盘效应问题[15 ] ,本文基于ESPCN设计特征图上采样模块. 如图5 所示为ESPCN网络结构,输入特征图的尺寸为7×7. 与输入层相连接的是N 层卷积层,其中第N 层卷积层设有r 2 个卷积核,即r 2 个通道,r 为放大倍数,ESPCN网络的r 取值为3. 在经过第N 层卷积后,特征图尺寸变为7×7×r 2 . 通过像素重组的操作,将7×7×r 2 的三维特征图转换为(7×r ) ×(7×r )尺寸的二维特征图,由此达到放大特征图尺寸的目的. 从图5 所示的卷积层N 及输出特征图可以看出,像素重组操作具体如下. 每次从卷积层N 的9个通道的特征图中各取一个值,按照从左至右、从上至下的排列顺序,填入3×3的9宫格,得到7×7个9宫格,排列为(7×3)×(7×3)尺寸的输出特征图. ...
1
... 在卷积神经网络中,特征图经过卷积运算之后,尺寸会变小或者保持不变. 在自编码器网络中,存在需要放大特征图尺寸的情形,因此设计“卷积-激活-像素重组”特征图上采样模块. 常用的神经网络特征图上采样方法有上池化(uppooling)、解卷积(deconvolution)和子像素卷积神经网络(efficient sub-pixel convolution neural network,ESPCN)[14 ] 等. 以上方法中,解卷积和ESPCN效果最好,生成的图像质量最高. ESPCN不会出现解卷积方法中的棋盘效应问题[15 ] ,本文基于ESPCN设计特征图上采样模块. 如图5 所示为ESPCN网络结构,输入特征图的尺寸为7×7. 与输入层相连接的是N 层卷积层,其中第N 层卷积层设有r 2 个卷积核,即r 2 个通道,r 为放大倍数,ESPCN网络的r 取值为3. 在经过第N 层卷积后,特征图尺寸变为7×7×r 2 . 通过像素重组的操作,将7×7×r 2 的三维特征图转换为(7×r ) ×(7×r )尺寸的二维特征图,由此达到放大特征图尺寸的目的. 从图5 所示的卷积层N 及输出特征图可以看出,像素重组操作具体如下. 每次从卷积层N 的9个通道的特征图中各取一个值,按照从左至右、从上至下的排列顺序,填入3×3的9宫格,得到7×7个9宫格,排列为(7×3)×(7×3)尺寸的输出特征图. ...
Image quality assessment: from error visibility to structural similarity
1
2004
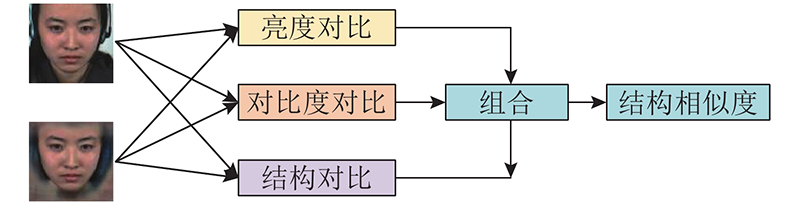
... 训练微表情生成网络,需要设计相应的损失函数. 图像生成类模型最常用和最简单的损失函数为均方差损失函数,传统自编码器和ESPCN网络均通过最小化均方差来训练网络,如式(3)、(4)所示. MegNet基于图像结构相似度(structural similarity,SSIM)[16 ] 设计损失函数,SSIM越大,表示图像越相似. 当2幅图像完全相同时,SSIM为1. ...
1
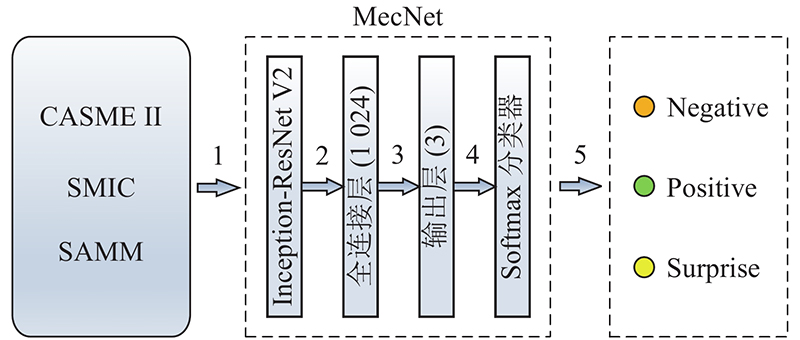
... 如图8 所示为微表情种类判别网络结构图,实验采用CASME II、SMIC和SAMM数据库. 步骤1表示将联合数据库的微表情样本放入MecNet网络进行训练. MecNet第1部分为Inception-ResNet V2[17 ] ,MecNet第2部分为全连接层. 步骤2表示使用Inception-ResNet V2从图像中提取形状和纹理特征,将该特征作为全连接层的输入. 步骤3表示在全连接层之后连接网络输出层. 步骤4表示MecNet采用Softmax分类器,损失函数为 ...
