[1]
范荣双, 陈洋, 徐启恒, 等 基于深度学习的高分辨率遥感影像建筑物提取方法
[J]. 测绘学报 , 2019 , 48 (1 ): 34 - 41
DOI:10.11947/j.AGCS.2019.20170638
[本文引用: 1]
FAN Rong-shuang, CHEN Yang, XU Qi-heng, et al A high-resolution remote sensing image building extraction method based on deep learning
[J]. Acta Geodaetica et Cartographica Sinica , 2019 , 48 (1 ): 34 - 41
DOI:10.11947/j.AGCS.2019.20170638
[本文引用: 1]
[3]
冉树浩, 胡玉龙, 杨元维, 等 基于样本形态变换的高分遥感影像建筑物提取
[J]. 浙江大学学报: 工学版 , 2020 , 54 (5 ): 996 - 1006
[本文引用: 1]
RAN Shu-hao, HU Yu-long, YANG Yuan-wei, et al Building extraction from high resolution remote sensing image based on sample morphological transformation
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (5 ): 996 - 1006
[本文引用: 1]
[4]
JUNG C R, SCHRAMM R. Rectangle detection based on a windowed Hough transform [C]// Proceedings of 17th Brazilian Symposium on Computer Graphics and Image Processing . Curitiba: IEEE, 2004: 113-120.
[本文引用: 1]
[6]
BOULILA W, SELLAMI M, DRISS M, et al RS-DCNN: a novel distributed convolutional-neural-networks based-approach for big remote-sensing image classification
[J]. Computers and Electronics in Agriculture , 2021 , 182 : 106014
DOI:10.1016/j.compag.2021.106014
[本文引用: 1]
[7]
HAN W, FENG R, WANG L, et al A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification
[J]. ISPRS Journal of Photogrammetry and Remote Sensing , 2018 , 145 : 23 - 43
DOI:10.1016/j.isprsjprs.2017.11.004
[8]
AILONG M, YUTING W, YANFEI Z, et al SceneNet: remote sensing scene classification deep learning network using multi-objective neural evolution architecture search
[J]. ISPRS Journal of Photogrammetry and Remote Sensing , 2021 , 172 : 171 - 188
DOI:10.1016/j.isprsjprs.2020.11.025
[本文引用: 1]
[9]
SAITO S, YAMASHITA T, AOKI Y Multiple object extraction from aerial imagery with convolutional neural networks
[J]. Electronic Imaging , 2016 , 2016 (10 ): 1 - 9
[本文引用: 1]
[10]
BALL J E, ANDERSON D T, CHAN C S Comprehensive survey of deep learning in remote sensing: theories, tools, and challenges for the community
[J]. Journal of Applied Remote Sensing , 2017 , 11 (4 ): 042609
[本文引用: 1]
[11]
MNIH V. Machine learning for aerial image labeling [D]. Canada: University of Toronto, 2013.
[本文引用: 2]
[12]
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2016 , 39 (4 ): 640 - 651
[本文引用: 2]
[13]
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation [C]// International Conference on Medical Image Computing and Computer-Assisted Intervention . Cham: Springer, 2015: 234-241.
[本文引用: 2]
[14]
YI Y, ZHANG Z, ZHANG W, et al Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network
[J]. Remote Sensing , 2019 , 11 (15 ): 1774
DOI:10.3390/rs11151774
[本文引用: 1]
[15]
SHAO Z, TANG P, WANG Z, et al BRRNet: a fully convolutional neural network for automatic building extraction from high-resolution remote sensing images
[J]. Remote Sensing , 2020 , 12 (6 ): 1050
DOI:10.3390/rs12061050
[本文引用: 2]
[16]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 40 (4 ): 834 - 848
[本文引用: 1]
[17]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. (2017-12-05)[2022-01-05]. https://arxiv.53yu.com/abs/1706.05587.
[本文引用: 1]
[18]
RAN S H, GAO X J, YANG Y W, et al Building multi-feature fusion refined network for building extraction from high-resolution remote sensing images
[J]. Remote Sensing , 2021 , 13 (14 ): 2794
DOI:10.3390/rs13142794
[本文引用: 1]
[19]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132-7141.
[本文引用: 1]
[20]
GAO Z, XIE J, WANG Q, et al. Global second-order pooling convolutional networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3024-3033.
[本文引用: 1]
[21]
FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3146-3154.
[22]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: [s. n. ], 2018: 3-19.
[本文引用: 1]
[23]
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2020.
[本文引用: 3]
[24]
LIN M, CHEN Q, YAN S. Network in network [EB/OL]. (2014-03-04)[2022-01-05]. https://arxiv.org/abs/1312.4400.
[本文引用: 1]
[25]
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// International Conference on Machine Learning . Lille: PMLR, 2015: 448-456.
[本文引用: 2]
[26]
WANG P, CHEN P, YUAN Y, et al. Understanding convolution for semantic segmentation [C]// 2018 IEEE Winter Conference on Applications of Computer Vision . Lake Tahoe: IEEE, 2018: 1451-1460.
