

自适应采样是以经典采样与全空间采样为基础发展出来的采样方法,可用于灵敏度分析、不确定性分析及全局优化等方面. 学者已提出的自适应采样模型近似方法很多,举例如下. Böttcher等[1]提出利用人工神经网络集合进行预测方差的自适应采样策略,Beck等[2]通过最大化设计空间来增加采样点,Gratiet等[3]提出基于Kriging的自适应采样方法,Liu等[4]提出自适应最大熵(AME)采样方法,Kucherenko等[5]提出基于概率图的自适应采样方法,郭述臻等[6]提出利用设计空间稀疏性来新增采样点的方法. Ajdari等[7]提出随机仿真模型自适应序列采样算法,Eason等[8]提出的方法将基于人工神经网络的全空间填充与自适应采样相混合. Liu等[9]提出基于径向基函数的最优加权点集自适应采样策略,Jiang等[10]针对输出空间的特性提出自适应采样策略,Steiner等[11]提出基于特定响应面模型的自适应采样方法,Wen等[12]提出避免在概率密度很低的区域选择样本的自适应采样策略,谢雨珩等[13]提出基于稀疏度和最邻近期望的自适应采样算法. Van等[14]提出的基于模糊逻辑的采样策略,适用于高维模型的近似处理,具有计算快及鲁棒性强的特点; Pan等[15]利用响应面模型的极值点和密度函数的最小点来自适应采样;Shahsavani等[16]提出的基于粗糙度的自适应采样方法能够利用插值方式实现多项式近似模型. 在将自适应采样方法运用于全局优化方面,Diez等[17]提出的方法将动态径向基函数响应面模型与顺序多准则自适应采样技术相结合,能够在优化目标过程中不断提高近似模型的精度;Serani等[18]提出基于随机径向基函数的自适应采样方法;Li等[19]提出基于多级自适应采样策略的改进SAO算法以逐步提高模型精度.
根据实际预测误差的表示方式,可以将上述自适应采样方法分为4类:1)基于方差自适应采样(Böttcher等[1-6]提出的方法),2)基于委员会查询的自适应采样(Ajdarj等[7-8,17-19]提出的方法),3)基于交叉验证的自适应采样(Liu等[9-13]提出的方法),4)基于梯度自适应采样(Van等[14-16]提出的方法). 自适应采样方法可以利用自身的采样技术完成对相关函数模型或者复杂产品模型的近似处理. 然而上述方法1)只能构造特定响应面模型;2)没有考虑曲面曲率的几何特性,即没有从几何角度利用曲面曲率进行自适应采样研究;3)对设计域的范围有限定,不适合大的设计域. 针对上述问题,本研究提出自适应采样结合曲面曲率的全局近似方法(adaptive sampling combined with surface curvature global approximation, ASCGA),并将其用于函数源模型及复杂电动车模型的近似处理测试,以证明ASCGA的实用性和有效性.
1. 响应面方法
构造响应面(response surface,RS)模型是响应面方法的主要功能. RS的常用模型包括多项式响应面(polynomial response surface,PRS)模型、Kriging插值模型、径向基函数(radial basis functions,RBF)模型等. 鉴于PRS模型具有较高的计算效率,为了降低计算复杂度,本研究将主要考虑该模型.
PRS模型的计算式为
使用二次多项式函数近似,得到
式中:
2. ASCGA
2.1. 方法描述
ASCGA采用中心点加全部端点的部分因子采样法获取初始采样集S. 设
上述过程涉及2个问题:1)如何确定设计域最佳分割位置,2)如何确定哪个子设计域需要进一步分割. 对于问题1),ASCGA将启发式直接搜索算法DIRECT[20]与曲面曲率几何计算法结合,迭代搜寻沿某个维度上的最大曲率点. DIRECT是全局优化算法,其搜寻准则为
式中:x为曲面上所求的某点,L为沿第i个维度上设计域的边长,
式中:
对不同维度的最大曲率进行排序及筛选,选择最大js所在的维度为该设计域的分割维度方向,同时最大js对应的最大曲率点位置也是设计域最佳分割位置.
对于问题2),ASCGA引入判定PRS模型精度的方法,通过判定各PRS模型域内已有采样点的最大源模型值与最小源模型值之差确定PRS模型的精度. 该值越大,说明PRS模型非线性越强. 在每次迭代过程中,ASCGA选择若干PRS模型作为最大误差单元. 上述判定PRS模型精度的方法区别于通过在子设计域内采样来判定RS模型精度的方法,可以大幅降低计算复杂度.