Dynamic texture recognition using local binary patterns with an application to facial expressions
1
2007
... Comparison of proposed method with existing methods
Tab.5 方法 联合数据库 SMIC CASME II SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[18 ] 0.588 2 0.578 5 0.200 0 0.528 0 0.702 6 0.742 9 0.395 4 0.410 2 Bi-WOOF[19 ] 0.629 6 0.622 7 0.572 7 0.582 9 0.780 5 0.802 6 0.521 1 0.513 9 OFF-ApexNet[8 ] 0.719 6 0.709 6 0.681 7 0.669 5 0.876 4 0.868 1 0.540 9 0.539 2 CapsuleNet[20 ] 0.652 0 0.650 6 0.582 0 0.587 7 0.706 8 0.701 8 0.620 9 0.598 9 Dual-Inception[9 ] 0.732 2 0.727 8 0.664 5 0.672 6 0.862 1 0.856 0 0.586 8 0.566 3 STSTNet[21 ] 0.735 3 0.760 5 0.680 1 0.701 3 0.838 2 0.868 6 0.658 8 0.681 0 EMR[22 ] 0.788 5 0.782 4 0.746 1 0.753 0 0.829 3 0.820 9 0.775 4 0.715 2 LGCcon[5 ] — — — — 0.792 9 0.763 9 0.524 8 0.495 5 LGCconD[5 ] — — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3
4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...
Less is more: micro-expression recognition from video using apex frame
1
2018
... Comparison of proposed method with existing methods
Tab.5 方法 联合数据库 SMIC CASME II SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[18 ] 0.588 2 0.578 5 0.200 0 0.528 0 0.702 6 0.742 9 0.395 4 0.410 2 Bi-WOOF[19 ] 0.629 6 0.622 7 0.572 7 0.582 9 0.780 5 0.802 6 0.521 1 0.513 9 OFF-ApexNet[8 ] 0.719 6 0.709 6 0.681 7 0.669 5 0.876 4 0.868 1 0.540 9 0.539 2 CapsuleNet[20 ] 0.652 0 0.650 6 0.582 0 0.587 7 0.706 8 0.701 8 0.620 9 0.598 9 Dual-Inception[9 ] 0.732 2 0.727 8 0.664 5 0.672 6 0.862 1 0.856 0 0.586 8 0.566 3 STSTNet[21 ] 0.735 3 0.760 5 0.680 1 0.701 3 0.838 2 0.868 6 0.658 8 0.681 0 EMR[22 ] 0.788 5 0.782 4 0.746 1 0.753 0 0.829 3 0.820 9 0.775 4 0.715 2 LGCcon[5 ] — — — — 0.792 9 0.763 9 0.524 8 0.495 5 LGCconD[5 ] — — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3
4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...
1
... Comparison of proposed method with existing methods
Tab.5 方法 联合数据库 SMIC CASME II SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[18 ] 0.588 2 0.578 5 0.200 0 0.528 0 0.702 6 0.742 9 0.395 4 0.410 2 Bi-WOOF[19 ] 0.629 6 0.622 7 0.572 7 0.582 9 0.780 5 0.802 6 0.521 1 0.513 9 OFF-ApexNet[8 ] 0.719 6 0.709 6 0.681 7 0.669 5 0.876 4 0.868 1 0.540 9 0.539 2 CapsuleNet[20 ] 0.652 0 0.650 6 0.582 0 0.587 7 0.706 8 0.701 8 0.620 9 0.598 9 Dual-Inception[9 ] 0.732 2 0.727 8 0.664 5 0.672 6 0.862 1 0.856 0 0.586 8 0.566 3 STSTNet[21 ] 0.735 3 0.760 5 0.680 1 0.701 3 0.838 2 0.868 6 0.658 8 0.681 0 EMR[22 ] 0.788 5 0.782 4 0.746 1 0.753 0 0.829 3 0.820 9 0.775 4 0.715 2 LGCcon[5 ] — — — — 0.792 9 0.763 9 0.524 8 0.495 5 LGCconD[5 ] — — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3
4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...