[本文引用: 1]
[27]
JI S, WEI S, MENG L Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2018 , 57 (1 ): 574 - 586
[本文引用: 1]
[28]
KINGMA D P, BA J. Adam: a method for stochastic optimization [EB/OL]. (2017-01-30)[2022-01-05]. https://arxiv.org/abs/1412.6980.
[本文引用: 1]
[29]
MILLETARI F, NAVAB N, AHMADI S A. V-net: fully convolutional neural networks for volumetric medical image segmentation [C]// 2016 4th International Conference on 3D Vision . Stanford: IEEE, 2016: 565-571.
[本文引用: 1]
[30]
BADRINARAYANAN V, KENDALL A, CIPOLLA R Segnet: a deep convolutional encoder-decoder architecture for image segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (12 ): 2481 - 2495
DOI:10.1109/TPAMI.2016.2644615
[本文引用: 1]
[31]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Proceedings of the European Conference on Computer Vision . Munich: [s. n. ], 2018: 801-818.
[本文引用: 1]
[32]
ZHU Q, LIAO C, HU H, et al MAP-Net: multiple attending path neural network for building footprint extraction from remote sensed imagery
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2020 , 59 (7 ): 6169 - 6181
[本文引用: 1]
基于深度学习的高分辨率遥感影像建筑物提取方法
1
2019
... 建筑物作为重要的地物目标,探究其空间分布对城市的建设具有重要的意义. 精确、高效地从高分辨率遥感影像中提取建筑是目前遥感影像处理及应用领域的重点研究方向[1 ] . ...
基于深度学习的高分辨率遥感影像建筑物提取方法
1
2019
... 建筑物作为重要的地物目标,探究其空间分布对城市的建设具有重要的意义. 精确、高效地从高分辨率遥感影像中提取建筑是目前遥感影像处理及应用领域的重点研究方向[1 ] . ...
Object based image analysis for remote sensing
1
2010
... 传统的建筑物提取方法大多利用高分辨率遥感影像丰富的光谱、纹理、几何和空间等特征,对图像进行分割和特征提取[2 ] ,获得高分辨率遥感影像中的建筑物. 冉树浩等[3 ] 利用建筑物的几何特征和阴影进行特征提取,但在阴影重叠区域的提取结果欠佳. Jung等[4 ] 通过窗口Hough的变换提取矩形建筑的角点特征,实现矩形屋顶的提取,但当建筑物角点被遮挡时,无法精确地提取建筑物. 总体而言,人工设计的特征容易受外界影响产生明显的变化[5 ] . ...
基于样本形态变换的高分遥感影像建筑物提取
1
2020
... 传统的建筑物提取方法大多利用高分辨率遥感影像丰富的光谱、纹理、几何和空间等特征,对图像进行分割和特征提取[2 ] ,获得高分辨率遥感影像中的建筑物. 冉树浩等[3 ] 利用建筑物的几何特征和阴影进行特征提取,但在阴影重叠区域的提取结果欠佳. Jung等[4 ] 通过窗口Hough的变换提取矩形建筑的角点特征,实现矩形屋顶的提取,但当建筑物角点被遮挡时,无法精确地提取建筑物. 总体而言,人工设计的特征容易受外界影响产生明显的变化[5 ] . ...
基于样本形态变换的高分遥感影像建筑物提取
1
2020
... 传统的建筑物提取方法大多利用高分辨率遥感影像丰富的光谱、纹理、几何和空间等特征,对图像进行分割和特征提取[2 ] ,获得高分辨率遥感影像中的建筑物. 冉树浩等[3 ] 利用建筑物的几何特征和阴影进行特征提取,但在阴影重叠区域的提取结果欠佳. Jung等[4 ] 通过窗口Hough的变换提取矩形建筑的角点特征,实现矩形屋顶的提取,但当建筑物角点被遮挡时,无法精确地提取建筑物. 总体而言,人工设计的特征容易受外界影响产生明显的变化[5 ] . ...
1
... 传统的建筑物提取方法大多利用高分辨率遥感影像丰富的光谱、纹理、几何和空间等特征,对图像进行分割和特征提取[2 ] ,获得高分辨率遥感影像中的建筑物. 冉树浩等[3 ] 利用建筑物的几何特征和阴影进行特征提取,但在阴影重叠区域的提取结果欠佳. Jung等[4 ] 通过窗口Hough的变换提取矩形建筑的角点特征,实现矩形屋顶的提取,但当建筑物角点被遮挡时,无法精确地提取建筑物. 总体而言,人工设计的特征容易受外界影响产生明显的变化[5 ] . ...