图 1
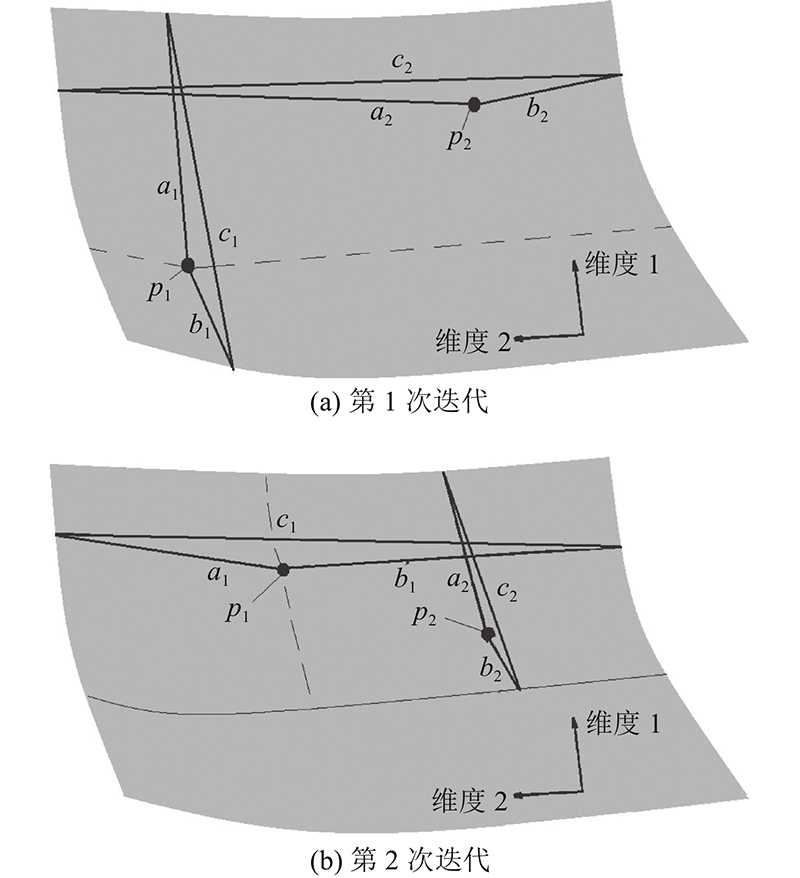
图 1 利用ASCGA进行的设计域前2次迭代分割过程
Fig.1 First two iterations of design domain segmentation process using ASCGA
采用ASCGA对现有设计域分割,每次都会获得2个子设计域,并会在子设计域内构造新的PRS模型. 因此随着迭代进行,原设计域被不断分割,子设计域及PRS模型越来越多,这些PRS模型的集合称为响应面集(response surface set,RSS). DIRECT在PRS模型内进行全局搜索时,若最大曲率点与设计域边界十分接近,将使DIRECT进行局部搜索,引起较大误差. 为了避免这种情况,应适当增加曲率最大点与设计域边界的距离. 分割不同源模型的原设计域得到的子设计域数量不同,ASCGA中子设计域数量主要取决于源模型特性和参数设置. 若源模型存在非线性较强的区域,则在该区域一般需要较多的子设计域来满足总体近似模型在该区域的精度要求. ASCGA设置了多个参数作为迭代计算退出准则. 若在自适应设计域分割过程中满足某退出准则,则退出迭代计算,并在获得一定精度的总体近似模型情况下得到一定数量的子设计域. 为了使不同的源模型的设计域分割成合理数量的子设计域,并兼顾计算效率和总体近似模型精度,须根据实际需求确定源模型的总体近似模型精度要求δ3. 若δ3设置过小,则子设计域数量增加,计算效率降低. 根据源模型的原设计域设置参数:δ1为子设计域最小边长、δ2为子设计域构造的PRS模型误差. 若原设计域具有较大的尺寸,则δ1应适当增大,避免原设计域在非线性较强的区域过度划分,以降低计算复杂度,提高计算效率. 也应注意到,这样做适度降低了近似模型精度. 设置δ2为合理值,可以避免由于δ2过小使原设计域划分过密,从而导致计算效率降低. 总之,为了使原设计域在自适应分割过程中能够平衡计算效率及总体近似模型精度,应该在确定δ3的情况下,选择合适的δ1、δ2,使得ASCGA在计算过程中能够保证总体近似模型具有较好的精度和计算效率.
2.2. 方法流程
ASCGA实现源模型全局近似的流程如图2所示.