1
... Comparison of proposed method with existing methods
Tab.5 方法 联合数据库 SMIC CASME II SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[18 ] 0.588 2 0.578 5 0.200 0 0.528 0 0.702 6 0.742 9 0.395 4 0.410 2 Bi-WOOF[19 ] 0.629 6 0.622 7 0.572 7 0.582 9 0.780 5 0.802 6 0.521 1 0.513 9 OFF-ApexNet[8 ] 0.719 6 0.709 6 0.681 7 0.669 5 0.876 4 0.868 1 0.540 9 0.539 2 CapsuleNet[20 ] 0.652 0 0.650 6 0.582 0 0.587 7 0.706 8 0.701 8 0.620 9 0.598 9 Dual-Inception[9 ] 0.732 2 0.727 8 0.664 5 0.672 6 0.862 1 0.856 0 0.586 8 0.566 3 STSTNet[21 ] 0.735 3 0.760 5 0.680 1 0.701 3 0.838 2 0.868 6 0.658 8 0.681 0 EMR[22 ] 0.788 5 0.782 4 0.746 1 0.753 0 0.829 3 0.820 9 0.775 4 0.715 2 LGCcon[5 ] — — — — 0.792 9 0.763 9 0.524 8 0.495 5 LGCconD[5 ] — — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3
4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...
2
... 如表5 所示为MecNet与现有方法的性能对比. 表中,MecNet一行表示不使用微表情数据增强方法,仅使用MecNet微表情种类判别网络的实验结果;MegNet+MecNet表示使用MegNet生成的微表情样本扩充训练集,再使用MecNet的实验结果. 从表5 可见,仅使用MecNet的实验结果优于部分现有的方法. 在使用MegNet扩充训练集后,MecNet性能得到显著提高. 与现有方法相比,MegNet+MecNet在SMIC和SAMM数据库上的性能略低于EMR方法[22 ] ;在CASME II数据库上的UF1略低于OFF-ApexNet方法,UAR略低于OFF-ApexNet、Dual-Inception和STSTNet方法. MegNet+MecNet在SMIC、CASME II和SAMM组成的联合数据库上的UF1和UAR优于现有的其他方法. ...
... Comparison of proposed method with existing methods
Tab.5 方法 联合数据库 SMIC CASME II SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[18 ] 0.588 2 0.578 5 0.200 0 0.528 0 0.702 6 0.742 9 0.395 4 0.410 2 Bi-WOOF[19 ] 0.629 6 0.622 7 0.572 7 0.582 9 0.780 5 0.802 6 0.521 1 0.513 9 OFF-ApexNet[8 ] 0.719 6 0.709 6 0.681 7 0.669 5 0.876 4 0.868 1 0.540 9 0.539 2 CapsuleNet[20 ] 0.652 0 0.650 6 0.582 0 0.587 7 0.706 8 0.701 8 0.620 9 0.598 9 Dual-Inception[9 ] 0.732 2 0.727 8 0.664 5 0.672 6 0.862 1 0.856 0 0.586 8 0.566 3 STSTNet[21 ] 0.735 3 0.760 5 0.680 1 0.701 3 0.838 2 0.868 6 0.658 8 0.681 0 EMR[22 ] 0.788 5 0.782 4 0.746 1 0.753 0 0.829 3 0.820 9 0.775 4 0.715 2 LGCcon[5 ] — — — — 0.792 9 0.763 9 0.524 8 0.495 5 LGCconD[5 ] — — 0.619 5 0.606 6 0.776 2 0.749 9 0.492 4 0.471 1 MecNet 0.763 2 0.770 4 0.720 1 0.731 9 0.866 7 0.851 0 0.735 8 0.677 2 MegNet+MecNet 0.789 3 0.805 6 0.742 5 0.751 3 0.867 4 0.852 1 0.768 2 0.709 3
4. 结 语 本文提出基于深度网络和迁移学习的MecNet网络,用于微表情种类判别. 为了提高多数据库下微表情种类的判别性能,构建基于自编码器的MegNet网络扩充微表情样本数量,可以在一定程度上缓解制约微表情研究发展的困难,为今后微表情种类判别研究提供帮助. 本文方法在SMIC、CASME II和SAMM联合数据库上的结果优于现有的其他几种方法. 未来的研究工作可以从以下方面着手:为了提高自动微表情识别的准确率,可以考虑以计算机视觉的方法为主,结合其他辅助手段检测和判别微表情. 在谎言检测的场景中,除了采集面部视频,还可以采集受试者的生理信号数据,以生理信号的强度变化来辅助微表情的识别. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}