遥感影像建筑物提取的卷积神经元网络与开源数据集方法
1
2019
... 传统的建筑物提取方法大多利用高分辨率遥感影像丰富的光谱、纹理、几何和空间等特征,对图像进行分割和特征提取[2 ] ,获得高分辨率遥感影像中的建筑物. 冉树浩等[3 ] 利用建筑物的几何特征和阴影进行特征提取,但在阴影重叠区域的提取结果欠佳. Jung等[4 ] 通过窗口Hough的变换提取矩形建筑的角点特征,实现矩形屋顶的提取,但当建筑物角点被遮挡时,无法精确地提取建筑物. 总体而言,人工设计的特征容易受外界影响产生明显的变化[5 ] . ...
遥感影像建筑物提取的卷积神经元网络与开源数据集方法
1
2019
... 传统的建筑物提取方法大多利用高分辨率遥感影像丰富的光谱、纹理、几何和空间等特征,对图像进行分割和特征提取[2 ] ,获得高分辨率遥感影像中的建筑物. 冉树浩等[3 ] 利用建筑物的几何特征和阴影进行特征提取,但在阴影重叠区域的提取结果欠佳. Jung等[4 ] 通过窗口Hough的变换提取矩形建筑的角点特征,实现矩形屋顶的提取,但当建筑物角点被遮挡时,无法精确地提取建筑物. 总体而言,人工设计的特征容易受外界影响产生明显的变化[5 ] . ...
RS-DCNN: a novel distributed convolutional-neural-networks based-approach for big remote-sensing image classification
1
2021
... 近十年,随着计算机软硬件技术的高速发展,深度学习技术随之兴起并被广泛应用. 早期卷积神经网络(convolutional neural networks, CNN)主要被用于图像分类[6 -8 ] 和目标检测[9 ] . Ball等[10 ] 利用深度学习的方法对遥感影像进行提取. Mnih[11 ] 将CNN应用于建筑物提取,但是该方法会导致大量的重复计算,严重影响图像分割效率. 为了解决上述问题,Long等[12 ] 在CNN的基础上,提出全卷积神经网络(full convolutional neural, FCN)用于语义分割任务,逐步成为众多语义分割网络的基本框架. ...
A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification
0
2018
SceneNet: remote sensing scene classification deep learning network using multi-objective neural evolution architecture search
1
2021
... 近十年,随着计算机软硬件技术的高速发展,深度学习技术随之兴起并被广泛应用. 早期卷积神经网络(convolutional neural networks, CNN)主要被用于图像分类[6 -8 ] 和目标检测[9 ] . Ball等[10 ] 利用深度学习的方法对遥感影像进行提取. Mnih[11 ] 将CNN应用于建筑物提取,但是该方法会导致大量的重复计算,严重影响图像分割效率. 为了解决上述问题,Long等[12 ] 在CNN的基础上,提出全卷积神经网络(full convolutional neural, FCN)用于语义分割任务,逐步成为众多语义分割网络的基本框架. ...
Multiple object extraction from aerial imagery with convolutional neural networks
1
2016
... 近十年,随着计算机软硬件技术的高速发展,深度学习技术随之兴起并被广泛应用. 早期卷积神经网络(convolutional neural networks, CNN)主要被用于图像分类[6 -8 ] 和目标检测[9 ] . Ball等[10 ] 利用深度学习的方法对遥感影像进行提取. Mnih[11 ] 将CNN应用于建筑物提取,但是该方法会导致大量的重复计算,严重影响图像分割效率. 为了解决上述问题,Long等[12 ] 在CNN的基础上,提出全卷积神经网络(full convolutional neural, FCN)用于语义分割任务,逐步成为众多语义分割网络的基本框架. ...
Comprehensive survey of deep learning in remote sensing: theories, tools, and challenges for the community
1
2017
... 近十年,随着计算机软硬件技术的高速发展,深度学习技术随之兴起并被广泛应用. 早期卷积神经网络(convolutional neural networks, CNN)主要被用于图像分类[6 -8 ] 和目标检测[9 ] . Ball等[10 ] 利用深度学习的方法对遥感影像进行提取. Mnih[11 ] 将CNN应用于建筑物提取,但是该方法会导致大量的重复计算,严重影响图像分割效率. 为了解决上述问题,Long等[12 ] 在CNN的基础上,提出全卷积神经网络(full convolutional neural, FCN)用于语义分割任务,逐步成为众多语义分割网络的基本框架. ...
2
... 近十年,随着计算机软硬件技术的高速发展,深度学习技术随之兴起并被广泛应用. 早期卷积神经网络(convolutional neural networks, CNN)主要被用于图像分类[6 -8 ] 和目标检测[9 ] . Ball等[10 ] 利用深度学习的方法对遥感影像进行提取. Mnih[11 ] 将CNN应用于建筑物提取,但是该方法会导致大量的重复计算,严重影响图像分割效率. 为了解决上述问题,Long等[12 ] 在CNN的基础上,提出全卷积神经网络(full convolutional neural, FCN)用于语义分割任务,逐步成为众多语义分割网络的基本框架. ...
... Massachusetts建筑物数据集由Mnih[11 ] 在2013年开放,包含了155个波士顿地区的航空图像和建筑物标签图像. 图像分辨率为1 m,每个图像的大小为1 500×1 500像素. 因为计算机的显存不足,将所有图像修整到256×256像素,得到训练图像4 392张,验证图像144张,测试图像360张. 如图4 (a)所示为部分影像与对应的建筑物标签数据. ...