图 2
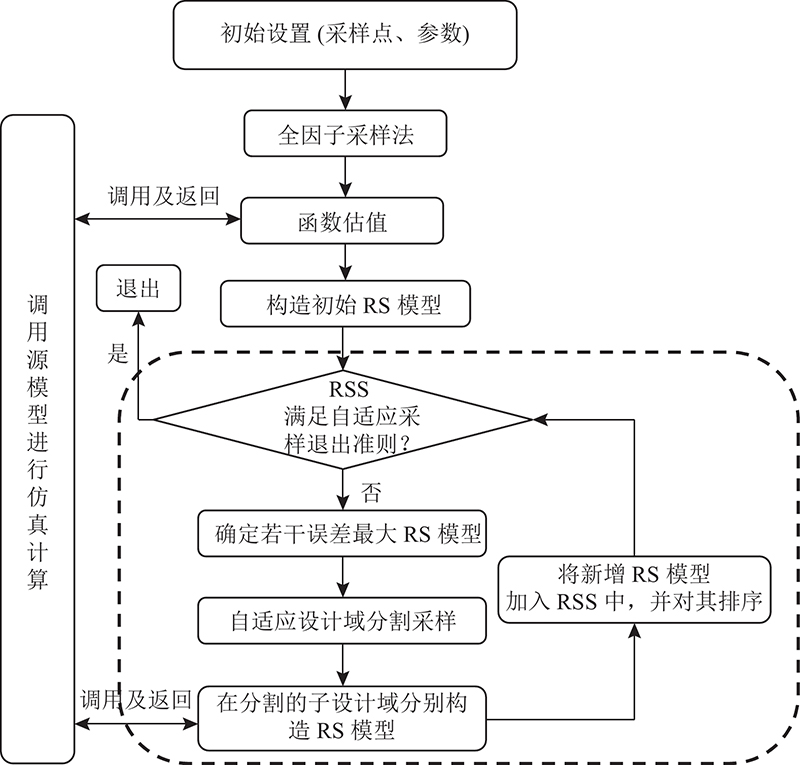
1 )初始采样点及参数设置. 采样点采用端点加中心点的全因子采样法获取. 参数包括设计域最大分割次数N、δ1、δ2、δ3.
2) 构建初始RS模型. 在整个设计域内,利用初始采样点调用源模型进行仿真计算,获得相应的源模型值,结合初始采样点及源模型值构造初始RS模型.
设计域自适应采样过程步骤如下. 3)迭代计算,若方法满足退出准则,则退出. 迭代准则主要涉及:迭代过程达到设计域最大分割次数、子设计域边长小于δ1、RSS中每个RS模型误差都小于δ2、RSS总体近似模型误差小于δ3. 4)获取RSS中每个RS模型的绝对误差,选择最大误差的RS模型的设计域作为后续分割对象. 5)利用DIRECT结合曲面曲率计算方法迭代搜寻RS模型曲面上沿某个维度的最大曲率点(设计域最佳分割位置),获得非线性最强的维度方向,在该维度上按最佳分割位置分割子设计域. 在分割的2个子设计域内分别利用已有采样点集构建新的RS模型. 6)更新RSS模型,返回步骤3). 在构造新的RS模型添加到原有RSS时,重新对原有RSS内的各个RS模型进行删减、排序.
7)计算结束.
3. 函数算例
使用标准无约束测试函数源模型测试ASCGA. 测试函数源模型为generalized polynomial function (GF)函数、Schaffer’s函数、Apline函数及Hartmann函数. 如表1所示,δ1根据算例的不同设计域尺寸进行设定;δ2、δ3均设置为10−3,若数值设置较大,则可能导致近似处理过早结束.
表 1 模型参数及ASCGA参数设定
Tab.1
| 算例编号 | δ1 | δ2 | δ3 |
| 1) | 0.2 | 10−3 | 10−3 |
| 2) | 0.2 | 10−3 | 10−3 |
| 3) | 0.2 | 10−3 | 10−3 |
| 4) | 0.1 | 10−3 | 10−3 |
算例1): 二维GF函数为
式中:x1、x2∈[−2, 2].
算例2): 二维Schaffer’s 函数为
式中:x1、x2∈[−2, 2].
算例3): 三维Apline函数为
式中:x1、x2、x3∈[0,10].
算例4): 三维Hartmann函数为
式中:x1、x2、x3∈[0,1].
采用增量拉丁超立方采样(Latin hypercube sampling,LHCS)及基于粗糙度的自适应采样(adaptive sampling based on roughness sampling,ASRS)[16]近似处理函数源模型. LHCS为全空间采样方法,是在全空间内随机但不重叠的采样. ASRS作为自适应采样方法,可以对设计域进行自适应分割采样. 利用LHCS、ASRS采样评估ASCGA的采样效率及近似模型构造精度,并在LHCS及ASRS采样后均利用RBF构造近似模型. 在测试最终获得的近似模型时,为了克服LHCS采样的随机性,进行多次数值试验并取均方根误差(root mean square error,RMSE)的平均值.
利用3种采样方法构造的函数源模型的近似模型测试结果如表2、3所示. 表中,R1、R2、R3及R4表示利用ASCGA分别构造算例1)~4)近似模型的均方根误差. T1、T2、T3及T4分别构造算例1)~4)近似模型的估值次数. 可知,与LHCS、ASRS相比,ASCGA能够在二维情况下使用有限个采样点构造较高精度的近似模型. 不同采样方法的效率高低由函数源模型的估值次数多少来判断. 函数源模型越复杂,估值次数越多,耗时越长,相应方法的效率越低. 可知,在相同精度条件下,ASCGA比LHCS、ASRS的效率更高. 如图3、4所示分别为采用ASCGA对二维函数源模型的设计域分割情况和近似模型三维视图. 在三维情况下, ASCGA需要较多数量的采样点才能获得一定精度的近似模型. 由表可知,ASCGA对源模型进行近似处理的初期效果略逊于LHCS,但是随着采样点的增多,ASCGA的精度、效率都有明显提升. ASRS的三维源模型近似处理效果不佳,即使增加采样点,也不能提高该方法的近似模型精度.
表 2 在不同采样数量情况下3种方法构造的函数近似模型精度对比
Tab.2
| S | R1 | R2 | R3 | R4 | |||||||||||
| LHCS | ASRS | ASCGA | LHCS | ASRS | ASCGA | LHCS | ASRS | ASCGA | LHCS | ASRS | ASCGA | ||||
| 25 | 27.471 | 25.535 | 25.498 | 0.178 | 0.107 | 0.106 | — | — | — | — | — | — | |||
| 50 | 23.707 | 9.8004 | 7.8934 | 0.128 | 0.044 | 0.044 | — | — | — | — | — | — | |||
| 75 | 17.608 | 5.7585 | 5.6250 | 0.066 | 0.040 | 0.027 | — | — | — | — | — | — | |||
| 100 | 14.416 | 2.9364 | 2.9280 | 0.058 | 0.029 | 0.023 | 3.378 | 5.279 | 6.3039 | 1.136 | 1.294 | 1.1825 | |||
| 125 | 12.511 | 1.8283 | 1.7880 | 0.045 | 0.013 | 0.011 | — | — | — | — | — | — | |||
| 150 | 7.1561 | 1.4775 | 1.5980 | 0.024 | 0.010 | 0.009 | — | — | — | — | — | — | |||
| 200 | — | — | — | — | — | — | 2.847 | 3.430 | 3.553 | 0.986 | 1.132 | 0.905 0 | |||
| 300 | — | — | — | — | — | — | 2.283 | 2.877 | 2.934 | 0.859 | 1.584 | 0.843 0 | |||
| 400 | — | — | — | — | — | — | 2.138 | 2.422 | 2.102 | 0.760 | 1.338 | 0.768 0 | |||
| 500 | — | — | — | — | — | — | 1.618 | 1.994 | 1.515 | 0.703 | 1.330 | 0.700 0 | |||
表 3 在不同精度情况下3种方法构造函数近似模型的效率对比
Tab.3
| R1 | T1 | R2 | T2 | R3 | T3 | R4 | T4 | ||||||||
| LHCS | ASRS | ASCGA | LHCS | ASRS | ASCGA | LHCS | ASRS | ASCGA | LHCS | ASRS | ASCGA | ||||