Fully convolutional networks for semantic segmentation
2
2016
... 近十年,随着计算机软硬件技术的高速发展,深度学习技术随之兴起并被广泛应用. 早期卷积神经网络(convolutional neural networks, CNN)主要被用于图像分类[6 -8 ] 和目标检测[9 ] . Ball等[10 ] 利用深度学习的方法对遥感影像进行提取. Mnih[11 ] 将CNN应用于建筑物提取,但是该方法会导致大量的重复计算,严重影响图像分割效率. 为了解决上述问题,Long等[12 ] 在CNN的基础上,提出全卷积神经网络(full convolutional neural, FCN)用于语义分割任务,逐步成为众多语义分割网络的基本框架. ...
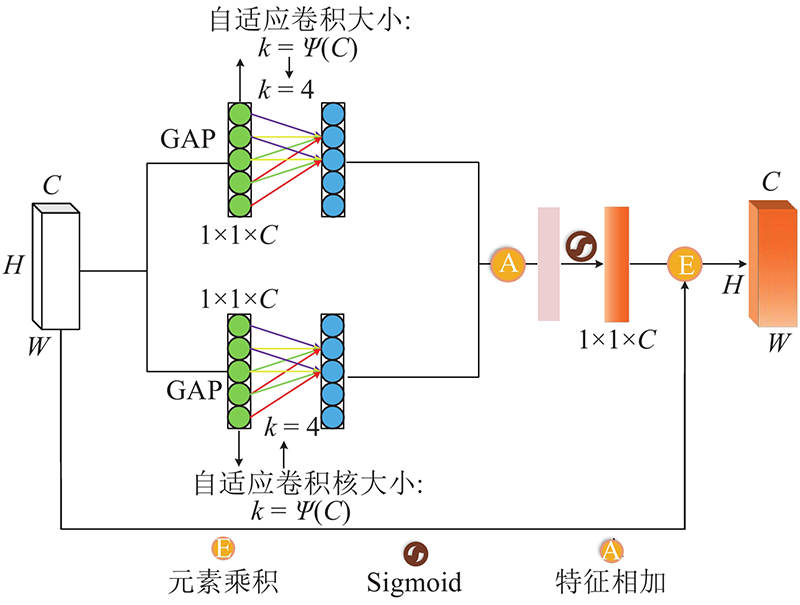
... FCN-8s、FCN-16s、FCN-32s[12 ] 网络主要利用不同尺度的上采样操作逐步恢复目标的详细信息,U-Net通过跳跃连接实现了特征图的二次利用,帮助实现解码器从编码器路径中恢复目标的详细信息,但这种方法会导致低维特征值的过度使用. 受注意力机制的启发,在U-Net中引入多重提取高效通道注意力机制(MECA),以增强有效的低维特征,抑制无效特征. MECA模块的结构如图1 所示. 采用自适应一维卷积核和不降维的跨通道交互策略,增强有效的低维特征信息的表达,去除噪声,避免低维特征被过度使用,旨在保护网络的效率和有效性,有助于学习建筑物特征对应的通道,更好地提取建筑物特征. ...
2
... Ronneberger等[13 ] 以FCN为基础提出U-Net,该网络利用跳跃连接结构实现了深层和浅层特征的融合,提高了分割精度,在建筑物提取任务中得到了广泛应用. 为了进一步提高建筑物的提取效果,研究人员在U-Net的基础上,提出神经网络DeepResUnet[14 ] 和BRRNet[15 ] . 这些网络的跳跃连接层容易导致低维特征值的过度引用,造成图像的错分和漏分. Chen等[16 -17 ] 提出空间金字塔池化(ASPP)模块,该模块利用不同空洞率的卷积提取不同尺度的特征值. 更大空洞率在带来更大视野的同时,会导致有效特征值的过度损失. 冉树浩等[18 ] 提出BMFR-Net,该网络通过并行连续空洞卷积,改善了空洞卷积带来的信息丢失,但网络没有重点提取建筑物的特征,减少非建筑物特征的提取. ...