| 20 | 48 | 42 | 44 | 0.10 | 61 | 28 | 25 | 6 | <10 | 89 | 109 | 1.5 | 43 | 68 | 55 |
| 15 | 51 | 49 | 47 | 0.05 | 117 | 41 | 43 | 5 | <10 | 110 | 138 | 1.0 | 137 | 失败 | 144 |
| 10 | 144 | 55 | 51 | 0.03 | 138 | 88 | 68 | 4 | <10 | 151 | 161 | 0.8 | 362 | 失效 | 314 |
| 5 | 182 | 86 | 90 | 0.02 | 166 | 103 | 106 | 3 | 166 | 256 | 244 | 0.5 | 826 | 失效 | 739 |
| 2 | 325 | 131 | 118 | — | — | — | — | 2 | 452 | 488 | 441 | — | — | — | — |
图 3
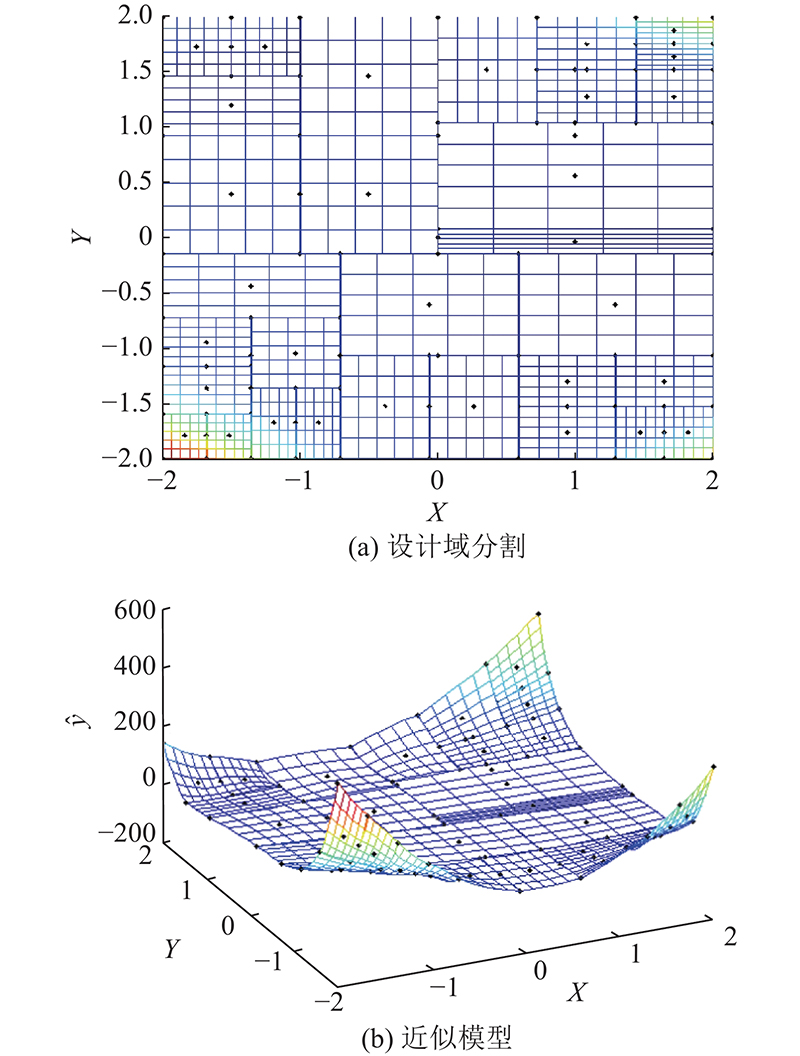
图 3 利用ASCGA方法对GF函数源模型的近似处理(采样数为100)
Fig.3 Approximate processing of GF function model by ASCGA method (sample number: 100)
图 4
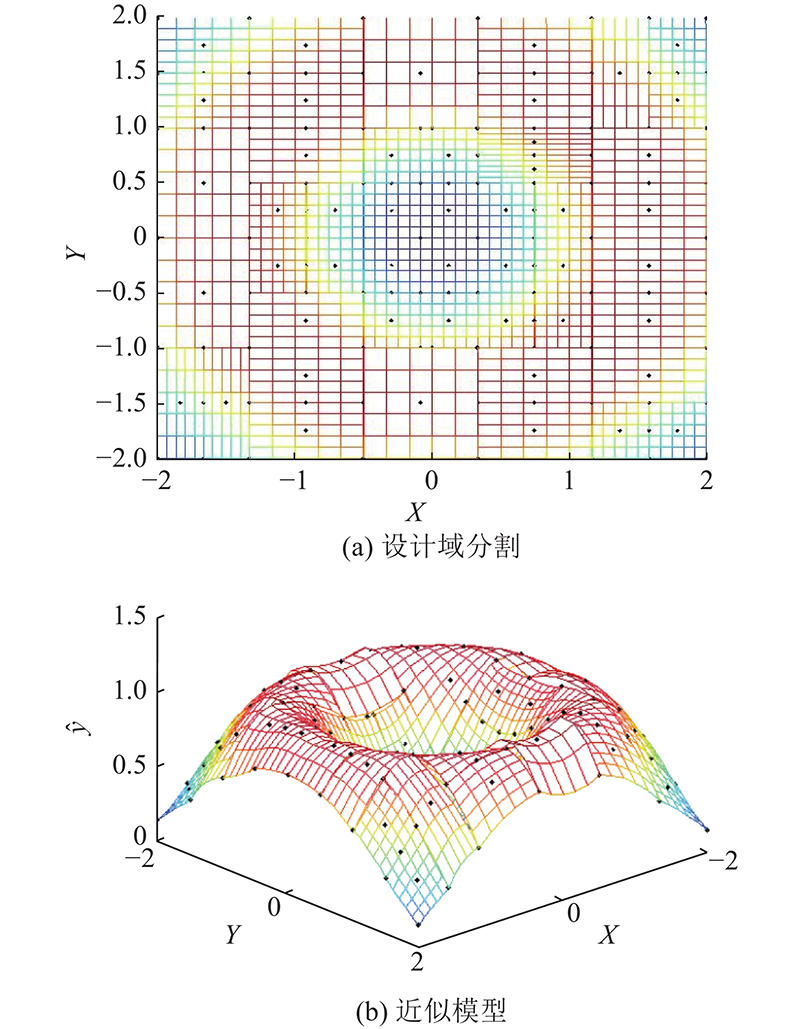
图 4 利用ASCGA方法对Schaffer’s函数源模型的近似处理(采样数为150)
Fig.4 Approximate processing of Schaffer’s function model by ASCGA method (sample number: 150)
4. 实 例
4.1. 问题描述
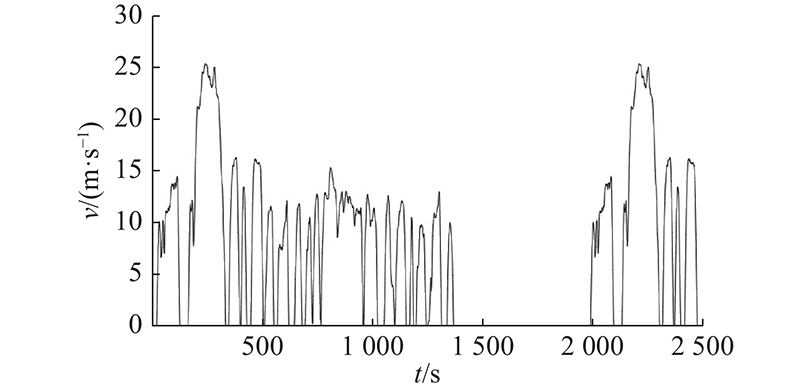
将ASCGA应用于电动车模型的近似处理. 如图5所示,Matlab电动车模型主要包含电机发动机、电池、传动系统及控制器等部件. 电动车模型主要用于动力总成匹配分析,控制与诊断算法设计及硬件在环(hardware in the loop,HIL)测试. HIL测试要求电动车模型仿真无延迟,因此须简化电动车模型. 车辆模型的复杂度最高,对整车模型计算复杂度有直接影响. 为了加快模型仿真计算速度,降低计算复杂度并保证实时性,采用响应面近似模型代替车辆模型,利用足够精度的近似模型进行快速计算. 如图6所示,电动车模型仿真采用FTP75循环工况作为车辆公路行驶的驱动循环. 图中,t为时间,v为车辆行驶速度.
图 5

图 6
4.2. 模型近似过程
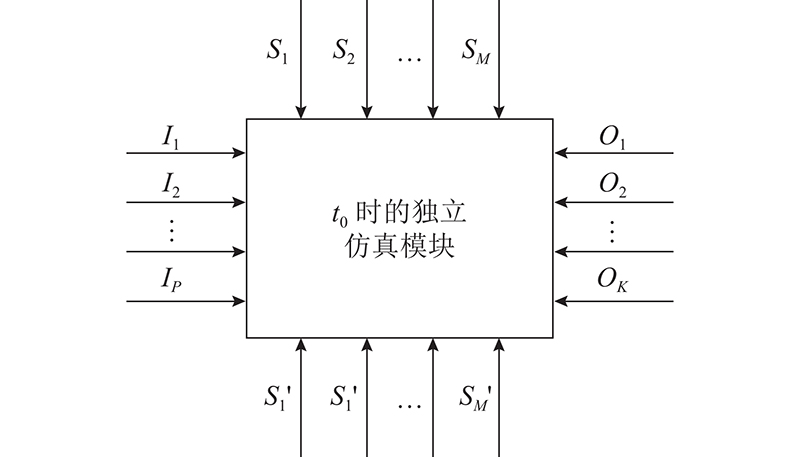
提出基于固定步长且带有反馈的模型处理方法. 如图7所示,模型在运行时存在3个状态:前模型状态、当前模型状态及后模型状态. 图中,Ip为模型的第p个输入,OK为模型的第K个输出. 忽略前后模型状态,对当前状态进行如下处理.
图 7

1)建立独立仿真模块(independent simulation module,ISM). 给ISM添加输入端口和输出端口,包括状态变量的输入及输出端口;由完整电动车模型的历史仿真数据,获得ISM输入变量的取值范围;确定时间步长t0. 不同t0的ISM输出不同结果. 考虑模型的实时环境,设定t0=0.1 s. 如图8所示,处理后的ISM包含状态变量的输入和输出端口及t0. ISM的表达式为
图 8
式中:SM为第M个状态变量输入.
2)利用ASCGA对ISM进行近似处理.
3)验证近似模型精度Acc. Acc的计算式为
式中:xk表示第k个测试点,f(xk)为在点xk在源模型上的真实值,fa(xk)为点xk在近似模型上的估值,
4)若近似模型精度满足要求,则完成对当前状态的处理. 若近似模型精度不能满足要求,则需返回步骤2),继续使用ASCGA处理ISM,进一步提高近似模型精度.
4.3. 状态变量处理过程
模型状态变量的表达式为
式中:t、u、s、y分别为时间、输入、状态和输出变量. 验证近似模型精度,须处理M个状态变量(S1、S2,···,SM),使其能自循环,并能在仿真过程中自动更新,如图9所示. 此时,ISM的输入端口为P个输入加上M个状态变量输入,输出端口为P个输出加上M个状态变量输出. 状态变量输出与输入相差时间步长t0.
图 9
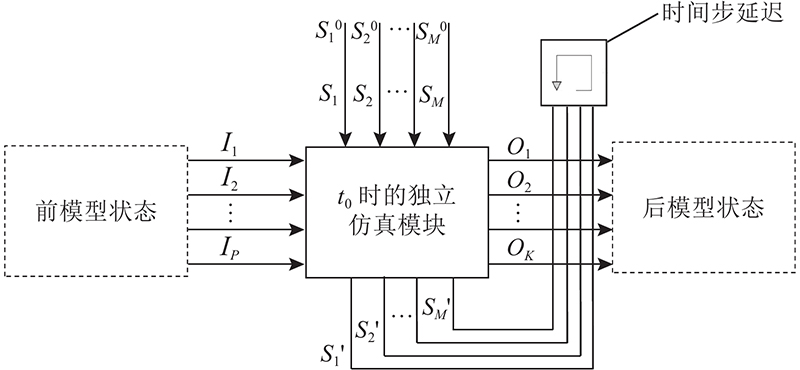
图 9 独立仿真模块中的状态变量处理
Fig.9 Handling of state variables in independent simulation module
4.4. 测试
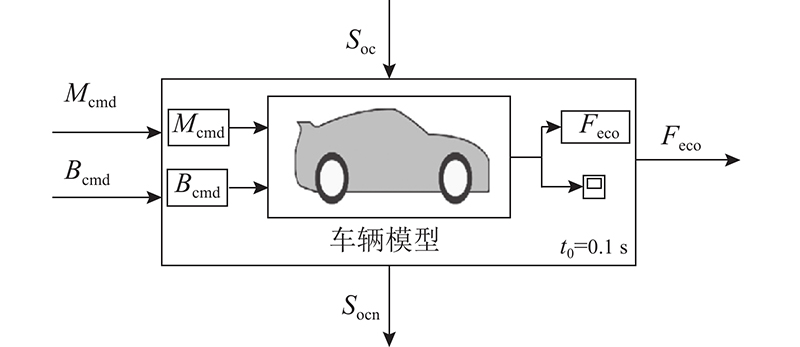
如图10所示,建立车辆模型的ISM,添加3个输入端口(加速指令Mcmd、刹车指令Bcmd及当前电池状态SOC). 添加2个输出端口(燃料经济性Feco,下个时间步长的放电状态SOCn),t0=0.1 s.