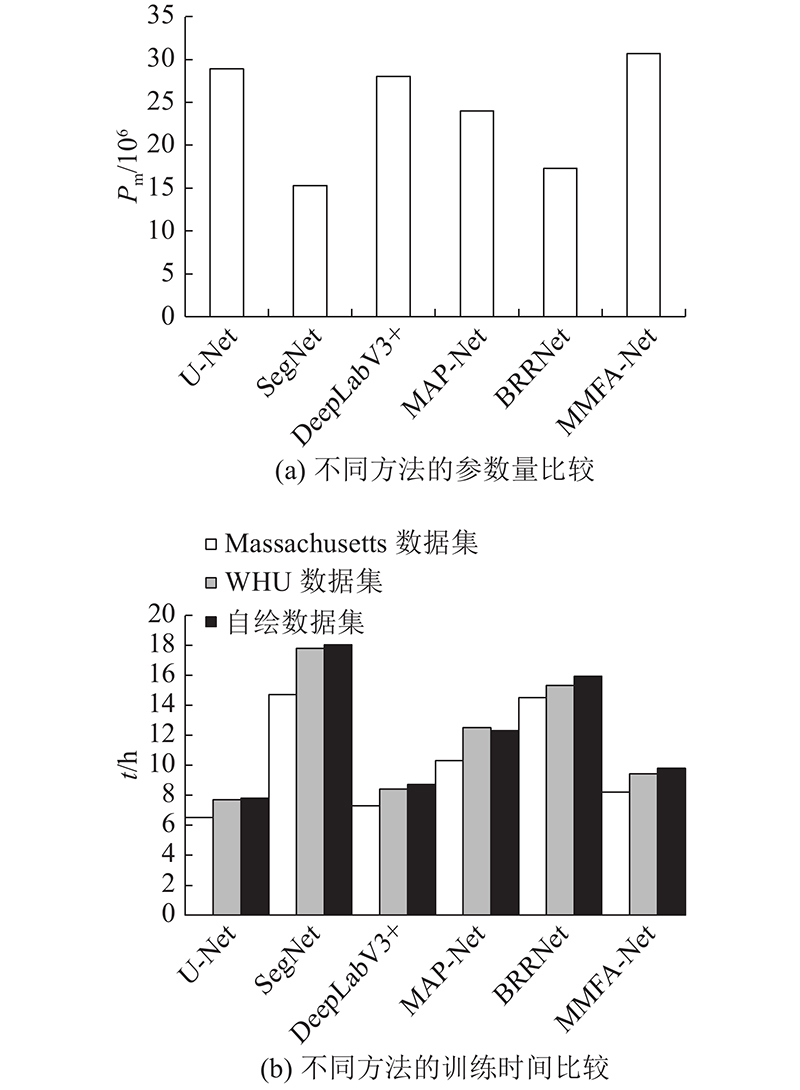
... 为了有效评估MMFA-Net的精度性能,将MMFA-Net与U-Net[13 ] 、SegNet[30 ] 、DeepLabV3+[31 ] 、MAP-Net[32 ] 及BRRNet[15 ] 网络进行对比. 其中U-Net、SegNet和DeepLabV3+的模型结构均为与本文类似的编解码结构,且U-Net为MMFA-Net的主体框架. SegNet具有独特的池化索引结构,DeepLabV3+是DeepLab系列最新的一个. 考虑到残差结构和空洞卷积对神经网络的影响,选择BRRNet作为对比实验. 将MMFA-Net与具有多通道分支结构的建筑物提取网络MAP-Net进行对比. ...
Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network
1
2019
... Ronneberger等[13 ] 以FCN为基础提出U-Net,该网络利用跳跃连接结构实现了深层和浅层特征的融合,提高了分割精度,在建筑物提取任务中得到了广泛应用. 为了进一步提高建筑物的提取效果,研究人员在U-Net的基础上,提出神经网络DeepResUnet[14 ] 和BRRNet[15 ] . 这些网络的跳跃连接层容易导致低维特征值的过度引用,造成图像的错分和漏分. Chen等[16 -17 ] 提出空间金字塔池化(ASPP)模块,该模块利用不同空洞率的卷积提取不同尺度的特征值. 更大空洞率在带来更大视野的同时,会导致有效特征值的过度损失. 冉树浩等[18 ] 提出BMFR-Net,该网络通过并行连续空洞卷积,改善了空洞卷积带来的信息丢失,但网络没有重点提取建筑物的特征,减少非建筑物特征的提取. ...
BRRNet: a fully convolutional neural network for automatic building extraction from high-resolution remote sensing images
2
2020
... Ronneberger等[13 ] 以FCN为基础提出U-Net,该网络利用跳跃连接结构实现了深层和浅层特征的融合,提高了分割精度,在建筑物提取任务中得到了广泛应用. 为了进一步提高建筑物的提取效果,研究人员在U-Net的基础上,提出神经网络DeepResUnet[14 ] 和BRRNet[15 ] . 这些网络的跳跃连接层容易导致低维特征值的过度引用,造成图像的错分和漏分. Chen等[16 -17 ] 提出空间金字塔池化(ASPP)模块,该模块利用不同空洞率的卷积提取不同尺度的特征值. 更大空洞率在带来更大视野的同时,会导致有效特征值的过度损失. 冉树浩等[18 ] 提出BMFR-Net,该网络通过并行连续空洞卷积,改善了空洞卷积带来的信息丢失,但网络没有重点提取建筑物的特征,减少非建筑物特征的提取. ...