图 10
建立车辆模型的ISM,利用ASCGA对ISM进行近似处理,针对2个输出端口的变量分别建立3输入1输出的Feco近似模型和SOC近似模型. 近似过程中Mcmd∈[0,1],Bcmd∈[0,1],SOC∈[93,100]. Mcmd的δ1=0.1, δ2、δ3=10−3. Bcmd的δ1=0.5, δ2、δ3=10−3. SOC的δ1=0.5, δ2、δ3=10−3. 为了验证近似车辆模型精度,使用近似车辆模型代替原车辆模型,如图11所示. 在相同工况下,带有近似车辆模型的整车模型与原整车模型的仿真结果对比如图12所示. 该图纵坐标采用每加仑汽油等同燃料计算整车在特定工况下的经济燃油性,可根据图示曲线计算得到等效百公里耗油. 可知,带有近似车辆模型的整车模型与原整车模型相关仿真曲线基本一致. 带有近似车辆模型的整车模型其SOC的Acc=0.9358,Feco的Acc=0.8977,表明近似车辆模型具有较好的精度. 在一台4 GHz,8 GB内存的计算机上仿真运行原整车模型和带有近似车辆模型的整车模型,前者运行近15 min,后者约为1 min,表明近似模型的仿真计算效率明显高于原有模型.
图 11
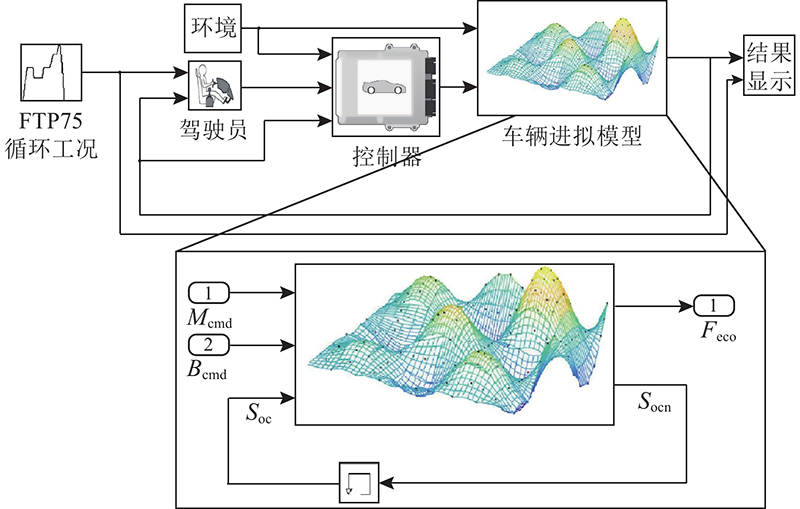
图 11 在电动车上验证近似模型精度
Fig.11 Verify accuracy of approximate model on electric vehicle
图 12
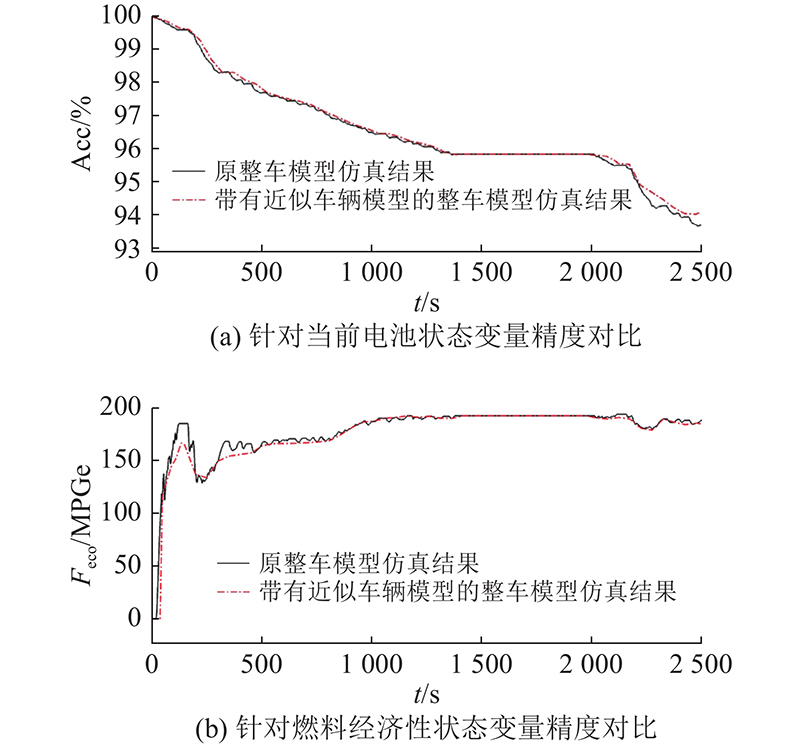
图 12 在相同工况下不同模型的仿真结果对比
Fig.12 Comparison of simulation results with different models under same operating condition
由上述案例可知,通过近似模型代替原有模型,可以大大加速仿真计算效率. 因此,后续可以将带有近似模型的整车模型进行代码生成,导入相应目标机,利用相应电动车控制器实物控制整车模型并测试其实时性,最终实现半物理仿真实验(hardware-in-loop,HIL).
5. 结 论
(1)针对复杂模型近似处理问题,提出自适应采样结合曲面曲率的全局近似方法. 该方法1)具有一定的灵活性,可以运用于其他响应面模型;2)引入新的判定响应面模型精度的方法;3)提出利用几何方法计算曲面曲率,并结合启发式的直接搜索算法DIRECT搜索响应面模型上的最大曲率点及最佳分割位置;4)对于大设计域、大数据量的源模型可以进行有效的近似处理.
(2)本研究所提方法采用设计域自适应分割的采样策略,并在分割后的设计域上进行采样并构造子响应面模型,避免了在大设计域上构造单一的、简单的近似模型,有效提高了大设计域模型的整体近似模型精度. 在分割的子设计域上采用PRS模型构造的近似模型具有计算效率高、占用空间少的优点. 该方法在分割后的众多子设计域上进行采样,仍能高效地实现近似模型构造,避免了在大设计域上采样过多导致近似模型构造缓慢,甚至构造失败的问题.
(3)本研究所提方法存在如下不足之处. 1)ASCGA从几何角度计算曲面曲率. 由于几何方法有自身的缺陷,超过四维的问题,待进一步研究并解决. 2)未能解决设计域分割后子域边界的连续性问题. 即使关键点连续,也不能保障所有边界连续. 3)ASCGA只能构造单个目标的近似模型,因此拓展该方法,使其同时构造多个目标的响应面集近似模型是需要考虑的问题. 4)ASCGA对约束函数的近似处理能力有限,获得的近似模型精度较差;后续可以以此为研究点,并进一步探索非连续区域的约束函数近似问题.
参考文献
ELSA: an efficient, adaptive ensemble learning-based sampling approach
[J].DOI:10.1016/j.advengsoft.2021.102974 [本文引用: 2]
Sequential design with mutual information for computer experiments (MICE): emulation of a tsunami model
[J].DOI:10.1137/140989613 [本文引用: 1]
Kriging-based sequential design strategies using fast cross-validation techniques for multi-fidelity computer codes
[J].DOI:10.1080/00401706.2014.928233 [本文引用: 1]
An adaptive Bayesian sequential sampling approach for global metamodeling
[J].
Computationally efficient identification of probabilistic design spaces through application of metamodeling and adaptive sampling
[J].
一种自适应抽样的代理模型构建及其在复材结构优化中的应用
[J].
Construction of an adaptive sampling surrogate model and application in composite material structure optimization
[J].
An adaptive exploration-exploitation algorithm for constructing metamodels in random simulation using a novel sequential experimental design
[J].
Adaptive sequential sampling for surrogate model generation with artificial neural networks
[J].
Optimal weighted pointwise ensemble of radial basis functions with different basis functions
[J].DOI:10.2514/1.J054664 [本文引用: 2]
A novel sequential exploration-exploitation sampling strategy for global metamodeling
[J].DOI:10.1016/j.ifacol.2015.12.183 [本文引用: 1]
An adaptive sampling method for global sensitivity analysis based on least-squares support vector regression
[J].DOI:10.1016/j.ress.2018.11.015 [本文引用: 1]
A sequential Kriging reliability analysis method with characteristics of adaptive sampling regions and parallelizability
[J].DOI:10.1016/j.ress.2016.05.002 [本文引用: 1]
基于自适应采样算法的芳烃异构化代理模型
[J].
Surrogate model of aromatic isomerization process based on adaptive sampling algorithm
[J].
A fuzzy hybrid sequential design strategy for global surrogate modeling of high-dimensional computer experiments
[J].DOI:10.1137/140962437 [本文引用: 2]
A sequential optimization sampling method for metamodels with radial basis functions
[J].
An adaptive design and interpolation technique for extracting highly nonlinear response surfaces from deterministic models
[J].DOI:10.1016/j.ress.2008.10.013 [本文引用: 3]
Adaptive multi-fidelity sampling for CFD-based optimisation via radial basis function metamodels
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}