... 为了有效评估MMFA-Net的精度性能,将MMFA-Net与U-Net[13 ] 、SegNet[30 ] 、DeepLabV3+[31 ] 、MAP-Net[32 ] 及BRRNet[15 ] 网络进行对比. 其中U-Net、SegNet和DeepLabV3+的模型结构均为与本文类似的编解码结构,且U-Net为MMFA-Net的主体框架. SegNet具有独特的池化索引结构,DeepLabV3+是DeepLab系列最新的一个. 考虑到残差结构和空洞卷积对神经网络的影响,选择BRRNet作为对比实验. 将MMFA-Net与具有多通道分支结构的建筑物提取网络MAP-Net进行对比. ...
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
1
2017
... Ronneberger等[13 ] 以FCN为基础提出U-Net,该网络利用跳跃连接结构实现了深层和浅层特征的融合,提高了分割精度,在建筑物提取任务中得到了广泛应用. 为了进一步提高建筑物的提取效果,研究人员在U-Net的基础上,提出神经网络DeepResUnet[14 ] 和BRRNet[15 ] . 这些网络的跳跃连接层容易导致低维特征值的过度引用,造成图像的错分和漏分. Chen等[16 -17 ] 提出空间金字塔池化(ASPP)模块,该模块利用不同空洞率的卷积提取不同尺度的特征值. 更大空洞率在带来更大视野的同时,会导致有效特征值的过度损失. 冉树浩等[18 ] 提出BMFR-Net,该网络通过并行连续空洞卷积,改善了空洞卷积带来的信息丢失,但网络没有重点提取建筑物的特征,减少非建筑物特征的提取. ...
1
... Ronneberger等[13 ] 以FCN为基础提出U-Net,该网络利用跳跃连接结构实现了深层和浅层特征的融合,提高了分割精度,在建筑物提取任务中得到了广泛应用. 为了进一步提高建筑物的提取效果,研究人员在U-Net的基础上,提出神经网络DeepResUnet[14 ] 和BRRNet[15 ] . 这些网络的跳跃连接层容易导致低维特征值的过度引用,造成图像的错分和漏分. Chen等[16 -17 ] 提出空间金字塔池化(ASPP)模块,该模块利用不同空洞率的卷积提取不同尺度的特征值. 更大空洞率在带来更大视野的同时,会导致有效特征值的过度损失. 冉树浩等[18 ] 提出BMFR-Net,该网络通过并行连续空洞卷积,改善了空洞卷积带来的信息丢失,但网络没有重点提取建筑物的特征,减少非建筑物特征的提取. ...
Building multi-feature fusion refined network for building extraction from high-resolution remote sensing images
1
2021
... Ronneberger等[13 ] 以FCN为基础提出U-Net,该网络利用跳跃连接结构实现了深层和浅层特征的融合,提高了分割精度,在建筑物提取任务中得到了广泛应用. 为了进一步提高建筑物的提取效果,研究人员在U-Net的基础上,提出神经网络DeepResUnet[14 ] 和BRRNet[15 ] . 这些网络的跳跃连接层容易导致低维特征值的过度引用,造成图像的错分和漏分. Chen等[16 -17 ] 提出空间金字塔池化(ASPP)模块,该模块利用不同空洞率的卷积提取不同尺度的特征值. 更大空洞率在带来更大视野的同时,会导致有效特征值的过度损失. 冉树浩等[18 ] 提出BMFR-Net,该网络通过并行连续空洞卷积,改善了空洞卷积带来的信息丢失,但网络没有重点提取建筑物的特征,减少非建筑物特征的提取. ...
1
... 近年来,注意力机制被广泛应用于计算机视觉领域,其中代表性网络为SE-Net(squeeze-and-excitation networks)[19 ] . 该网络通过获得每个特征通道的重要程度,突出首要特征,为CNN结构模型带来一定的性能增幅. Gao等[20 -22 ] 通过捕获更加复杂的相关通道的依存关系改善通道注意力,或者利用添加空间注意力机制的方法来改进注意力机制模块. ...
1
... 近年来,注意力机制被广泛应用于计算机视觉领域,其中代表性网络为SE-Net(squeeze-and-excitation networks)[19 ] . 该网络通过获得每个特征通道的重要程度,突出首要特征,为CNN结构模型带来一定的性能增幅. Gao等[20 -22 ] 通过捕获更加复杂的相关通道的依存关系改善通道注意力,或者利用添加空间注意力机制的方法来改进注意力机制模块. ...
1
... 近年来,注意力机制被广泛应用于计算机视觉领域,其中代表性网络为SE-Net(squeeze-and-excitation networks)[19 ] . 该网络通过获得每个特征通道的重要程度,突出首要特征,为CNN结构模型带来一定的性能增幅. Gao等[20 -22 ] 通过捕获更加复杂的相关通道的依存关系改善通道注意力,或者利用添加空间注意力机制的方法来改进注意力机制模块. ...
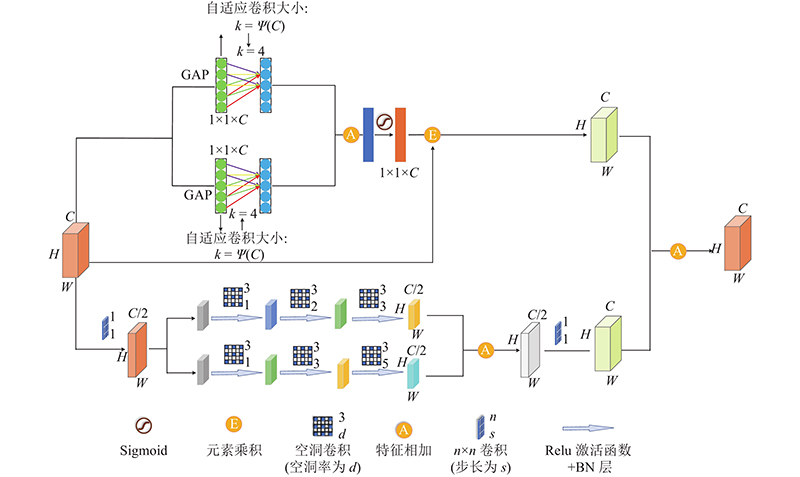
3
... 现有的通道注意力机制在提高精度的同时为网络引入了更多的训练参数,增加了模型的复杂度. 针对上述问题,本文在通道注意力[23 ] (efficient channel attention, ECA)的基础上,提出多重提取高效通道注意机制(multiple-extract efficient channel attention, MECA)模块. 为了进一步优化网络性能,增强网络判决能力,设计多尺度融合注意力(multiscale-feature fusion attention, MFA)模块,构建新型的轻量级建筑物提取网络MMFA-Net. ...
... 式中: $\gamma $ $b$ $C$ ${\left| t \right|_{{\text{odd}}}}$ $t$ . 全局平均池化(global average pooling, GAP)[24 ] 对每一个特征图进行平局值的操作,形成含有 $n$ $n$ [23 ] 网络模型进行改进,提出MECA模块. 通过并行2次全局平均池化及一维卷积运算,开展特征融合,强化了部分重要特征值的提取能力. 为了实现以上思想,采用卷积核大小为 $k$ $k - 1$
... 式中: ${\boldsymbol{F}} \in {{\bf{R}}^{C \times H \times W}}$ ${{\boldsymbol{F}}_{\text{P}}} \in {{\bf{R}}^{C \times H \times W}}$ $ \otimes $ ${\boldsymbol{\phi}} _{{k_1}}^D $ ${k_1}$ $D$ $\delta $ [25 ] 层和Sigmoid激活函数;“ $* $ [26 ] 的思想,以实现对输入特征中不同尺寸特征值的提取,缓解不同尺度特征提取中重要信息的损失. 模块融合注意力机制思想来源于高效通道注意力ECA[23 ] ,旨在增强网络的语义分割能力,通过高效、自动地获取各个通道的重要程度并赋予权重,达到增强首要特征的效果. ...
1
... 式中: $\gamma $ $b$ $C$ ${\left| t \right|_{{\text{odd}}}}$ $t$ . 全局平均池化(global average pooling, GAP)[24 ] 对每一个特征图进行平局值的操作,形成含有 $n$ $n$ [23 ] 网络模型进行改进,提出MECA模块. 通过并行2次全局平均池化及一维卷积运算,开展特征融合,强化了部分重要特征值的提取能力. 为了实现以上思想,采用卷积核大小为 $k$ $k - 1$
2
... 式中: ${\boldsymbol{F}} \in {{\bf{R}}^{C \times H \times W}}$ ${{\boldsymbol{F}}_{\text{P}}} \in {{\bf{R}}^{C \times H \times W}}$ $ \otimes $ ${\boldsymbol{\phi}} _{{k_1}}^D $ ${k_1}$ $D$ $\delta $ [25 ] 层和Sigmoid激活函数;“ $* $ [26 ] 的思想,以实现对输入特征中不同尺寸特征值的提取,缓解不同尺度特征提取中重要信息的损失. 模块融合注意力机制思想来源于高效通道注意力ECA[23 ] ,旨在增强网络的语义分割能力,通过高效、自动地获取各个通道的重要程度并赋予权重,达到增强首要特征的效果. ...
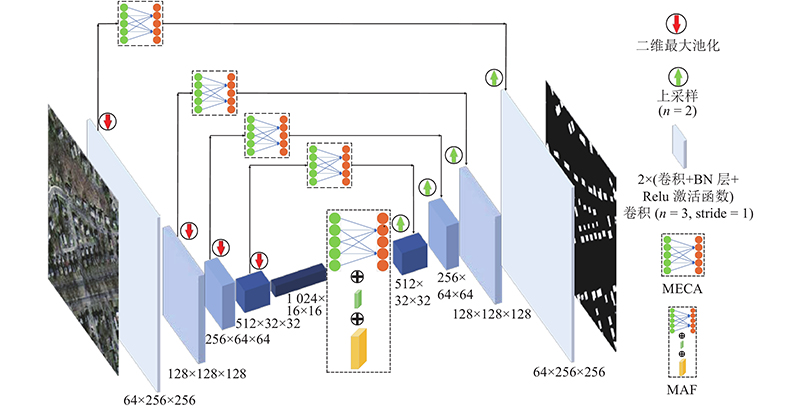
... 提出MMFA-Net,该模型以U-Net网络为主干,在跳跃连接层内嵌入MECA,在底层加MFA确保首要信息的保留,防止重要信息的丢失. 通过MECA注意力门控制关注区域,提取重要特征值,提高建筑物的提取精度;在每次卷积之后添加BN[25 ] 层,改善网络的梯度. 在模型底部加入MFA,在不同尺度上对影像进行提取,改善了有效特征的丢失;利用注意力思想,保留重要特征,删减次要特征. 该模型平衡了计算效率和计算参数,在一定程度上提高了网络的精度. 如图3 所示为网络模型的整体结构. ...
1
... 式中: ${\boldsymbol{F}} \in {{\bf{R}}^{C \times H \times W}}$ ${{\boldsymbol{F}}_{\text{P}}} \in {{\bf{R}}^{C \times H \times W}}$ $ \otimes $ ${\boldsymbol{\phi}} _{{k_1}}^D $ ${k_1}$ $D$ $\delta $ [25 ] 层和Sigmoid激活函数;“ $* $ [26 ] 的思想,以实现对输入特征中不同尺寸特征值的提取,缓解不同尺度特征提取中重要信息的损失. 模块融合注意力机制思想来源于高效通道注意力ECA[23 ] ,旨在增强网络的语义分割能力,通过高效、自动地获取各个通道的重要程度并赋予权重,达到增强首要特征的效果. ...
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set
1
2018
... WHU[27 ] 建筑物数据集图覆盖了新西兰克赖斯特彻奇大约450 km2 的区域,由3部分构成:18 944幅影像的训练集、4 144幅影像的验证集和9 664幅影像的测试集. 受限于GPU,所有影像均为256×256像素,空间分辨率均为0.3 m. 如图4 (b)所示为部分影像与对应的建筑物标签数据. ...
1
... Table of training parameters
Tab.1 参数 数值 输入图像像素 256×256 优化器 Adam[28 ] 学习率 0.0001 每次训练选取样本数 6 在Massachusetts数据集上的训练轮数 200 在WHU数据集上的训练轮数 50 在自绘数据集上的训练轮数 200
2.2.1. 评价指标 选择5种常用于语义分割任务的评估度量,评估实验结果包括总精度OA、准确度P 、召回率R 、F 1 分数F 1 、交并比IoU,公式如下. ...
1
... 模型采用Dice loss[29 ] 作为损失函数,以应对样本中建筑物像素与背景像素数目不均衡的问题. Dice loss的计算过程如下所示: ...
Segnet: a deep convolutional encoder-decoder architecture for image segmentation
1
2017
... 为了有效评估MMFA-Net的精度性能,将MMFA-Net与U-Net[13 ] 、SegNet[30 ] 、DeepLabV3+[31 ] 、MAP-Net[32 ] 及BRRNet[15 ] 网络进行对比. 其中U-Net、SegNet和DeepLabV3+的模型结构均为与本文类似的编解码结构,且U-Net为MMFA-Net的主体框架. SegNet具有独特的池化索引结构,DeepLabV3+是DeepLab系列最新的一个. 考虑到残差结构和空洞卷积对神经网络的影响,选择BRRNet作为对比实验. 将MMFA-Net与具有多通道分支结构的建筑物提取网络MAP-Net进行对比. ...
1
... 为了有效评估MMFA-Net的精度性能,将MMFA-Net与U-Net[13 ] 、SegNet[30 ] 、DeepLabV3+[31 ] 、MAP-Net[32 ] 及BRRNet[15 ] 网络进行对比. 其中U-Net、SegNet和DeepLabV3+的模型结构均为与本文类似的编解码结构,且U-Net为MMFA-Net的主体框架. SegNet具有独特的池化索引结构,DeepLabV3+是DeepLab系列最新的一个. 考虑到残差结构和空洞卷积对神经网络的影响,选择BRRNet作为对比实验. 将MMFA-Net与具有多通道分支结构的建筑物提取网络MAP-Net进行对比. ...
MAP-Net: multiple attending path neural network for building footprint extraction from remote sensed imagery
1
2020
... 为了有效评估MMFA-Net的精度性能,将MMFA-Net与U-Net[13 ] 、SegNet[30 ] 、DeepLabV3+[31 ] 、MAP-Net[32 ] 及BRRNet[15 ] 网络进行对比. 其中U-Net、SegNet和DeepLabV3+的模型结构均为与本文类似的编解码结构,且U-Net为MMFA-Net的主体框架. SegNet具有独特的池化索引结构,DeepLabV3+是DeepLab系列最新的一个. 考虑到残差结构和空洞卷积对神经网络的影响,选择BRRNet作为对比实验. 将MMFA-Net与具有多通道分支结构的建筑物提取网络MAP-Net进行对比. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}